Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
ACSI-MJR Jak to się robi i dlaczego tak, czyli krótkie wprowadzenie do złożonych liniowych modeli skalowania

2
Krótki program Wskaźnik, cecha ukryta, reguła korespondencji, skala. Model skalowania. Modele kumulatywne, liniowe. Probabilistyczne i deterministyczne modele skalowania. Reflektywne i formatywne modele skalowania. Analiza czynnikowa, analiza głównych składowych. Liniowe modelowanie procesów: analiza ścieżkowa. Złożone liniowe modele skalowania w socjologii i badaniach rynku – przykłady: skalowanie zadowolenia z miejsca zamieszkania, ISEI, kapitał społeczny, umiejętności złożone. Skalowanie satysfakcji konsumenta za pomocą modelu równań strukturalnych. Dwa warianty modelowania strukturalnego. Strukturalne skalowanie satysfakcji klienta: ACSI –MJR. Statystyczne i obliczeniowe problemy estymacji parametrów modelu skalowania metodą PLS.

3
Program szczegółowy

5
Abdullah, Mokhtar, et. al., 2001, Malaysian Customer Satisfaction Index. TQM World Congress Papers, Saint Petersburg. American Customer Satisfaction Index (ACSI) Methodology Report, 2001, National Quality Research Center (NQRC), University of Michigan, Business School. Byrne, B. M., 2010, Structural Equation Modeling With AMOS: Basic Concepts, Applications, and Programming, 2nd ed. Taylor and Francis Group, LLC. Chatelin, Yves Marie et. al., 2002, State of art on PLS modeling, ECSI. Chin Wynne W., Matthew K. O. Lee, 2000, A proposed model and measurement instrument for the formation of IS satisfaction: the case of end-user computing satisfaction ICIS Conference Proceedings. Dunteman, G. H Principal components analysis: Quantitative applications in the social sciences. SAGE Publications, Thousand Oaks. Fornell, Claes, 1992, A National Customer Satisfaction Barometer: The Swedish Experience. Journal of Marketing; Jan 1992; 56. Fornell, Claes; et.al., 1996, The American Customer Satisfaction Index: Nature, purpose, and findings. Journal of Marketing; Oct 1996; 60, Freed Larry, 2009, American Customer Satisfaction Index. E-Government Satisfaction Index ForeSee Results. Ganzeboom, Harry, B.G. et. al., 1992, A Standard International Socio-Economic Index Of Occupational Status. Social Science Research, 21, 1-56 (1992). Johnson Michael D., et. al., 2001, The evolution and future of national customer satisfaction index models. Journal of Economic Psychology, 22 (2001), Kaplan, D Structural equation modeling: Foundations and extensions. Sage Publications, Inc. Kim, J. O. and C. W. Mueller Factor analysis: Statistical methods and practical issues.Sage Publications, Inc. Kim, J. O. and C. W. Mueller Introduction to factor analysis: What it is and how to do it. Sage Publications, Inc. Kline, R. B Principles and practice of structural equation modeling. The Guilford Press. Konarski, Roman Modele równań strukturalnych. Teoria i praktyka. PWN. Lissowski, Grzegorz, et. al., 2008, Podstawy statystyki dla socjologów. Oficyna Naukowa Scholar. Nie, Norman H SPSS: statistical package for the social sciences. 2d ed. New York: McGraw-Hill. (wybrane rozdziały) Pirouz Dante M., 2006, An Overview of Partial Least Squares. The Paul Merage School of Business, University of California, Irvine (draft). Sellin Norbert, Otto Versand, 2007, Partial Least Squares Modeling in Research on Educational Achievement, Hamburg. Tacq Jacques, 1997, Multivariate Analysis Techniques in Social Science Research. From Problem to Analysis. SAGE Publications, London. Temme, D. et. al., 2006, PLS Path Modeling – A Software Review, SFB 649 Discussion Paper Tenenhaus, M. et al., 2004, PLS path modeling, Computational Statistics & Data Analysis 48 (2005) 159 – 205. Yang, Xiaoming, et. al., 2000, A Comparative Study on Several National Customer Satisfaction Indices (CSI). Shanghai Jiao Tong University, Shanghai, P.R.China. Lektury
 Methodology Report, 2001, National Quality Research Center (NQRC), University of Michigan, Business School. Byrne, B. M., 2010, Structural Equation Modeling With AMOS: Basic Concepts, Applications, and Programming, 2nd ed. Taylor and Francis Group, LLC. Chatelin, Yves Marie et. al., 2002, State of art on PLS modeling, ECSI. Chin Wynne W., Matthew K. O. Lee, 2000, A proposed model and measurement instrument for the formation of IS satisfaction: the case of end-user computing satisfaction ICIS Conference Proceedings. Dunteman, G. H Principal components analysis: Quantitative applications in the social sciences. SAGE Publications, Thousand Oaks. Fornell, Claes, 1992, A National Customer Satisfaction Barometer: The Swedish Experience. Journal of Marketing; Jan 1992; 56. Fornell, Claes; et.al., 1996, The American Customer Satisfaction Index: Nature, purpose, and findings. Journal of Marketing; Oct 1996; 60, Freed Larry, 2009, American Customer Satisfaction Index. E-Government Satisfaction Index ForeSee Results. Ganzeboom, Harry, B.G. et. al., 1992, A Standard International Socio-Economic Index Of Occupational Status. Social Science Research, 21, 1-56 (1992). Johnson Michael D., et. al., 2001, The evolution and future of national customer satisfaction index models. Journal of Economic Psychology, 22 (2001), Kaplan, D Structural equation modeling: Foundations and extensions. Sage Publications, Inc. Kim, J. O. and C. W. Mueller Factor analysis: Statistical methods and practical issues.Sage Publications, Inc. Kim, J. O. and C. W. Mueller Introduction to factor analysis: What it is and how to do it. Sage Publications, Inc. Kline, R. B Principles and practice of structural equation modeling. The Guilford Press. Konarski, Roman Modele równań strukturalnych. Teoria i praktyka. PWN. Lissowski, Grzegorz, et. al., 2008, Podstawy statystyki dla socjologów. Oficyna Naukowa Scholar. Nie, Norman H SPSS: statistical package for the social sciences. 2d ed. New York: McGraw-Hill. (wybrane rozdziały) Pirouz Dante M., 2006, An Overview of Partial Least Squares. The Paul Merage School of Business, University of California, Irvine (draft). Sellin Norbert, Otto Versand, 2007, Partial Least Squares Modeling in Research on Educational Achievement, Hamburg. Tacq Jacques, 1997, Multivariate Analysis Techniques in Social Science Research. From Problem to Analysis. SAGE Publications, London. Temme, D. et. al., 2006, PLS Path Modeling – A Software Review, SFB 649 Discussion Paper Tenenhaus, M. et al., 2004, PLS path modeling, Computational Statistics & Data Analysis 48 (2005) 159 – 205. Yang, Xiaoming, et. al., 2000, A Comparative Study on Several National Customer Satisfaction Indices (CSI). Shanghai Jiao Tong University, Shanghai, P.R.China. Lektury.")
6
Skalowanie Skalowalność Wymiarowość Wskaźniki niezbędne
Zmienne obserwowalne i ukryte Poziom pomiaru – typy zmiennych Pomiar a skalowanie Skalowanie Skalowalność Wymiarowość Wskaźniki niezbędne Własności wskaźników Algorytm skalowania Wynik skalowania

7
SKALUJĄC: problemy do rozwiązania
I. Problem skalowalności 1. Jak dalece łączny rozkład wskaźników jest zgodny z modelem? Jak dobrze model pozwala odtwarzać łączny rozkład wskaźników? Czy zbiór wskaźników jest skalowalny, to znaczy, czy stopień zgodności danych z modelem jest wystarczający? II. Problem liczby wymiarów cechy ukrytej i relacji między nimi 2. Ile cech ukrytych (wymiarów zmiennej ukrytej) trzeba założyć aby dany zbiór wskaźników (w danym zbiorze obiektów) był skalowalny? 3. W jakich relacjach pozostają poszczególne wskaźniki z poszczególnymi wymiarami cechy ukrytej? 4. W jakich relacjach pozostają względem siebie wymiary cechy ukrytej III. Czy wszystkie wskaźniki są potrzebne? 5. Czy w zbiorze wskaźników są pozycje zbędne? Czy są wskaźniki (pozycje testu), z których bez szkody dla skalowalności można zrezygnować? IV. Jakie są własności diagnostyczne poszczególnych wskaźników? 6. Jakie są parametry wskaźników? Których wymiarów cechy ukrytej są wskaźnikami V. Jak skalować 7. Jak przyporządkować obiektom wartości zmiennej ukrytej ? [SCORE] VI. Jaki jest efekt skalowania 8. Jaki rozkład ma cecha ukryta w danym zbiorze obiektów? Poziom pomiarowy skali? Prawo jazdy: test, jazda, pomoc medyczna Test oceniający efekt kształcenia na kursie – n pytań o różnym charakterze {pamięć, wiedza matematyczna, biegłość komputerowa, spostrzegawczość, wyobraźnia przestrzenna, wyobraźnia algebraiczna) - tak/nie (ew. w ramkach) [0-1] - wybierz jedną z 4 (jedna prawdziwa) [0-1] - wybierz jedną z 4 (dwie odp.prawdziwe)[0-2] - policz w Excelu - policz w SPSS - policz zw innym pakiecie wprowadzonym w kursie - rozwiąż zadanie na papierze[0-2] - opisz problem [0-5] - udowodnij twierdzenie
 trzeba założyć aby dany zbiór wskaźników (w danym zbiorze obiektów) był skalowalny 3. W jakich relacjach pozostają poszczególne wskaźniki z poszczególnymi wymiarami cechy ukrytej 4. W jakich relacjach pozostają względem siebie wymiary cechy ukrytej. III. Czy wszystkie wskaźniki są potrzebne 5. Czy w zbiorze wskaźników są pozycje zbędne Czy są wskaźniki (pozycje testu), z których bez szkody dla skalowalności można zrezygnować IV. Jakie są własności diagnostyczne poszczególnych wskaźników 6. Jakie są parametry wskaźników Których wymiarów cechy ukrytej są wskaźnikami. V. Jak skalować. 7. Jak przyporządkować obiektom wartości zmiennej ukrytej [SCORE] VI. Jaki jest efekt skalowania. 8. Jaki rozkład ma cecha ukryta w danym zbiorze obiektów Poziom pomiarowy skali Prawo jazdy: test, jazda, pomoc medyczna. Test oceniający efekt kształcenia na kursie – n pytań o różnym charakterze {pamięć, wiedza matematyczna, biegłość komputerowa, spostrzegawczość, wyobraźnia przestrzenna, wyobraźnia algebraiczna) - tak/nie (ew. w ramkach) [0-1] - wybierz jedną z 4 (jedna prawdziwa) [0-1] - wybierz jedną z 4 (dwie odp.prawdziwe)[0-2] - policz w Excelu. - policz w SPSS. - policz zw innym pakiecie wprowadzonym w kursie. - rozwiąż zadanie na papierze[0-2] - opisz problem [0-5] - udowodnij twierdzenie.")
8
Kryteria oceny modelu skalowania
Niezmienniczość wyników skalowania przy dopuszczalnych poziomem pomiaru przekształceniach wskaźników; Optymalność algorytmu skalowania, Jednoznaczność i przekonywujące uzasadnienia dla decyzji, które trzeba podejmować rozwiązując problemy (1) - (8) wymienione wyżej.
 - (8) wymienione wyżej.")
9
Popularne metody analizy danych - szczególne przypadki modeli skalowania
Poziom pomiaru wskaźników Rodzaj zależności wskaźników od cech ukrytych Poziom pomiaru cechy ukrytej Analiza ukrytej struktury Lazarsfelda Nominalny Binarny Probabilistyczny Analiza skupień K-Means Interwałowy Deterministyczy Probabilistyczne metody analizy skupień Skalogram Guttmana Porządkowy Skalogram Mokkena Skalogram Rascha Binarny Porządkowy Eksploracyjna analiza czynnikowa Model równań strukturalnych

10
NURTY TEORII SKALOWANIA
Kumulatywne Addytywne nominalne K: Rasch. Mokken, Guttman - porządkowe A: PC, FA, CTT, SEM - interwałowe Mieszane

11
Dystans społeczny względem grupy
Nieco historii Bogardus, 1926: skala uprzedzeń (dystansów) etnicznych Czy akceptuje Pan(i) [XXXXX] jako: Dystans społeczny względem grupy Spokrewnionego z Panem(ią) w wyniku małżeństwa [0-1] ? 1 Pana(i) bliskiego przyjaciela [0-1] 2 Pana(i) sąsiada mieszkającego na tej samej ulicy [0-1] 3 Osoby wykonującej ten sam zawód co Pan(i) [0-1] 4 Obywatela Pana(i) kraju [0-1] 5 Turysty odwiedzającego Pana(i) kraj [0-1] 6
 etnicznych. Czy akceptuje Pan(i) [XXXXX] jako: Dystans społeczny względem grupy. Spokrewnionego z Panem(ią) w wyniku małżeństwa [0-1] 1. Pana(i) bliskiego przyjaciela [0-1] 2. Pana(i) sąsiada mieszkającego na tej samej ulicy [0-1] 3. Osoby wykonującej ten sam zawód co Pan(i) [0-1] 4. Obywatela Pana(i) kraju [0-1] 5. Turysty odwiedzającego Pana(i) kraj [0-1] 6.")
12
Skok wzwyż Kategoria zawodnika 180 190 200 Liczba udanych prób a b 1 c
b 1 c 2 d 3

13
Obiekty różnią się parametrami istotnymi dla wyniku zdarzenia losowego
Założenia probabilistycznych modeli skalowania kumulatywnego a sytuacja testowania kompetencji Przykład: osoby rozwiązujące zadania testowe Obiekty różnią się parametrami istotnymi dla wyniku zdarzenia losowego Osoby różnią się poziomem kompetencji, łatwością z jaką rozwiązują zdania testowe Wskaźniki różnią parametrami istotnymi dla wyniku zdarzenia losowego Pytania testowe różnią się stopniem trudności, jaką sprawiają odpowiadającym, Obserwowalna reakcja obiektu na wskaźnik jest zdarzeniem losowym Osoby testowane reagują do pewnego stopnia przypadkowo: osoba bardzo kompetentna może nie odpowiedzieć na pytanie łatwe a osoba mało kompetentna może odpowiedzieć a pytanie trudne Zbiór możliwych reakcji i ich prawdopodobieństwa stanowią zmienną losową, której rozkład zależy od parametrów osoby i parametrów wskaźnika (zmienna losowa – funkcja reakcji) Szanse na poprawą odpowiedź osoby na pojedyncze pytanie testowe zależą zarazem od tego jak trudne jest to pytanie i jak kompetentna jest odpowiadająca na nie osoba Reakcje obiektów o ustalonych parametrach (tym samym poziomie kompetencji) są stochastycznie niezależne Pojedyncza osoba odpowiada na kolejne pytanie testu „bez pamięci” o wynikach poprzednich odpowiedzi i wyłącznie w zależności od tego, jak trudne jest kolejne pytanie i jak kompetentna jest osoba
 Szanse na poprawą odpowiedź osoby na pojedyncze pytanie testowe zależą zarazem od tego jak trudne jest to pytanie i jak kompetentna jest odpowiadająca na nie osoba. Reakcje obiektów o ustalonych parametrach (tym samym poziomie kompetencji) są stochastycznie niezależne. Pojedyncza osoba odpowiada na kolejne pytanie testu „bez pamięci o wynikach poprzednich odpowiedzi i wyłącznie w zależności od tego, jak trudne jest kolejne pytanie i jak kompetentna jest osoba.")
14
Liczba pozytywnych odpowiedzi
Dopuszczalne i niedopuszczalne profile reakcji w skalogramie Guttmana Wskaźnik Liczba pozytywnych odpowiedzi Profil X1 X2 X3 A 1 3 B 2 C D E F G H Strukturalne zero Xj trudny Suma 1 Xi łatwy I II 1-p III IV p 1-q q 1,00

15
Model Mokkena Krzywe reakcji na trzy wskaźniki w modelu Mokkena

16
Funkcja logistyczna z parametrem a

17
Funkcja reakcji w modelu Rascha 1 PL

18
Warianty modelu Rascha
1PL: x 2PL: a,x 3PL: a,c, x

19
Arkusz PP1 – statystyka opisowa

20
Suma punktów a oszacowany poziom umiejętności

22
Które z pytań arkusza jest do wymiany

23
Wprowadzenie do analizy czynnikowej

24
Single latent common factor F and two manifest indicators X1, X2
b1 X1 U1 F b2 d2 X2 U2 Model assunptions Unique variables U1 and U2 are linearly independent and independent on common latent factor F: Consequences: Common (explained) variance of an indicator Xi with common factor F equals the square of a factor loading bi: Correlation coefficient between indicators Xi and Xj is a product of their loadings with common factor F:
 variance of an indicator Xi with common factor F equals the square of a factor loading bi: Correlation coefficient between indicators Xi and Xj is a product of their loadings with common factor F:")
25
d1 0,8 X1 F d2 0,6 X2 Solution 1 Solution 2 Solution 3 Solution 4 U1
Reproduction of correlation coefficient by the factor model is not unique Factor matrix d1 F X1 0,8 X2 0,6 0,8 X1 U1 F d2 0,6 X2 U2 Solution 1 Solution 2 Solution 3 Solution 4 F X1 0,50 X2 0,96 F X1 0,60 X2 0,80 F X1 0,70 X2 0,69 F X1 0,90 X2 0,53 0,50*0,96=0,48 0,60*0,80=0,48 0,70*0,69=0,48 0,90*0,53=0,48

26
Two independent factors F1, F2, two indicators X1, X2
b11 X1 X1 U1 F1 b21 d2 X2 X2 U2 b12 b22 F2 Assumptions Unique factors U1 and U2 are linearly independent and independent on common factors F1 and F2: Common factors are linearly independent: Orthogonality of factors Consequences: Common (explained) variance of an indicator with a common factor is the sum of factor loadings squares, with both common factors F1 and F2: Correlatin coefficient between indicators equals the sum of factor loadings products
 variance of an indicator with a common factor is the sum of factor loadings squares, with both common factors F1 and F2: Correlatin coefficient between indicators equals the sum of factor loadings products.")
27
Perfect reproduction of correlations between indicators can be derived from different factor models
F1 F2 X1 ,614 -,513 X2 ,537 -,449 X3 ,845 ,076 X4 ,513 X5 ,385 ,460 F1’ X3 X1 F2’ X2 X4 X5 F2 Model 2 F1 F2 X1 ,800 ,000 X2 ,700 X3 ,600 X4 X5

28
Oblique factor models are as good as orthogonal ones
X1 X2 X3 F1 F2 X1 ,766 -,232 X2 ,670 -,203 X3 ,574 -,174 X4 ,454 ,533 X5 ,389 ,457 X6 ,324 ,381 F1 F2 X1 0,586 0,054 X2 0,449 0,041 X3 0,330 0,030 X4 0,206 0,284 X5 0,152 0,208 X6 0,105 0,145 1,827 0,763 2,590 X4 X5 X6 F2 F1 F2 X1 ,800 ,000 X2 ,700 X3 ,600 X4 X5 X6 ,500 F1 F2 X1 0,640 0,000 X2 0,490 X3 0,360 X4 X5 X6 0,250 1,490 1,100 2,590 F1 F2 X1 ,783 ,163 X2 ,685 ,143 X3 ,587 ,123 X4 X5 X6 ,102 ,489 F1 F2 X1 0,613 0,027 X2 0,470 0,020 X3 0,345 0,015 X4 X5 X6 0,010 0,240 1,474 1,116 2,590

29
Permanent Problems of FACTOR ANALYSIS as a scaling tool
How to find factor solution Permanent Problems of FACTOR ANALYSIS as a scaling tool How to evaluate its quality Which indicators are useless What variables can be used as an indicators of latent factor What to do if my indicators are binary or ordinary

30
Matrix - eigenvalue matrix decomposition
Eigenvalues of R Eigenvectors of R Eigenvalue decomposition of R =

31
Factor model in matrix notation
Common assumptions indicators (n) (1) F common factors (k < n) Unique factors are mutually independent U unique factors (n) (2) B Factor loadings matrix (n,k) Unique and common factors are independent Factor model assumptions Orthogonal factors (3) Common factors are mutually linearly independent; C(Fi, Fj) = 0 Oblique factors (3) Common factors are linearly dependent; C(Fi, Fj) ≠ 0
 (1) F. common factors (k < n) Unique factors are mutually independent. U. unique factors (n) (2) B. Factor loadings matrix (n,k) Unique and common factors are independent. Factor model assumptions. Orthogonal factors. (3) Common factors are mutually linearly independent; C(Fi, Fj) = 0. Oblique factors. (3) Common factors are linearly dependent; C(Fi, Fj) ≠ 0.")
32
Decomposition of R between Σ and Ψ is not unique
Factor equation X = Where: Ψ – diagonal matrix with di2 on main diagonal Σ – symmetric matrix with rij out-diagonal and hi2 on the diagonal Decomposition of R between Σ and Ψ is not unique

33
Finding factor model parameters
Data: empirical correlation between indicators with unknown decomposition between 𝛴 and 𝛹 Decomposition theorem Solution: factor loading matrix Correlations between indicators implied by the solution Finding factor model parameters

34
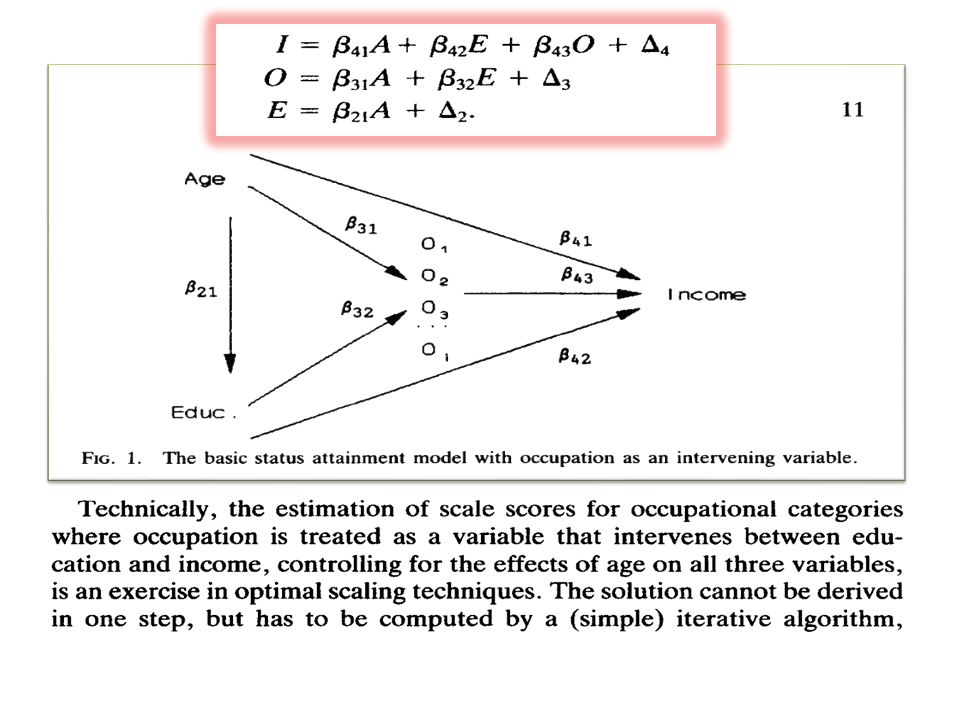
Obliczalność kowariancji między elementami modelu ścieżkowego

35
Recursive models calculus
Heise 2001

36
Z=X3 Y = X2 X = X1 Model implications Model parameters 0,64 0,29
Kim, 1973 Z=X3 Y = X2 X = X1 Model implications Pyx P21 0,64 Pyz P32 0,29 Pzx P31 Model parameters Cov(X,Y) Pxy = 0,64 Cov(Y, Z) Pzy+ PyxPzx 0,29 + (0,64*0,29) Cov(Z, X) Pzx + PyxPzy
 Pxy. = 0,64. Cov(Y, Z) Pzy+ PyxPzx. 0,29 + (0,64*0,29) Cov(Z, X) Pzx + PyxPzy.")
37
Formatywne modele skalowania
SEI Potencjał partycypacyjny Zadowolenie z okolicy miejsca zamieszkania Pozycja społeczna ACSI - MJR

40
Cecha ukryta: poziom zadowolenia Z
Idea pomiaru strukturalnego: skalowanie poziomu zadowolenia z miejsca zamieszkania Jak bardzo zadowolony(a) jest Pan(i) Wyznacz takie wartości Z, które najlepiej przewidują odpowiedź Y X1 ze swoich sąsiadów Cecha ukryta: poziom zadowolenia Z X2 z poziomu czystości Biorąc to wszystko pod uwagę, proszę powiedzieć, jak Panu(i) się żyje w Pana(i) okolicy? Y X3 z zaopatrzenia sklepów X4 z placówek kulturalnych X5 z poziomu bezpieczeństwa Wskaźniki typu „źródła” Wskaźniki typu „skutki”
 jest Pan(i) Wyznacz takie wartości Z, które najlepiej przewidują odpowiedź Y. X1. ze swoich sąsiadów. Cecha ukryta: poziom zadowolenia Z. X2. z poziomu czystości. Biorąc to wszystko pod uwagę, proszę powiedzieć, jak Panu(i) się żyje w Pana(i) okolicy Y. X3. z zaopatrzenia sklepów. X4. z placówek kulturalnych. X5. z poziomu bezpieczeństwa. Wskaźniki typu „źródła Wskaźniki typu „skutki")
41
Bariery – katalizatory partycypacji
Dlaczego nie uczestniczę? bariery bronię dóbr indywidualnych Dlaczego uczestniczę bronię dobra wspólnego katalizatory tworzę dobro wspólne

42
Potencjał partycypacyjny: schemat pomiarowy
Katalizatory potencjał Świadomość prawna Umiejętności komunikacyjne Standardy etyczne Kapitały: społeczne kulturowe ekonomiczne Zachowania partycypacyjne partycypacyjny Bariery

44
Od American Customer Satisfaction Index (ACSI) do MJR Podstawowe wyniki MJR Katarzyna Wądołowska
 do MJR Podstawowe wyniki MJR Katarzyna Wądołowska")
45
Amerykański Indeks Satysfakcji Klienta (ACSI)
Przedstawiony jesienią 1994 roku przez Claesa Fornella Pierwowzór: Szwedzki Barometr Satysfakcji Klienta z 1989 roku Wskaźnik długookresowej wydajności ekonomicznej państwa oraz sektora prywatnego Pomiar wydajności oparty na subiektywnej ewaluacji jakości dóbr i usług nabywanych w USA, dokonywanej przez konsumentów Odzwierciedla satysfakcję z dóbr i usług dostępnych na rynku krajowym Pozwala oszacować przyszłe zyski przedsiębiorstwa, promować jakość i zwiększać konkurencyjność firm ACSI obejmuje 100 instytucji federalnych dostarczających 200 usług publicznych

46
Monitor Jakości Rządzenia (MJR)
Geneza MJR Monitor Jakości Rządzenia (MJR) Adaptacja amerykańskiego schematu pomiarowego do warunków polskich Wykorzystuje doświadczenia z badań rynku i usług federalnych w USA Państwo traktowane jako dostarczyciel usług publicznych Rynek: konsument – produkt – jakość/wartość Państwo: obywatel – usługa publiczna – jakość
 Adaptacja amerykańskiego schematu pomiarowego do warunków polskich. Wykorzystuje doświadczenia z badań rynku i usług federalnych w USA. Państwo traktowane jako dostarczyciel usług publicznych. Rynek: konsument – produkt – jakość/wartość. Państwo: obywatel – usługa publiczna – jakość.")
47
Założenia modelu teoretycznego
poziom satysfakcji oczekiwania wobec danej usługi publicznej zachowania i deklaracje dotyczące przyszłości: generalizacja Konsekwencje - skargi na jakość - zaufanie - rekomendacje doświadczenie w korzystaniu z usługi

48
poziom satysfakcji z usługi
poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości oczekiwania i doświadczenia konsekwencje oczekiwań i doświadczeń odczuwana jakość usługi Od czego zależy satysfakcja? Co zależy od satysfakcji?

49
poziom satysfakcji z usługi
poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości Q1 ogólne oczekiwania Q6 ogólna satysfakcja Q11 polecanie usługi innym Q7 spełnianie oczekiwań Q8 porównanie z ideałem Q5 ogólna ocena jakości Q2 ocena jakości wymiaru 1 Q3 ocena jakości wymiaru 2 Q4 ocena jakości wymiaru 3 Q9 czy złożył skargę Q10A/B reakcja na skargę Q12 wiara w stabilność poziomu jakości odczuwana jakość usługi

50
Usługi objęte badaniem
Komunikacja publiczna Urząd Gminy Urząd Skarbowy ZUS / KRUS Urząd Pocztowy Policja Biblioteka Publiczna Dom lub Ośrodek Kultury Usługi medyczne (5 rodzajów usług) Szkoła podstawowa / gimnazjum w podziale na prywatną i publiczną służbę zdrowia
 Szkoła podstawowa / gimnazjum. w podziale na prywatną i publiczną służbę zdrowia.")
51
Wymiary jakości usług (1)
Wymiary jakości badanych usług publicznych Częstotliwość kursowania środków transportu Punktualność kursowania środków transportu Wygląd i czystość środków transportu Komunikacja publiczna Sprawność załatwienia sprawy Łatwość uzyskania informacji na temat sposobu załatwienia sprawy, opłat, potrzebnych dokumentów Kompetencje urzędników załatwiających sprawę Urząd Gminy Urząd Skarbowy ZUS / KRUS Szybkość dostarczania przesyłek Dogodność terminów dostarczania przesyłek poleconych Szybkość załatwiania spraw i kolejek Urząd Pocztowy

52
Wymiary jakości usług (2)
Wymiary jakości badanych usług publicznych Szybkość reakcji Skuteczność interwencji Sposób potraktowania przez policjantów Policja Pomocność pracowników biblioteki Dostępność informacji o zbiorach bibliotecznych Dostępność książek i materiałów multimedialnych Biblioteka Publiczna Oferta organizowanych zajęć i imprez Jakość organizowanych zajęć i imprez Poziom wyposażenia, jakość pomieszczeń, jakość sprzętu technicznego Dom lub Ośrodek Kultury

53
Wymiary jakości usług (3)
Wymiary jakości badanych usług publicznych Możliwość umówienia się na wizytę w odpowiadającym terminie Posiadane kompetencje lekarza, personelu Życzliwość wobec pacjenta Usługi medyczne (5 rodzajów usług) Poziom bezpieczeństwa dziecka w szkole Poziom nauczania w szkole Relacje rodzica z wychowawcą Szkoła podstawowa / gimnazjum
 Poziom bezpieczeństwa dziecka w szkole. Poziom nauczania w szkole. Relacje rodzica z wychowawcą. Szkoła podstawowa / gimnazjum.")
54
Przykładowe pytanie z kwestionariusza
dla Urzędu Skarbowego

55
Struktura MJR . . . . I1 I10-100 MJR1 I2 I20-100 MJR2 MJR(o) Ik
modele SEM-PLS satysfakcja obywateli unormowana satysfakcja obywateli (skala 0-100) indeks MJR dla usługi wagi proporcjonalne do liczby osób, które korzystały z usługi w ciągu ostatniego roku poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości odczuwana jakość usługi średnia I1 I10-100 MJR1 usługa 1. u1 poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości odczuwana jakość usługi średnia u2 I2 I20-100 MJR2 usługa 2. MJR(o) . . . . uk względem usługi poziom wymagań wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości odczuwana jakość usługi średnia usługa k. Ik Ik0-100 MJRk
 indeks MJR dla usługi. wagi proporcjonalne do liczby osób, które korzystały z usługi w ciągu ostatniego roku. poziom wymagań. względem usługi. wskaźniki jakości. poziom satysfakcji z usługi. skargi na jakość usługi i sposób ich załatwiania. zaufanie do jakości usługi w przyszłości. odczuwana jakość usługi. średnia. I1. I MJR1. usługa 1. u1. poziom wymagań. względem usługi. wskaźniki jakości. poziom satysfakcji z usługi. skargi na jakość usługi i sposób ich załatwiania. zaufanie do jakości usługi w przyszłości. odczuwana jakość usługi. średnia. u2. I2. I MJR2. usługa 2. MJR(o) uk. względem usługi. poziom wymagań. wskaźniki jakości. poziom satysfakcji z usługi. skargi na jakość usługi i sposób ich załatwiania. zaufanie do jakości usługi w przyszłości. odczuwana jakość usługi. średnia. usługa k. Ik. Ik MJRk.")
56
Sposób wyznaczania indeksu satysfakcji (1)
Satysfakcja z usługi pojedynczego obywatela Ik(x) poziom satysfakcji z usługi k dla respondenta x wki współczynniki dla wskaźników Qi uzyskane w wyniku estymacji modelu strukturalnego dla usługi k Qki(x) odpowiedź respondenta x na pytanie wskaźnikowe Qi dotyczące usługi k Pytania wskaźnikowe opierają się na skali od 1 do 9
 poziom satysfakcji z usługi k dla respondenta x. wki współczynniki dla wskaźników Qi uzyskane w wyniku estymacji modelu strukturalnego dla usługi k. Qki(x) odpowiedź respondenta x na pytanie wskaźnikowe Qi dotyczące usługi k. Pytania wskaźnikowe opierają się na skali od 1 do 9.")
57
Sposób wyznaczania indeksu satysfakcji (2)
Satysfakcja z usługi pojedynczego obywatela na skali 0-100 Ik0-100(x) poziom satysfakcji z usługi k dla respondenta x na skali 0-100 wki współczynniki dla wskaźników Qi uzyskane w wyniku estymacji modelu strukturalnego dla usługi k Qki(x) odpowiedź respondenta x na pytanie wskaźnikowe Qi dotyczące usługi k Zmienna Ik jest wyrażona na skali od 0 do 100
 poziom satysfakcji z usługi k dla respondenta x na skali wki współczynniki dla wskaźników Qi uzyskane w wyniku estymacji modelu strukturalnego dla usługi k. Qki(x) odpowiedź respondenta x na pytanie wskaźnikowe Qi dotyczące usługi k. Zmienna Ik0-100 jest wyrażona na skali od 0 do 100.")
58
Sposób wyznaczania indeksu satysfakcji (3)
Ogólna forma indeksu satysfakcji (MJR) Indeks satysfakcji obywateli wyliczany jest jako średnia satysfakcja (wyrażona na skali 0-100) zbadanych osób z danej usługi Taka średnia może zostać policzona zarówno dla całej Polski, jak i np. dla poszczególnych województw (bierzemy wtedy pod uwagę tylko mieszkańców danego województwa) MJR jest wyrażony na skali od 0 do 100
 Indeks satysfakcji obywateli wyliczany jest jako średnia satysfakcja (wyrażona na skali 0-100) zbadanych osób z danej usługi. Taka średnia może zostać policzona zarówno dla całej Polski, jak i np. dla poszczególnych województw (bierzemy wtedy pod uwagę tylko mieszkańców danego województwa) MJR jest wyrażony na skali od 0 do 100.")
59
Sposób wyznaczania indeksu satysfakcji (4)
Indeks jakości rządzenia na danym obszarze MJRk(o) indeks satysfakcji z usługi k na obszarze o (w województwie lub w całej Polsce) uk waga proporcjonalna do częstości korzystania obywateli z usługi k (wagi unormowano tak, aby MJR(o) było wyrażane na skali 0-100) MJR jest wyrażony na skali od 0 do 100
 indeks satysfakcji z usługi k na obszarze o (w województwie lub w całej Polsce) uk waga proporcjonalna do częstości korzystania obywateli z usługi k (wagi unormowano tak, aby MJR(o) było wyrażane na skali 0-100) MJR jest wyrażony na skali od 0 do 100.")
60
Zalety podejścia Zalety MJR Zalety metodologiczne
Sprawdzona metodologia Standaryzowany sposób oceny satysfakcji Możliwość agregacji i porównań uzyskanych ocen Możliwość śledzenia zmian w uzyskanych ocenach w czasie Zalety praktyczne Zobiektywizowana ocena jakości działania służb publicznych Opis jakości usług na poziomie ogólnokrajowym i lokalnym Pozyskanie informacji na temat oczekiwań obywateli wobec instytucji publicznych Możliwość wdrożenia okresowej kontroli jakości działania służb publicznych

61
Prywatna służba zdrowia 81 pkt
Polska 70 pkt Jakość usług publicznych w Polsce

62
Województwo lubelskie 74 pkt Prywatna służba zdrowia 85 pkt Jakość usług publicznych w woj. lubelskim

63
Województwo śląskie 67 pkt Prywatna służba zdrowia 82 pkt Jakość usług publicznych w woj. śląskim

64
Indeksy satysfakcji z usług publicznych w przekroju terytorialnym

65
Biłgoraj na tle pozostałych gmin wiejskich

66
Gołdap na tle pozostałych miast do 20 tys. mieszkańców

67
Słupsk na tle pozostałych miast od 20 tys. do 100 tys. mieszkańców

68
Poznań na tle pozostałych miast pow. 100 tys. mieszkańców

69
Polska: 70 pkt Porównanie wyników ACSI versus MJR (1)
")
70
Publiczna służba zdrowia Prywatna służba zdrowia
USA 2010 Polska 2010 Koszyk 10 usług 70 Publiczna służba zdrowia 75 Prywatna służba zdrowia 81 Poczta 64 Porównanie wyników ACSI versus MJR (2)
")
71
PLS rekonstrukcja metody Tomasz Żółtak

72
Statystyczna geneza PLS
Podstawy podejścia opracowane na przełomie lat 60. i 70. XX w. przez Hermana Wolda. Uczniem Wolda był Jöreskog, twórca modeli SEM-ML. W odróżnieniu od modeli SEM-ML metoda PLS z założenia miała być mało wymagająca względem danych: Nie odwoływać się do założeń o rozkładach zmiennych. Umożliwiać estymację nawet przy małej liczbie jednostek obserwacji. W latach 80. w pracach Wolda i Lohmöllera przedstawiono dowody, że przy pomocy pewnych wariantów modeli PLS można estymować: Korelacje kanoniczne (w tym dwa uogólnienia korelacji kanonicznej na wiele grup zmiennych zaproponowane przez Horsta i Carolla). Regresję PLS. Inter-battery factor analysis. Redundancy analysis. I wymienione w ostatniej kropie są jedynymi sytuacjami, w których udowodniono, że algorytm zawsze zbiega (odpowiada to, po pierwsze wszystkim możliwym rodzajom modeli dla dwóch bloków zmiennych i modelowi hierarchicznemu z wieloma blokami-czynnikami i jednym czynnikiem wyższego rzędu – p. Tenenhaus i. in. s. 196).
. Regresję PLS. Inter-battery factor analysis. Redundancy analysis. I wymienione w ostatniej kropie są jedynymi sytuacjami, w których udowodniono, że algorytm zawsze zbiega (odpowiada to, po pierwsze wszystkim możliwym rodzajom modeli dla dwóch bloków zmiennych i modelowi hierarchicznemu z wieloma blokami-czynnikami i jednym czynnikiem wyższego rzędu – p. Tenenhaus i. in. s. 196).")
73
Własności estymacji metodą PLS
W odróżnieniu od modeli SEM-ML algorytm estymacji PLS w ogólności nie dąży do maksymalizacji żadnej globalnej funkcji dopasowania modelu do danych. Choć dla szczególnych modeli (por. poprzedni slajd) można wskazać, że efektem działania algorytmu jest optymalizacja pewnego kryterium. Estymacja modelu strukturalnego metodą PLS w ogólności daje się opisać tylko jako realizacja rozsądnego algorytmu działania. Nie można jednak (w ogólności) syntetycznie powiedzieć, do czego ten algorytm dąży. Modele PLS są nakierowane na przewidywanie i eksplorację (możliwość uwzględnienia bardzo wielu zmiennych bez napotykania problemów z identyfikowalnością modelu czy niestabilnością wyników), a nie (jak SEM-ML) na testowanie hipotez. Kasia w swojej prezentacji ma już coś o zaletach, więc ja wspominam jeśli nie o wadach, to o wątpliwościach ;) Niemniej zawsze możesz tu dopowiedzieć, że za to możemy bez obaw wrzucać tu praktycznie wszystko i mamy bardzo małe wymagania względem liczby obserwacji (gdyby ktoś pytał dlaczego – zaraz będzie). Mówienie o tym, że modele PLS są dobre do przewidywania opiera się na następującej argumentacji: do modeli PLS można bezkarnie wrzucić całą masę zmiennych (no bo co robisz jak chcesz dobrze przewidzieć, wrzucasz w model wszystko, co może mieć jakikolwiek związek ;) ) i one to cały czas pociągną, podczas gdy SEM-ML się tą liczbą zmiennych zapcha i na Ciebie wypnie.
 można wskazać, że efektem działania algorytmu jest optymalizacja pewnego kryterium. Estymacja modelu strukturalnego metodą PLS w ogólności daje się opisać tylko jako realizacja rozsądnego algorytmu działania. Nie można jednak (w ogólności) syntetycznie powiedzieć, do czego ten algorytm dąży. Modele PLS są nakierowane na przewidywanie i eksplorację (możliwość uwzględnienia bardzo wielu zmiennych bez napotykania problemów z identyfikowalnością modelu czy niestabilnością wyników), a nie (jak SEM-ML) na testowanie hipotez. Kasia w swojej prezentacji ma już coś o zaletach, więc ja wspominam jeśli nie o wadach, to o wątpliwościach ;) Niemniej zawsze możesz tu dopowiedzieć, że za to możemy bez obaw wrzucać tu praktycznie wszystko i mamy bardzo małe wymagania względem liczby obserwacji (gdyby ktoś pytał dlaczego – zaraz będzie). Mówienie o tym, że modele PLS są dobre do przewidywania opiera się na następującej argumentacji: do modeli PLS można bezkarnie wrzucić całą masę zmiennych (no bo co robisz jak chcesz dobrze przewidzieć, wrzucasz w model wszystko, co może mieć jakikolwiek związek ;) ) i one to cały czas pociągną, podczas gdy SEM-ML się tą liczbą zmiennych zapcha i na Ciebie wypnie.")
74
Estymacja PLS W modelu wydziela się część pomiarową (zewnętrzną) i część strukturalną (wewnętrzną). Ogólna idea estymacji sprowadza się do naprzemiennego wyliczania współczynników zewnętrznej i wewnętrznej części modelu w oparciu o wartości zmiennych ukrytych obliczone na podstawie współczynników z poprzedniego kroku estymacji. ξ1 X11 X51 ξ5 Tu nie ma strzałeczek, bo kierunek strzałeczek zależy od wariantu. Warianty na kolejnych slajdach. X31 X52 ξ4 ξ3 X21 X61 ξ6 ξ2 X22 X62 X23 X41 X42 X43

75
Warianty dla części pomiarowej
Warianty można wybrać niezależnie od siebie dla każdego bloku zmiennych. Blok typu reflective: Xij= ωij0+ ωijξj+εij E(εij)=0, cor(εij, ξj)=0 Dla każdej zmiennej w bloku estymowane jest oddzielne równanie regresji liniowej. Blok powinien być jednowymiarowy (teoria plus sprawdzian empiryczny, np. PCA, alfa Cronbacha). X21 ξ2 X22 X23 Blok typu formative: ξj=∑ω ijXij+δj E(δj)=0, i cor(δj, Xij)=0 Dla całego bloku estymuje się jedno równanie regresji liniowej. Z analizy należy usunąć zmienne, dla których okazałoby się, że sign(ω ij)≠sign(cor(Xij, ξj)) Można się oczywiście posłużyć analogią: reflective to coś na kształt analizy czynnikowej, formative coś na kształt metody głównych składowych. Gdy w bloku jest tylko jedna zmienna, to oczywiście uznaje się ją za tożsamą ze zmienną ukrytą, składniki błędów wylatują i w praktyce nie ma żadnej różnicy między jednym wariantem a drugim. Pewnie warto będzie wspomnieć, że w MJRze wykorzystujemy wariant reflective. X21 ξ2 X22 X23
=0, cor(εij, ξj)=0. Dla każdej zmiennej w bloku estymowane jest oddzielne równanie regresji liniowej. Blok powinien być jednowymiarowy (teoria plus sprawdzian empiryczny, np. PCA, alfa Cronbacha). X21. ξ2. X22. X23. Blok typu formative: ξj=∑ω ijXij+δj E(δj)=0, i cor(δj, Xij)=0. Dla całego bloku estymuje się jedno równanie regresji liniowej. Z analizy należy usunąć zmienne, dla których okazałoby się, że sign(ω ij)≠sign(cor(Xij, ξj)) Można się oczywiście posłużyć analogią: reflective to coś na kształt analizy czynnikowej, formative coś na kształt metody głównych składowych. Gdy w bloku jest tylko jedna zmienna, to oczywiście uznaje się ją za tożsamą ze zmienną ukrytą, składniki błędów wylatują i w praktyce nie ma żadnej różnicy między jednym wariantem a drugim. Pewnie warto będzie wspomnieć, że w MJRze wykorzystujemy wariant reflective. X21. ξ2. X22. X23.")
76
Warianty dla części strukturalnej
ξj=ej0+∑eijξi+νj gdzie ξi są bezpośrednio połączone z ξj (również gdy ξi następują po ξi ) Centroid scheme: eij=sign(cor(ξi, ξj)) Factorial scheme: eij=cor(ξi, ξj) Path weghting scheme: eij=βξj|ξi; ξi’ dla ξi poprzedzających ξj w porządku czasowym eij=cor(ξi, ξj) dla ξi następujących po ξj w porządku czasowym A tu wspomnieć, że w MJRze korzystamy z Path weigting scheme. Beta w path weigthing scheme to standaryzowany współczynnik przy danej zmiennej w regresji ξj ze względu na wszystkie poprzedzające go ξi ξ1 ξ5 ξ4 ξ3 ξ2 ξ6
 Centroid scheme: eij=sign(cor(ξi, ξj)) Factorial scheme: eij=cor(ξi, ξj) Path weghting scheme: eij=βξj|ξi; ξi’ dla ξi poprzedzających ξj w porządku czasowym. eij=cor(ξi, ξj) dla ξi następujących po ξj w porządku czasowym. A tu wspomnieć, że w MJRze korzystamy z Path weigting scheme. Beta w path weigthing scheme to standaryzowany współczynnik przy danej zmiennej w regresji ξj ze względu na wszystkie poprzedzające go ξi. ξ1. ξ5. ξ4. ξ3. ξ2. ξ6.")
77
Algorytm estymacji PLS
Załóż początkowe wartości współczynników dla pomiarowej części modelu (ωij). Współcześnie używa się zwykle wag z 1. składowej głównej. Oblicz zewnętrzne estymatory zmiennych ukrytych jako: ξj ∑ωij [Xij –E(Xij)] gdzie oznacza standaryzację wyrażenia po prawej. Na podstawie tak wyliczonych estymatorów oblicz wartości współczynników strukturalnej części modelu (eij). Oblicz wewnętrzne estymatory zmiennych ukrytych jako: ξj ∑ei ξi Na podstawie tak wyliczonych estymatorów oblicz nowe wartości współczynników zewnętrznej części modelu (ωij). Powtarzaj kroki do uzyskania zbieżności. Obliczenia w punktach 3. i 5. przebiegają oczywiście zgodnie z tym, co było pokazane na dwóch poprzednich slajdach.
. Współcześnie używa się zwykle wag z 1. składowej głównej. Oblicz zewnętrzne estymatory zmiennych ukrytych jako: ξj ∑ωij [Xij –E(Xij)] gdzie oznacza standaryzację wyrażenia po prawej. Na podstawie tak wyliczonych estymatorów oblicz wartości współczynników strukturalnej części modelu (eij). Oblicz wewnętrzne estymatory zmiennych ukrytych jako: ξj ∑ei ξi. Na podstawie tak wyliczonych estymatorów oblicz nowe wartości współczynników zewnętrznej części modelu (ωij). Powtarzaj kroki do uzyskania zbieżności. Obliczenia w punktach 3. i 5. przebiegają oczywiście zgodnie z tym, co było pokazane na dwóch poprzednich slajdach.")
78
Algorytm estymacji PLS
Po uzyskaniu zbieżności wykonuje się dwa ostatnie kroki: Wyliczenie ostatecznych wartości estymatorów zmiennych ukrytych: ξj=∑ωij [Xij –E(Xij)] / σ gdzie σ=D(∑ωij [Xij –E(Xij)] ) Tak uzyskane estymatory zwykle unormowuje się jeszcze na jeden z dwóch sposobów: 1) ξj‘= ξj+∑ωijE(Xij) / σ („odcentrowanie” zmiennej) 2) ξj‘’= [ξj‘+∑ωijE(Xij) ] / ∑ωij równoważnie: ξj‘’= ∑ωijXij / ∑ωij (przedstawieniu zmiennej ukrytej na tej samej skali, co zmienne mierzalne danego bloku) Wyliczenie współczynników opisujących zależności przyczynowe w części strukturalnej modelu, przy użyciu analizy ścieżkowej. Sposób 2) jest oczywiście ACSI’owy. Można dodać, że żeby dało się to tak policzyć, muszą być spełnione dwa założenia: 1. wszystkie zmienne mierzalne danego bloku są mierzone na jednej skali, 2. wszystkie wagi zewnętrzne w danym bloku są nieujemne. Sposób 1) to właśnie „odcentrowanie”, tak aby zmienna ukryta miała średnią równą średniej ważonej (wagami) zmiennych mierzalnych z bloku.
] / σ gdzie σ=D(∑ωij [Xij –E(Xij)] ) Tak uzyskane estymatory zwykle unormowuje się jeszcze na jeden z dwóch sposobów: 1) ξj‘= ξj+∑ωijE(Xij) / σ („odcentrowanie zmiennej) 2) ξj‘’= [ξj‘+∑ωijE(Xij) ] / ∑ωij. równoważnie: ξj‘’= ∑ωijXij / ∑ωij. (przedstawieniu zmiennej ukrytej na tej samej skali, co zmienne mierzalne danego bloku) Wyliczenie współczynników opisujących zależności przyczynowe w części strukturalnej modelu, przy użyciu analizy ścieżkowej. Sposób 2) jest oczywiście ACSI’owy. Można dodać, że żeby dało się to tak policzyć, muszą być spełnione dwa założenia: 1. wszystkie zmienne mierzalne danego bloku są mierzone na jednej skali, 2. wszystkie wagi zewnętrzne w danym bloku są nieujemne. Sposób 1) to właśnie „odcentrowanie , tak aby zmienna ukryta miała średnią równą średniej ważonej (wagami) zmiennych mierzalnych z bloku.")
79
Własności Estymacja metodą PLS sprowadza się do liczenia dużej liczby regresji liniowych, przy czym w każdym kroku procedury iteracyjnej każde z równań opisujących model jest wyliczane oddzielnie. Stąd niewielkie zapotrzebowanie na liczbę jednostek obserwacji – decyduje tutaj największa liczba zmiennych niezależnych występujących w pojedynczym równaniu (np. w modelu MJR cztery zmienne). Mniejsze są też problemy w przypadku braków danych – dany brak występuje bowiem tylko lokalnie, w jednym równaniu. W związku z tym nie występują też (dosyć często występujące w SEM-ML) problemy z nieidentyfikowalnością modelu. Błędy standardowe współczynników modelu można uzyskać z regresji obliczanych w ostatnim kroku estymacji, jednak obecnie często oblicza się je przy pomocy metod symulacyjnych (jakcknife, bootstrap). Duże zapotrzebowanie na obserwacje modeli SEM-ML wynika z tego, że wszystkie równania opisujące model są w nich estymowane jednocześnie.
. Mniejsze są też problemy w przypadku braków danych – dany brak występuje bowiem tylko lokalnie, w jednym równaniu. W związku z tym nie występują też (dosyć często występujące w SEM-ML) problemy z nieidentyfikowalnością modelu. Błędy standardowe współczynników modelu można uzyskać z regresji obliczanych w ostatnim kroku estymacji, jednak obecnie często oblicza się je przy pomocy metod symulacyjnych (jakcknife, bootstrap). Duże zapotrzebowanie na obserwacje modeli SEM-ML wynika z tego, że wszystkie równania opisujące model są w nich estymowane jednocześnie.")
80
Indeks zmienności wspólnej (communality index):
Miary dopasowania Model PLS nie optymalizuje żadnego globalnego kryterium dopasowania do danych. Zaproponowano jednak kilka miar pozwalających ocenić wyniki estymacji: Indeks zmienności wspólnej (communality index): Miara wyliczana dla każdego bloku oddzielnie: communalityj=E[cor2(Xij, ξj)] Jako miary globalnej można użyć średnią ze wszystkich bloków. Redundancy index: redundancyj=communalityj R2ξj|ξ{i} gdzie ξi wyjaśniają ξj GoF (Goodness-of-fit): GoF=[ E(communality) E(R2ξj|ξ{i}) ]0,5 GoF to w gruncie rzeczy średnia geometryczna średniej wartości indeksu zmienności wspólnej i średniego R-kwadrat.
: Miara wyliczana dla każdego bloku oddzielnie: communalityj=E[cor2(Xij, ξj)] Jako miary globalnej można użyć średnią ze wszystkich bloków. Redundancy index: redundancyj=communalityj R2ξj|ξ{i} gdzie ξi wyjaśniają ξj. GoF (Goodness-of-fit): GoF=[ E(communality) E(R2ξj|ξ{i}) ]0,5. GoF to w gruncie rzeczy średnia geometryczna średniej wartości indeksu zmienności wspólnej i średniego R-kwadrat.")
81
SEM: MLE vs PLS Wyznaczanie pametrów modelu MJR: SEM - PLS cecha
cel estymacja parametrów modelu przyczynowego test hipotez na temat modelu przewidywanie wartości zmiennych ukrytych identyfikacja modelu zależy od modelu zawsze zidentyfikowany zależności między zmiennymi nie dopuszcza współliniowości dopuszcza współliniowość zarówno w części pomiarowej jak i strukturalnej modelu konieczna liczba jednostek obserwacji duża: 15-20 razy liczba zmiennych w modelu niewielka: max(15-20 razy liczba zmiennych niezależnych w pojedynczym równaniu modelu) metoda estymacji ML iteracyjna OLS założenia o rozkładach parametryczne: wielowymiarowy rozkład normalny nieparametryczne: dopuszcza brak normalności SEM: MLE vs PLS
 metoda estymacji. ML. iteracyjna OLS. założenia o rozkładach. parametryczne: wielowymiarowy rozkład normalny. nieparametryczne: dopuszcza brak normalności. SEM: MLE vs PLS.")
82
Model Realizacja sondażu Otoczenie modelu
Co dalej z MJR ? Model Weryfikacja trafności modelu reakcji klienta (relacje między konstruktami) Weryfikacja trafności wskaźników Problemy statystyczne: nieliniowość relacji konstrukt-wskaźnik, respondent-bias, Realizacja sondażu Definicja populacji użytkownków usługi i kontrola reprezentatywności ich prób Tanie technologie dotarcia do klientów usług Otoczenie modelu Wyczerpujące badanie triady lokalnej (O – W – N) Statystyka publiczna – efektywność usługi na obszarze
 Weryfikacja trafności wskaźników. Problemy statystyczne: nieliniowość relacji konstrukt-wskaźnik, respondent-bias, Realizacja sondażu. Definicja populacji użytkownków usługi i kontrola reprezentatywności ich prób. Tanie technologie dotarcia do klientów usług. Otoczenie modelu. Wyczerpujące badanie triady lokalnej (O – W – N) Statystyka publiczna – efektywność usługi na obszarze.")
Podobne prezentacje



, gdzie X jest liczbą osób w rodzinie, a Y liczbą izb w mieszkaniu. Niech f.r.p. tej zmiennej.>")


















