Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Tabelaryczne i graficzne metody opisu danych Patrycja Jędrzejewska

2
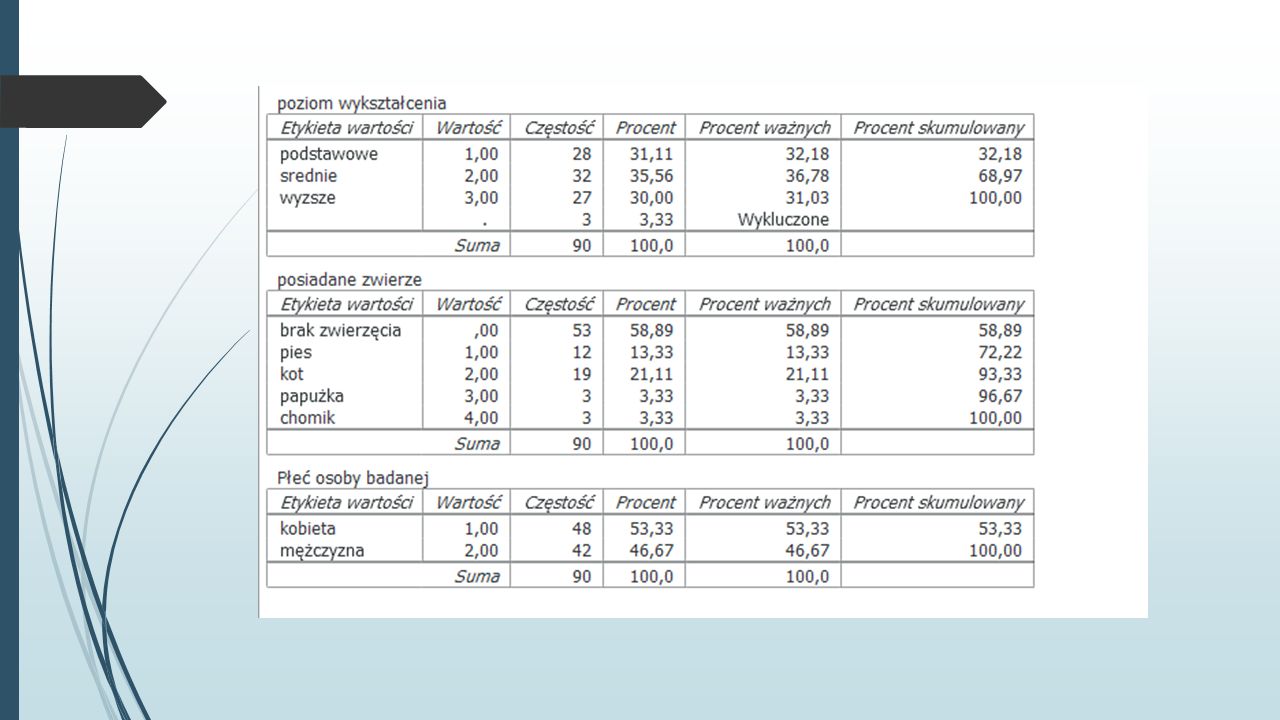
TABELA CZĘSTOŚCI – pozwala w szybki i nieskomplikowany sposób uzyskać wiele wartościowych informacji plik1.sav Interesuje nas sprawdzenie trzech kwestii: wykształcenia badanych (wykształcenie), informacji o posiadanym przez nich zwierzęciu (zwierzę) oraz liczby kobiet i mężczyzn w badanej próbie (płeć) Analizy te chcemy wykonać dla całej próby, bez podziału na grupy wiekowe Program PSPP pozwala nam wykonać jednocześnie kilka tabel częstości, tak więc możemy od razu obejrzeć tabele dla trzech zmiennych Analiza->Opis statystyczny->Częstości…
, informacji o posiadanym przez nich zwierzęciu (zwierzę) oraz liczby kobiet i mężczyzn w badanej próbie (płeć) Analizy te chcemy wykonać dla całej próby, bez podziału na grupy wiekowe Program PSPP pozwala nam wykonać jednocześnie kilka tabel częstości, tak więc możemy od razu obejrzeć tabele dla trzech zmiennych Analiza->Opis statystyczny->Częstości…")
4
Braki danych wystąpiły w przypadku zmiennej wykształcenie (badani mogli nam nie podać swojego poziomu wykształcenia lub też dane te zostały w jakiś sposób utracone) W kolejnych tabelach mamy szczegółowe informacje o: poziomie wykształcenia osób badanych, posiadanym przez nich zwierzęciu oraz liczbie kobiet i mężczyzn w naszej próbie
 W kolejnych tabelach mamy szczegółowe informacje o: poziomie wykształcenia osób badanych, posiadanym przez nich zwierzęciu oraz liczbie kobiet i mężczyzn w naszej próbie")
5
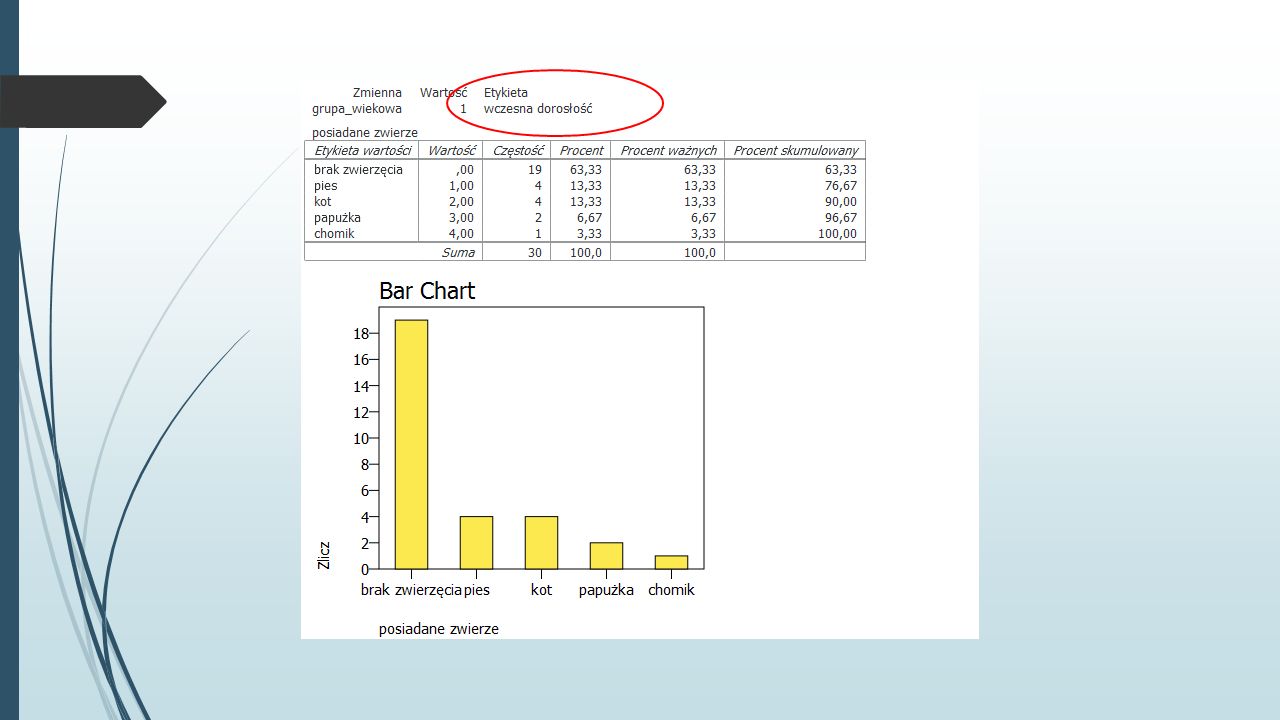
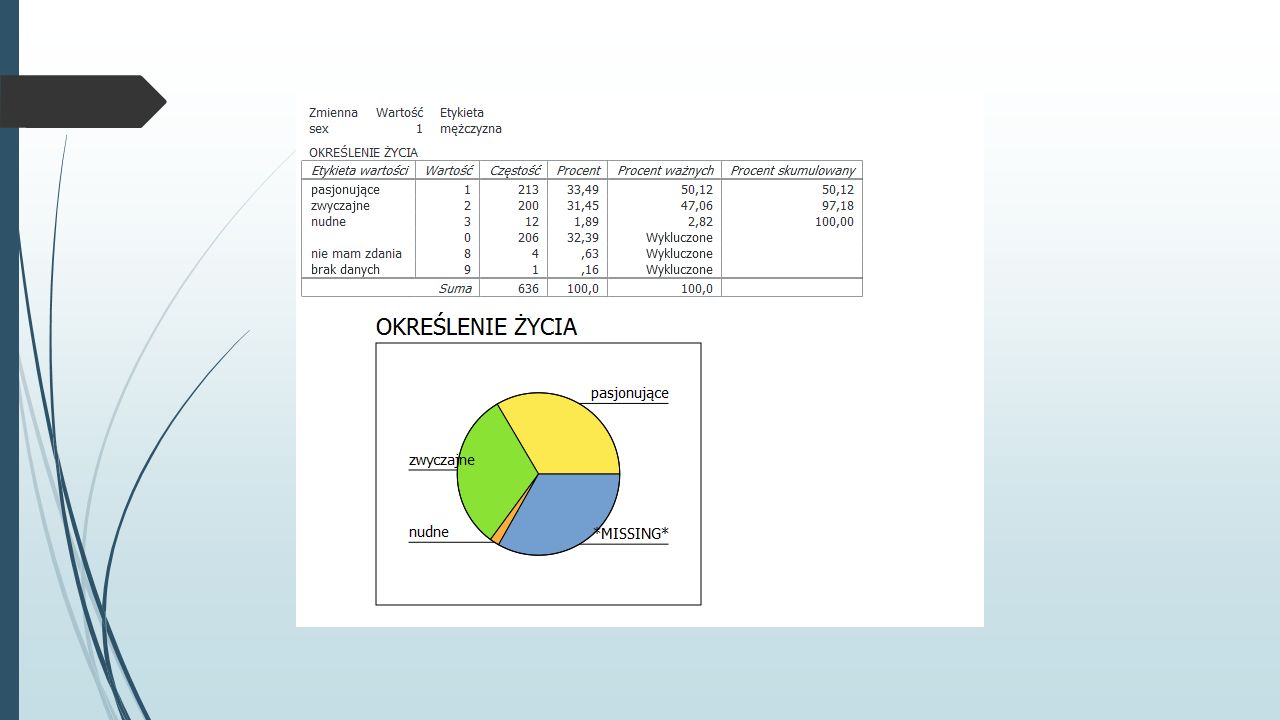
Przyglądając się bliżej tabeli dot. zmiennej wykształcenie, widzimy, że w kolumnie CZĘSTOŚCI mamy informację o liczbie osób z określonym rodzajem wykształcenia (np. jest 27 osób z wykształceniem wyższym), widzimy też, że w pliku są 3 braki danych Kolumna PROCENT pokazuje nam, jaką część całej grupy (razem z brakami danych) stanowią badani z poszczególnych kategorii Np. 27 osób z wyższym wykształceniem stanowi 30% z całej próby, a 3,33% grupy stanowią braki danych Kolejna kolumna, PROCENT WAŻNYCH, pokazuje nam również procentowy udział w próbie, z tą ważną różnicą, że pod uwagę nie są brane braki danych - > a zatem w tym przypadku 100% to nie 90, a 87 osób, dlatego też 27 osób z wyższym wykształceniem stanowi teraz 31% W ostatniej kolumnie PROCENT SKUMULOWANY widzimy zsumowane po kolei procentowe udziały poszczególnych kategorii (tu również braki danych są ignorowane), np. 69% badanych ma wykształcenie średnie lub podstawowe
, widzimy też, że w pliku są 3 braki danych Kolumna PROCENT pokazuje nam, jaką część całej grupy (razem z brakami danych) stanowią badani z poszczególnych kategorii Np. 27 osób z wyższym wykształceniem stanowi 30% z całej próby, a 3,33% grupy stanowią braki danych Kolejna kolumna, PROCENT WAŻNYCH, pokazuje nam również procentowy udział w próbie, z tą ważną różnicą, że pod uwagę nie są brane braki danych - > a zatem w tym przypadku 100% to nie 90, a 87 osób, dlatego też 27 osób z wyższym wykształceniem stanowi teraz 31% W ostatniej kolumnie PROCENT SKUMULOWANY widzimy zsumowane po kolei procentowe udziały poszczególnych kategorii (tu również braki danych są ignorowane), np. 69% badanych ma wykształcenie średnie lub podstawowe.")
6
Funkcja PODZIEL NA PODZBIORY Wiemy, ile w całej grupie jest mężczyzn i kobiet. Ale co z naszymi kategoriami wiekowymi? Chcieliśmy, żeby było tam po 15 kobiet i 15 mężczyzn. Żeby sprawdzić, czy rzeczywiście tak jest… Dane->Podziel dane na podzbiory…

8
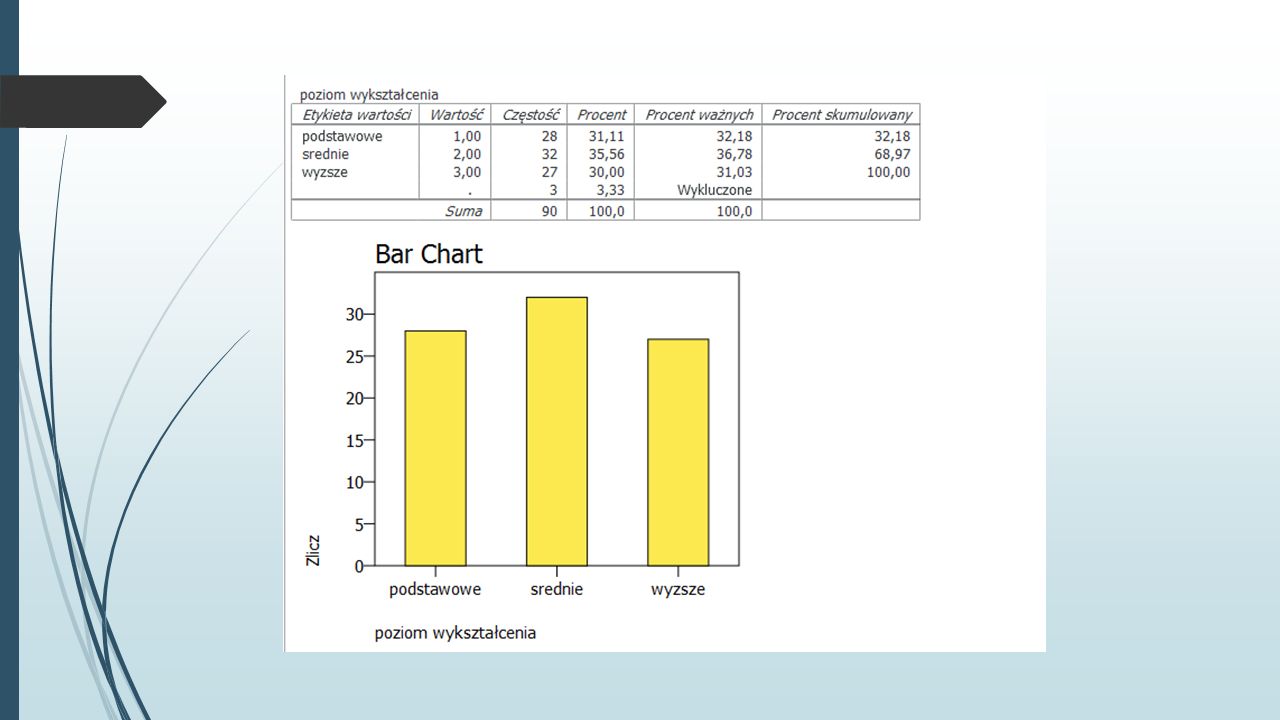
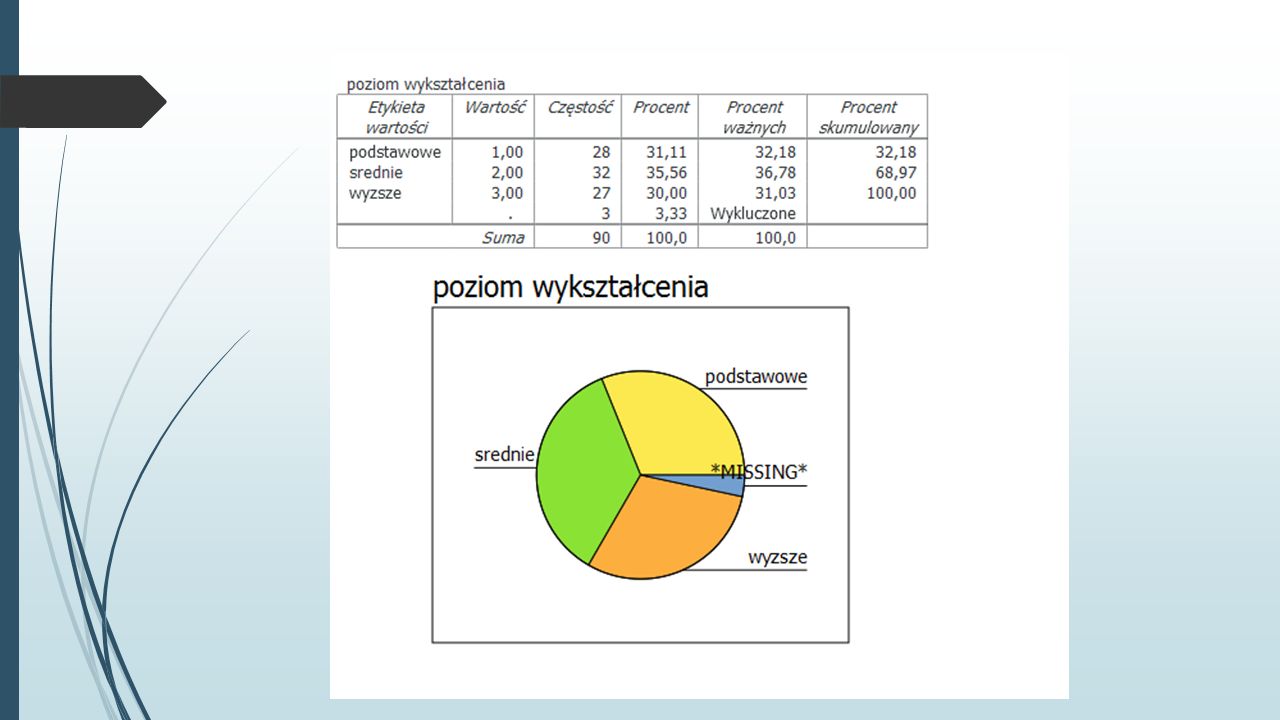
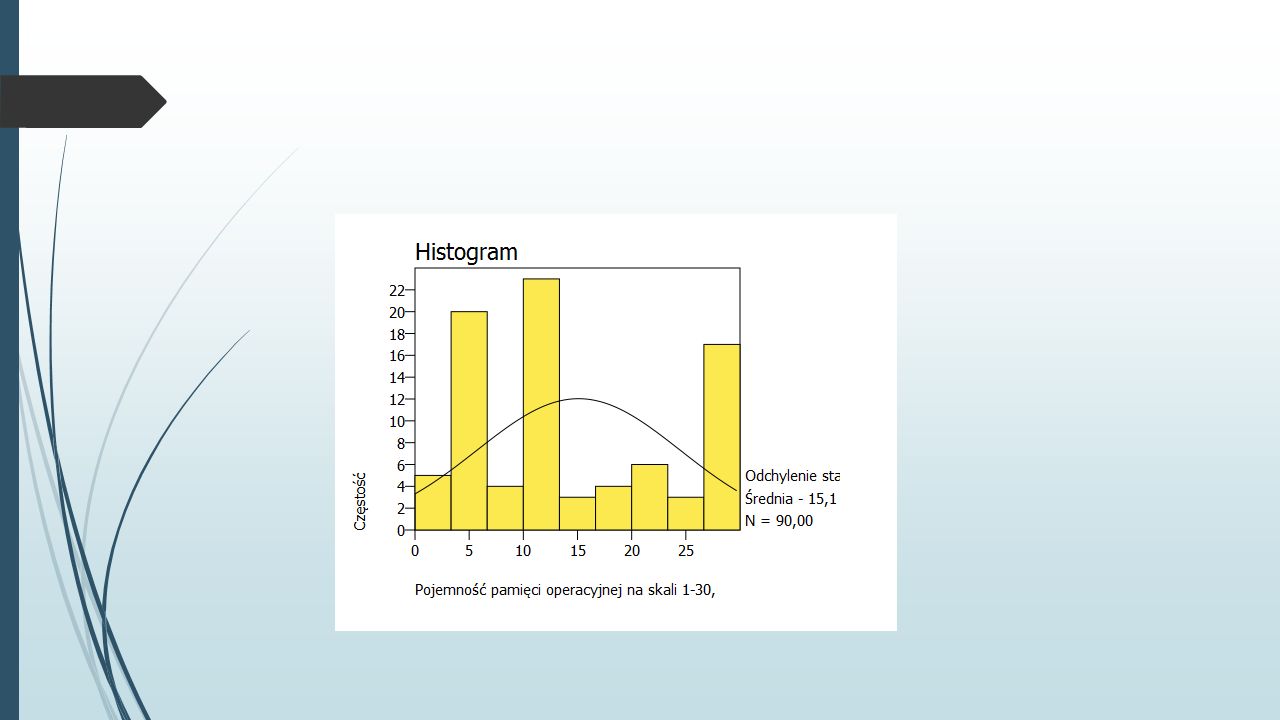
Wykresy Celem wykresu jest klarowna i jak najprostsza prezentacja danych. Tutaj skupimy się na trzech prostych i użytecznych rodzajach wykresów: wykres słupkowy, wykres kołowy, histogram

9
Wykres słupkowy Analiza->Opis statystyczny->Częstości Wybieramy zmienną wykształcenie Wykresy->Draw bar charts

11
Wykres kołowy Analiza->Opis statystyczny->Częstości Wybieramy zmienną wykształcenie Wykresy->Rysuj wykresy kołowe

13
Histogram Graphs-> Histogram Wybieramy zmienną operacyjna

15
Prezentowane wyżej wykresy były wykonywane dla całej próby Wykorzystajmy funkcję PODZIEL NA PODZBIORY Może być ona przydatna przy opracowywaniu wykresów (np. kiedy chcemy zobaczyć osobno dla trzech kategorii wiekowych, jakie zwierzęta posiadają badani- wtedy zmienna grupa_wiekowa ląduje w podziale na zbiory) Wykres słupkowy wykonujemy zaś poprzez CZĘSTOŚCI dla zmiennej zwierzę Otrzymamy 3 wykresy słupkowe, po jednym dla każdej kategorii wiekowej
 Wykres słupkowy wykonujemy zaś poprzez CZĘSTOŚCI dla zmiennej zwierzę Otrzymamy 3 wykresy słupkowe, po jednym dla każdej kategorii wiekowej.")
17
Obliczanie miar tendencji centralnej i miar rozproszenia Analiza->Opis statystyczny->Częstości… Zmienna prospektywna

18
Analiza->Opis statystyczny->Eksploracja Zmienna prospektywna

19
Otrzymany raport składa się z 3 tabel Pierwsza z nich pokazuje nam informacje o ilości obserwacji Druga prezentuje już percentyle Trzecia pokazuje obliczone miary tendencji centralnej i miary rozproszenia, jak również inne statystyki (w tym skośność i kurtozę)
")
20
W oknie eksploracji wprowadźmy na LISTĘ CZYNNIKÓW zmienną płeć Otrzymamy obliczenia wykonane osobno dla kobiet i mężczyzn (w przypadku CZĘSTOŚCI trzeba by użyć omawianej funkcji PODZIEL NA PODZBIORY )
")
21
Sortowanie obserwacji w zbiorze danych Sortowanie ułatwia nam poruszanie się w zbiorze danych. Opcję te znajdziemy w meny Dane-> Sortuj zmienne (zmienna wiek) Sortowanie może być rosnące lub malejące według wskazanej przez nas zmiennej. Wprowadzenie wielu zmiennych spowoduje, że sortowanie będzie się odbywać według kolejności wprowadzanych zmiennych.
 Sortowanie może być rosnące lub malejące według wskazanej przez nas zmiennej. Wprowadzenie wielu zmiennych spowoduje, że sortowanie będzie się odbywać według kolejności wprowadzanych zmiennych..")
22
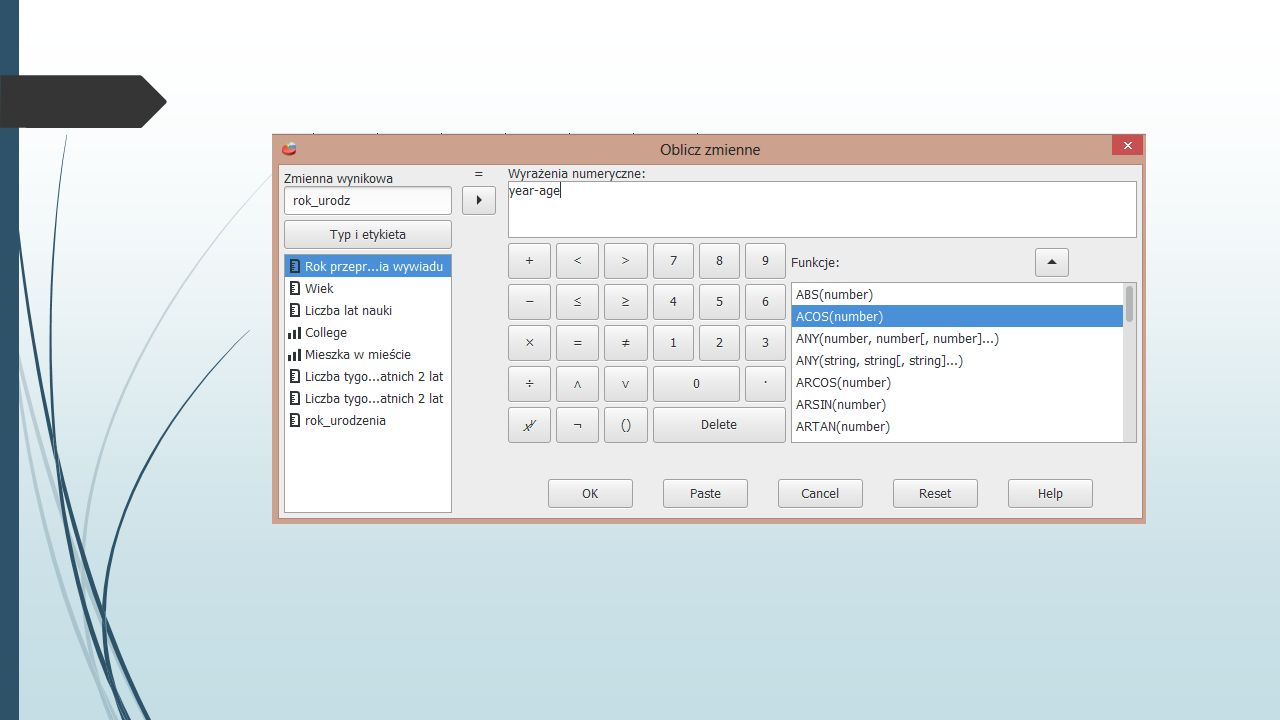
Funkcje zmiennych Pakiet PSPP pozwala tworzyć funkcje od zmiennych zawartych w arkuszu. Wybierz z menu: Przekształcenia -> Oblicz.... Dostaniesz w wyniku okno, pozwalające definiować Ci nowe zmienne, które powstają z przekształcenia starych. Ćwiczenie Otwórz plik work.sav.work.sav Utwórz zmienną rok_urodz, która będzie określała rok urodzenia respondenta.

24
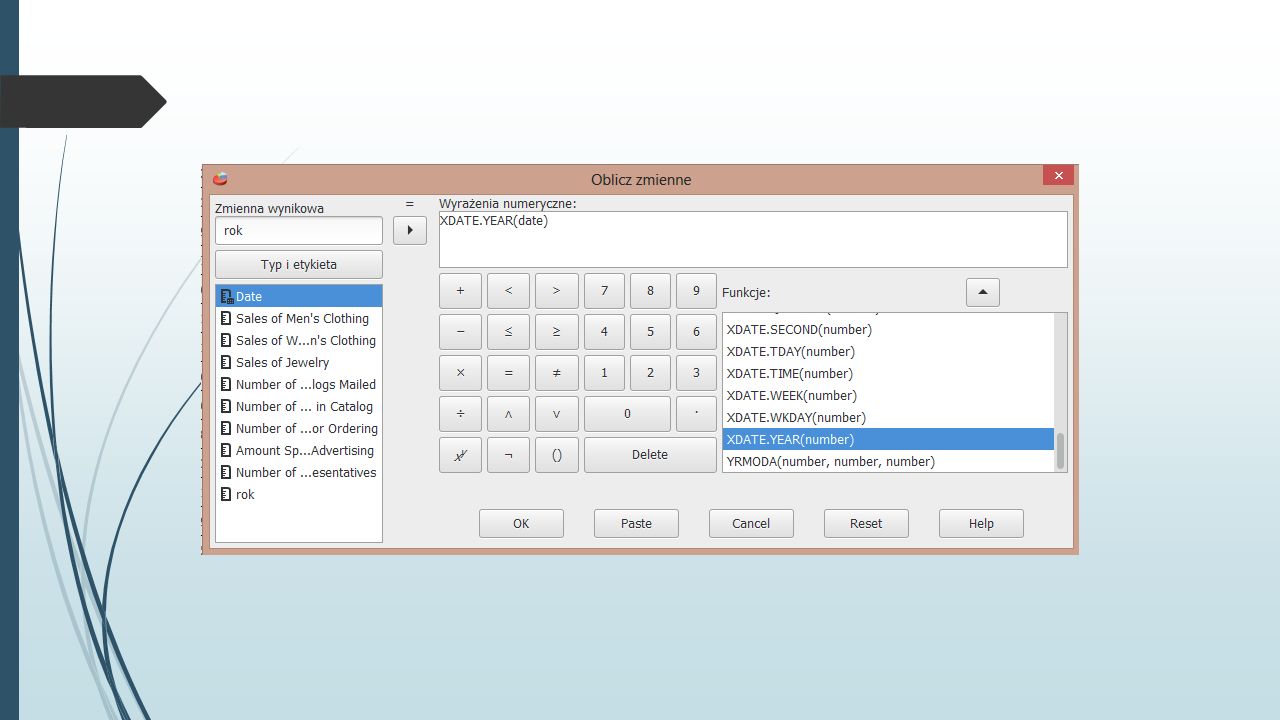
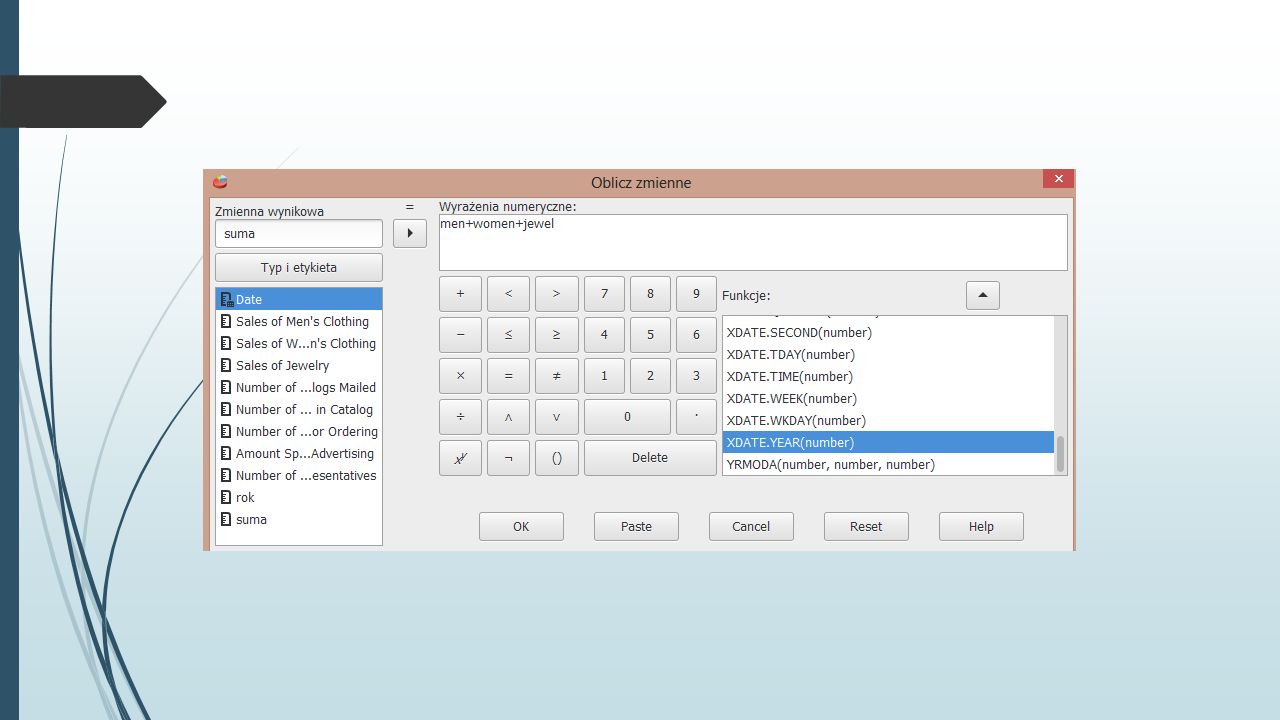
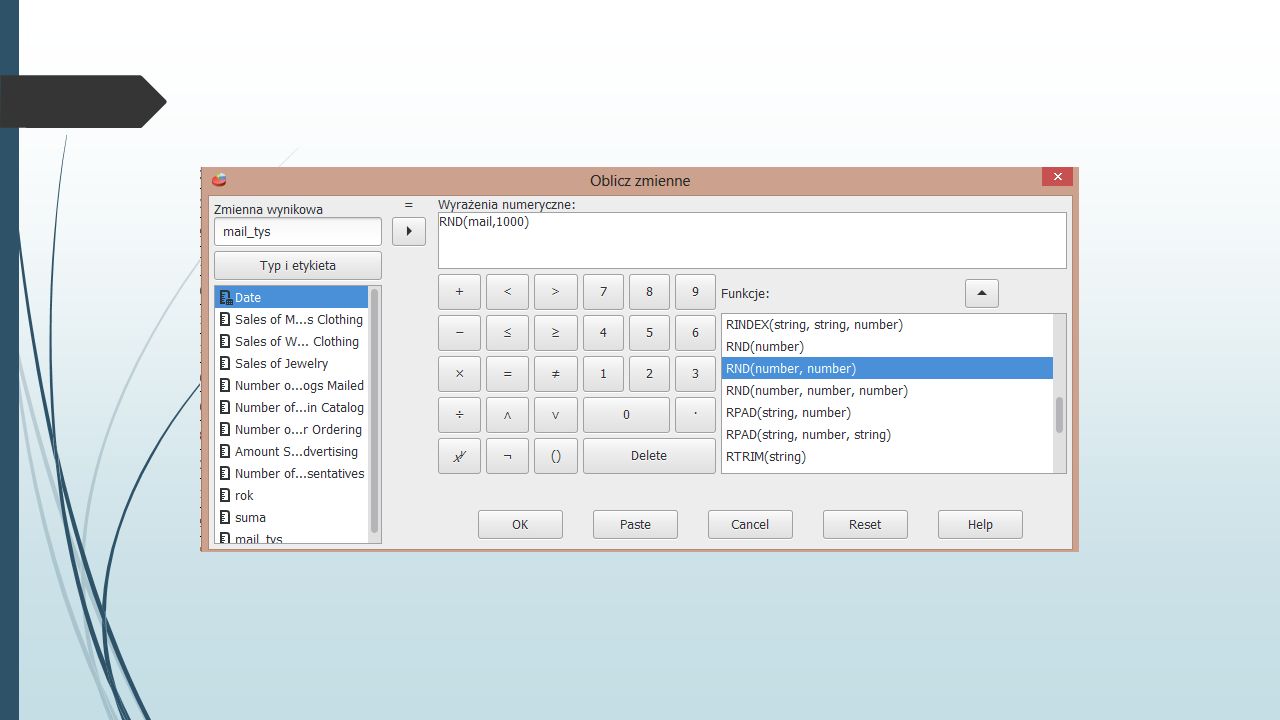
Ćwiczenie Otwórz plik catalog.sav. Utwórz zmienne: rok, która będzie zawierać rok przeprowadzenia obserwacji, suma, będącą łączną wartością sprzedaży odzieży męskiej, damskiej i biżuterii, mail_tys, która będzie podawała liczbę rozesłanych katalogów z zaokrągleniem do pełnych tysięcy.

28
Rekodowanie wartości zmiennych Dzięki rekodowaniu badacz może przekodować wartości zmiennych lub te wartości pogrupować (agregacja zmiennej). Umiejętność ta jest często wykorzystywana na etapie analizy (np. przy liczeniu chi-kwadrat niezależności). W procesie rekodowania powstaje nowa zmienna wynikowa, która tworzona jest za zmienną źródłową lub jako zmienna dodatkowa (opcje Rekoduj na te same zmienne, Rekoduj na inne zmienne).
. W procesie rekodowania powstaje nowa zmienna wynikowa, która tworzona jest za zmienną źródłową lub jako zmienna dodatkowa (opcje Rekoduj na te same zmienne, Rekoduj na inne zmienne)..")
29
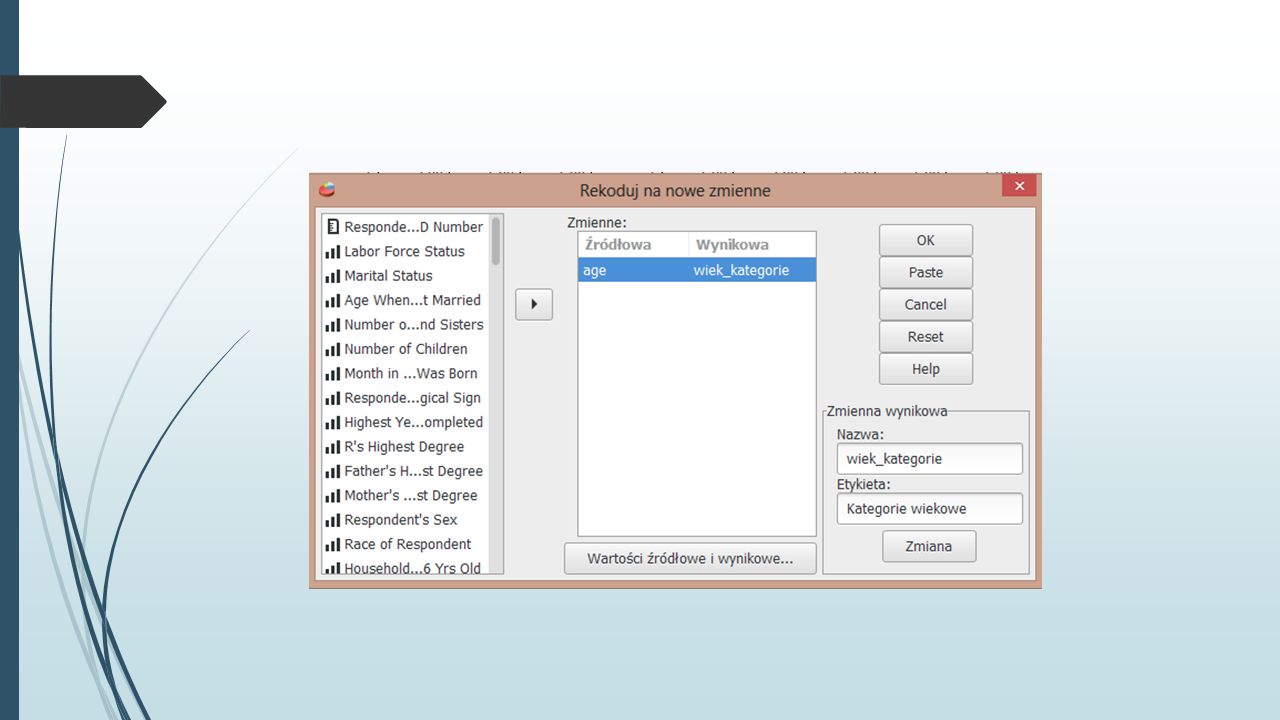
Plik GSS93subset.sav Wykorzystując plik GSS93 spróbujmy przeprowadzić rekodowania. W tym celu wykorzystamy zmienną wiek. Zmienna ta jest ilościowa. My zrekodujemy ją na zmienną nominalną i wprowadzimy trzy kategorie respondentów: młodzi (do 35 lat), w średnim wieku (36-55 lat) i starsi (powyżej 55 lat). Zachowamy pierwotną zmienną. Klikamy Przekształcenia –> Rekoduj na inne zmienne. W polu Zmienna źródłowa->wynikowa umieszczamy zmienną, którą będziemy rekodować. Następnie określamy nazwę i etykietę z zmiennej wynikowej i klikamy Zmiana.
, w średnim wieku (36-55 lat) i starsi (powyżej 55 lat). Zachowamy pierwotną zmienną. Klikamy Przekształcenia –> Rekoduj na inne zmienne. W polu Zmienna źródłowa->wynikowa umieszczamy zmienną, którą będziemy rekodować. Następnie określamy nazwę i etykietę z zmiennej wynikowej i klikamy Zmiana..")
31
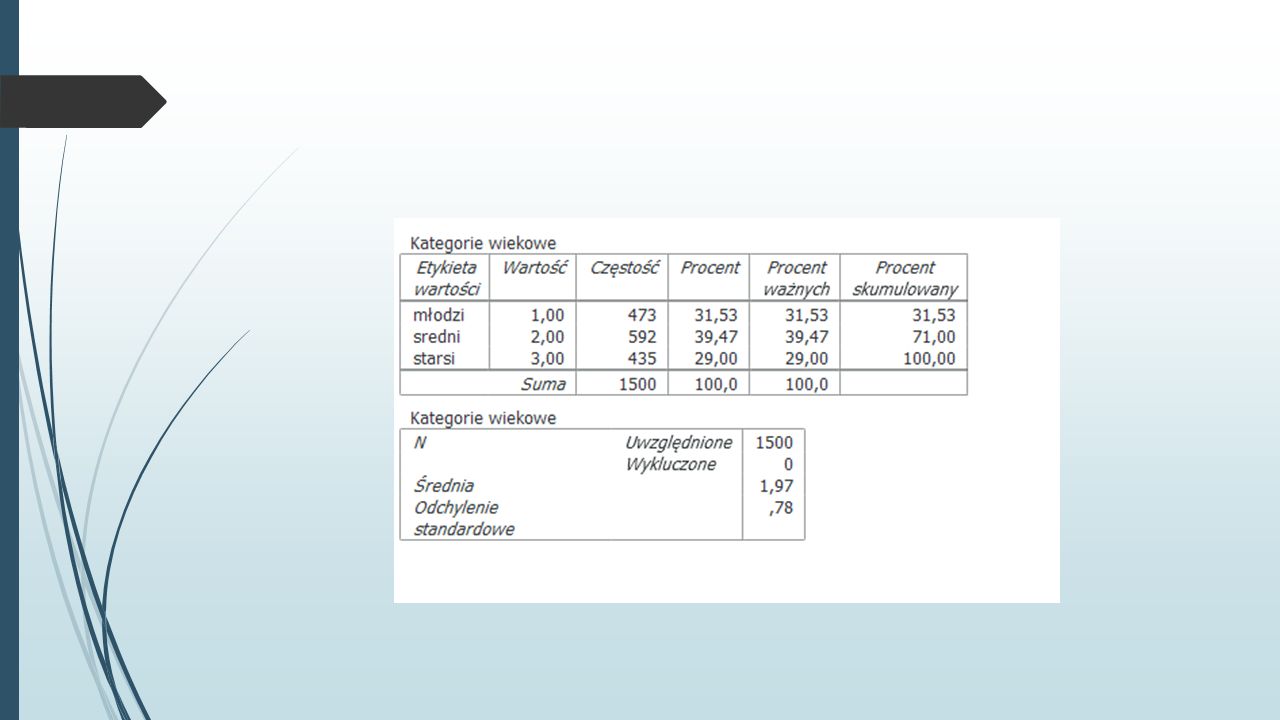
Kolejny krok to określenie wartości źródłowych i wynikowych. W naszym przykładzie mamy podane zakresy: on najmniejszego wieku do 35 lat, od 35 lat do 55 lat i od 55 lat do wartości największej. Zatem zakresy te przyjmą nowe wartości, kolejno 1, 2, 3.

32
Klikamy Dalej i OK.W ten sposób utworzyliśmy nową zmienną, a jej wartościom nadajemy etykiety.

34
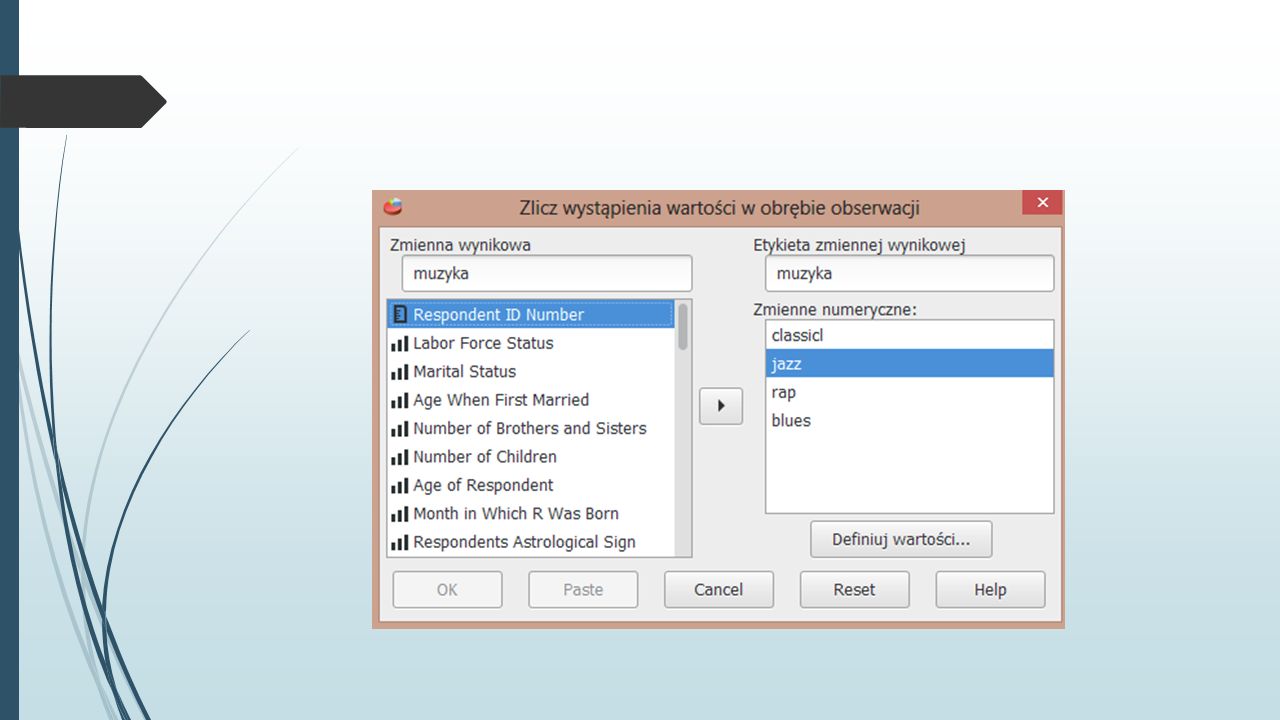
Zliczanie wystąpień wartości Jak sama nazwa wskazuje opcja ta służy do zliczania wystąpień określonych wartości w wybranym zestawie zmiennych. Tworzona jest nowa zmienna, która zawiera wartości mieszczące się w przedziale od 0 do wartości równej liczbie zadanych zmiennych. Sprawdźmy (GSS93.sav) ile gatunków muzyki lubią respondenci spośród zestawu: klasyczna, jazz, blues, rap. Odpowiedź lubię została zakodowana jako 1, a więc ta wartość będzie zliczana. Skoro mamy cztery gatunki zakres zliczeń będzie wynosił 0-4, gdzie 0 oznacza, że respondent nie lubi żadnego z tych gatunków muzyki a 4, że lubi wszystkie. W menu Przekształcenia klikamy Zlicz wystąpienia. Wprowadzamy nazwę i etykietę nowej zmiennej. Wprowadzamy również zestaw zmiennych.
 ile gatunków muzyki lubią respondenci spośród zestawu: klasyczna, jazz, blues, rap. Odpowiedź lubię została zakodowana jako 1, a więc ta wartość będzie zliczana. Skoro mamy cztery gatunki zakres zliczeń będzie wynosił 0-4, gdzie 0 oznacza, że respondent nie lubi żadnego z tych gatunków muzyki a 4, że lubi wszystkie. W menu Przekształcenia klikamy Zlicz wystąpienia. Wprowadzamy nazwę i etykietę nowej zmiennej. Wprowadzamy również zestaw zmiennych..")
36
W menu Definiuj wartości wpisujemy wartość (lub wartości), które mają być zliczane, podobnie jak w opcji rekodowania). U nas jest to 1. Po kliknięciu dalej i OK na końcu zbioru danych pojawi się nasza zmienna. Ćwiczenie Plik uni_town.sav zawiera informacje dotyczące domów wystawionych na sprzedaż w pewnym mieście uniwersyteckim. Ostatnio najbardziej poszukiwane są domy w pobliżu uniwersytetu, posiadające basen i kominek. Utwórz zmienną, która będzie informowała ile z pożądanych cech posiadają domy w tej ofercie.uni_town.sav

37
Ćwiczenie Otwórz plik work.sav. Na podstawie zmiennej wks_work utwórz zmienną o nazwie wks_group przyjmującą wartości:work.sav 0, jeśli wks_work jest równa 0, 1, jeśli wks_work jest większa od 0 i mniejsza lub równa 25, 2, jeśli wks_work jest większa od 25 i mniejsza lub równa 50, 3, jeśli wks_work jest większa od 50 i mniejsza lub równa 75, 4, jeśli wks_work jest większa od 75 i mniejsza lub równa 100, 5, jeśli wks_work jest większa od 100.

38
Ćwiczenie Średnie kursy EUR Narodowego Banku Polskiego w dniach roboczych od 2009-06- 15 do 2009-06-30 wynosiły: 4,50 4,54 4,52 4,55 4,54 4,50 4,55 4,55 4,52 4,51 4,49 4,47 Oblicz podstawowe statystyki opisowe dla tej próby, najpierw rachunkowo (z pomocą Excela), a potem z użyciem programu PSPP.
, a potem z użyciem programu PSPP.")
39
Ćwiczenie Dla danych zawartych w pliku Dane o zatrudnieniu.sav wykonaj następujące czynności:Dane o zatrudnieniu.sav dokonaj analizy częstości grup pracowniczych w postaci tabeli i graficznie (wykres słupkowy), dla stażu pracy wylicz wartość minimalną i maksymalną, średnią i odchylenie standardowe, oblicz podstawowe statystyki dla bieżącego wynagrodzenia, wykonaj podstawowe wykresy (histogram), ile wynosi wynagrodzenie, poniżej którego znajdują się zarobki 25% pracowników, a ile takie, powyżej którego znajdują się zarobki tylko 10% pracowników?
, dla stażu pracy wylicz wartość minimalną i maksymalną, średnią i odchylenie standardowe, oblicz podstawowe statystyki dla bieżącego wynagrodzenia, wykonaj podstawowe wykresy (histogram), ile wynosi wynagrodzenie, poniżej którego znajdują się zarobki 25% pracowników, a ile takie, powyżej którego znajdują się zarobki tylko 10% pracowników")
40
Ćwiczenie Wczytaj plik Dane o zatrudnieniu.sav. Przeprowadź analizę danych w podgrupach wydzielonych ze względu na wartości zmiennej stanowis. Dokonaj analizy początkowego wynagrodzenia wykonując histogramy i odpowiadając na pytania:Dane o zatrudnieniu.sav Jaka jest najczęstsza wysokość zarobków w każdej z grup? Poniżej jakiej kwoty zarabiała połowa pracowników z każdej grupy? Poniżej jakiej kwoty zarabiała jedna czwarta pracowników każdej grupy, a poniżej jakiej trzy czwarte? Jakie były średnie zarobki każdej grupy pracowniczej?

41
Ćwiczenie Plik handel.sav zawiera wysokość obrotów towarowych (w mld zł.) 20 największych firm handlowych w Polsce w 1998 r. Dane są wyrażone w jednostkach waluty krajowej. Posortuj obserwacje malejąco ze względu na wysokość obrotów. Wykonaj podstawową analizę statystyczną wysokości obrotów. Sporządź raport.handel.sav

42
Ćwiczenie Dla danych z pliku catalog.sav wykonaj analizę statystyczną wartości sprzedaży odzieży damskiej i odzieży męskiej. Zilustruj rozkłady tych zmiennych na histogramach Ćwiczenie W pliku stores.sav znajdują się dane dotyczące obrotów dwóch sieci handlowych. Wykonaj podstawową analizę statystyczną danych. Rozkład zilustruj na histogramach.stores.sav

43
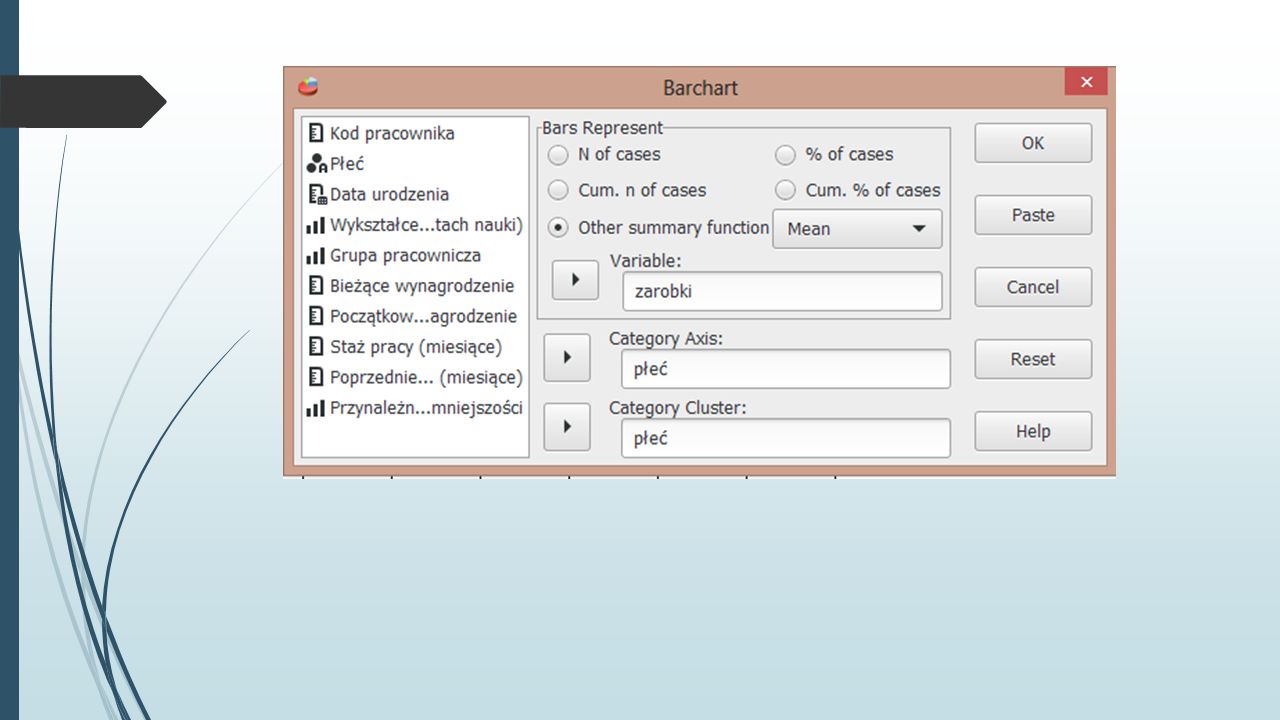
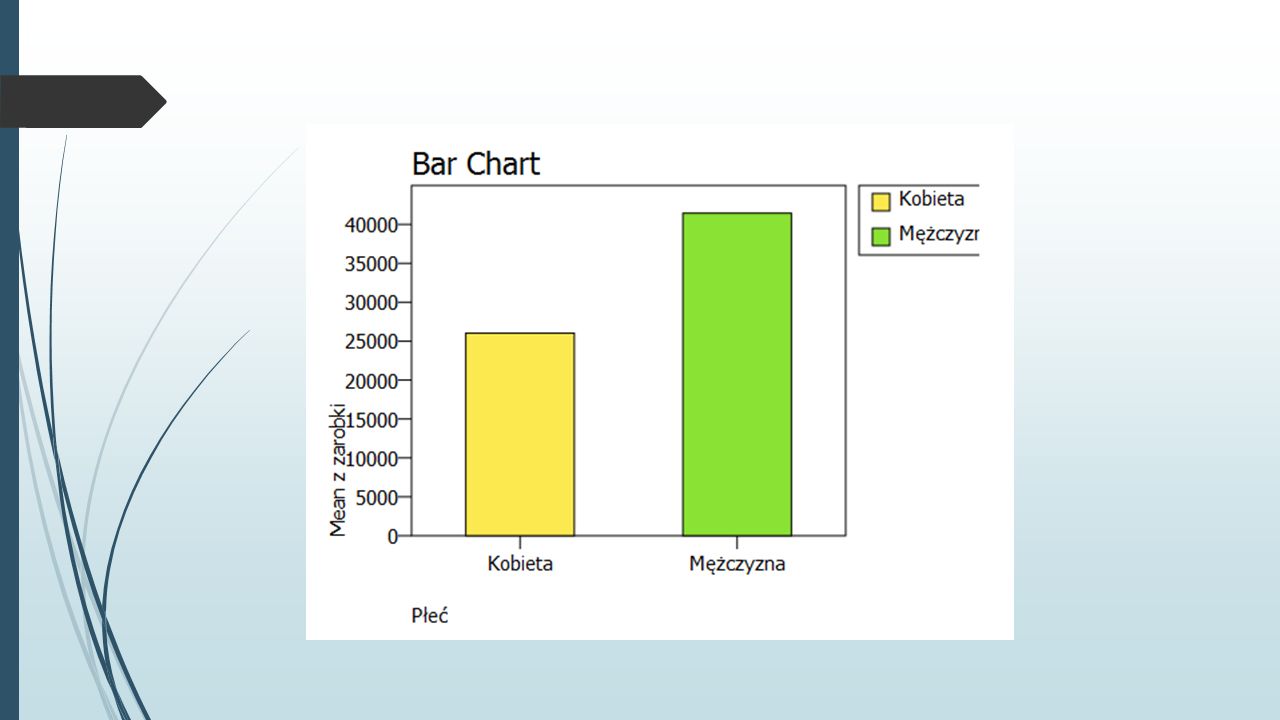
Ćwiczenie Wczytaj plik Dane o zatrudnieniu.sav. Narysuj wykresy słupkowe prezentujące:Dane o zatrudnieniu.sav procent kobiet i mężczyzn w badanej grupie respondentów, liczebność kobiet i mężczyzn z uwzględnieniem podziału na zajmowane stanowisko średnie zarobki kobiet i mężczyzn.

46
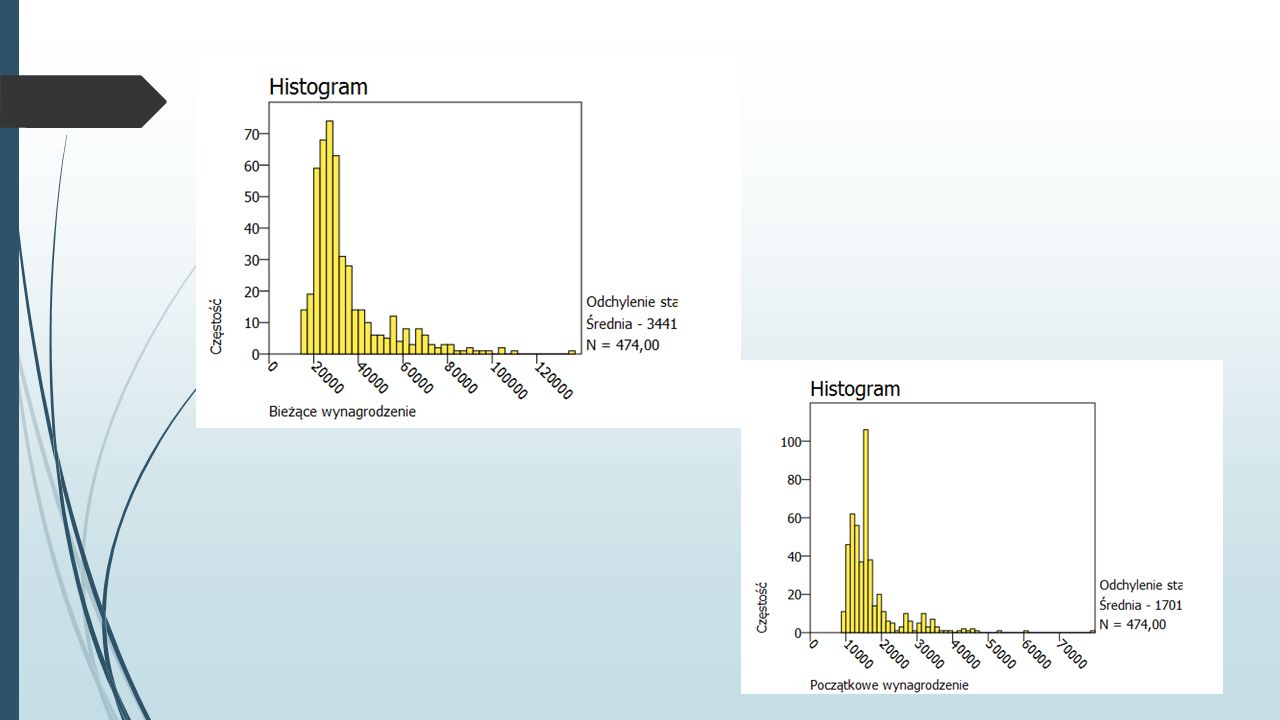
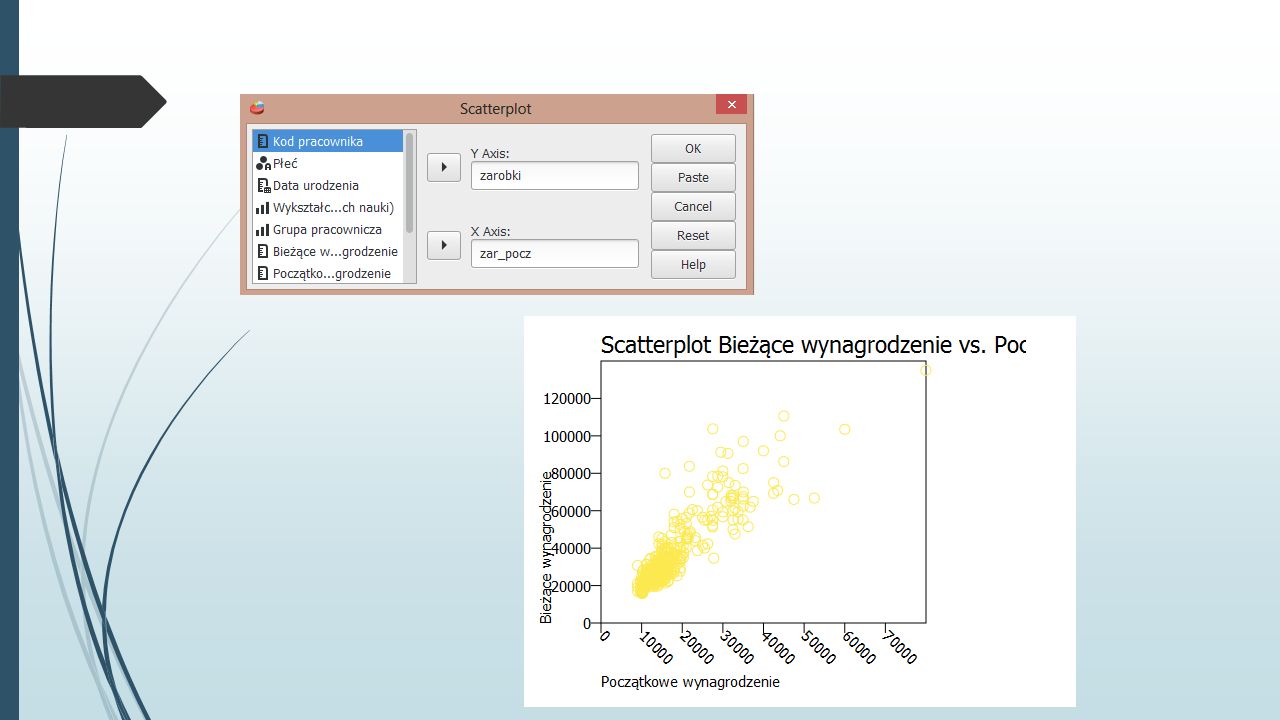
Ćwiczenie Wczytaj plik Dane o zatrudnieniu.sav.Dane o zatrudnieniu.sav Narysuj wykres kołowy przedstawiający procentowy udział kobiet i mężczyzn w próbie. Narysuj histogramy prezentujące rozkład wynagrodzeń: początkowego i bieżącego. Wykonując wykres rozrzutu, zbadaj zależność wynagrodzenia bieżącego od płacy początkowej.

50
Ćwiczenie W pliku virus.sav znajdują się dane dotyczące rozwoju wirusa komputerowego od chwili jego wykrycia na serwerze testowym do czasu przygotowania programu antywirusowego. Na wykresie liniowym przedstaw jak zmieniała się proporcja zainfekowanych wiadomości pocztowych w tym czasie.

52
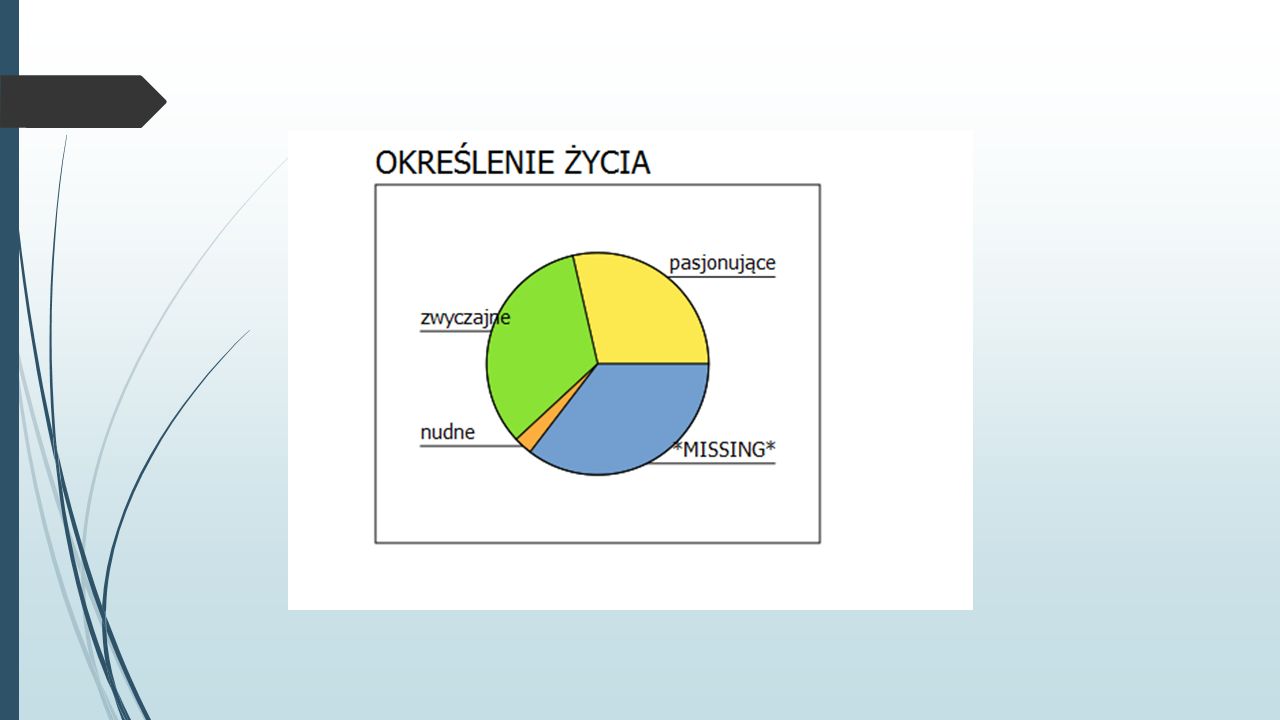
Ćwiczenie Korzystając z danych zawartych w pliku 1991 U.S. General Social Survey.sav, wykonaj wykresy kołowe prezentujące udział procentowy osób oceniających swoje życie jako pasjonujące, zwyczajne i nudne1991 U.S. General Social Survey.sav

54
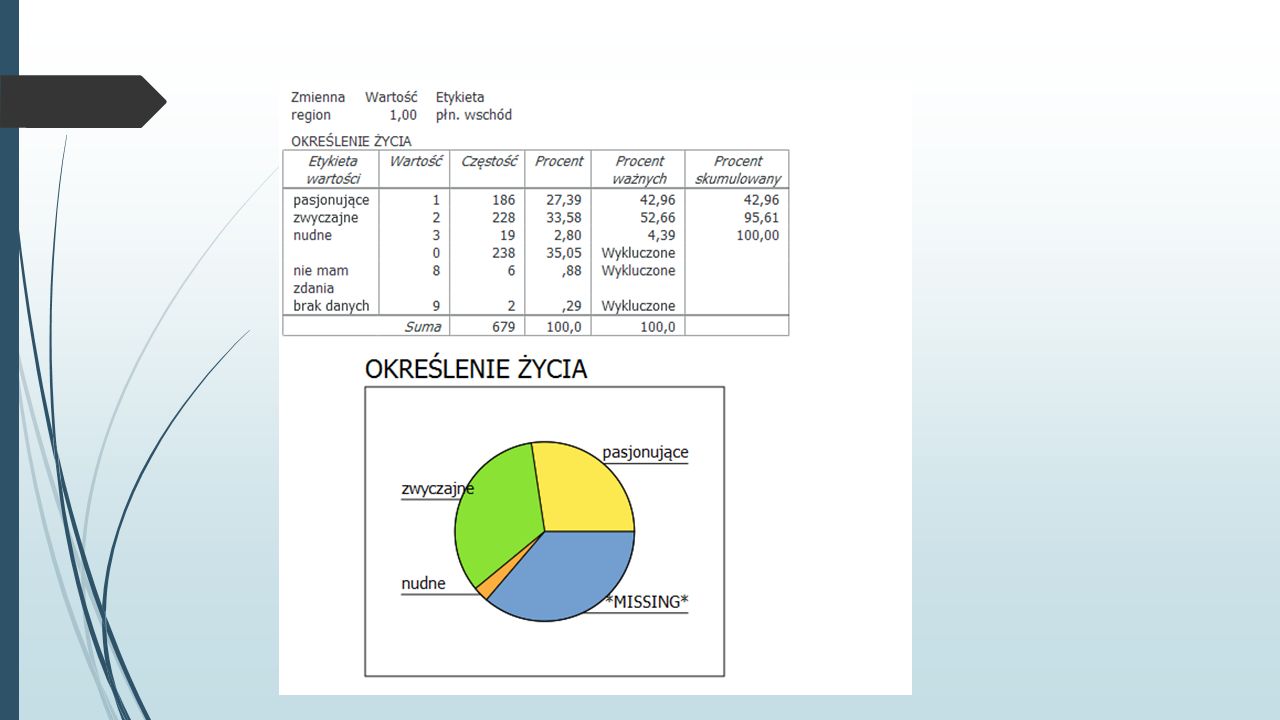
Ćwiczenie Korzystając z danych zawartych w pliku 1991 U.S. General Social Survey.sav, wykonaj wykresy kołowe prezentujące udział procentowy osób oceniających swoje życie jako pasjonujące, zwyczajne i nudne w podziale na grupy wyróżnione przez zmienne sex i region.1991 U.S. General Social Survey.sav

57
Ćwiczenie Otwórzmy dane ‘PGSS_2002_pr’ (niektóre zmienne z Polskiego Generalnego Sondażu Społecznego z roku 2002). Baza danych PGSS (w oryginale grubo ponad tysiąc zmiennych) bada nastroje, opinie i jakość życia Polaków. Potrzebna nam jest zmienna, która będzie wskazywała, że respondent mieszka sam lub że nie mieszka sam. Informacja ta mogłaby być zawarta w zmiennej Przeglądając bazę danych, widzimy, że jest w niej zmienna ‘hompop’, która mówi ile osób liczy gospodarstwo domowe respondenta. Rekodując tę zmienną, możemy uzyskać interesującą nas zmienną ‘miesz_sam’.
 bada nastroje, opinie i jakość życia Polaków. Potrzebna nam jest zmienna, która będzie wskazywała, że respondent mieszka sam lub że nie mieszka sam. Informacja ta mogłaby być zawarta w zmiennej Przeglądając bazę danych, widzimy, że jest w niej zmienna ‘hompop’, która mówi ile osób liczy gospodarstwo domowe respondenta. Rekodując tę zmienną, możemy uzyskać interesującą nas zmienną ‘miesz_sam’..")
58
Ćwiczenie

59
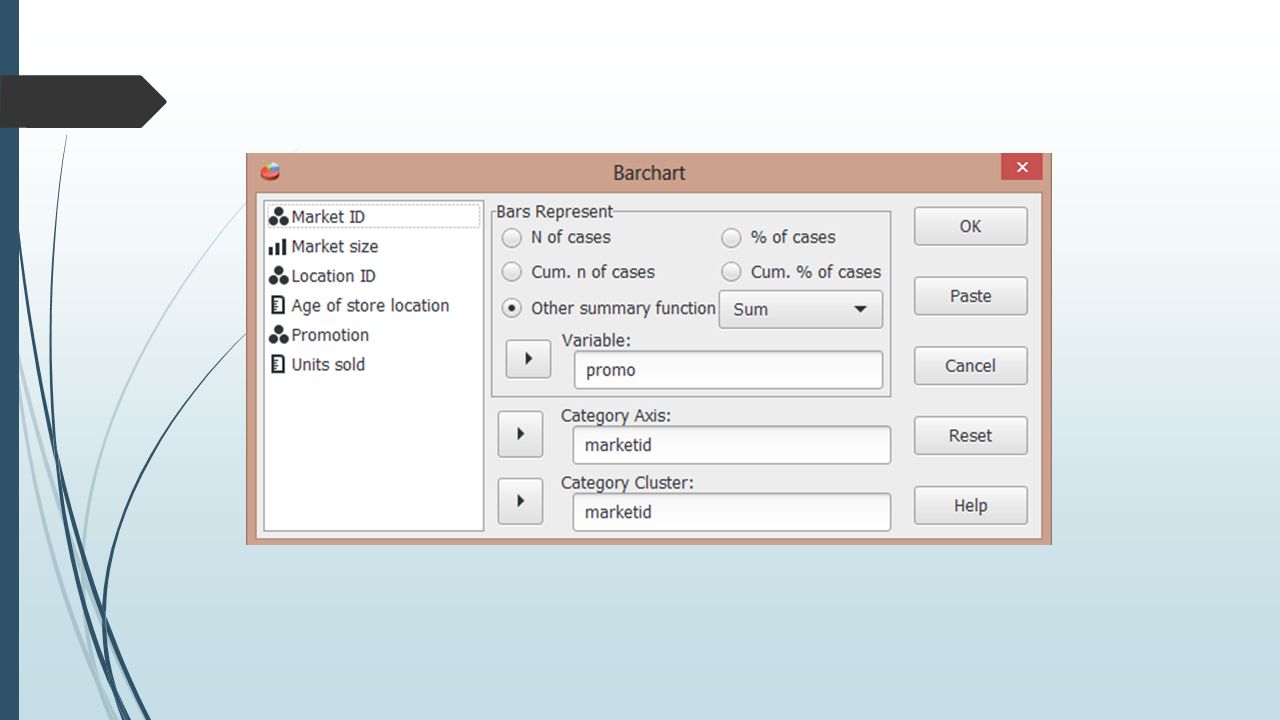
Plik testmarket_1month.sav zawiera dane dotyczące marketów 10 różnych sieci handlowych. Zmienna marketid odpowiada nazwom sieci, a zmienna locid identyfikuje różne markety. Na wykresie słupkowym porównaj łączną liczbę promocji zorganizowanych w marketach różnych sieci. Która sieć przoduje w organizacji promocji, a która ma najgorsze wyniki? Na wykresie kołowym przedstaw procentowy udział marketów małych, średnich i dużych w badanej grupie. Wykonaj wykres słupkowy, na którym zaprezentujesz liczbę marketów kolejno małych, średnich i dużych.

63
Ćwiczenie Na podstawie analizy 50 ofert turystycznych, w których proponowano wczasy w basenie Morza Śródziemnego w maju 2005 roku, uzyskano następujące dane dotyczące długości proponowanego wypoczynku (w dniach): 15 9 13 15 14 10 14 12 16 14 12 12 12 11 15 15 15 14 15 14 15 9 12 10 12 10 12 9 9 14 7 10 14 12 7 14 10 11 11 9 13 16 11 14 7 14 14 10 14 11 Podaj tabelę częstości. Oceń przeciętny czas trwania oferowanych wczasów. Oblicz odchylenie standardowe. Wyznacz dominantę, medianę, kwartyle. Narysuj histogram.

64
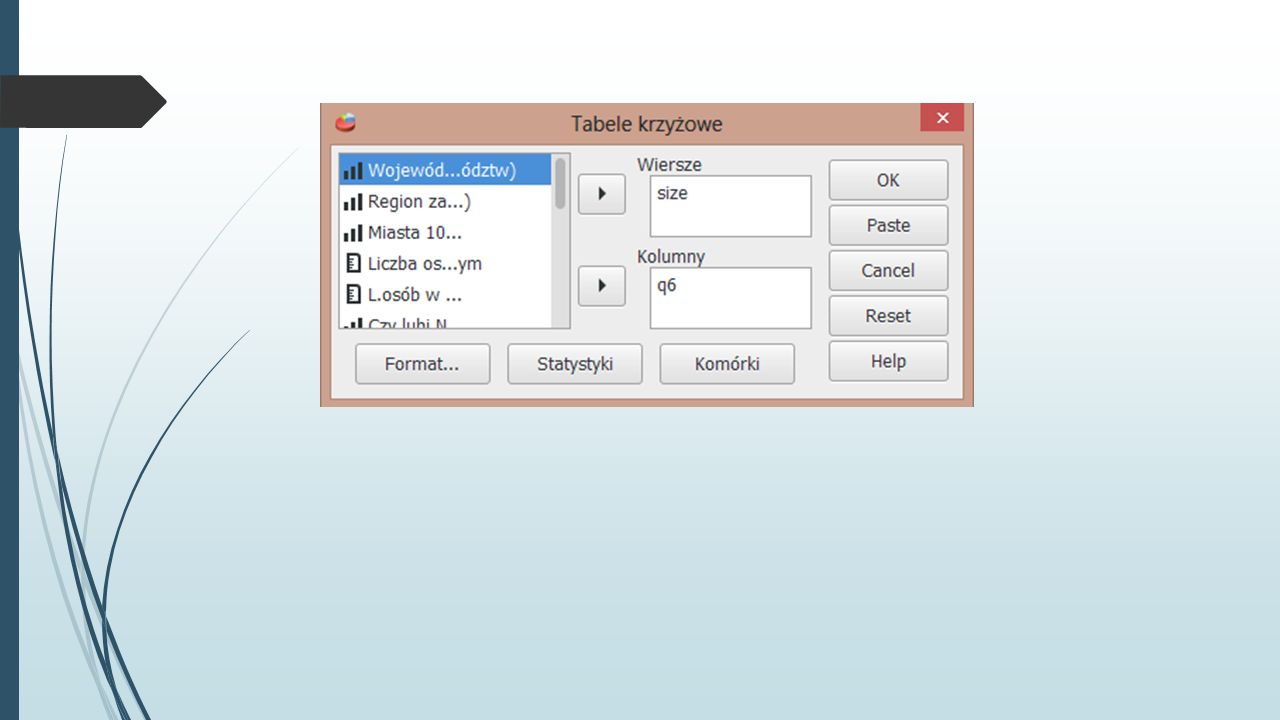
Tabele krzyżowe Tabele kontyngencji (inaczej krzyżowe) to jedna z najpopularniejszych, a zarazem najprostszych form prezentowania zależności między zmiennymi dyskretnymi. Pokazują one jak kategorie jednej zmiennej rozkładają się w kategoriach innej. Analiza->Opis statystyczny->Tabele krzyżowe Plik PGSS_2002_pr.sav Powiedzmy, że chcemy zobaczyć jak rozkładały się odpowiedzi na pytanie „Czy rządzenie krajem należy zostawić mężczyznom (zmienna „q6”) w zależności od wielkości miejscowości, w której respondent mieszkał (zmienna „size”). Kategorie jednej ze zmiennych wstawiamy więc do wiersza, a kategorie drugiej do kolumny (wybór wiersza i kolumny może być przypadkowy). W wyniku dostajemy tabelę krzyżową, z której widać, ilu było respondentów dla każdego pola tabeli.
 w zależności od wielkości miejscowości, w której respondent mieszkał (zmienna „size ). Kategorie jednej ze zmiennych wstawiamy więc do wiersza, a kategorie drugiej do kolumny (wybór wiersza i kolumny może być przypadkowy). W wyniku dostajemy tabelę krzyżową, z której widać, ilu było respondentów dla każdego pola tabeli..")
67
Ilu było bardzo szczęśliwych (‘q95’) bezrobotnych (‘q18st’)? Ile procent bezrobotnych jest bardzo szczęśliwych?

Podobne prezentacje











>")


 Średnia arytmetyczna (dla szeregu szczegółowego) Średnią arytmetyczną nazywamy sumę wartości zmiennej wszystkich jednostek.>")



 Wykład 6/7: Analiza statystyczna wyników symulacyjnych Dr inż. Halina Tarasiuk (halina@tele.pw.edu.pl),>")






