Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Regresja logistyczna - model binarny cz. I

2
Model regresji logistycznej
Metoda estymacji modelu Kodowanie zmiennych jakościowych Przykład i interpretacja wyników Testowanie istotności parametrów

3
Modelowanie – MODEL BINARNEJ REGRESJI LOGISTYCZNEJ
Interesuje nas, czy jakieś zjawisko wystąpi czy nie wystąpi w przyszłości i co będzie miało wpływ na prawdopodobieństwo wystąpienia zdarzenia. Ponadto, interesuje nas też identyfikacja czynników, od których zależy czy zdarzenie wystąpi, kierunku oraz siły wpływu determinant, co umożliwić ma prognozowanie interesujących nas zjawisk. Przykłady problemów: Dlaczego pewni ludzie chorują na daną chorobę, a inni nie? Dlaczego jeden konsument kupuje dany produkt, a inny nie?

4
Zapis modelu RL Zmienną zależną jest zmienna Y, która przyjmuje tylko dwie wartości związane z wystąpieniem lub nie wystąpieniem pewnego zdarzenia losowego A (kodowanie binarne, np. zero-jedynkowe). Y = 1, gdy zaszło zdarzenie A Y = 0, gdy zdarzenie A nie zaszło Y jest zmienną losową o rozkładzie zerojedynkowym.
. Y = 1, gdy zaszło zdarzenie A. Y = 0, gdy zdarzenie A nie zaszło. Y jest zmienną losową o rozkładzie zerojedynkowym.")
5
Analizę zmiennej objaśnianej o charakterze binarnym umożliwia model binarnej regresji logistycznej. W modelu regresji logistycznej estymujemy bezpośrednio prawdopodobieństwo wystąpienia zdarzenia A tj. prawdopodobieństwo gdzie µ jest wartością oczekiwaną zmiennej Y. tzn. µ = E(Y). Przyjmujemy, że to prawdopodobieństwo jest funkcją zależną od zmiennych i zależność ma postać: Oznaczając kombinację liniową zmiennych objaśniających przez Z możemy zapisać: oraz
. Przyjmujemy, że to prawdopodobieństwo jest funkcją zależną od zmiennych i zależność ma postać: Oznaczając kombinację liniową zmiennych objaśniających przez Z możemy zapisać: oraz.")
6
Funkcja logistyczna Wykres funkcji logistycznej w przedziale -4 < z < 4. Kierunek zmian P w zależności od zmiennej zależy od znaku współczynnika występującego przy tej zmiennej. Jeżeli βi > 0, to wraz ze wzrostem Xi wartość prawdopodobieństwa P wzrasta. Mówimy wtedy, że czynnik opisywany przez zmienną Xi działa stymulująco na zdarzenie A. Jeżeli βi < 0, to wzrost powoduje spadek wartości P. Mówimy wtedy, że czynnik opisywany przez zmienną działa ograniczająco (limitująco) na zdarzenie A. Zależność P(A) od zmiennych X1,...,Xk jest nieliniowa. Parametry równania logistycznego szacuje się metodą największej wiarygodności (MNW, maksimum likelihood - ML). Jest to metoda iteracyjna.
 na zdarzenie A. Zależność P(A) od zmiennych X1,...,Xk jest nieliniowa. Parametry równania logistycznego szacuje się metodą największej wiarygodności (MNW, maksimum likelihood - ML). Jest to metoda iteracyjna.")
7
Metoda estymacji Zaobserwowane w próbie wartości y1,…,yn są realizacją n-wymiarowej zmiennej losowej (Y1,…,Yn). Każda ze zmiennych Yi (i=1,...n) ma rozkład zerojedynkowy o wartości średniej μi = P(Yi = 1), gdzie Jeżeli wartości zmiennych objaśniających są ustalone, to rozkład zmiennej losowej (Y1,…,Yn) zależy jedynie od parametrów β1,… βk, . Ponieważ zmienne losowe Y1,…,Yn są niezależne, prawdopodobieństwo otrzymania zaobserwowanych wartości y1,…,yn w próbie wynosi: Dla ustalonej próby powyższe prawdopodobieństwo jest funkcją parametrów β0,... βk zwaną funkcją wiarogodności próby. W przypadku stosowania wag dla obserwacji funkcja wiarogodności ma postać: (i-ta obserwacja jest brana pod uwagę wi razy)
. Każda ze zmiennych Yi (i=1,...n) ma rozkład zerojedynkowy o wartości średniej μi = P(Yi = 1), gdzie. Jeżeli wartości zmiennych objaśniających są ustalone, to rozkład zmiennej losowej (Y1,…,Yn) zależy jedynie od parametrów β1,… βk, . Ponieważ zmienne losowe Y1,…,Yn są niezależne, prawdopodobieństwo otrzymania zaobserwowanych wartości y1,…,yn w próbie wynosi: Dla ustalonej próby powyższe prawdopodobieństwo jest funkcją parametrów β0,... βk zwaną funkcją wiarogodności próby. W przypadku stosowania wag dla obserwacji funkcja wiarogodności ma postać: (i-ta obserwacja jest brana pod uwagę wi razy)")
8
Metoda estymacji Metoda największej wiarogodności (MNW) polega na szukaniu takich wartości nieznanych parametrów, dla których funkcja L przyjmuje wartość maksymalną. Bierze się to z założenia, że w wyniku wylosowania próby powinno zrealizować się zdarzenie o największym prawdopodobieństwie. Wartości estymatorów dla β0,... βk otrzymane metodą największej wiarogodności oznaczamy b0,...,bk. Ponieważ funkcja L osiąga maksimum w tych samych punktach, co jej logarytm (tj. funkcja lnL), w praktyce wyznacza się maksimum funkcji lnL. Maksimum to znajduje się metodami rachunku różniczkowego, rozwiązując układ równań j=0,...,k W naszym przypadku j=0,...,k Układ k+1 równań jest układem równań nieliniowych. Można go rozwiązać stosując algorytm Newtona-Raphsona. Jest to algorytm iteracyjny.
 polega na szukaniu takich wartości nieznanych parametrów, dla których funkcja L przyjmuje wartość maksymalną. Bierze się to z założenia, że w wyniku wylosowania próby powinno zrealizować się zdarzenie o największym prawdopodobieństwie. Wartości estymatorów dla β0,... βk otrzymane metodą największej wiarogodności oznaczamy b0,...,bk. Ponieważ funkcja L osiąga maksimum w tych samych punktach, co jej logarytm (tj. funkcja lnL), w praktyce wyznacza się maksimum funkcji lnL. Maksimum to znajduje się metodami rachunku różniczkowego, rozwiązując układ równań. j=0,...,k. W naszym przypadku. j=0,...,k. Układ k+1 równań. jest układem równań nieliniowych. Można go rozwiązać stosując algorytm Newtona-Raphsona. Jest to algorytm iteracyjny.")
9
Metoda estymacji Po wyznaczeniu wartości estymatorów b0,...,bk .należy obliczyć ich średnie błędy szacunku. Średnie błędy szacunku estymatorów wyznacza się na podstawie macierzy kowariancji, której estymatorem jest macierz r,s=0,...,k

10
Przykład modelu logistycznego
W modelu zmienną binarną będzie nadwaga (zmienna zero-jedynkowa; 1-ma nadwagę 0-nie ma nadwagi). Wartość zmiennej jest określana na podstawie Body Mass Indem BMI, który obliczany jest jako iloraz wzrostu i masy ciała. Im mniejsza wartość BMI, tym ryzyko wystąpienia chorób jest mniejsze. Ustalono krytyczną wartość tego indeksu (25). Wartości powyżej 25 są klasyfikowane jako nadwaga. Do objaśnienia zmiennej zależnej: nadwaga wybrano 9 następujących zmiennych niezależnych: dochod, wydatki, syt_mat, komputer, plec stan_cywilny, wiek, wyd_zyw, fastfood.
. Wartość zmiennej jest określana na podstawie Body Mass Indem BMI, który obliczany jest jako iloraz wzrostu i masy ciała. Im mniejsza wartość BMI, tym ryzyko wystąpienia chorób jest mniejsze. Ustalono krytyczną wartość tego indeksu (25). Wartości powyżej 25 są klasyfikowane jako nadwaga. Do objaśnienia zmiennej zależnej: nadwaga wybrano 9 następujących zmiennych niezależnych: dochod, wydatki, syt_mat, komputer, plec stan_cywilny, wiek, wyd_zyw, fastfood.")
11
Przykład modelu logistycznego
Nazwa zmiennej Opis zmiennej Wartości/kody Nadwaga Zmienna binarna informująca o nadwadze 1=nadwaga, 0=brak nadwagi Dochod Dochod respondenta Od do 19 000 dolarów Wydatki Wydatki miesięczne respondenta Od 184 do 16 456 dolarów K_miej Kategoria miejsca zamieszkania 1=mała wieś; 2=wieś, 3=małe miasto, 4=średnie miasto, 5=duże miasto, 6=metropolia Syt_mat Ocena sytuacji materialnej (subiektywna) 1=bardzo dobra, 2=raczej dobra,3=przeciętna, 4=raczej zła, 5=zła Stan_cywilny Stan cywilny klienta 1=kawaler, panna 2=żonaty, mężatka 3=wdowiec, wdowa 4=rozwiedziony(a) separowany(a) Komputer Zmienna binarna informująca czy osoba posiada komputer (wykonuje pracę siedzącą) 1 = posiada komputer, 0 – nie posiada komputera Wiek Wiek (kalendarzowy) Plec Zmienna binarna określająca płeć respondenta 1= mężczyzna, 2=kobieta Wyd_zyw Wysokość wydatków przeznaczanych na produkty żywnościowe Fastfood Zmienna jakościowa opisująca jak często dany respondent je żywność z fastfoodów 1= często (przynajmniej raz w tygodniu, 0 = rzadko lub prawie nigdy (mniej niż 1 raz w tygodniu)
 1=bardzo dobra, 2=raczej dobra,3=przeciętna, 4=raczej zła, 5=zła. Stan_cywilny. Stan cywilny klienta. 1=kawaler, panna. 2=żonaty, mężatka. 3=wdowiec, wdowa. 4=rozwiedziony(a) separowany(a) Komputer. Zmienna binarna informująca czy osoba posiada komputer (wykonuje pracę siedzącą) 1 = posiada komputer, 0 – nie posiada komputera. Wiek. Wiek (kalendarzowy) Plec. Zmienna binarna określająca płeć respondenta. 1= mężczyzna, 2=kobieta. Wyd_zyw. Wysokość wydatków przeznaczanych na produkty żywnościowe. Fastfood. Zmienna jakościowa opisująca jak często dany respondent je żywność z fastfoodów. 1= często (przynajmniej raz w tygodniu, 0 = rzadko lub prawie nigdy (mniej niż 1 raz w tygodniu)")
12
Przykład modelu logistycznego
Wśród zmiennych objaśniających mamy dwa rodzaje zmiennych: a) zmienne ciągłe: dochod, wydatki, wiek, lata, wyd_zyw Mogą przyjmować dowolne wartości w ustalonym przedziale zmienności, przy czym wartości obserwowane w próbie są skwantowane jedynie ze względu na dokładność pomiaru. b) zmienne wskaźnikowe (dummy variables): plec, k_miej, syt_mat, stan cywilny, fastfood komputer Mogą przyjmować wartości 0 lub 1 (lub więcej poziomów dychotomicznych). Mówią one o tym, czy jednostka posiada określoną cechę, czy jej nie posiada. Czym są i czym się różnią zmienne ilościowe od zmiennych jakościowych. Z jakimi zmiennymi będziemy mieli do czynienia w modelach szacowanych na zajęciach.
 zmienne ciągłe: dochod, wydatki, wiek, lata, wyd_zyw. Mogą przyjmować dowolne wartości w ustalonym przedziale zmienności, przy czym wartości obserwowane w próbie są skwantowane jedynie ze względu na dokładność pomiaru. b) zmienne wskaźnikowe (dummy variables): plec, k_miej, syt_mat, stan cywilny, fastfood komputer. Mogą przyjmować wartości 0 lub 1 (lub więcej poziomów dychotomicznych). Mówią one o tym, czy jednostka posiada określoną cechę, czy jej nie posiada. Czym są i czym się różnią zmienne ilościowe od zmiennych jakościowych. Z jakimi zmiennymi będziemy mieli do czynienia w modelach szacowanych na zajęciach.")
13
Zbiór danych

14
Tabela BMI na fastfoody Tabela BMI na komputery
Proces modelowania powinien być poprzedzony wstępną analizą danych, w szczególności sprawdzić należy czy nie występuje sytuacja uniemożliwiająca modelowanie w postaci braków w tablicach kontyngencji oraz czy nie mamy do czynienia z dysproporcjami w przypadku poszczególnych rozkładów, ponieważ taka sytuacja może zostać zniwelowana poprzez wprowadzenie wag. Tabela BMI na sex BMI sex Razem kobieta mężczyzna brak na nadwaga Tabela BMI na fastfoody BMI fastfoody Razem często prawie brak na nadwaga Tabela BMI na komputery BMI komputery Razem często rzadko brak na nadwaga

15
Wstępna analiza rozkładów
Tabela BMI na zamieszk BMI zamieszk Razem b małe bardzo duże duże małe wieś średnie brak na nadwaga Tabela BMI na syt_materialna BMI syt_materialna Razem bardzo dobra przeciętna raczej dobra raczej zła zła brak na 6 0.63 nadwaga 4 0.42

17
Estymacja – MNW (“maximum likelihood estimation”)
Procedura iteracyjna znaleźć ma najlepszy zbiór parametrów (jedyny). Poszukiwane jest maksimum funkcji wiarygodności, które to pozwoli wyznaczyć zestaw parametrów największej wiarygodności. Różne kształty funkcje wiarygodności i problemy ze znalezieniem maksimum.
. Poszukiwane jest maksimum funkcji wiarygodności, które to pozwoli wyznaczyć zestaw parametrów największej wiarygodności. Różne kształty funkcje wiarygodności i problemy ze znalezieniem maksimum.")
18
Metoda estymacji Nieznane parametry β1,… βk, szacujemy na podstawie próby losowej. Niech y1,…,yn będą zaobserwowanymi wartościami zmiennej zależnej w n-elementowej próbie losowej i niech x1j,…,xnj będą wartościami j-tej zmiennej objaśniającej (j=1,...,k). Wynik próby możemy zapisać w postaci macierzowej jako: gdzie xi0=1 (i=1,...,n) Próba powinna być reprezentatywna dla populacji, z której została wylosowana. Jeżeli podejrzewamy, że tak nie jest (np. z powodu odmowy przez niektóre osoby udzielenia odpowiedzi na pytania ankiety), to stosuje się wagi mające na celu zapewnienie zgodności próby i populacji, Różnym obserwacjom nadajemy wtedy różne znaczenie przypisując im wagi (i=1,...,n). Pożądane jest, aby tzn. by suma wag była równa liczbie obserwacji. Oznaczmy wektor wag
. Wynik próby możemy zapisać w postaci macierzowej jako: gdzie xi0=1 (i=1,...,n) Próba powinna być reprezentatywna dla populacji, z której została wylosowana. Jeżeli podejrzewamy, że tak nie jest (np. z powodu odmowy przez niektóre osoby udzielenia odpowiedzi na pytania ankiety), to stosuje się wagi mające na celu zapewnienie zgodności próby i populacji, Różnym obserwacjom nadajemy wtedy różne znaczenie przypisując im wagi (i=1,...,n). Pożądane jest, aby. tzn. by suma wag była równa liczbie obserwacji. Oznaczmy wektor wag.")
19
Metoda estymacji Zaobserwowane w próbie wartości y1,…,yn są realizacją n-wymiarowej zmiennej losowej (Y1,…,Yn). Każda ze zmiennych Yi (i=1,...n) ma rozkład zerojedynkowy o wartości średniej μi = P(Yi = 1), gdzie Jeżeli wartości zmiennych objaśniających są ustalone, to rozkład zmiennej losowej (Y1,…,Yn) zależy jedynie od parametrów β1,… βk, . Ponieważ zmienne losowe Y1,…,Yn są niezależne, prawdopodobieństwo otrzymania zaobserwowanych wartości y1,…,yn w próbie wynosi: Dla ustalonej próby powyższe prawdopodobieństwo jest funkcją parametrów β0,... βk zwaną funkcją wiarogodności próby. W przypadku stosowania wag dla obserwacji funkcja wiarogodności ma postać: (i-ta obserwacja jest brana pod uwagę wi razy)
. Każda ze zmiennych Yi (i=1,...n) ma rozkład zerojedynkowy o wartości średniej μi = P(Yi = 1), gdzie. Jeżeli wartości zmiennych objaśniających są ustalone, to rozkład zmiennej losowej (Y1,…,Yn) zależy jedynie od parametrów β1,… βk, . Ponieważ zmienne losowe Y1,…,Yn są niezależne, prawdopodobieństwo otrzymania zaobserwowanych wartości y1,…,yn w próbie wynosi: Dla ustalonej próby powyższe prawdopodobieństwo jest funkcją parametrów β0,... βk zwaną funkcją wiarogodności próby. W przypadku stosowania wag dla obserwacji funkcja wiarogodności ma postać: (i-ta obserwacja jest brana pod uwagę wi razy)")
20
Model z jedna zmienną objaśniającą

21
Przy kodowaniu umożliwiającym wykorzystanie opcji „zmienne ilościowe” dodatkowo można narzucić programowi poziom zmiennej, który ma być poziomem „ustalonym” przy późniejszej interpretacji oszacowań modelu. Ważne jest aby odpowiednio wybrać kategorię zmiennej objaśnianej, która staje się modelowanym prawdopodobieństwem zajścia zdarzenia Styl kodowania zmiennej niezależnej jest istotny z punktu widzenia rodzaju szacowanego modelu regresji logistycznej. Kategoria odniesienia ma istotne znaczenie w modelu regresji uporządkowanej oraz wielostanowej. W modelu regresji binarnej wpływa na otrzymane oceny parametrów, ale nie wpływa na wartość ilorazu szans.

22
Różnice w kodowaniu zmiennych objaśniających
Zmienne jakościowe z dwoma poziomami mogą być kodowane na trzy sposoby, np. (0,1); (1,2) lub (kobieta mężczyzna). Tylko pierwszy sposób kodowania umożliwia dowolny sposób wprowadzenia zmiennej do modelu, tzn. zmienna taka może zostać wprowadzona do modelu zarówno jako zmienna ilościowa jak i jakościowa i nie ma to wpływu na wielkość oszacowań jeżeli dodatkowo w przypadku wprowadzenia takiej zmiennej jako zmiennej jako zmiennej jakościowej zaznaczy się opcję „odniesienie” zamiast „skutki” . Jeżeli zastosuje się opcję „skutki” wówczas oszacowania przy różnych sposobach kodowania będą różńe. Pozostałe sposoby kodowania zmiennej z dwoma poziomami wymuszają wprowadzenie danej zmiennej jako zmiennej jakościowej (czyli powinny zostać dodane do modelu jako zmienne „klasyfikujące”). Zmienne jakościowe z więcej niż dwoma poziomami muszą niezależnie od sposobu kodowania być wprowadzone do modelu jako zmienne „klasyfikujące”. Do sposobów kodowania i różnic z nich wynikających wrócimy jeszcze przy modelu z 4 zmiennymi. Z punktu widzenia analizy istotny jest sposób kodowania zmiennych jakościowych. Zmienne mogą, w zależności od liczby kategorii, być kodowane w sposób nominalny (np. binarny-0,1; poprzez przyporządkowanie liczby danej kategorii) lub też w sposób jakościowy, poprzez przypisanie poszczególnym poziomom zmiennej nazwy znakowej (np. kobieta, mężczyzna). Forma kodowania narzuca określony sposób włączenia jej do modelu.
; (1,2) lub (kobieta mężczyzna). Tylko pierwszy sposób kodowania umożliwia dowolny sposób wprowadzenia zmiennej do modelu, tzn. zmienna taka może zostać wprowadzona do modelu zarówno jako zmienna ilościowa jak i jakościowa i nie ma to wpływu na wielkość oszacowań jeżeli dodatkowo w przypadku wprowadzenia takiej zmiennej jako zmiennej jako zmiennej jakościowej zaznaczy się opcję „odniesienie zamiast „skutki . Jeżeli zastosuje się opcję „skutki wówczas oszacowania przy różnych sposobach kodowania będą różńe. Pozostałe sposoby kodowania zmiennej z dwoma poziomami wymuszają wprowadzenie danej zmiennej jako zmiennej jakościowej (czyli powinny zostać dodane do modelu jako zmienne „klasyfikujące ). Zmienne jakościowe z więcej niż dwoma poziomami muszą niezależnie od sposobu kodowania być wprowadzone do modelu jako zmienne „klasyfikujące . Do sposobów kodowania i różnic z nich wynikających wrócimy jeszcze przy modelu z 4 zmiennymi. Z punktu widzenia analizy istotny jest sposób kodowania zmiennych jakościowych. Zmienne mogą, w zależności od liczby kategorii, być kodowane w sposób nominalny (np. binarny-0,1; poprzez przyporządkowanie liczby danej kategorii) lub też w sposób jakościowy, poprzez przypisanie poszczególnym poziomom zmiennej nazwy znakowej (np. kobieta, mężczyzna). Forma kodowania narzuca określony sposób włączenia jej do modelu.")
23
Ponieważ nie zajmujemy się analiza interakcji ani też modelowanie regresji innej niż podstawowa regresji binarna, należy przy każdej zmiennej zaznaczyć, że interesują nas wyłącznie efekty główne danej zmiennej.

24
Zakładka „Opcje” umożliwia wyświetlenie dodatkowych statystyk dla szacowanego modelu. Celem porównania w dalszej części prezentacji różnych modeli poproszę o zaznaczenie odpowiednich opcji.

25
Podstawowe informacje o Modelu
Model Information Data Set WORK.SORTTEMPTABLESORTED Response Variable nadwaga Number of Response Levels 2 Model binary logit Optimization Technique Fisher's scoring Podstawowe informacje o modelu pozwalają dowiedzieć się czy model, który został wyspecyfikowany jest takim o jaki chodziło. Czym jest iteracyjne kryterium zbieżności oraz do czego służy w odniesieniu do funkcji wiarygodności. Dlaczego spełnienie tego kryterium jest niezbędne do dalszej analizy. Number of Observations Read 943 Number of Observations Used Response Profile Ordered Value nadwaga Total Frequency 1 467 2 brak nadwagi 476 Model Convergence Status Convergence criterion (GCONV=1E-8) satisfied. Spełnione zostało iteracyjne kryterium zbieżności, udało się wyznaczyć parametry największej wiarygodności. Probability modeled is nadwaga='nadwaga'.
 satisfied. Spełnione zostało iteracyjne kryterium zbieżności, udało się wyznaczyć parametry największej wiarygodności. Probability modeled is nadwaga= nadwaga .")
26
Analysis of Maximum Likelihood Estimates
Mając oszacowany model możemy obliczać prawdopodobieństwa teoretyczne dla wybranej osoby. Według innej interpretacji są to wartości średnie zmiennej Y , czyli udziały osób z nadwagą w grupie osób reprezentowanych przez określony układ zmiennych objaśniających. Probability modeled is nadwaga='nadwaga'. nadwaga (należy opuścić czynniki, dla których zmienna objaśniająca wynosi 0, pozostałe uzupełnić zgodnie z wartością zmiennej- w tym dychotomicznej) Analysis of Maximum Likelihood Estimates Parameter DF Estimate Standard Error Wald Chi-Square Pr > ChiSq Intercept 1 0.2629 <.0001 fastfood 5.1635 0.2926 W analizowanym przykładzie modelu z jedną zmienną objaśniającą formalny zapis przedstawia się następująco!
 Analysis of Maximum Likelihood Estimates. Parameter. DF. Estimate. Standard Error. Wald Chi-Square. Pr > ChiSq. Intercept < fastfood W analizowanym przykładzie modelu z jedną zmienną objaśniającą formalny zapis przedstawia się następująco!")
27
Przykład modelu logistycznego- interpretacja
je fastfoody Z=-1,865 nie je fastfoodów Z=-3,2983 Oznacza to, że 86,6% osób o wymienionych cechach ma nadwagę, inaczej mówiąc jeżeli je się fastfoody to prawdopodobieństwo, że będzie się miało nadwagę wynosi 0,866. Dla osób o tych samych cechach, ale nie jedzących fastfoodów P=0,036. Fakt, że prawdopodobieństwa się nie dopełniają do jedności wynika to z nieliniowości związku. Dopisek ‘dla osób o tych samych cechach’ lub też ‘przy pozostałych zmiennych ustalonych’ odnosi się do modelu o większej liczbie zmiennych objaśniajacych (poziom ustalony to poziom referencyjny danej zmiennej objaśniającej, np. 1 lub Kobieta).
.")
28
Testowanie hipotez dotyczących współczynników (istotność zmiennej Xj)
Analysis of Maximum Likelihood Estimates Parameter DF Estimate Standard Error Wald Chi-Square Pr > ChiSq Intercept 1 0.2629 <.0001 fastfood 5.1635 0.2926 W kolumnach są wyświetlane współczynniki regresji oraz ich błędy szacunku. Zmienna jest istotna w modelu, jeżeli wartość błędu szacunku jest dostatecznie mała w porównaniu z wartością współczynnika regresji. Do pomiaru tej istotności służy statystyka Walda, podana w kolumnie zatytułowanej Chi-Kwadrat Walda. Statystyka Walda ma rozkład χ2 z liczbą stopni swobody o 1 mniejszą niż liczba kategorii. Dla zmiennych numerycznych (jak wiek) liczba stopni swobody wynosi zawsze 1. Również dla zmiennych zerojedynkowych liczba stopni swobody wynosi 1. Liczba stopni swobody jest zamieszczona w kolumnie zatytułowanej st.sw.(df).
 liczba stopni swobody wynosi zawsze 1. Również dla zmiennych zerojedynkowych liczba stopni swobody wynosi 1. Liczba stopni swobody jest zamieszczona w kolumnie zatytułowanej st.sw.(df).")
29
Testowanie hipotez dotyczących współczynników (istotność zmiennej Xj)
Jeżeli mamy df=1, to wartość statystyki Walda obliczamy ze wzoru: Testowane Hipotezy: H0: parametr jest równy zero H1: parametr jest różny od zera Analysis of Maximum Likelihood Estimates Parameter DF Estimate Standard Error Wald Chi-Square Pr > ChiSq Intercept 1 0.2629 <.0001 fastfood 5.1635 0.2926 dla zmiennej fastfood mamy Prawdopodobieństwo testowe dla statystyki Walda jest wyświetlane w kolumnie Pr>ChiKw. Należy je porównywać z przyjętym poziomem istotności (np.0,05). Jeżeli Pr ChiKw < 0,05, to odpowiednia zmienna jest istotna na poziomie 0,05. W modelu statystycznie istotne na poziomie 0,05 są jedynie zmienne komputer i fastfood oraz stała (Pr ChiKw< 0,05).
. Jeżeli Pr ChiKw < 0,05, to odpowiednia zmienna jest istotna na poziomie 0,05. W modelu statystycznie istotne na poziomie 0,05 są jedynie zmienne komputer i fastfood oraz stała (Pr ChiKw< 0,05).")
30
Logit Zapiszmy równanie logistyczne w postaci: albo : gdzie A’ jest zdarzeniem przeciwnym do A. Wyrażenie znajdujące się po lewej stronie równania nazywamy logitem. Problem w tym, że logit jest czymś innym niż prawdopodobieństwo i jest trudny do interpretacji. Łatwiej rozważać wyrażenie: Wyrażenie to będące stosunkiem prawdopodobieństwa wystąpienia zdarzenia A do prawdopodobieństwa niewystąpienia zdarzenia A nazywamy szansą (ryzykiem względnym)- odds
- odds.")
31
Ryzyko względne Jeżeli prawdopodobieństwo zdarzenia A wynosi ½. (jak np. wyrzucenia orła w rzucie monetą), to ryzyko względne wynosi 1 Jeżeli P(A) = 0,9 to Teraz znaczenie współczynników regresji jest następujące. Wartość mówi, ile razy wzrośnie wartość ryzyka względnego, jeżeli wartość j-tej zmiennej objaśniającej wzrośnie o jednostkę. Jeżeli , to
 = 0,9 to. Teraz znaczenie współczynników regresji jest następujące. Wartość mówi, ile razy wzrośnie wartość ryzyka względnego, jeżeli wartość j-tej zmiennej objaśniającej wzrośnie o jednostkę. Jeżeli. , to.")
32
Interpretacja parametrów
Analysis of Maximum Likelihood Estimates Parameter DF Estimate Standard Error Wald Chi-Square Pr > ChiSq Intercept 1 0.2629 <.0001 fastfood 5.1635 0.2926 Odds Ratio Estimates Effect Point Estimate 95% Wald Confidence Limits fastfood 98.488 Interpretujemy pozostałe parametry Stała = -3, exp(stała) = 0, Gdy wszystkie inne zmienne przyjmują wartość zero, iloraz szans bycia otyłym do nie bycia otyłym wynosi 3,4% fastfood = 5,1635 exp = 174,769 Przy ustalonych wartościach pozostałych zmiennych, osoby jedzące często fastfoody mają 175 razy wyższe szanse bycia w otyłym, niż pozostali (nie jedzący fastfoodów). Uwaga! Jeżeli do modelu weszłaby zmienna ciągłą wówczas exp(β) interpretuje się jako przyrost/spadek prawdopodobieństwa bycia otyłym przy wzroście danej cechy o jednostkę (np. przy ustalonych, pozostałych wartościach zmiennych, wzrost dochodów o jednostkę 100 zł, zwiększa szansę bycia otyłym o 1%).
 = 0, Gdy wszystkie inne zmienne przyjmują wartość zero, iloraz szans bycia otyłym do nie bycia otyłym wynosi 3,4% fastfood = 5,1635 exp = 174,769 Przy ustalonych wartościach pozostałych zmiennych, osoby jedzące często fastfoody mają 175 razy wyższe szanse bycia w otyłym, niż pozostali (nie jedzący fastfoodów). Uwaga! Jeżeli do modelu weszłaby zmienna ciągłą wówczas exp(β) interpretuje się jako przyrost/spadek prawdopodobieństwa bycia otyłym przy wzroście danej cechy o jednostkę (np. przy ustalonych, pozostałych wartościach zmiennych, wzrost dochodów o jednostkę 100 zł, zwiększa szansę bycia otyłym o 1%).")
33
Przedziały ufności Przedziały ufności dla ilorazów szans [exp(B)]
na poziomie ufności (domyślnie jest 95%)- domyślnie α=0,05. Zmienna jest istotna na danym poziomie α, jeżeli przedział ufności dla exp(β) z współczynnikiem 1-α nie zawiera liczby 1. W modelu otrzymaliśmy 95% przedział ufności dla zmiennych: Odds Ratio Estimates Effect Point Estimate 95% Wald Confidence Limits fastfood 98.488 Zatem zmienna fastfood jest istotna statystycznie
![Przedziały ufności Przedziały ufności dla ilorazów szans [exp(B)]](http://slideplayer.pl/slide/3024710/11/images/33/Przedzia%C5%82y+ufno%C5%9Bci+Przedzia%C5%82y+ufno%C5%9Bci+dla+iloraz%C3%B3w+szans+%5Bexp%28B%29%5D.jpg "na poziomie ufności (domyślnie jest 95%)- domyślnie α=0,05. Zmienna jest istotna na danym poziomie α, jeżeli przedział ufności dla exp(β) z współczynnikiem 1-α nie zawiera liczby 1. W modelu otrzymaliśmy 95% przedział ufności dla zmiennych: Odds Ratio Estimates. Effect. Point Estimate. 95% Wald Confidence Limits. fastfood Zatem zmienna fastfood jest istotna statystycznie.")
34
Przedziały ufności Oceny ilorazu szans Efekt Ocena punktowa
95% granice przedziału ufności Walda dochod 1.000 wydatki syt_mat 0.863 0.637 1.170 komputer 2.011 1.161 3.485 plec 1.125 0.679 1.865 stan_cywilny 1.043 0.691 1.574 wiek 0.999 0.982 1.015 wyd_zyw 0.998 fastfood Przedział ufności Walda dla parametrów Parametr Ocena 95% granice przedziału ufności Intercept dochod wydatki syt_mat 0.1570 komputer 0.6988 0.1490 1.2486 plec 0.1178 0.6233 stan_cywilny 0.0421 0.4536 wiek 0.0149 wyd_zyw fastfood 5.3705 4.6267 6.1143 Przedział ufności Walda dla skorygowanych ilorazów szans Efekt Jednostka Ocena 95% granice przedziału ufności dochod 1000.0 0.918 0.746 1.129 wydatki 1.127 0.861 1.476 wyd_zyw 100.0 0.935 0.835 1.047

35
Model z 4 zmiennymi objaśniającymi
Różnice w kodowaniu zmiennych- wersja nieprawidłowa! O sposobach kodowania zmiennych mowa była już wcześniej, jednak różnice uwidaczniają się dopiero, gdy do modelu wprowadzone zostaną dodatkowe zmienne jakościowe posiadające więcej niż dwa poziomy. Jeżeli zmienna zostanie zakodowana jak zmienna ilościowa (poszczególnym poziomom zostaną przyporządkowane cyfry, wówczas program traktuje wartości poszczególnych poziomów jako różnice w odległości pomiędzy nimi, a oszacowane parametry modelu są dopasowane tak by można było podstawić wartość liczbową i uzyskać miarę wpływu danego poziomu na prawdopodobieństwo, zatem odzwierciedlają dystans pomiędzy poszczególnymi poziomami. Tymczasem zmienna jakościowa nie wyraża z założenia dystansu a jedynie inne kategorie jakie może ona przyjmować. Zdefiniowanie zatem takiej zmiennej jako zmiennej ilościowej jest błędne! W takim przypadku należy zdefiniować zmienną jako zmienną jakościową, przy czym są dwa sposoby zdefiniowania takiej zmiennej. Sposób kodowania zmiennej jakościowej nie wpływa w tym ujęciu na interpretowane wartości odds ratio, a jedynie na wartości ocen parametrów.

36
Model z 4 zmiennymi objaśniającymi
Różnice w kodowaniu zmiennych- wersja 1 Wersja obowiązująca na ćwiczeniach, interpretowana poniżej

37
Różnice w kodowaniu zmiennych- wersja 2

38
KODOWANIE Odniesienie Skutki
Informacje o poziomie klasyfikacji Klasa Wartość Zmienne planowania sex Kobieta 1 Mezczyz syt_materialna bardzo dobra przeciętna raczej dobra raczej zła zła fast często rzadko lub prawie nigdy komp brak komputera komputer Informacje o poziomie klasyfikacji Klasa Wartość Zmienne planowania sex Kobieta 1 Mezczyz -1 komp brak komputera komputer syt_materialna bardzo dobra przeciętna raczej dobra raczej zła zła fast często rzadko lub prawie nigdy W SASie dostępne są dwa rodzaje kodowania: „skutki” oraz „odniesienie”, które różnią się sposobem zapisu zmiennych. Pierwszy sposób sprowadza się do tego, że zmienna jakościowa z (w naszym przypadku) zostaje rozpisana na 5 zmiennych binarnych, przy czym z uwagi na występowanie współliniowości do modelu zostają wprowadzone jedynie 4 zmienne. Wskaźnikowy (indicator) porównywane są efekty należenia i nie należenia do danej kategorii. Jedna z kategorii jest kategorią referencyjną. W macierzy kontrastów odpowiada jej wiersz złożony z samych zer (odniesienie) Odchylenia (deviation) efekt dla każdej kategorii zmiennej objaśniającej jest porównywany z całkowitym efektem tej zmiennej. Dla jednej kategorii współczynnik regresji nie jest wyświetlany w tablicy wyników i musimy go samodzielnie obliczyć poza programem (współczynniki wszystkich kategorii sumują się do zera, więc jest to suma wyświetlanych współczynników ze zmienionym znakiem). Ta wybrana kategoria nazywana jest w dalszym ciągu kategorią referencyjną, ale tutaj już nie należy do niej odnosić porównań (skutki) Sposób kodowania nie ma wpływu na istotność tej zmiennej taktowanej jako całość, ale ma wpływ na wartości stałej regresji i współczynników regresji poszczególnych kategorii danej zmiennej, a zatem na interpretację modelu.
 zostaje rozpisana na 5 zmiennych binarnych, przy czym z uwagi na występowanie współliniowości do modelu zostają wprowadzone jedynie 4 zmienne. Wskaźnikowy (indicator) porównywane są efekty należenia i nie należenia do danej kategorii. Jedna z kategorii jest kategorią referencyjną. W macierzy kontrastów odpowiada jej wiersz złożony z samych zer (odniesienie) Odchylenia (deviation) efekt dla każdej kategorii zmiennej objaśniającej jest porównywany z całkowitym efektem tej zmiennej. Dla jednej kategorii współczynnik regresji nie jest wyświetlany w tablicy wyników i musimy go samodzielnie obliczyć poza programem (współczynniki wszystkich kategorii sumują się do zera, więc jest to suma wyświetlanych współczynników ze zmienionym znakiem). Ta wybrana kategoria nazywana jest w dalszym ciągu kategorią referencyjną, ale tutaj już nie należy do niej odnosić porównań (skutki) Sposób kodowania nie ma wpływu na istotność tej zmiennej taktowanej jako całość, ale ma wpływ na wartości stałej regresji i współczynników regresji poszczególnych kategorii danej zmiennej, a zatem na interpretację modelu.")
39
Analiza ocen maksymalnej wiarygodności
Kodowanie ODNIESIENIE Porównywane są efekty należenia i nie należenia do danej kategorii. Jedna z kategorii jest kategorią referencyjną. W macierzy kontrastów odpowiada jej wiersz złożony z samych zer. Interpretacja oszacowań powinna być taka, że modelowane prawdopodobieństwo wzrośnie lub spadnie, jeżeli dana jednostka wykazuję przynależność do jednej z grup względem kategorii referencyjne (pamiętając, że tylko w jednym przypadku może wystąpić jedynka, bowiem dana osoba musiała wskazać jedną z kategorii). Analiza ocen maksymalnej wiarygodności Parametr St. sw. Ocena Błąd standardowy Chi-kwadrat Walda Pr > chi kw.. Intercept 1 0.5085 <.0001 fast często 5.1402 0.3031 komp brak komputera 0.2613 6.9162 0.0085 sex Kobieta 0.1461 0.2521 0.3358 0.5623 syt_materialna bardzo dobra 1.1627 0.4367 0.5087 przeciętna 0.6354 0.3840 2.7386 0.0980 raczej dobra 0.4288 0.4746 0.8161 0.3663 raczej zła 0.4511 0.4336 1.0823 0.2982
. Analiza ocen maksymalnej wiarygodności. Parametr. St. sw. Ocena. Błąd standardowy. Chi-kwadrat Walda. Pr > chi kw.. Intercept < fast. często komp. brak komputera sex. Kobieta syt_materialna. bardzo dobra przeciętna raczej dobra raczej zła")
40
Analiza ocen maksymalnej wiarygodności
Kodowanie SKUTKI Wszystkie współczynniki dla kategorii syt_materialna nieistotnie różnią się od średniej. Współczynnik dla sytuacji bardzo dobrej (-0,9178) jest niższy od średniej, współczynniki dla sytuacji przeciętnej, raczej dobrej i raczej złej są wyższe od średniej. Ponieważ w tej metodzie kodowania suma współczynników dla wszystkich kategorii wynosi 0, więc wartość dla sytuacji materialnej bardzo złej (kategoria referencyjna) obliczymy jako -(-0,9178+0,4861+0,2794+0,3017) = -0,1494 Analiza ocen maksymalnej wiarygodności Parametr St. sw. Ocena Błąd standardowy Chi-kwadrat Walda Pr > chi kw.. Intercept 1 0.2656 0.0006 fast często 2.5701 0.1516 <.0001 komp brak komputera 0.1307 6.9162 0.0085 sex Kobieta 0.0731 0.1261 0.3358 0.5623 syt_materialna bardzo dobra 0.8890 1.0656 0.3019 przeciętna 0.4861 0.2750 3.1250 0.0771 raczej dobra 0.2794 0.3462 0.6511 0.4197 raczej zła 0.3017 0.3205 0.8863 0.3465
 jest niższy od średniej, współczynniki dla sytuacji przeciętnej, raczej dobrej i raczej złej są wyższe od średniej. Ponieważ w tej metodzie kodowania suma współczynników dla wszystkich kategorii wynosi 0, więc wartość dla sytuacji materialnej bardzo złej (kategoria referencyjna) obliczymy jako. -(-0,9178+0,4861+0,2794+0,3017) = -0,1494. Analiza ocen maksymalnej wiarygodności. Parametr. St. sw. Ocena. Błąd standardowy. Chi-kwadrat Walda. Pr > chi kw.. Intercept fast. często < komp. brak komputera sex. Kobieta syt_materialna. bardzo dobra przeciętna raczej dobra raczej zła")
44
Testowanie hipotez dotyczących współczynników (istotność zmiennej Xj)
Programy komputerowe podają prawdopodobieństwo testowe (p-value). Jest to największa wartość poziomu istotności α, przy której nie odrzucamy hipotezy zerowej H0:βj = 0 (wszystkie parametry są równe zero). Np. gdyby p-value=0,032, to na poziomie istotności α = 0,05 odrzucamy hipotezę zerową, natomiast na poziomie α = 0,02 nie ma podstaw do odrzucenia hipotezy zerowej. Ogólnie rzecz biorąc, odrzucamy hipotezę zerową, gdy p-value przyjmuje dostatecznie małą wartość. Ogólnie, w modelu jest przynajmniej jeden parametr istotnie różniący się od zera. Testowanie globalnej hipotezy zerowej: BETA=0 Test Chi-kwadrat St. sw. Pr > chi kw.. Iloraz wiarygodn 7 <.0001 Ocena Wald Ponadto testować również można łączną hipotezę o statystycznej istotności wyestymowanych parametrów modelu. Testowana jest hipoteza zerowa, mówiąca o tym, że wektor parametrów beta jest równy zero (bety są nieistotne statystycznie). Wyniki testów sugerują odrzucenie hipotezy zerowej na korzyść alternatywnej, czyli przynajmniej jeden ze współczynników modelu jest istotnie różny od zera.
. Jest to największa wartość poziomu istotności α, przy której nie odrzucamy hipotezy zerowej H0:βj = 0 (wszystkie parametry są równe zero). Np. gdyby p-value=0,032, to na poziomie istotności α = 0,05 odrzucamy hipotezę zerową, natomiast na poziomie α = 0,02 nie ma podstaw do odrzucenia hipotezy zerowej. Ogólnie rzecz biorąc, odrzucamy hipotezę zerową, gdy p-value przyjmuje dostatecznie małą wartość. Ogólnie, w modelu jest przynajmniej jeden parametr istotnie różniący się od zera. Testowanie globalnej hipotezy zerowej: BETA=0. Test. Chi-kwadrat. St. sw. Pr > chi kw.. Iloraz wiarygodn < Ocena Wald Ponadto testować również można łączną hipotezę o statystycznej istotności wyestymowanych parametrów modelu. Testowana jest hipoteza zerowa, mówiąca o tym, że wektor parametrów beta jest równy zero (bety są nieistotne statystycznie). Wyniki testów sugerują odrzucenie hipotezy zerowej na korzyść alternatywnej, czyli przynajmniej jeden ze współczynników modelu jest istotnie różny od zera.")
45
Ocena oszacowań modelu z 4 zmiennymi
Ogólnie, w modelu jest przynajmniej jeden parametr istotnie różniący się od zera. Analiza ocen maksymalnej wiarygodności Parametr St. sw. Ocena Błąd standardowy Chi-kwadrat Walda Pr > chi kw.. Intercept 1 0.5085 <.0001 fast często 5.1402 0.3031 komp brak komputera 0.2613 6.9162 0.0085 sex Kobieta 0.1461 0.2521 0.3358 0.5623 syt_materialna bardzo dobra 1.1627 0.4367 0.5087 przeciętna 0.6354 0.3840 2.7386 0.0980 raczej dobra 0.4288 0.4746 0.8161 0.3663 raczej zła 0.4511 0.4336 1.0823 0.2982 ALE: interesuje nas, który z parametrów zmiennych w modelu jest istotny, czy istotne ponadto są inne zmienne niż w modelu z jedną zmienną oraz czy w nowym modelu zmienna, która była istotna poprzednio nadal jest istotna. TEST WALDa: Testowana jest hipoteza zerowa o braku istotności poszczególnych zmiennych w modelu na domyślnym poziomie istotności alpha 0,05 W przypadku zmiennych fastfood i komputer brak należy odrzucić hipotezę zerową na korzyść hipotezy alternatywnej. Decyzja : oszacowane parametry zmienny komputer i fastfood statystycznie istotnie różnią się od od zera i pozostają w modelu, pozostałe parametry należy uznać za nieistotnie różne od zera (brak podstaw do odrzucenia hipotezy zerowej)
")
46
Przykład modelu logistycznego
Jeżeli oszacuje się model z dwiema zmiennymi, wówczas: Analiza ocen maksymalnej wiarygodności Parametr St. sw. Ocena Błąd standardowy Chi-kwadrat Walda Pr > chi kw.. Intercept 1 0.3135 <.0001 fast często 5.1061 0.2936 komp brak komputera 0.2539 7.5551 0.0060 Uwagę należy zwrócić na sposób kodowania (na kategorię referencyjną) oraz odpowiednia interpretację. Posiada komputer oraz nie je fastfoodów Posiada komputer oraz je fastfoody Z=2,8203 Z=-2,2858 Oznacza to, że 94% osób o wymienionych cechach ma nadwagę. Dla osób o tych samych cechach, ale nie jedzących fastfoodów P=0,09. Jeżeli powyższe obliczenia wykonamy dla osób jedzących i nie jedzących fastfoody i nie mających komputerów wówczas prawdopodobieństwa wyniosą odpowiednio 89,3 oraz 4,8. Wynika to z nieliniowości związku.
 oraz odpowiednia interpretację. Posiada komputer oraz nie je fastfoodów. Posiada komputer oraz je fastfoody. Z=2,8203. Z=-2,2858. Oznacza to, że 94% osób o wymienionych cechach ma nadwagę. Dla osób o tych samych cechach, ale nie jedzących fastfoodów P=0,09. Jeżeli powyższe obliczenia wykonamy dla osób jedzących i nie jedzących fastfoody i nie mających komputerów wówczas prawdopodobieństwa wyniosą odpowiednio 89,3 oraz 4,8. Wynika to z nieliniowości związku.")
47
Interpretacja parametrów
Oceny ilorazu szans Efekt Ocena punktowa 95% granice przedziału ufności Walda fast często vs rzadko lub prawie nigdy 92.823 komp brak komputera vs komputer 0.498 0.303 0.819 Stała = -2, exp(stała) = 0,06168 Gdy wszystkie inne zmienne przyjmują wartość zero, iloraz szans (sznasa, ryzyko) bycia otyłym do nie bycia otyłym wynosi 5% Komputer = -0,6979 exp = 0, Przy ustalonych wartościach pozostałych zmiennych, osoby nie posiadające komputera mają dwa razy mniejsze szanse bycia otyłym, niż osoby posiadając komputer. fastfood = 5,37 exp = 165,029 Przy ustalonych wartościach pozostałych zmiennych, osoby jedzące często fastfoody mają o niemal 165 razy wyższe szanse bycia w otyłym, niż jedzący rzadko. Interpretujemy pozostałe parametry UWAGA na interpretację! Uwaga! Jeżeli do modelu weszłaby zmienna ciągłą wówczas exp(β) interpretuje się jako przyrost/spadek prawdopodobieństwa bycia otyłym przy wzroście danej cechy o jednostkę (np. przy ustalonych, pozostałych wartościach zmiennych, wzrost dochodów o jednostkę 100 zł, zwiększa szansę bycia otyłym o 1%).
 = 0,06168 Gdy wszystkie inne zmienne przyjmują wartość zero, iloraz szans (sznasa, ryzyko) bycia otyłym do nie bycia otyłym wynosi 5% Komputer = -0,6979 exp = 0,498 Przy ustalonych wartościach pozostałych zmiennych, osoby nie posiadające komputera mają dwa razy mniejsze szanse bycia otyłym, niż osoby posiadając komputer. fastfood = 5,37 exp = 165,029 Przy ustalonych wartościach pozostałych zmiennych, osoby jedzące często fastfoody mają o niemal 165 razy wyższe szanse bycia w otyłym, niż jedzący rzadko. Interpretujemy pozostałe parametry. UWAGA na interpretację! Uwaga! Jeżeli do modelu weszłaby zmienna ciągłą wówczas exp(β) interpretuje się jako przyrost/spadek prawdopodobieństwa bycia otyłym przy wzroście danej cechy o jednostkę (np. przy ustalonych, pozostałych wartościach zmiennych, wzrost dochodów o jednostkę 100 zł, zwiększa szansę bycia otyłym o 1%).")
48
ZADANIA dla studentów Zbiór arthrit zawiera 4 zmienne: better, sex, age oraz treat Proszę zbadać zależność poprawy stanu zdrowia (better) od sposobu leczenia (treat-jakościowej), ocenić istotność parametru oraz zinterpretować otrzymane wyniki oraz ilorazy szans Proszę zbadać zależność poprawy stanu zdrowia od pozostałych zmiennych, ocenić istotność parametru oraz zinterpretować otrzymane wyniki oraz ilorazy szans
 od sposobu leczenia (treat-jakościowej), ocenić istotność parametru oraz zinterpretować otrzymane wyniki oraz ilorazy szans. Proszę zbadać zależność poprawy stanu zdrowia od pozostałych zmiennych, ocenić istotność parametru oraz zinterpretować otrzymane wyniki oraz ilorazy szans.")
49
Projekt 1 Proszę opracować, na podstawie onlinedoc SAS, procedury służące do estymacji modeli binarnej regresji logistycznej Szczegółowo pisać należy instrukcje i opcje dla proc logistic Proszę opracować interpretację do drugiego sposobu kodowania zmiennych jakościowych (skutki)
")
50
Regresja logistyczna - model binarny cz. I

51
Omówienie procedury proc logistic
Dobór zmiennych do modelu Oszacowanie dobroci modelu Ocena jakości modelu

52
Przykład modelu logistycznego
Nazwa zmiennej Opis zmiennej Wartości/kody Nadwaga Zmienna binarna informująca o nadwadze 1=nadwaga, 0=brak nadwagi Dochod Dochod respondenta Od do 19 000 dolarów Wydatki Wydatki miesięczne respondenta Od 184 do 16 456 dolarów K_miej Kategoria miejsca zamieszkania 1=mała wieś; 2=wieś, 3=małe miasto, 4=średnie miasto, 5=duże miasto, 6=metropolia Syt_mat Ocena sytuacji materialnej (subiektywna) 1=bardzo dobra, 2=raczej dobra,3=przeciętna, 4=raczej zła, 5=zła Stan_cywilny Stan cywilny klienta 1=kawaler, panna 2=żonaty, mężatka 3=wdowiec, wdowa 4=rozwiedziony(a) separowany(a) Komputer Zmienna binarna informująca czy osoba posiada komputer (wykonuje pracę siedzącą) 1 = posiada komputer, 0 – nie posiada komputera Wiek Wiek (kalendarzowy) Plec Zmienna binarna określająca płeć respondenta 1= mężczyzna, 2=kobieta Wyd_zyw Wysokość wydatków przeznaczanych na produkty żywnościowe Fastfood Zmienna jakościowa opisująca jak często dany respondent je żywność z fastfoodów 1= często (przynajmniej raz w tygodniu, 0 = rzadko lub prawie nigdy (mniej niż 1 raz w tygodniu)
 1=bardzo dobra, 2=raczej dobra,3=przeciętna, 4=raczej zła, 5=zła. Stan_cywilny. Stan cywilny klienta. 1=kawaler, panna. 2=żonaty, mężatka. 3=wdowiec, wdowa. 4=rozwiedziony(a) separowany(a) Komputer. Zmienna binarna informująca czy osoba posiada komputer (wykonuje pracę siedzącą) 1 = posiada komputer, 0 – nie posiada komputera. Wiek. Wiek (kalendarzowy) Plec. Zmienna binarna określająca płeć respondenta. 1= mężczyzna, 2=kobieta. Wyd_zyw. Wysokość wydatków przeznaczanych na produkty żywnościowe. Fastfood. Zmienna jakościowa opisująca jak często dany respondent je żywność z fastfoodów. 1= często (przynajmniej raz w tygodniu, 0 = rzadko lub prawie nigdy (mniej niż 1 raz w tygodniu)")
53
proc logistic data = biblioteka.zbior; model y = x1 x2 x3; run;
proc logistic data=reglog.oty; class syt_materialna (param=ref) komputer (param=ref)plec (param=ref)stan_cywilny (param=ref) wiek (param=ref) fast; MODEL nadwaga(ref=first)= dochod wydatki wyd_zyw syt_mat komputer plec stan_cywilny wiek fastfood/ SELECTION=none /*stepwise*/ /* wybór metody selekcji zmiennych niezależnych do modelu, domyślnie sls i sle=0,05 */ CORRB /* korelacje cząstkowe */ RSQUARE /* r-kwadrat i skorygowane R-kwadrat */ LINK=LOGIT /* funkcja linkująca */ CLPARM=BOTH /* wyświetlenie przedziałów ufności dla parametrów */ CLODDS=BOTH /* wyświetlenie przedziałów ufności dla ilorazów szans */ ALPHA= /* poziom istotności */ OUTROC=WORK.EGOUTROC ROCEPS= /* zapisanie zbioru dla krzywej ROC */ aggregate scale=none lackfit; title 'Model binarny'; UNITS dochod=1000 wydatki=1000 wyd_zyw=100; /* przedziały jednostkowe dla zmiennych ciągłych*/ OUTPUT OUT=WORK.TEMP1456 PREDPROBS=INDIVIDUAL /* zbiór z wyliczonymi prawdopodobieństwami teoret.*/ PREDICTED=_predicted1 /* zmienna z wartościami teoretycznymi*/ RESCHI=_reschi1 RESDEV=_resdev1 /* dewiancja i Pearson Chi-Square*/ DIFCHISQ=_difchisq1 DIFDEV=_difdev1 DFBETAS=_dfbetas0-_dfbetas5 /*wartości DfBeta*/ H=_h1 C=_c1; /*wartości wpływu dla odległości Cook’a oraz pole pod krzywą ROC*/ RUN; /* zbiór wejściowy */ /* zdefiniowanie zmiennej zależnej i zmiennych niezależnych w modelu oraz kategorii referencyjnej */ LACKFIT performs two goodness-of-fit tests (a Pearson chi-square test and a log-likelihood ratio chi-square test) for the fitted model. To compute the test statistics, proper grouping of the observations into subpopulations is needed. You can use the AGGREGATE or AGGREGATE= option to this end. See the entry for the AGGREGATE and AGGREGATE= options under the MODEL statement. If neither AGGREGATE nor AGGREGATE= is specified. Note: This test is not appropriate if the data are very sparse, with only a few values at each set of the independent variable values. If the Pearson chi-square test statistic is significant, then the covariance estimates and standard error estimates are adjusted.See the section "Lack of Fit Tests" for a description of the tests. Note that the SCALE= scale enables you to specify the method for estimating the dispersion parameter. To correct for overdispersion or underdispersion, the covariance matrix is multiplied by the estimate of the dispersion parameter. Valid values for scale are as follows: D | DEVIANCE specifies that the dispersion parameter be estimated by the deviance divided by its degrees of freedom. P | PEARSON specifies that the dispersion parameter be estimated by the Pearson chi-square statistic divided by its degrees of freedom. This is set as the default. You can use the AGGREGATE= option to define the subpopulations for calculating the Pearson chi-square statistic and the deviance. The "Goodness-of-Fit " table includes the Pearson chi-square statistic, the deviance, their degrees of freedom, the ratio of each statistic divided by its degrees of freedom, and the corresponding p-value. INFLUENCE displays diagnostic measures for identifying influential observations in the case of a binary response model. It has no effect otherwise. For each observation, the INFLUENCE option displays the case number (which is the sequence number of the observation), the values of the explanatory variables included in the final model, and the regression diagnostic measures developed by Pregibon (1981). For a discussion of these diagnostic measures, see the "Regression Diagnostics" section. When a STRATA statement is specified, the diagnostics are computed following Storer and Crowley (1985); see the "Regression Diagnostic Details" section for details. IPLOTS produces an index plot for each regression diagnostic statistic. An index plot is a scatterplot with the regression diagnostic statistic represented on the y-axis and the case number on the x-axis. See Example 42.6 for an illustration. Results of the CTABLE option are shown in Output Each row of the "Classification Table" corresponds to a cutpoint applied to the predicted probabilities, which is given in the Prob Level column. The 2×2 frequency tables of observed and predicted responses are given by the next four columns. For example, with a cutpoint of 0.5, 4 events and 16 nonevents were classified correctly. On the other hand, 2 nonevents were incorrectly classified as events and 5 events were incorrectly classified as nonevents. For this cutpoint, the correct classification rate is 20/27 (=74.1%), which is given in the sixth column. Accuracy of the classification is summarized by the sensitivity, specificity, and false positive and negative rates, which are displayed in the last four columns. You can control the number of cutpoints used, and their values, by using the PPROB= option. /*zmiana dewiancji i statystyki Pearson Chi-square przy wykluczeniu jednostki*/
 komputer (param=ref)plec (param=ref)stan_cywilny (param=ref) wiek (param=ref) fast; MODEL nadwaga(ref=first)= dochod wydatki wyd_zyw. syt_mat komputer plec stan_cywilny wiek fastfood/ SELECTION=none /*stepwise*/ /* wybór metody selekcji zmiennych niezależnych do modelu, domyślnie sls i sle=0,05 */ CORRB /* korelacje cząstkowe */ RSQUARE /* r-kwadrat i skorygowane R-kwadrat */ LINK=LOGIT /* funkcja linkująca */ CLPARM=BOTH /* wyświetlenie przedziałów ufności dla parametrów */ CLODDS=BOTH /* wyświetlenie przedziałów ufności dla ilorazów szans */ ALPHA=0.05 /* poziom istotności */ OUTROC=WORK.EGOUTROC ROCEPS= /* zapisanie zbioru dla krzywej ROC */ aggregate scale=none lackfit; title Model binarny ; UNITS dochod=1000 wydatki=1000 wyd_zyw=100; /* przedziały jednostkowe dla zmiennych ciągłych*/ OUTPUT OUT=WORK.TEMP1456 PREDPROBS=INDIVIDUAL /* zbiór z wyliczonymi prawdopodobieństwami teoret.*/ PREDICTED=_predicted1 /* zmienna z wartościami teoretycznymi*/ RESCHI=_reschi1 RESDEV=_resdev1 /* dewiancja i Pearson Chi-Square*/ DIFCHISQ=_difchisq1 DIFDEV=_difdev1. DFBETAS=_dfbetas0-_dfbetas5 /*wartości DfBeta*/ H=_h1 C=_c1; /*wartości wpływu dla odległości Cook’a oraz pole pod krzywą ROC*/ RUN; /* zbiór wejściowy */ /* zdefiniowanie zmiennej zależnej i zmiennych niezależnych w modelu. oraz kategorii referencyjnej */ LACKFIT performs two goodness-of-fit tests (a Pearson chi-square test and a log-likelihood ratio chi-square test) for the fitted model. To compute the test statistics, proper grouping of the observations into subpopulations is needed. You can use the AGGREGATE or AGGREGATE= option to this end. See the entry for the AGGREGATE and AGGREGATE= options under the MODEL statement. If neither AGGREGATE nor AGGREGATE= is specified. Note: This test is not appropriate if the data are very sparse, with only a few values at each set of the independent variable values. If the Pearson chi-square test statistic is significant, then the covariance estimates and standard error estimates are adjusted.See the section Lack of Fit Tests for a description of the tests. Note that the. SCALE= scale enables you to specify the method for estimating the dispersion parameter. To correct for overdispersion or underdispersion, the covariance matrix is multiplied by the estimate of the dispersion parameter. Valid values for scale are as follows: D | DEVIANCE specifies that the dispersion parameter be estimated by the deviance divided by its degrees of freedom. P | PEARSON specifies that the dispersion parameter be estimated by the Pearson chi-square statistic divided by its degrees of freedom. This is set as the default. You can use the AGGREGATE= option to define the subpopulations for calculating the Pearson chi-square statistic and the deviance. The Goodness-of-Fit table includes the Pearson chi-square statistic, the deviance, their degrees of freedom, the ratio of each statistic divided by its degrees of freedom, and the corresponding p-value. INFLUENCE displays diagnostic measures for identifying influential observations in the case of a binary response model. It has no effect otherwise. For each observation, the INFLUENCE option displays the case number (which is the sequence number of the observation), the values of the explanatory variables included in the final model, and the regression diagnostic measures developed by Pregibon (1981). For a discussion of these diagnostic measures, see the Regression Diagnostics section. When a STRATA statement is specified, the diagnostics are computed following Storer and Crowley (1985); see the Regression Diagnostic Details section for details. IPLOTS produces an index plot for each regression diagnostic statistic. An index plot is a scatterplot with the regression diagnostic statistic represented on the y-axis and the case number on the x-axis. See Example 42.6 for an illustration. Results of the CTABLE option are shown in Output Each row of the Classification Table corresponds to a cutpoint applied to the predicted probabilities, which is given in the Prob Level column. The 2×2 frequency tables of observed and predicted responses are given by the next four columns. For example, with a cutpoint of 0.5, 4 events and 16 nonevents were classified correctly. On the other hand, 2 nonevents were incorrectly classified as events and 5 events were incorrectly classified as nonevents. For this cutpoint, the correct classification rate is 20/27 (=74.1%), which is given in the sixth column. Accuracy of the classification is summarized by the sensitivity, specificity, and false positive and negative rates, which are displayed in the last four columns. You can control the number of cutpoints used, and their values, by using the PPROB= option. /*zmiana dewiancji i statystyki Pearson Chi-square przy wykluczeniu jednostki*/")
54
Wskazanie zbioru danych, opcje ogólne
Przeprowadzenie analizy w podgrupach (zbiór musi być wcześniej posortowany) Wskazanie zmiennych jakościowych i określenie ich kodowania Przeprowadzenie testu liniowych ograniczeń, przy czym w testowanym równaniu nie może występować stała Dokładne testy istotności parametrów Wskazanie zmiennej określającej częstości obserwacji (dane pogrupowane) Określenie postaci modelu i opcji, np: wyliczenie dodatkowych miar Zapisanie pewnych informacji do zbioru SAS Obliczenie score (prawdopodobieństw) z gotowego modelu na nowych danych Przeprowadzenie stratyfikowanej regresji logistycznej Zadanie dla jakich zmian wartości zmiennych ciągłych mają być obliczone ilorazy szans Przeprowadzenie testów liniowych ograniczeń Wskazanie zmiennej zawierającej wagi obserwacji PROC LOGISTIC < options >; BY variables ; CLASS variable <(v-options)> <variable <(v-options)>... > < / v-options >; CONTRAST 'label' effect values <,... effect values>< /options >; EXACT < 'label' >< Intercept >< effects >< / options > ; FREQ variable ; MODEL events/trials = < effects > < / options >; MODEL variable < (variable_options) > = < effects > < / options >; OUTPUT < OUT=SAS-data-set > < keyword=name...keyword=name > / < option >; SCORE < options >; STRATA effects < / options >; < label: > TEST equation1 < , ... , < equationk >> < /option >; UNITS independent1 = list1 < ... independentk = listk > < /option > ; WEIGHT variable </ option >;
 Wskazanie zmiennych jakościowych i określenie ich kodowania. Przeprowadzenie testu liniowych ograniczeń, przy czym w testowanym równaniu nie może występować stała. Dokładne testy istotności parametrów. Wskazanie zmiennej określającej częstości obserwacji (dane pogrupowane) Określenie postaci modelu i opcji, np: wyliczenie dodatkowych miar. Zapisanie pewnych informacji do zbioru SAS. Obliczenie score (prawdopodobieństw) z gotowego modelu na nowych danych. Przeprowadzenie stratyfikowanej regresji logistycznej. Zadanie dla jakich zmian wartości zmiennych ciągłych mają być obliczone ilorazy szans. Przeprowadzenie testów liniowych ograniczeń. Wskazanie zmiennej zawierającej wagi obserwacji. PROC LOGISTIC < options >; BY variables ; CLASS variable <(v-options)> <variable <(v-options)>... > < / v-options >; CONTRAST label effect values <,... effect values>< /options >; EXACT < label >< Intercept >< effects >< / options > ; FREQ variable ; MODEL events/trials = < effects > < / options >; MODEL variable < (variable_options) > = < effects > < / options >; OUTPUT < OUT=SAS-data-set > < keyword=name...keyword=name > / < option >; SCORE < options >; STRATA effects < / options >; < label: > TEST equation1 < , ... , < equationk >> < /option >; UNITS independent1 = list1 < ... independentk = listk > < /option > ; WEIGHT variable </ option >;")
55
Dobór zmiennych objaśniających do modelu
Oprócz weryfikacji istotności oszacowań parametrów modelu istotny jest logiczny i uzasadniony dobór zmiennych objaśniających do modelu. Dobór zmiennych objaśniających do modelu: Korelacja- typowanie zmiennych wykazujących zależności, identyfikacja współliniowych zmiennych objaśniających Korelacja cząstkowa (szacunkowa)- wkład poszczególnych zmiennych niezależnych do pojemności informacyjnej modelu (relacje typu parametr a zmienna objaśniana oraz parametr-parametr) Selekcja- wybór zmiennych do modelu Kolejną kwestią jest analiza istotności interakcji pomiędzy zmiennymi i ich statystyczna istotność. Jeżeli mamy do dyspozycji mały zestaw zmiennych wówczas można ręcznie sprawdzić ich istotność i wkład do modelu, gdy zestaw zmiennych się poszerza, wówczas pomocne stają się automatyczne metody doboru zmiennych do modelu. Omówione zostaną trzy metody selekcji dostępne w SASie. Kwestia ustalenia poziomu istotności na wejściu i wyjściu z modelu oraz odgórnego wprowadzania zmiennych do modelu , bez weryfikacji ich podczas selekcji.
- wkład poszczególnych zmiennych niezależnych do pojemności informacyjnej modelu (relacje typu parametr a zmienna objaśniana oraz parametr-parametr) Selekcja- wybór zmiennych do modelu. Kolejną kwestią jest analiza istotności interakcji pomiędzy zmiennymi i ich statystyczna istotność. Jeżeli mamy do dyspozycji mały zestaw zmiennych wówczas można ręcznie sprawdzić ich istotność i wkład do modelu, gdy zestaw zmiennych się poszerza, wówczas pomocne stają się automatyczne metody doboru zmiennych do modelu. Omówione zostaną trzy metody selekcji dostępne w SASie. Kwestia ustalenia poziomu istotności na wejściu i wyjściu z modelu oraz odgórnego wprowadzania zmiennych do modelu , bez weryfikacji ich podczas selekcji.")
56
Metody selekcji zmiennych objaśniających
W przypadku małej liczby zmiennych objaśniających jesteśmy w stanie przeanalizować szczegółowo adekwatność modelu regresji zmiennej objaśnianej względem dowolnego podzbioru tych zmiennych. Duża liczba zmiennych objaśniających wymusza zastosowanie automatycznych metod doboru zmiennych objaśniających. Celem selekcji jest wybór „najlepszego” podzbioru zmiennych objaśniających. Selekcja umożliwia: - ograniczenie dużego zbioru potencjalnych zmiennych objaśniających (spośród grona modeli adekwatnie opisujących dane zjawisko, najlepszym modelem jest model najprostszy), - wyeliminowanie zmiennych, które jedynie hipotetycznie mogły mieć wpływ na obserwowane zjawisko, - zrozumienie istoty zależności pomiędzy zmienną objaśnianą a zmiennymi objaśniającymi, - duża liczba parametrów osłabia jakość estymatorów (powoduje dużą ich zmienność), - eliminacja współliniowości zmiennych objaśniających, współliniowość wpływa negatywnie na stabilność i możliwość interpretacji.
, - wyeliminowanie zmiennych, które jedynie hipotetycznie mogły mieć wpływ na obserwowane zjawisko, - zrozumienie istoty zależności pomiędzy zmienną objaśnianą a zmiennymi objaśniającymi, - duża liczba parametrów osłabia jakość estymatorów (powoduje dużą ich zmienność), - eliminacja współliniowości zmiennych objaśniających, współliniowość wpływa negatywnie na stabilność i możliwość interpretacji.")
57
Metody selekcji zmiennych objaśniających
Metody selekcji sekwencyjnej: metoda eliminacji (backward) Inicjuje się w modelu, w którym uwzględniono wszystkie potencjalnie interesujące nas zmienne (krok 1). Następnie, zakładając prawdziwość tego modelu, testuje się indywidualne hipotezy o istotności poszczególnych zmiennych i usuwa się tę zmienną, dla której p-value odpowiadającego testu t jest największym p-value przekraczającym ustalony poziom alpha (krok 2). Potem dopasowujemy mniejszy model z usuniętą zmienną i powracamy do kroku 2. Procedura zostaje przerwana, gdy w pewnym kroku wszystkie p-value są mniejsze od alpha. - metoda dołączania (forward) Startuje od momentu zawierającego tylko stałą (krok 1), następnie wybiera się tę spośród możliwych zmiennych, dla których p-value odpowiadającego mu testu t jest najmniejszą wartością p-value mniejszą od alpha (krok 2).Procedura zostaje przerwana, gdy żadnemu z potencjalnych kandydatów na włącznie do modelu nie odpowiada wartość mniejsza od alpha. metoda selekcji krokowej (stepwise) Na każdym kroku można odrzucić lub dodać zmienną.
 Inicjuje się w modelu, w którym uwzględniono wszystkie potencjalnie interesujące nas zmienne (krok 1). Następnie, zakładając prawdziwość tego modelu, testuje się indywidualne hipotezy o istotności poszczególnych zmiennych i usuwa się tę zmienną, dla której p-value odpowiadającego testu t jest największym p-value przekraczającym ustalony poziom alpha (krok 2). Potem dopasowujemy mniejszy model z usuniętą zmienną i powracamy do kroku 2. Procedura zostaje przerwana, gdy w pewnym kroku wszystkie p-value są mniejsze od alpha. - metoda dołączania (forward) Startuje od momentu zawierającego tylko stałą (krok 1), następnie wybiera się tę spośród możliwych zmiennych, dla których p-value odpowiadającego mu testu t jest najmniejszą wartością p-value mniejszą od alpha (krok 2).Procedura zostaje przerwana, gdy żadnemu z potencjalnych kandydatów na włącznie do modelu nie odpowiada wartość mniejsza od alpha. metoda selekcji krokowej (stepwise) Na każdym kroku można odrzucić lub dodać zmienną.")
58
Metody selekcji zmiennych objaśniających
Wadą automatycznej selekcji jest to, że pechowy wybór jednej zmiennej dokonany na pewnym etapie selekcji nie może być już później skorygowany. Szczególnie widoczne staje się to, gdy zastosowany zostanie wariant selekcji z ustaloną, wstępną liczbą zmiennych objaśniających (np. dobraną na podstawie wiedzy eksperckiej). Ponadto problematyczny jest również dobór odpowiedniego progu alpha (0,05-0,1 przy procedurze eliminacji; 0,1-0,2 przy procedurze dołączania), któremu nie można nadać jednoznacznej interpretacji. Związane jest to z tym, że testowanych jest wiele hipotez, których wyniki zależą od siebie.
. Ponadto problematyczny jest również dobór odpowiedniego progu alpha (0,05-0,1 przy procedurze eliminacji; 0,1-0,2 przy procedurze dołączania), któremu nie można nadać jednoznacznej interpretacji. Związane jest to z tym, że testowanych jest wiele hipotez, których wyniki zależą od siebie.")
59
Model z 9 zmiennymi objaśniającymi- selekcja

63
Kodowanie w modelu z 9 zmiennymi
Informacje o poziomie klasyfikacji Klasa Wartość Zmienne planowania komp brak komputera 1 komputer syt_materialna bardzo dobra przeciętna raczej dobra raczej zła zła stan_cyw kawaler, panna rozwiedziony(a wdowiec, wdowa zonaty, mezatk fast często rzadko lub prawie nigdy sex Kobieta Mezczyz

64
Model z 8 zmiennymi bez selekcji- ocena istotności
Analiza ocen maksymalnej wiarygodności Parametr St. sw. Ocena Błąd standardowy Chi-kwadrat Walda Pr > chi kw.. Intercept 1 0.6744 <.0001 dochod 0.4003 0.5269 wiek 0.2096 0.6471 wydatki 0.7403 0.3896 fast często 5.1342 0.3363 komp brak komputera 0.2815 5.1544 0.0232 sex Kobieta 0.1732 0.2706 0.4095 0.5222 stan_cyw kawaler, panna 0.1131 0.4542 0.0621 0.8033 rozwiedziony(a 0.7591 0.5548 1.8719 0.1713 wdowiec, wdowa 0.4942 2.9461 0.0861 syt_materialna bardzo dobra 1.3903 0.4975 0.4806 przeciętna 0.6777 0.3984 2.8940 0.0889 raczej dobra 0.4676 0.5090 0.8439 0.3583 raczej zła 0.4973 0.4384 1.2871 0.2566 Jak się ma istotność zmiennych do tego czy zostaną zakwalifikowane do modelu

65
Model z 8 zmiennymi bez selekcji- ocena istotności
Oceny ilorazu szans Efekt Ocena punktowa 95% granice przedziału ufności Walda dochod 1.000 wiek 1.004 0.987 1.022 wydatki fast często vs rzadko lub prawie nigdy 87.804 komp brak komputera vs komputer 0.528 0.304 0.916 sex Kobieta vs Mezczyz 1.189 0.700 2.021 stan_cyw kawaler, panna vs zonaty, mezatk 1.120 0.460 2.727 stan_cyw rozwiedziony(a vs zonaty, mezatk 2.136 0.720 6.338 stan_cyw wdowiec, wdowa vs zonaty, mezatk 0.428 0.163 1.128 syt_materialna bardzo dobra vs zła 0.375 0.025 5.722 syt_materialna przeciętna vs zła 1.969 0.902 4.299 syt_materialna raczej dobra vs zła 1.596 0.589 4.329 syt_materialna raczej zła vs zła 1.644 0.696 3.882

66
Przykład modelu logistycznego- 9 zmiennych po selekcji
Podsumowanie wyboru krokowego Krok Efekt St. sw. Liczba w Chi-kwadrat punktacji Chi-kwadrat Walda Pr > chi kw.. Etykieta zmiennej Wstawione Usunięte 1 fast <.0001 2 komp 7.7244 0.0054 No (additional) effects met the 0.05 significance level for entry into the model. Analiza ocen maksymalnej wiarygodności Parametr St. sw. Ocena Błąd standardowy Chi-kwadrat Walda Pr > chi kw.. Intercept 1 0.3135 <.0001 fast często 5.1061 0.2936 komp brak komputera 0.2539 7.5551 0.0060 Studenci proszeni są o samodzielna interpretację otrzymanych wyników. Interpretacja?
 effects met the 0.05 significance level for entry into the model. Analiza ocen maksymalnej wiarygodności. Parametr. St. sw. Ocena. Błąd standardowy. Chi-kwadrat Walda. Pr > chi kw.. Intercept < fast. często komp. brak komputera Studenci proszeni są o samodzielna interpretację otrzymanych wyników. Interpretacja")
67
Współczynnik korelacji cząstkowej
Wkład poszczególnych zmiennych objaśniających w modelu regresji logistycznej możemy ocenić na podstawie wartości współczynników korelacji cząstkowej tych zmiennych ze zmienną zależną. gdzie sign(bj) - znak współczynnika , dfj liczba stopni swobody dla j-tej zmiennej , L(0) funkcja wiarogodności modelu początkowego tj. modelu, w którym nie występują zmienne objaśniające, a jedynie stała) Jeżeli , to jest przyjmowane
 - znak współczynnika , dfj - liczba stopni swobody dla j-tej zmiennej , L(0) - funkcja wiarogodności modelu początkowego tj. modelu, w którym nie występują zmienne objaśniające, a jedynie stała) Jeżeli , to jest przyjmowane.")
68
Współczynnik korelacji cząstkowej
W naszym przykładzie mamy –2lnL(0) = 1307,19, więc dla zmiennej wiek a dla zmiennej plec
 = 1307,19, więc dla zmiennej wiek. a dla zmiennej plec.")
69
Oszacowanie dobroci modelu
Dotychczas tworzyliśmy różne modele regresji logistycznej. Mniejszą uwagę zwracaliśmy na to, czy są to dobre modele. Jak ocenić, czy model jest dobry? W regresji liniowej porównuje się wartości teoretyczne proponowane przez model z rzeczywistymi wartościami zmiennej objaśnianej w zbiorze danych i konstruuje się różne mierniki dobroci dopasowania modelu do danych np. współczynnik determinacji W modelach regresji, w tym w szczególnym przypadku regresji binarnej, sposobów oceny dobroci oszacowań modelu jest wiele. Poniżej omówione zostaną procedury weryfikacji modelu. Przedmiotem weryfikacji modelu jest sprawdzenie czy: Model jest dobrze dopasowany do danych (jak często się myli) Model ma dużą pojemność informacyjną, dobrze opisuje dane zjawisko
 Model ma dużą pojemność informacyjną, dobrze opisuje dane zjawisko.")
70
Miary dobroci dopasowania
Na pytanie czy warto szacować model z danym zestawem zmiennych podpowiedzi pośrednio udzielają testy istotności parametrów, ponieważ nieistotność parametru sugeruje, że nie wnosi on wiele do analizy. Nie dają one jednak odpowiedzi na pytanie czy dana zmienna jest bardzo mało ważna czy też jest całkowicie nieadekwatna dla tego rodzaju analizy. Z punktu widzenia analizy, jeżeli uda się oszacować kilka modeli z różną ilością zmiennych, które są istotne statystycznie, przydatna jest metoda wyboru modelu najlepszego. Warto sobie zadać pytanie który z modeli (z dużą liczbą zmiennych objaśniających [istotnych, nieistotnych], małą czy może wcale zmienne nie wnoszą żadnej istotnej informacji) jest lepszy.
 jest lepszy.")
71
Miary dobroci dopasowania
Statystyką przydatną do oceny dobroci dopasowania modelu jest wartość funkcji wiarogodności. W metodzie estymacji wybieraliśmy wartości b0,…,bk w ten sposób, żeby zmaksymalizować funkcję wiarogodności L. Tutaj jako miary stopnia dopasowania użyjemy statystyki -2lnL tj. minus 2 razy logarytm funkcji wiarogodności (-2 Log Likelihood). Jeżeli hipoteza zerowa mówiąca, że model idealnie pasuje do danych, jest prawdziwa, to statystyka -2lnL ma rozkład χ2 o n-k stopniach swobody. Jeżeli model idealnie pasuje do danych, to funkcji wiarogodności przyjmuje wartość 1 i wtedy -2lnL = 0. W praktyce otrzymujemy wartości L < 1 i wtedy -2lnL > 0. Zbyt duże wartości funkcji -2lnL świadczą o tym, że hipoteza zerowa nie może być prawdziwa i należy ja odrzucić. W tablicy wyników wartość -2lnL odczytujemy w tabeli Model fit statistics.
. Jeżeli hipoteza zerowa mówiąca, że model idealnie pasuje do danych, jest prawdziwa, to statystyka -2lnL ma rozkład χ2 o n-k stopniach swobody. Jeżeli model idealnie pasuje do danych, to funkcji wiarogodności przyjmuje wartość 1 i wtedy -2lnL = 0. W praktyce otrzymujemy wartości L < 1 i wtedy -2lnL > 0. Zbyt duże wartości funkcji -2lnL świadczą o tym, że hipoteza zerowa nie może być prawdziwa i należy ja odrzucić. W tablicy wyników wartość -2lnL odczytujemy w tabeli Model fit statistics.")
72
Miary dobroci dopasowania
Są dwie modyfikacje kryterium -2lnL AIC - kryterium informacyjne Akaike (Akaike's Information Criterion) SC - kryterium Schwarza (Schwarz Criterion) W kryteriach AIC i SC wprowadza się karę za dużą liczbę obserwacji i dużą liczbę zmiennych. Należy używać tych statystyk, jeżeli porównujemy modele dla tych samych danych, ale różniące się liczba szacowanych parametrów np. przy stosowaniu regresji krokowej.
 SC - kryterium Schwarza (Schwarz Criterion) W kryteriach AIC i SC wprowadza się karę za dużą liczbę obserwacji i dużą liczbę zmiennych. Należy używać tych statystyk, jeżeli porównujemy modele dla tych samych danych, ale różniące się liczba szacowanych parametrów np. przy stosowaniu regresji krokowej.")
73
Miary dobroci dopasowania
Model z 1 zmienną Model z 4 zmiennymi Model z 8 zmiennymi Statystyki dopasowania modelu Kryterium Tylko wyraz wolny Wyraz wolny i współzmienne AIC SC -2 log L Statystyki dopasowania modelu Kryterium Tylko wyraz wolny Wyraz wolny i współzmienne AIC SC -2 log L Statystyki dopasowania modelu Kryterium Tylko wyraz wolny Wyraz wolny i współzmienne AIC SC -2 log L Prośba o weryfikację poszczególnych oszacowań modeli i wybór lepszych spośród modeli bez i ze zmiennymi, a następnie prośba o wybór najlepszego z trzech prezentowanych. W następnej kolejności prośba o zastanowienie się czy istnieje model lepszy i który z modeli dyskutowanych na zajęciach może być najlepszym. Dyskusj ana temat czy lepszy jest model z większą czy mniejszą liczba zmiennych i dlaczego…dlaczego model z 9 zmiennymi jest gorszy od modelu z 4 zmiennymi ale ten z 4 jest lepszy od tego z jedną i dlaczego najlepszy jest z dwiema zmiennymi. Statystyki: informacyjne kryterium Akaike, kryterium Schwarza, oraz podwojony logarytm funkcji wiarygodności z ujemnym znakiem dla modeli ze wszystkimi zmiennymi objaśniającymi są wyraźnie mniejsze niż w przypadku modeli jedynie z wyrazem wolnym, co oznacza, że dopasowanie jest lepsze w przypadku modeli ze zmiennymi. Statystyki dopasowania modelu Kryterium Tylko wyraz wolny Wyraz wolny i współzmienne AIC SC -2 log L Zastanowić się zatem należy, który spośród wszystkich modeli ze zmiennymi jest najlepszy i czego to może wynikać. Czy na podstawie wcześniej uzyskanych informacji można stwierdzić, że istnieje jeszcze lepszy model?

74
Reszty Reszty są to różnice między wartościami obserwowanymi i przewidywanymi. Na przykład, jeżeli wystąpiło zdarzenie dla obiektu i, a z modelu wynika, że prawdopodobieństwo zdarzenia wynosi 0,8, to reszta wynosi Są to reszty niestandaryzowane. Reszty standaryzowane wynoszą ponieważ są odchyleniami standardowymi w rozkładzie Bernoulliego.

75
Reszty Odchylenia (deviance) są obliczane jako
Studentyzowane reszty są obliczane jako zmiana odchylenia (deviance) modelu, gdy dana obserwacja jest usunięta. Różnice między odchyleniami i studentyzowanymi resztami mogą identyfikować nietypowe obserwacje. Reszty logitowe (logit) są obliczane jako
 modelu, gdy dana obserwacja jest usunięta. Różnice między odchyleniami i studentyzowanymi resztami mogą identyfikować nietypowe obserwacje. Reszty logitowe (logit) są obliczane jako.")
76
Reszty Pearsona i Dewiancji
Reszty Pearsona i Dewiancji są przydatne przy identyfikacji obserwacji, które nie są dobrze przewidywane przez model. Reszty Pearsona są składową statystyki chi-kwadrat Pearsona, reszty dewiancji sa składnikiem dewiancji. Statystyka chi-kwadrat Pearsona jest suma kwadratów reszt Pearsona, dewiancja jest sumą kwadratów reszt dewiancji. Kolejnym punktem weryfikacji modelu jest analiza statystyk zgodności dewiancji i Pearsona- mierzących dopasowanie modelu. Zgodnie z teorią, statystyki te mogą być w modelu binarnym estymowane oraz interpretowane, jeżeli liczba unikalnych subpopulacji (grup udzielanych odpowiedzi) minus liczba estymowanych parametrów jest większa od 0.
 minus liczba estymowanych parametrów jest większa od 0.")
77
Statystyki zgodności dewiancji i Pearsona
Number of unique profiles: 4 Statystyki zgodności dewiancji i Pearsona Kryterium Wartość St. sw. Wartość/st. sw. Pr > chi kw.. Deviance 1 <.0001 Pearson W prezentowanym przykładzie wyróżniono 4 unikalne profile przy 2 estymowanych parametrach modelu, w związku z czym, wartości statystyk zgodności mogą być interpretowane. Testowana jest hipoteza zerowa, że model jest dobrze dopasowany do danych. Wartości p-value są niższe od domyślnego poziomu istotności 0,05, zatem należy odrzucić hipotezę zerową na korzyść hipotezy alternatywnej; model jest źle dopasowany do danych. Uwaga: bardzo duża liczba profili w stosunku do liczby obserwacji, świadczy o tym, że w wielu komórkach tablicy kontyngencji znalazły się pojedyncze jednostki schematu odpowiedzi na poszczególne pytania, stanowiące zmienne objaśniające w modelu. Bez wątpienia ma to ogromny wpływ na jakość predykcyjną.

78
Tablice klasyfikacji Z punktu widzenia jakości modelu istotne jest, aby model dobrze szacował i klasyfikował wartości teoretyczne. Celem zbadania jakości klasyfikacji sporządzić można tablice kontyngencji (klasyfikacji) wartości empirycznych zmiennej objaśnianej względem poszczególnych zmiennych objaśniających. Na podstawie modelu chcemy przewidzieć, czy dane zjawisko wystąpiło czy nie. Jeżeli prawdopodobieństwo tego, że osoba ma nadwagę >0.5, to z modelu wynika, że bardziej prawdopodobne jest wystąpienie zjawiska, jeżeli <0.5, to bardziej prawdopodobne jest, że osoba nie ma nadwagi. Pojawia się tu kolejna komplikacja w postaci nierównomiernego rozkładu badanej cechy względem zmiennych objaśniających. W rezultacie model może lepiej szacować tylko jeden wariant zmiennej objaśnianej (rozpoznaje ‘bezbłędnie’ osoby z nadwagą, myli się w przypadku osób bez nadwagi). Response Sample 1 2 ... r Total n11 n12 n1r n1 n21 n22 n2r n2 s ns1 ns2 nsr ns Po estymacji modelu można podzielić zbiór obserwacji na dwie części: osoby, dla których pnadwaga>0.5 oraz osoby, dla których pnienadwaga <0.5. Wartość =0.5 możemy arbitralnie zaliczyć do jednej z wymienionych grup lub wyszczególnić.
 wartości empirycznych zmiennej objaśnianej względem poszczególnych zmiennych objaśniających. Na podstawie modelu chcemy przewidzieć, czy dane zjawisko wystąpiło czy nie. Jeżeli prawdopodobieństwo tego, że osoba ma nadwagę >0.5, to z modelu wynika, że bardziej prawdopodobne jest wystąpienie zjawiska, jeżeli <0.5, to bardziej prawdopodobne jest, że osoba nie ma nadwagi. Pojawia się tu kolejna komplikacja w postaci nierównomiernego rozkładu badanej cechy względem zmiennych objaśniających. W rezultacie model może lepiej szacować tylko jeden wariant zmiennej objaśnianej (rozpoznaje ‘bezbłędnie’ osoby z nadwagą, myli się w przypadku osób bez nadwagi). Response. Sample r. Total. n11. n12. n1r. n1. n21. n22. n2r. n2. s. ns1. ns2. nsr. ns. Po estymacji modelu można podzielić zbiór obserwacji na dwie części: osoby, dla których pnadwaga>0.5 oraz osoby, dla których pnienadwaga <0.5. Wartość =0.5 możemy arbitralnie zaliczyć do jednej z wymienionych grup lub wyszczególnić.")
79
Tablice klasyfikacji Tabela nadwaga na komputer nadwaga(nadwaga)
komputer(komputer) Razem brak komputera komputer brak nadwagi nadwaga Tabela nadwaga na fastfood nadwaga(nadwaga) fastfood(fastfood) Razem żadko lub prawie nigdy często brak nadwagi nadwaga Tabela 1 fastfood na nadwaga Sterowanie dla komputer=brak komputera fastfood(fastfood) nadwaga(nadwaga) Razem brak nadwagi nadwaga żadko lub prawie nigdy 3 0.47 często Tabela 2 fastfood na nadwaga Sterowanie dla komputer=komputer fastfood(fastfood) nadwaga(nadwaga) Razem brak nadwagi nadwaga żadko lub prawie nigdy często Liczebność Procent
 Razem. brak komputera. komputer. brak nadwagi nadwaga Tabela nadwaga na fastfood. nadwaga(nadwaga) fastfood(fastfood) Razem. żadko lub prawie nigdy. często. brak nadwagi nadwaga Tabela 1 fastfood na nadwaga. Sterowanie dla komputer=brak komputera. fastfood(fastfood) nadwaga(nadwaga) Razem. brak nadwagi. nadwaga. żadko lub prawie nigdy często Tabela 2 fastfood na nadwaga. Sterowanie dla komputer=komputer. fastfood(fastfood) nadwaga(nadwaga) Razem. brak nadwagi. nadwaga. żadko lub prawie nigdy często Liczebność Procent.")
80
Tablice klasyfikacji Po estymacji modelu można podzielić zbiór obserwacji na dwie części: osoby, dla których pnadwaga>0.5 oraz osoby, dla których pnienadwaga <0.5. Wartość =0.5 możemy arbitralnie zaliczyć do jednej z wymienionych grup lub wyszczególnić. Idealna sytuacja jest taka, gdy wartości zmiennej zależnej (nadwaga) pokrywają się z wartościami przynależności do teoretycznych klas wyznaczonych przez model. Oznacza to, że model prawidłowo podzielił zbiór osób na dwie kategorie – z nadwagą i tych, którzy nie mają nadwagi. W praktyce tak nigdy nie jest. Są osoby, które maja nadwagę, ale model zalicza je do kategorii osób nie mających nadwagi. Są też osoby, które nie maja nadwagi, ale model zalicza je do kategorii osób z nadwagą. Dokładniej zagadnienie to zostanie omówione nieco później Testy chi-kwardat pozwalają na testowanie niezależności analizowanych zmiennych (pozwala to zweryfikować hipotezę zerową o braku zależności pomiędzy poszczególnymi kategoriami zmiennych).
 pokrywają się z wartościami przynależności do teoretycznych klas wyznaczonych przez model. Oznacza to, że model prawidłowo podzielił zbiór osób na dwie kategorie – z nadwagą i tych, którzy nie mają nadwagi. W praktyce tak nigdy nie jest. Są osoby, które maja nadwagę, ale model zalicza je do kategorii osób nie mających nadwagi. Są też osoby, które nie maja nadwagi, ale model zalicza je do kategorii osób z nadwagą. Dokładniej zagadnienie to zostanie omówione nieco później. Testy chi-kwardat pozwalają na testowanie niezależności analizowanych zmiennych (pozwala to zweryfikować hipotezę zerową o braku zależności pomiędzy poszczególnymi kategoriami zmiennych).")
81
Dyskryminacja modelu Dyskryminacja modelu mówi nam, jak dobrze model rozróżnia obiekty w obu grupach. Idealny model zawsze przypisuje wyższe prawdopodobieństwo obiektom, dla których wystąpiło zdarzenie niż obiektom, dla których zdarzenie nie wystąpiło. Oznacza to, że oba zbiory nie zachodzą na siebie. Miarami tej zgodności są statystyki dla cech porządkowych. Mówimy, że para obserwacji z różnymi wartościami zmiennej objaśnianej jest zgodna (concordant), gdy niezgodna (discordant), gdy gdzie pi i pl i są przewidywanymi prawdopodobieństwami zdarzenia. Przypisując odpowiednie prawdopodobieństwa model się uczy, następnie na podstawie prawdopodobieństw wtórnie oblicza wartości teoretyczne zmiennej zależnej (dla poszczególnych komórek tablicy kontyngencji).
, gdy. niezgodna (discordant), gdy. gdzie pi i pl i są przewidywanymi prawdopodobieństwami zdarzenia. Przypisując odpowiednie prawdopodobieństwa model się uczy, następnie na podstawie prawdopodobieństw wtórnie oblicza wartości teoretyczne zmiennej zależnej (dla poszczególnych komórek tablicy kontyngencji).")
82
Skojarzenie przewidywanych prawdopodobieństw i obserwowanych reakcji
Dyskryminacja modelu Wówczas oblicza się następujące statystyki: Percent Concordant Percent Discordant Percent Tied Pairs Somers' d Goodman-Kruskal Gamma Tau Kendalla C gdzie t - liczba par (yi, yl) z różnymi wartościami nc - liczba par zgodnych, nd - liczba par niezgodnych, n - liczba obserwacji. Skojarzenie przewidywanych prawdopodobieństw i obserwowanych reakcji Procent zgodnych 88.0 D Somersa 0.844 Procent niezgodnych 3.7 Gamma 0.920 Percent Tied 8.3 Tau-a 0.422 Pary 222292 c 0.922
 z różnymi wartościami. nc - liczba par zgodnych, nd - liczba par niezgodnych, n - liczba obserwacji. Skojarzenie przewidywanych prawdopodobieństw i obserwowanych reakcji. Procent zgodnych D Somersa Procent niezgodnych Gamma Percent Tied Tau-a Pary c")
83
Skojarzenie przewidywanych prawdopodobieństw i obserwowanych reakcji
W tablicy przedstawione zostały cztery miary skojarzenia mierzące zdolności predykcyjne modelu. Z 943 analizowanych przypadków 88,0% zostało poprawnie zakwalifikowanych, 3,8% źle, w 8,1% decyzja nie została ogłoszona. Statystyka c jest polem pod powierzchnią krzywej ROC. Krzywa ROC jest wykresem zależności sensitivity (czułości będącej ilorazem liczby przypadków prawidłowo zakwalifikowanych przez model do grupy osób z nadwagą oraz liczby wszystkich przypadków nadwagi); 1-specificity (1- specyficzność; będącej ilorazem liczby przypadków nieprawidłowo zakwalifikowanych jako, ci u których wystąpiła nadwaga do liczby wszystkich przypadków z grupy osób, u których nie stwierdzono nadwagi). Krzywą ROC przedstawia kolejny wykres. Skojarzenie przewidywanych prawdopodobieństw i obserwowanych reakcji Procent zgodnych 88.0 D Somersa 0.844 Procent niezgodnych 3.7 Gamma 0.920 Percent Tied 8.3 Tau-a 0.422 Pary 222292 c 0.922 Statystyki D Somersa, Gamma oraz Tau-a testują niezależność zmiennych objaśnianej i objaśniających, na podstawie tablic kontyngencji. Statystyka gamma, dla skali porządkowej, jest nadwyżką zgodnych par ponad niezgodne wyrażana jako procent w stosunku do wszystkich wyodrębnionych par (poza tied). Interpretować ją należy jako proporcjonalną redukcję błędu. Znając zmienne niezależne eliminujemy błąd oszacowania rangowania par o 91 %. Statystyka D Somersa jest modyfiakcją gamma i jest to nadwyżka par zgodnych wyrażona jako procent zgodnych, niezgodnych i związanych. Innymi słowy D Somers jest warunkowym prawdopodobieństwem, że para jest zgodna minus para jest niezgodna.
; 1-specificity (1- specyficzność; będącej ilorazem liczby przypadków nieprawidłowo zakwalifikowanych jako, ci u których wystąpiła nadwaga do liczby wszystkich przypadków z grupy osób, u których nie stwierdzono nadwagi). Krzywą ROC przedstawia kolejny wykres. Skojarzenie przewidywanych prawdopodobieństw i obserwowanych reakcji. Procent zgodnych D Somersa Procent niezgodnych Gamma Percent Tied Tau-a Pary c Statystyki D Somersa, Gamma oraz Tau-a testują niezależność zmiennych objaśnianej i objaśniających, na podstawie tablic kontyngencji. Statystyka gamma, dla skali porządkowej, jest nadwyżką zgodnych par ponad niezgodne wyrażana jako procent w stosunku do wszystkich wyodrębnionych par (poza tied). Interpretować ją należy jako proporcjonalną redukcję błędu. Znając zmienne niezależne eliminujemy błąd oszacowania rangowania par o 91 %. Statystyka D Somersa jest modyfiakcją gamma i jest to nadwyżka par zgodnych wyrażona jako procent zgodnych, niezgodnych i związanych. Innymi słowy D Somers jest warunkowym prawdopodobieństwem, że para jest zgodna minus para jest niezgodna.")
84
Kalibracja modelu Kalibracja modelu mówi nam, jak silnie wartości obserwowane i przewidywane pasują do siebie w całym przedziale zmienności. Do oceny tego służy test Hosmera i Lemeshowa (1989). Dzielimy obserwacje na 10 w przybliżeniu równych klas rosnąco według oszacowanego prawdopodobieństwa zdarzenia (są to więc grupy decylowe) i badamy rozkład obserwowanych i przewidywanych wartości w tych grupach. Następnie stosujemy test zgodności oparty na statystyce χ2. Powinna być dostateczna liczebność zbioru, tak aby w większości grup decylowych liczba oczekiwanych zdarzeń przekraczała 5 i żadna grupa nie miała zerowej liczby oczekiwanych zdarzeń. Oblicza się różnice między obserwowanymi wartościami ni i przewidywanymi a następnie
. Dzielimy obserwacje na 10 w przybliżeniu równych klas rosnąco według oszacowanego prawdopodobieństwa zdarzenia (są to więc grupy decylowe) i badamy rozkład obserwowanych i przewidywanych wartości w tych grupach. Następnie stosujemy test zgodności oparty na statystyce χ2. Powinna być dostateczna liczebność zbioru, tak aby w większości grup decylowych liczba oczekiwanych zdarzeń przekraczała 5 i żadna grupa nie miała zerowej liczby oczekiwanych zdarzeń. Oblicza się różnice między obserwowanymi wartościami ni i przewidywanymi. a następnie.")
85
Test Hosmera i Lemeshowa
Test Homera i Lemershowa, na podstawie percentyli wyliczonych prawdopodobieństw, podzielił wszystkie obserwacje na 10 grup. Stosując statystykę chi-kwadrat testowane są różnice pomiędzy przewidywaną a obserwowaną liczbą obserwacji w danych grupach. Test zgodności Hosmera i Lemeshowa Chi-kwadrat St. sw. Pr > chi kw.. 8 0.1003 Miejsce na test Hosmera i Lemeshowa Grupa Razem nadwaga = 1 nadwaga = 0 Empiryczne Oczekiwane 1 94 1.32 92.68 2 2.29 93 91.71 3 3.10 90.90 4 6 4.39 88 89.61 5 46 40.18 48 53.82 79 77.86 15 16.14 7 83 80.17 11 13.83 8 78 82.15 16 11.85 9 85.30 8.70 10 97 85 90.23 12 6.77 Im więcej zmiennych tym więcej komórek w tablicach kontyngencji, tym dokładniej szacowane są poszczególne prawdopodobieństwa ale tez tym więcej jest komórek pustych, co utrudnia modelowanie. Dlaczego zmiana liczby zmiennych powoduję zmianę decyzji o dobroci dopasowania? Dlaczego uległa zmianie liczba percentyli szacowanych par zgodnych i niezgodnych. Dlaczego ważne jest aby grupy (komórki tablicy kontyngencji) były licznie reprezentowane. Otrzymane wysokie p-value sugeruje, że model jest dobrze dopasowany, bowiem testowana była hipoteza zerowa o tym, że model jest dobrze dopasowany do danych. Dla rozpatrywanego modelu test ten pokazał na poziomie istotności 0,05 adekwatność modelu, co jest zjawiskiem pożądanym. Test zgodności Hosmera i Lemeshowa Chi-kwadrat St. sw. Pr > chi kw.. 2 <.0001 …ale w modelu po selekcji (gdzie wyróżniono 4 grupy) na poziomie istotności stwierdzić należy brak adekwatności!!!
 były licznie reprezentowane. Otrzymane wysokie p-value sugeruje, że model jest dobrze dopasowany, bowiem testowana była hipoteza zerowa o tym, że model jest dobrze dopasowany do danych. Dla rozpatrywanego modelu test ten pokazał na poziomie istotności 0,05 adekwatność modelu, co jest zjawiskiem pożądanym. Test zgodności Hosmera i Lemeshowa. Chi-kwadrat. St. sw. Pr > chi kw < …ale w modelu po selekcji (gdzie wyróżniono 4 grupy) na poziomie istotności stwierdzić należy brak adekwatności!!!")
86
Miary dobroci dopasowania
Statystyki R2 Coxa i Snella i R2 Nagelkerke'a mają na celu oszacowanie zmienności zmiennej zależnej wyjaśnionej przez model w całkowitej zmienności. Mają one interpretację zbliżoną do współczynnika determinacji w klasycznej regresji liniowej (pozwalają ocenić pojemność informacyjną modelu). Większa wartość wartości przeskalowanej świadczy o tym, że wszystkie wprowadzone do tej pory do modelu zmienne są istotne statystycznie, a wprowadzanie zmiennych wpływa na poprawę jakości modelu. Czym jest test dobroci dopasowania (pojemności informacyjnej modelu). Czym się różni i dlaczego odnosi się do funkcji wiarygodności (jako do tej, która pozwala wybrać najlepszy zestaw parametrów modelu) w porównaniu do miar jakości dopasowania omówionych wcześniej (bazujących na tablicy kontyngencji). Ponieważ R2 Coxa i Snella nie osiąga maksymalnej wartości 1, Nagelkerke (1991) zaproponował korektę tej statystyki. gdzie R-kwadrat 0.5600 Maksymalnie przeskalowany r-kwadrat 0.7467
. Większa wartość wartości przeskalowanej świadczy o tym, że wszystkie wprowadzone do tej pory do modelu zmienne są istotne statystycznie, a wprowadzanie zmiennych wpływa na poprawę jakości modelu. Czym jest test dobroci dopasowania (pojemności informacyjnej modelu). Czym się różni i dlaczego odnosi się do funkcji wiarygodności (jako do tej, która pozwala wybrać najlepszy zestaw parametrów modelu) w porównaniu do miar jakości dopasowania omówionych wcześniej (bazujących na tablicy kontyngencji). Ponieważ R2 Coxa i Snella nie osiąga maksymalnej wartości 1, Nagelkerke (1991) zaproponował korektę tej statystyki. gdzie. R-kwadrat Maksymalnie przeskalowany r-kwadrat")
87
ZADANIA dla studentów Proszę na podstawie zbioru arthrit dokonać selekcji zmiennych do modelu ze zmienną objaśniającą better, ocenić istotność zmiennych, dokonać weryfikacji modelu (dopasowania do danych oraz pojemności informacyjnej), Proszę uzasadnić wybór danej metody kodowania zmiennych oraz zinterpretować otrzymane wyniki, Proszę na podstawie zbioru gosp zbadać zależność zmiennej komputer od pozostałych zmiennych w zbiorze (modelując prawdopodobieństwo ma komputer oraz nie ma komputera), przeprowadzić selekcję, zinterpretować wyniki.
, Proszę uzasadnić wybór danej metody kodowania zmiennych oraz zinterpretować otrzymane wyniki, Proszę na podstawie zbioru gosp zbadać zależność zmiennej komputer od pozostałych zmiennych w zbiorze (modelując prawdopodobieństwo ma komputer oraz nie ma komputera), przeprowadzić selekcję, zinterpretować wyniki.")
88
Projekt 2 Projekt powinien zawierać:
1. Estymacja modelu (z porównaniami modeli przy różnych sposobach selekcji zmiennych do modelu) 2. Weryfikacja istotności parametrów 3. Weryfikacja jakości modelu oraz interpretacja otrzymanych wyników
 2. Weryfikacja istotności parametrów. 3. Weryfikacja jakości modelu oraz interpretacja otrzymanych wyników.")
89
Dziękuję za uwagę

Podobne prezentacje
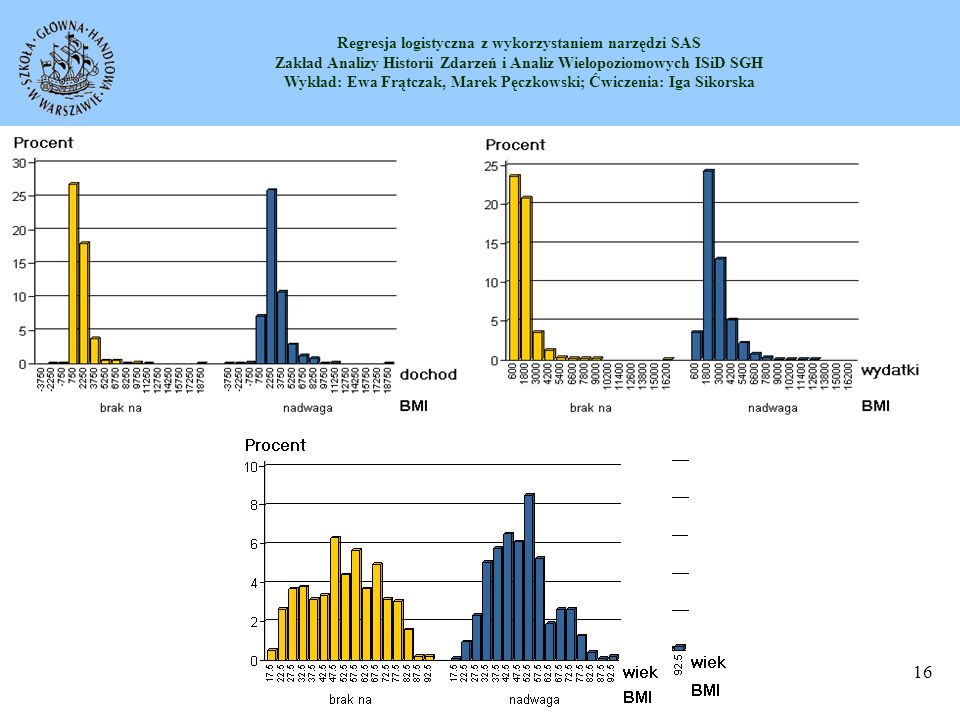

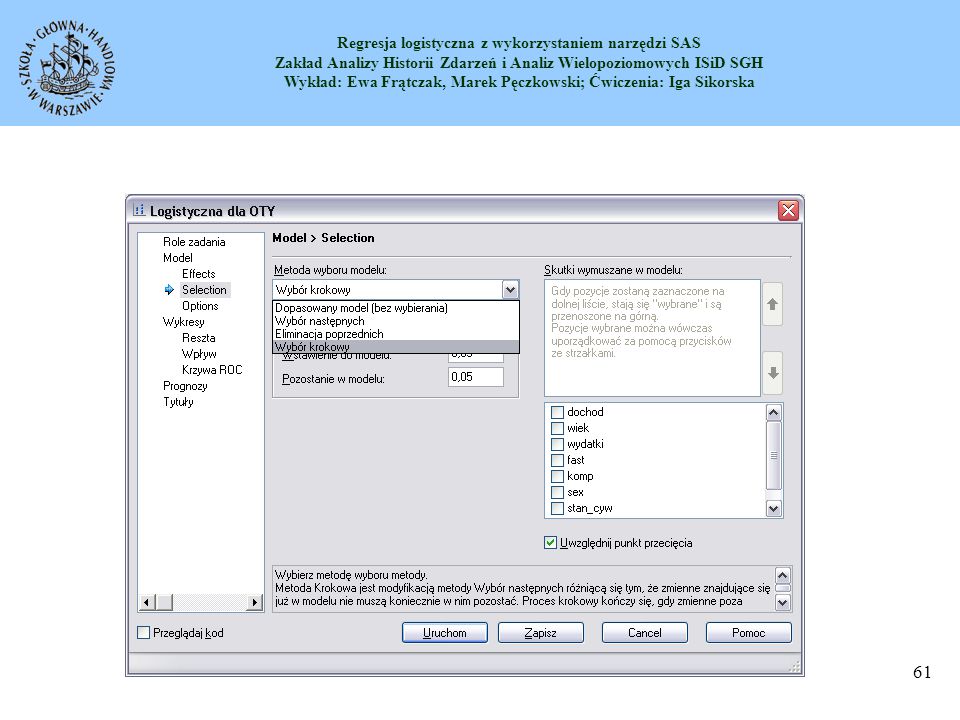
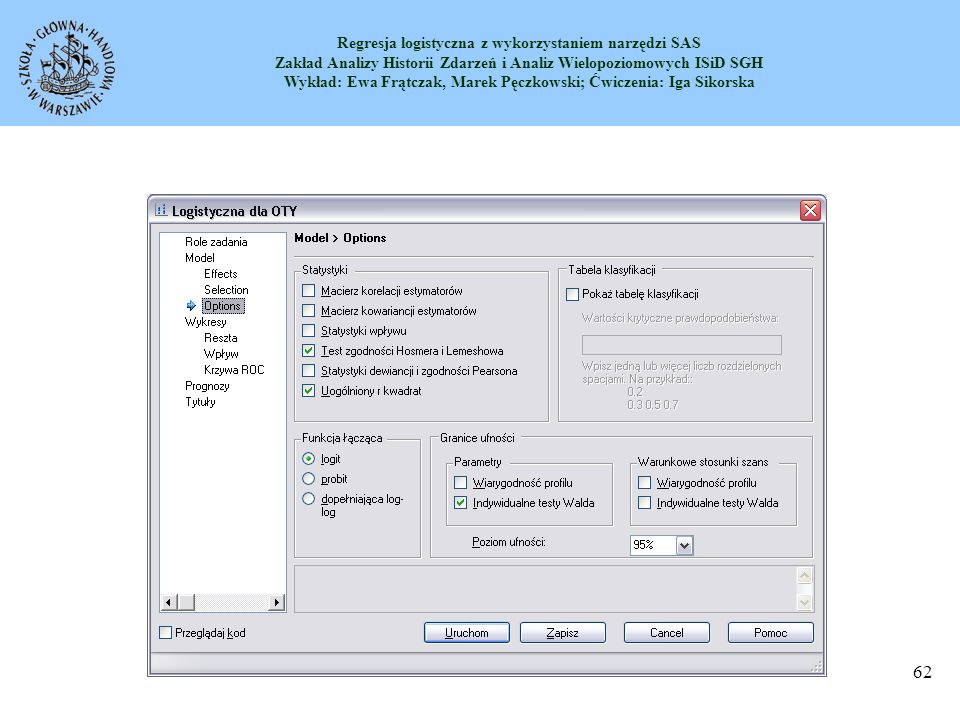
, gdzie X jest liczbą osób w rodzinie, a Y liczbą izb w mieszkaniu. Niech f.r.p. tej zmiennej.>")


















