Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Wykład 9 Analiza wariancji (ANOVA)
Sposób analizy danych, gdy porównujemy więcej niż dwie populacje/zabiegi. Omówimy ANOV-ę w najprostszej postaci. Te same podstawowe założenia/ograniczenia, co przy teście Studenta: W każdej populacji badana cecha ma rozkład normalny Obserwacje są niezależne i losowe Testujemy hipotezy o średnich w populacjach: I Dodatkowe założenie – standardowe odchylenia badanej cechy w badanych populacjach są sobie równe (podobne) – użyjemy uśrednionego SE
 – użyjemy uśrednionego SE.")
2
Uwaga: ANOVA może być stosowana także wtedy, gdy próby nie są niezależne, np. w zrandomizowanym układzie blokowym (zasada podobna do testu Studenta dla par). Tutaj jednak omówimy tylko układy zrandomizowane zupełne (=jednoblokowe). Cel: Testujemy hipotezy postaci: H0: 1 = 2 = 3 = … = k HA: nie wszystkie średnie są równe

3
Dlaczego nie stosujemy wielu testów Studenta?
Wielokrotne porównania: prawdopodo-bieństwo błędu pierwszego rodzaju (odrzucenia prawdziwej hipotezy zerowej) byłoby trudne do kontrolowania. Estymacja błędu standardowego: ANOVA wykorzystuje informację zawartą we wszystkich obserwacjach: zwykle daje większą precyzję obliczenia/mniejsze SE niż indywidualne testy Studenta dla par. ANOVA automatycznie porównuje konfiguracje populacji większe niż pary.
 byłoby trudne do kontrolowania. Estymacja błędu standardowego: ANOVA wykorzystuje informację zawartą we wszystkich obserwacjach: zwykle daje większą precyzję obliczenia/mniejsze SE niż indywidualne testy Studenta dla par. ANOVA automatycznie porównuje konfiguracje populacji większe niż pary.")
4
Korekta Bonferoniego Przy k testach na poziomie α, przyjmujemy łączny poziom istotności kα. Prosta, ale na ogół konserwatywna: prawdo-podobieństwo błędu pierwszego rodzaju jest mniejsze niż założone kα – w efekcie strata mocy. Np. przy porównywaniu 5 populacji testem Studenta dla niezależnych prób Bonferoni daje poziom istotności równy

5
Notacja: k = 3 zabiegi (grupy)
1 48 40 39 2 30 3 42 44 32 4 43 35 średnia 34 SS 46

6
SS df MS Trzy kategorie: W każdej - trzy wartości: SS, df, MS.
wewnątrz grup, pomiędzy grupami, łącznie. W każdej - trzy wartości: SS, df, MS. SS df MS wewnątrz pomiędzy łącznie

7
Notacja, cd.: k : # grup (prób, zabiegów), tutaj k =
n1, n2, n3, …, nk : rozmiary grup (# obserwacji) n1 = , n2 = , n3 = y1 , y2, … yk = średnie w grupach y1= ,y2 = , y3= = całkowita średnia (wszystkich obserwacji) n* = całkowita liczba obserwacji n* =
 n1 = , n2 = , n3 = y1 , y2, … yk = średnie w grupach. y1= ,y2 = , y3= = całkowita średnia (wszystkich obserwacji) n* = całkowita liczba obserwacji. n* =")
8
Używamy i do indeksowania grup a j do indeksowania obserwacji w każdej grupie, np: yij .
oznacza sumę ``wewnątrz grupy’’:

9
Uwzględniające wszystkie grupy
oznacza sumę po grupach: np ; tutaj n* =

10
UWAGA: Gdy rozmiary prób nie są równe
nie jest średnią z k średnich! Można ją obliczyć jako = (n1y1 + n2y2 + …+n3y3) / n*
 / n*")
11
Wewnątrz grup: wypełniamy drugi rząd w tabeli
Suma kwadratów wewnątrz grup (SSW): Liczymy SS dla każdej grupy (SS2, SS3 , itd.) SS1 = ..... SS2 = … = 32, SS3 = … = 46
: Liczymy SS dla każdej grupy. (SS2, SS3 , itd.) SS1 = SS2 = … = 32, SS3 = … = 46.")
12
SSW = SS1+SS2+…+SSk , tutaj SSW =.... Stopnie swobody wewnątrz grup: dfw = n* - k, tutaj dfw =... Średnia suma kwadratów wewnątrz grup: MSW = SSW / dfw , tutaj MSW =... MSW to uśredniona wariancja, np.(wykład 6): Uśrednione odchylenie standardowe sc = , tutaj sc =...
: Uśrednione odchylenie standardowe. sc = , tutaj sc =...")
13
Pomiędzy grupami: wypełniamy pierwszy rząd tabeli
Porównujemy średnie grupowe do całko-witej z wagą daną przez rozmiar grupy. Suma kwadratów pomiędzy grupami (SSB) SSB = Tutaj SSB =....
 SSB = Tutaj SSB =....")
14
Stopnie swobody pomiędzy grupami (dfb)
dfb = k – 1, tutaj dfb = ... Średnia suma kwadratów pomiędzy grupami (MSB) MSB = SSB/dfb, tutaj MSB =...
 MSB = SSB/dfb, tutaj MSB =...")
15
Całkowite: wypełniamy trzeci rząd tabeli
Całkowita suma kwadratów (SST): SST= SST= …+82+52=348
: SST= SST= …+82+52=348.")
16
Uwaga: SST = SSW+SSB, tu 348 = 120 + 228
Zwykle nie trzeba liczyć SST z definicji! Całkowita liczba stopni swobody (dft) dft = n* – 1 , tutaj dft = Uwaga: dft = dfb+dfw , tutaj = 2 + 8
 dft = n* – 1 , tutaj dft = Uwaga: dft = dfb+dfw , tutaj 10 =")
17
Tablica ANOV-y (ponownie)
SS df MS Between Within Total puste

18
Ta tabela będzie dostępna na kolokwium i egzaminie:
SS df MS Pomiędzy SSB= dfb = k – 1 SSB/dfb Wewnątrz SSW= dfw = n* – k SSW/dfw Całkowite SST= dft = n* – 1

19
Test F (Fishera) Założenia (jak w ANOV-ie):
Dane dla k 2 populacji/zabiegów są niezależne Dane w każdej populacji mają rozkład normalny ze średnią i (dla populacji I), oraz z tym samym odchyleniem standardowym
, oraz z tym samym odchyleniem standardowym ")
20
(wszystkie średnie są sobie równe) przeciwko
Testujemy H0: 1 = 2 = 3 = … = k (wszystkie średnie są sobie równe) przeciwko HA: nie wszystkie średnie są sobie równe HA jest niekierunkowa, ale obszar odrzuceń będzie jednostronny (duże dodatnie wartości statystyki) Kroki: Obliczenie tabeli ANOV-y Testowanie
 przeciwko. HA: nie wszystkie średnie są sobie równe. HA jest niekierunkowa, ale obszar odrzuceń będzie jednostronny (duże dodatnie wartości statystyki) Kroki: Obliczenie tabeli ANOV-y. Testowanie.")
21
Jak opisać F test Zdefinować wszystkie
H0 podać za pomocą wzoru i słownie HA tylko słownie Statystyka testowa Fs = MSB/MSW Przy H0, Fs ma rozkład F Snedecora ze stopniami swobody (dfb, dfw) Na slajdach podane są wartości krytyczne z książki D.S. Moore i G. P. McCabe „Introduction to the Practice of Statistics” „numerator df” = dfb, „denominator df” = dfw.
 Na slajdach podane są wartości krytyczne z książki D.S. Moore i G. P. McCabe „Introduction to the Practice of Statistics „numerator df = dfb, „denominator df = dfw.")
26
Odrzucamy H0 , gdy zaobserwowane
Fs > Fkrytyczne Przykładowy wniosek: „Na poziomie istotności α (nie) mamy przesłanki, aby twierdzić, że grupy różnią się poziomem badanej cechy.”
 mamy przesłanki, aby twierdzić, że grupy różnią się poziomem badanej cechy.")
27
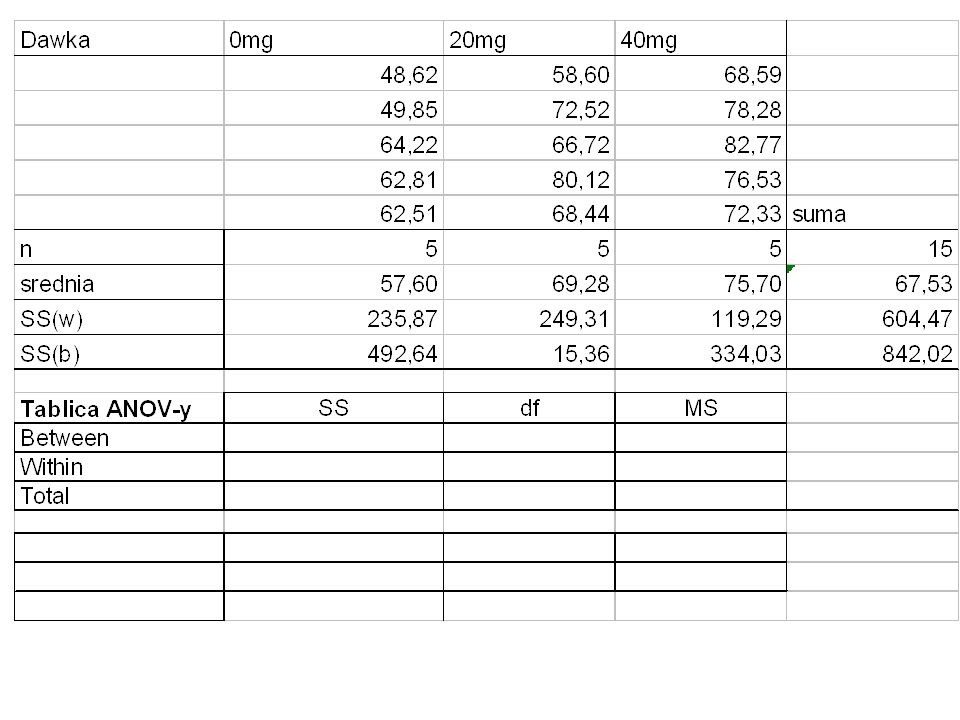
Przykład: Losową próbę 15 zdrowych mężczyzn podzielono losowo na 3 grupy składające się z 5 mężczyzn. Przez tydzień otrzymywali oni lekarstwo Paxil w dawkach 0, 20 i 40 mg dziennie. Po tym czasie zmierzono im poziom serotoniny. Czy Paxil wpływa na poziom serotoniny u zdrowych, młodych mężczyzn ? Niech 1 będzie średnim poziomem serotoniny u mężczyzn przyjmujących 0 mg Paxilu. Niech 2 będzie średnim poziomem serotoniny u mężczyzn przyjmujących 20 mg Paxilu. Niech 3 będzie średnim poziomem serotoniny u mężczyzn przyjmujących 40 mg Paxilu.

28
H0: 1 = 2 = 3 ; średni poziom serotoniny nie zależy od dawki Paxilu
HA: średni poziom serotoniny nie jest ten sam we wszystkich grupach (albo średni poziom serotoniny zależy od dawki Paxilu). Zastosujemy F-Test
. Zastosujemy F-Test.")
30
Fs = MSB / MSW przy H0 ma rozkład...
Testujemy na poziomie = 0.05. Wartość krytyczna F.05 = Obserwujemy Fs =... Wniosek:...

31
Na jakiej zasadzie to działa ?
Dla przypomnienia: Statystyka testu Studenta ma w liczniku różnicę między średnimi (y1-y2) Tę dzielimy przez miarę rozrzutu tej różnicy (SEy1-y2 ) Jeżeli (y1-y2) jest duże w porównaniu do błędu standardowego, to statystyka testu Studenta jest duża i odrzucamy H0.
 Tę dzielimy przez miarę rozrzutu tej różnicy (SEy1-y2 ) Jeżeli (y1-y2) jest duże w porównaniu do błędu standardowego, to statystyka testu Studenta jest duża i odrzucamy H0.")
32
Dla testu F: W liczniku mamy „uśredniony kwadrat różnicy między średnimi” (MSB) W mianowniku mamy oszacowanie zróżnicowania w obserwacji (MSW) Jeżeli MSB jest duże w porównaniu do MSW, to statystyka testu F jest duża i odrzucamy H0. Test F jest analogiczny do testu Studenta. Umożliwia jednoczesne porównanie dowolnej liczby średnich.

33
Test F można stosować również, gdy mamy tylko dwie próby. Wtedy:
Statystyka testu F dla dwóch prób jest równa kwadratowi statystyki Studenta (przy (U)SE). Decyzje i p-wartości są dokładnie takie same dla obu testów.
SE). Decyzje i p-wartości są dokładnie takie same dla obu testów.")
Podobne prezentacje






>")






 stanowi rozszerzenie testu t-Studenta w przypadku porównywanie większej liczby grup. Podział na grupy (czyli.>")






 Sposób analizy danych gdy mamy więcej niż dwa zabiegi lub populacje. Omówimy ANOV-ę w najprostszej postaci. Te same.>")