Pobierz prezentację
Pobieranie prezentacji. Proszę czekać


1
One flew over... statistics czyli statystyka w 8 godzin
testowanie hipotez statystyka opisowa data mining teoria estymacji modele probabilistyczne statystyczna teoria decyzji modelowanie dr Krystyna Stanisz-Wallis dr Wojciech Jawień

2
ABC...

3
Zmienna losowa Jeżeli wynik eksperymentu wyrazimy w postaci liczbowej, to otrzymamy zmienną losową. Gdy zmienna losowa może przybierać dowolne wartości z pewnego przedziału, nazywamy ją zmienną losową ciągłą. Jeśli natomiast przyjmuje tylko pewne wartości, a nie przyjmuje wartości pośrednich, nazywamy ją zmienną losową dyskretną.

4
Zmienna losowa Wszystkie zmienne losowe, z którymi spotykamy się w praktyce, są dyskretne. Zmienna losowa ciągła pozostaje użyteczną idealizacją. Często analizę teoretyczną i praktyczne obliczenia łatwiej przeprowadzić dla zmiennych losowych ciągłych niż dyskretnych.

5
Zmienna losowa ciągła Losujemy w sposób równomierny liczbę z przedziału [0,1] – to nasza zmienna losowa X. Jakie są prawdopodobieństwa:
![Zmienna losowa ciągła Losujemy w sposób równomierny liczbę z przedziału [0,1] – to nasza zmienna losowa X.](http://slideplayer.pl/slide/57532/1/images/5/Zmienna+losowa+ci%C4%85g%C5%82a+Losujemy+w+spos%C3%B3b+r%C3%B3wnomierny+liczb%C4%99+z+przedzia%C5%82u+%5B0%2C1%5D+%E2%80%93+to+nasza+zmienna+losowa+X..jpg "Jakie są prawdopodobieństwa: .")
6
Zmienna losowa ciągła Dla zmiennych losowych ciągłych celowe jest rozważanie prawdopodobieństw w przedziałach a nie punktach. Można dla tych zmiennych wprowadzić funkcję gęstości rozkładu prawdopodobieństwa.

7
Funkcja gęstości – właściwości
Funkcja gęstości rozkładu prawdopodobieństwa pozwala obliczać prawdopodobieństwo znalezienia zmiennej losowej w dowolnym przedziale.

8
Funkcja gęstości

9
Rozkłady prawdopodobieństwa
Różne eksperymenty opisywane mogą być różnymi funkcjami gęstości, czyli zmienne losowe mogą mieć różne rozkłady prawdopodobieństwa. W praktyce bardzo często spotykamy rozkład normalny.

10
Rozkład normalny Parametry: wartość oczekiwana odchylenie standardowe

11
Galeria rozkładów ciągłych

12
Ogólna teoria testów statystycznych
Teoria Neymana*-Pearsona** *Jerzy Spława-Neyman, **Egon Pearson, syn Karla,

13
Hipotezy Hipoteza – dowolna wypowiedź o rozkładzie zmiennej losowej
parametryczna (mówi o wartościach parametrów rozkładu) nieparametryczna Hipoteza parametryczna prosta (jedna wartość) złożona (zbiór wartości, np. przedział)
 nieparametryczna. Hipoteza parametryczna. prosta (jedna wartość) złożona (zbiór wartości, np. przedział)")
14
Hipotezy - przykłady AUC nie ma rozkładu normalnego.
Wartość oczekiwana tmax wynosi 2h. Odchylenie standardowe Cmax nie przekracza 3 mg/l. (E – wartość oczekiwana, V – wariancja = ) lub: albo:
 lub: albo:")
15
Cel testowania Zadaniem testu jest obalenie hipotezy zerowej (H0) na rzecz hipotezy alterna-tywnej (H1). Obalenie hipotezy polega na wykazaniu, że gdyby była ona prawdziwa, to uzyskanie takich wyników pomiarów jak otrzymane byłoby mało prawdopodobne.

16
Weryfikacja Na podstawie wyniku badania (próby) obliczamy tzw. statystykę testową T. Wybór T zależy od H0 i H1, planu eksperymentu i przyjętych założeń o rozkładzie wyników pomiarów. W oparciu o H0 i H1, ew. inne, niejawne założenia i (nieraz głęboką) wiedzę statystyczną konstruujemy dla T obszar krytyczny K.
 obliczamy tzw. statystykę testową T. Wybór T zależy od H0 i H1, planu eksperymentu i przyjętych założeń o rozkładzie wyników pomiarów. W oparciu o H0 i H1, ew. inne, niejawne założenia i (nieraz głęboką) wiedzę statystyczną konstruujemy dla T obszar krytyczny K.")
17
Weryfikacja Jeśli T znajdzie się w tym obszarze, H0 odrzucamy i twierdzimy, że prawdziwa jest H1 W przeciwnym razie słuszność hipotez H0 lub H1 pozostaje nierozstrzygnięta. Absence of evidence is not evidence of absence. Dr Carl Sagan, astrofizyk

18
Błędy Błąd I rodzaju – odrzucenie słusznej hipotezy. Prawdopodobieństwo tego błędu oznaczamy i nazywamy poziomem istotności. Z reguły =0,05, czyli 5%.

19
Błędy Błąd II rodzaju – niepowodzenie obalenia H0, mimo że prawdziwa jest H1 Prawdopodobieństwo błędu II rodzaju oznaczamy . Nie jest ono zwykle równe 1- (i na ogół trudno je obliczyć). Prawdopodobieństwo udanej weryfikacji nazywa się mocą testu, jest ona równa 1-.
. Prawdopodobieństwo udanej weryfikacji nazywa się mocą testu, jest ona równa 1-.")
20
Przykład: Test t-Studenta
Dwie grupy pomiarów: na tych samych podmiotach, np. przed i po posiłku (zmienne połączone) na różnych podmiotach, np. ♀ i ♂ (zmienne niepołączone) Zakładamy, że pomiary podlegają rozkładowi normalnemu. Dla zmiennych niepołączonych dodatkowo zakładamy równość wariancji w grupach.
 na różnych podmiotach, np. ♀ i ♂ (zmienne niepołączone) Zakładamy, że pomiary podlegają rozkładowi normalnemu. Dla zmiennych niepołączonych dodatkowo zakładamy równość wariancji w grupach.")
21
Test t-Studenta Hipoteza zerowa: Hipotezy alternatywne
test jednostronny test dwustronny

22
Przykład – test t-Studenta, zmienne połączone
Czy dieta (np. sok grejpfrutowy) wpływa na DB? Y – wielkość będąca miarą DB. Przeformułowanie problemu:
 wpływa na DB Y – wielkość będąca miarą DB. Przeformułowanie problemu:")
23
test t-Studenta (cd) Wykonujemy eksperyment i wyznaczamy dla każdego osobnika Di. Wyznaczamy estymaty (oszacowania) wartości oczekiwanej i odchylenia standardowego zmiennej losowej D
 wartości oczekiwanej i odchylenia standardowego zmiennej losowej D.")
24
test t-Studenta (cd) Odchylenie standardowe średniej jest razy mniejsze: Jeśli D ma rozkład normalny to statystyka ma rozkład t-Studenta z n-1 stopniami swobody.

25
test t-Studenta (cd)
")
26
Test t-Studenta – moc W przedstawionym teście H0 była hipotezą prostą, a jej alternatywa – hipotezą złożoną. Przypuśćmy, że zachodzi jeden ze składników alternatywy:

27
Test t-Studenta – moc Wtedy a rozkład zmiennej t jest nieco inny (nazy-wa się niecentralnym rozkładem t ). Ze wzrostem maleje , a więc zwiększa się moc testu.

28
Test t-Studenta – moc Moc zwiększa się ze wzrostem liczebności próby.
Dokładne określenie mocy testu nie jest możliwe, gdyż nie znamy dokładnie potrzebnych parametrów.

29
Moc i liczebność próby Ocena mocy, choć trudna, jest ważnym elementem planowania badań. Staramy się tak dobrać liczbę pomiarów, aby uzyskać spodziewaną moc co najmniej 80%. To call in the statistician after the experiment is done may be no more than asking him to perform a post-mortem examination: he may be able to say what the experiment died of. Sir Ronald Fisher, wielki statystyk

30
Test t-Studenta, jedno- i dwustronny
W teście jednostronnym porównujemy wartość t z W teście dwustronnym porównujemy |t| z Jeśli są przesłanki przemawiające za tes-tem jednostronnym, warto go stosować. Postawą tej decyzji nie może być jednak bieżący eksperyment.

31
Test t-Studenta, zmienne niepowiązane
Test dla zmiennych niepowiązanych zawiera istotne założenie o równości wariancji w obu grupach (jednorodność wariancji). Jeśli założenie to nie jest spełnione, należy stosować przybliżony wariant opracowany przez Satterthwaite’a. Spotyka się też nazwę test Welcha.
. Jeśli założenie to nie jest spełnione, należy stosować przybliżony wariant opracowany przez Satterthwaite’a. Spotyka się też nazwę test Welcha.")
32
Inne testy parametryczne dla ciągłych zmiennych losowych

33
Test równoważności Test t-Studenta pozwala udowodnić istnienie różnic między grupami. W celu udowodnienia braku tych różnic chciałoby się w teście dwustronnym zamienić role hipotezy zerowej i alternatywnej: vs

34
Test równoważności Niestety, moc takiego testu byłaby równa dokładnie 0. Test równoważności ma udowodnić, że różnica wartości oczekiwanych nie przekracza z góry zadanego zakresu.

35
Test równoważności Taki test, opracowany przez Schuirmanna, używany bywa do wykazywania równoważ-ności postępowania terapeutycznego. Określenie granic i należy do ekspertów z zakresu nauk medycznych, a nie do statystyków.

36
Test równości wariancji
Test F-Fishera-Snedecora pozwala porównać wariancje (a więc i odchylenia standardowe) w dwu grupach pomiarów. Zakłada się w nim rozkład normalny w obu grupach. Test może być jednostronny lub dwustronny: lub
 w dwu grupach pomiarów. Zakłada się w nim rozkład normalny w obu grupach. Test może być jednostronny lub dwustronny: lub.")
37
Analiza wariancji Analiza wariancji (ANOVA) stanowi rozszerzenie testu t-Studenta w przypadku porównywania większej liczby grup. Podział na grupy (czyli klasyfikacja) dokonywany jest na podstawie jednego lub kilku czynników. Mówimy więc o jednoczynnikowej (one-way) lub wieloczynnikowej analizie wariancji.
 dokonywany jest na podstawie jednego lub kilku czynników. Mówimy więc o jednoczynnikowej (one-way) lub wieloczynnikowej analizie wariancji.")
38
Analiza wariancji Czynnik może przybierać pewną liczbę wartości, zwanych poziomami. Np. czynnik płeć ma tylko dwa poziomy (♀,♂), czynnik grupa krwi – cztery poziomy (0,A,B,AB). Należy odróżniać liczbę czynników od liczby poziomów danego czynnika. Jeszcze ważniejsze jest odróżnianie wyniku od czynnika.
, czynnik grupa krwi – cztery poziomy (0,A,B,AB). Należy odróżniać liczbę czynników od liczby poziomów danego czynnika. Jeszcze ważniejsze jest odróżnianie wyniku od czynnika.")
39
Analiza wariancji Założenia
Podobnie jak w teście t-Studenta zakłada się, że wyniki podlegają rozkładowi normalnemu, a wariancje we wszystkich grupach są takie same. Procedury analizy wariancji są dość odporne na naruszenie tych założeń.

40
Jednoczynnikowa analiza wariancji
Najprostszy plan eksperymentu – układ kompletnie zrandomizowany. Na każdym podmiocie pomiar wykonywany jest tylko raz. Ten układ jest więc odpowiednikiem testu t-Studenta dla zmiennych niepołączonych.

41
Jednoczynnikowa analiza wariancji
Hipoteza zerowa: wartość oczekiwana w każdej grupie jest taka sama. Hipoteza alternatywna: nie wszystkie wartości oczekiwane są jednakowe.

42
Jednoczynnikowa analiza wariancji
Weryfikacja hipotezy polega na estymacji wariancji na dwa niezależne od siebie sposoby: uśredniając wyniki uzyskane dla każdej grupy badając zmienność średnich między grupami O ile H0 jest słuszna, obie wariancje powinny być jednakowe. Sprawdzamy to jednostronnym testem F.

43
Jednoczynnikowa analiza wariancji
Wyniki przedstawia się w postaci tabeli analizy wariancji: Źródło zmienności Sumy kwadratów St. swobody Średni kwadrat F Pomiędzy grupami k-1 Wewnątrz grup (błąd) n-k Całkowita n-1
 n-k. Całkowita. n-1.")
44
Jednoczynnikowa analiza wariancji
Pozytywny wynik testu (odrzucenie hipotezy zerowej) nie daje odpowiedzi na pytanie, które wartości oczekiwane różnią się między sobą. Odpowiedzi takiej udzielają testy po analizie wariancji, zwane porównaniami post-hoc.
 nie daje odpowiedzi na pytanie, które wartości oczekiwane różnią się między sobą. Odpowiedzi takiej udzielają testy po analizie wariancji, zwane porównaniami post-hoc.")
45
Testy po analizie wariancji
Porównania post-hoc są w istocie równoczesnym wykonaniem wielu testów. Jeśli pojedynczy test miałby poziom istotności , to poziom istotności wszystkich porównań mógłby być znacznie wyższy.

46
Testy po analizie wariancji
Wybór testu post-hoc zależy od porównań, jakie zamierzamy przeprowadzić. Jeśli porównujemy grupy z kontrolą, możemy użyć testu Dunnetta. Gdy chcemy dokonać porównań typu każdy z każdym przyda się nam test Tukeya (lub Tukeya-Kramera dla niejednakowo licznych grup).
.")
47
Testy post-hoc Wymienione testy zapewniają poziom istotności dla całego zbioru porównań.

48
Skale pomiarowe

49
Dyskretne zmienne losowe a skale pomiarowe.
Gdy zbiór zdarzeń elementarnych jest skończony, odwzorowywanie go w zbiór liczb (czyli tworzenie zmiennej losowej) może być mniej użyteczne niż w przypadku zmiennej losowej ciągłej.
 może być mniej użyteczne niż w przypadku zmiennej losowej ciągłej.")
50
Skala nominalna Jeśli zbiór zdarzeń elementarnych nie wykazuje naturalnego uporządkowania, mówimy o skali nominalnej Przykłady: grupa krwi (0,A,B,AB), rozpoznanie, czynnik etiologiczny, sympatie polityczne, wyznanie, narodowość, rasa...
, rozpoznanie, czynnik etiologiczny, sympatie polityczne, wyznanie, narodowość, rasa...")
51
Skala porządkowa Gdy w zbiorze zdarzeń istnieje naturalne uporządkowanie, ale wprowadzanie odległości nie ma sensu, mamy do czynienia ze skalą porządkową. Przykłady: wynik leczenia (pogorszenie,b.z., poprawa), wykształcenie (brak, podst., gimn., średnie, wyższe...), WBC (poniżej, w normie, powyżej)
, wykształcenie (brak, podst., gimn., średnie, wyższe...), WBC (poniżej, w normie, powyżej)")
52
Skala interwałowa (równomierna)
Gdy w skończonym zbiorze zdarzeń elementarnych istnieje odległość, pre-zentacja wyników w postaci zmiennej losowej jest w pełni uzasadniona. Przykłady: tętno, WBC (tys./mm3), liczba dzieci w rodzinie Gdy liczba możliwych wartości jest duża, traktujemy taką zmienną jako ciągłą.
, liczba dzieci w rodzinie. Gdy liczba możliwych wartości jest duża, traktujemy taką zmienną jako ciągłą.")
53
Skale pomiarowe Pojęcie skali pomiarowej ma zastosowa-nie nie tylko do zmiennych losowych (wyników pomiarów), ale także w odniesieniu do wielkości kontrolowanych w eksperymencie (czynników).
, ale także w odniesieniu do wielkości kontrolowanych w eksperymencie (czynników).")
54
Testy nieparametryczne

55
Testy zgodności rozkładów
Test dla zmiennych połączonych – test rang Wilcoxona. Zmienna losowa nie musi być zmienną ciągłą, ale może być zmienną porządkową. Dla zmiennych niepołączonych analogicznym testem jest test rang U – Manna-Whitney’a.

56
Nieparametryczne testy zgodności
Jak nieparametrycznie wyrazić hipotezy analogiczne do hipotez testu t-Studenta? Hipoteza zerowa: Hipotezy alternatywne: test jednostronny, np.: test dwustronny

57
Testy zgodności Rozszerzenia tych testów na porównanie większej liczby grup to: Test Kruskala-Wallisa dla zmiennych niepołączonych. Test Friedmana dla zmiennych połączonych.

58
Testy normalności Do badania, czy pomiary podlegają rozkładowi normalnemu służą testy: Lillieforsa Shapiro-Wilka D-Kołmogorowa-Smirnowa

59
Test zgodności z rozkładem teoretycznym
Test zgodności Kołmogorowa

60
Test Q-Dixona Test Q-Dixona służy do eliminacji pomiarów, co do których spodziewamy się błędu grubego. Może być źródłem nadużyć. Można go użyć do odrzucenia tylko jednego pomiaru w danej próbie.

61
Zmienne skategoryzowane
Pomiary o skali nominalnej lub porządkowej nazywamy zmiennymi skategoryzowanymi. Wyniki tego typu badań przedstawia się często w postaci tablicy kontyngencji.

62
Tablice kontyngencji

63
Tablice kontyngencji Podstawowym narzędziem badania takich tablic jest test niezależności Gdy oczekiwane liczebności w niektórych polach tabeli są małe (<5), stosuje się tzw. test dokładny (oryginalny test Pearsona opiera się na przybliżeniu słusznym przy dużych próbach).
, stosuje się tzw. test dokładny (oryginalny test . -Pearsona opiera się na przybliżeniu słusznym przy dużych próbach).")
64
Tablice kontyngencji Szczególnie często spotykamy tablice 2x2
Przykład: Mann i wsp. (1975)
")
65
Tablice kontyngencji – iloraz szans
szansa 1) p11/p12 2) p21/p22 iloraz szans (odds ratio)
 p11/p12. 2) p21/p22. iloraz szans (odds ratio)")
66
Iloraz szans Estymator ilorazu szans

67
W postępowaniu z takimi zmiennymi zaciera się często granica między czynnikiem a wynikiem. Iloraz szans nie zmieni się, gdy zamienimy wiersze z kolumnami.

68
Tablice kontyngencji zmienne połączone
Taką tabelę można badać testem McNemary.

69
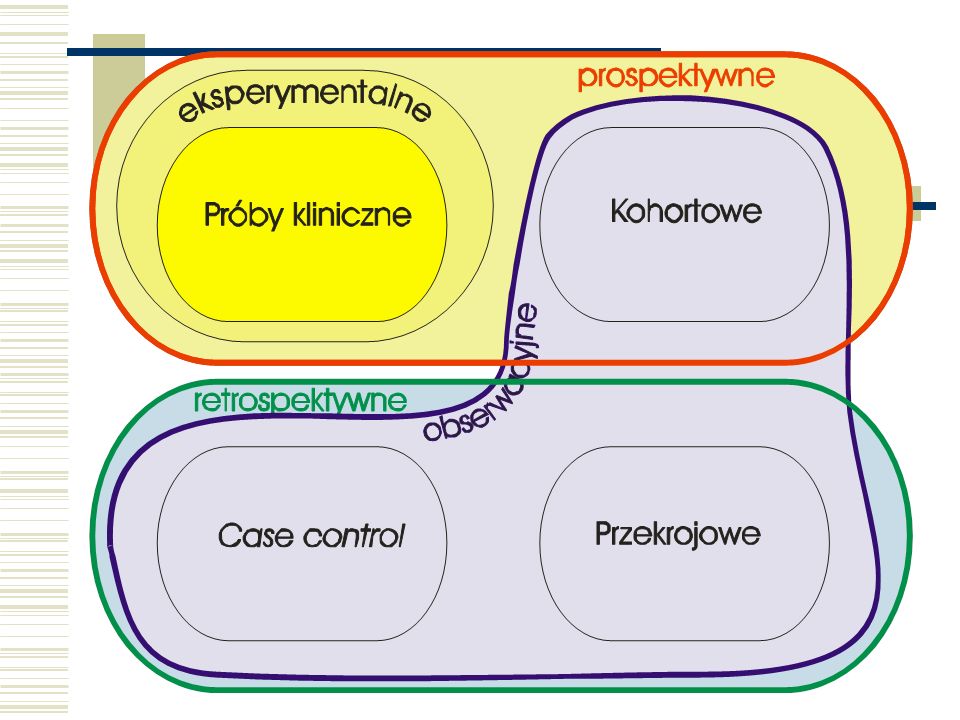
Typy badań w naukach medycznych
Badania eksperymentalne Badania obserwacyjne kohortowe case-control przekrojowe

71
Typy badań Badania prospektywne:
W badaniach eksperymentalnych przydzielamy obiekty do grup losowo (randomizacja) W badaniu kohortowym obiekt sam wybiera grupę
 W badaniu kohortowym obiekt sam wybiera grupę.")
72
Typy badań Badania retrospektywne
Case-control – wybieramy do badań pod-mioty, u których stwierdzono przynależność do grupy wynikowej (a ustalamy, jakim poziomom czynników objaśniających były poddane). Przekrojowe – podmioty wybieramy losowo z populacji generalnej i ustalamy zarówno grupę wynikową jak i czynniki objaśniające.
. Przekrojowe – podmioty wybieramy losowo z populacji generalnej i ustalamy zarówno grupę wynikową jak i czynniki objaśniające.")
73
Układy eksperymentalne analizy wariancji

74
Analiza wariancji Planowanie eksperymentu
Analiza jednoczynnikowa, p poziomów czynnika, dla każdego obiektu jest tylko jeden pomiar. Obiekty przydzielane są do grup w wyniku losowania. Taki plan eksperymentalny nazywa się układem kompletnie zrandomizowanym. Układ ten jest rozszerzeniem testu t-Stu-denta dla zmiennych niepołączonych. Była już o nim mowa.

75
Układ kompletnie zrandomizowany
Model: wynik pomiaru na obiekcie i w grupie j ogólna wartość oczekiwana efekt czynnika na poziomie j błąd losowy Zakładamy, że wszystkie błędy są wzajem-nie niezależne i mają taki sam rozkład normalny o wartości oczekiwanej 0:

76
Układ kompletnie zrandomizowany
Hipotezy ANOVA dla tego układu można teraz zapisać tak: H0: dla wszystkich j H1: istnieje takie j, że W wyniku analizy wariancji otrzymujemy estymaty i Dla jednoznaczności trzeba założyć, że:

77
Układ kompletnie zrandomizowany
Błąd losowy zawiera w sobie wpływ czynników niekontrolowanych w doświadczeniu, w tym zmienność międzyosobniczą jak i wewnątrzosobniczą. Inne układy eksperymentalne, jeśli mogą być zastosowane, służą zmniejszeniu tego błędu przez eliminację wpływu czynników zakłócających.

78
Układ bloków losowych Model: wynik pomiaru na obiekcie i w grupie j
ogólna wartość oczekiwana wpływ czynnika na poziomie j wpływ bloku i błąd losowy

79
Układ bloków losowych Układ ten jest rozszerzeniem testu t-Stu-denta dla zmiennych połączonych na przypadek wielu grup. Pozwala wyeliminować wpływ jednego źródła zakłóceń. Np. wykonując pomiary na tym samym osobniku eliminujemy wpływ zmienności międzyosobniczej.

80
Układ kwadratu łacińskiego
Układ ten pozwala wyeliminować wpływ dwóch czynników zakłócających ( ). Czynniki te muszą mieć tyle samo poziomów co czynnik będący przedmiotem badania. Model błędu jest tu bardziej skomplikowany.
. Czynniki te muszą mieć tyle samo poziomów co czynnik będący przedmiotem badania. Model błędu jest tu bardziej skomplikowany.")
81
Układ kwadratu łacińskiego
Obiekty przydziela się do grup (wyznaczonych przez kombinacje czynnika badanego i zakłócających) jak zwykle w wyniku losowania.
 jak zwykle w wyniku losowania.")
82
Układ kwadratu łacińskiego
B C D A B C D A B C D i jeszcze 573 inne możliwości...

83
Dwuczynnikowy układ kompletnie zrandomizowany
Model: wynik pomiaru na obiekcie i w grupie o poziomie j 1. czynnika i poz. k 2. czynnika ogólna wartość oczekiwana wpływ czynnika 1. na poziomie j wpływ czynnika 2. na poziomie k interakcja czynników 1 i 2 na poz. j oraz k błąd losowy

84
Dwuczynnikowy układ kompletnie zrandomizowany
W układzie tym możemy niezależnie weryfikować trzy hipotezy: H0: dla wszystkich j H0: dla wszystkich k H0(): dla wszystkich j oraz k Tabela analizy wariancji dla tego układu zawiera trzy różne statystyki F.
: dla wszystkich j oraz k. Tabela analizy wariancji dla tego układu zawiera trzy różne statystyki F.")
85
Dwuczynnikowy układ kompletnie zrandomizowany
Przykład: 1. czynnik – pracownik laboratorium 2. czynnik – przyrząd (np. mikroskop) W badaniu możemy niezależnie zweryfikować trzy hipotezy: H01: wynik badania nie zależy od laboranta H02: wynik badania nie zależy od przyrządu H0(12): nie ma interakcji między laborantem a przyrządem.
 W badaniu możemy niezależnie zweryfikować trzy hipotezy: H01: wynik badania nie zależy od laboranta. H02: wynik badania nie zależy od przyrządu. H0(12): nie ma interakcji między laborantem a przyrządem.")
86
Dwuczynnikowy układ kompletnie zrandomizowany
Możliwe przypadki interakcji: laborantowi najlepiej pracuje się na własnym mikroskopie laborant nie lubi jednego z mikroskopów

Podobne prezentacje









>")






 stanowi rozszerzenie testu t-Studenta w przypadku porównywanie większej liczby grup. Podział na grupy (czyli.>")


