Pobierz prezentację
1
Optymalizacja wybranych algorytmów przetwarzania obrazów przy użyciu zestawu instrukcji NEON dla urządzeń z procesorem ARM Promotor: dr hab. prof. WWSI Michał GrabowskiAutor: Piotr Hechelski

2
Plan prezentacji 1.Cel pracy 2.Architektura ARM i instrukcje NEON 3.Prezentacja aplikacji 4.Implementacja i optymalizacja algorytmów na przykładzie 2 efektów 5.Wyniki testów 6.Podsumowanie

3
Cel pracy Implementacja i optymalizacja wybranych algorytmów do nakładania efektów na zdjęcia w językach C#, C++ i C++ z instrukcjami NEON Stworzenie aplikacji na system Windows Phone 8 wykorzystującej zaimplementowane algorytmy Przeprowadzenie testów wydajnościowych na różnych urządzeniach

4
Architektura ARM Advanced RISC Machine – zredukowany zestaw instrukcji, 32 i 64 bitowa przestrzeń adresowa Systemy wbudowane i niewielkie urządzenia elektroniczne, niski pobór mocy

5
Instrukcje NEON (intrinsics) 64 i 128-bitowy zestaw instrukcji typu SIMD Instrukcje wywoływane z C++ po dołączeniu pliku nagłówkowego „arm_neon.h” Operacje na wektorach danych – max. 16 elementów int8x8_t int8x16_t int16x4_t int16x8_t int32x2_t int32x4_t int64x1_t int64x2_t

6
Wybrane efekty Sepia Dwa kolory Znajdowanie krawędzi Farby olejne

7
Działanie aplikacji DEMONSTRACJA

8
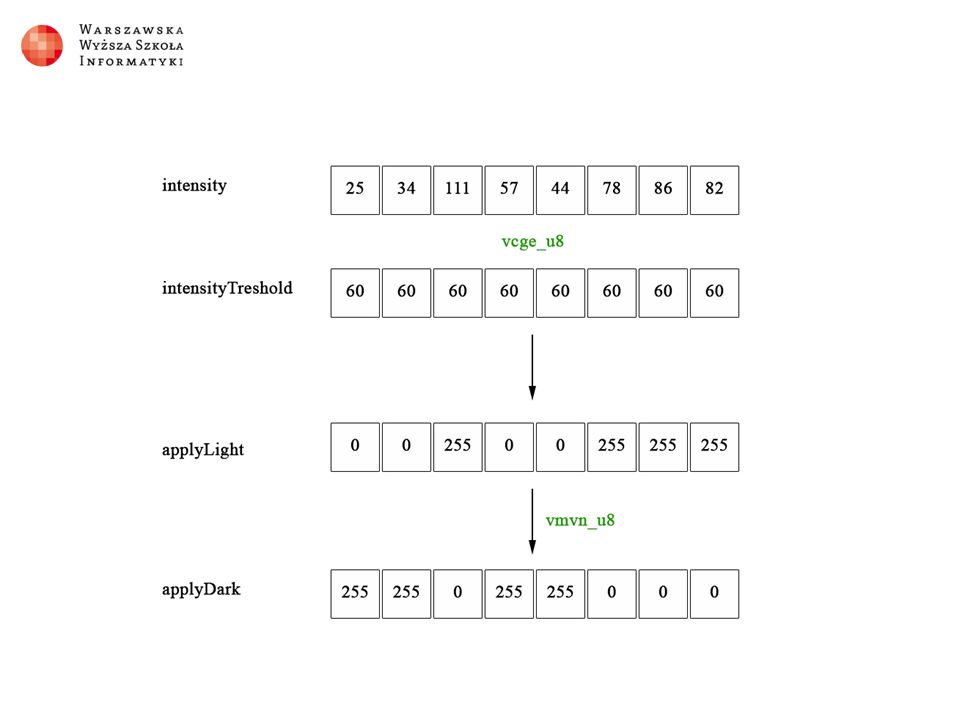
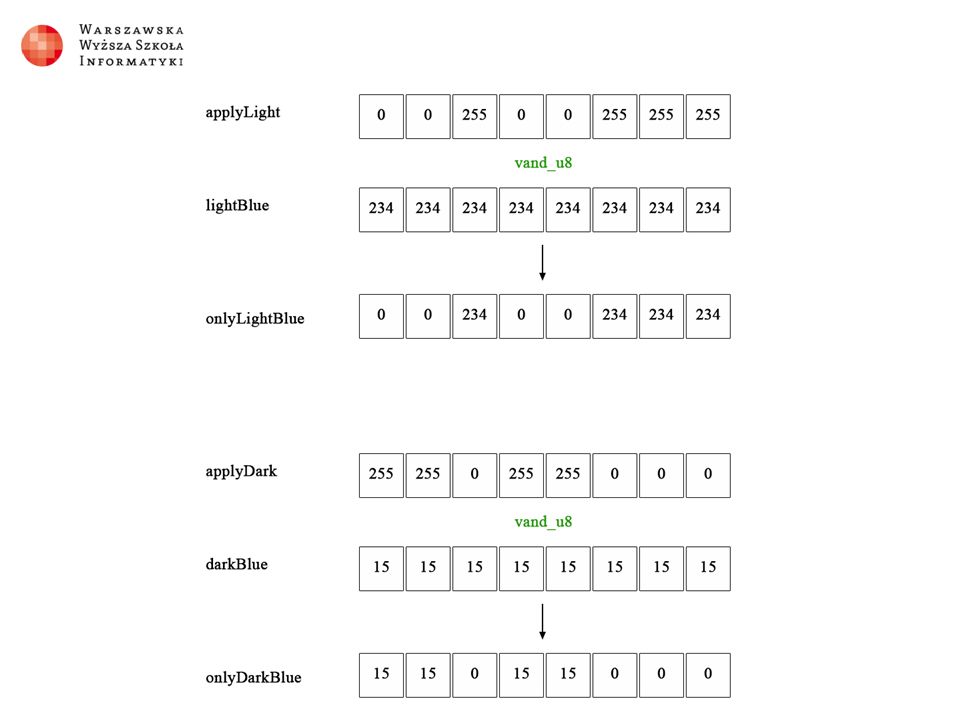
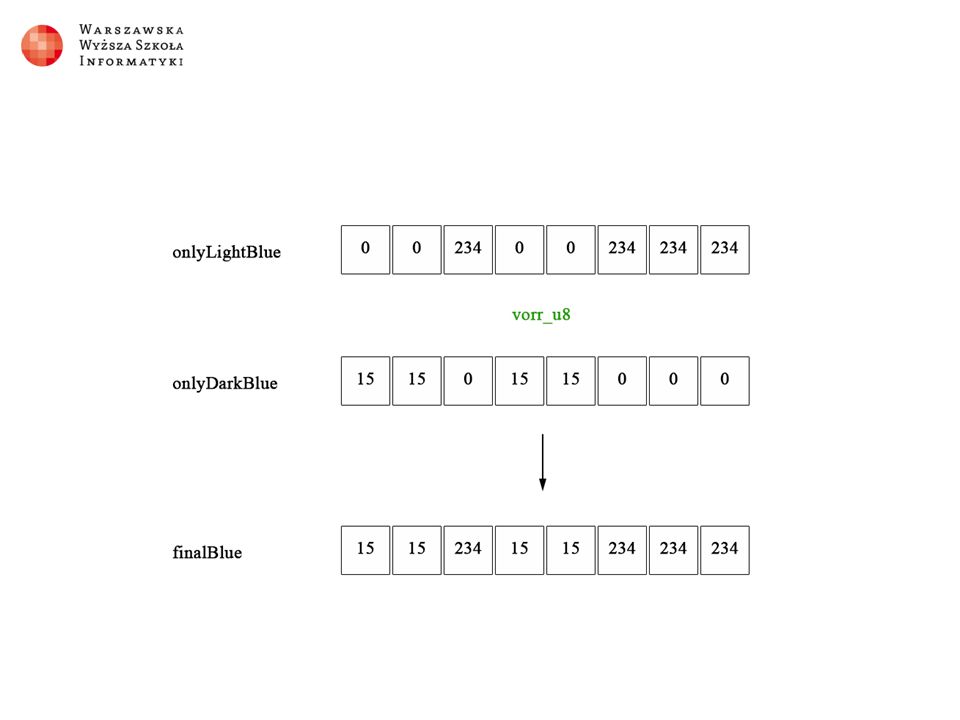
Efekt „Dwa kolory”

9
Implementacja w C# byte intensity = (byte)((red + green + blue) / 3); if (intensity >= IntensityTreshold) { source.PixelBuffer[i * 4] = LightColor.Blue; //overwrite blue source.PixelBuffer[i * 4 + 1] = LightColor.Green; //overwrite green source.PixelBuffer[i * 4 + 2] = LightColor.Red; //overwrite red } else { source.PixelBuffer[i * 4] = DarkColor.Blue; source.PixelBuffer[i * 4 + 1] = DarkColor.Green; source.PixelBuffer[i * 4 + 2] = DarkColor.Red; }
![Implementacja w C# byte intensity = (byte)((red + green + blue) / 3); if (intensity >= IntensityTreshold) { source.PixelBuffer[i * 4] = LightColor.Blue; //overwrite blue source.PixelBuffer[i * 4 + 1] = LightColor.Green; //overwrite green source.PixelBuffer[i * 4 + 2] = LightColor.Red; //overwrite red } else { source.PixelBuffer[i * 4] = DarkColor.Blue; source.PixelBuffer[i * 4 + 1] = DarkColor.Green; source.PixelBuffer[i * 4 + 2] = DarkColor.Red; }](http://images.slideplayer.pl/39/10948521/slides/slide_9.jpg "Implementacja w C# byte intensity = (byte)((red + green + blue) / 3); if (intensity >= IntensityTreshold) { source.PixelBuffer[i * 4] = LightColor.Blue; //overwrite blue source.PixelBuffer[i * 4 + 1] = LightColor.Green; //overwrite green source.PixelBuffer[i * 4 + 2] = LightColor.Red; //overwrite red } else { source.PixelBuffer[i * 4] = DarkColor.Blue; source.PixelBuffer[i * 4 + 1] = DarkColor.Green; source.PixelBuffer[i * 4 + 2] = DarkColor.Red; }")
10
Implementacja w NEONIE (R+G+B)/3 ≈ (R+G+B) * 85 >> 8 //załadowanie kanałów do tablicy wektorów uint8x8x4_t bgra = vld4_u8(pixels + i); //zsumowanie kanałów kolorów uint16x8_t tempIntensity = vaddw_u8(vaddl_u8(bgra.val[0], bgra.val[1]), bgra.val[2]); //wymnożenie przez liczbę 85 (multiplyNumber) tempIntensity = vmulq_u16(tempIntensity, multiplyNumber); //przesunięcie w prawo o 8 bitów (dzielenie przez 256) i zawężenie komórek z 16 bitów do 8 bitów uint8x8_t intensity = vshrn_n_u16(tempIntensity, 8);
![Implementacja w NEONIE (R+G+B)/3 ≈ (R+G+B) * 85 >> 8 //załadowanie kanałów do tablicy wektorów uint8x8x4_t bgra = vld4_u8(pixels + i); //zsumowanie kanałów kolorów uint16x8_t tempIntensity = vaddw_u8(vaddl_u8(bgra.val[0], bgra.val[1]), bgra.val[2]); //wymnożenie przez liczbę 85 (multiplyNumber) tempIntensity = vmulq_u16(tempIntensity, multiplyNumber); //przesunięcie w prawo o 8 bitów (dzielenie przez 256) i zawężenie komórek z 16 bitów do 8 bitów uint8x8_t intensity = vshrn_n_u16(tempIntensity, 8);](http://images.slideplayer.pl/39/10948521/slides/slide_10.jpg "Implementacja w NEONIE (R+G+B)/3 ≈ (R+G+B) * 85 >> 8 //załadowanie kanałów do tablicy wektorów uint8x8x4_t bgra = vld4_u8(pixels + i); //zsumowanie kanałów kolorów uint16x8_t tempIntensity = vaddw_u8(vaddl_u8(bgra.val[0], bgra.val[1]), bgra.val[2]); //wymnożenie przez liczbę 85 (multiplyNumber) tempIntensity = vmulq_u16(tempIntensity, multiplyNumber); //przesunięcie w prawo o 8 bitów (dzielenie przez 256) i zawężenie komórek z 16 bitów do 8 bitów uint8x8_t intensity = vshrn_n_u16(tempIntensity, 8);")
14
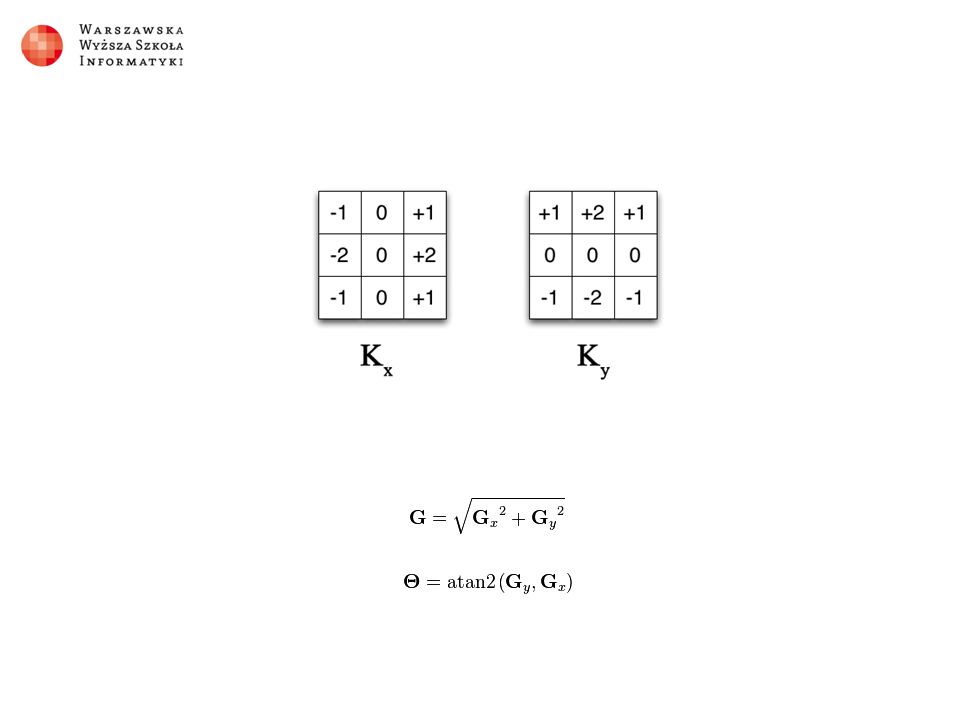
Efekt „znajdowanie krawędzi”

15
Koncepcja

17
Implementacja w NEONIE – wersja 1 1.Oblicz intensywność każdego piksela wykorzystując wektor danych (8 pikseli naraz) 2.Stwórz macierze sąsiednich intensywności i załaduj do 8- elementowego wektora, pomijając wartość środkową 3.Wykorzystaj macierze przekształceń załadowane do 8- elementowego wektora, pomijając wartość środkową
 2.Stwórz macierze sąsiednich intensywności i załaduj do 8- elementowego wektora, pomijając wartość środkową 3.Wykorzystaj macierze przekształceń załadowane do 8- elementowego wektora, pomijając wartość środkową")
18
//wymnóż wektory int16x8_t vectorMultiplied = vmulq_s16(kernelX, area); //po pierwszym zsumowaniu zostają 4 pary, a po drugim już tylko 2 int64x2_t pair = vpaddlq_s32(vpaddlq_s16(vectorMultiplied)); //zsumuj ostatnie dwa elementy int64_t gradientX = vgetq_lane_s64(pair, 0) + vgetq_lane_s64(pair, 1);
; //po pierwszym zsumowaniu zostają 4 pary, a po drugim już tylko 2 int64x2_t pair = vpaddlq_s32(vpaddlq_s16(vectorMultiplied)); //zsumuj ostatnie dwa elementy int64_t gradientX = vgetq_lane_s64(pair, 0) + vgetq_lane_s64(pair, 1);")
19
Implementacja w NEONIE – wersja 2 1.Oblicz intensywność każdego piksela wykorzystując wektor danych (8 pikseli naraz) 2.Wykorzystaj współbieżną pętlę przy tworzeniu macierzy sąsiednich intensywności i mnożeniu skalarnym macierzy. Wykorzystaj standardowe macierze przekształceń.

20
Concurrency::parallel_for(1, source->PixelHeight - 1, [source, buffer, &KernelX, &KernelY](int row) { for (int column = 1; column PixelWidth - 1; column++) { byte area[3][3] = { 0 }; area[0][0] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column - 1, source->PixelWidth)]; area[0][1] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column, source->PixelWidth)]; area[0][2] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column + 1, source->PixelWidth)]; (…) int gradientX = KernelX[0][0] * area[0][0] + KernelX[0][1] * area[0][2] + KernelX[1][0] * area[1][0] + KernelX[1][1] * area[1][2] + KernelX[2][0] * area[2][0] + KernelX[2][1] * area[2][2]; int gradientY = KernelY[0][0] * area[0][0] + KernelY[0][1] * area[0][1] + KernelY[0][2] * area[0][2] + KernelY[1][0] * area[2][0] + KernelY[1][1] * area[2][1] + KernelY[1][2] * area[2][2]; int gradient = (int)sqrt((double)(gradientX * gradientX + gradientY * gradientY)); int pixelOffset = source->GetPixelOffset(row, column); source->PixelBuffer[pixelOffset] = source->PixelBuffer[pixelOffset + 1] = source->PixelBuffer[pixelOffset + 2] = MathHelper::ClampToByte(gradient); } });
 { for (int column = 1; column PixelWidth - 1; column++) { byte area[3][3] = { 0 }; area[0][0] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column - 1, source->PixelWidth)]; area[0][1] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column, source->PixelWidth)]; area[0][2] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column + 1, source->PixelWidth)]; (…) int gradientX = KernelX[0][0] * area[0][0] + KernelX[0][1] * area[0][2] + KernelX[1][0] * area[1][0] + KernelX[1][1] * area[1][2] + KernelX[2][0] * area[2][0] + KernelX[2][1] * area[2][2]; int gradientY = KernelY[0][0] * area[0][0] + KernelY[0][1] * area[0][1] + KernelY[0][2] * area[0][2] + KernelY[1][0] * area[2][0] + KernelY[1][1] * area[2][1] + KernelY[1][2] * area[2][2]; int gradient = (int)sqrt((double)(gradientX * gradientX + gradientY * gradientY)); int pixelOffset = source->GetPixelOffset(row, column); source->PixelBuffer[pixelOffset] = source->PixelBuffer[pixelOffset + 1] = source->PixelBuffer[pixelOffset + 2] = MathHelper::ClampToByte(gradient); } });](http://images.slideplayer.pl/39/10948521/slides/slide_20.jpg "Concurrency::parallel_for(1, source->PixelHeight - 1, [source, buffer, &KernelX, &KernelY](int row) { for (int column = 1; column PixelWidth - 1; column++) { byte area[3][3] = { 0 }; area[0][0] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column - 1, source->PixelWidth)]; area[0][1] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column, source->PixelWidth)]; area[0][2] = buffer[GetPixelOffsetInGrayScaleArray(row - 1, column + 1, source->PixelWidth)]; (…) int gradientX = KernelX[0][0] * area[0][0] + KernelX[0][1] * area[0][2] + KernelX[1][0] * area[1][0] + KernelX[1][1] * area[1][2] + KernelX[2][0] * area[2][0] + KernelX[2][1] * area[2][2]; int gradientY = KernelY[0][0] * area[0][0] + KernelY[0][1] * area[0][1] + KernelY[0][2] * area[0][2] + KernelY[1][0] * area[2][0] + KernelY[1][1] * area[2][1] + KernelY[1][2] * area[2][2]; int gradient = (int)sqrt((double)(gradientX * gradientX + gradientY * gradientY)); int pixelOffset = source->GetPixelOffset(row, column); source->PixelBuffer[pixelOffset] = source->PixelBuffer[pixelOffset + 1] = source->PixelBuffer[pixelOffset + 2] = MathHelper::ClampToByte(gradient); } });")
21
Wyniki testów – zdjęcie 1280x720

22
Podsumowanie - metody optymalizacji Współbieżne pętle (Concurrency::parallel_for) Wykorzystanie instrukcji NEON Mnożenie i przesunięcie bitów wyniku w prawo zamiast dzielenia Operacje na pikselach wykonywane w osobnym wątku Stosowanie typów prostych w złożonych algorytmach (WinRT) Implementacja algorytmów w językach natywnych (np. C++) zamiast w językach kompilowanych do kodu bajtowego (np. C#, Java)
 zamiast w językach kompilowanych do kodu bajtowego (np. C#, Java).")
23
Podsumowanie – co zostało wykonane Implementacja 4 efektów – sepia, dwa kolory, znajdowanie krawędzi i farby olejne – w C#, C++ i C++ z instrukcjami NEON Aplikacja na Windows Phone 8 wykorzystująca algorytmy efektów do nakładania na zdjęcia oraz testująca ich wydajność Testy wydajnościowe algorytmów Analiza sposobów optymalizacji algorytmów