Pobierz prezentację
1
Wykład 2 Wrocław, 11 X 2006 Wpływ przekształceń
Co się stanie ze średnią i odchyleniem standardowym gdy zmienimy jednostki ? stopnie Celsiusza stopnie Fahrenheita dolary 1,000 dolarów wartość faktyczna odległość od minimum cm : mm, in, nm, m, ft; dolary : euro

2
Zmiana wartości wynikająca ze zmiany jednostek dana jest zwykle funkcją liniową: y’ = ay + c
Przykłady: y’ = 1.8 y + 32 y’ = 1/1000 y ( + 0) y’ = (1)y - ymin
 y’ = (1)y - ymin.")
3
Liniowa transformacja zmiennych, cd.
Funkcja liniowa nie zmienia w zasadniczy sposób kształtu histogramu. Może go rozszerzyć (|a| >1), ścieśnić (|a|<1), przesunąć (c<>0) i obrócić (a<0).
, ścieśnić (|a|<1), przesunąć (c<>0) i obrócić (a<0).")
4
Wpływ stałej (odejmujemy 20)
Dev. y’ Dev 25 -1 5 26 6 28 2 8 Średnia

5
Liniowa transformacja zmiennych, cd.
Średnia zmienia się tak jak y. Mamy: y’ = ay + c Odchylenie standardowe s zmienia się tylko w zależności od współczynnika a. Stała c nie ma wpływu na odchylenie standardowe, ponieważ zależy ono jedynie od odchyleń od średniej. Mamy: s’ = |a| s

6
Liniowa transformacja zmiennych, cd.
Wariancja próbkowa Wariancja jest kwadratem SD. Mamy: s2’ = a2s2 Przykład: Y- temperatura w F: = 98.6, s = 0.9, s2 = 0.81 Pytanie 1: Oblicz średnią, odchylenie standardowe i wariancję dla tych samych danych wyrażonych w stopniach Celsjusza.

7
Odpowiedź

8
Standardyzacja Pytanie 2: Jakich wyników należy oczekiwać, gdy dane przekształcimy w następujący sposób Y' = (Y- )/s =(Y-98.6)/0.9 ? Jest to transformacja liniowa: Y' = 1/s Y - y/s. Odpowiedź:
/s =(Y-98.6)/0.9 Jest to transformacja liniowa: Y = 1/s Y - y/s. Odpowiedź:")
9
Liniowa transformacja zmiennych: inne statystyki
Funkcja liniowa zmienia: medianę i kwartyle tak jak średnią, rozstęp i IQR tak jak odchylenie standardowe.

10
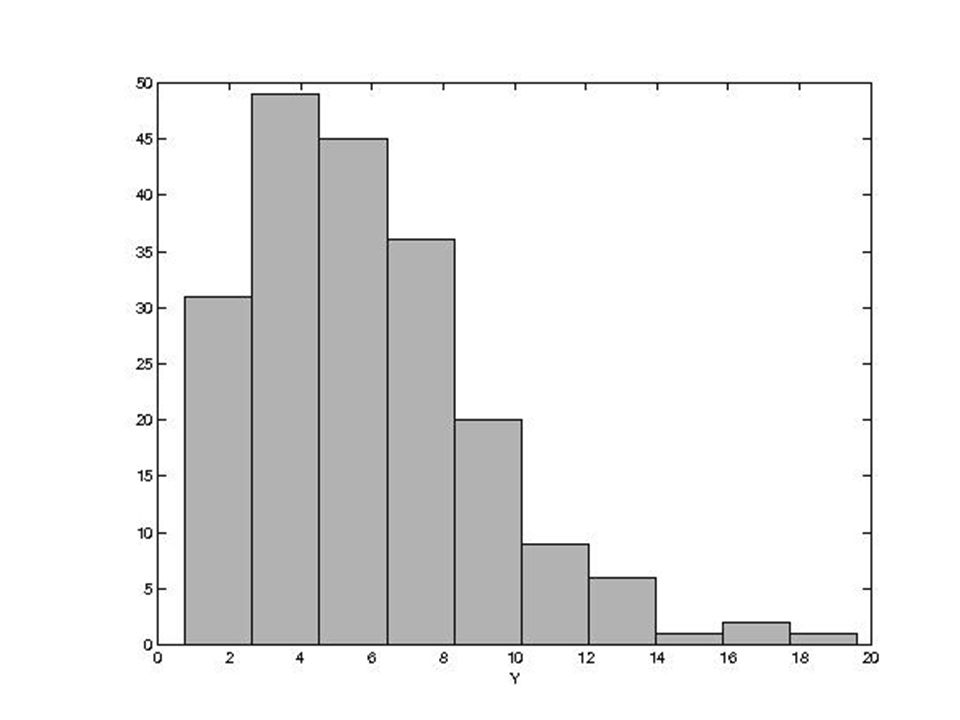
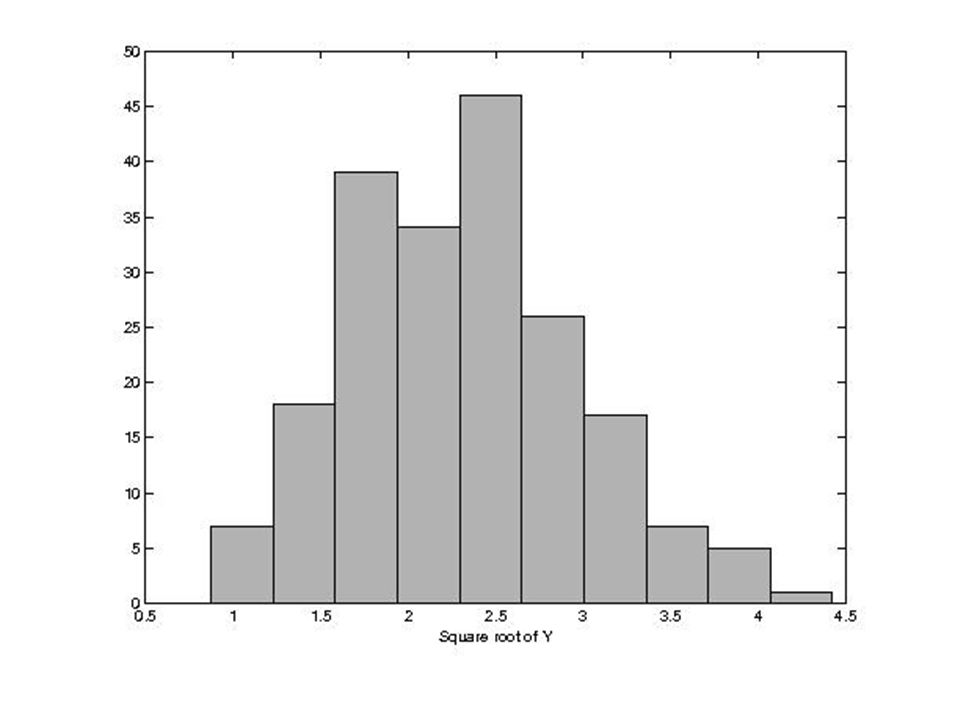
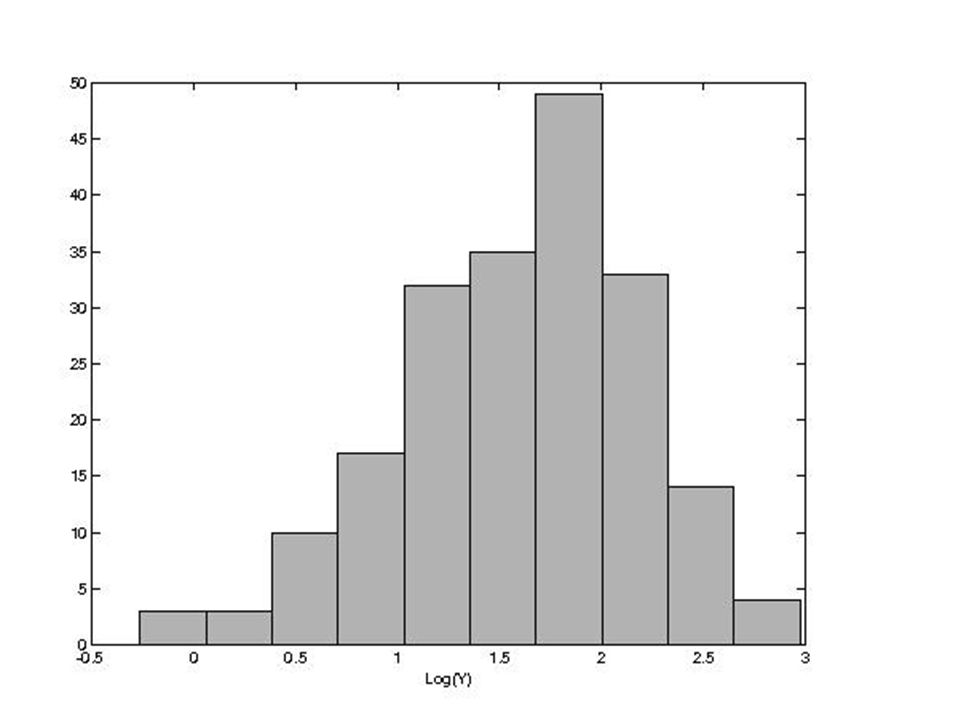
Transformacje nieliniowe
Funkcje nieliniowe (np. logarytm) zmieniają kształt histogramu i na ogół nie ma dla nich prostych formuł umożliwiających obliczenie nowej średniej i nowego odchylenia standardowego. Parametry te liczymy z definicji korzystając z „nowego’’ zbioru danych. Przykład : dla Y’=log(Y) na ogóły’ ≠ logy Z medianą i kwartylami jest lepiej... Czasami używamy funkcji nieliniowych, aby przekształcić skośne dane w bardziej symetryczne.
 zmieniają kształt histogramu i na ogół nie ma dla nich prostych formuł umożliwiających obliczenie nowej średniej i nowego odchylenia standardowego. Parametry te liczymy z definicji korzystając z „nowego’’ zbioru danych. Przykład : dla Y’=log(Y) na ogóły’ ≠ logy. Z medianą i kwartylami jest lepiej... Czasami używamy funkcji nieliniowych, aby przekształcić skośne dane w bardziej symetryczne.")
14
Wnioskowanie statystyczne Próba a populacja
Zbiór, z którego losujemy próbę i który chcemy opisać. Czasami rzeczywista, czasami abstrakcyjna (np. „nieskończenie duża próba”) . Próba: Podzbiór populacji. Próba powinna być reprezentatywna dla populacji. Wnioskowanie statystyczne: Wnioskowanie o populacji w oparciu o próbę.
 . Próba: Podzbiór populacji. Próba powinna być reprezentatywna dla populacji. Wnioskowanie statystyczne: Wnioskowanie o populacji w oparciu o próbę.")
15
Populacja Próba , Grupa wykładowa 10 losowo wybranych studentów
Wszyscy pacjenci biorący Prozac 30 pacjentów biorących Prozac ``wszystkie’’ rzuty kostkami 25 rzutów kostką Wszystkie owocówki ze śmietnika, albo Wszystkie owocówki w okolicy Owocówki złapane na śmietniku Populacja Próba y s Próbkowanie Wnioskowanie Parametry : , Statystyki

16
Parametry populacji μ = średnia w populacji, μ=EY, wartość oczekiwana zmiennej Y σ = odchylenie standardowe w populacji, σ =(Var Y)1/2, ...i inne. Statystyki z próby są estymatorami, służą do oceny parametrów całej populacji.
1/2, ...i inne. Statystyki z próby są estymatorami, służą do oceny parametrów całej populacji.")
17
Przykład Grupy krwi u 3696 osób żyjących w Anglii.
Około 44% ludzi w próbie ma grupę krwi A. A w Anglii?? Czy nie było systematycznego błędu przy próbkowaniu? Czy rozmiar próby był dość duży? Grupa krwi Liczność A 1,634 B 327 AB 119 O 1616 suma 3696

18
Możliwe błędy przy próbkowaniu:
Próba złożona z przyjaciół i pracowników może nie być reprezentatywna. Mimo tego... Grupy krwi mogą być reprezentatywne. Ale już... Pomiary ciśnienia nie byłyby reprezentatywne (ciśnienie na ogół wzrasta z wiekiem).
.")
19
Populacja a próba Średnia z próbyy na ogół różni się od wartości oczekiwanej μ=EY (średniej w populacji), ale w miarę wzrostu rozmiaru próby różnica między tymi wielkościami zwykle dąży do zera (Mocne Prawo Wielkich Liczb). Średnia z próby jest estymatorem wartości oczekiwanej. Podobnie próbkowe odchylenie standardowe s i wariancja próbkowa s2 są estymatorami odpowiednich parametrów w populacji: σ i σ2=Var Y.
, ale w miarę wzrostu rozmiaru próby różnica między tymi wielkościami zwykle dąży do zera (Mocne Prawo Wielkich Liczb). Średnia z próby jest estymatorem wartości oczekiwanej. Podobnie próbkowe odchylenie standardowe s i wariancja próbkowa s2 są estymatorami odpowiednich parametrów w populacji: σ i σ2=Var Y.")
20
Przykład Rozmiar populacji=50, średnia w populacji =26.48
Dane: stopniowo powiększamy próbę losową do rozmiarów n=10, 20, 30, 40 otrzymana średnia z próby: 23.5 (dla n=10), 27.3 (n=20), 26.7 (n=30), 26.4 (n=40)
, 27.3 (n=20), 26.7 (n=30), 26.4 (n=40)")
21
Histogram z populacji a histogram próbkowy
Dane dyskretne (klasy) Oznaczamy: pi=frakcja (częstość) osobników w całej populacji w i-tej kategorii. pi można ustalić w oparciu o histogram skonstruowany dla całej populacji. Oznaczamy: = estymator obliczony w oparciu o histogram z próby (zaobserwowana częstość w danej kategorii).
 Oznaczamy: pi=frakcja (częstość) osobników w całej populacji w i-tej kategorii. pi można ustalić w oparciu o histogram skonstruowany dla całej populacji. Oznaczamy: = estymator obliczony w oparciu o histogram z próby (zaobserwowana częstość w danej kategorii).")
22
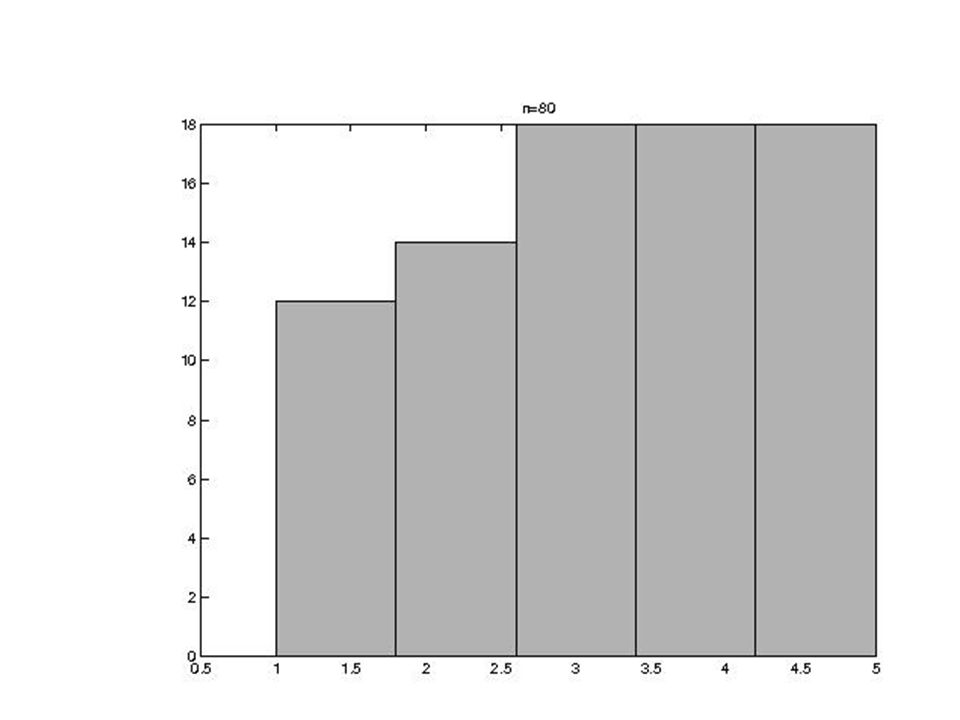
Przykład Rozmiar populacji = klas o tej samej częstości pi= (?). W tabeli tylko kategorie 1. i 5. n 10 0.1 0.3 20 0.35 40 0.2 0.25 80 0.15 0.225 160 0.1625 0.1875 320 0.1781 0.1938

23
n=10

26
Próbkowanie, cd. Prosta próba losowa:
Każdy osobnik z populacji może być wybrany z tym samym prawdopodobieństwem. Wybory poszczególnych osobników są od siebie niezależne.

27
Jak wybrać prostą próbę losową:
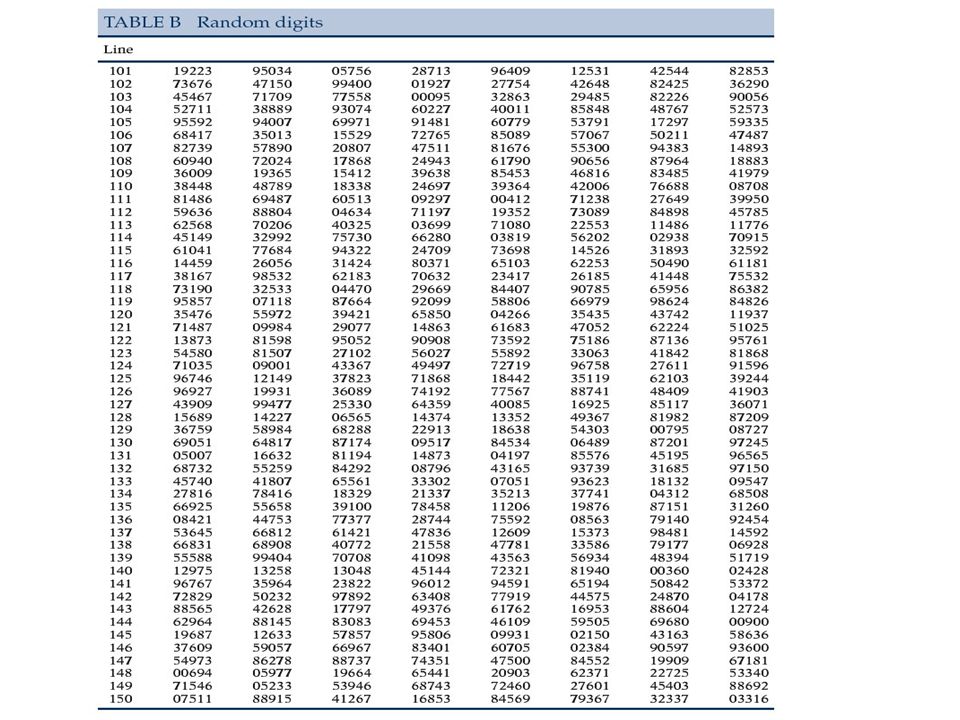
Mechanizm losujący, np.: Przyznajemy numer każdemu osobnikowi Zapisujemy numery na kulach Mieszamy kule w urnie Losujemy kule=numery=osobników, tyle razy, ile wynosi rozmiar próby Do losowania możemy również użyć komputera lub gotowej tablicy liczb (numerów) losowych (zob. dalej). Gdy rozmiar populacji nie jest ustalony lub nie mamy dostępu do wszystkich osobników, zadanie jest dużo trudniejsze.
 losowych (zob. dalej). Gdy rozmiar populacji nie jest ustalony lub nie mamy dostępu do wszystkich osobników, zadanie jest dużo trudniejsze.")
29
Błędy w póbkowaniu, cd, Przykład 1 (Ochotnicy)
Dziennikarka Ann Landers spytała swoich czytelników „Gdybyście mogli zacząć je-szcze raz: czy mielibyście znowu dzieci?” Odpisało prawie 10,000 czytelników i 70% powiedziało: Nie! Populacja: wszyscy rodzice w USA

30
Przykład 1 (Ochotnicy) cd.
Próba: pewna część populacji, która zdecydowała się odpisać, n=10,000. Czasopismo Newsday przeprowadziło „statystycznie zaplanowaną” ankietę, w której 91% z 1,373 przepytanych rodziców odpowiedziało: Tak! Ochotnicy: bardzo zła reprezentatywność (badanie bezwartościowe).
.")
31
Przykład 2 Przewidywanie wyników wyborów prezydenckich w USA, 1936:
Literary Digest wysłało kwestionariusze do 10 milionów ludzi (25% głosujących) Odpowiedziało 2.4 miliona: Przewidywanie: Landon 57%, Roosevelt 43% Wynik wyborów: Roosevelt 62%, Landon 38% Uwagi: F.D. Roosevelt, Partia Demokratyczna, prezydent w latach ; Wielki Kryzys:
 Odpowiedziało 2.4 miliona: Przewidywanie: Landon 57%, Roosevelt 43% Wynik wyborów: Roosevelt 62%, Landon 38% Uwagi: F.D. Roosevelt, Partia Demokratyczna, prezydent w latach ; Wielki Kryzys:")
32
Przyczyny błędu Literary Digest:
Złe (dyskryminujące) próbkowanie Użyto książek telefonicznych, list członkowskich klubów, listy zamówień pocztowych, listy właścicieli pojazdów Brak odpowiedzi Tylko 24% odpowiedziało (niemal wyłącznie Republikanie) Uwaga: George Gallup przewidział poprawnie na podstawie reprezentatywnej próbki osób.
 próbkowanie. Użyto książek telefonicznych, list członkowskich klubów, listy zamówień pocztowych, listy właścicieli pojazdów. Brak odpowiedzi. Tylko 24% odpowiedziało (niemal wyłącznie Republikanie) Uwaga: George Gallup przewidział poprawnie na podstawie reprezentatywnej próbki osób.")
33
Obciążenie w próbkowaniu
Obciążenie w próbkowaniu występuje, gdy mamy do czynienia z systematycznym błędem faworyzującym pewną część populacji. W przypadku takiego obciążenia nie pomoże nawet duży rozmiar próby. Losowy wybór elementów do próby zwykle eliminuje takie obciążenie.

34
Warianty losowego wyboru: Stratyfikacja
Dzielimy populację na pod-populacje podobnych jednostek (warstwy) i oddzielnie próbkujemy w każdej warstwie. Przykłady warstw: studenci & studentki grupy zawodowe regiony geograficzne
 i oddzielnie próbkujemy w każdej warstwie. Przykłady warstw: studenci & studentki. grupy zawodowe. regiony geograficzne.")
35
Podstawowe metody estymacji (patrz tablica)
Metoda momentów Metoda największej wiarogodności












 Miary asymetrii.>")









