ANALIZA WSPÓŁZALEŻNOŚCI W wielu badaniach gromadzimy dane będące liczebnościami. Na przykład możemy klasyfikować chorych w badanej próbie do różnych kategorii pod względem wieku, płci czy natężenia choroby, czyli kilku badanych cech. Przedstawiane do tej pory metody statystyczne stają się użyteczne dla danych jednej cechy. Techniki statystyczne omówione poniżej należą do najbardziej przydatnych w analizie danych jakościowych i ilościowych. Umożliwiają one dokonanie oceny zależności między zmiennymi tego typu.
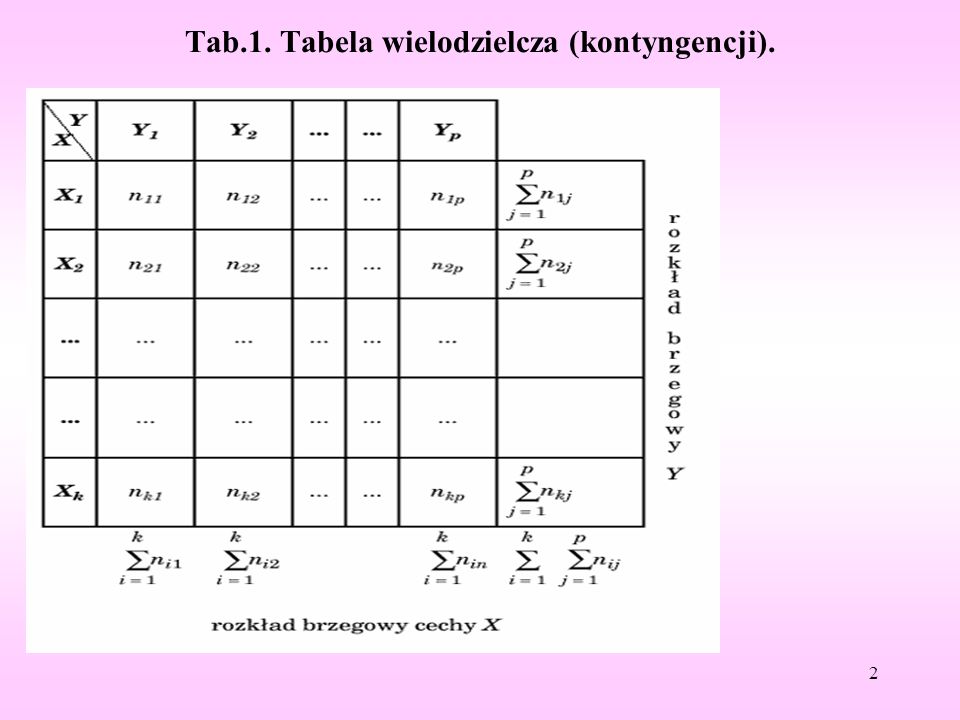
Tab.1. Tabela wielodzielcza (kontyngencji).
Tab.2. Przykład tabeli wielodzielczej Grupa Kobiety Mężczyźni Razem n % Cukrzyca 25 35,7 20 40,0 45 37,5 Bez cukrzycy 64,3 30 60,0 75 62,5
Tabele wielodzielcze (kontyngencji). Pierwszym krokiem jest przedstawienie zebranych danych indywidualnych w postaci tabeli wielodzielczej (kontyngencji). Wymaga to zliczenia jednostek w odpowiednich komórkach tabeli. Zliczanie to bez użycia komputera jest żmudne, zwłaszcza dla dużej liczby przypadków. Tabele wielodzielcze stanowią podstawę do obliczania pozostałych statystyk określających siłę związku. Tabela wielodzielcza przedstawia rozkład obserwacji ze względu na kilka cech jednocześnie. Załóżmy, że dysponujemy n obserwacjami dla jakościowej cechy X (posiadającej kategorie X1, X2, ... Xk) i jakościowej cechy Y (o kategoriach Y1, Y2, ...Yp) (tab. 1). Liczebności nij określają liczbę elementów próby, dla których cecha X ma wariant Xi i jednocześnie cecha Y - wariant Yj. Tablica wielodzielcza pokazuje więc określony łączny rozkład obu cech. Liczebności w ostatnim wierszu i w ostatniej kolumnie nazywamy empirycznymi, odpowiednio cechy Y i cechy X. Na przykład, chcąc ocenić wpływ używek (papieros, kawa, alkohol) na pewną chorobę, zebraliśmy dane na temat ich używania w grupie 90-osobowej. Zastosowano podział na 4 kategorie: nigdy (tzn. nie używano nigdy), niewiele (używano w małych ilościach), średnio (używano w średnich ilościach) i dużo (używano w dużych ilościach).
Lp. Kawa Papierosy Alkohol Płeć 1 nigdy dużo niewiele m 2 3 średnio k 4 5 6 7 8 srednio 9 10 Zliczając otrzymane dane dla papierosów i płci, otrzymamy następującą tabelę wielodzielczą (tab. 3)
Tabela 3 Płeć Papieros nigdy Papieros niewiele Papieros średnio Papieros dużo Razem Kobieta 11 8 6 5 30 Mężczyzna 4 28 24 60 15 12 34 29 90 Widać wyraźną przewagę mężczyzn w grupie palących dużą lub średnią liczbę papierosów, natomiast około 3-krotnie więcej kobiet niż mężczyzn nigdy nie paliło. Informacje byłyby bogatsze po dołączeniu danych odsetkowych. Odsetki wylicza się względem: ostatniej rubryki (płci), ostatniego wiersza (liczby wypalanych papierosów) oraz całkowitej liczby respondentów. Następny etap analizy statystycznej tak zebranych danych to próba weryfikacji hipotezy, że dwie jakościowe cechy w populacji są niezależne.
Współzależność cech – cechy jakościowe
Najczęściej stosowanym narzędziem jest test chi-kwadrat Najczęściej stosowanym narzędziem jest test chi-kwadrat. Został on opracowany przez Karla Pearsona w 1900 roku i jest metodą, dzięki której można się upewnić, czy dane zawarte w tabeli wielodzielczej dostarczają wystarczającego dowodu na związek tych dwóch zmiennych. Test chi-kwadrat polega na porównaniu liczebności zaobserwowanych z oczekiwanymi przy założeniu hipotezy o braku związku między tymi dwiema zmiennymi. Liczebności (częstości) oczekiwane obliczamy, wykorzystując liczebności brzegowe(z tablicy wielodzielczej) według następującego wzoru: Wówczas hipotezę o tym, że cechy X i Y są niezależne, możemy zweryfikować testem według następującego schematu:
Weryfikacja hipotezy zerowej: H0: cechy X i Y są niezależne Wobec hipotezy alternatywnej: H1: cechy X i Y są zależne Do weryfikacji hipotezy stosujemy statystykę: Otrzymaną wartość należy porównać z wartością krytyczną chi-kwadrat o (k - 1)·(p - 1) stopniach swobody
Korzystanie z badań profilaktycznych Na przykład: zapytano 260 osób o to, czy korzystają z bezpłatnych darmowych badań profilaktycznych dowolnego typu. Zebrane dane przedstawiono w wielodzielczej tabeli 4. Czy istnieje zależność między korzystaniem z takiej oferty i miejscem zamieszkania? Tabela 4 Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 20 45 63 128 Miasto 40 52 132 60 97 103 260
Korzystanie z badań profilaktycznych Wyliczymy liczebności oczekiwane. Wyniki obliczeń pozostałych liczebności oczekiwanych przedstawiono w tabeli w nawiasach obok wartości obserwowanych. Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 29,54 47,75 50,71 128 Miasto 30,46 49,25 52,29 132 60 97 103 260 A jak się to liczy? Mnożymy sumę z wiersza i sumę z kolumny (patrzymy po brzegach), następnie dzielimy przez liczbę wszystkich elementów (tu 260).
Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 60*128 260 97*128 103*128 128 Miasto 60*132 97*132 103*132 132 60 97 103 I stąd jest Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 29,54 47,75 50,71 128 Miasto 30,46 49,25 52,29 132 60 97 103 260
Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś Następny krok to porównanie liczebności empirycznych i teoretycznych, a końcowym efektem jest obliczona wartość statystyki chi-kwadrat. Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 3,08 0,16 2,98 6,22 Miasto 2,99 0,15 2,89 6,03 6,07 0,31 5,87 12,25 A jak się to liczy? We wnętrzu tabeli: liczebność empiryczna minus teoretyczna, podnosimy do kwadratu, dzielimy przez teoretyczną. Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś (20-29,54)2 29,54 (45-47,75)2 47,75 (63-50,71)2 50,71 6,22 Miasto (40-30,36)2 30,46 (52-49,25)2 49,25 (40-52,29)2 52,29 6,03 6,07 0,31 5,87 12,25
W takiej sytuacji formułujemy wniosek końcowy: Tak więc wartość obliczona chi-kwadrat = 12,25 Wartość odczytana wynosi (dla poziomu istotności 0,05 i (3–1)*(2–1)) stopni swobody = 5,991 Wartość obliczona > wartość krytyczna (odczytana) 12,25 > 5,991 W takiej sytuacji formułujemy wniosek końcowy: Istnieje zależność między miejscem zamieszkania a częstotliwością korzystania z badań profilaktycznych. A teraz szukamy największych rozbieżności między liczebnościami empirycznymi i teoretycznymi, np.: Miejsce zamieszkania Korzystanie z badań profilaktycznych często rzadko nigdy Wieś 20-29,54 45-47,75 63-50,71 Miasto 40-30,36 52-49,25 40-52,29
Korzystanie z badań profilaktycznych Miejsce zamieszkania Korzystanie z badań profilaktycznych często rzadko nigdy Wieś 20-29,54 45-47,75 63-50,71 Miasto 40-30,36 52-49,25 40-52,29 Zauważmy, że mieszkańcy wsi częściej przyznawali, ze nigdy nie korzystali z badań profilaktycznych (63 wobec 50,71). Mieszkańcy miast w większym stopniu niż można się było spodziewać przyznawali, że często korzystają z badań profilaktycznych (40 wobec 30,36). Zauważmy, że bardzo duże wartości chi-kwadrat obliczonego oznaczają dużą różnicę pomiędzy częstościami obserwowanymi a oczekiwanymi, i jest to dowód istnienia zależności. Przeciwnie mała wartość (zwłaszcza bliska 0) nie daje dowodu na istnienie korelacji.
Współzależność cech – cechy ilościowe
MIARY WSPÓŁZALEŻNOŚCI Do badania zależności między zmiennymi X i Y wykorzystuje się najczęściej współczynnik korelacji liniowej Pearsona, będący miarą siły związku prostoliniowego między dwiema cechami mierzalnymi. Współczynnik ten wylicza się ze wzoru: gdzie: cov(x,y) - kowariancja zmiennych X i Y s - odchylenie standardowe.
Wartość korelacji (współczynnik korelacji) nie zależy od jednostek miary, w jakich wyrażamy badane zmienne, np. korelacja pomiędzy wzrostem i ciężarem będzie taka sama bez względu na to, w jakich jednostkach (cale i funty czy centymetry i kilogramy) wyrazimy badane wielkości.
Kowariancja jest średnią arytmetyczną iloczynu odchyleń zmiennych X i Y od ich średnich arytmetycznych: Rozpatrując kowariancję uzyskać można następujące informacje o istniejącym związku pomiędzy zmiennymi X i Y: Jeżeli cov(x,y)>0 – dodatnia korelacja Jeżeli cov(x,y)<0 – ujmena korelacja Jeżeli cov(x,y)=0 – brak korelacji
Kowariancji nie można stosować do bezpośrednich porównań Kowariancji nie można stosować do bezpośrednich porównań. Dlatego jest ona standaryzowana przez odchylenia standardowe, dzięki czemu otrzymuje się współczynnik korelacji liniowej Pearsona. Właściwości współczynnika korelacji: Przyjmuje wartości z przedziału <-1;1> Dodatni znak świadczy o dodatnim, zaś ujemny o ujemnym związku korelacyjnym Im tym związek korelacyjny jest silniejszy.
W sytuacji, gdy wraz ze wzrostem (spadkiem) wartości jednej zmiennej następuje wzrost (spadek) warunkowych średnich drugiej zmiennej, wówczas można stwierdzić istnienie korelacji dodatniej między zmiennymi. W sytuacji, kiedy występuje przeciwny kierunek zmian, można mówić o korelacji ujemnej.
Znak informuje o kierunku zależności r>0 r<0 Korelacja dodatnia Korelacja ujemna Moduł informuje o sile zależności r=1 r=0,5 r=0
Sposoby komentowania współczynnika korelacji: - współzależność nie występuje, - słaby stopień współzależności, - umiarkowany (średni) stopień współzależności, - znaczny stopień współzależności, - wysoki stopień współzależności, - bardzo wysoki stopień - całkowita (ścisła) współzależność (zależność funkcyjna pomiędzy badanymi cechami).
Pomiędzy zmiennymi jest silna dodatnia korelacja Lp. x y 1 22 16 -17,8 -6,6 316,84 43,56 117,48 2 26 17 -13,8 -5,6 190,44 31,36 77,28 3 45 5,2 3,4 27,04 11,56 17,68 4 37 24 -2,8 1,4 7,84 1,96 -3,92 5 28 -11,8 -0,6 139,24 0,36 7,08 6 50 21 10,2 -1,6 104,04 2,56 -16,32 7 56 32 16,2 9,4 262,44 88,36 152,28 8 34 18 -5,8 -4,6 33,64 21,16 26,68 9 60 30 20,2 7,4 408,04 54,76 149,48 10 40 20 0,2 -2,6 0,04 6,76 -0,52 suma 398 226 1489,60 262,40 527,20 średnia 39,8 22,6 odchylenie 12,2 5,12 Pomiędzy zmiennymi jest silna dodatnia korelacja
Innym miernikiem korelacyjnego związku cech jest współczynnik korelacji rang Spearmana. Współczynnik ten stosowany jest głównie do badania współzależności cech niemierzalnych, bądź cechy mierzalnej i niemierzalnej. Może być on również stosowany w badaniu związku korelacyjnego pomiędzy cechami mierzalnymi (szczególnie w przypadku małej próby). Konstrukcja współczynnika korelacji rang opiera się na zgodności pozycji, którą zajmuje każda z odpowiadających sobie wielkości we wzrastającym lub malejącym szeregu wartości cechy.
Współczynnik korelacji rang Spearmana (rS) wylicza się w oparciu o wyznaczone różnice rang (d) oraz liczby par obserwacji (n): przy czym: gdzie: - rangi zmiennej X oraz Y (i=1,2,...n)
gdy Współczynnik korelacji rang przyjmuje wartości z przedziału od -1 do 1, a jego interpretacja jest analogiczna do współczynnika korelacji Pearsona.
Kwadrat różnicy rang (d2) Przykład. W celu zbadania, czy istnieje związek między zdyscyplinowaniem pacjentów względem zaleceń personelu medycznego a wynikami terapii na pewną dolegliwość poddano obserwacji 10 pacjentów. Otrzymano następujące wyniki obserwacji zestawione w tabeli: Pacjent Ranga zdyscyply- -nowanie terapii Różnica rang (d) Kwadrat różnicy rang (d2) 1 2 3 4 5 6 7 8 9 10 -2 -3 -1 Razem 30
Korelacja jest dodatnia i silna Korelacja jest dodatnia i silna. Dodatnia korelacja oznacza, że im bardziej pacjenci byli zdyscyplinowani, tym lepszy efekt terapii.