Pobierz prezentację
1
możemy wyrzucić dobrą szynkę
Podobnie jak testy w życiu codziennym, test statystyczny też ma jeden wynik: „jest OK albo nie jest OK” Wąchamy wędlinkę sprzed paru dni i kierujemy ją na stół albo pod stół ;-) Nie ma trzeciej drogi, chyba że mamy psa, który nam się opatrzył ;-) Zwróćmy przy okazji uwagę na to, że przy testowaniu możemy popełnić dwa rodzaje błędów: możemy wyrzucić dobrą szynkę albo zjeść zepsutą
 Nie ma trzeciej drogi, chyba że mamy psa, który nam się opatrzył ;-) Zwróćmy przy okazji uwagę na to, że przy testowaniu możemy popełnić dwa rodzaje błędów: możemy wyrzucić dobrą szynkę. albo zjeść zepsutą.")
2
Opinie, przekonania, stereotypy
W Warszawie życie jest droższe niż w Rzeszowie W prywatnych uczelniach więcej niż połowa wykładowców jest przyjezdnych Panie powodują mniej wypadków czy stłuczek niż panowie Wraz z podwyżkami czesnego, zmaleje liczba chętnych do studiowania Panowie, rzadziej niż panie, wykonują zawód fryzjera Nieobecność na wykładach i można mieć kłopoty ze zdaniem egzaminu Do Rz. pociągi przyjeżdżają z opóźnieniem > 20 minut

3
Przykładowo: czy wartość określonej statystyki (np. średniej) uzyskana z próbki losowej (szczególnie jeśli próbka ma małą liczność), pozwala sądzić, że odpowiada ona wartości wymaganej (spodziewanej) lub też, czy uzyskana w wyniku działań doskonalących poprawa jest tylko pozorna – wynika z małej liczby pomiarów sprawdzających – czy rzeczywista Odpowiedzi na tak i podobnie postawione pytanie uzyskuje się w tzw. testach statystycznych
 uzyskana z próbki losowej (szczególnie jeśli próbka ma małą liczność), pozwala sądzić, że odpowiada ona wartości wymaganej (spodziewanej) lub też, czy uzyskana w wyniku działań doskonalących poprawa jest tylko pozorna – wynika z małej liczby pomiarów sprawdzających – czy rzeczywista. Odpowiedzi na tak i podobnie postawione pytanie uzyskuje się w tzw. testach statystycznych.")
4
Hipotezy statystyczne
Hipoteza statystyczna to każde przypuszczenie weryfikowane na podstawie n-elementowej próby Hipotezą zerową, oznaczoną przez H0, jest hipoteza w wartości jednego z parametrów populacji (lub wielu) Tę hipotezę traktujemy jako prawdziwą, dopóki nie uzyskamy informacji dostatecznych do zmiany naszego stanowiska Hipotezą alternatywną, oznaczoną przez H1, jest hipoteza przypisująca parametrowi (parametrom) populacji wartość inną niż podaje to hipoteza zerowa
 Tę hipotezę traktujemy jako prawdziwą, dopóki nie uzyskamy informacji dostatecznych do zmiany naszego stanowiska. Hipotezą alternatywną, oznaczoną przez H1, jest hipoteza przypisująca parametrowi (parametrom) populacji wartość inną niż podaje to hipoteza zerowa.")
5
Hipoteza zerowa: często opisuje sytuację, która istniała do tej pory lub jest wyrazem naszego przekonania, które chcemy sprawdzić Sprawdzenia dokonuje się korzystając z informacji zawartej w próbie losowej Sprawdzianem lub statystyką testu nazywamy statystkę z próby, której wartość obliczona na podstawie wyników obserwacji jest wykorzystywana do ustalenia czy możemy hipotezę zerową odrzucić czy jej odrzucić nie możemy

6
Stosuje się dwie grupy testów:
parametryczne i nieparametryczne testy parametryczne – testujemy parametr (np. średnią) testy nieparametryczne – testujemy zjawisko (prawidłowość) – np. test niezależności
 testy nieparametryczne – testujemy zjawisko (prawidłowość) – np. test niezależności.")
7
Grupa 1: Testy parametryczne

8
Test dla średniej w populacji dla dużej próby (n > 30)
H0: m = m0 H1: m ≠ m0 Poziom istotności: a (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: Ra = (-; -ua/2) (ua/2; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra
 Statystyka testu: Obszar krytyczny: Ra = (-; -ua/2) (ua/2; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra.")
9
Test dla średniej w populacji dla małej próby (n ≤ 30)
H0: m = m0 H1: m ≠ m0 Poziom istotności: a (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: ma rozkład t o n-1 stopniach swobody Obszar krytyczny: Ra = (-; -ta;n-1 ) (ta;n-1; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do Ra
 Statystyka testu: ma rozkład t o n-1 stopniach swobody. Obszar krytyczny: Ra = (-; -ta;n-1 ) (ta;n-1; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do Ra.")
10
Próby niezależne i zależne
Próby niezależne – dwie różne grupy, jedno badanie Mierzymy ciśnienie grupie osób (mężczyźni i kobiety; pracujący i bezrobotni; bezdzietni i mający potomstwo) Próby zależne – jedna grupa, dwa badania Mierzymy tętno grupie osób PRZED i PO wykonaniu serii podskoków
 Próby zależne – jedna grupa, dwa badania. Mierzymy tętno grupie osób PRZED i PO wykonaniu serii podskoków.")
11
Test dla porównania dwóch wartości oczekiwanych dwóch populacji przy dużych próbach (n1 > 30 i n2 > 30); próby niezależne H0: m1= m2 H1: m1 ≠ m2 Poziom istotności: a (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: Ra = (-; -ua/2) (ua/2; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra
 Statystyka testu: Obszar krytyczny: Ra = (-; -ua/2) (ua/2; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra.")
12
Test dla porównania dwóch wartości oczekiwanych dwóch populacji przy małych próbach (n1 ≤ 30 i n2 ≤ 30); próby niezależne H0: m1= m2 H1: m1 ≠ m2 Poziom istotności: a (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: ma rozkład t o n1 + n2 - 2 stopniach swobody Obszar krytyczny: Ra = (-; -ta) (ta; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do Ra
 Statystyka testu: ma rozkład t o n1 + n2 - 2 stopniach swobody. Obszar krytyczny: Ra = (-; -ta) (ta; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do Ra.")
13
Test dla porównania dwóch wartości oczekiwanych dwóch populacji; próby niezależne
H0: m1= m2 H1: m1 ≠ m2 Poziom istotności: a (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: ma rozkład t o n1 + n2 - 2 stopniach swobody Obszar krytyczny: Ra = (-; -ta) (ta; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do Ra
 Statystyka testu: ma rozkład t o n1 + n2 - 2 stopniach swobody. Obszar krytyczny: Ra = (-; -ta) (ta; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do Ra.")
14
Test hipotezy o wskaźniku frakcji w populacji (n > 100)
H0: p= p0 H1: p ≠ p0 jeśli próba jest duża, to rozkład frakcji w próbie jest rozkładem normalnym o średniej p i odchyleniu pq/n Poziom istotności: a (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: Ra = (-; -ua/2) (ua/2; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra
 Statystyka testu: Obszar krytyczny: Ra = (-; -ua/2) (ua/2; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra.")
15
Test hipotezy o wskaźnikach frakcji w dwóch populacjach (każde n > 100)
H0: p1= p2 H1: p1 ≠ p2 Poziom istotności: a (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: gdzie: Obszar krytyczny: Ra = (-; -ua/2) (ua/2; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra
 Statystyka testu: gdzie: Obszar krytyczny: Ra = (-; -ua/2) (ua/2; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra.")
16
Test hipotezy o istotności współczynnika korelacji
H0: rpop = 0 H1: rpop ≠ 0 Poziom istotności: a (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: Ra = (-; -ta) (ta; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra
 Statystyka testu: Obszar krytyczny: Ra = (-; -ta) (ta; +) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do Ra.")
17
Testy jednostronne H0: μ = A H1: μ > A H1: μ < A
Wybór rodzaju testu podyktowany jest potrzebą działania Jeżeli działanie (np. korygujące) będzie podjęte, gdy parametr przekroczy pewną wartość A, to stosujemy test prawostronny: H0: μ = A H1: μ > A Jeżeli działanie będzie podjęte, gdy parametr przyjmie wartość mniejszą niż A, to stosujemy test lewostronny: H1: μ < A
 będzie podjęte, gdy parametr przekroczy pewną wartość A, to stosujemy test prawostronny: H0: μ = A. H1: μ > A. Jeżeli działanie będzie podjęte, gdy parametr przyjmie wartość mniejszą niż A, to stosujemy test lewostronny: H1: μ < A.")
18
H0: μ = A H1: μ A H0: μ = A H1: μ > A

19
Przykład 1: Firma rozwożąca paczki zapewnia, że średni czas dostarczenia przesyłki od drzwi klienta do odbiorcy wynosi 28 minut. By sprawdzić to stwierdzenie pobrano próbę 100 przesyłek i obliczono średni czas dostawy 31,5 minut oraz odchylenie standardowe 5 minut.

20
Obszar krytyczny: Ra = (-; -1,96) (1,96; +)
Obliczenia do przykładu: H0 : µ = 28 H1 : µ 28 Obszar krytyczny: Ra = (-; -1,96) (1,96; +) u
 (1,96; +) u.")
21
Przykład 2: Przypuszcza się, że przeciętny czas jaki potrzebuje komputer do wykonania pewnego zadania wynosi 3,24 sekundy. Grupa naukowców z Bell Laboratories testowała algorytmy, które mogłyby zmienić czas obliczeń. Przeprowadzono badania: wybrano losowo próbę 200 cykli obliczeń komputera według nowych algorytmów i otrzymano średni czas obliczeń 3,48 s przy odchyleniu 2,8 sekundy. Jaki wniosek wyciągną naukowcy przy poziomie istotności 0,05?

22
Obszar krytyczny: R0,05 = (-; -1,96) (1,96; +)
H0 : µ = 3,24 H1 : µ 3,24 Obszar krytyczny: R0,05 = (-; -1,96) (1,96; +) Obszar krytyczny: R0,1 = (-; -1,65) (1,65; +) Otrzymana wartość u nie należy do obszaru krytycznego. Zatem nie ma podstaw do odrzucenia hipotezy zerowej. Oznacza to jedynie, że na przyjętym poziomie istotności nie mamy dostatecznych powodów do odrzucenia H0.
 (1,96; +) Obszar krytyczny: R0,1 = (-; -1,65) (1,65; +) Otrzymana wartość u nie należy do obszaru krytycznego. Zatem nie ma podstaw do odrzucenia hipotezy zerowej. Oznacza to jedynie, że na przyjętym poziomie istotności nie mamy dostatecznych powodów do odrzucenia H0.")
23
Grupa 2: Testy nieparametryczne

24
Najczęściej stosowanym narzędziem jest test chi-kwadrat
Najczęściej stosowanym narzędziem jest test chi-kwadrat. Został on opracowany przez Karla Pearsona w 1900 roku i jest metodą, dzięki której można się upewnić, czy dane zawarte w tabeli wielodzielczej dostarczają wystarczającego dowodu na związek tych dwóch zmiennych. Test chi-kwadrat polega na porównaniu liczebności zaobserwowanych z oczekiwanymi przy założeniu hipotezy o braku związku między tymi dwiema zmiennymi. Liczebności (częstości) oczekiwane obliczamy, wykorzystując liczebności brzegowe(z tablicy wielodzielczej) według następującego wzoru: Wówczas hipotezę o tym, że cechy X i Y są niezależne, możemy zweryfikować testem według następującego schematu:
 oczekiwane obliczamy, wykorzystując liczebności brzegowe(z tablicy wielodzielczej) według następującego wzoru: Wówczas hipotezę o tym, że cechy X i Y są niezależne, możemy zweryfikować testem według następującego schematu:")
25
Weryfikacja hipotezy zerowej: H0: cechy X i Y są niezależne Wobec hipotezy alternatywnej: H1: cechy X i Y są zależne Do weryfikacji hipotezy stosujemy statystykę: Otrzymaną wartość należy porównać z wartością krytyczną chi-kwadrat o (k - 1)·(p - 1) stopniach swobody
·(p - 1) stopniach swobody.")
26
Korzystanie z badań profilaktycznych
Na przykład: zapytano 260 osób o to, czy korzystają z bezpłatnych darmowych badań profilaktycznych dowolnego typu. Zebrane dane przedstawiono w wielodzielczej tabeli. Czy istnieje zależność między korzystaniem z takiej oferty i miejscem zamieszkania? Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 20 45 63 128 Miasto 40 52 132 60 97 103 260

27
Korzystanie z badań profilaktycznych
Wyliczymy liczebności oczekiwane. Wyniki obliczeń pozostałych liczebności oczekiwanych przedstawiono w tabeli w nawiasach obok wartości obserwowanych. Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 29,54 47,75 50,71 128 Miasto 30,46 49,25 52,29 132 60 97 103 260 A jak się to liczy? Mnożymy sumę z wiersza i sumę z kolumny (patrzymy po brzegach), następnie dzielimy przez liczbę wszystkich elementów (tu 260).
, następnie dzielimy przez liczbę wszystkich elementów (tu 260).")
28
Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś
Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 60*128 260 97*128 103*128 128 Miasto 60*132 97*132 103*132 132 60 97 103 I stąd jest Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 29,54 47,75 50,71 128 Miasto 30,46 49,25 52,29 132 60 97 103 260

29
Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś
Następny krok to porównanie liczebności empirycznych i teoretycznych, a końcowym efektem jest obliczona wartość statystyki chi-kwadrat. Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś 3,08 0,16 2,98 6,22 Miasto 2,99 0,15 2,89 6,03 6,07 0,31 5,87 12,25 A jak się to liczy? We wnętrzu tabeli: liczebność empiryczna minus teoretyczna, podnosimy do kwadratu, dzielimy przez teoretyczną. Miejsce zamieszkania Korzystanie z badań profilaktycznych Razem często rzadko nigdy Wieś (20-29,54)2 29,54 (45-47,75)2 47,75 (63-50,71)2 50,71 6,22 Miasto (40-30,36)2 30,46 (52-49,25)2 49,25 (40-52,29)2 52,29 6,03 6,07 0,31 5,87 12,25
2. 29,54. (45-47,75)2. 47,75. (63-50,71)2. 50,71. 6,22. Miasto. (40-30,36)2. 30,46. (52-49,25)2. 49,25. (40-52,29)2. 52,29. 6,03. 6,07. 0,31. 5,87. 12,25.")
30
Tak więc wartość obliczona chi-kwadrat = 12,25
Wartość odczytana wynosi (dla poziomu istotności 0,05 i (3–1)*(2–1)) stopni swobody = 5,991 Wartość obliczona > wartość krytyczna (odczytana) 12,25 > 5,991 W takiej sytuacji formułujemy wniosek końcowy: Istnieje zależność między miejscem zamieszkania a częstotliwością korzystania z badań profilaktycznych. A teraz szukamy największych rozbieżności między liczebnościami empirycznymi i teoretycznymi, np.: Miejsce zamieszkania Korzystanie z badań profilaktycznych często rzadko nigdy Wieś 20-29,54 45-47,75 63-50,71 Miasto 40-30,36 52-49,25 40-52,29
*(2–1)) stopni swobody = 5,991. Wartość obliczona > wartość krytyczna (odczytana) 12,25 > 5,991. W takiej sytuacji formułujemy wniosek końcowy: Istnieje zależność między miejscem zamieszkania a częstotliwością korzystania z badań profilaktycznych. A teraz szukamy największych rozbieżności między liczebnościami empirycznymi i teoretycznymi, np.: Miejsce zamieszkania. Korzystanie z badań profilaktycznych. często. rzadko. nigdy. Wieś , , ,71. Miasto , , ,29.")
31
Korzystanie z badań profilaktycznych
Miejsce zamieszkania Korzystanie z badań profilaktycznych często rzadko nigdy Wieś 20-29,54 45-47,75 63-50,71 Miasto 40-30,36 52-49,25 40-52,29 Zauważmy, że mieszkańcy wsi częściej przyznawali, ze nigdy nie korzystali z badań profilaktycznych (63 wobec 50,71). Mieszkańcy miast w większym stopniu niż można się było spodziewać przyznawali, że często korzystają z badań profilaktycznych (40 wobec 30,36). Zauważmy, że bardzo duże wartości chi-kwadrat obliczonego oznaczają dużą różnicę pomiędzy częstościami obserwowanymi a oczekiwanymi, i jest to dowód istnienia zależności. Przeciwnie mała wartość (zwłaszcza bliska 0) nie daje dowodu na istnienie korelacji.
. Mieszkańcy miast w większym stopniu niż można się było spodziewać przyznawali, że często korzystają z badań profilaktycznych (40 wobec 30,36). Zauważmy, że bardzo duże wartości chi-kwadrat obliczonego oznaczają dużą różnicę pomiędzy częstościami obserwowanymi a oczekiwanymi, i jest to dowód istnienia zależności. Przeciwnie mała wartość (zwłaszcza bliska 0) nie daje dowodu na istnienie korelacji.")
32
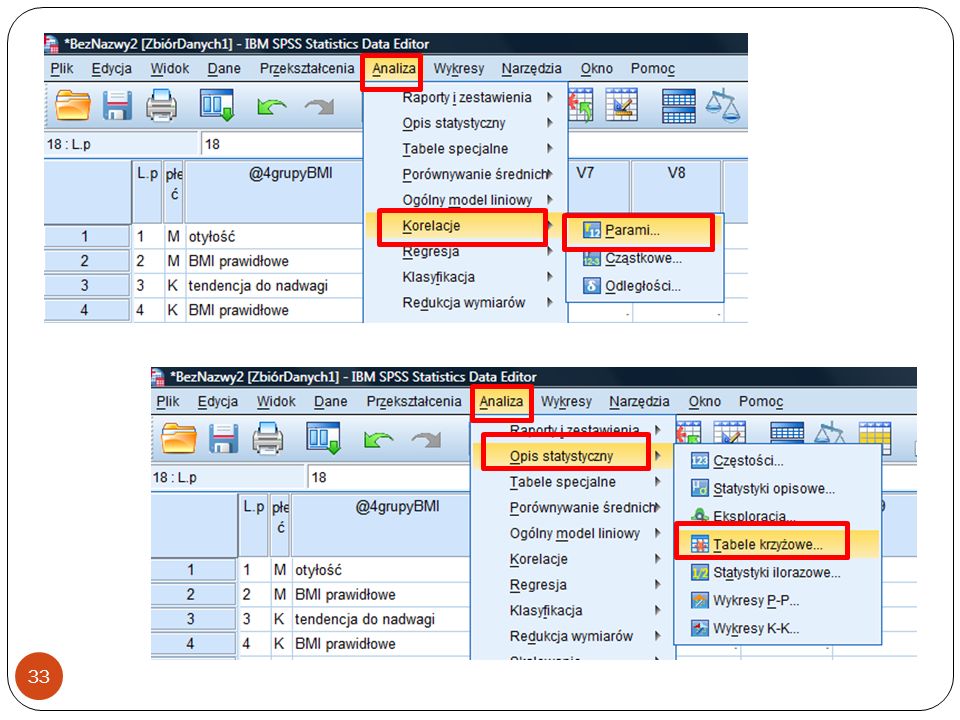
Tymczasem w SPSS…

34
Sposoby podejmowania decyzji:
porównujemy obliczoną wartość statystyki testu z wartością krytyczną otrzymaną istotność z zakładanym poziomem istotności Typowy sposób przy liczeniu „na piechotę” Typowy sposób przy liczeniu z użyciem programów komputerowych Jeśli otrzymana istotność ≤ zakładany poziom istotności, odrzucamy H0 Jeśli otrzymana istotność > zakładany poziom istotności, nie odrzucamy H0


, gdzie X jest liczbą osób w rodzinie, a Y liczbą izb w mieszkaniu. Niech f.r.p. tej zmiennej.>")




>")













