Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
11 REGRESJA LINIOWA - PREDYKCJA
(LINEAR REGRESSION - PREDICTION) Rok akademicki 2010/2012 Prof. Dr Franciszek Kubiczek
 Rok akademicki 2010/2012. Prof. Dr Franciszek Kubiczek.")
2
STATYSTYCZNA TEORIA KORELACJI I REGRESJI
„Rak płuc jest powiązany z paleniem papierosów” – im więcej pali się papierosów, tym bardziej jest prawdopodobne, że zachoruje się na raka!! Narzędzie do dokładnego określania stopnia, w jakim zmienne są ze sobą powiązane. Pozwala zweryfikować (także negatywnie) rozpoznane powiązanie, jak również wykryć nierozpoznane dotychczas współzależności. Podstawowym problemem statystyki korelacji i regresji jest stwierdzenie, czy między zmiennym (zjawiskami, procesami, zdarzeniami) występuje jakiś związek, jakaś zależność i czy związek ten jest mniej lub bardziej ścisły.
 rozpoznane powiązanie, jak również wykryć nierozpoznane dotychczas współzależności. Podstawowym problemem statystyki korelacji i regresji jest stwierdzenie, czy między zmiennym (zjawiskami, procesami, zdarzeniami) występuje jakiś związek, jakaś zależność i czy związek ten jest mniej lub bardziej ścisły.")
3
GALTON – TWÓRCA STATYSTYCZNEJ TEORII REGRESJI
Sir Francis Galton (kuzyn Darwina) – , twórca eugeniki, daktyloskopii, prekursor badań nad inteligencją, statystyk, meteorolog, antropolog, kryminolog. Pisarz, lekarz. Opracował metody statystyczne badania rozkładu uzdolnień w populacjach, wprowadził pojęcie testu umysłowego (składały się z zadań psychofizycznych) . Za odpowiedzialne za inteligencję i zdolności umysłowe uważał dwie zmienne: energię działania i wrażliwość zmysłową. W 1899 r. w pracy „Naturalna dziedziczność” ogłosił, że rozmiary nasion groszku pachnącego mają tendencję w kolejnych generacjach do powracania (to regress) do swego średniego rozmiaru, podobnego związku dopatrzył się także między wzrostem syna i ojca itd. Dopasowywał do tych par liczb linię prostą opisującą tę zależność
 – , twórca eugeniki, daktyloskopii, prekursor badań nad inteligencją, statystyk, meteorolog, antropolog, kryminolog. Pisarz, lekarz. Opracował metody statystyczne badania rozkładu uzdolnień w populacjach, wprowadził pojęcie testu umysłowego (składały się z zadań psychofizycznych) . Za odpowiedzialne za inteligencję i zdolności umysłowe uważał dwie zmienne: energię działania i wrażliwość zmysłową. W 1899 r. w pracy „Naturalna dziedziczność ogłosił, że rozmiary nasion groszku pachnącego mają tendencję w kolejnych generacjach do powracania (to regress) do swego średniego rozmiaru, podobnego związku dopatrzył się także między wzrostem syna i ojca itd. Dopasowywał do tych par liczb linię prostą opisującą tę zależność.")
4
ISTOTA REGRESJI KORELACJA (Correlation) daje możliwość stwierdzenia, czy istnieje związek (niekoniecznie przyczynowo-skutkowy) miedzy badanymi cechami (zmiennymi) oraz jaka jest jego siła i kierunek REGRESJA (Regression) daje możliwość oszacowania (estymacji) wartości jednej cechy (zmiennej zależnej, objaśnianej) na podstawie wartości przyjmowanych przez drugą cechę (zmienną niezależną, objaśniającą) FUNKCJA REGRESJI (Function of regression) której parametry można oszacować przy pomocy metody najmniejszych kwadratów (MNK). Równanie opisujące związek statystyczny między zmiennymi nazywa się równaniem lub modelem regresji.
 daje możliwość stwierdzenia, czy istnieje związek (niekoniecznie przyczynowo-skutkowy) miedzy badanymi cechami (zmiennymi) oraz jaka jest jego siła i kierunek. REGRESJA (Regression) daje możliwość oszacowania (estymacji) wartości jednej cechy (zmiennej zależnej, objaśnianej) na podstawie wartości przyjmowanych przez drugą cechę (zmienną niezależną, objaśniającą) FUNKCJA REGRESJI (Function of regression) której parametry można oszacować przy pomocy metody najmniejszych kwadratów (MNK). Równanie opisujące związek statystyczny między zmiennymi nazywa się równaniem lub modelem regresji.")
5
METODA NAJMNIEJSZYCH KWADRATÓW MNK LEAST SQUARES METHOD
K. F. Gauss – twórca metody (1809 r. , w wieku 25 lat) Metoda powstała w kontekście estymacji sześciu stałych w czasie parametrów określających położenie ciała niebieskiego na orbicie eliptycznej Początek szerszego stosowania Najmniejszy błąd kwadratowy jako kryterium oceny, stąd nazwa metody najmniejszych kwadratów Metoda najmniejszych kwadratów polega na estymacji parametrów modelu regresji zapisanego w postaci addytywnej (sumarycznej), która pozwala na znalezieniu takich wartości tych parametrów, że suma kwadratów odchyleń pomiędzy rzeczywistymi (empirycznymi) a teoretycznymi (obliczonymi z równania regresji) wartościami zmiennej objaśnianej jest najmniejsza. Model jest tym lepiej dopasowany do danych rzeczywistych, im różnice miedzy zaobserwowanymi wartościami zmiennej objaśnianej (Y) a jej wartościami teoretycznymi są mniejsze.
 Metoda powstała w kontekście estymacji sześciu stałych w czasie parametrów określających położenie ciała niebieskiego na orbicie eliptycznej. Początek szerszego stosowania Najmniejszy błąd kwadratowy jako kryterium oceny, stąd nazwa metody najmniejszych kwadratów. Metoda najmniejszych kwadratów polega na estymacji parametrów modelu regresji zapisanego w postaci addytywnej (sumarycznej), która pozwala na znalezieniu takich wartości tych parametrów, że suma kwadratów odchyleń pomiędzy rzeczywistymi (empirycznymi) a teoretycznymi (obliczonymi z równania regresji) wartościami zmiennej objaśnianej jest najmniejsza. Model jest tym lepiej dopasowany do danych rzeczywistych, im różnice miedzy zaobserwowanymi wartościami zmiennej objaśnianej (Y) a jej wartościami teoretycznymi są mniejsze.")
6
MODELE REGRESJI Model ekonometryczny (Econometric model): równanie (lub układ równań) opisujące zależność pomiędzy zjawiskami ekonomicznymi - przyczynowo-skutkowe (cause and effect model): w których między zmiennymi objaśnianymi a zmiennymi objaśniającymi zachodzi związek przyczynowo-skutkowy - symptomatyczne: bez związku przyczynowo-skutkowego, ale w których zachodzi statystyczny silny związek korelacyjny; może to oznaczać, że inne zmienne (tzw. symptomatyczne) oddziałują silnie na zmienne objaśniające włączone do modelu - autoregresyjne (autoregression): w których w roli zmiennych objaśniających występują opóźnione w czasie zmienne objaśniane - tendencji rozwoju: opisują rozwój zjawisk w czasie (bez analizy przyczyny zjawisk bądź związków miedzy zmiennymi)
: w których między zmiennymi objaśnianymi a zmiennymi objaśniającymi zachodzi związek przyczynowo-skutkowy. - symptomatyczne: bez związku przyczynowo-skutkowego, ale w których zachodzi statystyczny silny związek korelacyjny; może to oznaczać, że inne zmienne (tzw. symptomatyczne) oddziałują silnie na zmienne objaśniające włączone do modelu. - autoregresyjne (autoregression): w których w roli zmiennych objaśniających występują opóźnione w czasie zmienne objaśniane. - tendencji rozwoju: opisują rozwój zjawisk w czasie (bez analizy przyczyny zjawisk bądź związków miedzy zmiennymi)")
7
ETAPY BUDOWY MODELU (RÓWNANIA) REGRESJI
Określenie istoty zjawiska, które jest badane; wybór modelu Wybór zmiennych objaśniających (x), spośród wielu czynników wpływających na zmienną objaśnianą (y); informacje o tym zdobywamy w rezultacie analizy korelacji miedzy zmiennymi. Jeżeli modelujemy zjawisko, które ma swoją rozwiniętą teorię, wtedy z tej teorii możemy uzyskać informację o potencjalnych zmiennych objaśniających, a niekiedy nawet o analitycznej postaci funkcji regresji. Zdarza się, że zmienne uważane za przyczynę nie mogę zostać zmierzone lub informacja o nich nie jest osiągalna. Wtedy sięgamy do innych zmiennych, pośrednio mówiące o pierwotnych przyczynach. Takie zmienne nazywamy symptomatycznymi i ich wykorzystanie w modelu jest uzasadnione.
, spośród wielu czynników wpływających na zmienną objaśnianą (y); informacje o tym zdobywamy w rezultacie analizy korelacji miedzy zmiennymi. Jeżeli modelujemy zjawisko, które ma swoją rozwiniętą teorię, wtedy z tej teorii możemy uzyskać informację o potencjalnych zmiennych objaśniających, a niekiedy nawet o analitycznej postaci funkcji regresji. Zdarza się, że zmienne uważane za przyczynę nie mogę zostać zmierzone lub informacja o nich nie jest osiągalna. Wtedy sięgamy do innych zmiennych, pośrednio mówiące o pierwotnych przyczynach. Takie zmienne nazywamy symptomatycznymi i ich wykorzystanie w modelu jest uzasadnione.")
8
ETAPY BUDOWY MODELU (RÓWNANIA) REGRESJI
W wielu zjawiskach, liczba potencjalnych zmiennych objaśniających jest bardzo duża i nie możemy ich wszystkich zamieścić w równaniu regresji. Ograniczeniem jest jednak zwykle liczba posiadanych (lub możliwych do zdobycia) informacji liczbowych o wartościach tych zmiennych. Wnioskowanie przyczynowo-skutkowe wymaga nie tylko spełnienia formalnych wymagań poprawności równania regresji, lecz przede wszystkim logicznej i merytorycznej analizy modelowanego zjawiska.
 informacji liczbowych o wartościach tych zmiennych. Wnioskowanie przyczynowo-skutkowe wymaga nie tylko spełnienia formalnych wymagań poprawności równania regresji, lecz przede wszystkim logicznej i merytorycznej analizy modelowanego zjawiska.")
9
ETAPY BUDOWY MODELU (RÓWNANIA) REGRESJI
Wybór postaci analitycznej modelu: określenie postaci funkcji matematycznych opisujących zależność zmiennej objaśnianej od zmiennych objaśniających; Najczęściej stosowanym modelem regresji jest model liniowy oraz jednorównaniowy Oszacowanie (estymacja) parametrów modelu (równania) Weryfikacja modelu: sprawdzenie czy model adekwatnie opisuje badaną rzeczywistość ekonomiczną Wnioskowanie na podstawie modelu: analiza ekonomiczna i prognozowanie
 parametrów modelu (równania) Weryfikacja modelu: sprawdzenie czy model adekwatnie opisuje badaną rzeczywistość ekonomiczną. Wnioskowanie na podstawie modelu: analiza ekonomiczna i prognozowanie.")
10
RÓWNANIE REGRESJI LINIOWEJ (LINEAR REGRESSION EQUATION)
Y = a x + b S [Y – (a x + b)]2 = minimum Y – zmienna objaśniana (dane rzeczywiste) Y – zmienna objaśniana (dane teoretyczne z równania regresji) x – zmienna objaśniająca a, b – parametry strukturalne równania regresji a - współczynnik regresji (regression coefficient) b - wyraz wolny (tzw. parametr skali); podaje wartość zmiennej y, gdy zmienna x przybiera wartość zero. ^
]2 = minimum. Y – zmienna objaśniana (dane rzeczywiste) Y – zmienna objaśniana (dane teoretyczne z równania regresji) x – zmienna objaśniająca. a, b – parametry strukturalne równania regresji. a - współczynnik regresji (regression coefficient) b - wyraz wolny (tzw. parametr skali); podaje wartość zmiennej y, gdy zmienna x przybiera wartość zero. ^")
11
RÓWNANIE REGRESJI LINIOWEJ (LINEAR REGRESSION EQUATION)
Parametry tej funkcji (a i b) muszą być tak dobierane, aby wartość sumy kwadratów odchyleń wartości rzeczywistych cechy (Y) od wartości tej cechy, obliczonej na podstawie tego równania (Y) była jak najmniejsza, czyli:
 muszą być tak dobierane, aby wartość sumy kwadratów odchyleń wartości rzeczywistych cechy (Y) od wartości tej cechy, obliczonej na podstawie tego równania (Y) była jak najmniejsza, czyli:")
12
RÓWNANIE REGRESJI Gdy obliczymy parametry równania a i b i wstawimy je do równania otrzymamy empiryczne równanie regresji wyprowadzone z konkretnego szeregu danych statystycznych. Estymacja parametrów liniowej funkcji regresji polega na znajdowaniu takich wartości, aby model regresji jak najlepiej pasował do danych rzeczywistych. Mając to równanie możemy obliczyć zmienną zależną (objaśnianą) podstawiając konkretną wartość zmiennej niezależnej (objaśniającej) Wyniki te możemy wykorzystać do prognozowania kształtowania się konkretnego zjawiska w konkretnej przyszłości, badania wariantów rozwojowych; Współczynnik regresji: informuje, o ile, średnio biorąc, zmieni się przeciętny poziom zmiennej zależnej (objaśnianej - Y), jeśli wartość zmiennej niezależnej (objaśniającej – X), przy której stoi współczynnik, wzrośnie (spadnie) o jednostkę, natomiast wartości pozostałych zmiennych objaśniających nie ulegną zmianie.
 podstawiając konkretną wartość zmiennej niezależnej (objaśniającej) Wyniki te możemy wykorzystać do prognozowania kształtowania się konkretnego zjawiska w konkretnej przyszłości, badania wariantów rozwojowych; Współczynnik regresji: informuje, o ile, średnio biorąc, zmieni się przeciętny poziom zmiennej zależnej (objaśnianej - Y), jeśli wartość zmiennej niezależnej (objaśniającej – X), przy której stoi współczynnik, wzrośnie (spadnie) o jednostkę, natomiast wartości pozostałych zmiennych objaśniających nie ulegną zmianie.")
13
ESTYMACJA I WERYFIKACJA
Estymacja: zastosowanie odpowiednich metod statystycznych w celu otrzymania jak najlepszych wartości występujących w modelu parametrów w oparciu o rzeczywiste dane liczbowe. Weryfikacja: sprawdzenie, czy otrzymane oszacowania (estymacje) wytrzymują konfrontację z teorią (równaniem regresji) oraz czy dane potwierdzają poprawność przyjętego modelu. Szacujemy istotność otrzymanych parametrów równania (równań). Jeżeli model nie spełnia stawianym wymaganiom możemy opracować nowy: zmienić postać funkcji, zebrać nowe dane, wykorzystać inną teorię.
 wytrzymują konfrontację z teorią (równaniem regresji) oraz czy dane potwierdzają poprawność przyjętego modelu. Szacujemy istotność otrzymanych parametrów równania (równań). Jeżeli model nie spełnia stawianym wymaganiom możemy opracować nowy: zmienić postać funkcji, zebrać nowe dane, wykorzystać inną teorię.")
14
a, b – parametry (współczynniki) równania regresji
OBLICZANIE PARAMETRÓW RÓWNANIA REGRESJI (Estimate of the parameters) lub a, b – parametry (współczynniki) równania regresji xi , yi – wartości rzeczywiste zmiennych x, y - wartości średnie zmiennych rxy – współczynnik korelacji Sx, Sy – odchylenia standardowe
 lub. a, b – parametry (współczynniki) równania regresji. xi , yi – wartości rzeczywiste zmiennych. x, y - wartości średnie zmiennych rxy – współczynnik korelacji. Sx, Sy – odchylenia standardowe.")
15
WERYFIKACJA OSZACOWANIA PARAMETRÓW ( VERIFICATION OF THE ESTIMATION)
S to odchylenie standardowe wartości rzeczywistych (empirycznych) cechy y od jej wartości teoretycznych uzyskanych z liniowej funkcji regresji dla tych samych wartości cechy x; im mniejsze S tym większa precyzja dopasowania linii regresji do danych rzeczywistych V = x 100 S y V to współczynnik zmienności, miara natężenia odchyleń
 cechy y od jej wartości teoretycznych uzyskanych z liniowej funkcji regresji dla tych samych wartości cechy x; im mniejsze S tym większa precyzja dopasowania linii regresji do danych rzeczywistych. V = x 100. S. y. V to współczynnik zmienności, miara natężenia odchyleń.")
16
WSPÓŁCZYNNIK DETERMINACJI (DETERMINATION COEFFICIENT)
Współczynnik determinacji informuje, jaka część zmienności zjawiska (Y) jest wyjaśniana przez zaobserwowane zmiany w wartościach zmiennych objaśniających. R2 jest miarą siły liniowego związku między zmiennymi, czyli miarą dopasowania linii regresji do danych rzeczywistych i przyjmuje wartości od 0 do 1 i oznacza w skrajnych wypadkach: 0 - zupełny brak dopasowania funkcji regresji do danych rzeczywistych 1 - idealne dopasowanie funkcji regresji do danych rzeczywistych Im większe R2 tym dopasowanie jest lepsze i tym większe można mieć zaufanie do regresji
 jest wyjaśniana przez zaobserwowane zmiany w wartościach zmiennych objaśniających. R2 jest miarą siły liniowego związku między zmiennymi, czyli miarą dopasowania linii regresji do danych rzeczywistych i przyjmuje wartości od 0 do 1 i oznacza w skrajnych wypadkach: 0 - zupełny brak dopasowania funkcji regresji do danych rzeczywistych. 1 - idealne dopasowanie funkcji regresji do danych rzeczywistych. Im większe R2 tym dopasowanie jest lepsze i tym większe można mieć zaufanie do regresji.")
17
WSPÓŁCZYNNIK ZBIEŻNOŚCI (CONVERGENCE COEFFICIENT)
Z = 1 – R2 Informuje, jaka część całkowitej zmienności cechy y nie jest wyjaśniana regresją liniową względem cechy x; Jeżeli funkcja regresji jest idealnie dopasowana to R2 = 1, czyli Zb = 0 i odwrotnie, Jeżeli funkcja regresji zupełnie odbiega od danych rzeczywistych to R2 = 0, czyli Zb = 1

18
TABLICA KORELACYJNA Tablicę budujemy porządkując szeregi danych wg wartości zmiennej niezależnej, np. wg czasu, wartości PKB na mieszkańca, wysokości wynagrodzenia, Z oglądu tablicy wnioskujemy intuicyjnie, czy istnieje jakiś związek (choćby liczbowy) pomiędzy zmiennymi, np. wraz ze wzrostem PKB na mieszkańca wydłuża się długość życia, wraz ze wzrostem ceny spada popyt Jako specjaliści w danej dziedzinie może stwierdzić lub przyjąć hipotezę, że pomiędzy zmiennymi istnieje związek przyczynowo-skutkowy Dopiero obliczenie współczynników korelacji i determinacji pozwoli określić kierunek i siłę ewentualnej korelacji pomiędzy danymi zmiennymi Po stwierdzeniu korelacji, jej siły i kierunku przystępujemy do wyboru rodzaju krzywej regresji. Pomocny jest w tym celu diagram (wykres) korelacji. Układ punktów na wykresie powinien wskazać na rodzaj krzywej (lub prostej) regresji
 pomiędzy zmiennymi, np. wraz ze wzrostem PKB na mieszkańca wydłuża się długość życia, wraz ze wzrostem ceny spada popyt. Jako specjaliści w danej dziedzinie może stwierdzić lub przyjąć hipotezę, że pomiędzy zmiennymi istnieje związek przyczynowo-skutkowy. Dopiero obliczenie współczynników korelacji i determinacji pozwoli określić kierunek i siłę ewentualnej korelacji pomiędzy danymi zmiennymi. Po stwierdzeniu korelacji, jej siły i kierunku przystępujemy do wyboru rodzaju krzywej regresji. Pomocny jest w tym celu diagram (wykres) korelacji. Układ punktów na wykresie powinien wskazać na rodzaj krzywej (lub prostej) regresji.")
19
TABLICA KORELACYJNA (Correlation table)
KORELACJA I REGRESJA RYNEK CENY zł/szt. xi ILOŚCI SPRZEDANE w szt. yi 1 2 3 1995 1 050 1 200 1996 1 250 1999 1 100 1993 1 150 2000 1998 2001 950 1992 1 000 1994 1 300 900 1997 1 350 800 RAZEM 11 800 10 700 REGRESJA 1400 1200 1000 800 600 400 200 200 400 600 800 1 000 1 200 1 400 1 600 Ilości sprzedane Z oglądu tablicy i wykresu widać intuicyjnie, że występuje korelacja, gdyż wraz ze wzrostem ceny maleje sprzedaż oraz, że dobrym przybliżeniem będzie regresja liniowa.

20
OBLICZANIE WSPÓŁCZYNNIKA KORELACJI I DETERMINACJI
Współczynnik korelacji r = SILNA KORELACJA UJEMNA Współczynnik determinacji r 2= (-0,93)2 = 0,87 tzn. , że w 87% zmiana ceny wpływa na zmianę sprzedaży
2 = 0,87 tzn. , że w 87% zmiana ceny wpływa na zmianę sprzedaży.")
21
OBLICZANIE PARAMETRÓW RÓWNANIA REGRESJI
Współczynnik regresji Równanie regresji Błąd standardowy Współczynnik zmienności

22
WYKRES KORELACYJNY (DIAGRAM OF CORRELATION)
REGRESJA 1400 1200 1000 800 600 400 200 200 400 600 800 1 000 1 200 1 400 1 600 Równanie regresji Ilości sprzedane

23
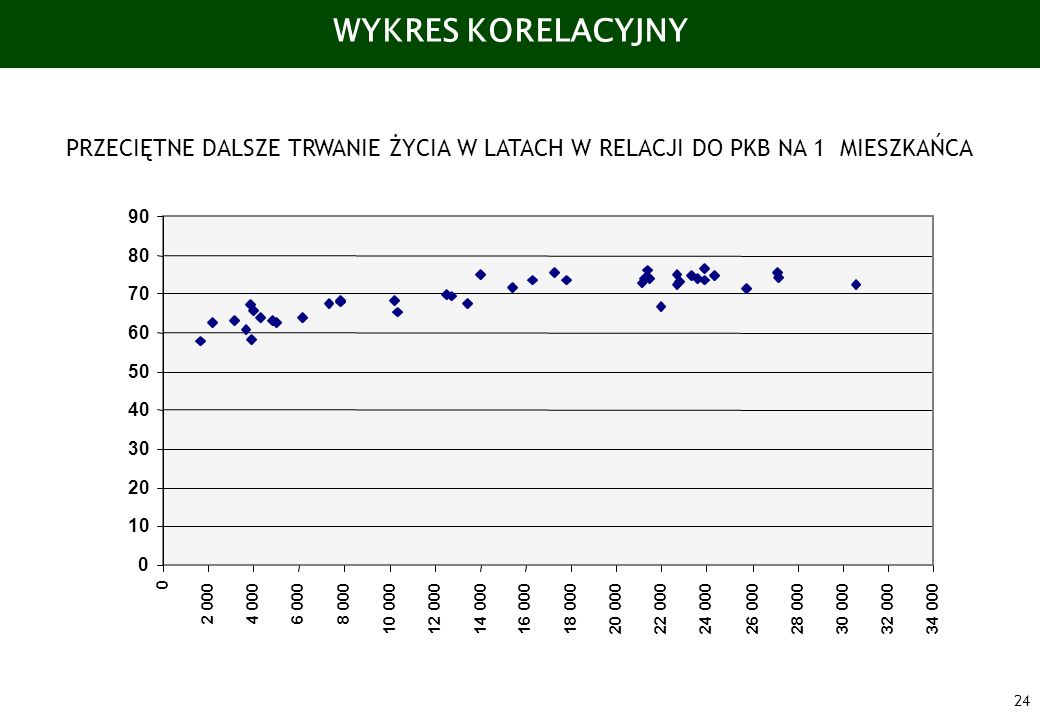
TABLICA KORELACYJNA 1 2 3 INDIE 35. 1 700 57,70 EGIPT 34. 3 130 62,86
NAZWA KRAJU NR KRAJU i PKB Xi ŻYCIE yi 1 2 3 INDIE 35. 1 700 57,70 EGIPT 34. 3 130 62,86 BUŁGARIA 4. 3 860 67,11 BIAŁORUŚ 3. 4 840 62,87 BRAZYLIA 32. 6 160 63,81 MEKSYK 40. 7 858 67,84 ARGENTYNA 30. 10 200 68,42 KOREA 39 13 447 67,66 IZRAEL 36. 17 310 75,49 NOWA ZELANDIA 41. 17 777 73,40 CHINY 33. 22 000 66,70 AUSTRALIA 31. 22 704 75,04 BELGIA 2. 23 569 73,88 JAPONIA 37. 23 880 76,36 AUSTRIA 1. 23 884 73,54 KANADA 38. 24 359 74,55 USA 42. 30 588 72,50 RAZEM 2 925

24
WYKRES KORELACYJNY PRZECIĘTNE DALSZE TRWANIE ŻYCIA W LATACH W RELACJI DO PKB NA 1 MIESZKAŃCA 90 80 70 60 50 40 30 20 10 2 000 4 000 6 000 8 000 10 000 12 000 14 000 16 000 18 000 20 000 22 000 24 000 26 000 28 000 30 000 32 000 34 000
25
WSPÓŁCZYNNIKI KORELACJI I DETERMINACJI
KORELACJI (Correlation coefficient) R = 0,85, tzn. że korelacja jest silna i jednokierunkowa, tzn. że związek między poziomem PKB na mieszkańca a długością życia jest silny oraz że wzrost PKB powoduje wydłużanie życia ludności DETERMINACJI (Determination coefficient) R2 = 0,852 = 0,72, tzn. że w 72% poziom PKB na mieszkańca wyjaśnia (określa) poziom długości życia INTERDETERMINACJI (Indetermination coefficient) 1 – R2 = 1 - 0,72 = 0,28, tzn. że w 28% poziom długości życia zależy od innych czynników niż poziom PKB na mieszkańca Po obliczeniu tych współczynników i stwierdzeniu istnienia korelacji przystępujemy do dalszych kroków mających na celu wypracowanie równania regresji
 R = 0,85, tzn. że korelacja jest silna i jednokierunkowa, tzn. że związek między poziomem PKB na mieszkańca a długością życia jest silny oraz że wzrost PKB powoduje wydłużanie życia ludności. DETERMINACJI (Determination coefficient) R2 = 0,852 = 0,72, tzn. że w 72% poziom PKB na mieszkańca wyjaśnia (określa) poziom długości życia. INTERDETERMINACJI (Indetermination coefficient) 1 – R2 = 1 - 0,72 = 0,28, tzn. że w 28% poziom długości życia zależy od innych czynników niż poziom PKB na mieszkańca. Po obliczeniu tych współczynników i stwierdzeniu istnienia korelacji przystępujemy do dalszych kroków mających na celu wypracowanie równania regresji.")
26
OBLICZENIE WSPÓŁCZYNNIKÓW RÓWNANIA REGRESJI
a = : = 0,00052 $/rok co oznacza, że każde 1000$ PKB na mieszkańca wydłuża życie o 0,52 roku b = 70 – 0,52 15,1 = 62,2 lata (70 = średnia trwania życia, 15,1 = średni PKB) Równanie regresji liniowej: Y = 0,52 xi + 62,2 (PKB w tys. USD)
 Równanie regresji liniowej: Y = 0,52 xi + 62,2 (PKB w tys. USD)")
27
WYKRES KORELACYJNY Trzeba się dobrze przyjrzeć (wzrokowo – dosłownie) wykresowi pod kątem wybory formy regresji: liniowej bądź nieliniowej, jeśli nieliniowej to wg jakiej krzywej Wybierając formę regresji (rodzaj funkcji) przystępujemy do obliczeń współczynników równania regresji
 wykresowi pod kątem wybory formy regresji: liniowej bądź nieliniowej, jeśli nieliniowej to wg jakiej krzywej. Wybierając formę regresji (rodzaj funkcji) przystępujemy do obliczeń współczynników równania regresji.")
28
WYKRES FUNKCJI REGRESJI I DANYCH RZECZYWISTYCH
PRZECIĘTNE DALSZE TRWANIE ŻYCIA W LATACH W RELACJI DO PKB NA 1 MIESZKAŃCA 85 80 75 70 65 60 55 50 45 40 35 30 25 20 15 10 5 1 000 2 000 3 000 4 000 5 000 6 000 7 000 8 000 9 000 10 000 11 000 12 000 13 000 14 000 15 000 16 000 17 000 18 000 19 000 20 000 21 000 22 000 23 000 24 000 25 000 26 000 27 000 28 000 29 000 30 000 31 000 32 000 33 000

29
PROGNOZY SZEREGÓW CZASOWYCH (Time series forecating)
Wyrównywanie szeregów czasowych przy pomocy średniej ruchomej nazywaliśmy metodą mechaniczną Wyrównywanie szeregów czasowych przy pomocy równań regresji liniowej (lub nieliniowej) i MNK nazywamy metodą analityczną W tych równaniach zmienną niezależną (x) jest czas (lata, miesiące itp.), najczęściej oznaczana jako zmienna t. Równania regresji mogą służyć prognozowaniu szeregów czasowych, zwłaszcza w perspektywie średnio i długookresowej (time specific regression). Równanie: y = b + a t
 i MNK nazywamy metodą analityczną. W tych równaniach zmienną niezależną (x) jest czas (lata, miesiące itp.), najczęściej oznaczana jako zmienna t. Równania regresji mogą służyć prognozowaniu szeregów czasowych, zwłaszcza w perspektywie średnio i długookresowej (time specific regression). Równanie: y = b + a t.")
30
TYPOWE POSTACI ZWIĄZKÓW DWÓCH ZMIENNYCH
FUNKCJA LINIOWA (Linear) FUNKCJA WYKŁADNICZA (potential) Y = aX + b Y = abx
 FUNKCJA WYKŁADNICZA (potential) Y = aX + b. Y = abx.")
31
TYPOWE POSTACI ZWIĄZKÓW DWÓCH ZMIENNYCH
FUNKCJA HIPERBOLICZNA FUNKCJA PARABOLOCZNA (parabolic) KWADRATOWA Y = a + b 1 X Y = a + bX + cX2
 KWADRATOWA. Y = a + b. 1. X. Y = a + bX + cX2.")
32
TYPOWE POSTACI ZWIĄZKÓW DWÓCH ZMIENNYCH
FUNKCJA LOGARYTMICZNA FUNKCJA WIELOMIANOWA (polynominal) Y = a + blnX Y = a0 + a1X + a2X2+ a3X3+ …+anXn
 Y = a + blnX. Y = a0 + a1X + a2X2+ a3X3+ …+anXn.")
33
TYPOWE POSTACI ZWIĄZKÓW DWÓCH ZMIENNYCH TRYGONOMETRYCZNA (sine)
FUNKCJA TRYGONOMETRYCZNA (sine) FUNKCJA LOGISTYCZNA (logistic) Y = a0 1 + a1e-x Y = a sinX + b
 FUNKCJA LOGISTYCZNA (logistic) Y = a a1e-x. Y = a sinX + b.")
34
PROBLEM WYBORU KRZYWEJ DO REGRESJI
Aby wybrać właściwą dla danego zjawiska postać krzywej musimy sporządzić wykres punktowy i dobrze się przyjrzeć kształtowi rozmieszczenia się punktów xi yi Mając do dyspozycji wiele postaci krzywych (parabolicznych, wykładniczych, logistycznych, trygonometrycznych itp.) musimy sami wybrać tę, która jest najbliższa zjawisku ukazanemu na wykresie Tę właśnie wybraną krzywą dopasowujemy do zjawiska poszukując parametry równania funkcji jej odpowiadającej przy pomocy MNK Jeśli dla wybranej krzywej błąd standardowy okaże się zbyt duży, poszukujemy innej postaci krzywej lub zrezygnować z metody regresji na rzecz metod mechanicznych (średnia ruchoma, wyrównanie wykładnicze Browna)
 musimy sami wybrać tę, która jest najbliższa zjawisku ukazanemu na wykresie. Tę właśnie wybraną krzywą dopasowujemy do zjawiska poszukując parametry równania funkcji jej odpowiadającej przy pomocy MNK. Jeśli dla wybranej krzywej błąd standardowy okaże się zbyt duży, poszukujemy innej postaci krzywej lub zrezygnować z metody regresji na rzecz metod mechanicznych (średnia ruchoma, wyrównanie wykładnicze Browna)")
35
BŁĄD PREDYKCJI Ocenę dokładności prognozy opartej o równanie regresji prowadzimy przy pomocy tzw. błędu predykcji Jeśli wielkość błędu (stopnia precyzji) jest akceptowalna pozostajemy przy wybranej formie regresji (np. liniowej) Jeśli jest zbyt wysoki, poszukujemy innej krzywej bądź innej formy regresji, np. wielorakiej, gdyż być może na zmienną zależną ma wpływ więcej niż jedna – dotychczas brana pod uwagę - zmienna
 jest akceptowalna pozostajemy przy wybranej formie regresji (np. liniowej) Jeśli jest zbyt wysoki, poszukujemy innej krzywej bądź innej formy regresji, np. wielorakiej, gdyż być może na zmienną zależną ma wpływ więcej niż jedna – dotychczas brana pod uwagę - zmienna.")
36
BŁĄD PREDYKCJI (PREDICTION ERROR)
Y p,n = wartość cechy y dla ustalonej wartości cechy x równej x k

37
REGRESJA WIELORAKA (MULTIPLES REGRESION)
W analizie regresji często się zdarza, że zmienna (y) zależy od więcej niż jednej zmiennej niezależnej (x), które ją objaśniają przyczynowo Często w modelach posługujemy się układem wielu równań, a nie tylko jednym równaniem z wieloma zmiennymi Jeśli do równania regresji włączymy kilka takich zmiennych powstaje model regresji wielorakiej Y = b + a1 x1 + a2 x ak xk + e gdzie: xi – zmienne niezależne wpływające na y ai - współczynniki regresji wiążące daną zmienną xi ze zmienną zależną y b - wielkość stała e – współczynnik losowy
 zależy od więcej niż jednej zmiennej niezależnej (x), które ją objaśniają przyczynowo. Często w modelach posługujemy się układem wielu równań, a nie tylko jednym równaniem z wieloma zmiennymi. Jeśli do równania regresji włączymy kilka takich zmiennych powstaje model regresji wielorakiej. Y = b + a1 x1 + a2 x ak xk + e. gdzie: xi – zmienne niezależne wpływające na y. ai - współczynniki regresji wiążące daną zmienną xi ze zmienną zależną y. b - wielkość stała. e – współczynnik losowy.")
38
ANALIZA REGRESJI WIELORAKIEJ (Multiple regression analysis)
Zadaniem analizy regresji wielorakiej jest: Budowa właściwego równania (liniowego lub nieliniowego), jako modelu zjawiska Oszacowanie wartości parametrów (oraz składnika losowego) równania przy pomocy MNK Obliczenie standardowego błędu oszacowania parametrów wg wzoru RMSE oraz współczynników korelacji, determinacji i regresji wielorakiej. Uwaga: współczynnik regresji wielorakiej mierzy część zmienności zmiennej zależnej (objaśnianej), która została wyjaśniona oddziaływaniem zmiennych niezależnych (objaśniających) występujących w danym modelu regresji
, jako modelu zjawiska. Oszacowanie wartości parametrów (oraz składnika losowego) równania przy pomocy MNK. Obliczenie standardowego błędu oszacowania parametrów wg wzoru RMSE oraz współczynników korelacji, determinacji i regresji wielorakiej. Uwaga: współczynnik regresji wielorakiej mierzy część zmienności zmiennej zależnej (objaśnianej), która została wyjaśniona oddziaływaniem zmiennych niezależnych (objaśniających) występujących w danym modelu regresji.")
39
REGRESJA WIELORAKA - PRZYKŁAD
Firma Alka-Seltzer nasiliła kampanię promocji swoich produktów chemicznych. W ciągu 10 tygodni firma śledziła swoje wydatki na reklamę radiowo-telewizyjną (zmienna x1 ) oraz wydatki na pokazy w sklepach (zmienna x2 ). Wielkość sprzedaży to zmienna zależna Y. Analityk przeprowadził badania statystyczne modelu liniowej regresji wielorakiej wg równania: Y = b + a1x1 + a2x2 + e wiążącego wielkość sprzedaży z dwiema zmiennymi.
 oraz wydatki na pokazy w sklepach (zmienna x2 ). Wielkość sprzedaży to zmienna zależna Y. Analityk przeprowadził badania statystyczne modelu liniowej regresji wielorakiej wg równania: Y = b + a1x1 + a2x2 + e. wiążącego wielkość sprzedaży z dwiema zmiennymi.")
40
REGRESJA WIELORAKA - PRZYKŁAD
Rezultat analiz to równanie regresji (miano w tys. $): Y = 47,2 + 1,6 x1 + 1,15 x2 a1 = 1,6 oznacza, że każdy 1 000$ wydatków (w danym okresie) na reklamę radiowo-telewizyjną przynosi wzrost sprzedaży o 1 600$ w dłuższym okresie czasu a2 = 1,15 oznacza, że każdy 1 000$ wydatków (w danym okresie) na pokazy w sklepach przynosi wzrost sprzedaży o 1 150$ w dłuższym okresie czasu
: Y = 47,2 + 1,6 x1 + 1,15 x2. a1 = 1,6 oznacza, że każdy 1 000$ wydatków (w danym okresie) na reklamę radiowo-telewizyjną przynosi wzrost sprzedaży o 1 600$ w dłuższym okresie czasu. a2 = 1,15 oznacza, że każdy 1 000$ wydatków (w danym okresie) na pokazy w sklepach przynosi wzrost sprzedaży o 1 150$ w dłuższym okresie czasu.")
41
REGRESJA WIELORAKA - PROGNOZOWANIE
x1 = $ (wydatki na reklamę) x2 = 5 000$ (wydatki na pokazy w sklepach) Y = b + a1 x1 + a2 x2 Y = 47,2 + 1,6 x ,15 x = $
 x2 = 5 000$ (wydatki na pokazy w sklepach) Y = b + a1 x1 + a2 x2. Y = 47,2 + 1,6 x ,15 x = $")
42
REGRESJA NIELINIOWA (NONLINEAR REGRESSION)
W praktyce czasami między zmienną zależną (Y) a zmiennymi niezależnymi (xi ) zachodzą nieliniowe związki korelacyjne; najlepiej informuje o tym wykres korelacyjny (rozrzutu). W wielu przypadkach model nieliniowy można przekształcić w liniowy (modele linearyzowane), który jest znacznie prostszy w analizie i oszacowaniu parametrów Gdy to przekształcenie jest zbytnim uproszczeniem zjawiska, poszukujemy modeli wykładniczych, logarytmicznych, logistycznych, trygonometrycznych itd., które lepiej (bardziej adekwatnie do rzeczywistości) opisują badane zjawisko.
 a zmiennymi niezależnymi (xi ) zachodzą nieliniowe związki korelacyjne; najlepiej informuje o tym wykres korelacyjny (rozrzutu). W wielu przypadkach model nieliniowy można przekształcić w liniowy (modele linearyzowane), który jest znacznie prostszy w analizie i oszacowaniu parametrów. Gdy to przekształcenie jest zbytnim uproszczeniem zjawiska, poszukujemy modeli wykładniczych, logarytmicznych, logistycznych, trygonometrycznych itd., które lepiej (bardziej adekwatnie do rzeczywistości) opisują badane zjawisko.")
43
REGRESJA LINIOWA I NIELINIOWA
Jeżeli chcemy sprawdzić, czy linia prosta nadaje się do wyrównania szeregu (przy pomocy MNK), badamy pierwsze przyrosty wyrazów danego szeregu Jeśli te przyrosty są mniej więcej równe, to dla wyrównania szeregu można (w pierwszej przymiarce) przyjąć linię prostą (regresję liniową) wg równania y = a x + b Jeśli przyrosty stale wzrastają lub maleją to należy posłużyć się wielomianem wyższego stopnia np. y = b + a x + c x2 Jeśli przyrosty względne są stałe to można się posłużyć wzorem na funkcję wykładniczą: y = a (1+p)t, gdzie a=wartość wyjściowa, p=stopa przyrostu, t= czas
, badamy pierwsze przyrosty wyrazów danego szeregu. Jeśli te przyrosty są mniej więcej równe, to dla wyrównania szeregu można (w pierwszej przymiarce) przyjąć linię prostą (regresję liniową) wg równania y = a x + b. Jeśli przyrosty stale wzrastają lub maleją to należy posłużyć się wielomianem wyższego stopnia np. y = b + a x + c x2. Jeśli przyrosty względne są stałe to można się posłużyć wzorem na funkcję wykładniczą: y = a (1+p)t, gdzie a=wartość wyjściowa, p=stopa przyrostu, t= czas.")
44
MODELE EKONOMETRYCZNE (Econometric models)
Modele rozwoju gospodarki narodowej Langego, Kaleckiego, Pajestki itd., w których interesują nas głównie trendy Modele koniunktury gospodarek lub branż, w których interesują nas cykle i wahania sezonowe Modele rynkowo-produktowe, w których interesują nas elastyczności cenowo-dochodowe w kontekście popytu i podaży W modelach tych wielkie znaczenie ma właściwe statystyczne oszacowanie parametrów równań. Wtedy modele te nabierają wartości analityczno-prognostycznych

45
MODELE EKONOMETRYCZNE (Econometric models)
W sferze finansów zaproponowano modelowanie zjawisk wysokiej częstotliwości; dotyczy to głównie kursów walut, kursów akcji, które zmieniają się niezmiernie często. Do analizowania takich procesów powstała nowa klasa modeli o nazwie ARCH. Jej twórca Robert Engle otrzymał za to Nagrodę Nobla w 2003 r. W innych obszarach ekonomii, gdzie posługujemy się danymi o niskiej częstotliwości, a więc miesięcznych, kwartalnych czy rocznych zaproponowano nowe podejście modelowe, które złożyło się na teorię kointegracji. Za nią Nagrodę Nobla otrzymał Clive Granger.

46
MODEL Langego DD/D = I/D x DD/I R = a x b Model Oskara Langego:
STOPA PRZYROSTU PRODUKTU KRAJOWEGO = iloczyn stopy inwestycji i efektywności inwestycji DD/D = I/D x DD/I R = a x b STOPA INWESTYCJI = iloraz wydatków na inwestycje i produktu krajowego (udział inwestycji w produkcie krajowym) – a = I/D EFEKTYWNOŚĆ INWESTYCJI = iloraz przyrostu produktu i wydatków na inwestycje (przyrost produktu na 1 zł inwestycji) – b = D/I
 – a = I/D. EFEKTYWNOŚĆ INWESTYCJI = iloraz przyrostu produktu i wydatków na inwestycje (przyrost produktu na 1 zł inwestycji) – b = D/I.")
47
PROBLEMY Przykład: a = 0,15 (15% produktu krajowego)
Dla polityka gospodarczego: - ustalić stopę inwestycji Dla analityka-statystyka: - oszacować statystycznie (na podstawie długiego szeregu czasowego i prognoz) przy pomocy MNK współczynnik makroekonomicznej efektywności inwestycji Przykład: a = 0,15 (15% produktu krajowego) b = 0,3 R = a b = 0,15 0,3= 0,045 Przy założonym a = 0,15 i oszacowanej efektywności 0,3 produkt krajowy wzrasta o 4,5% rocznie
 przy pomocy MNK współczynnik makroekonomicznej efektywności inwestycji. Przykład: a = 0,15 (15% produktu krajowego) b = 0,3. R = a b = 0,15 0,3= 0,045. Przy założonym a = 0,15 i oszacowanej efektywności 0,3 produkt krajowy wzrasta o 4,5% rocznie.")
48
PKBt = - 102,98 + 1,529 Kt + 0,485 Zt MODEL I. Kudryckiej
gdzie: PKBt - indeks dynamiki PKB w cenach stałych (1990=100) Kt - indeks dynamiki majątku trwałego w cenach stałych (1990=100) Zt - indeks dynamiki przeciętnej liczby pracowników (1990=100) R2 = 97,69 !
 Kt - indeks dynamiki majątku trwałego w cenach stałych (1990=100) Zt - indeks dynamiki przeciętnej liczby pracowników (1990=100) R2 = 97,69 !")
49
REGRESJA LOGISTYCZNA (LOGISTIC REGRESSION)
Historia modelu logistycznego sięga końca XIX w.: P.F. Verhulst i R.F.Pearl Pierwsze zastosowania: prognoza wzrostu populacji Podstawy modelu: J. Berkson 1944 r. – „Application of the logistic function to bio-assay” Pełny model regresji logistycznej zastosowany po raz pierwszy w 1972 r. przez D.J. Finneya – „Probit analysis”

50
Yt = a/(1+b e–ct) KRZYWA LOGISTYCZNA (Logistic curve)
gdzie: Yt - wartość funkcji logistycznej w punkcie t a, b i c – to parametry funkcji logistycznej wartość a – odpowiada poziomowi nasycenia e – podstawa logarytmu naturalnego t - czas Funkcja logistyczna wzrasta najpierw powoli, potem w tempie coraz bardziej przyspieszonym i osiągnąwszy punkt przegięcia tempo maleje i wreszcie niemal całkowicie ustaje zbliżając się do punktu nasycenia

51
KRZYWA LOGISTYCZNA (Krzywa Gompertza) PRZYKŁAD
Tendencja rozwoju zasobów produkcyjnych linii automatycznie sterowanych a = – oszacowany poziom nasycenia, z pewnością zmieni się w miarę upływu czasu i za kilka lat wzrośnie

52
KRZYWA WYKŁADNICZA (Exponential regression)
Yt = a bt gdzie: Yt – wartość funkcji wykładniczej w punkcie t a i b to parametry funkcji a – to punkt wyjściowy (startu) funkcji wzrostu b – współczynnik przyrostu np. PKB Funkcja wykładnicza wzrasta w tempie stałym wg współczynnika b Przydatna w analizach i prognozowaniu procesów rozwojowych
 funkcji wzrostu. b – współczynnik przyrostu np. PKB. Funkcja wykładnicza wzrasta w tempie stałym wg współczynnika b. Przydatna w analizach i prognozowaniu procesów rozwojowych.")
53
KRZYWA WYKŁADNICZA - PRZYKŁAD
Tendencja rozwoju w kraju x Parametry (świat): a = $ (PKB na 1 mieszkańca świata) b = 1,02 (dynamika wzrostu) Równanie: Y = ,02t Parametry (Polska): a = $ PKB na 1 mieszkańca w 2002r. b = 1,035 (dynamika wzrostu) Y = ,035t dla t= Y= ,03510= ,41=14 541 Y = ,05t dla t= Y= ,0510 = ,63=16 792
: a = $ (PKB na 1 mieszkańca świata) b = 1,02 (dynamika wzrostu) Równanie: Y = ,02t. Parametry (Polska): a = $ PKB na 1 mieszkańca w 2002r. b = 1,035 (dynamika wzrostu) Y = ,035t dla t=10 Y= ,03510= ,41= Y = ,05t dla t=10 Y= ,0510 = ,63=")
54
yt= a + b sin(2pt/p+c) FUNKCJA TRYGONOMETRYCZNA (Sine curve)
gdzie: a, b, p i c - parametry równania a – średnia w danym okresie b – amplituda wahań liczona od średniej danego okresu p – długość okresu c – faza liczona od początku układu współrzędnych Przydatna w analizach wahań sezonowych i cykli koniunkturalnych

55
FUNKCJA PRODUKCJI (Production function)
Najpopularniejsza: funkcja produkcji typu Cobba-Douglasa, model dwuczynnikowy nieliniowy Podstawowe narzędzie analizy rozwoju procesu produkcyjnego Funkcja pozwala określić, jakiego poziomu produkcji można oczekiwać w określonym w przyszłości okresie, przy danych czynnikach produkcji: kapitale i pracy bądź przy różnych ich kombinacjach

56
FUNKCJA PRODUKCJI Vt – produkcja Kt – kapitał Lt - praca
Ogólna postać funkcji produkcji Cobba-Douglasa: Vt – produkcja Kt – kapitał Lt - praca a, b i c - parametry równania, d – czynnik losowy t - czas Szacowanie parametrów i czynnika losowego wg MNK lub Kt – środki trwałe Lt - środki obrotowe

57
ln PKB Pt = 0,225 + 0,173 ln ZPt + 0,817 ln MPt
FUNKCJA PRODUKCJI O postaci logarytmicznej typu Cobba-Douglasa w przemyśle przetwórczym: ln PKB Pt = 0, ,173 ln ZPt + 0,817 ln MPt gdzie: PKB Pt - wartość PKB wytworzona w przemyśle przetwórczym w cenach 2000 r. ZPt - przeciętna liczba zatrudnionych w przemyśle przetwórczym MPt - wartość majątku trwałego w przemyśle przetwórczym w cenach 2000 r. R2=94,59 !

58
Zbudować właściwy model:
PROBLEMY PRAKTYCZNE Zbudować właściwy model: a. dobór czynników (zmiennych niezależnych) b. wybór postaci funkcji Szacowanie parametrów: a. zebranie danych statystycznych b. zastosowanie MNK Interpretacja modelu: a. ograniczenia danych statystycznych b. świadomość krzywej
 b. wybór postaci funkcji. Szacowanie parametrów: a. zebranie danych statystycznych. b. zastosowanie MNK. Interpretacja modelu: a. ograniczenia danych statystycznych. b. świadomość krzywej.")
59
ŚWIAT: Korelacja między wskaźnikiem przedsiębiorczości i czasem niezbędnym na rozpoczęcie działalności Time to start a business vs. # of SMEs 10 20 30 40 50 60 70 80 90 100 120 140 160 Time to start a business (days) # of SMEs per people y = - 0,21x + 36,7
 # of SMEs per people. y = - 0,21x + 36,7.")
60
ŚWIAT: Korelacja między wskaźnikiem przedsiębiorczości i nakładami niezbędnymi dla rozpoczęcia działalności Cost to start a business vs. # of SMEs y = - 0,28x + 33,3 90 80 70 60 # of SMEs per people 50 40 30 20 10 10 20 30 40 50 60 70 Cost to start a business (% of income per capita)
")
61
ŚWIAT: Korelacja między wskaźnikiem przedsiębiorczości i dostępnością do kredytu
Private Credit vs. # of SMEs 10 20 30 40 50 60 70 80 90 100 150 200 Private credit as % of GDP # of SMEs per people y = 0,14x + 21,7

62
ŚWIAT: Korelacja między wskaźnikiem przedsiębiorczości i klimatem inwestycyjnym
Investment Climate vs. # of SMEs 10 20 30 40 50 60 70 80 15 25 35 45 55 65 75 85 Investment Climate Index # of SMEs per people y = 0,45x + 11

63
POLSKA: Tendencje zmian w umieralności niemowląt w latach 1970 - 2002
Wartości teoretyczne Wartości empiryczne Liczba zgonów y = -595,4 x ,49 lata

64
POLSKA: Przeobrażenia struktury społeczno-ekonomicznej ludności migrującej w latach Trend empiryczny i teoretyczny napływu ludności z wyższym wykształceniem Wartości teoretyczne Wartości empiryczne y = 104,94 t2 – 3044,7t Sy = 5084,01 R2= 0,5894 Liczba osób lata

65
POLSKA: Przeobrażenia struktury społeczno-ekonomicznej ludności migrującej w latach Trend empiryczny i teoretyczny napływu ludności z wykształceniem podstawowym i niepełnym podstawowym Wartości teoretyczne Liczba osób Wartości empiryczne y = 452,44 t2 – 20813t Sy = 30418,55 R2= 0,849 lata

Podobne prezentacje
, gdzie X jest liczbą osób w rodzinie, a Y liczbą izb w mieszkaniu. Niech f.r.p. tej zmiennej.>")














 zmiennej>")



>")