Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Agnieszka Nowak Instytut Informatyki, Uniwersytet Śląski
Ile ludzkiej inteligencji jest w sztucznej inteligencji ? - Techniki inteligentne w zastosowaniach praktycznych Agnieszka Nowak Instytut Informatyki, Uniwersytet Śląski

2
Czy sztuczna inteligencja to robotyka ?
Mózgiem każdego urządzenia, które ma wykazywać się inteligencją jest odpowiednio zaprogramowany komputer. Dział nauki zajmujący się inteligencją przedmiotów nieożywionych to sztuczna inteligencja. Wizja przyszłości: inteligentne, autonomiczne roboty, zdolne do samodzielnego rozwiązywania złożonych problemów.

3
Inteligencja i ekspert dziedzinowy
Inteligencja - (psych.) zespół zdolności umysłowych umożliwiających jednostce sprawne korzystanie z nabytej wiedzy oraz skuteczne zachowanie się wobec nowych zadań i sytuacji EKSPERT: Człowiek posiadający specjalistyczną wiedzę z pewnej dziedzinie (wiedzę dziedzinową) i umiejętność stosowania jej dla podejmowania decyzji związanych z tą dziedziną (umiejętność wnioskowania w oparciu o posiadaną wiedzę), nabyte w wyniku studiów i praktyki.
 zespół zdolności umysłowych umożliwiających jednostce sprawne korzystanie z nabytej wiedzy oraz skuteczne zachowanie się wobec nowych zadań i sytuacji. EKSPERT: Człowiek posiadający specjalistyczną wiedzę z pewnej dziedzinie (wiedzę dziedzinową) i umiejętność stosowania jej dla podejmowania decyzji związanych z tą dziedziną (umiejętność wnioskowania w oparciu o posiadaną wiedzę), nabyte w wyniku studiów i praktyki.")
4
Sztuczna Inteligencja - AI
Sztuczna Inteligencja - (skrót AI od angielskiego określenia Artificial Intelligence) - jest to pojęcie stosowane w informatyce i oznacza rozwiązywanie problemów sposobami wzorowanymi na naturalnych działaniach i procesach poznawczych człowieka za pomocą symulujących je programów komputerowych.
 - jest to pojęcie stosowane w informatyce i oznacza rozwiązywanie problemów sposobami wzorowanymi na naturalnych działaniach i procesach poznawczych człowieka za pomocą symulujących je programów komputerowych.")
5
System ekspertowy – definicja…
System ekspercki (funkcjonuje też nazwa system ekspertowy) jest to program, lub zestaw programów komputerowych wspomagający korzystanie z wiedzy i ułatwiający podejmowanie decyzji. Systemy ekspertowe mogą wspomagać bądź zastępować ludzkich ekspertów w danej dziedzinie, mogą dostarczać rad, zaleceń i diagnoz dotyczących problemów tej dziedziny.
 jest to program, lub zestaw programów komputerowych wspomagający korzystanie z wiedzy i ułatwiający podejmowanie decyzji. Systemy ekspertowe mogą wspomagać bądź zastępować ludzkich ekspertów w danej dziedzinie, mogą dostarczać rad, zaleceń i diagnoz dotyczących problemów tej dziedziny.")
6
Inteligencja ludzka a sztuczna inteligencja ?
Zastosowania systemów ekspertowych: diagnozowanie chorób poszukiwanie złóż minerałów identyfikacja struktur molekularnych udzielanie porad prawniczych diagnoza problemu (np. nieprawidłowego działania urządzenia)
")
7
Systemy ekspertowe… Systemy ekspertowe:
są narzędziem kodyfikacji wiedzy eksperckiej, mają zdolność rozwiązywania problemów specjalistycznych, w których duża rolę odgrywa doświadczenie a wiedza ekspercka jest dobrem rzadkim i kosztownym, zwiększają dostępność ekspertyzy, zapewniają możliwość prowadzenia jednolitej polityki przez centralę firm mających wiele oddziałów, poziom ekspertyzy jest stabilny - jej jakość nie zależy od warunków zewnętrznych i czasu pracy systemu, jawna reprezentacja wiedzy w postaci zrozumiałej dla użytkownika końcowego, zdolność do objaśniania znalezionych przez system rozwiązań, możliwość przyrostowej budowy i pielęgnacji bazy wiedzy.

8
Wnioskowanie Dwie podstawowe strategie wnioskowania:
Wnioskowanie w przód, zwane też wnioskowaniem progresywnym. Polega ono na uaktywnianiu reguł spełnionych, a więc takich, których przesłanki są w zbiorze faktów. Uaktywnienie reguły powoduje dopisanie nowego faktu, co może spowodować, że spełniona i potem uaktywniona może zostać kolejna reguła. Wnioskowanie w przód nie może odbyć się bez faktów. Mówi się, że jest ono sterowane faktami ( ang. data driven). Wnioskowanie wstecz, zwane też regresywnym. Polega ono na potwierdzeniu prawdziwości postawionej hipotezy, zwanej celem wnioskowania. Hipoteza jest potwierdzona wtedy, gdy istnieje reguła, której przesłanki są w bazie faktów a konkluzja zgodna jest z hipotezą. Ustalenie prawdziwości przesłanek może powodować konieczność uaktywnienia wielu reguł. Wnioskowanie wstecz nie może odbyć się bez ustalonej hipotezy, stanowiącej cel wnioskowania. Mówi się, że jest ono sterowane celem ( ang. goal driven).
. Wnioskowanie wstecz, zwane też regresywnym. Polega ono na potwierdzeniu. prawdziwości postawionej hipotezy, zwanej celem wnioskowania. Hipoteza jest. potwierdzona wtedy, gdy istnieje reguła, której przesłanki są w bazie faktów a. konkluzja zgodna jest z hipotezą. Ustalenie prawdziwości przesłanek może. powodować konieczność uaktywnienia wielu reguł. Wnioskowanie wstecz nie może odbyć się bez ustalonej hipotezy, stanowiącej cel. wnioskowania. Mówi się, że jest ono sterowane celem ( ang. goal driven).")
10
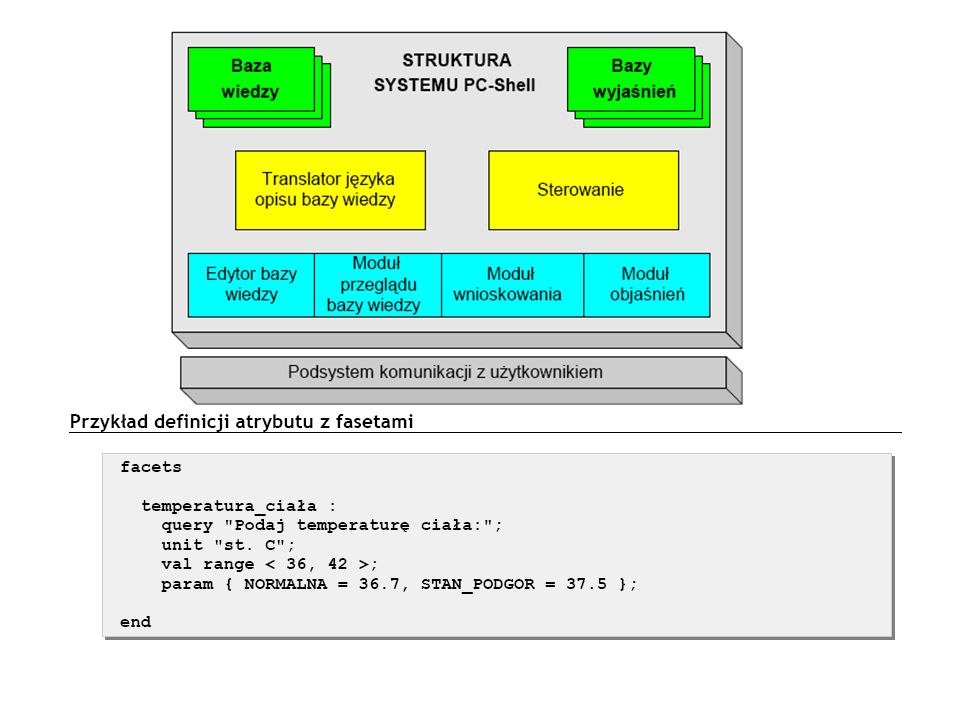
Architektura SE

11
Wyznaczniki dobrego systemu ekspertowego:
Udzielanie jak najbardziej precyzyjnych i wiarygodnych odpowiedzi Prostota obsługi dla każdego użytkownika Rozwiązywanie problemów w określonym czasie Umiejętność imitowania wiedzy i wieloletniego doświadczenia eksperta Uniwersalność Rozbudowana i dobrej jakości baza danych

13
Reprezentacja wiedzy…

14
Reguły proste

15
Reguły złożone

16
Definicje AI Automatyzacja czynności, które wiążemy z myśleniem, takich jak: podejmowanie decyzji, rozwiązywanie problemów, zapamiętywanie... . R. Bellman, An Introduction to Artificial Intelligence, Boyd & Frase, 1978 Badania nad zdolnościami umysłowymi poprzez stosowanie metod obliczeniowych. E. Charniak, D. McDermott, Introduction to Artificial Intelligence, Addison-Wesley Publishing, 1985 Sztuka tworzenia maszyn, które wykonują funkcje wymagające inteligencji od ludzi. R. Kurzweil, The Age of Intelligence Machines, The MIT Press, 1992 Dziedzina badan zajmująca się maszynami, które są zdolne wykonywać rzeczy, jakie wykonują ludzie używając inteligencji. M. Minsky, Society of Mind, Simon & Schuster, 1985 Dziedzina informatyki zajmująca się automatyzacją inteligentnych zachowań. G.F. Luger, Artificial Intelligence, Structures and Strategies for Complex Problem Solving, AddisonWesley, 2002 Dwa uzupełniające znaczenia terminu Sztuczna Inteligencja: … dyscyplina inżynierii dotyczy tworzenia inteligentnych maszyn, … empiryczna nauka, zajmująca się obliczeniowym modelowaniem ludzkiej inteligencji. M. I. Jordan, S. Russell, Computational Intelligence, The MIT Encylopedia of Cognitive Sciences, The MIT Press, 1999

17
Definicje… Definicje… dlaczego ich aż tyle ?
Sztuczna inteligencja stała się interdyscyplinarną dziedziną naukową, zajmującą się: badaniem zachowań inteligentnych istot żywych, eksploracją dokonań różnych dyscyplin naukowych w zakresie procesów myślenia i uczenia się, poszukiwaniem nowych technik i metod modelowania zachowań inteligentnych, syntezą algorytmów zdolnych do rozwiązywania problemów trudnych i uciążliwych, budową systemów komputerowych zdolnych do inteligentnego sterowania maszynami i urządzeniami.

18
Badamy „model” ? Czy „rzeczywistość” ??
Rzeczywistość jest zbyt bogata i różnorodna. „Kawałek” rzeczywistości, który nas interesuje, trzeba wyciąć z kontekstu i opisać jakimś formalnym językiem. Ponieważ jest to działanie bardzo podstawowe, może być stosowane w wielu dziedzinach badań, od socjologii po biologię molekularną i fizykę wysokich energii. Od modelu przechodzi się często do symulacji... Rozwiązywanie problemów decyzyjnych odbywa się w trójkącie: problem model metoda

19
…że niby komputer zamiast lekarza ?
Medyczny System Ekspertowy będzie jedynie wspomagał, ale nie zastąpi pracy lekarza. W szpitalu w Ottawie, w izbie przyjęć nie dyżuruje specjalista chirurg, lecz stażyści, interniści, a nawet wykwalifikowane pielęgniarki. Chirurg jest pod telefonem. Tymczasem trzeba ocenić, czy konkretnemu małemu pacjentowi chirurg jest potrzebny. To nie jest takie proste. Trafność decyzji, czy przywołać chirurga, czy skierować na obserwację, czy też odesłać do domu, jest rzędu sześćdziesięciu procent. Czyli często się zdarza, że do domu odsyła się kogoś bardzo chorego, a chirurga wzywa się do banalnego zatrucia pokarmowego. Dzięki sztucznej inteligencji, maszyna może wyindukować z danych reguły decyzyjne, jednak, na przykład w przypadku medycyny, dopiero po zrozumieniu i akceptacji tych reguł przez lekarza reguły te mogą pretendować do miana wiedzy i prowadzić do interesującego, potwierdzającego intuicję odkrycia. Niewątpliwie maszyny w coraz większym stopniu będą wyręczały człowieka w wykonywaniu pewnych intelektualnych czynności, bo są sprawniejsze obliczeniowo, bardziej pojemne pamięciowo, nie męczą się, nie mają złych dni itd. W związku z tym potrafią wykonywać prace, które przerastają człowieka swoim ogromem i uciążliwością.

20
Fakty… liczby… Rozmiar baz danych współczesnych systemów informatycznych osiąga wielkości rzędu terabajtów. Średniej wielkości hipermarket rejestruje dziennie sprzedaż przynajmniej kilkunastu tysięcy produktów. Puchną bazy danych systemów e-commerce, dostępnych na bieżąco, 24 godziny na dobę – wzrasta liczba ich klientów oraz liczba zawieranych transakcji.

21
Fakty… liczby… (cd.) Jednocześnie….
Konkurencja pomiędzy firmami zaostrza się. Coraz trudniej znaleźć nowe obszary ekspansji, nisze rynkowe. Coraz trudniej utrzymać dotychczasowych klientów. Bazy danych zawierają ogromne ilości użytecznych informacji, pozwalających firmom utrzymać lub wzmocnić ich pozycje rynkową.

22
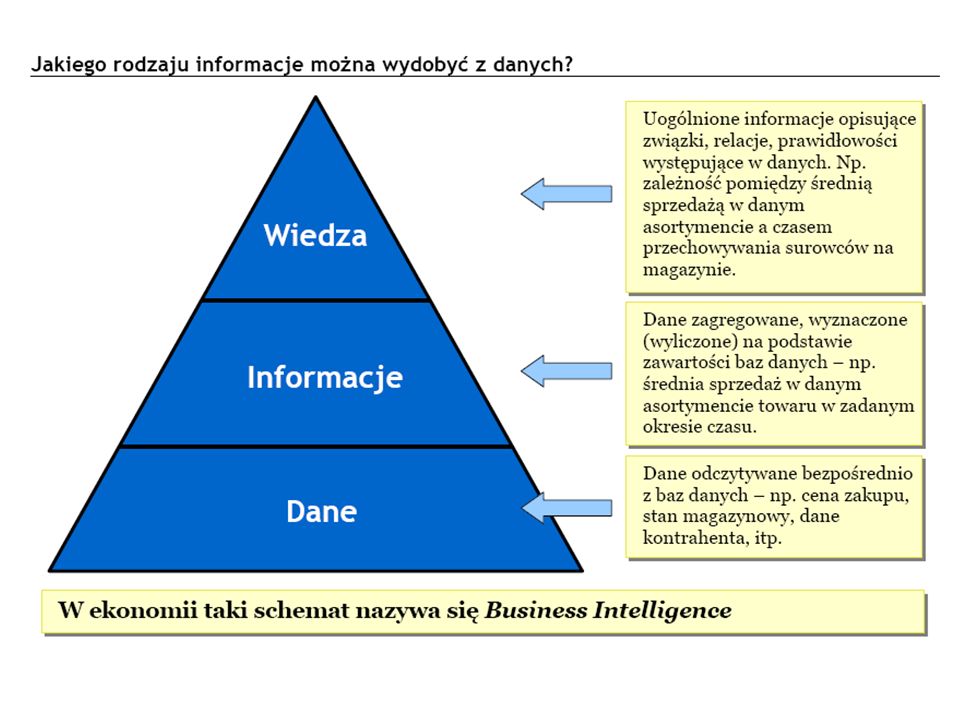
Co więc można się wywiedzieć z danych ?
Faktów nigdy za wiele… Korporacyjne bazy danych kopalnią użytecznych informacji: Użyteczne informacje są wyrażone niejawnie, są ukryte w danych, należy je odkryć, wydobyć. Proces ten nazywa się potocznie eksploracją danych (ang. Data Mining). Świadomość istnienia ukrytego potencjału informacyjnego baz danych jest znana od lat. Jednak dopiero w ciągu ostatnich kilkunastu lat intensywnie prowadzi się badania nad odkrywaniem metod eksploracji danych oraz wykorzystuje się te metody w praktyce. Co więc można się wywiedzieć z danych ?
. Świadomość istnienia ukrytego potencjału informacyjnego baz danych jest znana od lat. Jednak dopiero w ciągu ostatnich kilkunastu lat intensywnie prowadzi się badania nad odkrywaniem metod eksploracji danych oraz wykorzystuje się te metody w praktyce. Co więc można się wywiedzieć z danych")
23
Jaką wiedzę odkrywamy dzięki DM …
1.odkrywanie asocjacji (associations) znajdowanie reguł typu:piwo -> orzeszki 2.wzorce sekwencji (sequential patterns) znajdowanie sekwencji dot. np. zakupów klienta: (TV, video, kamera) 3. klasyfikacja (classifications) klasyfikacja danych do grup ze względu na atrybut decyzyjny, np.: klasyfikacja klientów przez bank do grup: dać kredyt / nie dać kredytu 4. analiza skupień (clustering) grupowanie danych na wcześniej nieznane klasy, znajdowanie wspólnych cech, np.: wyodrębnienie różnych rodzajów klientów – różnych taryf – przez sieć telefonii komórkowej 5. podobieństwo szeregów czasowych (time-series similarities) badanie podobieństwa przebiegów czasowych, np. wykresów giełdowych 6. wykrywanie odchyleń (deviation detection) znajdowanie anomalii, wyjątków, np.: rozpoznawanie kradzieży karty kredytowej (nietypowe operacje na koncie)
 znajdowanie reguł typu:piwo -> orzeszki. 2.wzorce sekwencji (sequential patterns) znajdowanie sekwencji dot. np. zakupów klienta: (TV, video, kamera) 3. klasyfikacja (classifications) klasyfikacja danych do grup ze względu na atrybut decyzyjny, np.: klasyfikacja klientów przez bank do grup: dać kredyt / nie dać kredytu. 4. analiza skupień (clustering) grupowanie danych na wcześniej nieznane klasy, znajdowanie wspólnych cech, np.: wyodrębnienie różnych rodzajów klientów – różnych taryf – przez sieć telefonii komórkowej. 5. podobieństwo szeregów czasowych (time-series similarities) badanie podobieństwa przebiegów czasowych, np. wykresów giełdowych. 6. wykrywanie odchyleń (deviation detection) znajdowanie anomalii, wyjątków, np.: rozpoznawanie kradzieży karty kredytowej (nietypowe operacje na koncie)")
24
Mniej poważna definicja DM …
“Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać”

25
odkrywaniem wiedzy zapisanej niejawnie w dużych zbiorach danych oraz
Data mining – eksploracja danych – jest dziedziną informatyki zajmującą się odkrywaniem wiedzy zapisanej niejawnie w dużych zbiorach danych oraz przedstawieniem jej w zrozumiały dla użytkownika sposób. Pod pojęciem wiedzy rozumieć będziemy relacje, powiązania, związki i wzorce odkrywane przez algorytmy eksploracji danych w sposób autonomiczny. Eksploracja danych (DM – Data Mining) określana jest również pojęciem odkrywania wiedzy w bazach danych (KDD – Knowledge Discovery in Databases)
 określana jest również pojęciem odkrywania wiedzy w bazach danych (KDD – Knowledge Discovery in Databases)")
29
Cała prawda o OLAP… Problemy na styku OLAP a wspomaganie decyzji:
Systemy OLAP działają zwykle obliczając zagregowane wielkości na podstawie danych pochodzących z magazynu danych. Systemu OLAP pozwalają na analizowanie tego co się wydarzyło na podstawie danych o przeszłości. Działanie OLAP jest sterowane hipotezą sformułowaną przez użytkownika (ang. query-driven eksploration), system OLAP jest pasywny. Używając systemów OLAP można wchodzić w głąb, dochodząc do danych bardziej szczegółowych, ale użytkownik nadal pozostaje odpowiedzialny za identyfikowanie interesujących trendów czy powiązań. Koncepcje postrzegania danych jako „wielowymiarowych kostek” powoduje problemy w percepcji przeprowadzanych analiz. Do skutecznego podejmowania decyzji potrzebna jest wiedza o prawidłowościach rządzących daną dziedziną. Decydenci oczekują, iż systemy informatyczne prawidłowości te odkryją, potwierdzając to, co już wiemy lub dostarczą nam nowej wiedzy.
, system OLAP jest pasywny. Używając systemów OLAP można wchodzić w głąb, dochodząc do danych bardziej szczegółowych, ale użytkownik nadal pozostaje odpowiedzialny za identyfikowanie interesujących trendów czy powiązań. Koncepcje postrzegania danych jako „wielowymiarowych kostek powoduje. problemy w percepcji przeprowadzanych analiz. Do skutecznego podejmowania decyzji potrzebna jest wiedza o prawidłowościach. rządzących daną dziedziną. Decydenci oczekują, iż systemy informatyczne. prawidłowości te odkryją, potwierdzając to, co już wiemy lub dostarczą nam nowej. wiedzy.")
30
Różne metody – cel ten sam !!!

32
Jeżeli jest ładna pogoda to mam dobry humor. pogoda=ladna → humor=tak
Jeżeli jest ładna pogoda i mam czas wolny to pójdę na spacer. pogoda=ladna czas_wolny=tak → zajecie=spacer

33
Baza danych – przykład

34
Tablica decyzyjna ? Zachmurzenie=slonce temperatura = goraco
Po wyodrębnieniu atrybutów warunkowych i decyzyjnych taka tabela staje się tablicą decyzyjną. Z tablicy można próbować bezpośrednio odczytywać reguły: Zachmurzenie=slonce temperatura = goraco wilgotnosc = wysoka wiatr=slaby → grac=nie 14 rekordów produkuje 14 reguł... . A jeżeli rekordów będzie kilkadziesiąt tysięcy? Kto potrzebuje wiedzy w postaci kilkudziesięciu tysięcy reguł ?????

35
Klasyfikator wybawcą ?

36
Co nam daje DataMining ? Eksploracja danych
Stosując zdroworozsądkową analizę zbioru danych udało się odkryć zależności pomiędzy polami warunkującymi a polem decyzyjnym. Czy to już jest Data Mining ? Prawie tak, ale niech to robi komputer ! Eksploracja danych dane wiedza grac=nie if zachmurzenie=słońce;wilgotność=wysoka grac=tak if zachmurzenie=pochmurno grac=tak if zachmurzenie=słońce;wilgotność=normalna grac=nie if zachmurzenie=deszcz;wiatr=silny grac=tak if zachmurzenie=deszcz;wiatr=slaby warunki decyzje

37
Metody eksploracji danych można podzielić, bardzo ogólnie, na 6 zasadniczych klas.
• Odkrywanie asocjacji Najszersza klasa metod obejmująca, najogólniej, odkrywanie różnego rodzaju nieznanych zależności w bazie danych. Metody te obejmują głównie odkrywanie asocjacji pomiędzy obiektami. Generalnie, odkrywane zależności posiadają pewne miary statystyczne określające ich wsparcie i ufność. • Klastrowanie Celem tych metod jest znajdowanie skończonego zbioru klas obiektów (klastrów) w bazie danych posiadających podobne cechy. Liczba klastrów jest nieznana, stąd, proces klastrowania przebiega, najczęściej, w dwóch cyklach: cykl zewnętrzny przebiega po liczbie możliwych klastrów, cykl wewnętrzny próbuje znaleźć optymalny podział obiektów pomiędzy klastry. • Odkrywanie wzorców sekwencji Odkrywanie czasowych wzorców zachowań, np. znajdowanie sekwencji notowań giełdowych, zachowań klientów ubezpieczalni, klientów supermarketów. • Odkrywanie klasyfikacji Celem tych metod jest znajdowanie zależności pomiędzy klasyfikacją obiektów (klasyfikacja naturalna bądź wprowadzona przez eksperta) a ich charakterystyką. Zastosowanie: charakterystyka pacjentów, klientów kart kredytowych, pożyczkobiorców. • Odkrywanie podobieństw w przebiegach czasowych Znajdowanie podobieństw w przebiegach czasowych opisujących określone procesy. • Wykrywanie zmian i odchyleń Znajdowanie różnic pomiędzy aktualnymi a oczekiwanymi wartościami danych: znajdowanie anomalnych zachowań klientów ubezpieczalni, klientów kart kredytowych, klientów firm telekomunikacyjnych.
 w bazie. danych posiadających podobne cechy. Liczba klastrów jest nieznana, stąd, proces klastrowania przebiega, najczęściej, w dwóch cyklach: cykl zewnętrzny przebiega po liczbie możliwych klastrów, cykl wewnętrzny próbuje znaleźć optymalny podział obiektów pomiędzy klastry. • Odkrywanie wzorców sekwencji. Odkrywanie czasowych wzorców zachowań, np. znajdowanie sekwencji notowań giełdowych, zachowań klientów ubezpieczalni, klientów supermarketów. • Odkrywanie klasyfikacji. Celem tych metod jest znajdowanie zależności pomiędzy klasyfikacją obiektów (klasyfikacja. naturalna bądź wprowadzona przez eksperta) a ich charakterystyką. Zastosowanie: charakterystyka pacjentów, klientów kart kredytowych, pożyczkobiorców. • Odkrywanie podobieństw w przebiegach czasowych. Znajdowanie podobieństw w przebiegach czasowych opisujących określone procesy. • Wykrywanie zmian i odchyleń. Znajdowanie różnic pomiędzy aktualnymi a oczekiwanymi wartościami danych: znajdowanie anomalnych zachowań klientów ubezpieczalni, klientów kart kredytowych, klientów firm telekomunikacyjnych.")
38
Analiza danych w bazach danych
wielkie bazy danych (Very Large Databases) i magazyny danych (Data Warehouses) rozmiary współczesnych systemów baz danych sieć sprzedaży Wal-Mart gromadzi dziennie dane dotyczące ponad 20 milionów transakcji koncern Mobil Oil rozwija magazyn danych pozwalający na przechowywanie ponad 100 terabajtów danych o wydobyciu ropy naftowej system satelitarnej obserwacji EOS zbudowany przez NASA generuje w każdej godzinie dziesiątki gigabajtów danych niewielkie supermarkety rejestrują codziennie sprzedaż tysięcy artykułów wielkie wolumeny danych są trudne w analizowaniu informacje o dotychczasowej działalności przedsiębiorstwa, poziomie i strukturze sprzedaży oraz cechach klientów mogą posłużyć do wspomagania podejmowania decyzji
 i magazyny danych (Data Warehouses) rozmiary współczesnych systemów baz danych. sieć sprzedaży Wal-Mart gromadzi dziennie dane dotyczące ponad 20 milionów transakcji. koncern Mobil Oil rozwija magazyn danych pozwalający na przechowywanie ponad 100 terabajtów danych o wydobyciu ropy naftowej. system satelitarnej obserwacji EOS zbudowany przez NASA generuje w każdej godzinie dziesiątki gigabajtów danych. niewielkie supermarkety rejestrują codziennie sprzedaż tysięcy artykułów. wielkie wolumeny danych są trudne w analizowaniu. informacje o dotychczasowej działalności przedsiębiorstwa, poziomie i strukturze sprzedaży oraz cechach klientów mogą posłużyć do wspomagania podejmowania decyzji.")
39
Data Mining - sukcesy Database Marketing w American Express Database Marketing polega na analizie danych o klientach w celu znajdowania schematów ich preferencji i następnie wykorzystywania tych schematów dla precyzyjnej selekcji kolejnych klientów. „Database Marketing” w American Express doprowadził do 10-15% wzrostu zakupów z wykorzystaniem kart kredytowych. Weryfikacja poprawności danych w Reuters Reuters stosuje techniki eksploracji danych dla weryfikacji poprawności i wykrywania prawdopodobnych przekłamań w wysokości publikowanych kursów wymiany walut. Profil słuchacza w BBC BBC przy pomocy systemu eksploracji danych przewiduje profil widowni programów telewizyjnych w celu wyboru optymalnych pór ich nadawania. Skład zespołu w Orlando Magic trener Orlando Magic wykorzystuje data-mining do ustalania składu zespołu rozgrywającego mecze - rezultat likwidacja trendu spadkowego (2 wygrane mecze)
")
40
Data Mining – sukcesy cd.
Firma American Express podała, że wykorzystanie technik eksploracji na bazie danych klientów pozwoliło zwiększyć o 10 – 15 % użycie jej kart kredytowych. Bardzo duża firma handlowa dzięki ekstrakcji potrafiła określić 5-cio procentowy segment tych klientów, którzy charakteryzują się tym, że regularnie udzielają odpowiedzi na różne zapytania firmy. Klienci ci dostarczali 60 % wszystkich odpowiedzi. Dzięki ustaleniu tego faktu firma zwiększyła 12- krotnie stopę odpowiedzi i zmniejszyła koszty opłat pocztowych o 95 %.

41
Data Mining - Zależności w bazach danych
wiek lat prawo kolor poj. moc razem kierowcy jazdy pojazdu silnika szkody biały czerwony czerwony czarny czerwony niebieski kierowcy, którzy jeżdżą czerwonymi samochodami o pojemności 650 ccm, powodują wypadki drogowe kierowcy w wieku powyżej 40 lat jeżdżą samochodami o pojemności większej niż 1600 ccm kierowcy, którzy posiadają prawo jazdy dłużej niż 3 lata, nie powodują wypadków kierowcy w wieku poniżej 30 lat jeżdżą samochodami koloru czerwonego

42
Drzewa decyzyjne - przykład

43
Drzewa decyzyjne dla przykładu

44
przykład nie nie nie nie nie

45
Rozkład obiektów do klas decyzyjnych
słonecznie 1,2,8,9,11 3 N + 2 T 5/14 zachmurzenie pochmurno 4/14 3,7,12,13 4 T + 0 N deszczowo 4,5,6,10,14 3 T + 2 N 5/14 4/14 gorąco 1,2,3,13 2 N + 2 T temperatura łagodnie 6/14 4,8,10,11,12,14 4 T + 2 N zimno 5,6,7,9 3 T + 1 N 4/14 wysoka 1,2,3,4,8,12,14 3 N + 4 T 7/14 wilgotność normalna 5,6,7,9,10,11,13 6 T + 1 N 7/14 słaby 1,3,4,5,8,9,10,13 2 N + 6 T 8/14 wiatr 2,6,7,11,12,14 3 T + 3 N 6/14 silny Entropia (rozkład):
:")
46
Information Gain – przykład
W przykładzie golf jako pierwszy do podziału został wybrany atrybut „zachmurzenie”, bo jego wskaźnik „gain” był największy S – zawiera 14 elementów 2 klasy – TAK (9 elementów) i NIE (5 elementów) E(S) = -9/14 log 9/14 – 5/14 log 5/14 = = 0.94 E(S/zachmurzenie) = 5/14(-3/5log23/5 – 2/5log22/5) + 4/14(-1log21 – 0log 20) + 5/14(-3/5log23/5 – 2/5log22/5) = 0.2 E(S/temperatura) = 4/14(-2/4log22/4 – 2/4log22/4) + 4/14(-3/4log23/4 – 1/4 log21/4) + 6/14(-2/6log22/6 – 4/6log24/6) = 0.48 E(S/wilgotnosc) = 7/14(-4/7log24/7 – 3/7log23/7) + 7/14(-6/7log26/7 – 1/7 log21/7) = 0.43 E(S/wiatr) = 8/14(-6/8log26/8 – 2/8log22/8) + 6/14(-3/6log23/6 – 3/6log2 3/6) = 0.71 Gain Information(zachmurzenie) = 0.94 – 0.2 = 0.74 Gain Information(temperatura) = 0.94 – 0.48 = 0.46 Gain Information(wilgotnosc) = 0.94 – 0.43 = 0.51 Gain Information(wiatr) = 0.94 – 0.71 = 0.23 Największy zysk informacji dostarcza atrybut „zachmurzenie” i to on będzie korzeniem drzewa…
 i NIE (5 elementów) E(S) = -9/14 log 9/14 – 5/14 log 5/14 = = E(S/zachmurzenie) = 5/14(-3/5log23/5 – 2/5log22/5) + 4/14(-1log21 – 0log 20) + 5/14(-3/5log23/5 – 2/5log22/5) = 0.2. E(S/temperatura) = 4/14(-2/4log22/4 – 2/4log22/4) + 4/14(-3/4log23/4 – 1/4 log21/4) + 6/14(-2/6log22/6 – 4/6log24/6) = E(S/wilgotnosc) = 7/14(-4/7log24/7 – 3/7log23/7) + 7/14(-6/7log26/7 – 1/7 log21/7) = E(S/wiatr) = 8/14(-6/8log26/8 – 2/8log22/8) + 6/14(-3/6log23/6 – 3/6log2 3/6) = Gain Information(zachmurzenie) = 0.94 – 0.2 = Gain Information(temperatura) = 0.94 – 0.48 = Gain Information(wilgotnosc) = 0.94 – 0.43 = Gain Information(wiatr) = 0.94 – 0.71 = Największy zysk informacji dostarcza atrybut „zachmurzenie i to on będzie korzeniem drzewa…")
47
R1: grac=nie if zachm=słońce and temp=gorąco and wilg=wysoka and wiatr=słaby
R2: grac=nie if zachm=słońce and temp=gorąco and wilg=wysoka and wiatr=silny … R14: grac=nie if zachm=deszcz and temp=średnio and wilg=wysoka and wiatr=silny grac=nie if zachmurzenie=słońce;wilgotność=wysoka grac=tak if zachmurzenie=pochmurno grac=tak if zachmurzenie=słońce;wilgotność=normalna grac=nie if zachmurzenie=deszcz;wiatr=silny grac=tak if zachmurzenie=deszcz;wiatr=slaby

48
Jak zadziała SE z taką bazą wiedzy ?

49
Inne metody analizy danych DM
Metody eksploracji danych odkrywanie asocjacji odkrywanie wzorców sekwencji klasyfikacja analiza skupień - grupowanie szeregi czasowe wykrywanie zmian i odchyleń Grupowanie jest to podział zbioru obiektów na podzbiory taki by podobieństwo obiektów należących do jednego podzbioru było największe a obiektów należących do różnych podzbiorów najmniejsze.

50
Grupowanie – analiza skupień
Na czym polega grupowanie ? Obiekt jest przydzielony do skupienia, którego środek ciężkości leży najbliżej w sensie odległości euklidesowej.

51
Analiza skupień – cluster analysis
Uczenie nienadzorowane dany jest zbiór uczący, w którym obiekty nie są poklasyfikowane celem jest wykrycie nieznanych klasyfikacji, podobieństw między obiektami jak znajdować podobieństwo ? Miary odległości, Miary podobieństwa. X4 : X22:

53
Analiza skupień – przykład

54
Coraz trudniej jest uzyskać wartościową informację
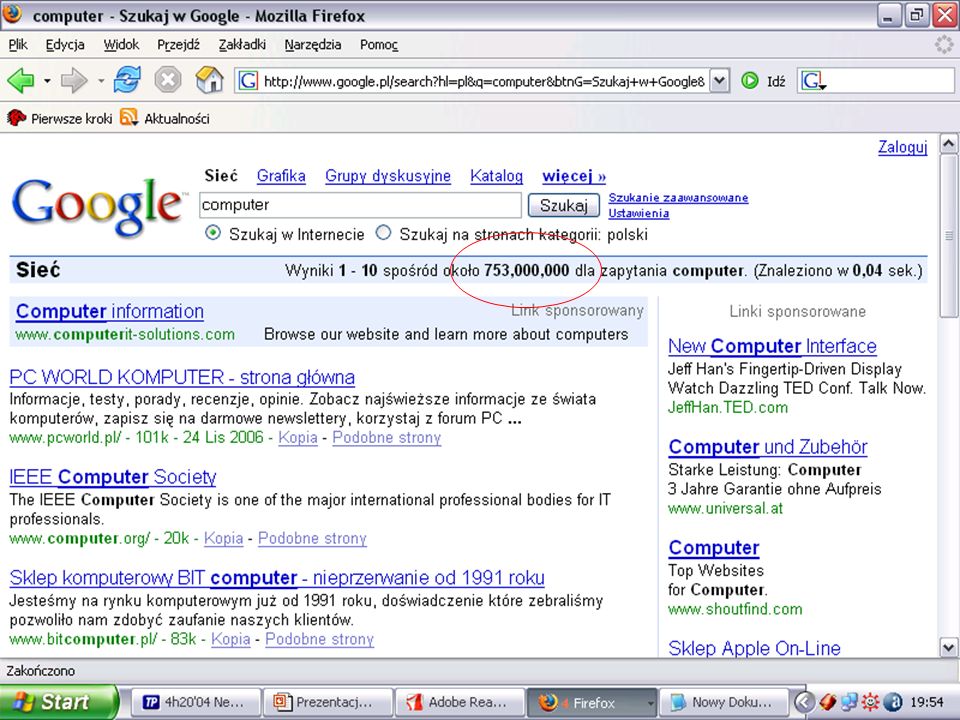
Problem z wyszukiwaniem informacji … Internet to dzisiaj: Użytkownicy ++, dane ^ 2 Postęp technologii Spadek wiarygodności Coraz trudniej jest uzyskać wartościową informację PROBLEM użytkownik dzisiaj: Oczekiwanie dostępności informacji: Łatwo, szybko i dokładnie

56
Za dużo !!!

61
Analiza koszykowa… to jest to !
Up-selling i cross-selling to 2 metody maksymalizowania zysku z jednej transakcji, a tym samym dochodów w ujęciu globalnym. Są to określenia dla działań mających jeden cel: aby klient kupił więcej niż planował. Analiza koszykowa - właściwy krok w kierunku cross- i up-sellingu Maksymalizacja zysku jest możliwa dzięki: Zrozumieniu, które produkty (usługi) są kupowane razem?, Zrozumieniu, które produkty są kupowane w następnej kolejności ?. Wykorzystanie narzędzi Data Mining pozwala nie tylko znaleźć odpowiedź na pytanie jakie produkty zwykle występują wspólnie w koszyku, ale także znaleźć takie produkty, których obecność w koszyku warunkuje obecność innych produktów i określić jak wysoki jest poziom prawdopodobieństwa tego typu zdarzeń.
 są kupowane razem , Zrozumieniu, które produkty są kupowane w następnej kolejności . Wykorzystanie narzędzi Data Mining pozwala nie tylko znaleźć odpowiedź na pytanie jakie produkty zwykle występują wspólnie w koszyku, ale także znaleźć takie produkty, których obecność w koszyku warunkuje obecność innych produktów i określić jak wysoki jest poziom prawdopodobieństwa tego typu zdarzeń.")
62
Analiza koszykowa… Menedżerowie i analitycy mogą używać "analiz koszykowych", aby planować między innymi: kampanie promocyjne - obniżone ceny przy zakupie na kolejne ze współkupowanych produktów, kupony promocyjne rozdawane przy zakupie określonych produktów itp. położenie produktów - ustawiać produkty współkupowane w sąsiedztwie jeśli współkupowanie jest silne lub umieszczanie produktów z dala od siebie, aby wymusić większy ruch obok półek z innymi produktami w przypadku produktów, dla których zakup jednego zasadniczo determinuje zakup drugiego itp. sprzedaż w czasie - jaką ilość danego produktu zamówić, jeśli ostatnio szczególnie dobrze sprzedają się produkty, które z nim są zwykle kupowane w sekwencjach o określonym interwale czasowym.

63
Analiza koszykowa… w hipermarkecie

64
Analiza koszykowa… w sklepie internetowym

65
Binarne reguły asocjacyjne - podstawowe definicje - wsparcie
Reguła X→Y posiada wsparcie s w bazie danych D, jeżeli s % transakcji w D wspiera zbiór X ∩ Y tidj Tj 1 A,B,C,D 2 A,D 3 A,C 4 B,D,F Wsparcie (A →B) = 25% Wsparcie (A →C) = 50%
 = 25% Wsparcie (A →C) = 50%")
66
Binarne reguły asocjacyjne - podstawowe definicje - ufność
Reguła X → Y posiada ufność c w bazie danych jeżeli c % transakcji w D, które wspierają zbiór X, wspierają również Y ufność (X →Y) = wsparcie (X ∩Y)/wsparcie (X) tidj Tj 1 A,B,C,D 2 A,D 3 A,C 4 B,D,F Ufność (A →B) = 33% Ufność (A →C) = 66% Zachodzącą regułę: A → C : wsparcie 50% , ufność 66% możemy zinterpretować następująco: 66 % osób, które kupiły towar A kupiły również towar C a sytuacja ta zachodzi w 50 % wszystkich transakcji.
 = wsparcie (X ∩Y)/wsparcie (X) tidj. Tj. 1. A,B,C,D. 2. A,D. 3. A,C. 4. B,D,F. Ufność (A →B) = 33% Ufność (A →C) = 66% Zachodzącą regułę: A → C : wsparcie 50% , ufność 66% możemy zinterpretować następująco: 66 % osób, które kupiły towar A kupiły również towar C a sytuacja ta zachodzi w 50 % wszystkich transakcji.")
67
Jak to się dzieje ? Że dzieje się tak…?
Dania mrożone <= warzywa konserwowe & piwo (16533: 16.7% 0.874) Reguła: mówi nam, że: 16533 klientów włożyło jednocześnie do koszyka warzywa konserwowe - piwo stanowi to 16,7 % spośród wszystkich klientów poddanych analizie Jednocześnie 87,4 % kupujących warzywa konserwowe i piwo kupiło także dania mrożone czyli z wysoką ufnością możemy stwierdzić, iż jeśli ktoś kupuje warzywa konserwowe i piwo to kupi też jakieś danie mrożone Warto tym klientom przyjrzeć się bliżej Jeśli podzielimy klientów na dwie grupy, tych którzy kupili i tych którzy nie kupili wiązki produktów dania mrożone - warzywa konserwowe - piwo Taka cecha posłuży do poszukiwania charakterystyk osób, które kupują produkty w danej konfiguracji Stosując algorytm drzewa decyzyjnego uzyskamy reguły…i opis grupy…
 Reguła: mówi nam, że: klientów włożyło jednocześnie do koszyka warzywa konserwowe - piwo. stanowi to 16,7 % spośród wszystkich klientów poddanych analizie. Jednocześnie 87,4 % kupujących warzywa konserwowe i piwo kupiło także dania mrożone. czyli z wysoką ufnością możemy stwierdzić, iż jeśli ktoś kupuje warzywa konserwowe i piwo to kupi też jakieś danie mrożone. Warto tym klientom przyjrzeć się bliżej. Jeśli podzielimy klientów na dwie grupy, tych którzy kupili i tych którzy nie kupili wiązki produktów dania mrożone - warzywa konserwowe - piwo. Taka cecha posłuży do poszukiwania charakterystyk osób, które kupują produkty w danej konfiguracji. Stosując algorytm drzewa decyzyjnego uzyskamy reguły…i opis grupy…")
68
Wyniki analizy… Co będzie dalej ?
Byli to mężczyźni o dochodach gospodarstwa poniżej 1690,-PLN. Spośród zakupów dokonanych przez tych klientów w ok. 84% przypadków w koszykach znalazła interesująca nas wiązka produktów tzn. dania mrożone - warzywa konserwowe - piwo. Tego typu informacje mogą być bardzo istotne zarówno z punktu widzenia planowanych akcji promocyjnych, jak i wzajemnego usytuowania produktów na półkach. Co będzie dalej ? Analiza mikromacierzy DNA… tysiące genów podlega grupowaniu… Analiza logów użytkowników i budowa profili użytkowników – personalizacja stron WWW… Optymalizacja systemów rozpoznawania mowy dzięki grupowaniu wyrazów, zdań…

69
Wnioski… Należy pamiętać, że początek AI to lata 60-te Wielki bum… SE to lata 80-te i 90-te Nie radziłyby sobie one dzisiaj bez DM DM dostarcza wielu użytecznych technik nie tylko analizy wiedzy dla potrzeb statystycznych, ale i dla wydobywania z danych ukrytej, użytecznej wiedzy

70
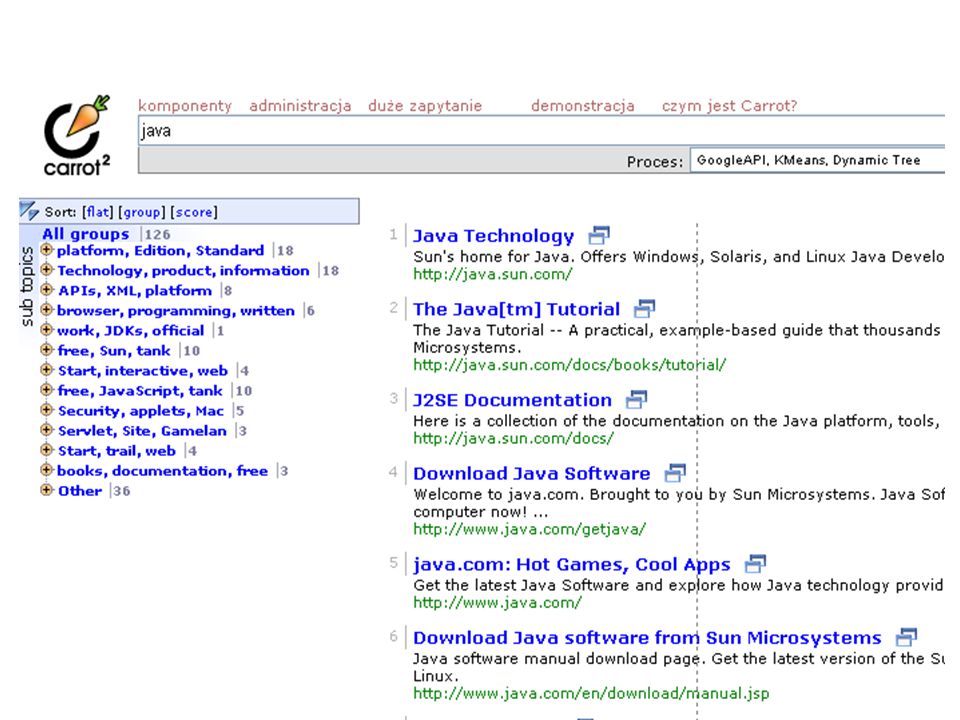
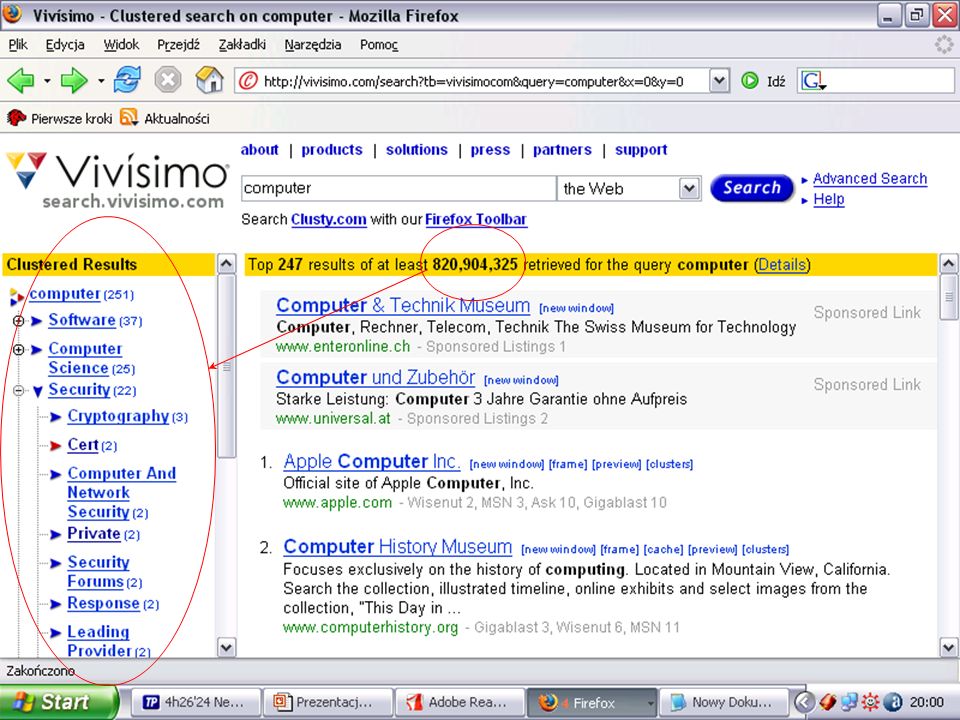
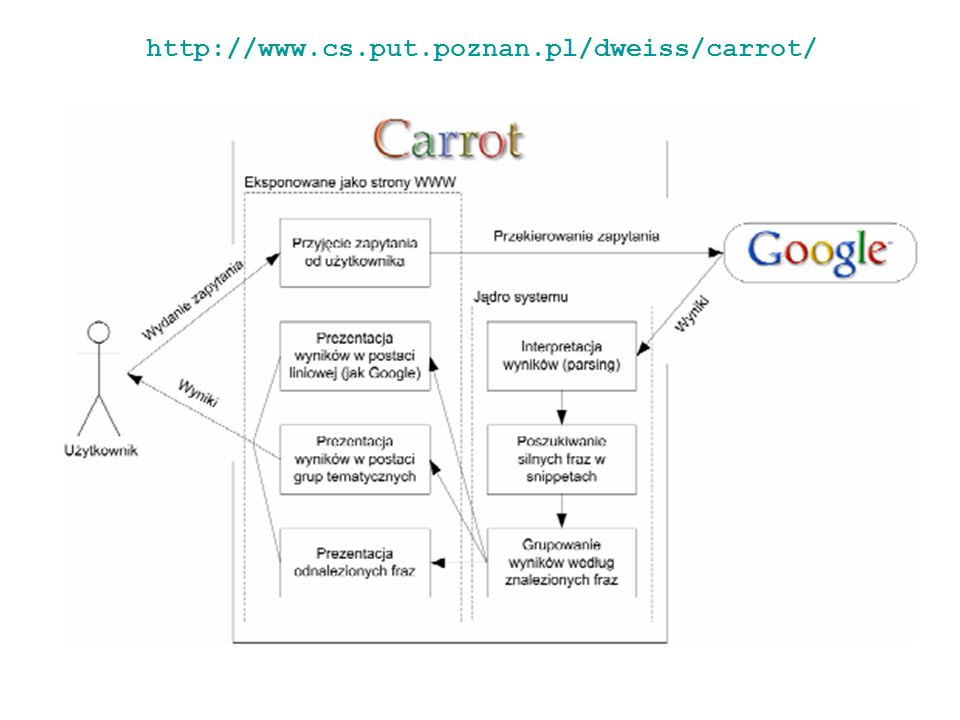
Literatura Carrot2: http://www.cs.put.poznan.pl/dweiss/
Wyszukiwarki: Kłopotek M., „Inteligentne wyszukiwarki internetowe”, EXIT, 2001 Grupowanie: Stąpor K. ,(2005), Automatyczna klasyfikacja obiektów, EXIT, Warszawa Everitt B.S., (1993), Cluster Analysis (3rd edition), London
, Automatyczna klasyfikacja obiektów, EXIT, Warszawa. Everitt B.S., (1993), Cluster Analysis (3rd edition), London.")
71
Dziękuję za uwagę… agnieszka.nowak@us.edu.pl

Podobne prezentacje





















>")

