Pobierz prezentację
1
K ODY ZMIENNEJ DŁUGOŚCI Alfabet Morsa Kody Huffmana

2
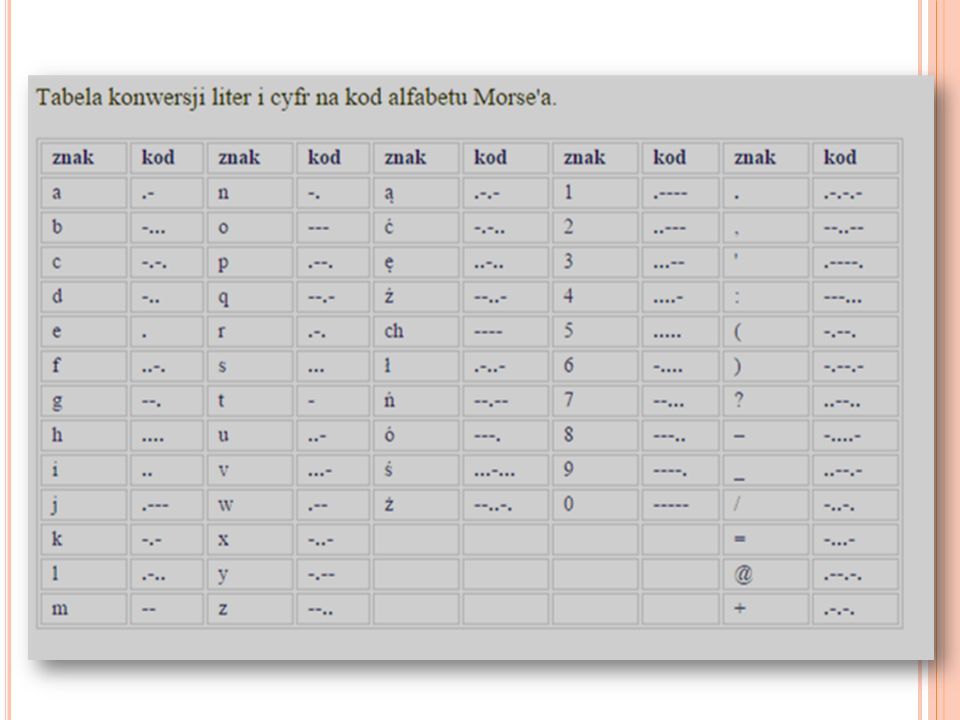
A LFABET M ORSA I KOD HUFFMANA Historia kompresji sięga wielu lat przed erą komputerów. Ideę oszczędnego reprezentowania informacji odnajdujemy w połowie XIX wieku, gdy Samuel Morse (1791-1872) wynalazł telegraf, mechaniczne urządzenie do przesyłania wiadomości i posłużył się przy tym specjalnym alfabetem, znanym jako alfabet Morse’a, który umożliwia kodowanie znaków w tekście za pomocą dwóch symboli – kropki i kreski. Najważniejszą cechą tego alfabetu jest kodowanie najczęściej występujących znaków w tekście za pomocą możliwie najkrótszych kodów, np. kodem litery E jest kropka, a kodem litery T jest kreska, gdyż są to dwie najczęściej występujące litery w tekstach w języku angielskim.
 wynalazł telegraf, mechaniczne urządzenie do przesyłania wiadomości i posłużył się przy tym specjalnym alfabetem, znanym jako alfabet Morse’a, który umożliwia kodowanie znaków w tekście za pomocą dwóch symboli – kropki i kreski. Najważniejszą cechą tego alfabetu jest kodowanie najczęściej występujących znaków w tekście za pomocą możliwie najkrótszych kodów, np. kodem litery E jest kropka, a kodem litery T jest kreska, gdyż są to dwie najczęściej występujące litery w tekstach w języku angielskim..")
3
Ponieważ w telegrafie wysyłanie tekstu polega na przekazaniu kluczem kodów kolejnych znaków z tekstu, alfabet Morse’a znacznie zmniejszał liczbę znaków (kropek i kresek) potrzebnych do wysłania wiadomości. Wadą alfabetu Morse’a jest to, że kody niektórych liter są częścią kodów innych liter, np. każdy kod zaczynający się od kropki zawiera na początku kod litery E. To powoduje, że w tekstach w kodzie Morse’a potrzebny jest dodatkowy znak oddzielający kody kolejnych liter. Tej wady nie ma kod Huffmana, zaproponowany w 1952 roku przez Davida Huffmana w jego pracy magisterskiej. W tym kodzie również często występujące znaki mają krótkie kody, ale żadan kod nie jest początkiem innego kodu.

4
Kodowanie w tym kodzie nie wymaga więc dodatkowego znaku oddzielającego litery. Na przykład słowo abrakadabra ma w kodzie Huffmana postać: 00101011001011001000010101100, czyli zamiast 88 bitów w kodzie ASCII wystarczy 29 bitów w kodzie Huffmana. Algorytm Huffmana jest wykorzystywany w wielu profesjonalnych metodach kompresji tekstu, obrazów i dźwięków, również w połączeniu z innymi metodami. Redukcja wielkości danych przy stosowaniu tego algorytmu wynosi około 50% (w przypadku obrazów i dźwięków kodowane są nie same znaki, ale różnice między kolejnymi znakami).
..")
6
K OD H UFFANA – ZASTOWOWANIE DRZEWA BINARNEGO Np. alfabet składajacy się z 5 liter. A B C D E W pliku, który chcemy zaszyfrować, litery występujż z czestościami: A – 45 B – 5 C – 15 D – 10 E – 25

7
Z liter i ich częstości (wag) tworzymy odrębne drzewa uporzdkowane od najmniejszych do największych częstości. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45

8
Z liter i ich częstości (wag) tworzymy odrębne drzewa uporzdkowane od najmniejszych do największych częstości. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45

9
Bierzemy dwa drzewa o najmniejszych wagach i łączymy je w jedno drzewo. Sumujemy ich wagi. Co więcej, w zależności od tej sumy wstawiamy je w odpowiednie miejsce B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45 15

10
Znowu bierzmy dwa drzewa, łaczymy je i wstawiamy w odpowiednie miejsce. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45 15 30

11
Drzewo wstawione w odpowiednie miejsce. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45 15 30

12
I znowu zabieramy dwa drzewa o najmniejszych wagach. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45 15 30

13
Łączymy je i wstawiamy w odpowiednie miejsce. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45 15 30 55

14
I ponownie zabieramy dwa drzewa o najmniejszych wagach. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45 15 30 55

15
Drzewo Huffmana. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45 15 30 55 100 0 – lewe gałęzie 1 – prawe gałęzie

16
Drzewo Huffmana. B5B5 B5B5 D 10 D 10 C 15 C 15 E 25 E 25 A 45 A 45 15 30 55 100 0 – lewe gałęzie 1 – prawe gałęzie 0 0 0 0 1 1 1 1 A A B B C C D D E Ma kod 0 Ma kod 1100 Ma kod 111 Ma kod 1101 Ma kod 10

17
WNIOSKI Ogólnie: Każdy znak zajmuje 1 bajt, czyli 8 bitów. Jeżeli mamy plik składający się z 100 znaków, to zajmuje on 100 bajtów, czyli 800 bitów. Kod Huffmana: A wystąpiło 45 razy i jest kodowane za pomocą jednego bitu; E wystąpiło 25 razy i jest kodowane za pomoca 2 bitów; C wystąpiło 15 razy i jest kodowane za pomocą 3 bitów; D wystąpiło 10 razy i jest kodowane za pomoca 4 bitów; B wystąpiło 5 razy i jest kodowane za pomocą 4 bitów

18
Mając takie dane otrzymujemy: 45*1+25*2+15*3+10*4+5*4=200 bitów. Nasz plik został skompresowany. Do deszyfrowania tekstu potrzebna jest wiedza na temat drzewa kodowego.

19
Tekst zaczerpnięty: http://informatykaplus.edu.pl/upload/materialy/K siazka_ZBIOR_tom1.pdf











>")









