Pobierz prezentację
1
Podstawy statystyczne Henryk Banaszak Zakład Statystyki, Demografii i Socjologii Matematycznej Henryk Banaszak Zakład Statystyki, Demografii i Socjologii Matematycznej

2
Elementy algebry wektorów i macierzy

3
Skalar = jedna liczba Wektor = uporządkowany ciąg liczb Wektory np. O wymiarach (1 x 3) Wektor wierszowy Wektor kolumnowy np. O wymiarach (4 x 1) np. Wymiar wektora = liczba jego elementów
 Wektor wierszowy Wektor kolumnowy np. O wymiarach (4 x 1) np. Wymiar wektora = liczba jego elementów.")
4
Iloczyn skalarny dwóch wektorów Mnożenie wektora przez skalar k Transpozycja wektora Liniowa kombinacja wektorów Wektor o rozmiarach m x 1 Iloczyn skalarny dwóch wektorów jest liczbą (skalarem)
")
5
Iloczyn skalarny wektora z samym sobą = suma kwadratów eelementów wektora Nierówność Schwartz ‘a Długość wektora, zwana jego normą Suma elementów wektora

6
Wektory względem siebie ortogonalne Wektor jednostkowy Układ (zestaw) wektorów ortogonalnych Układ wektorów orto-normalnych Specjalne wektory Wektor zerowy Wektor o długości 1
 wektorów ortogonalnych Układ wektorów orto-normalnych Specjalne wektory Wektor zerowy Wektor o długości 1")
7
Dane statystyczne w ujęciu macierzowym Zmienne statystyczne i ich momentyWektory i macierze Zmienna statystyczna określona w n ‑ elementowej populacji Ω = { 1, 2,..., n } Wektor o rozmiarze n Macierz danych surowych ze zmiennymi X 1, X 2, …., X k określonymi w n ‑ elementowej populacji Ω = { 1, 2,..., n } Uporządkowany zbiór wektorów o rozmiarze n; macierz o wymiarach n×k Suma wartości zmiennej X Iloczyn skalarny wektora zmiennej oraz wektra jednostkowego Średnia zmiennej X Suma kwadratów zmiennej X Wariancja zmiennej X (X cent oznacza zmienną centrowaną, to znaczy odchylenie X od własnej średniej Kowariancja zmiennych X 1 i X 2 Dane statystyczne w ujęciu macierzowym - 1

8
Zmienne statystyczne i ich momentyWektory i macierze Macierz kowariancji Macierz współczynników korelacji liniowej Macierz kowariancji zmienych liniowo nieskorelowanych Macierz współczynników korelacji zmienych liniowo nieskorelowanych Dane statystyczne w ujęciu macierzowym - 2

9
Dane statystyczne w ujęciu macierzowym x1x1 x2x2 x 1cent x 2cent x 1std x 2std 13,0011,002,751,500,990,65 9,0010,00-1,250,50-0,450,22 9,0010,00-1,250,50-0,450,22 15,008,004,75-1,501,72-0,65 11,0010,000,750,500,270,22 14,0011,003,751,501,350,65 11,006,000,75-3,500,27-1,52 11,00 0,751,500,270,65 6,007,00-4,25-2,50-1,53-1,08 7,006,00-3,25-3,50-1,17-1,52 7,008,00-3,25-1,50-1,17-0,65 8,007,00-2,25-2,50-0,81-1,08 12,0013,001,753,500,631,52 10,0011,00-0,251,50-0,090,65 10,0011,00-0,251,50-0,090,65 5,007,00-5,25-2,50-1,90-1,08 14,00 3,754,501,351,95 13,009,002,75-0,500,99-0,22 10,0012,00-0,252,50-0,091,08 10,008,00-0,25-1,50-0,09-0,65 x' 1 139915111411 67781210 5141310 x' 2 1110 8 116 76871311 7149128 x' 1cent 2,75-1,25 4,750,753,750,75 -4,25-3,25 -2,251,75-0,25 -5,253,752,75-0,25 x' 2cent 1,500,50 -1,500,501,50-3,501,50-2,50-3,50-1,50-2,503,501,50 -2,504,50-0,502,50-1,50 x' 1std 0,99-0,45 1,720,271,350,27 -1,53-1,17 -0,810,63-0,09 -1,901,350,99-0,09 x' 2std 0,650,22 -0,650,220,65-1,520,65-1,08-1,52-0,65-1,081,520,65 -1,081,95-0,221,08-0,65 x 1cent x 2cent x 1cent 145,7566,5 x 2cent 66,5101 1/19 x 1cent x 2cent x 1cent 7,673,50 x 2cent 3,505,32 x 1std x 2std x' 1std 1910,41 x' 2std 10,4119 1/19 x 1std x 2std x' 1std 10,55 x' 2std 0,551 Macierz R współczynników korelacji liniowej między zmiennymi X 1 oraz X 2 składa się z iloczynów skalarnych odpowiadających im wektorów x 1std oraz x 2std pomnożonych przez stałą (1/n-1)
")
10
Macierz X uporządkowany ciąg wektorów Macierz m wektorów o wymiarach (n x 1) macierz X wymiarach (n x m)
 macierz X wymiarach (n x m)")
11
Macierze i operacje na macierzach Suma Przykład iloczynu macierzy A i B Iloczyn Transpozycja

12
Macierz jednostkowa Macierz zerowa Macierz diagonalna („przekątniowa”) Specjalne macierze Iloczyn macierzy diagonalnych
 Specjalne macierze Iloczyn macierzy diagonalnych")
13
Macierz dodatnio (pozytywnie) określona ma wyznacznik dodatni Wyznacznik macierzy jest liczbą Odwrotność macierzy A jest macierzą A -1 Odwrotną do siebie macierz mają tylko macierze dodatnio określone Wyznacznik, odwrotnośc macierzy Własności odwrotności Macierz A bez i-tego wiersza oraz j-tej kolumny
 określona ma wyznacznik dodatni Wyznacznik macierzy jest liczbą Odwrotność macierzy A jest macierzą A -1 Odwrotną do siebie macierz mają tylko macierze dodatnio określone Wyznacznik, odwrotnośc macierzy Własności odwrotności Macierz A bez i-tego wiersza oraz j-tej kolumny")
14
a) tr(k A) = k tr(A) b) tr(A+B) = tr(A) + tr(B) c) tr(AB) = tr (BA) d) tr(A) = rank(A) gdy AA =A (A jet idempotentna) Rząd macierzy to liczba jej liniowo niezależnych wektorów lub kolumn Wektory (x 1, x 2,..., x m ) są liniowo niezależne, gdy ich liniowa kombinacja jest wektorem zerowym: c 1 x 1 + c 2 x 2 +... + c m x m = 0 tylko wtedy, gdy wszystkie jej współczynniki c i są równe zero Ślad macierzy = suma jej elementów diagonalnych Rząd macierzy Jeśli rząd macierzy jest mniejszy niż jej rozmiar, macierz ta ma wyznacznik równy zero Jeśli rząd macierzy jest mniejszy niż jej rozmiar (liczba wierszy, liczba kolumn) jeden z jej wektorów (wiersz, kolumna) jest liniową kombinacją pozostałych wektorów tej macierzy Rząd (rank) i ślad (trace) macierzy Wektory liniowo niezależne Rząd macierzy a jej wyznacznik
 jeden z jej wektorów (wiersz, kolumna) jest liniową kombinacją pozostałych wektorów tej macierzy Rząd (rank) i ślad (trace) macierzy Wektory liniowo niezależne Rząd macierzy a jej wyznacznik.")
15
Zmienna X w n-elementowej zbiorowości Zestaw m zmiennych (X 1, X 2, …, X m ) Macierz kowariancji Macierz korelacji Dane statystyczne w ujęciu macierzowym - 3 Wektor kolumnowy o wymiarach (n x 1) Macierz X o wymiarach (n x m) Pomnożony przez odwrotność liczebności (1/n) iloczyn trasponowanej macierzy X przez nią samą
 Macierz kowariancji Macierz korelacji Dane statystyczne w ujęciu macierzowym - 3 Wektor kolumnowy o wymiarach (n x 1) Macierz X o wymiarach (n x m) Pomnożony przez odwrotność liczebności (1/n) iloczyn trasponowanej macierzy X przez nią samą")
16
Rozwiązywanie układu równań liniowych A x = c Warunki niezbędne istnienia rozwiązania powyższego układu równań Macierz A musi mieć odwrotność A -1 Wyznacznik macierzy A musi być dodatni |A|> 0 Rząd macierzy A musi być równy 3 Macierz A musi mieć odwrotność A -1 Wyznacznik macierzy A musi być dodatni |A|> 0 Rząd macierzy A musi być równy 3 Układ równań

17
eigenvalue lambda and an eigenvector x of the square matrix A ; x 0 and x has length 1 Sum and product of matrix eigenvalues Eigenvalue, eigenvector

18
Wartości własne Macierz wartości własnych równanie charakterystyczne ma tyle rozwiązań, ile wynosi rząd macierzy R Gdy znane są wartości własne R, można wyznaczyć wektory własne u 1 i u 2 z równań postaci: Niestety, istnieje ich wiele, trzeba założyć, że mają długość 1 Macierz wektorów własnych wektor u oraz skalar, dla których zachodzi równość nazwywają się wektorem własnym i wartością własną macierzy R Dla R o wymiarach 2x2 Każda nieosobliwa kwadratowa macierz ma tyle wartości własnych i tyle wektorów własnych, ile wynosi jej rząd

19
Wartości i wektory własne macierzy R corr X1X2 X1 10,48 X2 0,481 1 - λ0,48 1 - λ (1 -λ ) * (1 -λ) - 0,48*0,48 = 0 1 - 2λ + λ 2 - 0,2304 = 0 λ 2 - 2λ + 0,7696 = 0 - 0,48u 11 + 0,48u 12 = 0 0,48 u 11 - 0,48u 12 = 0 0,48u 21 + 0,48u 12 = 0 0,48 u 21 + 0,48u 22 = 0 u 1 =u 11 0,707 u 12 0,707 u 2 =u 21 0,707 u 22 -0,707 1,480 00,52 0,707 -0,707
 * (1 -λ) - 0,48*0,48 = λ + λ 2 - 0,2304 = 0 λ 2 - 2λ + 0,7696 = 0 - 0,48u ,48u 12 = 0 0,48 u ,48u 12 = 0 0,48u ,48u 12 = 0 0,48 u ,48u 22 = 0 u 1 =u 11 0,707 u 12 0,707 u 2 =u 21 0,707 u 22 -0,707 1,480 00,52 0,707 -0,707")
20
Twierdzenie o rozkładzie macierzy ze względu na wektory i wartości własne Każdą odwracalną macierz kwadratową daje się przedstawić jako iloczyn trzech macierzy; takie przedstawienie nazywa się rozkładem ze względu na wektory i wartości własne (SVD) Macierz wartości własnych Macierz wektorów własnych
 Macierz wartości własnych Macierz wektorów własnych")
21
Twierdzenie o rozkładzie macierzy ze względu na wektory i wartości własne Każdą odwracalną macierz kwadratową daje się przedstawić jako sumę macierzy generowanych przez jej wektory i wartości własne

22
Własności wektorów i wartości własnych Wektory własne są względem siebie ortogonalne - ich iloczyny skalarne są równe 0 Wartości własne sumują się do rozmiaru oraz do śladu macierzy Iloczyn wartości własnych kwadratowej macierzy R jest równy wyznacznikowi tej macierzy

23
Rząd macierzy danych X Suma wariancji liniowo niezależnych zmiennych standaryzowanych macierzy danych X Macierz korelacji Dane statystyczne w ujęciu macierzowym - 4 Liczba liniowo niezależnych zmiennych statystycznych Suma wartości własnych macierzy korelacji R Macierzy korelacji R jest sumą macierzy korelacji generowanych przez jej wektory i warości własne

24
Problem głównych składowych (PC) i jego rozwiązanie Singular Value Decomposition SVD
 i jego rozwiązanie Singular Value Decomposition SVD")
25
Problem głównych składowych Case x1x1 x2x2 c1c1 c2c2 1 1311 2 910 3 9 4 158 5 1110 6 1411 7 6 8 9 67 10 76 11 78 12 87 13 1213 14 1011 15 1011 16 57 17 14 18 139 19 1012 20 108 Znaleźć takie dwie liniowe kombinacje wektorów x 1 oraz x 2 które tworzą zmienne C 1 oraz C 2 tak, aby C 1 miała największa możliwie wariancję oraz była nieskorelowana liniowo z C 2 ; U jest macierzą współczynników tych kombinacji

26
Własności rozwiązania problemu głównych składowych Rozwiązanie problemu głównych składowych Macierz współczynników korelacji między zmiennymi daje sie wyrazić jako suma macierzy korelacji „wynikających” z jej poszczególnych głównych składowych Wartość własna to wariancja głównej składowej Kolejne składowe mają coraz mniejszą wariancję Każda składowa „reprezentuje” jaką część sumy wariancji wskaźników Macierz wektorów własnych macierzy R

27
X2X2 X1X1 Przykład * -- dwie zmienne X1 X2 za: Kim, Mueller (1978) str 14 -.
 str 14 -.")
28
R X1X1 X2X2 X1X1 10,48 X2X2 1 Przykład Rozkład SVD macierzy korelacji R dla 2 zmiennych R -λI 1 - λ0,48 1 - λ det |R - λI| = 0 (1 -λ ) * (1 -λ) - 0,48*0,48 = 0 1 - 2λ + λ 2 - 0,2304 = 0 λ 2 - 2λ + 0,7696 = 0 λ2λ2 =0,52 λ1λ1 =1,48 λ1λ1 0 0λ2λ2 0 00,52 λ1Iλ1I(R - λ 1 I)u 1 0 1,480-0,480,48u 11 0 - 0,48u11 + 0,48u12 = 0u 1 =u 11 0,707 01,480,48-0,48u 12 0 0,48 u11 - 0,48u12 = 0u 12 0,707 λ2Iλ2I(R - λ 1 I)u 2 0 0,5200,48 u 21 0 0,48u 21 + 0,48u 12 = 0u 2 =u 21 0,707 00,520,48 u 22 0 0,48 u 21 + 0,48u 22 = 0u 22 -0,707 0,707 -0,707 U u1u1 u2u2 U‘U‘ 0,707 1,48000,707 -0,70700,5200,707-0,707 UU UU'UU' 1,0470,36810,48 1,047-0,3680,481
 * (1 -λ) - 0,48*0,48 = λ + λ 2 - 0,2304 = 0 λ 2 - 2λ + 0,7696 = 0 λ2λ2 =0,52 λ1λ1 =1,48 λ1λ1 0 0λ2λ2 0 00,52 λ1Iλ1I(R - λ 1 I)u 1 0 1,480-0,480,48u ,48u11 + 0,48u12 = 0u 1 =u 11 0,707 01,480,48-0,48u ,48 u11 - 0,48u12 = 0u 12 0,707 λ2Iλ2I(R - λ 1 I)u 2 0 0,5200,48 u ,48u ,48u 12 = 0u 2 =u 21 0,707 00,520,48 u ,48 u ,48u 22 = 0u 22 -0,707 0,707 -0,707 U u1u1 u2u2 U‘U‘ 0,707 1,48000,707 -0,70700,5200,707-0,707 UU UU UU 1,0470,36810,48 1,047-0,3680,481")
29
Przykład: wyznaczenie głównych składowych macierzy korelacji R C1C2 1,9800,000 0,8491,131 -0,849 0,0000,283 0,000-0,283 -1,1310,849 -0,849-1,131 -1,9800,000 0,707 -0,707 h X1X1 X2X2 11,4 2 -0,2 30,21,4 40,2-0,2 5 0,2 6-0,2-1,4 7 0,2 8-1,4 1,9800,000 0,8491,131 -0,849 0,0000,283 0,000-0,283 -1,1310,849 -0,849-1,131 -1,9800,000 1,9800,8491,1310,000 -1,131-0,849-1,980 0,0001,131-0,8490,283-0,2830,849-1,1310,000 C1C1 C2C2 C1C1 11,840 C2C2 04,16 1/8C1C1 C2C2 C1C1 1,480 C2C2 00,52 λ1λ1 0 0λ2λ2 1,480 00,52

30
Rozkład macierzy korelacji R na sumę macierzy Macierzy korelacji między wskaźnikami daje sie wyrazic jako suma macierzy korelacji wynikających z poszczególnych wymiarów czynnikowych X1X1 X2X2 X1X1 10,48 X2X2 1 0,707 -0,707 1,480 00,52 u1u1 1 u1'u1' 0,7071,480,707 0,74 u2u2 2 u2'u2' 0,7070,520,707-0,707 0,26-0,26 0,26 X1X1 X2X2 X1X1 10,48 X2X2 1

31
1 + 2 = n 1,48 +0,52 = 2 + = 74% +26% = 100% Przykład: rozkład sumy wariancji zmiennych między główne składowe λ1λ1 0 0λ2λ2 1,480 00,52

32
nrX1 std X2 std X3 std 1 1,4361,713-1,713 2 0,000 3 -0,479-0,4280,000 4 1,4360,856-1,285 5 0,957-1,713-0,428 6 -0,4790,0000,856 7 0,000 8 -1,4360,4281,285 9 0,4790,000-0,856 10 -0,957-1,2850,428 11 -1,4361,2851,713 12 0,479-0,8560,000 Przykład n=3: SVD + główne składowe 1,0000,056-0,932 0,0561,000-0,100 -0,932-0,1001,000 R 1 - 0,056-0,932 0,056 1 - -0,100 -0,932-0,100 1 - R- I 00 0 0 00 -0,701-0,1060,705 U = -0,1160,9930,034 0,7040,0580,708 -0,701-0,1160,704 -0,1060,9930,058 0,7050,0340,708 U’ = -1,363-0,1050,047 -0,2260,9810,002 1,3690,0570,047 1,0000,056-0,932 1,0000,056-0,932 0,0561,000-0,100 = 0,0561,000-0,100 -0,932-0,1001,001 -0,932-0,1001,000 C1C2C3 -2,4111,449-0,142 0,000 0,385-0,374-0,352 -2,0100,6240,132 -0,774-1,8270,314 0,9380,1000,269 0,000 1,8610,652-0,088 -0,938-0,100-0,269 1,122-1,149-0,416 2,0631,5270,244 -0,236-0,9010,308 C= XU X 1,9450,000 0,9890,000 0,067 C'C (1/n-1) =
 =")
33
Jak to się robi w SPSS * - dwie zmienne X1 X2 za: Kim, Mueller (1978) str 14 -. * - Współczynnik korelacji r X1X2 = 0,48 -. * - Główne składowe będą miały nazwy: PCA1 oraz PCA2 FAC /VAR X1 X2/CRI FAC(2)/EXT PC/SAVE (ALL, PCA). LIST PCA1 PCA2. * - sprawdzamy średnie i wariancje głównych składowych PCA1 PCA2 DES PCA1 PCA2/ STA SUM MEA VAR. * - sprawdzamy czy główne składowe PCA1 oraz PCA2 są względem siebie ortogonalne -. COR PCA1 PCA2. * - sprawdzamy jakimi funkcjami głównych składowych są X1, X2 -. REG /DEP X1/ENT PCA1 PCA2. Uwaga: SPSS standaryzuje główne składowe nieobciążonym estymatorem wariancji (n-1)
/EXT PC/SAVE (ALL, PCA). LIST PCA1 PCA2. * - sprawdzamy średnie i wariancje głównych składowych PCA1 PCA2 DES PCA1 PCA2/ STA SUM MEA VAR. * - sprawdzamy czy główne składowe PCA1 oraz PCA2 są względem siebie ortogonalne -. COR PCA1 PCA2. * - sprawdzamy jakimi funkcjami głównych składowych są X1, X2 -. REG /DEP X1/ENT PCA1 PCA2. Uwaga: SPSS standaryzuje główne składowe nieobciążonym estymatorem wariancji (n-1).")
34
Jak to się robi w SPSS PC 1 PC 2 1,9800,000 0,8491,131 -0,849 0,0000,283 0,000-0,283 -1,1310,849 -0,849-1,131 -1,9800,000 PC 1 PC 2 PC 1 11,840 PC 2 04,16 PC 1 PC 2 PC 1 1,480,00 PC 2 0,000,52 PCA 1 PCA 2 PCA 1 7,0000,000 PCA 2 0,0007,000 PCA 1 PCA 2 PCA11,0000,000 PCA20,0001,000 SVD SPSS Regresja wskaźników X 1, X 2 na składowe PC 1, PC 2 Regresja wskaźników X 1, X 2 na składowe PCA 1, PCA 2 Macierz kowariancji

35
Wektory Geometrycznie

36
Geometryczna interpretacja macierzy korelacji Wektory rozpatrujemy zawsze w jakiejś przestrzeni. Jeśli w przestrzeni, w której rozpatrywany jest wektor określimy kartezjański układ współrzędnych prostokątnych, to położenie wektora w przestrzeni będzie wyznaczone poprzez współrzędne dwóch punktów: początku i końca wektora Na powyższym (płaskim) rysunku, współrzędne początku wektora dane są uporządkowaną parą liczb (2,1); współrzędne końca wektora uporządkowaną parą liczb (5,2) zaś uporządkowana para punktów ((2,1), (5,2)) określa położenie wyrysowanego wyżej wektora na płaszczyźnie, czyli w przestrzeni dwuwymiarowej 0123456 1 2 3 Y X 0123456 1 2 3 4 Jeśli wiadomo, że początek wektora pokrywa się z początkiem układu współrzędnych, to położenie rozpatrywanego wektora będzie wyznaczone uporządkowaną parą liczb ( y,x ), określającą położenie jego punktu końcowego y x
 rysunku, współrzędne początku wektora dane są uporządkowaną parą liczb (2,1); współrzędne końca wektora uporządkowaną parą liczb (5,2) zaś uporządkowana para punktów ((2,1), (5,2)) określa położenie wyrysowanego wyżej wektora na płaszczyźnie, czyli w przestrzeni dwuwymiarowej Y X Jeśli wiadomo, że początek wektora pokrywa się z początkiem układu współrzędnych, to położenie rozpatrywanego wektora będzie wyznaczone uporządkowaną parą liczb ( y,x ), określającą położenie jego punktu końcowego y x.")
37
Długość wektora, iloczyn skalarny dwóch wektorów 0 Twierdzenie Pitagorasa Iloczynem (skalarnym) dwóch wektorów, t 1 i t 2, o początkach leżących w tym samym punkcie, nazywa się liczbę będącą iloczynem trzech liczb: długości wektora t 1, długości wektora t 2, cosinusa kąta 12 między wektorami t 1 i t 2 Iloczynem (skalarnym) dwóch wektorów, t 1 i t 2, o początkach leżących w tym samym punkcie, nazywa się liczbę będącą iloczynem trzech liczb: długości wektora t 1, długości wektora t 2, cosinusa kąta 12 między wektorami t 1 i t 2 W układzie o k współrzędnych x = (x 1, x 2, …, x k ) długość wektora jest pierwiastkiem sumy kwadratów jego współrzędnych
 dwóch wektorów, t 1 i t 2, o początkach leżących w tym samym punkcie, nazywa się liczbę będącą iloczynem trzech liczb: długości wektora t 1, długości wektora t 2, cosinusa kąta 12 między wektorami t 1 i t 2 Iloczynem (skalarnym) dwóch wektorów, t 1 i t 2, o początkach leżących w tym samym punkcie, nazywa się liczbę będącą iloczynem trzech liczb: długości wektora t 1, długości wektora t 2, cosinusa kąta 12 między wektorami t 1 i t 2 W układzie o k współrzędnych x = (x 1, x 2, …, x k ) długość wektora jest pierwiastkiem sumy kwadratów jego współrzędnych")
38
0 Długość wektora w czynnikowym układzie odniesienia F1F1 F2F2 b 11 b 21 b 12 b 22 x1x1 x2x2 Wariancja zmiennej wyrażona z układu czynnikowego to suma kwadratów ładunków czynnikowych zmiennej względem wszystkich czynników

39
0 Y X Iloczyn skalarny dwóch wektorów - geometrycznie Iloczyn skalarnym dwóch wektorów, t 1 i t 2 o początkach leżących w tym samym punkcie, jest równy sumie iloczynów ich współrzędnych

40
0 Iloczyn skalarny dwóch wektorów – to współczynnik korelacji między nimi F1F1 F2F2 b 11 b 21 b 12 b 22 x1x1 x2x2 Współczynnik korelacji między zmiennymi X 1 i X 2 to suma iloczynów ich ładunków czynnikowych względem ortogonalnych czynników F 1 i F 2 F 1 i F 2 tworzą układ współrzędnych dla X 1 i X 2 traktowanych jako wektory

41
Iloczyn skalarny dwóch wektorów - podsumowanie Wpółczynnik korelacji liniowej zmiennych X 1, X 2 Iloczyn skalarny wektorów-zmiennych to suma iloczynów ich współrzędnych To iloraz kowariancji oraz odchyleń standardowych zmiennych X 1, X 2 Pierwiastek iloczynu skalarnego dwóch wektorów to długość wektora Zmienne standaryzowane mają długość 1

42
Główne składowe a wskaźniki

43
Jeśli rozwiążemy problem PCA, wyznaczymy C 1 i C 2, wskaźniki X 1 i X 2 możemy wyrazić jako liniową kombinację głównych składowych Parametry liniowej kombinacji głównych składowych, które tworzą zmienne obserwowalne otrzymujemy dzięki SVD Jeśli wyznaczyliśmy główne składowe, możemy z nich wrócić do wskaźników

44
Problem czynnikowy

45
Model czynnikowy X wskaźniki (n) F Wspólne czxynniki (k < n) U Swoiste czynniki (n) B Macierz ładunków czynnikowych (n,k) Założenia modelu (1) (2) (3a)Czynniki wspólne wzlędem siebie ortogonalne; C(F i, F j ) = 0 (3b) Czynniki wspólne skorelowane ze sobą; C(F i, F j ) ≠ 0 Czynniki swoiste są nieskorelowane ze soba i z czynnikami wspólnymi Każdy wskaźnik X i jest liniową funkcją wspólnych czynników F 1, F 2,..., F k oraz czynnika swoistego U i Czynniki wspólne mogą być skorelowane ze sobą
 F Wspólne czxynniki (k < n) U Swoiste czynniki (n) B Macierz ładunków czynnikowych (n,k) Założenia modelu (1) (2) (3a)Czynniki wspólne wzlędem siebie ortogonalne; C(F i, F j ) = 0 (3b) Czynniki wspólne skorelowane ze sobą; C(F i, F j ) ≠ 0 Czynniki swoiste są nieskorelowane ze soba i z czynnikami wspólnymi Każdy wskaźnik X i jest liniową funkcją wspólnych czynników F 1, F 2,..., F k oraz czynnika swoistego U i Czynniki wspólne mogą być skorelowane ze sobą")
46
Factor model Decomposition theorem Solution: factor loading matrix Correlations between indicators implied by the solution Finding factor model parameters

47
Factor equation Where: Ψ – diagonal matrix with di 2 on main diagonal Σ – symmetric matrix with r ij out- diagonal and h i 2 on the diagonal Decomposition of R between Σ and Ψ is not unique X =

48
Single latent common factor F and two manifest indicators X 1, X 2 X1X1 X2X2 F b1b1 b2b2 U1U1 U2U2 Model assunptions 1.Unique variables U 1 and U 2 are linearly independent and independent on common latent factor F: Consequences: 1.Common (explained) variance of an indicator X i with common factor F equals the square of a factor loading b i : d1d1 d2d2 2.Correlation coefficient between indicators X i and X j is a product of their loadings with common factor F:
 variance of an indicator X i with common factor F equals the square of a factor loading b i : d1d1 d2d2 2.Correlation coefficient between indicators X i and X j is a product of their loadings with common factor F:")
49
X1X1 X2X2 F 0,8 0,6 U1U1 U2U2 d1d1 d2d2 F X1X1 0,8 X2X2 0,6 Factor matrix Solution 1 Solution 2Solution 3 F X1X1 0,50 X2X2 0,96 F X1X1 0,60 X2X2 0,80 F X1X1 0,70 X2X2 0,69 F X1X1 0,90 X2X2 0,53 Solution 4 0,50*0,96=0,480,60*0,80=0,480,70*0,69=0,48 0,90*0,53=0,48 Single factor F and two manifest indicators X 1, X 2

50
Two independent factors F 1, F 2, two indicators X 1, X 2 X1X1 X2X2 F1F1 b 11 b 21 U1U1 U2U2 d1d1 d2d2 X1X1 X2X2 F2F2 b 12 b 22 Assumptions 1.Unique factors U 1 and U 2 are linearly independent and independent on common factors F 1 and F 2 : 2.Common factors are linearly independent: Consequences : 1.Common (explained) variance of an indicator with a common factor is the sum of factor loadings squares, with both common factors F 1 and F 2 : 2.Correlation coefficient between indicators is the sum of factor loadings products Orthogonality of factors
 variance of an indicator with a common factor is the sum of factor loadings squares, with both common factors F 1 and F 2 : 2.Correlation coefficient between indicators is the sum of factor loadings products Orthogonality of factors")
51
F1F1 F2F2 X1X1 X2X2 X3X3 0,80 0,70 0,80 X4X4 0,60 X5X5 F1F2 h21h21 h22h22 hi2hi2 X1 0,80 0,640 X2 0,70 0,490 X3 0,6 0,36 0,72 X4 00,8 00,64 X5 00,6 00,36 suma 1,491,362,85 suma/5 29,8%27,2%57,0% X1X2X3X4X5 X1 1 X2 0,561 X3 0,480,421 X4 000,481 X5 000,360,481 Two orthogonal factors – five indicators

52
Perfect reproduction of correlations between indicators can be derived from different factor models F1F1 F2F2 F1F2 X1,607-,521 X2,532-,456 X3,846,065 X4,521,607 X5,390,456 F1F2 X1,800,000 X2,700,000 X3,600 X4,000,800 X5,000,600 Model 1 Model 2 X1 X2 X3 X4 X5 F1’F1’ F2’F2’

53
F1F1 F2F2 X1X1 X2X2 X3X3 0,40 0,80 0,70 X4X4 X6X6 0,60 X5X5 0,50 Oblique factor model algebraically r F1F2 =0,40 F1F2h21h21 h22h22 hi2hi2 X1 0,800,640,64 X20,700,490,49 X30,600,360,36 X400,700,49,49 X500,600,36,36 X600,500,25,25 suma1,491,102,59 % 25%18%43% X1X2X3X4X5X6 X11 X20,5601 X30,4800,4201 X40,2240,1960,1681 X50,1920,1680,1440,4201 X60,1600,1400,1200,3500,3001

54
Oblique factor model geometrically F1F2 X1,766-,232 X2,670-,203 X3,574-,174 X4,454,533 X5,389,457 X6,324,381 X1 F1 F2 X3 X2 X4 X5 X6 F1F2 X1,783,163 X2,685,143 X3,587,123 X4,143,685 X5,123,587 X6,102,489 F1F2 X1,800,000 X2,700,000 X3,600,000 X4,000,700 X5,000,600 X6,000,500 66 Orthogonal factors initialrotated Oblique factors Factor loadings are coordinates on the factor axes F1 F2

55
How to find factor solution How to evaluate its quality Which indicators are useless What variables can be used as an indicators of latent factor Permanent Problems of FACTOR ANALYSIS as a scaling tool What to do if my indicators are binary or ordinary

56
Factor model in matrix notation X indicators (n) F common factors (k < n) U unique factors (n) B Factor loadings matrix (n,k) Common assumptions (1) (2) Orthogonal factors (3) Common factors are mutually linearly independent; C(F i, F j ) = 0 (3)Common factors are linearly dependent; C(F i, F j ) ≠ 0 Oblique factors Unique factors are mutually independent Unique and common factors are independent Factor model assumptions
 F common factors (k < n) U unique factors (n) B Factor loadings matrix (n,k) Common assumptions (1) (2) Orthogonal factors (3) Common factors are mutually linearly independent; C(F i, F j ) = 0 (3)Common factors are linearly dependent; C(F i, F j ) ≠ 0 Oblique factors Unique factors are mutually independent Unique and common factors are independent Factor model assumptions")
57
Factor equation Where: Ψ – diagonal matrix with ui 2 on main diagonal Σ – symmetric matrix with r ij out- diagonal and h i 2 on the diagonal Decomposition of R between Σ and Ψ is not unique X =

58
Factor model Decomposition theorem; V – eigenvector matrix, – eigenvalue matrix Solution: factor loading matrix Correlations between indicators implied by the solution Finding factor model parameters

59
Obliczalność kowariancji między elementami modelu ścieżkowego

60
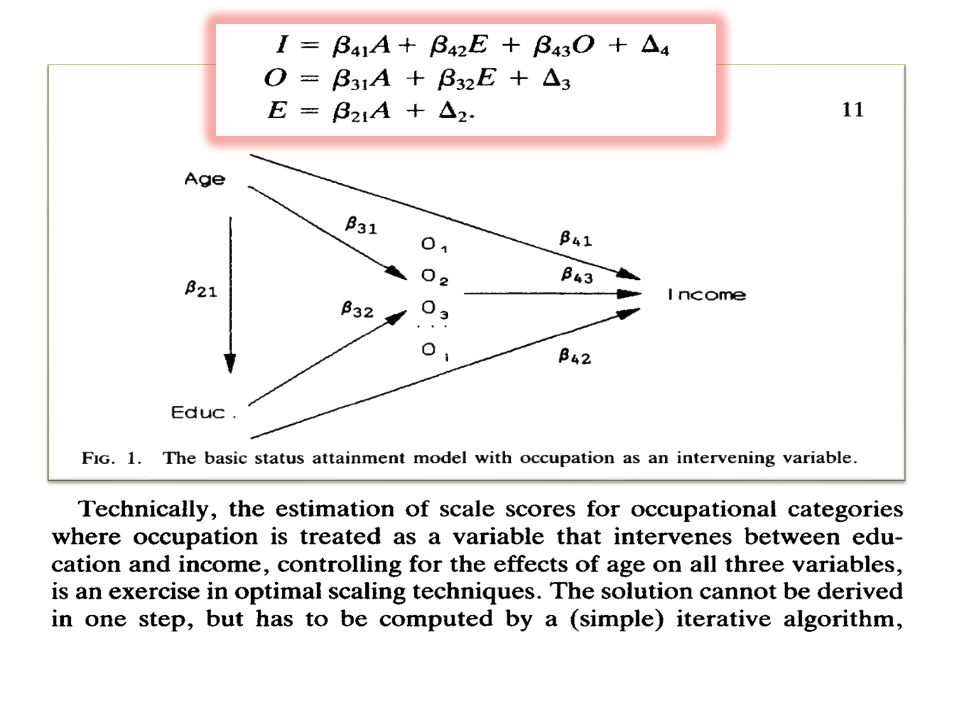
Model ścieżkowy = układ równań regresji wielokrotnej Rekursywne modele ścieżkowe wszystkie zależności są jednokierunkowe wszystkie błędy sa liniowo nieskorelowane parami błędy są nieskorelowane liniowo z wszystkimi zmiennymi niezależnymi równania, w którym występują parametry każdego rekursywnego modelu ścieżkowego dają się wyznaczyć X1X1 X2X2 X3X3 31.2 21 32.1 e2e2 E3E3 E2E2 e3e3 E4E4 42.13 41.23 43.12 e4e4 X4X4

61
X1X1 X2X2 X3X3 31.2 21 32.1 e2e2 E3E3 E2E2 e3e3

62
X1X1 X2X2 X3X3 0,29 0,64 0,29 e2e2 E3E3 E2E2 e3e3

63
F X1X1 X2X2 X3X3 0,80 0,60 0,80

64
Strukturalne modele skalowania liniowego Zadowolenie z okolicy miejsca zamieszkania Potencjał partycypacyjny SEI Pozycja społeczna ACSI - MJR

67
Idea pomiaru strukturalnego: skalowanie poziomu zadowolenia z miejsca zamieszkania Cecha ukryta: poziom zadowolenia Z Cecha ukryta: poziom zadowolenia Z X1X1 X2X2 X3X3 X4X4 Jak bardzo zadowolony(a) jest Pan(i) Y Wskaźniki typu „skutki”Wskaźniki typu „źródła” ze swoich sąsiadów z poziomu czystości z zaopatrzenia sklepów z placówek kulturalnych z poziomu bezpieczeństwa X5X5 Biorąc to wszystko pod uwagę, proszę powiedzieć, jak Panu(i) się żyje w Pana(i) okolicy? Wyznacz takie wartości Z, które najlepiej przewidują odpowiedź Y

68
Dlaczego nie uczestniczę? Dlaczego uczestniczę bronię dóbr indywidualnych bronię dobra wspólnego tworzę dobro wspólne bariery Bariery – katalizatory partycypacji

69
Potencjał partycypacyjny: schemat pomiarowy Katalizatory potencjał Zachowania partycypacyjne Zachowania partycypacyjne Świadomość prawna Umiejętności komunikacyjne Standardy etyczne Kapitały: społeczne kulturowe ekonomiczne Świadomość prawna Umiejętności komunikacyjne Standardy etyczne Kapitały: społeczne kulturowe ekonomiczne partycypacyjny Bariery

70
Stratyfikacja klasowa

71
KK Kapitał kulturowy E1E2...EkE1E2...Ek KE Kapitał ekonomiczny K1K2...KmK1K2...Km XE 1 XE 2.. XE k XK 1 XK 2.. XK m Segmentacja kapitałowa in out

73
ACSI Amerykański Indeks Satysfakcji Klienta (ACSI) Przedstawiony jesienią 1994 roku przez Claesa Fornella Pierwowzór: Szwedzki Barometr Satysfakcji Klienta z 1989 roku Wskaźnik długookresowej wydajności ekonomicznej państwa oraz sektora prywatnego Pomiar wydajności oparty na subiektywnej ewaluacji jakości dóbr i usług nabywanych w USA, dokonywanej przez konsumentów Odzwierciedla satysfakcję z dóbr i usług dostępnych na rynku krajowym Pozwala oszacować przyszłe zyski przedsiębiorstwa, promować jakość i zwiększać konkurencyjność firm ACSI obejmuje 100 instytucji federalnych dostarczających 200 usług publicznych
 Przedstawiony jesienią 1994 roku przez Claesa Fornella Pierwowzór: Szwedzki Barometr Satysfakcji Klienta z 1989 roku Wskaźnik długookresowej wydajności ekonomicznej państwa oraz sektora prywatnego Pomiar wydajności oparty na subiektywnej ewaluacji jakości dóbr i usług nabywanych w USA, dokonywanej przez konsumentów Odzwierciedla satysfakcję z dóbr i usług dostępnych na rynku krajowym Pozwala oszacować przyszłe zyski przedsiębiorstwa, promować jakość i zwiększać konkurencyjność firm ACSI obejmuje 100 instytucji federalnych dostarczających 200 usług publicznych")
74
Geneza MJR Monitor Jakości Rządzenia (MJR) Rynek: konsument – produkt – jakość/wartość Państwo: obywatel – usługa publiczna – jakość Rynek: konsument – produkt – jakość/wartość Państwo: obywatel – usługa publiczna – jakość Adaptacja amerykańskiego schematu pomiarowego do warunków polskich Wykorzystuje doświadczenia z badań rynku i usług federalnych w USA Państwo traktowane jako dostarczyciel usług publicznych
 Rynek: konsument – produkt – jakość/wartość Państwo: obywatel – usługa publiczna – jakość Rynek: konsument – produkt – jakość/wartość Państwo: obywatel – usługa publiczna – jakość Adaptacja amerykańskiego schematu pomiarowego do warunków polskich Wykorzystuje doświadczenia z badań rynku i usług federalnych w USA Państwo traktowane jako dostarczyciel usług publicznych")
75
Założenia modelu teoretycznego generalizacjaKonsekwencje oczekiwania wobec danej usługi publicznej doświadczenie w korzystaniu z usługi zachowania i deklaracje dotyczące przyszłości: - skargi na jakość - zaufanie - rekomendacje poziom satysfakcji

76
Od czego zależy satysfakcja? Co zależy od satysfakcji? poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości oczekiwania i doświadczenia konsekwencje oczekiwań i doświadczeń odczuwana jakość usługi

77
poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości Q1 ogólne oczekiwania Q6 ogólna satysfakcja Q11 polecanie usługi innym Q7 spełnianie oczekiwań Q8 porównanie z ideałem Q5 ogólna ocena jakości Q2 ocena jakości wymiaru 1 Q3 ocena jakości wymiaru 2 Q4 ocena jakości wymiaru 3 Q9 czy złożył skargę Q10A/B reakcja na skargę Q12 wiara w stabilność poziomu jakości odczuwana jakość usługi

78
Usługi objęte badaniem Komunikacja publiczna Urząd Gminy Urząd Skarbowy ZUS / KRUS Urząd Pocztowy Policja Biblioteka Publiczna Dom lub Ośrodek Kultury Usługi medyczne (5 rodzajów usług) Szkoła podstawowa / gimnazjum w podziale na prywatną i publiczną służbę zdrowia
 Szkoła podstawowa / gimnazjum w podziale na prywatną i publiczną służbę zdrowia")
79
Wymiary jakości usług (1) Wymiary jakości badanych usług publicznych Częstotliwość kursowania środków transportu Punktualność kursowania środków transportu Wygląd i czystość środków transportu Sprawność załatwienia sprawy Łatwość uzyskania informacji na temat sposobu załatwienia sprawy, opłat, potrzebnych dokumentów Kompetencje urzędników załatwiających sprawę Komunikacja publiczna Urząd Gminy Urząd Skarbowy ZUS / KRUS Szybkość dostarczania przesyłek Dogodność terminów dostarczania przesyłek poleconych Szybkość załatwiania spraw i kolejek Urząd Pocztowy
 Wymiary jakości badanych usług publicznych Częstotliwość kursowania środków transportu Punktualność kursowania środków transportu Wygląd i czystość środków transportu Sprawność załatwienia sprawy Łatwość uzyskania informacji na temat sposobu załatwienia sprawy, opłat, potrzebnych dokumentów Kompetencje urzędników załatwiających sprawę Komunikacja publiczna Urząd Gminy Urząd Skarbowy ZUS / KRUS Szybkość dostarczania przesyłek Dogodność terminów dostarczania przesyłek poleconych Szybkość załatwiania spraw i kolejek Urząd Pocztowy")
80
Wymiary jakości usług (2) Wymiary jakości badanych usług publicznych Szybkość reakcji Skuteczność interwencji Sposób potraktowania przez policjantów Pomocność pracowników biblioteki Dostępność informacji o zbiorach bibliotecznych Dostępność książek i materiałów multimedialnych Policja Oferta organizowanych zajęć i imprez Jakość organizowanych zajęć i imprez Poziom wyposażenia, jakość pomieszczeń, jakość sprzętu technicznego Dom lub Ośrodek Kultury Biblioteka Publiczna
 Wymiary jakości badanych usług publicznych Szybkość reakcji Skuteczność interwencji Sposób potraktowania przez policjantów Pomocność pracowników biblioteki Dostępność informacji o zbiorach bibliotecznych Dostępność książek i materiałów multimedialnych Policja Oferta organizowanych zajęć i imprez Jakość organizowanych zajęć i imprez Poziom wyposażenia, jakość pomieszczeń, jakość sprzętu technicznego Dom lub Ośrodek Kultury Biblioteka Publiczna")
81
Wymiary jakości usług (3) Wymiary jakości badanych usług publicznych Możliwość umówienia się na wizytę w odpowiadającym terminie Posiadane kompetencje lekarza, personelu Życzliwość wobec pacjenta Usługi medyczne (5 rodzajów usług) Poziom bezpieczeństwa dziecka w szkole Poziom nauczania w szkole Relacje rodzica z wychowawcą Szkoła podstawowa / gimnazjum
 Wymiary jakości badanych usług publicznych Możliwość umówienia się na wizytę w odpowiadającym terminie Posiadane kompetencje lekarza, personelu Życzliwość wobec pacjenta Usługi medyczne (5 rodzajów usług) Poziom bezpieczeństwa dziecka w szkole Poziom nauczania w szkole Relacje rodzica z wychowawcą Szkoła podstawowa / gimnazjum")
82
Przykładowe pytanie z kwestionariusza dla Urzędu Skarbowego Przykładowe pytanie z kwestionariusza dla Urzędu Skarbowego Przykładowe pytanie

83
Struktura MJR poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości odczuwana jakość usługi poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości odczuwana jakość usługi poziom wymagań względem usługi wskaźniki jakości poziom satysfakcji z usługi skargi na jakość usługi i sposób ich załatwiania zaufanie do jakości usługi w przyszłości odczuwana jakość usługi usługa 1. usługa 2. usługa k. I1I1 I2I2 IkIk............ I 1 0-100 I 2 0-100 I k 0-100 średnia...... MJR 1 MJR 2 MJR k...... MJR(o) u1u1 u2u2 ukuk wagi proporcjonalne do liczby osób, które korzystały z usługi w ciągu ostatniego roku modele SEM-PLSsatysfakcja obywateli unormowana satysfakcja obywateli (skala 0-100) indeks MJR dla usługi
 u1u1 u2u2 ukuk wagi proporcjonalne do liczby osób, które korzystały z usługi w ciągu ostatniego roku modele SEM-PLSsatysfakcja obywateli unormowana satysfakcja obywateli (skala 0-100) indeks MJR dla usługi.")
84
Sposób wyznaczania indeksu satysfakcji (1) Satysfakcja z usługi pojedynczego obywatela I k (x) poziom satysfakcji z usługi k dla respondenta x w ki współczynniki dla wskaźników Q i uzyskane w wyniku estymacji modelu strukturalnego dla usługi k Q ki (x) odpowiedź respondenta x na pytanie wskaźnikowe Q i dotyczące usługi k Pytania wskaźnikowe opierają się na skali od 1 do 9
 Satysfakcja z usługi pojedynczego obywatela I k (x) poziom satysfakcji z usługi k dla respondenta x w ki współczynniki dla wskaźników Q i uzyskane w wyniku estymacji modelu strukturalnego dla usługi k Q ki (x) odpowiedź respondenta x na pytanie wskaźnikowe Q i dotyczące usługi k Pytania wskaźnikowe opierają się na skali od 1 do 9")
85
Sposób wyznaczania indeksu satysfakcji (2) Satysfakcja z usługi pojedynczego obywatela na skali 0-100 I k 0-100 (x) poziom satysfakcji z usługi k dla respondenta x na skali 0-100 w ki współczynniki dla wskaźników Q i uzyskane w wyniku estymacji modelu strukturalnego dla usługi k Q ki (x) odpowiedź respondenta x na pytanie wskaźnikowe Q i dotyczące usługi k Zmienna I k 0-100 jest wyrażona na skali od 0 do 100
 Satysfakcja z usługi pojedynczego obywatela na skali I k (x) poziom satysfakcji z usługi k dla respondenta x na skali w ki współczynniki dla wskaźników Q i uzyskane w wyniku estymacji modelu strukturalnego dla usługi k Q ki (x) odpowiedź respondenta x na pytanie wskaźnikowe Q i dotyczące usługi k Zmienna I k jest wyrażona na skali od 0 do 100")
86
Sposób wyznaczania indeksu satysfakcji (3) Ogólna forma indeksu satysfakcji (MJR) MJR jest wyrażony na skali od 0 do 100 Indeks satysfakcji obywateli wyliczany jest jako średnia satysfakcja (wyrażona na skali 0-100) zbadanych osób z danej usługi Taka średnia może zostać policzona zarówno dla całej Polski, jak i np. dla poszczególnych województw (bierzemy wtedy pod uwagę tylko mieszkańców danego województwa)
.")
87
Sposób wyznaczania indeksu satysfakcji (4) Indeks jakości rządzenia na danym obszarze MJR k (o) indeks satysfakcji z usługi k na obszarze o (w województwie lub w całej Polsce) u k waga proporcjonalna do częstości korzystania obywateli z usługi k (wagi unormowano tak, aby MJR(o) było wyrażane na skali 0-100) MJR jest wyrażony na skali od 0 do 100
 Indeks jakości rządzenia na danym obszarze MJR k (o) indeks satysfakcji z usługi k na obszarze o (w województwie lub w całej Polsce) u k waga proporcjonalna do częstości korzystania obywateli z usługi k (wagi unormowano tak, aby MJR(o) było wyrażane na skali 0-100) MJR jest wyrażony na skali od 0 do 100")
88
Zalety MJR Zalety metodologiczne Sprawdzona metodologia Standaryzowany sposób oceny satysfakcji Możliwość agregacji i porównań uzyskanych ocen Możliwość śledzenia zmian w uzyskanych ocenach w czasie Zalety praktyczne Zobiektywizowana ocena jakości działania służb publicznych Opis jakości usług na poziomie ogólnokrajowym i lokalnym Pozyskanie informacji na temat oczekiwań obywateli wobec instytucji publicznych Możliwość wdrożenia okresowej kontroli jakości działania służb publicznych Zalety podejścia

89
Jakość usług publicznych w Polsce Polska 70 pkt Prywatna służba zdrowia 81 pkt

90
Jakość usług publicznych w woj. lubelskim Województwo lubelskie 74 pkt Prywatna służba zdrowia 85 pkt

91
Jakość usług publicznych w woj. śląskim Województwo śląskie 67 pkt Prywatna służba zdrowia 82 pkt

92
Indeksy satysfakcji z usług publicznych w przekroju terytorialnym

93
Biłgoraj na tle pozostałych gmin wiejskich

94
Gołdap na tle pozostałych miast do 20 tys. mieszkańców

95
Słupsk na tle pozostałych miast od 20 tys. do 100 tys. mieszkańców

96
Poznań na tle pozostałych miast pow. 100 tys. mieszkańców

97
Porównanie wyników ACSI versus MJR (1) Polska: 70 pkt
 Polska: 70 pkt")
98
Porównanie wyników ACSI versus MJR (2) Poczta 64 Prywatna służba zdrowia 81 Publiczna służba zdrowia 75 Koszyk 10 usług 70 Polska 2010USA 2010
 Poczta 64 Prywatna służba zdrowia 81 Publiczna służba zdrowia 75 Koszyk 10 usług 70 Polska 2010USA 2010")
99
PLS rekonstrukcja metody Tomasz Żółtak

100
– Podstawy podejścia opracowane na przełomie lat 60. i 70. XX w. przez Hermana Wolda. Uczniem Wolda był Jöreskog, twórca modeli SEM-ML. – W odróżnieniu od modeli SEM-ML metoda PLS z założenia miała być mało wymagająca względem danych: Nie odwoływać się do założeń o rozkładach zmiennych. Umożliwiać estymację nawet przy małej liczbie jednostek obserwacji. – W latach 80. w pracach Wolda i Lohmöllera przedstawiono dowody, że przy pomocy pewnych wariantów modeli PLS można estymować: Korelacje kanoniczne (w tym dwa uogólnienia korelacji kanonicznej na wiele grup zmiennych zaproponowane przez Horsta i Carolla). Regresję PLS. Inter-battery factor analysis. Redundancy analysis. Statystyczna geneza PLS
. Regresję PLS. Inter-battery factor analysis. Redundancy analysis. Statystyczna geneza PLS.")
101
– W odróżnieniu od modeli SEM-ML algorytm estymacji PLS w ogólności nie dąży do maksymalizacji żadnej globalnej funkcji dopasowania modelu do danych. Choć dla szczególnych modeli (por. poprzedni slajd) można wskazać, że efektem działania algorytmu jest optymalizacja pewnego kryterium. Estymacja modelu strukturalnego metodą PLS w ogólności daje się opisać tylko jako realizacja rozsądnego algorytmu działania. Nie można jednak (w ogólności) syntetycznie powiedzieć, do czego ten algorytm dąży. – Modele PLS są nakierowane na przewidywanie i eksplorację (możliwość uwzględnienia bardzo wielu zmiennych bez napotykania problemów z identyfikowalnością modelu czy niestabilnością wyników), a nie (jak SEM- ML) na testowanie hipotez. Własności estymacji metodą PLS
 można wskazać, że efektem działania algorytmu jest optymalizacja pewnego kryterium. Estymacja modelu strukturalnego metodą PLS w ogólności daje się opisać tylko jako realizacja rozsądnego algorytmu działania. Nie można jednak (w ogólności) syntetycznie powiedzieć, do czego ten algorytm dąży. – Modele PLS są nakierowane na przewidywanie i eksplorację (możliwość uwzględnienia bardzo wielu zmiennych bez napotykania problemów z identyfikowalnością modelu czy niestabilnością wyników), a nie (jak SEM- ML) na testowanie hipotez. Własności estymacji metodą PLS.")
102
– W modelu wydziela się część pomiarową (zewnętrzną) i część strukturalną (wewnętrzną). – Ogólna idea estymacji sprowadza się do naprzemiennego wyliczania współczynników zewnętrznej i wewnętrznej części modelu w oparciu o wartości zmiennych ukrytych obliczone na podstawie współczynników z poprzedniego kroku estymacji. Estymacja PLS X 11 X 23 X 42 X 41 X 51 X 52 ξ5ξ5 ξ1ξ1 ξ2ξ2 X 43 ξ4ξ4 X 21 X 22 X 61 X 62 ξ6ξ6 ξ3ξ3 X 31

103
Blok typu reflective: – X ij = ω ij0 + ω ij ξ j +ε ij E(ε ij )=0, cor(ε ij, ξ j )=0 – Dla każdej zmiennej w bloku estymowane jest oddzielne równanie regresji liniowej. – Blok powinien być jednowymiarowy (teoria plus sprawdzian empiryczny, np. PCA, alfa Cronbacha). Warianty dla części pomiarowej X 23 ξ2ξ2 X 21 X 22 X 23 ξ2ξ2 X 21 X 22 Warianty można wybrać niezależnie od siebie dla każdego bloku zmiennych. Blok typu formative: ξ j =∑ω ij X ij +δ j E(δ j )=0, i cor(δ j, X ij )=0 Dla całego bloku estymuje się jedno równanie regresji liniowej. Z analizy należy usunąć zmienne, dla których okazałoby się, że sign(ω ij )≠sign(cor(X ij, ξ j ))
. Warianty dla części pomiarowej X 23 ξ2ξ2 X 21 X 22 X 23 ξ2ξ2 X 21 X 22 Warianty można wybrać niezależnie od siebie dla każdego bloku zmiennych. Blok typu formative: ξ j =∑ω ij X ij +δ j E(δ j )=0, i cor(δ j, X ij )=0 Dla całego bloku estymuje się jedno równanie regresji liniowej. Z analizy należy usunąć zmienne, dla których okazałoby się, że sign(ω ij )≠sign(cor(X ij, ξ j )).")
104
ξ j =e j0 +∑e ij ξ i +ν j gdzie ξ i są bezpośrednio połączone z ξ j (również gdy ξ i następują po ξ i ) – Centroid scheme: e ij =sign(cor(ξ i, ξ j )) – Factorial scheme: e ij =cor(ξ i, ξ j ) – Path weghting scheme: e ij =β ξ j |ξ i ; ξ i ’ dla ξ i poprzedzających ξ j w porządku czasowym e ij =cor(ξ i, ξ j ) dla ξ i następujących po ξ j w porządku czasowym Warianty dla części strukturalnej ξ5ξ5 ξ1ξ1 ξ2ξ2 ξ4ξ4 ξ6ξ6 ξ3ξ3
 – Centroid scheme: e ij =sign(cor(ξ i, ξ j )) – Factorial scheme: e ij =cor(ξ i, ξ j ) – Path weghting scheme: e ij =β ξ j |ξ i ; ξ i ’ dla ξ i poprzedzających ξ j w porządku czasowym e ij =cor(ξ i, ξ j ) dla ξ i następujących po ξ j w porządku czasowym Warianty dla części strukturalnej ξ5ξ5 ξ1ξ1 ξ2ξ2 ξ4ξ4 ξ6ξ6 ξ3ξ3")
105
1.Załóż początkowe wartości współczynników dla pomiarowej części modelu (ω ij ). Współcześnie używa się zwykle wag z 1. składowej głównej. 2.Oblicz zewnętrzne estymatory zmiennych ukrytych jako: ξ j ∑ω ij [X ij –E(X ij )] gdzie oznacza standaryzację wyrażenia po prawej. 3.Na podstawie tak wyliczonych estymatorów oblicz wartości współczynników strukturalnej części modelu (e ij ). 4.Oblicz wewnętrzne estymatory zmiennych ukrytych jako: ξ j ∑e i ξ i 5.Na podstawie tak wyliczonych estymatorów oblicz nowe wartości współczynników zewnętrznej części modelu (ω ij ). 6.Powtarzaj kroki 2.- 5. do uzyskania zbieżności. Algorytm estymacji PLS
] gdzie oznacza standaryzację wyrażenia po prawej. 3.Na podstawie tak wyliczonych estymatorów oblicz wartości współczynników strukturalnej części modelu (e ij ). 4.Oblicz wewnętrzne estymatory zmiennych ukrytych jako: ξ j ∑e i ξ i 5.Na podstawie tak wyliczonych estymatorów oblicz nowe wartości współczynników zewnętrznej części modelu (ω ij ). 6.Powtarzaj kroki do uzyskania zbieżności. Algorytm estymacji PLS.")
106
Po uzyskaniu zbieżności wykonuje się dwa ostatnie kroki: 7.Wyliczenie ostatecznych wartości estymatorów zmiennych ukrytych: ξ j =∑ω ij [X ij –E(X ij )] / σgdzie σ=D(∑ω ij [X ij –E(X ij )] ) Tak uzyskane estymatory zwykle unormowuje się jeszcze na jeden z dwóch sposobów: 1) ξ j ‘= ξ j +∑ω ij E(X ij ) / σ(„odcentrowanie” zmiennej) 2) ξ j ‘’= [ξ j ‘+∑ω ij E(X ij ) ] / ∑ω ij równoważnie:ξ j ‘’= ∑ω ij X ij / ∑ω ij (przedstawieniu zmiennej ukrytej na tej samej skali, co zmienne mierzalne danego bloku) 8.Wyliczenie współczynników opisujących zależności przyczynowe w części strukturalnej modelu, przy użyciu analizy ścieżkowej. Algorytm estymacji PLS
![Po uzyskaniu zbieżności wykonuje się dwa ostatnie kroki: 7.Wyliczenie ostatecznych wartości estymatorów zmiennych ukrytych: ξ j =∑ω ij [X ij –E(X ij )] / σgdzie σ=D(∑ω ij [X ij –E(X ij )] ) Tak uzyskane estymatory zwykle unormowuje się jeszcze na jeden z dwóch sposobów: 1) ξ j ‘= ξ j +∑ω ij E(X ij ) / σ(„odcentrowanie zmiennej) 2) ξ j ‘’= [ξ j ‘+∑ω ij E(X ij ) ] / ∑ω ij równoważnie:ξ j ‘’= ∑ω ij X ij / ∑ω ij (przedstawieniu zmiennej ukrytej na tej samej skali, co zmienne mierzalne danego bloku) 8.Wyliczenie współczynników opisujących zależności przyczynowe w części strukturalnej modelu, przy użyciu analizy ścieżkowej.](http://images.slideplayer.pl/10/2865940/slides/slide_106.jpg "Algorytm estymacji PLS.")
107
– Estymacja metodą PLS sprowadza się do liczenia dużej liczby regresji liniowych, przy czym w każdym kroku procedury iteracyjnej każde z równań opisujących model jest wyliczane oddzielnie. Stąd niewielkie zapotrzebowanie na liczbę jednostek obserwacji – decyduje tutaj największa liczba zmiennych niezależnych występujących w pojedynczym równaniu (np. w modelu MJR cztery zmienne). Mniejsze są też problemy w przypadku braków danych – dany brak występuje bowiem tylko lokalnie, w jednym równaniu. – W związku z tym nie występują też (dosyć często występujące w SEM-ML) problemy z nieidentyfikowalnością modelu. – Błędy standardowe współczynników modelu można uzyskać z regresji obliczanych w ostatnim kroku estymacji, jednak obecnie często oblicza się je przy pomocy metod symulacyjnych (jakcknife, bootstrap). Własności
. Mniejsze są też problemy w przypadku braków danych – dany brak występuje bowiem tylko lokalnie, w jednym równaniu. – W związku z tym nie występują też (dosyć często występujące w SEM-ML) problemy z nieidentyfikowalnością modelu. – Błędy standardowe współczynników modelu można uzyskać z regresji obliczanych w ostatnim kroku estymacji, jednak obecnie często oblicza się je przy pomocy metod symulacyjnych (jakcknife, bootstrap). Własności.")
108
Model PLS nie optymalizuje żadnego globalnego kryterium dopasowania do danych. Zaproponowano jednak kilka miar pozwalających ocenić wyniki estymacji: – Indeks zmienności wspólnej (communality index): Miara wyliczana dla każdego bloku oddzielnie: communality j =E[cor 2 (X ij, ξ j )] Jako miary globalnej można użyć średnią ze wszystkich bloków. – Redundancy index: Miara wyliczana dla każdego bloku oddzielnie: redundancy j =communality j R 2 ξ j |ξ {i} gdzie ξ i wyjaśniają ξ j Jako miary globalnej można użyć średnią ze wszystkich bloków. – GoF (Goodness-of-fit): GoF=[ E(communality) E(R 2 ξ j |ξ {i} ) ] 0,5 Miary dopasowania
: Miara wyliczana dla każdego bloku oddzielnie: communality j =E[cor 2 (X ij, ξ j )] Jako miary globalnej można użyć średnią ze wszystkich bloków. – Redundancy index: Miara wyliczana dla każdego bloku oddzielnie: redundancy j =communality j R 2 ξ j |ξ {i} gdzie ξ i wyjaśniają ξ j Jako miary globalnej można użyć średnią ze wszystkich bloków. – GoF (Goodness-of-fit): GoF=[ E(communality) E(R 2 ξ j |ξ {i} ) ] 0,5 Miary dopasowania.")
109
SEM: MLE vs PLS Wyznaczanie pametrów modelu MJR: SEM - PLS

110
Wiele wektorów Liniowa kombinacja wektorów Macierz – uporządkowany zbiór wektorów kolumnowych Rozmiary macierzy - Operacje ma macierzy Dodawanie, mnożenie przez stałą, transpozycja Liniowa kombinacja wektorów w zapisie macierzowym Ślad Rząd Wyznacznik Wartości własne, wektory własne pierwsza, druga ostatnia, Wybrane macierze symetryczna, diagonalna, jednostkowa, odwrotna, zerowa,

111
Wektory geometrycznie Układ odniesienia – ortogonalny układ współrzędnych Układ jedno-wymiarowy (na R 1 ) Wektor w układzie odniesienia: początek, koniec, współrzędne wektora Długość wektora a jego współrzędne Rzut końca wektora na osie układu współrzędnych Wektor o długości 1 Dwa wektory – współrzędne, długości Kąt między wektorami Trygonometria na płaszczyźnie: sinus, cosinus i relacje między nimi Cosinus różnicy kątów Cosinus kąta między wektorami
 Wektor w układzie odniesienia: początek, koniec, współrzędne wektora Długość wektora a jego współrzędne Rzut końca wektora na osie układu współrzędnych Wektor o długości 1 Dwa wektory – współrzędne, długości Kąt między wektorami Trygonometria na płaszczyźnie: sinus, cosinus i relacje między nimi Cosinus różnicy kątów Cosinus kąta między wektorami")
112
MomentyWektory algebraicznieWektory geometrycznie Zmienna surowa w n- elementowej populacji Ω Wektor = uporządkowany zbiór liczb z R 1 z powtórzeniami Obiekt w układzie odniesienia o współrzędnych początk a i końca Wariancja zmiennej Zmienna wycentrowana, standaryzowana Kowariancja zmiennych surowych Kowariancja zmiennych wycentrowanych, standaryzowanych

113
MomentyWektory algebraicznieWektory geometrycznie

114
Rachunek momentów w notacji wektorowej-algebraicznej Wektor a skalar – przykład na osi R 1 Rozmiar wektora, wektor kolumnowy, wierszowy Wyróżnione wektory: 0, 1 Operacja na 1 wektorze: transpozycja, mnożenie/dzielenie przez stałą Operacje na dwóch wektorach +/-, */:, Liniowa kombinacja wektorów Iloczyn skalarny wektorów. Wektory ortogonalne Długość wektora/norma Wektory orto-normalne Wprowadzenie: założenia i ograniczenia Zmienne interwałowe, zależnosci liniowe, rozkłady normalne Ograniczenia opisowe: Igmorowanie nieliniowych zależności między zmiennymi interwałowymi Ignorowanie zmiennych porządkowych i binarnych Ograniczenia inferencyjne: normalność rozkładów Czy wszystkie ograniczenia mozna przezwyciężyć? PLS, korelacje tetra i polichoryczne Momenty Momenty – przypomnienie: średnia, wariancja, kowariancja, liniowe przekształcenia, Momenty zmiennej surowej, centrowanej, standaryzowane Momenty rozkładu dwóch zmiennych surowych, centrowanych, standaryzowanych




, gdzie X jest liczbą osób w rodzinie, a Y liczbą izb w mieszkaniu. Niech f.r.p. tej zmiennej.>")


















