Wnioskowanie statystyczne
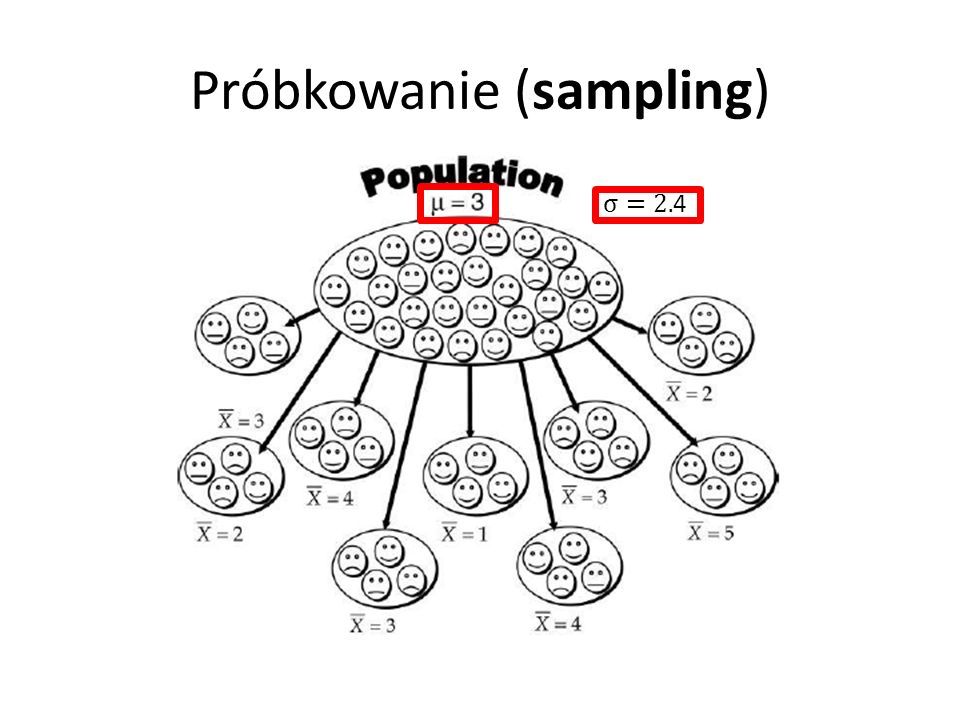
Próbkowanie (sampling)
SE (standard error) SE rozkład próbkowania – sampling distribution
ważna rzecz! µ
µ P(z>0.8)=0.468
ważna rzecz! µ P(z>1.7)=0.045
Jeżeli to prawdopodobieństwo jest odpowiednio małe, możemy odrzucić H0 Dane nie pasują do H0 Dane nie wspierają H0 Otrzymanie takich danych przy założeniu prawdziwości H0 jest bardzo małe Wnioskowanie statystyczne
Jak małe musi być to prawdopodobieństwo? Arbitralne! (kryterium Fishera) <0.05 odpowiada istotności statystycznej (ważna rzecz…)
ważna rzecz! µ P(z>1.7)=0.045
Wnioskowanie statystyczne H0: średnia µ w populacji wynosi 3 H1: średnia µ w populacji jest większa od 3 Na poziomie istotności p<0.05 (p=0.045) odrzucamy H0 na korzyść H1
Wnioskowanie statystyczne Rodzaje hipotez Używaliśmy hipotezy jednostronnej! H1: średnia µ w populacji jest większa od 3 Ustaliliśmy przedział krytyczny (Z kryt )
µ P(z>1.64)<0.050 Jeśli z >z kryt to odrzucamy hipotezę 0!
Wnioskowanie statystyczne Rodzaje hipotez
hipoteza dwustronna „bezpieczniejsza” ma swój koszt! – dwustronne przedziały krytyczne są nieco mniejsze!
Wnioskowanie statystyczne Rodzaje hipotez
Statystyka testowa
Błąd I rodzaju ( ), błąd II rodzaju ( ) Błąd I rodzaju odrzucamy H0, gdy w rzeczywistości jest ona prawdziwa maksymalna szansa popełnienia błędu I rodzaju to to poziom istotności testu Błąd II rodzaju nie odrzucamy H0, chociaż jest ona fałszywa szansa błędu II rodzaju to 1- to moc testu (prawdopodobieństwo odrzucenia hipotezy zerowej, gdy jest ona fałszywa)
Istotność a wielkość efektu (effect size statistics) różnica między średnimi może być istotna, ale nie interesuje nas to z punktu widzenia praktycznego Lek nadciśnieniowy A vs Lek nadciśnieniowy B B obniża ciśnienie o 1 mmHg w stosunku do leku A (różnica istotna statystycznie, p<0.002)