Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Metody Przetwarzania Danych Meteorologicznych Wykład 4
Krzysztof Markowicz Instytut Geofizyki UW

2
Wybrane rozkłady prawdopodobieństwa rozkład normalny
gęstość praw-a dystrybuanta Własności Jeśli X ~ N(μ, σ2) i a i b są liczbami rzeczywistymi, to: aX + b ~ N(aμ + b, (aσ)2). Jeśli X1 ~ N(μ1, σ12) i X2 ~ N(μ2, σ22), i X1 i X2 są niezależne, to X1 + X2 ~ N(μ1 + μ2, σ12 + σ22). Jeśli X1, ..., Xn są niezależnymi zmiennymi losowymi o standardowym rozkładzie normalnym, to X Xn2 ma rozkład chi-kwadrat z n stopniami swobody.
 i a i b są liczbami rzeczywistymi, to: aX + b ~ N(aμ + b, (aσ)2). Jeśli X1 ~ N(μ1, σ12) i X2 ~ N(μ2, σ22), i X1 i X2 są niezależne, to X1 + X2 ~ N(μ1 + μ2, σ12 + σ22). Jeśli X1, ..., Xn są niezależnymi zmiennymi losowymi o standardowym rozkładzie normalnym, to X Xn2 ma rozkład chi-kwadrat z n stopniami swobody.")
3
Parametry rozkładu normalnego
wartość oczekiwana: μ mediana: μ wariancja: σ2 odchylenie standardowe: σ skośność: 0 kurtoza: 0 (czwarty moment wynosi 3)
")
4
Centralne twierdzenie graniczne
Jedną z najważniejszych własności rozkładu normalnego jest fakt, że, przy pewnych założeniach, rozkład sumy dużej liczby zmiennych losowych jest w przybliżeniu normalny. W praktyce twierdzenie to ma zastosowanie jeśli chcemy użyć rozkładu normalnego jako przybliżenia dla innych rozkładów. Np. w teorii błędów pomiarowych. Rozkład dwumianowy z parametrami n i p jest w przybliżeniu normalny dla dużych n i p nie leżących zbyt blisko 1 lub 0. Przybliżony rozkład ma średnią równą μ = np i odchylenie standardowe σ = (n p (1 - p))0.5. Rozkład Poissona z parametrem λ jest w przybliżeniu normalny dla dużych wartości λ. Przybliżony rozkład normalny ma średnią μ = λ i odchylenie standardowe σ = √λ. Dokładność przybliżenia tych rozkładów zależy od celu użycia przybliżenia i tempa zbieżności do rozkładu normalnego. Zazwyczaj takie przybliżenia są mniej dokładne w ogonach rozkładów.
)0.5. Rozkład Poissona z parametrem λ jest w przybliżeniu normalny dla dużych wartości λ. Przybliżony rozkład normalny ma średnią μ = λ i odchylenie standardowe σ = √λ. Dokładność przybliżenia tych rozkładów zależy od celu użycia przybliżenia i tempa zbieżności do rozkładu normalnego. Zazwyczaj takie przybliżenia są mniej dokładne w ogonach rozkładów.")
5
Rozkład normalny - wielowymiarowy
n-wymiarowa zmienna losowa podlega n-wymiarowemu rozładowi normalnemu jeśli dowolna kombinacja liniowa jej składowych ma rozkład normalny. Funkcja gęstości n-wymiarowego rozkładu normalnego wektora losowego X o wektorze wartości oczekiwanych macierzy kowariancji dana jest wzorem: co oznacza się w skrócie zapisem

6
Niezależność zmiennych
Jeśli składowe wektora losowego X o wielowymiarowym rozkładzie normalnym są nieskorelowane to są niezależne i każda z nich podlega rozkładowi normalnemu N(i,i) . Wówczas funkcja gęstości wektora losowego X jest iloczynem funkcji gęstości każdej ze zmiennych:
 . Wówczas funkcja gęstości wektora losowego X jest iloczynem funkcji gęstości każdej ze zmiennych:")
7
Rozkład Poissona Rozkład Poissona to rozkład dyskretny przedstawiający liczbę wystąpień zjawiska w czasie t, w określonej liczbie prób, jeśli wystąpienia te są niezależne od siebie. Rozkład ma zastosowanie do obliczenia przybliżonej wartości prawdopodobieństwa w rozkładzie Bernoulliego przy dużej liczbie prób i niskim prawdopodobieństwie sukcesu. Rozkład Poissona jest określany przez jeden parametr λ, który ma interpretację wartości oczekiwanej. Parametr ten jest równy prawdopodobieństwu uzyskania sukcesu w pojedynczej próbie pomnożony przez liczbę prób. Gęstość prawdopodobieństwa Zmienna losowa ma rozkład Piossona gdy:

8
wartość oczekiwana: λ, wariancja: λ, Współczynnik skośności: λ-0.5 kurtoza: λ-1

9
Rozkład chi kwadrat Rozkład chi kwadrat (χ²) to rozkład zmiennej losowej, która jest sumą k kwadratów niezależnych zmiennych losowych o standardowym rozkładzie normalnym. Liczbę naturalną k nazywa się liczbą stopni swobody rozkładu zmiennej losowej. Jeżeli ciąg niezależnych zmiennych losowych oraz to Zmienna losowa Y ma rozkład chi kwadrat o k stopniach swobody Gęstość prawdopodobieństwa ma postać:
 to rozkład zmiennej losowej, która jest sumą k kwadratów niezależnych zmiennych losowych o standardowym rozkładzie normalnym. Liczbę naturalną k nazywa się liczbą stopni swobody rozkładu zmiennej losowej. Jeżeli ciąg niezależnych zmiennych losowych. oraz to. Zmienna losowa Y ma rozkład chi kwadrat o k stopniach swobody. Gęstość prawdopodobieństwa ma postać:")
10
gęstość pro-wa dystrybuanta Własności rozkładu: Średnia: k Wariancja: 2k

11
Rozkład Weibulla 2-parametrowy rozkład określony tylko dla zmiennej losowej x>0 k > 0 jest parametrem kształtu λ > 0 określa skale rozkładu Dystrybuanta rozkładu dla x ≥ 0, F(x; k; λ) = dla x < 0.
 = 0 dla x < 0.")
12
Rozkładu używa się do analizy prędkości wiatru i opadów.
Przy obliczaniu zasobów energetycznych na potrzeby energetyki wiatru. Wartość średnia Wariancja

13
Rozkład prędkości wiatru w listopadzie
stacja Strzyżów

14
Wnioskowanie statystyczne - polega na uogólnianiu wyników otrzymanych na podstawie próby losowej na całą populację generalną, z której próba została pobrana Wnioskowanie statystyczne dzieli się na: Estymację – szacowanie wartości parametrów lub postaci rozkładu zmiennej na podstawie próby – na podstawie wyników próby formułujemy wnioski dla całej populacji Weryfikację hipotez statystycznych – sprawdzanie określonych założeń sformułowanych dla parametrów populacji generalnej na podstawie wyników z próby – najpierw wysuwamy założenie, które weryfikujemy na podstawie wyników próby

15
Estymator – wielkość (charakterystyka, miara), obliczona na podstawie próby, służąca do oceny wartości nieznanych parametrów populacji generalnej. Najlepszym z pośród wszystkich estymatorów parametru w populacji generalnej jest ten, który spełnia wszystkie właściwości estymatorów (jest równocześnie nieobciążony, zgodny, efektywny, dostateczny).
.")
16
Definicja estymatora Niech zmienna losowa X ma funkcję gęstości prawdopodobieństwa fX zależną od m parametrów i i= 1,2,…,m. Jeśli zostało wygenerowanych (zmierzonych) N liczb losowych x1, x2, …, xN , będących wartościami zmiennej losowej X, wówczas można skonstruować m funkcji tych liczb, Si (x1, x2, …, xN), i=1,2,…,m których można użyć do wyznaczenia parametrów i. Funkcje Si nazywamy estymatorami parametru i.. Estymator nazywamy nieobciążonym, gdy dla każdego N jego wartość oczekiwana E(Si) jest równa parametrowi i. Różnicę B(Si)=E(Si)- i nazywamy obciążeniem (bias)
 N liczb losowych x1, x2, …, xN , będących wartościami zmiennej losowej X, wówczas można skonstruować m funkcji tych liczb, Si (x1, x2, …, xN), i=1,2,…,m których można użyć do wyznaczenia parametrów i. Funkcje Si nazywamy estymatorami parametru i.. Estymator nazywamy nieobciążonym, gdy dla każdego N jego wartość oczekiwana E(Si) jest równa parametrowi i. Różnicę B(Si)=E(Si)- i. nazywamy obciążeniem (bias)")
17
Estymacja parametrów Mając dane n wektorów pobranych z pewnego wielowymiarowego rozkładu możemy oszacować jego parametry w następujący sposób: Estymator wartości oczekiwanej: Estymator macierzy kowariancji o największej wiarygodności : Estymator nieobciążony macierzy kowariancji:

18
Estymacja przedziałowa
polega na budowie przedziału zwanego przedziałem ufności, który z określonym prawdopodobieństwem będzie zawierał nieznaną wartość szacowanego parametru gdzie: Q – nieznany parametr populacji generalnej, końce przedziałów (dolna i górna granica przedziału), będące funkcją wylosowanej próby
, będące funkcją wylosowanej próby.")
19
Przedział ufności Niech cecha X ma rozkład w populacji z nieznanym parametrem θ. Z populacji wybieramy próbę losową (X1, X2, ..., Xn). Przedziałem ufności (θ – θ1, θ + θ2) o współczynniku ufności 1 - α nazywamy taki przedział (θ – θ1, θ + θ2), który spełnia warunek: P(θ1 < θ < θ2) = 1 − α gdzie θ1 i θ2 są funkcjami wyznaczonymi na podstawie próby losowej. Podobnie jak w przypadku estymatorów definicja pozwala na dowolność wyboru funkcji z próby, jednak tutaj kryterium wyboru najlepszych funkcji narzuca się automatycznie - zazwyczaj będziemy poszukiwać przedziałów najkrótszych.
 o współczynniku ufności 1 - α nazywamy taki przedział (θ – θ1, θ + θ2), który spełnia warunek: P(θ1 < θ < θ2) = 1 − α. gdzie θ1 i θ2 są funkcjami wyznaczonymi na podstawie próby losowej. Podobnie jak w przypadku estymatorów definicja pozwala na dowolność wyboru funkcji z próby, jednak tutaj kryterium wyboru najlepszych funkcji narzuca się automatycznie - zazwyczaj będziemy poszukiwać przedziałów najkrótszych.")
20
Współczynnik ufności 1 - α jest wielkością, którą można interpretować w następujący sposób:
jest to prawdopodobieństwo, że rzeczywista wartość parametru θ w populacji znajduje się w wyznaczonym przez nas przedziale ufności. Im większa wartość tego współczynnika, tym szerszy przedział ufności, a więc mniejsza dokładność estymacji parametru. Im mniejsza wartość 1 - α, tym większa dokładność estymacji, ale jednocześnie tym większe prawdopodobieństwo popełnienia błędu. Wybór odpowiedniego współczynnika jest więc kompromisem pomiędzy dokładnością estymacji a ryzykiem błędu. W praktyce przyjmuje się zazwyczaj wartości: 0,99; 0,95 lub 0,90, zależnie od parametru.

21
Przedział ufności dla wartości oczekiwanej (średniej) – rozkład normalny
Jeśli cecha ma w populacji rozkład normalny N(m, σ), przy czym odchylenie standardowe σ jest znane. Przedział ufności dla parametru m tego rozkładu ma postać: n to liczebność próby losowej oznacza średnią z próby losowej σ to odchylenie standardowe z próby uα jest statystyką, spełniającą warunek: P( − uα < U < uα) = 1 − α gdzie U jest zmienną losową o rozkładzie normalnym N(0, 1). oraz to kwantyle rzędów odpowiednio i rozkładu N(0, 1)
, przy czym odchylenie standardowe σ jest znane. Przedział ufności dla parametru m tego rozkładu ma postać: n to liczebność próby losowej. oznacza średnią z próby losowej. σ to odchylenie standardowe z próby. uα jest statystyką, spełniającą warunek: P( − uα < U < uα) = 1 − α. gdzie U jest zmienną losową o rozkładzie normalnym N(0, 1). oraz to kwantyle rzędów odpowiednio i. rozkładu N(0, 1)")
22
Przedział ufności dla wariancji
Przedział ufności dla wariancji w populacji o rozkładzie normalnym N(m, σ) wyznaczamy ze wzoru gdzie: n to liczebność próby losowej s to odchylenie standardowe z próby i to statystyki spełniające odpowiednio równości: gdzie χ2 ma rozkład chi-kwadrat z n - 1 stopniami swobody i
 wyznaczamy ze wzoru. gdzie: n to liczebność próby losowej. s to odchylenie standardowe z próby. i to statystyki spełniające odpowiednio równości: gdzie χ2 ma rozkład chi-kwadrat z n - 1 stopniami swobody. i")
23
Przykład - Minimalna liczebność próby
Jeśli chcemy oszacować parametr z określoną dokładnością d, możemy, po odpowiednich przekształceniach wzorów na przedziały ufności, wyznaczyć liczebność próby losowej potrzebną do osiągnięcia zakładanej dokładności. Przykład: Niech wzrost wszystkich osób w Polsce ma rozkład normalny z odchyleniem standardowym 25,28 cm. Obliczmy ile osób wystarczy zmierzyć, aby z prawdopodobieństwem 95% wyznaczyć średni wzrost z dokładnością do 5 cm. Jeśli chcemy uzyskać dokładność 5 cm, należy zadbać o to, aby połowa długości przedziału ufności była mniejsza lub równa 5 cm. Ze wzoru na przedział ufności dla rozkładu normalnego o znanym odchyleniu standardowym wynika, że dokładność estymacji powinna spełniać zależność:

24
Mamy więc: Podstawiając do wzoru wartości σ = 25,28; d = 5 cm; u = 1,96 (wartość obliczona na podstawie tablic rozkładu normalnego lub w matlabie u =norminv(1-/2,0,1) ) uzyskujemy minimalną wielkość próby na poziomie n=99.
 ) uzyskujemy minimalną wielkość próby na poziomie n=99.")
25
Poziom istotności Poziom istotności - jest to prawdopodobieństwo popełnienia błędu I rodzaju (zazwyczaj oznaczane symbolem α). Określa również maksymalne ryzyko błędu, jakie badacz jest skłonny zaakceptować. Wybór wartości α zależy natury problemu i od tego jak dokładnie chce on weryfikować swoje hipotezy, najczęściej przyjmuje się α = 0,05, 0,03 lub 0,01. Błąd pierwszego rodzaju ('false positive') - w statystyce pojęcie z zakresu weryfikacji hipotez statystycznych - błąd polegający na odrzuceniu hipotezy zerowej, która w rzeczywistości jest prawdziwa. Błąd pierwszego rodzaju znany też jest jako: błąd pierwszego typu, błąd przyjęcia lub alfa-błąd. Oszacowanie prawdopodobieństwa popełnienia błędu pierwszego rodzaju oznaczamy symbolem α i nazywamy poziomem istotności testu.
. Określa również maksymalne ryzyko błędu, jakie badacz jest skłonny zaakceptować. Wybór wartości α zależy natury problemu i od tego jak dokładnie chce on weryfikować swoje hipotezy, najczęściej przyjmuje się. α = 0,05, 0,03 lub 0,01. Błąd pierwszego rodzaju ( false positive ) - w statystyce pojęcie z zakresu weryfikacji hipotez statystycznych - błąd polegający na odrzuceniu hipotezy zerowej, która w rzeczywistości jest prawdziwa. Błąd pierwszego rodzaju znany też jest jako: błąd pierwszego typu, błąd przyjęcia lub alfa-błąd. Oszacowanie prawdopodobieństwa popełnienia błędu pierwszego rodzaju oznaczamy symbolem α i nazywamy poziomem istotności testu.")
26
Weryfikacja hipotez statystycznych
Weryfikacja hipotez statystycznych jest drugim, obok estymacji statystycznej, sposobem uogólniania wyników losowej próby na populacje z której próba pochodzi. Polega ona na sprawdzaniu przypuszczeń na temat rozkładów statystycznych jednej lub wielu zmiennych w populacji. Podobnie jak w przypadku estymacji, wnioskowanie z próby o populacji nie jest i nie może być niezawodne. Będzie można jednak oceniać prawdopodobieństwa popełnienia błędów związanych ze stosowaną metodą weryfikacji hipotez. Hipotezą statystyczna nazywa się dowolne przypuszczenie dotyczące nieznanego rozkładu statystycznego jednej zmiennej lub łącznego rozkładu wielu zmiennych w populacji.

27
Przebieg procedury weryfikacyjnej
Wyróżnia się hipotezy parametryczne dotyczące nieznanych wartości parametrów rozkładu statystycznego oraz hipotezy nieparametryczne, które są przypuszczeniami na temat klasy rozkładów do których należy rozkład statystyczny w populacji. Przebieg procedury weryfikacyjnej 1. Sformułowanie hipotezy zerowej i alternatywnej Hipoteza zerowa (H0) - Jest to hipoteza poddana procedurze weryfikacyjnej, w której zakładamy, że różnica między analizowanymi parametrami lub rozkładami wynosi zero. Przykładowo wnioskując o parametrach hipotezę zerową zapiszemy jako: H0: θ1 = θ2 . Hipoteza alternatywna (H1) - hipoteza przeciwstawna do weryfikowanej. Możemy ją zapisać na trzy sposoby w zależności od sformułowania badanego problemu: H1: θ1 ≠ θ2 H1: θ1 > θ2 H1: θ1 < θ2
 - Jest to hipoteza poddana procedurze weryfikacyjnej, w której zakładamy, że różnica między analizowanymi parametrami lub rozkładami wynosi zero. Przykładowo wnioskując o parametrach hipotezę zerową zapiszemy jako: H0: θ1 = θ2 . Hipoteza alternatywna (H1) - hipoteza przeciwstawna do weryfikowanej. Możemy ją zapisać na trzy sposoby w zależności od sformułowania badanego problemu: H1: θ1 ≠ θ2. H1: θ1 > θ2. H1: θ1 < θ2.")
28
2. Wybór statystyki testowej
Budujemy pewną statystykę W, która jest funkcją wyników z próby losowej W = f(x1, x2, ..., xn) i wyznaczamy jej rozkład przy założeniu, że hipoteza zerowa jest prawdziwa. Funkcję W nazywa się statystyką testową lub funkcją testową. 3. Określenie poziomu istotności α Na tym etapie procedury weryfikacyjnej przyjmujemy prawdopodobieństwo popełnienia błędu I rodzaju, który polega na odrzuceniu hipotezy zerowej wtedy, gdy jest ona prawdziwa. Prawdopodobieństwo to jest oznaczane symbolem α i nazywane poziomem istotności. Na ogół przyjmujemy prawdopodobieństwo bliskie zeru, ponieważ chcemy aby ryzyko popełnienia błędu było jak najmniejsze. Najczęściej zakładamy, że poziom istotności α≤ 0.1 (np. α=0.01 ; α=0.05 ; α=0.1)
 i wyznaczamy jej rozkład przy założeniu, że hipoteza zerowa jest prawdziwa. Funkcję W nazywa się statystyką testową lub funkcją testową. 3. Określenie poziomu istotności α. Na tym etapie procedury weryfikacyjnej przyjmujemy prawdopodobieństwo popełnienia błędu I rodzaju, który polega na odrzuceniu hipotezy zerowej wtedy, gdy jest ona prawdziwa. Prawdopodobieństwo to jest oznaczane symbolem α i nazywane poziomem istotności. Na ogół przyjmujemy prawdopodobieństwo bliskie zeru, ponieważ chcemy aby ryzyko popełnienia błędu było jak najmniejsze. Najczęściej zakładamy, że poziom istotności α≤ 0.1 (np. α=0.01 ; α=0.05 ; α=0.1)")
29
4. Wyznaczenie obszaru krytycznego testu
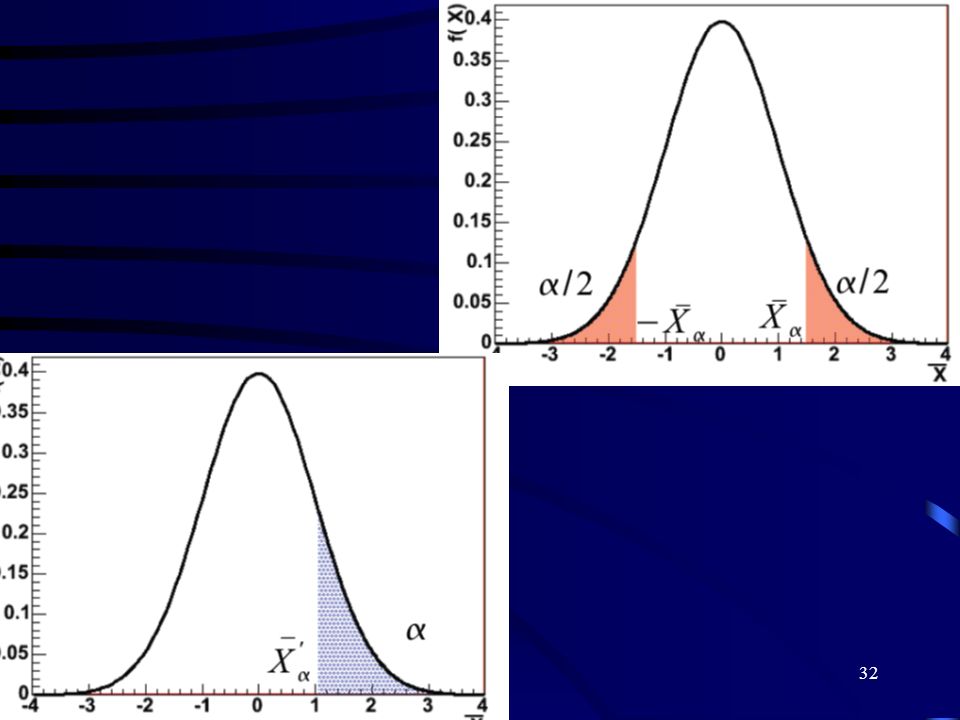
Obszar krytyczny - obszar znajdujący się zawsze na krańcach rozkładu. Jeżeli obliczona przez nas wartość statystyki testowej znajdzie się w tym obszarze to weryfikowaną przez nas hipotezę Ho odrzucamy. Wielkość obszaru krytycznego wyznacza dowolnie mały poziom istotności α, natomiast jego położenie określane jest przez hipotezę alternatywną. Obszar krytyczny od pozostałej części rozkładu statystyki oddzielony jest przez tzw. wartości krytyczne testu (w), czyli wartości odczytane z rozkładu statystyki przy danym α, tak aby spełniona była relacja zależna od sposobu sformułowania H1: P{|w|≥w} = α gdy H1: θ1 ≠ θ2 (obszar dwustronny) P{w ≥w} = α gdy H1: θ1 > θ2 (obszar prawostronny) P{w ≤w} = α gdy H1: θ1 < θ2 (obszar lewostronny)
, czyli wartości odczytane z rozkładu statystyki przy danym α, tak aby spełniona była relacja zależna od sposobu sformułowania H1: P{|w|≥w} = α gdy H1: θ1 ≠ θ2 (obszar dwustronny) P{w ≥w} = α gdy H1: θ1 > θ2 (obszar prawostronny) P{w ≤w} = α gdy H1: θ1 < θ2 (obszar lewostronny)")
30
5. Obliczenie statystyki na podstawie próby
Wyniki próby opracowujemy w odpowiedni sposób, zgodnie z procedurą wybranego testu i są one podstawą do obliczenia statystyki testowej. Większość statystyk testowych, mających dokładny rozkład normalny, t-Studenta lub graniczny rozkład normalny, obliczamy w następujący sposób: gdzie: W - Statystyka testowa a - Statystyka obliczona z próby b - Hipotetyczna wartość parametru(ów) c - Odchylenie standardowe rozkładu statystyki
 c - Odchylenie standardowe rozkładu statystyki.")
31
6. Podjęcie decyzji Wyznaczoną na podstawie próby wartość statystyki porównujemy z wartością krytyczną testu. Jeżeli wartość ta znajdzie się w obszarze krytycznym to hipotezę zerową należy odrzucić jako nieprawdziwą. Stąd wniosek, że prawdziwa jest hipoteza alternatywna. Jeżeli natomiast wartość ta znajdzie się poza obszarem krytycznym, oznacza to, że brak jest podstaw do odrzucenia hipotezy zerowej. Stąd wniosek, że hipoteza zerowa może, ale nie musi, być prawdziwa.

33
Test dla średniej Hipotezę zerową i alternatywną oznaczamy w następujący sposób: Ho: μ = μo Zakłada ona, że nieznana średnia w populacji μ jest równa średniej hipotetycznej μo H1: μ ≠ μo lub H1: μ > μo lub H1: μ < μo Jest ona zaprzeczeniem Ho, występuje w trzech wersjach w zależności od sformułowania badanego problemu. Sprawdzianem hipotezy jest statystyka testowa, która jest funkcją wyników próby losowej. Postać funkcji testowej (tzw. statystyki) zależy od: rozkładu cechy w populacji znajomości wartości odchylenia standardowego w populacji liczebności próby Biorąc pod uwagę powyższe przypadki, założoną przez nas hipotezę możemy sprawdzić za pomocą trzech testów:
 zależy od: rozkładu cechy w populacji. znajomości wartości odchylenia standardowego w populacji. liczebności próby. Biorąc pod uwagę powyższe przypadki, założoną przez nas hipotezę możemy sprawdzić za pomocą trzech testów:")
34
1. Jeżeli populacja ma rozkład normalny N(μ,σ) o nieznanej średniej μ i znanym odchyleniu standardowym σ, natomiast liczebność próby n jest dowolna, wtedy statystyka ma postać: gdzie: m - średnia z próby Jeżeli Ho jest prawdziwa, to statystyka testowa Z ma rozkład asymptotycznie normalny. Wartość statystyki, którą obliczymy korzystając z powyższego wzoru, oznaczamy jako z. Następnie porównujemy ją z wartością krytyczną testu z , którą możemy odczytać z tablic standaryzowanego rozkładu normalnego, uwzględniając poziom istotności α. Decyzję o odrzuceniu Ho podejmujemy, jeżeli wartość statystyki znajduje się w obszarze krytycznym. Jeżeli natomiast wartość ta znajdzie się poza obszarem krytycznym, nie ma wtedy podstaw do odrzucenia Ho.

35
2. Jeżeli rozkład populacji jest dowolny, o nieznanej średniej μ i nieznanym odchyleniu standardowym σ, natomiast liczebność próby jest n > 30, wtedy statystyka ma postać: Jeżeli Ho jest prawdziwa, to statystyka testowa ma rozkład asymptotycznie normalny. 3. Jeżeli rozkład populacji jest normalny N(μ,σ), o nieznanej średniej μ i nieznanym odchyleniu standardowym σ, natomiast liczebność próby jest n < 30, wtedy statystyka ma postać: Jeżeli Ho jest prawdziwa, to statystyka testowa ma rozkład t-Studenta o liczbie stopni swobody ν = n-1. Wartość statystyki, którą obliczymy korzystając z powyższego wzoru, oznaczamy jako t. Następnie porównujemy ją z wartością krytyczną testu t, którą odczytujemy z tablic rozkładu t-Studenta przy założonym poziomie istotności α oraz liczbie stopni swobody ν = n-1.
, o nieznanej średniej μ i nieznanym odchyleniu standardowym σ, natomiast liczebność próby jest n < 30, wtedy statystyka ma postać: Jeżeli Ho jest prawdziwa, to statystyka testowa ma rozkład. t-Studenta o liczbie stopni swobody ν = n-1. Wartość statystyki, którą obliczymy korzystając z powyższego wzoru, oznaczamy jako t. Następnie porównujemy ją z wartością krytyczną testu t, którą odczytujemy z tablic rozkładu t-Studenta przy założonym poziomie istotności α oraz liczbie stopni swobody ν = n-1.")
36
Testy dla jednej wariancji
Porównujemy wariancję w populacji z „wzorcową” wartością o2 Hipotezy mają postać: Ho: 2= o2 H1: postać hipotezy alternatywnej zależy od sformułowania zagadnienia: (a) 2> o2 (b) 2< o2 (c) 2 o2 Postać statystyki i dalszy przebieg testu zależy od rozmiaru próby.
 2> o2. (b) 2< o2. (c) 2 o2. Postać statystyki i dalszy przebieg testu zależy od rozmiaru próby.")
37
Próby małe Wyznaczamy wartość statystyki
s2 jest tutaj wariancją z próby a n – liczebnością próby. Statystyka ta ma rozkład chi-kwadrat - zatem wartość krytyczną kryt2 odczytujemy z tablic rozkładu chi-kwadrat dla v = n − 1 stopni swobody i dla poziomu istotności gdy hipoteza alternatywna H1 ma postać (a), w przypadku (b) – odczytujemy z tablic w przypadku (c) - odczytujemy dwie wartości: oraz Przedział krytyczny W przypadku (a) jest prawostronny, czyli gdy 2 > kryt2 odrzucamy H0, w przypadku przeciwnym – nie ma podstaw do jej odrzucenia. W przypadku (b) – przedział krytyczny jest lewostronny (dla 2 <kryt2 odrzucamy H0), W przypadku (c) – przedział krytyczny jest obustronny.
, w przypadku (b) – odczytujemy z tablic. w przypadku (c) - odczytujemy dwie wartości: oraz Przedział krytyczny. W przypadku (a) jest prawostronny, czyli gdy 2 > kryt2 odrzucamy H0, w przypadku przeciwnym – nie ma podstaw do jej odrzucenia. W przypadku (b) – przedział krytyczny jest lewostronny. (dla 2 <kryt2 odrzucamy H0), W przypadku (c) – przedział krytyczny jest obustronny.")
38
Próby duże Dla liczebności próby n > 30 możemy przekształcić wyznaczoną w poprzednim punkcie statystykę chi-kwadrat w statystykę z o rozkładzie normalnym obliczając: W powyższym wzorze χ2 oraz v = n − 1 oznaczają statystykę chi-kwadrat i jej liczbę stopni swobody wyznaczone tak, jak w poprzednim paragrafie (dla prób małych). Wartości krytyczne znajdujemy z tablic dystrybuanty rozkładu normalnego.Jeżeli Fn(z) jest dystrybuantą standardowego rozkładu normalnego, a Fn-1(z) - funkcją odwrotną do dystrybuanty, natomiast α - założonym poziomem istotności – to odczytujemy: dla przypadku (a) w przypadku (b) w przypadku (c) mamy 2 wartości graniczne: oraz zkryty2 = − zkryt1
. Wartości krytyczne znajdujemy z tablic dystrybuanty rozkładu normalnego.Jeżeli Fn(z) jest dystrybuantą standardowego rozkładu normalnego, a Fn-1(z) - funkcją odwrotną do dystrybuanty, natomiast α - założonym poziomem istotności – to odczytujemy: dla przypadku (a) w przypadku (b) w przypadku (c) mamy 2 wartości graniczne: oraz zkryty2 = − zkryt1.")
39
Inne testy wariancji Testy dla dwóch wariancji
Testy dla dwóch prób niezależnych Testy dla dwóch prób zależnych Testy dla wielu wariancji

40
Testy nieparametryczne dla współczynnika korelacji
Formułujemy zerowa hipotezę Ho: „Brak korelacji pomiędzy zmienną X a zmienną Y: Ustalamy poziom istotności : 1- Hipotezę testujemy przy pomocy testu studenta o N-2 stopniach swobody (N jest długością wektorów X i Y) Wyznaczamy wartość:
 Wyznaczamy wartość:")
41
Kolejno obliczamy wartości krytyczną testu t
Jeśli t>t to hipotezę zerową odrzucamy w przeciwnym razie przyjmujemy. Alternatywnie możemy zdefiniować krytyczną wartość współczynnika korelacji (na podstawie ostatniego wzoru):
:")
42
Przykład Mamy zbiór danych meteorologicznych zawierający: temperaturę na stacji A ora na stacji B. Testujemy hipotezę, że obie wielkości nie są ze sobą skorelowane na poziomie istotności =0.05. Wykujemy to w 2 przypadkach gdy bierzemy pod uwagę jedynie 6 punktów pomiarowych (niebieskie kwadraty na wykresie) oraz gdy bierzemy wszystkie punkty (20) Przepadek 1. Obliczamy współ. korelacji: r=0.47 Obliczamy wartość krytyczną testu (dla N=6) studenta t=tinv(1-0.05/2,4). Następnie krytyczna wartość współ. korelacji rc=0.72. rc> r wiec hipotezę przyjmujemy.
 oraz gdy bierzemy wszystkie punkty (20) Przepadek 1. Obliczamy współ. korelacji: r=0.47. Obliczamy wartość krytyczną testu (dla N=6) studenta. t=tinv(1-0.05/2,4). Następnie krytyczna wartość współ. korelacji rc=0.72. rc> r wiec hipotezę przyjmujemy.")
43
Przepadek 2 (wszystkie punkty).
Obliczamy współ. korelacji: r=0.84 Obliczamy wartość krytyczną testu (dla N=20) studenta t =tinv(1-0.05/2,18). Następnie krytyczna wartość współ. korelacji rc =0.44. rc < r wiec hipotezę odrzucamy. Nie podstaw do wnioskowania, że dane są nie skorelowane!
 studenta. t =tinv(1-0.05/2,18). Następnie krytyczna wartość współ. korelacji rc =0.44. rc < r wiec hipotezę odrzucamy. Nie podstaw do wnioskowania, że dane są nie skorelowane!")
Podobne prezentacje
, gdzie X jest liczbą osób w rodzinie, a Y liczbą izb w mieszkaniu. Niech f.r.p. tej zmiennej.>")


















