Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Narzędzia wyszukiwawcze repozytoriów cyfrowych Piotr Gawrysiak Warszawa, 2009

2
Repozytoria informacji Współczesne repozytoria informacji to już przede wszystkim repozytoria cyfrowe Nie oznacza to bynajmniej, iż produkujemy mniej informacji na tradycyjnych jej nośnikach – zostaje ona jednak zagłuszona przez łatwo dostępną informację w postaci cyfrowej Wykładniczy wzrost globalnych zasobów informacji nazywany określany bywa 1,2 mianemkryzysu informacji czy wręcz eksplozji informacyjnej – czy słusznie? 1. Weinberg A.., Science, Government, and Information, Oak Ridge National Laboratory, USA, 1963 2. Lyman P., Varian R., How Much Information?, University of Berkeley, USA 2003 Światowa roczna produkcja informacji 2 Nośnik2002 TB Górna granica 2002 TB Dolna granica 1999 TB Górna granica 1999 TB Dolna granica Zmiana (górne granice oszacowania) Papierowy1,6343271,20024036% Światłoczuły420,25476,69431,69058,209-3% Magnetyczny5,187,1303,416,2302,779,7602,073,76087% Optyczny10351812928% Suma5,609,1213,416,2813,212,7312,132,23874.5%
 Papierowy1, , % Światłoczuły420,25476,69431,69058,209-3% Magnetyczny5,187,1303,416,2302,779,7602,073,76087% Optyczny % Suma5,609,1213,416,2813,212,7312,132, %.")
3
Narzędzia wyszukiwawcze Mechanizm wyszukiwawczy zapewniać może w szczególności: a) Odszukanie konkretnego obiektu (np. książki) – gdy znana jest jego dokładna charakterystyka (np. autor, tytuł, wydawca, rok wydania); b) Odszukanie obiektów, zawierających żądaną przez użytkownika biblioteki informację – np. książek o pewnej tematyce, lub też akapitów traktujących o zadanym temacie; c) Agregacja informacji zapisanej w przechowywanych obiektach w celu udzielenia odpowiedzi na pytanie użytkownika – np. podanie definicji terminu. Systemy, jakie możemy stworzyć dla bibliotek klasycznych, mogą posiadać funkcjonalność określoną powyżej w punktach a) i - do pewnego stopnia - b). Wynika to bezpośrednio ze specyfiki repozytorium fizycznego, uniemożliwiającego bezpośredni dostęp do zawartości przechowywanych obiektów. Co jest zaś możliwe w przypadku repozytoriów cyfrowych? Jakiekolwiek repozytorium informacji (np. biblioteka) jest użyteczne jedynie gdy istnieje mechanizm organizacji i przeszukiwania jego zasobów
 – gdy znana jest jego dokładna charakterystyka (np. autor, tytuł, wydawca, rok wydania); b) Odszukanie obiektów, zawierających żądaną przez użytkownika biblioteki informację – np. książek o pewnej tematyce, lub też akapitów traktujących o zadanym temacie; c) Agregacja informacji zapisanej w przechowywanych obiektach w celu udzielenia odpowiedzi na pytanie użytkownika – np. podanie definicji terminu. Systemy, jakie możemy stworzyć dla bibliotek klasycznych, mogą posiadać funkcjonalność określoną powyżej w punktach a) i - do pewnego stopnia - b). Wynika to bezpośrednio ze specyfiki repozytorium fizycznego, uniemożliwiającego bezpośredni dostęp do zawartości przechowywanych obiektów. Co jest zaś możliwe w przypadku repozytoriów cyfrowych. Jakiekolwiek repozytorium informacji (np. biblioteka) jest użyteczne jedynie gdy istnieje mechanizm organizacji i przeszukiwania jego zasobów.")
4
Repozytoria cyfrowe Czym jest repozytorium cyfrowe? Nie wystarcza tu jedynie samo przechowywanie informacji w postaci cyfrowej – niezbędna jest możliwość automatycznego przetwarzania i transmisji tej informacji – co współcześnie oznacza dostęp poprzez sieć Internet. Internet jest jednak nie tylko siecią transmisji danych pomiędzy bibliotekami cyfrowymi, a ich użytkownikami. Jego część (sieć WWW) to także repozytorium cyfrowe (oraz narzędzie kreacji treści typu digital born) Łatwość tworzenia i publikacji treści o atrakcyjnej formie graficznej, Sieciowość – możliwość łatwego i niekontrolowanego tworzenia odnośników do innych zasobów (inspirowana koncepcją Vannevara Busha memexu), Praktyczny brak kontroli nad zawartością powstającej sieci - zarówno organizacyjnej jak i merytorycznej oraz prawnej (anonimowość!), Łatwość kopiowania i przywłaszczania istniejącej już treści (tu mają także znaczenie kwestie prawne m.in. związane z tzw. otwartymi licencjami). Powyższe cechy łączy ze sobą brak kontroli – sieć WWW to swego rodzaju cyfrowa anarchia! Nb. warto porównać WWW z innym projektem inspirowanym ideą Vannevara Busha memexu – tj. systemem Teda Nelsona XANADU tworzonym od 1960 roku 1. 1. Tuomi I., The Vision of Xanadu w Networks of Innovation, Oxford University Press, 2002, s. 48-50
 to także repozytorium cyfrowe (oraz narzędzie kreacji treści typu digital born) Łatwość tworzenia i publikacji treści o atrakcyjnej formie graficznej, Sieciowość – możliwość łatwego i niekontrolowanego tworzenia odnośników do innych zasobów (inspirowana koncepcją Vannevara Busha memexu), Praktyczny brak kontroli nad zawartością powstającej sieci - zarówno organizacyjnej jak i merytorycznej oraz prawnej (anonimowość!), Łatwość kopiowania i przywłaszczania istniejącej już treści (tu mają także znaczenie kwestie prawne m.in. związane z tzw. otwartymi licencjami). Powyższe cechy łączy ze sobą brak kontroli – sieć WWW to swego rodzaju cyfrowa anarchia. Nb. warto porównać WWW z innym projektem inspirowanym ideą Vannevara Busha memexu – tj. systemem Teda Nelsona XANADU tworzonym od 1960 roku Tuomi I., The Vision of Xanadu w Networks of Innovation, Oxford University Press, 2002, s")
5
Pierwsze systemy wyszukiwawcze WWW Wczesny Internet traktowany jest przez większość użytkowników jako duża (cyfrowa oczywiście) biblioteka 1 Jak duża? Jest to trudne do określenia, jednak można szacować iż wielkość sieci WWW wynosi obecnie kilkanaście miliardów stron Pierwsze narzędzia wyszukiwawcze stanowią zatem odpowiedniki narzędzi klasycznych bibliotek cyfrowych: Systemy klasyfikacji – w postaci ręcznie tworzonych katalogów, takich jak projekt DMOZ, czy też wczesne portale internetowe (np. Yahoo, Wirtualna Polska), Wykorzystanie metadanych (odpowiednie nagłówki stron WWW – tzw. tag META), Systemy wyszukiwawcze i języki zapytań (np. W3QL, WebSQL) traktujące sieć jako klasyczną bazę danych o dużym rozmiarze. … i okazują się nieefektywne. 1. Dokładniej zaś kolekcja powiązanych ze sobą bibliotek – patrz koncepcje autostrady informacyjnej np. Gates B., The Road Ahead, Penguin Books, 1996 2. Gulli A. et al.., The Indexable Web is more than 11.5 billion pages In WWW '05 conf. proc., ACM, New York, USA, s. 902-903
, Wykorzystanie metadanych (odpowiednie nagłówki stron WWW – tzw. tag META), Systemy wyszukiwawcze i języki zapytań (np. W3QL, WebSQL) traktujące sieć jako klasyczną bazę danych o dużym rozmiarze. … i okazują się nieefektywne. 1. Dokładniej zaś kolekcja powiązanych ze sobą bibliotek – patrz koncepcje autostrady informacyjnej np. Gates B., The Road Ahead, Penguin Books, Gulli A. et al.., The Indexable Web is more than 11.5 billion pages In WWW 05 conf. proc., ACM, New York, USA, s")
6
Pierwsze systemy wyszukiwawcze WWW Potrzebne jest zatem inne podejście, nie oparte o dane kontrolowane – wyszukiwarka internetowa Różnice w stosunku do narzędzi klasycznych bibliotek cyfrowych: analiza pełnotekstowa dokumentów (z racji braku metadanych), automatyczne zbieranie dokumentów (z racji braku kontrolowanego repozytorium) Elementy systemu 1 : Robot sieciowy (tzw. pająk, ang. web crawler) – wykorzystanie hiperpołączeń Indekser – budujący zbiór odwrócony Mechanizm wykonywania zapytań Wielkość sieci powoduje, iż budowa takiego systemu stanowi wyzwanie technologiczne Początkowo najpopularniejsze systemy, posiadające największy indeks (AltaVista – Digital Equipment Corporation) - 1996 Systemy te działają, jednak jakość wyszukiwania (w szczególności precyzja) okazuje się bardzo niezadowalająca Ważne dla użytkowników informacje okazują się bowiem trudne do odnalezienia w śmietniku Internetu 2 1. Brin, S. and Page, L. Anatomy of a large scale hypertextual search engine, w WWW7 Conf. Proceedings, Brisbane, Australia, 1998 2. Por. np. Oramus M., Mózg w malinach, Polityka, nr 2243, kwiecień 2000 Kosztowne obliczeniowo
 – wykorzystanie hiperpołączeń Indekser – budujący zbiór odwrócony Mechanizm wykonywania zapytań Wielkość sieci powoduje, iż budowa takiego systemu stanowi wyzwanie technologiczne Początkowo najpopularniejsze systemy, posiadające największy indeks (AltaVista – Digital Equipment Corporation) Systemy te działają, jednak jakość wyszukiwania (w szczególności precyzja) okazuje się bardzo niezadowalająca Ważne dla użytkowników informacje okazują się bowiem trudne do odnalezienia w śmietniku Internetu 2 1. Brin, S. and Page, L. Anatomy of a large scale hypertextual search engine, w WWW7 Conf. Proceedings, Brisbane, Australia, Por. np. Oramus M., Mózg w malinach, Polityka, nr 2243, kwiecień 2000 Kosztowne obliczeniowo.")
7
Systemy skuteczne Rozwiązaniem problemu niewielkiej precyzji okazały się metody oszacowania jakości stron – wykorzystujące specyficzne cechy sieci WWW (takie jak znaczna redundancja informacji, obecność hiperpołączeń, dane behawioralne) Podejście (miara PageRank) podobne do metod bibliometrycznych – istotność źródła jest bezpośrednio związana z liczbą cytowań (tu – wskazujących na stronę hiperpołączeń) i jakością cytujących źródeł PageRank nie jest oczywiście miarą idealną – ale jest metodą skuteczną Dysponujemy także innymi metodami analizy treści zawartej w sieci WWW – nie tak spektakularnymi, lecz także skutecznymi: Rozwiązania maszynowe (automatyczna klasyfikacja i grupowanie dokumentów, maszynowe budowanie ontologii, wizualizacja, …) Rozwiązania społecznościowe (collaborative filtering, tagging, reblogging, …) Wszystkie wymagają otwartości zasobów cyfrowych które analizują
 Podejście (miara PageRank) podobne do metod bibliometrycznych – istotność źródła jest bezpośrednio związana z liczbą cytowań (tu – wskazujących na stronę hiperpołączeń) i jakością cytujących źródeł PageRank nie jest oczywiście miarą idealną – ale jest metodą skuteczną Dysponujemy także innymi metodami analizy treści zawartej w sieci WWW – nie tak spektakularnymi, lecz także skutecznymi: Rozwiązania maszynowe (automatyczna klasyfikacja i grupowanie dokumentów, maszynowe budowanie ontologii, wizualizacja, …) Rozwiązania społecznościowe (collaborative filtering, tagging, reblogging, …) Wszystkie wymagają otwartości zasobów cyfrowych które analizują")
8
Narzędzia społeczeństwa informacyjnego? Internet przestaje być śmietnikiem a staje się repozytorium wiedzy dzięki możliwości skutecznego odnajdywania tejże wiedzy… …ale… jest to repozytorium, którego właściwie nie można przeglądać, można je jedynie przeszukiwać – to zaś wymaga aktywnego sformułowania zapytania. Treść cyfrowa konkuruje o swego potencjalnego odbiorcę poprzez jakość, a raczej odnajdywalność – ta zaś staje się dostępna także dla elementów trudnych do odszukania (czy wręcz umieszczenia!) w klasycznych bibliotekach. Zmiana sposobu korzystania z repozytoriów wiedzy – zamiast najpierw wybierać dostawcę wiedzy (np. agencję prasową, bibliotekę itd.) korzystać poczynamy z usług pośrednika, którym stają się narzędzia wyszukiwawcze. Coraz łatwiej łączyć okruchy wiedzy pochodzące z różnych źródeł.
 w klasycznych bibliotekach. Zmiana sposobu korzystania z repozytoriów wiedzy – zamiast najpierw wybierać dostawcę wiedzy (np. agencję prasową, bibliotekę itd.) korzystać poczynamy z usług pośrednika, którym stają się narzędzia wyszukiwawcze. Coraz łatwiej łączyć okruchy wiedzy pochodzące z różnych źródeł..")
9
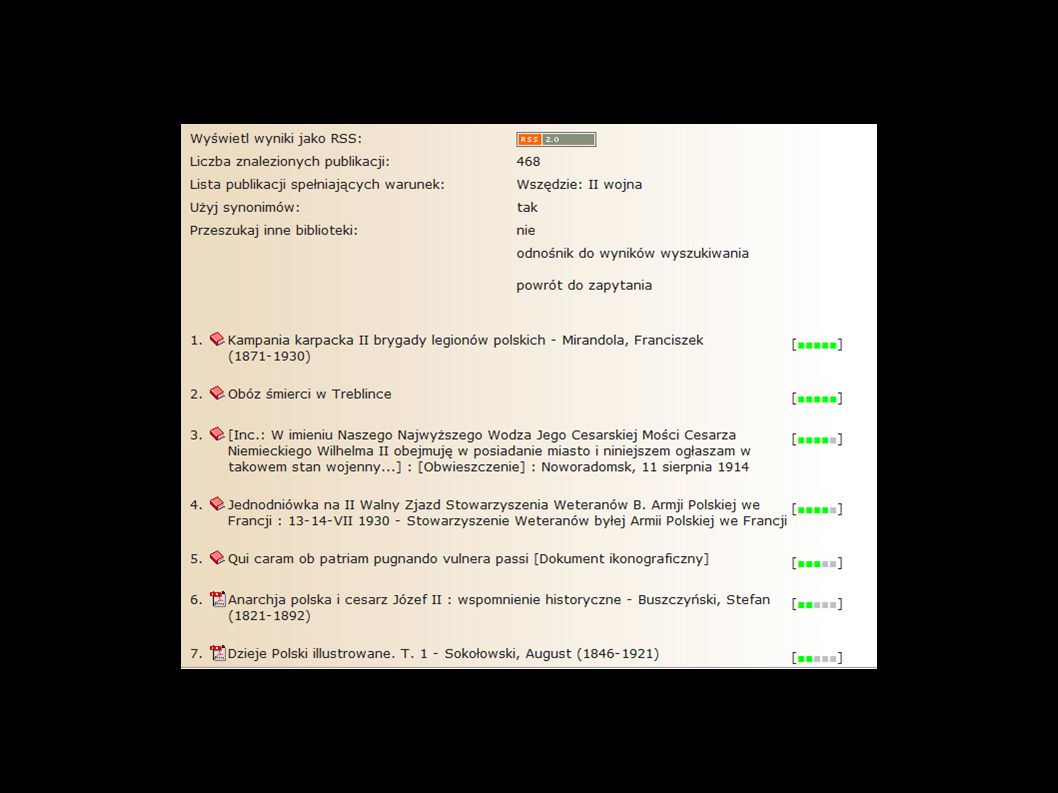
Biblioteki cyfrowe (versus Wikipedia) Powstaje coraz więcej bibliotek cyfrowych, zaś nakłady na cyfryzację zasobów bibliotecznych rosną – lecz ich popularność pozostaje niewielka. Biblioteki cyfrowe nie potrafią sprzedać swoich zasobów użytkownikom, są bowiem niewygodne i nieefektywne – i poprawienie tej sytuacji nie będzie zadaniem prostym: Repozytoria bibliotek nie posiadają informacji o połączeniach semantycznych pomiędzy zasobami, która umożliwiłaby zastosowanie efektywnych algorytmów wyszukiwawczych, takich jak PageRank, Restrykcyjne często ograniczenia IPR uniemożliwiają bezpośredni dostęp do zasobów dla wszystkich użytkowników (zjawisko cyfrowego wykluczenia dokumentów), Format przechowywania cyfrowych danych uniemożliwia tworzenie bezpośrednich odnośników do treści zasobów (ang. deep linking), Siłą bibliotek mogłyby być wysokiej klasy metadane będące wynikiem pracy katalogerów – jednak ich użyteczność, szczególnie dla użytkowników przyzwyczajonych do jakości i specyfiki działania wyszukiwarek sieciowych, jest znikoma 1. 1. Gawrysiak P., Cyfrowe biblioteki a wyszukiwanie informacji, w Przegląd biblioteczny, 4/2008, s.111-118
, Format przechowywania cyfrowych danych uniemożliwia tworzenie bezpośrednich odnośników do treści zasobów (ang. deep linking), Siłą bibliotek mogłyby być wysokiej klasy metadane będące wynikiem pracy katalogerów – jednak ich użyteczność, szczególnie dla użytkowników przyzwyczajonych do jakości i specyfiki działania wyszukiwarek sieciowych, jest znikoma Gawrysiak P., Cyfrowe biblioteki a wyszukiwanie informacji, w Przegląd biblioteczny, 4/2008, s")
10
Biblioteki cyfrowe (versus Wikipedia) Serwisy takie jak Wikipedia czy też nawet Google Books są obecnie po prostu znacznie bardziej bardziej wygodne – i przez to bardziej popularne, Problem nie zniknie sam – zaś tworzenie metabibliotek cyfrowych (harvesting, OAI) powoduje, iż biblioteki cyfrowe zaczynają upodabniać się, pod względem objętości ale i jakości zasobów informacyjnych – do wczesnej sieci WWW, Czy rozwiązaniem byłoby pełne otwarcie zawartości bibliotek cyfrowych – i umożliwienie przeszukiwania przechowywanych tamże zasobów przez uniwersalne systemy wyszukiwawcze takie jak Google Search? Co zatem z profesją bibliotekarza – katalogera? Być może przeciwnie – należy tworzyć skomplikowane mechanizmy katalogowania, wyposażone w narzędzia sztucznej inteligencji, które przekształcą biblioteki cyfrowe z repozytoriów informacji w źródła (kontrolowanej) wiedzy (curated knowledge) – przykład: WolframAlpha 1. Gawrysiak P., Cyfrowe biblioteki a wyszukiwanie informacji, w Przegląd biblioteczny, 4/2008, s.111-118
 wiedzy (curated knowledge) – przykład: WolframAlpha 1. Gawrysiak P., Cyfrowe biblioteki a wyszukiwanie informacji, w Przegląd biblioteczny, 4/2008, s")
11
Wyzwania Problemy techniczne - dostęp do energii elektrycznej oraz możliwości chłodzenia urządzeń elektronicznych mogą ograniczyć w przyszłości wzrost zarówno repozytoriów cyfrowych jak i ich narzędzi wyszukiwawczych, Grey web – nie wszystkie rodzaje treści cyfrowych są łatwe, czy wręcz możliwe, do indeksowania, Transparentność systemów wyszukiwawczych – czy możemy wierzyć firmom takim jak Google? Nowe rodzaje treści – Internet coraz częściej poczyna być wykorzystywany nie tylko jako źródło wiedzy, lecz także medium komunikacji błyskawicznej. Przeszukiwanie takich wiadomości (np. z serwisów twitter) wymaga specyficznych algorytmów i metod – innych niż te używane przez współczesne wyszukiwarki sieciowe, Nowe metody dostępu – coraz częściej także wykorzystujemy zasoby sieci WWW przy użyciu urządzeń mobilnych – to zaś wymaga jeszcze (sic!) szybszych i prostszych narzędzi wyszukiwawczych Nowe problemy wyszukiwawcze – współczesny Internet to nie tylko baza wiedzy, to także globalny rynek, na którym poszukujemy także towarów i usług
 wymaga specyficznych algorytmów i metod – innych niż te używane przez współczesne wyszukiwarki sieciowe, Nowe metody dostępu – coraz częściej także wykorzystujemy zasoby sieci WWW przy użyciu urządzeń mobilnych – to zaś wymaga jeszcze (sic!) szybszych i prostszych narzędzi wyszukiwawczych Nowe problemy wyszukiwawcze – współczesny Internet to nie tylko baza wiedzy, to także globalny rynek, na którym poszukujemy także towarów i usług.")
12
Zakończenie

Podobne prezentacje














 to rodzaj strony internetowej, na której autor umieszcza datowane wpisy, wyświetlane kolejno,>")
 Wyszukiwarki użytkownicy końcowi -dostarczanie i prezentacja wyników wyszukiwań -usługi dodatkowe (katalog stron, najpopularniejsze.>")




