Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Wykrywanie wzorców częstych
Anna Seweryn Opiekun: dr inż. Grzegorz Protaziuk

2
Spis treści: Eksploracja danych Podstawowe definicje Algorytm Apriori
Ulepszenia Algorytmu Apriori Algorytm dla grafów skierowanych ważonych Implementacja algorytmu Testy wydajnościowe Zastosowanie algorytmu Podsumowanie

3
Eksploracja danych Pojęcie eksploracji danych potocznie rozumiane jest jako odkrywanie wiedzy w bazach danych, integruje ono kilka dziedzin takich jak: statystyka, systemy baz danych, sztuczna inteligencja, optymalizacja, obliczenia równoległe. Problemy: Magazynowanie danych Dostęp do danych Analizowanie w rozsądnym przedziale czasowym Niepoprawne wartości, zanieczyszczenia, zakłamane dane Zależności i podsumowania będące wynikami eksploracji danych zwane są modelami lub wzorcami

4
Podstawowe pojęcia Częstość fr(Y) zadanego wzorca zbioru elementów Y jest liczba przypadków w danych spełniających Y. Wsparcie częstość wystąpień zbioru X lub Y. Dokładność (ufność) zadanej reguły to frakcja (część wszystkich) wierszy spełniających wśród tych wierszy, które spełniają Y (prawdopodobieństwo warunkowe P(Y|X). Zadanie znajdowania wzorców częstych: mając dany próg częstościowy s znajdujemy wszystkie wzorce zbiorów elementów, które są częste i ich częstości. Jeśli próg częstości jest niski może być wiele zbiorów częstych.
 zadanej reguły to frakcja (część wszystkich) wierszy spełniających wśród tych wierszy, które spełniają Y (prawdopodobieństwo warunkowe P(Y|X). Zadanie znajdowania wzorców częstych: mając dany próg częstościowy s znajdujemy wszystkie wzorce zbiorów elementów, które są częste i ich częstości. Jeśli próg częstości jest niski może być wiele zbiorów częstych.")
5
Metoda trywialna wyszukiwania wzorców częstych
Metodą trywialną jest branie po kolei każdego wzorca i sprawdzanie czy występuje on w danych i czy jest w jakimś sensie znaczący. Jeśli liczba możliwych wzorców jest mała, to wówczas można tę metodę zastosować, ale z reguły jest ona całkowicie niewykonalna.

6
Algorytm Apriori Algorytm Apriori
znalezienie wszystkich wzorców częstych zaczynamy od znalezienia wszystkich zbiorów częstych składających się z 1 zmiennej. Zakładając, że już je znamy, budujemy zbiory kandydujące rozmiaru 2: zbiory {A,B} takie, że {A} jest częsty i {B} jest częsty. Po zbudowaniu przeglądamy je i stwierdzamy, które są częste. Budujemy z nich zbiory kandydujące rozmiaru 3, których częstość jest następnie obliczana z danych i tak dalej. Ograniczenia: struktura danych jest ograniczona do elementów zbioru.

7
Ulepszenia algorytmu Apriori
Możliwość stosowania algorytmu Apriori dla struktur grafowych po prostym przetworzeniu danych. Wada: utrata ważnych informacji o strukturze, wierzchołki i etykiety muszą być unikalne Zastosowanie zasady MDL przycinania drzew Wada: strategia wyszukiwań chciwa i heurystyczna – pomijanie znaczących związków. Duża złożoność obliczeniowa

8
Ulepszenia algorytmu Apriori cd
Równe rozmieszczenie sekwencji – sekwencje epizodów. Mając dany zbiór E typów zdarzeń, sekwencję zdarzenia s w E, zbiór epizodów EE, okno szerokości win i próg częstości min_fr, następujący algorytm oblicza zbiór epizodów częstych FE(s, win, min_fr): Wada: ważna kolejność wstawiania wierzchołków Zastosowanie podgrafu jako cechy, by sklasyfikować w grafach dane Wada: ograniczenia co do ilości węzłów, większa ilość prowadzi do wykładniczej eksplozji obliczeniowej czasu
: Wada: ważna kolejność wstawiania wierzchołków. Zastosowanie podgrafu jako cechy, by sklasyfikować w grafach dane. Wada: ograniczenia co do ilości węzłów, większa ilość prowadzi do wykładniczej eksplozji obliczeniowej czasu.")
9
System: WARMR Pierwszy algorytm dla wyszukiwania danych stosujący ILP (Indukcyjne Programowanie Logiki) ILP ma ograniczenia ilościowe By zmniejszyć złożoność obliczeniową stosuje się heurystyki by przyciąć badaną przestrzeń Wzorce: relacyjne reguły asocjacyjne budowane na podstawie częstych zapytań do baz wiedzy w Prologu wsparcie s zapytania to procent liczby możliwych podstawień pod zmienne wyróżnione dla danego zapytania w stosunku do liczby wszystkich możliwych podstawień pod zmienne wyróżnione

10
System: FARMAR 2001 Słabszy warunek równoważności niż w WARMR, by przyspieszyć wyszukiwanie wzorców częstych Bazuje na strukturze TRIE Ścieżka od korzenia do liścia reprezentuje całe zapytania

11
Inokuchi, Washio, Motoda 2003 - algorytm
Proces przerobienia ogólnego grafu danych transakcji do grafu etykietowanych węzłów z zapętleniem macierz sąsiedztwa – nie unikalna kodowanie macierzy – zmniejszenie zapotrzebowania pamięci zaufanie i częstość Kanoniczna postać

12
Proces przerobienia ogólnego grafu danych transakcji do grafu etykietowanych węzłów z zapętleniem
Graf reprezentowany jako macierz sąsiedztwa Jeśli graf ma etykietowane związki to związki stają się węzłami i węzły stają się związkami: informacja link() –etykieta może zostać usunięta i otrzymujemy zredukowany graf, gdzie oryginalna informacja o związku i węźle zostaje zachowana:
 –etykieta może zostać usunięta i otrzymujemy zredukowany graf, gdzie oryginalna informacja o związku i węźle zostaje zachowana:")
13
Transformacja macierzy sąsiedztwa

14
kiedy jest pętla ważona tak jak w N1, zmienia się etykieta węzła na N’1, odtąd macierz wygląda tak:
Fakt ten pozwala na zapisywanie różnych etykiet dla węzłów, które mają wiele pętli. Zapisywanie etykiet węzłów odbywa się wg zasady:

15
Kody macierzy – graf nieskierowany
Dla wydajności algorytmu definiujemy kody macierzy sąsiedztwa. Dla grafu nie skierowanego otrzymujemy kody przez skanowanie wyższych trójkątnych elementów. Powstaje kod 01 według poniższego schematu: Dla macierzy otrzymujemy kod: code(Xk)=
=")
16
Kody macierzy – graf skierowany
Dla grafu skierowanego jeżeli oba elementy (i,j) oraz (j,i) są zerami to dla kodu wstawiamy 0, natomiast gdy: element (i,j) ma wartość 1 a element ma wartość 0 to wstawiamy 1. w przypadku gdy element (i,j) ma wartość 0 a (j,i) wartość 1 to w kod w stawiamy 2, w końcu, gdy element (i,j) i (j,i) mają wartości 1 to w kodzie wstawiamy 3. Wzór: Dla macierzy kod jest następujący: code(Xk)=
 oraz (j,i) są zerami to dla kodu wstawiamy 0, natomiast gdy: element (i,j) ma wartość 1 a element ma wartość 0 to wstawiamy 1. w przypadku gdy element (i,j) ma wartość 0 a (j,i) wartość 1 to w kod w stawiamy 2, w końcu, gdy element (i,j) i (j,i) mają wartości 1 to w kodzie wstawiamy 3. Wzór: Dla macierzy kod jest następujący: code(Xk)=")
17
Algorytm wyszukiwania wzorców częstych
Generowanie kandydata Xk i Yk – macierze sąsiedztwa dwóch podrafów G(Xk) i G(Yk). Jeśli dwa częste podgrafy mają równe elementy z wyjątkiem k-tej kolumny i k-tego wiersza to wtedy łączy się i tworzy się podgraf Zk+1:
 i G(Yk). Jeśli dwa częste podgrafy mają równe elementy z wyjątkiem k-tej kolumny i k-tego wiersza to wtedy łączy się i tworzy się podgraf Zk+1:")
18
Graf nieskierowany grafu nie skierowanego rozważane są 2 przypadki:
(1)jest związek między k-węzłem i k+1-węzłem grafu G(Zk+1) oraz (2) nie ma żadnego związku między nimi. Odpowiednio tym dwóm przypadkom generujemy 2 macierze sąsiedztwa wstawiając odpowiednio 0 lub 1 dla (k, k+1)-elementu oraz (k+1, k)-elementu.
jest związek między k-węzłem i k+1-węzłem grafu G(Zk+1) oraz. (2) nie ma żadnego związku między nimi. Odpowiednio tym dwóm przypadkom generujemy 2 macierze sąsiedztwa wstawiając odpowiednio 0 lub 1 dla (k, k+1)-elementu oraz (k+1, k)-elementu.")
19
Graf skierowany W przypadku skierowanego grafu możliwe są 4 przypadki:
(1) skierowany związek z węzła k do k+1 grafu G(Zk+1) oraz (2) skierowany związek od k+1 do k oraz (3)są dwukierunkowe związki między nimi oraz (4) nie ma żadnych związków między nimi. Odpowiednio 4 różne macierze graniczne są generowane. Nazywamy odpowiednio Xk i Yk "pierwsza macierz” i "druga macierz” by wygenerować kolejno Zk + 1
 skierowany związek z węzła k do k+1 grafu G(Zk+1) oraz. (2) skierowany związek od k+1 do k oraz. (3)są dwukierunkowe związki między nimi oraz. (4) nie ma żadnych związków między nimi. Odpowiednio 4 różne macierze graniczne są generowane. Nazywamy odpowiednio Xk i Yk pierwsza macierz i druga macierz by wygenerować kolejno Zk + 1.")
20
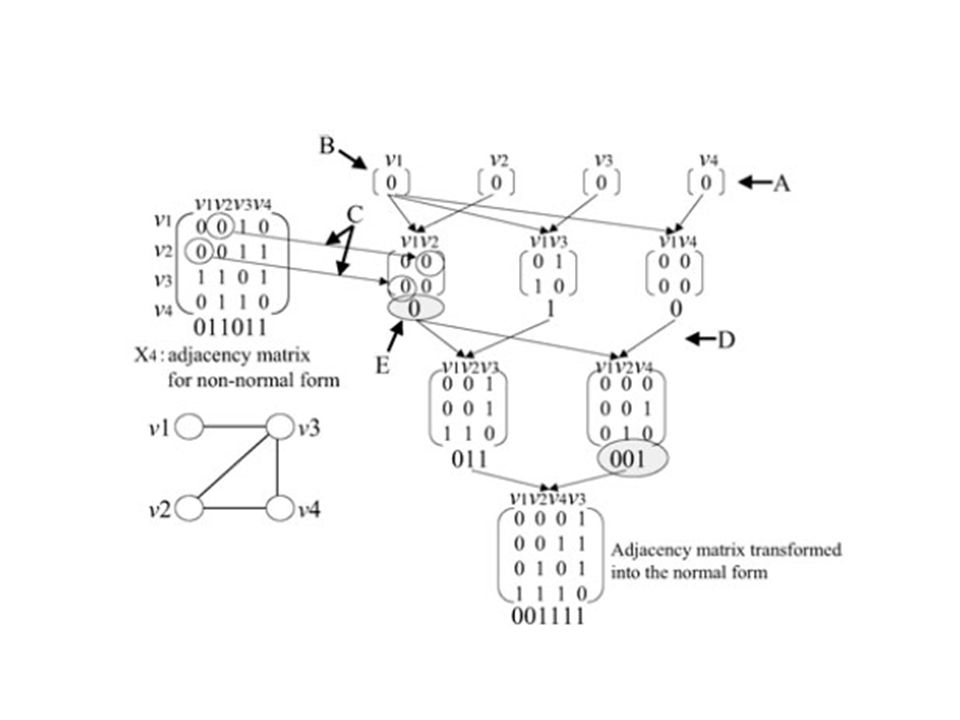
Kandydat częsty k+1 elementowy graf G(Zk+1) jest rozważany na kandydata częstego wyszukanego podgrafu gdy macierz sąsiedztwa wszystkich wywołanych k-podgrafów G(Zk+1) jest potwierdzona aby reprezentować częsty podgraf. Ponieważ nasz algorytm wygeneruje tylko macierze sąsiedztwa normalnej formy. Wcześniejsza k macierz sąsiedztwa jest generowana przez usunięcie i-tego węzła, i-tej kolumny i wiersza prowadzi to do powstanie nie normalnej postaci macierzy sąsiedztwa. Macierz nienormalnej formy jest przekształcana do normalnej wg schematu:
 jest rozważany na kandydata częstego wyszukanego podgrafu gdy macierz sąsiedztwa wszystkich wywołanych k-podgrafów G(Zk+1) jest potwierdzona aby reprezentować częsty podgraf. Ponieważ nasz algorytm wygeneruje tylko macierze sąsiedztwa normalnej formy. Wcześniejsza k macierz sąsiedztwa jest generowana przez usunięcie i-tego węzła, i-tej kolumny i wiersza prowadzi to do powstanie nie normalnej postaci macierzy sąsiedztwa. Macierz nienormalnej formy jest przekształcana do normalnej wg schematu:")
22
Kandydat częsty cd Gdy wyprowadzimy wszystkich kandydatów częstych ich wartość wsparcia jest wyliczana przez skanowanie całej bazy danych. Jednakże różne normalne macierze sąsiedztwa mogą reprezentować inne grafy. Aby poprawnie policzyć wsparcie musimy sprowadzić macierz do postaci kanonicznej. K jest wielkością grafu G i T(G)-{Xk | Xk jest normalną formą macierzy G przystającą do G(Xk)}. Wtedy kanoniczna postać CK grafu G ma postać kanoniczna forma macierzy Ck jest otrzymywana przez permutacje wierszy i kolumn normalnej formy macierzy Xk. Permutacje są zrobione przez operację
-{Xk | Xk jest normalną formą macierzy G przystającą do G(Xk)}. Wtedy kanoniczna postać CK grafu G ma postać. kanoniczna forma macierzy Ck jest otrzymywana przez permutacje wierszy i kolumn normalnej formy macierzy Xk. Permutacje są zrobione przez operację.")
23
Wyliczenie częstości

24
Implementacja Struktura drzewa jest często stosowaną strukturą danych do przeszukiwań. Przeszukiwania zaczyna się od korzenia i schodzi się niżej. Poniżej struktura drzewa nieskierowanego o dwóch etykietach N1 I N2. Punkt rozgałęzienia odpowiada normalnej formie macierzy. Kolejność symbolu składająca się z literowego (powyższy) i liczebnik (poniżej) w każdym pokazie punktu kolejno etykieta węzła i kod macierzy sąsiedztwa. Głębokość struktury Trie odpowiada wielkości wykresów i źródłowa macierz każdej macierzy w strukturze Trie jest pierwszą macierzą, by wygenerować macierz.
 i liczebnik (poniżej) w każdym pokazie punktu kolejno etykieta węzła i kod macierzy sąsiedztwa. Głębokość struktury Trie odpowiada wielkości wykresów i źródłowa macierz każdej macierzy w strukturze Trie jest pierwszą macierzą, by wygenerować macierz.")
25
Testy wydajnościowe 1/5 Jak zmienia się czas kiedy zmieniamy ilość transakcji

26
Testy wydajnościowe 2/5 Jak zmienia się czas kiedy zmieniamy średnią wielkość transakcji

27
Testy wydajnościowe 3/5 Jak zmienia się czas kiedy zmieniamy liczbę etykiet węzła

28
Testy wydajnościowe 4/5 Jak zmienia się czas kiedy zmieniamy minimalne wsparcie

29
Testy wydajnościowe 5/5 Jak zmienia się czas kiedy zmieniamy istnienie związków

30
Zastosowanie Analiza sieci Web (web browning analysis)
liczba wpisów url: 25000 wielkość pliku ok. 400MB około 8700-adresów i powiązań Średni czas trwania dostępu do strony przez użytkowników: 5minut zmiana pliku testowego do struktury macierz doprowadziła do powiększenia pliku do 800MB liczba transakcji wyniosła 50666 przeciętna wielkość jednej transakcji to 118 liczba etykiet węzła 8566 każda etykieta była zastąpiona przez krótki symbol indeksu upakowanie tak danych do 79MB dla minsup=15% liczba częstych wzorców wyniosła 1898 i rozmiar maksymalny transakcji to 7 czas 52.3 sekundy

31
3 przykłady wykrytych wzorców:

32
Zastosowanie Analiza substancji chemicznej
Eksperymenty na toksyczność substancji chemicznej w mieszaninie Zadanie: znaleźć czynniki rakotwórcze Uniwersytet Oxford do odnajdywania substancji rakotwórczej w substancjach

33
Podsumowanie Powyższy algorytm świetnie sobie radzi ze strukturą grafu skierowanego jak i niekierowanego, graf może mieć wiele etykietowanych węzłów oraz może posiadać pętle. Może być stosowany w praktyce do wyszukiwania częstych zachowań użytkowników WWW jak również do analizy substancji chemicznych – badanie toksyczności substancji chemicznej- znajdywanie struktury typowej dla czynnika rakotwórczego

34
Dziękuję za uwagę!

Podobne prezentacje






 < IR(G)>")











![Macierz incydencji Macierzą incydencji grafu skierowanego D = (V, A), gdzie V = {1, ..., n} oraz A = {a1, ..., am}, nazywamy macierz I(D) = [aij]i=1,...,n,](/1/425436/big_thumb.jpg "Macierz incydencji Macierzą incydencji grafu skierowanego D = (V, A), gdzie V = {1, ..., n} oraz A = {a1, ..., am}, nazywamy macierz I(D) = [aij]i=1,...,n,>")
