Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Systemy komputerowe wysokiej dostępności

2
Strategia tworzenia HAS
Określenie kosztów przestoju systemu informatycznego Określenie kosztów, które można można ponieść dla instalacji HAS Przydatne pojęcia: system bazowy (basic system) system failover (dwa systemy - jedno przeznaczenie) disaster recovery redundancja
 system failover (dwa systemy - jedno przeznaczenie) disaster recovery. redundancja.")
3
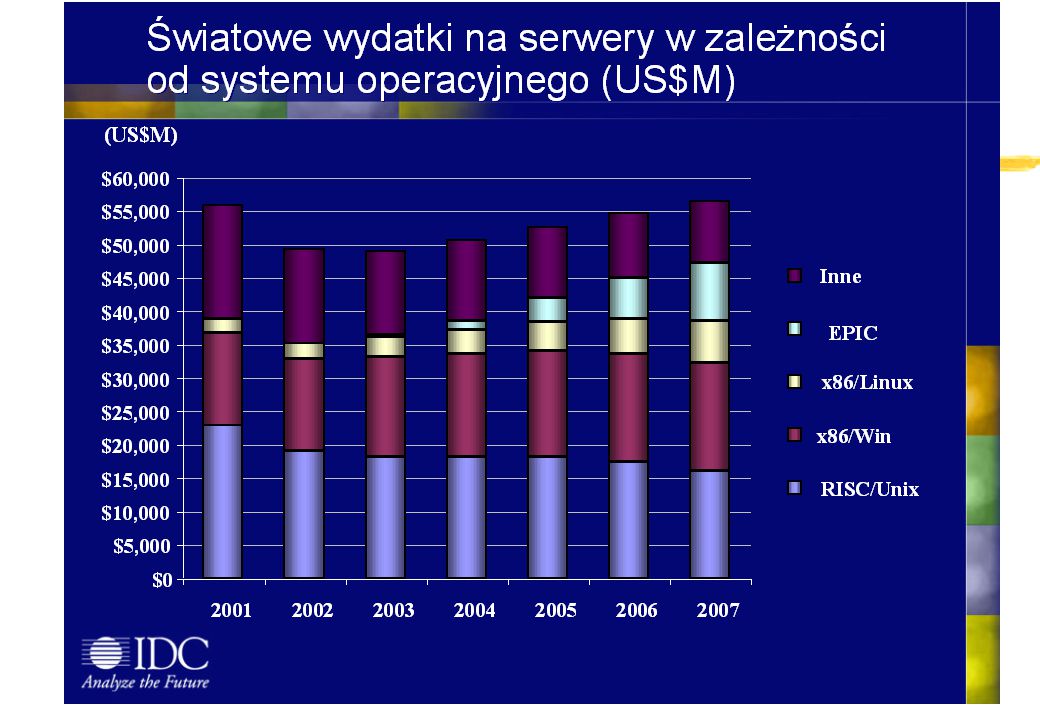
wybór platformy dostęp aplikacje bazy danych
common middleware, tools & integration wybór linux/win2000 platformy unix Konfiguracja serwera dostęp serwery na krawędzi internetu (examples: caching, firewall, security) Dlaczego storage jest tak istotny w dzisiejszym świecie, dlaczego z roku na rok mówi się o nim coraz więcej, dlaczego rośnie sprzedaż pamięci masowych? Najlepszą odpowiedź znajdziemy w opublikowanych swego czasu badaniach Uniwersytetu Berkeley. Naukowcy podsumowali ostatnie lat ludzkości liczbą 12m TB (czyli 12 exabajtów) danych stworzonych w tym okresie (poczynając od rysunków w jaskiniach). aplikacje bazy danych grup roboczych podstawy funkcjonowania rozwiązań korporacyjnych i korporacyjne -
 Dlaczego storage jest tak istotny w dzisiejszym świecie, dlaczego z roku na rok mówi się o nim coraz więcej, dlaczego rośnie sprzedaż pamięci masowych Najlepszą odpowiedź znajdziemy w opublikowanych swego czasu badaniach Uniwersytetu Berkeley. Naukowcy podsumowali ostatnie lat ludzkości liczbą 12m TB (czyli 12 exabajtów) danych stworzonych w tym okresie (poczynając od rysunków w jaskiniach). aplikacje. bazy danych. grup roboczych. podstawy. funkcjonowania. rozwiązań korporacyjnych. i korporacyjne. -")
4
obecne środowisko informatyczne nowe środowisko informatyczne
konsultacje serwis projekt obsługa szkolenia wdrożenie obecne środowisko informatyczne nowe środowisko informatyczne integracja strategia usług obsługa Następnie naukowcy oszacowali przewidywany przyrost ilości danych generowanych przez cywilizację w latach i stwierdzili, że w latach będzie ona istotnie większa niż w przeciągu poprzednich 40000lat. Przewidują również, że ilość danych w latach będzie ok. 4-krotnie większa od wygenerowanej przez poprzednie 40 tys. lat! Potwierdzeniem tych przewidywań może być rosnąca lawinowo sprzedaż pamięci masowych. Dla przykładu w roku 2000 HP sprzedało 28 petabajtów systemów dyskowych RAID przy 70% wzrostu w stosunku do poprzedniego roku. Ta liczba nie obejmuje m.in. systemów nie zabezpieczanych przez RAID (czyli np. zwykłych dysków w serwerach i PC-tach) oraz bardzo pojemnych systemów taśmowych. rozwój
 oraz bardzo pojemnych systemów taśmowych. rozwój.")
5
Taksonomia

6
Architektury równoległe

7
More detailed analysis

8
Address space

9
64-Bity IA-32 posiada 64-bit a nawet więcej 64-bitowa magistrala
64- bitowa jednostka zmiennoprzecinkowa 80-bitowe rejestry 64-bitowa jednostka stałoprzecinkowa 64/128-bity MMX™/XMM rejestry ale tylko 32-bity przestrzeni adresowej Procesor Itanium® ma 64-bitową przestrzeń adresowa ale to nie wszystko Jak wiele i jak szybko można przesłać dane jako: 32-bitowe paczki 64-bitowe paczki

10
64-bity przestrzeni adresowej
32-bity adresowania 1 cm wysokość CD 64-bity adresowania km odległość między ziemią a księżycem 64-bit 32-bit .

11
Shared space organization

12
Distributed memory

13
Virtually-shared physically distributed

14
Własności warstwy sieciowej

15
Podsumowanie Pamięć wspólna (współdzielona) - shared memory
łatwość programowania - trudno skalowalna Pamięć rozproszona - distributed memory trudno programować - łatwiejsza skalowalność Pamięć wirtualnie wspólna - virtual shared OpenMP SM DM DSM

16
HAC High Availability Clusters - podklasa Parallel SMP
Systemy sieciowe (rozproszone) versus klastry Klastry (systemy roproszone): przeznaczenie do obliczeń o wysokiej złożoności (rozproszenie aplikacji) wysokiej dostępności (realizacja lokalna aplikacji z możliwością migracji procesów) użytkowanie dedykowane sieciowe zasoby dyski dzielone dyski lokalne SMP z pamięcią dzieloną
 versus klastry. Klastry (systemy roproszone): przeznaczenie. do obliczeń o wysokiej złożoności (rozproszenie aplikacji) wysokiej dostępności (realizacja lokalna aplikacji z możliwością migracji procesów) użytkowanie. dedykowane. sieciowe. zasoby. dyski dzielone. dyski lokalne. SMP z pamięcią dzieloną.")
17
Odpowiedniość Odpowiedniość A - najbardziej D - najmniej

18
Zastosowania przemysłowe i komercyjne
obliczenia n-t przetwrzanie transakcyjne eksploracja danych architektury wieloprocesorowe atrybuty: największa wydajność komputera wydajność poszczególnego węzła (mała liczba węzłów) wysoka dostępność (duża liczba węzłów) ---> optymalizacja
 wysoka dostępność (duża liczba węzłów) ---> optymalizacja.")
19
Rozwój architektur bazodanowych
Przetwarzanie rozproszone rozdział mocy obliczeniowej decentralizacja zasobów

20
3-warstwowa architektura
Przetwarzanie rozproszone --transakcyjne zarządzanie regułami zarządzanie danymi logika aplikacji zarządzanie i logika prezentacji

21
Sieciowe Przeglądarki dowolny OS H/W Cieżki klient JavaOS H/W
Lekki klient (thin client) Java Computing Procesory-historia: Pico- Micro- Ultra-Java
 Java Computing. Procesory-historia: Pico- Micro- Ultra-Java.")
22
Przewidywana popularność systemów operacyjnych (Linux !!)
Inne: OS/400, Novell, Modesto WindowsNT, Windows2000 Win64 Unix: IBM AIX HP-UX Compaq Tru64UNIX SUN Solaris Linux Monterey Zadowolenie użytkowników: 1. IBM AIX Compaq True64UBIX 3. HP-UX SUN Solaris SGI IRIX

23
Udział procentowy ( dane z 2000 )
")
25
Czy Przyszłość to Itanium 2 ?
RISC / UNIX Migration to Intel® Itanium® 2 Processor IDC Forecast (Q1 04) Dell Hewlett Packard Hitachi NEC SGI Unisys IBM Bull Fujitsu Fujitsu Siemens Sun Power SPARC RISC & Itanium-based Server Volumes 500 400 300 200 SPARC 100 8 na 9 producentów procesorów RISC przechodzi na technologie Itanium 2 2003 2004 2005 2006 2007 2008 IPF Alpha PA-RISC Power SPARC
 Dell. Hewlett Packard. Hitachi. NEC. SGI. Unisys. IBM. Bull. Fujitsu. Fujitsu Siemens. Sun. Power. SPARC. RISC & Itanium-based Server Volumes SPARC na 9 producentów procesorów RISC. przechodzi na technologie Itanium IPF. Alpha. PA-RISC. Power. SPARC.")
26
Dobór Procesorów Do Aplikacji
Workstations Front-End (Edge) Mid-Tier (Enterprise) Backend (Databases) High Performance Computing Itanium™ 2 Processor Intel® Itanium™ 2 Processor Xeon™ Processor Intel® Xeon™ Processor Workloads Web Server ERP BI CRM CAE Life/Med Sci Finance Oil&Gas EDA/MCAD/DCC/CAE Mail/Calendar Gaming SCM Database Best for general purpose IT infrastructure: Workstation, front-end & mid-tier solutions Best for business critical enterprise mid-tier & back-end servers & tech computing
 Mid-Tier (Enterprise) Backend. (Databases) High Performance Computing. Itanium™ 2 Processor. Intel® Itanium™ 2 Processor. Xeon™ Processor. Intel® Xeon™ Processor. Workloads. Web Server. ERP. BI. CRM. CAE Life/Med Sci Finance Oil&Gas. EDA/MCAD/DCC/CAE. Mail/Calendar. Gaming. SCM. Database. Best for general purpose IT infrastructure: Workstation, front-end & mid-tier solutions. Best for business critical enterprise mid-tier & back-end servers & tech computing.")
27
64-bit computing Adresacja: 32-bitowy do 4GB; 64-bitowy do ~18 EB
Obliczenia stałoprzecinkowe: zwiększony zakres (long i pointer), zwiększona wydajność Lepsze wykorzystanie zasobów: większe zbiory większa ich liczba większa liczba użytkowników Aplikacje o dużym zapotrzebowaniu na zasoby zwłaszcza dla SMP
, zwiększona wydajność. Lepsze wykorzystanie zasobów: większe zbiory. większa ich liczba. większa liczba użytkowników. Aplikacje o dużym zapotrzebowaniu na zasoby. zwłaszcza dla SMP.")
28
64-bity przestrzeni adresowej
32-bity adresowania 1 cm wysokość CD 64-bity adresowania km odległość między ziemią a księżycem 64-bit 32-bit .

29
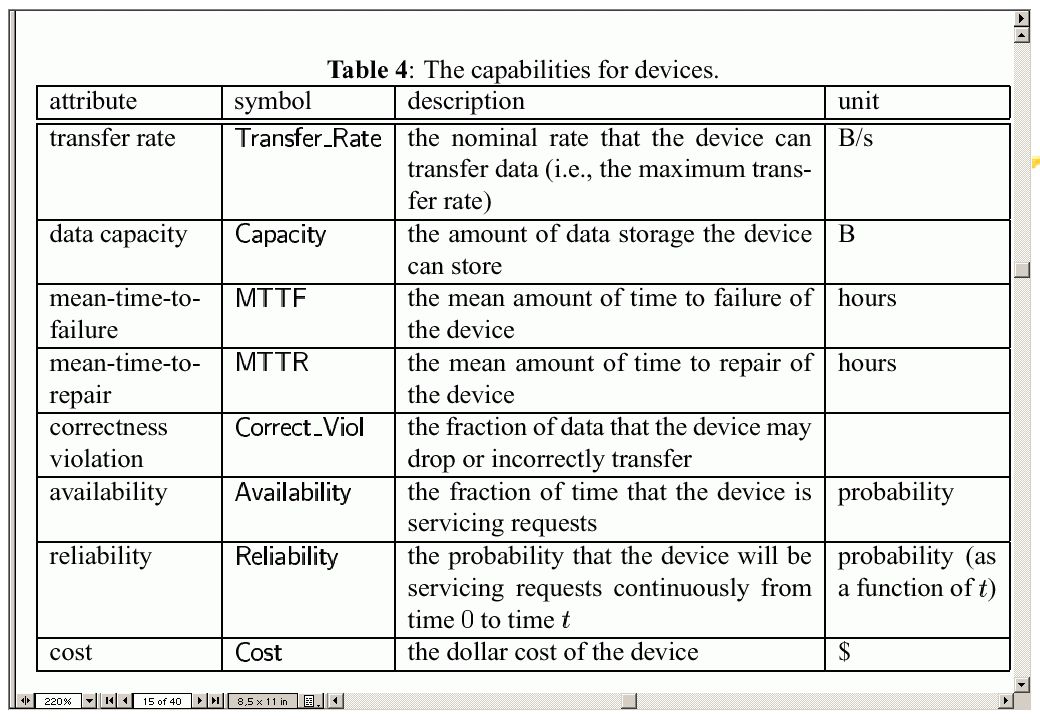
ECC ECC (either "error correction [or correcting] code" or "error checking and correcting") allows data that is being read or transmitted to be checked for errors and, when necessary, corrected on the fly. It differs from parity-checking in that errors are not only detected but also corrected. ECC is increasingly being designed into data storage and transmission hardware as data rates (and therefore error rates) increase. Here's how it works for data storage: When a unit of data (or "word") is stored in RAM or peripheral storage, a code that describes the bit sequence in the word is calculated and stored along with the unit of data. For each 64-bit word, an extra 7 bits are needed to store this code. When the unit of data is requested for reading, a code for the stored and about-to-be-read word is again calculated using the original algorithm. The newly generated code is compared with the code generated when the word was stored. If the codes match, the data is free of errors and is sent. If the codes don't match, the missing or erroneous bits are determined through the code comparison and the bit or bits are supplied or corrected. No attempt is made to correct the data that is still in storage. Eventually, it will be overlaid by new data and, assuming the errors were transient, the incorrect bits will "go away." Any error that recurs at the same place in storage after the system has been turned off and on again indicate a permanent hardware error and a message is sent to a log or to a system administrator indicating the location with the recurrent errors. At the 64-bit word level, parity-checking and ECC require the same number of extra bits. In general, ECC increases the reliability of any computing or telecommunications system (or part of a system) without adding much cost. Reed-Solomon codes are commonly implemented; they're able to detect and restore "erased" bits as well as incorrect bits.
 allows data that is being read or transmitted to be checked for errors and, when necessary, corrected on the fly. It differs from parity-checking in that errors are not only detected but also corrected. ECC is increasingly being designed into data storage and transmission hardware as data rates (and therefore error rates) increase. Here s how it works for data storage: When a unit of data (or word ) is stored in RAM or peripheral storage, a code that describes the bit sequence in the word is calculated and stored along with the unit of data. For each 64-bit word, an extra 7 bits are needed to store this code. When the unit of data is requested for reading, a code for the stored and about-to-be-read word is again calculated using the original algorithm. The newly generated code is compared with the code generated when the word was stored. If the codes match, the data is free of errors and is sent. If the codes don t match, the missing or erroneous bits are determined through the code comparison and the bit or bits are supplied or corrected. No attempt is made to correct the data that is still in storage. Eventually, it will be overlaid by new data and, assuming the errors were transient, the incorrect bits will go away. Any error that recurs at the same place in storage after the system has been turned off and on again indicate a permanent hardware error and a message is sent to a log or to a system administrator indicating the location with the recurrent errors. At the 64-bit word level, parity-checking and ECC require the same number of extra bits. In general, ECC increases the reliability of any computing or telecommunications system (or part of a system) without adding much cost. Reed-Solomon codes are commonly implemented; they re able to detect and restore erased bits as well as incorrect bits.")
30
Perspektywy rozwojowe

31
Technology Infrastructure
Składowe dostępności Availability is Built, Managed and Measured "Technology is one component in the evolution to high availability systems" Technology Infrastructure Availability IT Processes Support Partnerships

32
Udział czynników wywołujących awarie
w standardowych warunkach bez dodatkowych zabezpieczeń MTBF - Mean, przykład: 500 dysków, dla każdego MTBF = 200,000 godz. średnio uszkodzenie co 200,000/500 = 400 godz = 16.5 dnia !!!

33
Wiarygodność systemu informatycznego
Pojęcie pojemne, atrybuty: niezawodność, dostępność, tolerowanie awarii nadmiarowość i diagnostyka istniejących błędów i usterek w systemie bezpieczeństwo systemu w sytuacjach wyjątkowych zabezpieczenie systemu przed niepowołanym dostępem do zasobów poufność i integralność przetwarzanej lub przesyłanej informacji przeżywalność systemu - odporność na zagrożenia Ważny element - organizacja pracy

34
Uszkodzenia/wady systemu (rozproszonego)
Zdolność do przetrwania uszkodzenia (niemożliwa eliminacja prawdopodobieństwa powstania) Rodzaje uszkodzeń z względu na widoczność awarii uszkodzenie uciszające (fail-silent fault) - brak działania (fail-stop fault) uszkodzenie „bizantyjskie” (Byzantine fault) - wadliwe działanie Wady (pod względem trwałości awarii) przejściowe (transient faults) nieciągłe (intermittent) - przypadkowe trwałe (permanent) Systemy synchroniczne (odpowiedź na komunikat w określonym czasie) i asynchroniczne
 Rodzaje uszkodzeń z względu na widoczność awarii. uszkodzenie uciszające (fail-silent fault) - brak działania (fail-stop fault) uszkodzenie „bizantyjskie (Byzantine fault) - wadliwe działanie. Wady (pod względem trwałości awarii) przejściowe (transient faults) nieciągłe (intermittent) - przypadkowe. trwałe (permanent) Systemy synchroniczne (odpowiedź na komunikat w określonym czasie) i asynchroniczne.")
35
Analiza atrybutów wiarygodności
model przejść stanów dopuszczalne kontrolowane (błędy oczekiwane i strategie postępowania) zagrożenia stany nieoczekiwane - błędy przypadkowe błędy celowe - ingerencja z zewnątrz błędy nadciągające - niederministyczne działanie systemów i aplikacji niesprawdzone aplikacje, modyfikacje konfiguracji .... katastrofy - wstrzymanie pracy
 zagrożenia stany nieoczekiwane - błędy przypadkowe. błędy celowe - ingerencja z zewnątrz. błędy nadciągające - niederministyczne działanie systemów i aplikacji. niesprawdzone aplikacje, modyfikacje konfiguracji .... katastrofy - wstrzymanie pracy.")
36
Redundancja w systemach wysokiej dostępności
Redundancja (inaczej): czasu (powtórzenie działania - niepodzielne transakcje; wady przejściowe lub nieciągłe) fizyczna (aktywne zwielokrotnienie zasoby rezerwowe) informacji (dodatkowe bity; kod Hamminga)
: czasu (powtórzenie działania - niepodzielne transakcje; wady przejściowe lub nieciągłe) fizyczna (aktywne zwielokrotnienie zasoby rezerwowe) informacji (dodatkowe bity; kod Hamminga)")
37
Przykładowe dane Skutki utraty danych:
50% firm upada natychmiast, 90% w ciągu 2 lat Oracle: średni koszt przerwy w pracy systemu: 80 tys.USD/godz. firma brokerska: mln USD/godz. weryfikacja kart kredytowych/zakupy: mln USD/godz. rezerwacja biletów lotniczych: tys. USD/godz.

38
wszystkie dane stworzone przez ostatnie 40000 lat
40,000 bc cave paintings bone tools 3500 bc writing 105 paper 1450 printing 1870 electricity, telephone 1947 transistor 1993 the web 1999 source: uc berkeley 12M TB

39
(add 24m) 57m (add 12m) 33m (add 6m) 21m (add 3m) 15m tb więcej danych zostanie stworzonych przez najbliższe 3 lata niż przez ostatnie lat 40,000 bc cave paintings bone tools 3500 bc writing 105 paper 1450 printing 1870 electricity, telephone 1947 transistor 1993 the web 1999 source: uc berkeley 57M TB

40
Prawne wymogi przechowywania dokumentów z dysków produkcyjnych (katalog rozwiązań ILM 2005; materiały reklamowe firmy StorageTek)
")
41
System pracy ciągłej Realizuje funkcje bez znaczących przerw w pracy
W elementach składowych uwzględnia się wymagania: niezawodności (Reliability) - R(t), statystyczna miara MTBF, MTTF dostępności (Availability) - A(t) serwisowania (Serviceability) Wymagania RAS
 - R(t), statystyczna miara MTBF, MTTF. dostępności (Availability) - A(t) serwisowania (Serviceability) Wymagania RAS.")
43
Dostępność systemu komputerowego
Ogólnie: Nieliniowo rosnący wzrost kosztów

44
Podział systemów - inaczej
1. standardowa dostępność - tylko backup („do nothing special”) 2. poziom podwyższony - ochrona danych („protect the data”) - dyski lustrzane, RAID 3. wysoka dostępność - ochrona systemu („protect the system”) - HA 4. ochrona organizacji („protect the organization”) - rozdział geograficzny 5. Fault tolerant - specjalizowane systemy komputerowe - równoległa praca elementów - niebezpieczeństwo w uszkodzeniu oprogramowania konieczne zrównoważenie zysków i strat, uwzględnienie przypadków niekorzystnych
 2. poziom podwyższony - ochrona danych („protect the data ) - dyski lustrzane, RAID. 3. wysoka dostępność - ochrona systemu („protect the system ) - HA. 4. ochrona organizacji („protect the organization ) - rozdział geograficzny. 5. Fault tolerant - specjalizowane systemy komputerowe - równoległa praca elementów - niebezpieczeństwo w uszkodzeniu oprogramowania. konieczne zrównoważenie zysków i strat, uwzględnienie przypadków niekorzystnych.")
45
Wymagania serwisowania
Serviceability Usługi serwisowe, przykładowe poziomy: Gwarancja 1-3 lata opcje - czas reakcji serwisu producenta następny dzień roboczy 4 godz x 7 x wsparcie telefoniczne systemy krytyczne - gwarantowany czas naprawy 4 godz x 7 x wsparcie telefoniczne

46
Stadia projektu systemu HA
Analiza funkcjonalna aplikacji Wybór architektury komputerów i systemu Analiza usług serwisowych producenta Analiza ekonomiczna Plan implementacji i eksploatacji zarządzania Polityka ochrony danych prawa dostępu, ochrona dostępu, kopie zapasowe, archiwizacja) Zniszczenia rozległe Plan szkoleń
 Zniszczenia rozległe. Plan szkoleń.")
47
O czym mówiliśmy do tej pory ?
niezawodność (Reliability) - R(t), statystyczna miara MTBF, MTTF dostępność (Availability) - A(t) serwisowanie (Serviceability) 4 godz x 7 x wsparcie telefoniczne
 - R(t), statystyczna miara MTBF, MTTF. dostępność (Availability) - A(t) serwisowanie (Serviceability) 4 godz. 365 x 7 x 24 + wsparcie telefoniczne.")
48
Poziom podwyższony - ochrona danych
Macierze dyskowe RAID automatyczne biblioteki taśmowe urządzenia do zapisu optycznego na dyskach CD.

Podobne prezentacje