Pobierz prezentację
1
Wykład 10 Rozważmy populacje i jej podgrupy.
Model dla jednoczynnikowej ANOV-y: yij = μ+γi+ij , gdzie ij są niezależne N(0,2) μ- średnia wartość cechy w całej populacji μi=μ+γi– średnia dla i-tej grupy: γi = μi –μ Hipoteza H0: 1 = 2 = 3 = … = k jest równoważna hipotezie H0: γ1 = γ2 = γ3 = … = γk=0
 μ- średnia wartość cechy w całej populacji. μi=μ+γi– średnia dla i-tej grupy: γi = μi –μ. Hipoteza. H0: 1 = 2 = 3 = … = k. jest równoważna hipotezie. H0: γ1 = γ2 = γ3 = … = γk=0.")
2
Model dwuczynnikowej ANOV-y
Zrandomizowany układ blokowy Wpływ zabiegu: γi, wpływ bloku: βj Model: Yijk = μ + γi + βj+ εijk Hipoteza H0 : γ1 = γ2 = γ3 = … = γk=0 (zabieg nie ma wpływu, nic o blokach) H1 : Nie H0 (niektóre γi są różne od zera)
 H1 : Nie H0 (niektóre γi są różne od zera)")
3
Rozkład SS Suma kwadratów pomiędzy blokami:
Tutaj mj jest rozmiarem bloku. SS(całkowita) = SS(wewnątrz)+SS(pomiędzy)+SS(blok) df(całkowita) = df(wewnątrz)+df(pomiędzy)+df(blok) df(blok)=b-1 = liczba bloków -1
 = SS(wewnątrz)+SS(pomiędzy)+SS(blok) df(całkowita) = df(wewnątrz)+df(pomiędzy)+df(blok) df(blok)=b-1 = liczba bloków -1.")
4
Tabela ANOV-y Source df SS MS Statistics
Between k SSBt MSBt=SSBt/(k-1) Block b SSBl MSBl= SSBl/(b-1) Within n-k-b+1 SSW MSW=SSW/(n-k-b+1) F=MSBt/MSW Total n SST
 Block b-1 SSBl MSBl= SSBl/(b-1) Within n-k-b+1 SSW MSW=SSW/(n-k-b+1) F=MSBt/MSW. Total n-1 SST.")
5
Przykład (wysokość roślin)
Nawóz I Nawóz II Nawóz III Średnia dla bloku Blok1 1.58 1.10 2.47 1.717 Blok2 1.15 1.05 2.15 1.450 Blok3 1.27 0.50 1.46 1.077 Blok4 1.25 1.00 2.36 1.537 Blok5 1.50 1.167 n 5 Średnia dla zabiegu 1.03 1.888

6
Budujemy tabelę ANOV-y
Całkowita średnia =... SSBt (SS zabiegu)=... MSBt =... SSBl (SS bloków)=... MSBl =...
=... MSBt =... SSBl (SS bloków)=... MSBl =...")
7
SSW = SST – SSBt – SSBl = 1.452 df(SSW) = , MSW =... Fs = MSBt / MSW =... df(pomiedzy)= , df(wewnątrz)=... Wartość krytyczna=... Decyzja:... Wniosek:....

8
Dane jakościowe Obserwacje klasyfikujemy do klas
Zliczamy liczbę obserwacji w każdej klasie Jeżeli są tylko dwie klasy, to jedną z nich możemy nazwać „sukcesem”, a drugą „porażką”. Generalnie, liczba obserwacji w ustalonej klasie ma rozkład:....

9
Jeżeli mamy więcej niż dwie klasy, tp
możemy się skoncentrować na jednej klasie albo rozważać wszystkie klasy na raz

10
Przypomnienie: p (nieznane) prawdopodobieństwo sukcesu – np. bycia w klasie 1 n liczba obserwacji. Obserwujemy y = # obserwacji w klasie 1. = ... y ma rozkład , Jeżeli np i n(1-p) są dość duże, to rozkład ten możemy aproksymować rozkładem ....
 są dość duże, to rozkład ten możemy aproksymować rozkładem ....")
11
Rozkład 2 Definicja: Niech Y1, … Yk będą niezależnymi zmiennymi losowymi o rozkładzie N(0,1). Suma kwadratów tych zmiennych ma rozkład 2k (rozkład chi-kwadrat z k stopniami swobody).
. Suma kwadratów tych zmiennych ma rozkład 2k (rozkład chi-kwadrat z k stopniami swobody).")
12
Test zgodności chi-kwadrat
Rozważymy przypadek danych jakościowych Mamy próbę składającą się z n niezależnych obserwacji Będziemy testowali hipotezy o wartości prawdo-podobieństw należenia do poszczególnych klas Do obliczania wartości krytycznych skorzystamy z przybliżenia rozkładem (normalnym i) chi-kwadrat, które działa dla dużych rozmiarów prób.
 chi-kwadrat, które działa dla dużych rozmiarów prób.")
13
Zakładamy wartości pi (prawdopodobień-stwo ``bycia’’ w i-tej klasie)
Liczymy oczekiwaną liczbę obserwacji w każdej klasie: npi Porównujemy z zaobserwowanymi (zob. dalej) Uwagi: Test stosujemy, gdy oczekiwana liczba obserwacji (npi) w każdej z klas nie jest mniejsza od 5. Test jest w założeniu podobny do testu znaków, ale nie wykorzystuje rozkładu dwumianowego.
 Uwagi: Test stosujemy, gdy oczekiwana liczba obserwacji (npi) w każdej z klas nie jest mniejsza od 5. Test jest w założeniu podobny do testu znaków, ale nie wykorzystuje rozkładu dwumianowego.")
14
Prosty przypadek: dwie klasy
Np. samiec/samica, tak/nie, sukces/porażka, poprawa/pogorszenie, itd. Badamy model genetyczny dziedziczenia pewnej cechy. Mamy dwie linie homozygotyczne muszki Drosophilae, jedną z czerwonymi oczami i jedną z fioletowymi oczami. Sugeruje się, że za kolor oczu odpowiedzialny jest tylko jeden gen i że allel oczu czerwonych dominuje nad allelem oczu fioletowych.

15
Jeżeli założona hipoteza jest prawdziwa to w krzyżówce F2 stosunek liczby muszek z czerwonymi oczami do liczby muszek z fioletowymi oczami powinien być w przybliżeniu równy: ..... Aby zweryfikować tę hipotezę wyhodowano 43 muszki z populacji F2 (wykorzystując kilku rodziców z linii homozygotycznych). 29 z tych muszek miało czerwone oczy, a 14 fioletowe oczy.
. 29 z tych muszek miało czerwone oczy, a 14 fioletowe oczy.")
16
Klasy: Czerwone oczy; hipotetyczne prawdopodobieństwo p =... Oczekiwana liczba czerwonych: E1 =... Fioletowe oczy; hipotetyczne p’ =... Oczekiwana liczba: E2 =...

17
Czy allel czerwonych oczu dominuje nad allelem fioletowych oczu?
Niech p będzie p-stwem, że muszka w populacji F2 ma czerwone oczy H0: p = ; HA: ....

18
Użyjemy testu zgodności chi-kwadrat
2s = (O-E)2/E przy H0 ma w przybliżeniu rozkład chi-kwadrat z df = #klas - 1 = Testujemy na poziomie = 0.05 Wartość krytyczna = ... = Tablica wartości krytycznych z książki ``Introduction to the Practice of Statistics’’, D.S. Moore, G. P. McCabe
2/E przy H0 ma w przybliżeniu rozkład chi-kwadrat z. df = #klas - 1 = Testujemy na poziomie = Wartość krytyczna = ... = Tablica wartości krytycznych z książki ``Introduction to the Practice of Statistics’’, D.S. Moore, G. P. McCabe.")
20
2s = (O-E)2/E = (zaobserwowana - oczekiwana)2/oczekiwana tutaj =.... Wniosek:
2/E = (zaobserwowana - oczekiwana)2/oczekiwana tutaj =.... Wniosek:")
21
Możemy także testować przeciwko alternatywie kierunkowej np
Możemy także testować przeciwko alternatywie kierunkowej np. HA : p < W tym przypadku odrzucamy H0 gdy oba poniższe warunki są spełnione: X2s > 21(2), tzn. ... < 0.75 tzn. estymator odchyla się od hipotetycznej wartości w tym samym kierunku co HA
, tzn. ... < tzn. estymator odchyla się od hipotetycznej wartości w tym samym kierunku co HA.")
22
Więcej niż 2 klasy U słodkiego groszku allel fioletowego koloru kwiatów (F) jest dominujący nad allelem czerwonego koloru (C) a allel wydłużonych ziaren pyłku (d) jest dominujący nad allelem okrągłych ziaren (o). Mamy rodziców homozygotycznych P1 z allelami dominującymi (FFdd) i rodziców homozygotycznych P2 z allelami recesywnymi (CCoo). W generacji F1 wszystkie groszki mają genotypy ( ) i mają fenotypy ..... Groszki z populacji F1 krzyżujemy i dostajemy populację F2. Przypuszcza się, że geny kontrolujące obie cechy są odległe o 20 cM. Jeżeli jest to prawdą to w populacji F2 poszczególne fenotypy powinny występować w proporcjach 67.44 : 7.56 : 7.56 : 17.44
 jest dominujący nad allelem czerwonego koloru (C) a allel wydłużonych ziaren pyłku (d) jest dominujący nad allelem okrągłych ziaren (o). Mamy rodziców homozygotycznych P1 z allelami dominującymi (FFdd) i rodziców homozygotycznych P2 z allelami recesywnymi (CCoo). W generacji F1 wszystkie groszki mają genotypy ( ) i mają fenotypy Groszki z populacji F1 krzyżujemy i dostajemy populację F2. Przypuszcza się, że geny kontrolujące obie cechy są odległe o 20 cM. Jeżeli jest to prawdą to w populacji F2 poszczególne fenotypy powinny występować w proporcjach : 7.56 : 7.56 :")
23
67.44% fioletowe/wydłużone
FFdd albo FCdd albo FFdo albo FCdo, [(2 -2+3)/4] 7.56% fioletowe/okrągłe : FFoo albo FCoo, [(2-2)/4] 7.56% czerwone/wydłużone = CCdd albo CCLdo, [(2-2)/4] 17.44% czerwone/okrągłe = CCoo, [(1-)2/4], gdzie = (prawdopodobieństwo rekombinacji). Wśród 381 osobników z populacji F2 zaobserwowano 284 fioletowe/wydłużone 21 fioletowe/okrągłe 21 czerwone/wydłużone 55 czerwone/okrągłe
/4] 7.56% fioletowe/okrągłe : FFoo albo FCoo, [(2-2)/4] 7.56% czerwone/wydłużone = CCdd albo CCLdo, [(2-2)/4] 17.44% czerwone/okrągłe = CCoo, [(1-)2/4], gdzie = (prawdopodobieństwo rekombinacji). Wśród 381 osobników z populacji F2 zaobserwowano. 284 fioletowe/wydłużone. 21 fioletowe/okrągłe. 21 czerwone/wydłużone. 55 czerwone/okrągłe.")
24
Czy geny są w odległości 20 cM ?
Niech p1, p2, p3, p4 będą p-stwami odpowiednio fioletowe/wydłużone, fioletowe/okragłe, czerwone/wydłużone, czerwone/okrągłe w populacji F2. H0: p1 =0.6744, p2 = , p3 =0.0756, p4 = ; p-stwa poszczególnych klas odpowiadają odległości 20 cM. HA: p-stwa klas nie odpowiadają odległości 20 cM.

25
Użyjemy testu chi-kwadrat, df = #klas - 1 =....
2s = (O-E)2/E ma przy H0 rozkład ..... Testujemy na poziomie = 0.05; Wartość krytyczna = ..... Wartości oczekiwane liczby obserwacji w każdej klasie przy H0 (n pi):
2/E ma przy H0 rozkład Testujemy na poziomie = 0.05; Wartość krytyczna = Wartości oczekiwane liczby obserwacji w każdej klasie przy H0 (n pi):")
26
2s = ... Wniosek: ....

27
Podsumowanie testu zgodności chi-kwadrat
Definiujemy pi dla każdej klasy i formułujemy hipotezę. Jeżeli są tylko dwie klasy, to alternatywę można łatwo opisać za pomocą wzoru, może ona też być kierunkowa.

28
Jeżeli mamy więcej niż dwie klasy, to alternatywę należy opisać słowami.
Dla każdej klasy liczymy Ei = npi . Sprawdzamy, czy wszystkie Ei są nie mniejsze niż 5. (Aby można było stosować test chi-kwadrat) Liczymy 2s = (O-E)2/E sumując po wszystkich klasach. Porównujemy z wartością krytyczną z rozkładu 2k-1; odrzucamy H0 , gdy statystyka jest większa od wartości krytycznej.
 Liczymy 2s = (O-E)2/E sumując po wszystkich klasach. Porównujemy z wartością krytyczną z rozkładu 2k-1; odrzucamy H0 , gdy statystyka jest większa od wartości krytycznej.")
29
Tablice wielodzielcze
Najpierw tablice”2x2”: dwa rzędy i dwie kolumny Dane jakościowe z czterema klasami, które można połączyć w pary. Dwie typowe sytuacje: Dwie niezależne próby; w każdej obserwujemy jedną cechę o dwu wartościach Jedna próba; obserwujemy dwie różne cechy, z których każda może przyjmować dwie wartości.

30
Przykład sytuacji 1 Próby to „lekarstwo” i „placebo” (lub dowolne dwa zabiegi); obserwowana zmienna to „poprawa” lub „brak poprawy”. próby „samce" i „samice" (dowolne dwie grupy, które chcemy porównać); obserwowana zmienna – np. kolor oczu, ``fioletowe’’ i „czerwone”. Przykład sytuacji 2 obserwujemy „kolor oczu" (czerwone/fioletowe) i „kształt skrzydła" (normalny/mniejszy) Oberwujemy, czy ludzie palą i czy ćwiczą
; obserwowana zmienna – np. kolor oczu, ``fioletowe’’ i „czerwone . Przykład sytuacji 2. obserwujemy „kolor oczu (czerwone/fioletowe) i „kształt skrzydła (normalny/mniejszy) Oberwujemy, czy ludzie palą i czy ćwiczą.")
31
4 klasy; obserwacje w tabeli 2x2
Kolor oczu czerwone fioletowe Kszatłt skrzydła normalne 39 11 mniejsze 18 32 : Testujemy niezależność zmiennych definiujących rzędy i kolumny. W tym przypadku będzie to odpowiadać testowaniu hipotezy, czy oba geny leżą na innych chromosomach.

32
Przykład (wstępny): Obserwowane zabieg Suma Lekarstwo Placebo Wynik
Poprawa 15 4 19 Brak poprawy 11 17 28 26 21 47

33
p1 = p-stwo, że nastąpi poprawa, jeżeli pacjent bierze lekarstwo
p2 = p-stwo, że nastąpi poprawa, jeżeli pacjent bierze placebo H0: p1 = p2 HA: p1 p2 ( or p1 > p2) Niech poziom istotności =0.01
 Niech poziom istotności =0.01.")
34
W przeciwieństwie do testu zgodności, nie mamy hipotetycznych wartości na p. Zamiast tego, H0 mówi, że oba p-stwa są takie same. Można to wyrazić w terminach niezależności. HA mówi, że p-stwa są różne, co oznacza, że zmienne ``zabieg’’ i „wynik” nie są niezależne.

35
= Jakich wartości oczekiwalibyśmy, gdyby H0 była prawdziwa ? Poprawa nastąpiła u 19 pacjentów. Jest to 19/47 = 40.4% wszystkich badanych. 26 pacjentów brało lekarstwo. Jeżeli H0 jest prawdziwa, to u około 40.4% z nich powinna nastąpić poprawa.

36
Podobnie liczba pacjentów, u których nastąpiła poprawa mimo, że brali placebo powinna być bliska....
Ponadto oczekujemy, że nie nastąpiła poprawa u osób biorących lekarstwo i u osób biorących placebo. Te oczekiwane wartości umieszczamy w podobnej tabeli.

37
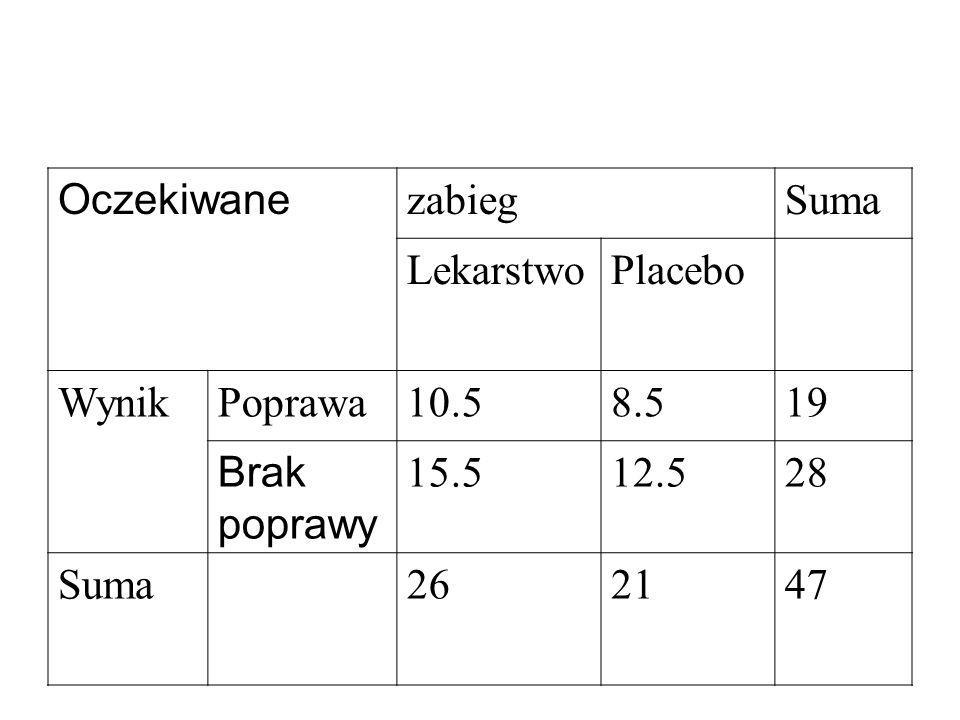
Oczekiwane zabieg Suma Lekarstwo Placebo Wynik Poprawa 10.5 8.5 19 Brak poprawy 15.5 12.5 28 26 21 47
38
Ogólnie: E = (suma w rzędzie)(suma w kolumnie)/(całkowita suma )
Dla każdej z czterech klas. Aby stosować test chi-kwadrat, w każdej klasie E powinno być nie mniejsze niż 5.

39
Łączymy obie tabele: Oberwowane (Oczekiwane) zabieg Suma Lekarstwo
Placebo Wynik Poprawa 15 (10.5) 4 (8.5) 19 Brak poprawy 11 (15.5) 17 (12.5) 28 26 21 47
 4 (8.5) 19. Brak poprawy. 11 (15.5) 17 (12.5)")
40
Czy u pacjentów biorących lekarstwo poprawa występuje częściej niż u pacjentów biorących placebo ?
p1 = p-stwo poprawy u pacjentów biorących lekarstwo p2 = p-stwo poprawy u pacjentów biorących placebo H0: p1 = p2 ; p-stwo poprawy jest takie samo w obu grupach (albo: wynik i zabieg są niezależne). HA: p1 > p2 ; p-stwo poprawy jest większe u pacjentów biorących lekarstwo
. HA: p1 > p2 ; p-stwo poprawy jest większe u pacjentów biorących lekarstwo.")
41
Stosujemy test 2 dla niezależności
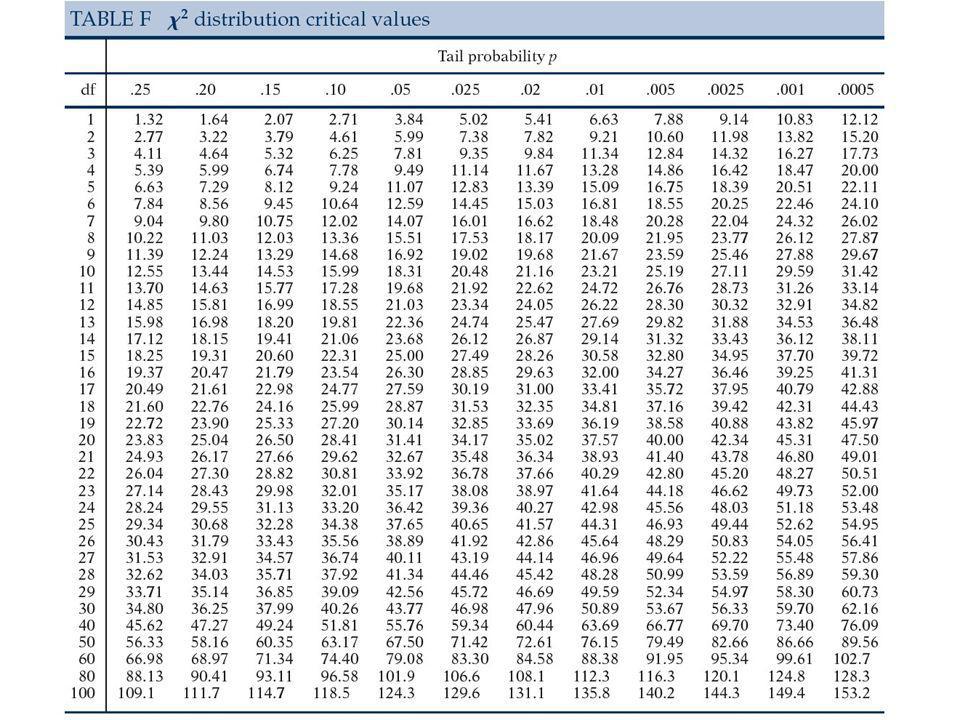
X2s = (O-E)2/E przy H0 ma rozkład 21. Testujemy na poziomie istotności = 0.01; odrzucamy H0 gdy X2s > [używamy kolumny 0.02 bo alternatywa jest kierunkowa] [Ponieważ alternatywa jest kierunkowa musimy wykonać kolejny krok]
2/E przy H0 ma rozkład 21. Testujemy na poziomie istotności = 0.01; odrzucamy H0 gdy X2s > [używamy kolumny 0.02 bo alternatywa jest kierunkowa] [Ponieważ alternatywa jest kierunkowa musimy wykonać kolejny krok]")
42
2s =..... Wniosek:.....

43
Stopnie swobody df = 1 dla tabeli 2x2. Ogólnie (#rzędów-1)(#kolumn-1) Wartości krytyczne: Gdy HA jest niekierunkowa szukamy w kolumnie , gdy jest kierunkowa w kolumnie 2.

44
Co oznacza odrzucenie H0
Co oznacza odrzucenie H0? Czasami trzeba być ostrożnym przy formułowaniu wniosków. Gdy odrzucamy H0 , to mamy przesłanki, aby przypuszczać, że zmienne nie są niezależne. To jednak nie zawsze odpowiada związkowi przyczynowemu! Nasze badanie wskazuje, że stan pacjentów biorących lekarstwo częściej się poprawia, niż stan pacjentów biorących placebo. Tutaj kontrolowaliśmy zabieg, więc możemy przypuszczać, że istnieje związek przyczynowy. Gdybyśmy jednak testowali niezależność koloru oczu i kształtu skrzydeł u muszek owocówek nie moglibyśmy stwierdzić związku przyczynowego (np. „Kolor oczu wpływa na kształt skrzydeł”??). Możemy tylko powiedzieć, że oba fenotypy są zmiennymi zależnymi.
. Możemy tylko powiedzieć, że oba fenotypy są zmiennymi zależnymi.")




>")

>")











>")

