Pobierz prezentację
1
Wykład 11 Analiza wariancji (ANOVA) Sposób analizy danych gdy mamy więcej niż dwa zabiegi lub populacje. Omówimy ANOV-ę w najprostszej postaci. Te same podstawowe założenia/ograniczenia co przy teście Studenta W każdej populacji badana cecha ma rozkład normalny Obserwacje są niezależne i losowe Będziemy testowali hipotezy o średnich w populacjach i Założenie – standardowe odchylenia badanej cechy w każdej populacji są sobie równe (podobne) więc możemy użyć uśrednionego SE
 więc możemy użyć uśrednionego SE.")
2
Uwaga: ANOVA może być stosowana także gdy próby nie są niezależne Np. W układzie zrandomizowanym blokowym (zasada podobna do testu Studenta dla powiązanych par) Nie będziemy tego omawiać. Omówimy tylko układy zupełne zrandomizowane. Cel: Testujemy hipotezy postaci: H 0 : 1 = 2 = 3 = … = k H A : nie wszystkie średnie są równe
 Nie będziemy tego omawiać. Omówimy tylko układy zupełne zrandomizowane. Cel: Testujemy hipotezy postaci: H 0 : 1 = 2 = 3 = … = k H A : nie wszystkie średnie są równe.")
3
Dlaczego nie stosujemy wielu testów Studenta? Wielokrotne porównania –P-stwo błędu pierwszego rodzaju (p - stwo odrzucenia prawdziwej hipotezy) jest trudne do kontrolowania)
 jest trudne do kontrolowania).")
4
Korekta Bonferoniego –Prosta ale na ogół konserwatywna (p-stwo błędu pierwszego rodzaju mniejsze niż założone – strata mocy).
.")
5
Estymacja błędu standardowego –ANOVA wykorzystuje informację zawartą we wszystkich obserwacjach: zwykle daje większą precyzję

6
Notacja: k = 3 zabiegi (próby, grupy) Zabieg 1Zabieg 2Zabieg 3 1484039 2 4830 3424432 44335 średnia434434 SS423246
 Zabieg 1Zabieg 2Zabieg średnia SS423246")
7
Trzy rodzaje rachunków: Wewnątrz grup, pomiędzy grupami, całkowite. Liczymy trzy wartości: SS, df, MS SSdfMS Between Within Total

8
Notacja: k = # grup (prób, zabiegów)k = n 1, n 2, n 3, …, n k = rozmiary grup (# obserwacji) n 1 =, n 2 =, n 3 = y 1, y 2, … y k = średnie w grupach y 1 =, y 2 =, y 3 = = całkowita średnia n* = całkowita liczba obserwacjin* =
k = n 1, n 2, n 3, …, n k = rozmiary grup (# obserwacji) n 1 =, n 2 =, n 3 = y 1, y 2, … y k = średnie w grupach y 1 =, y 2 =, y 3 = = całkowita średnia n* = całkowita liczba obserwacjin* =")
9
Dwa podstawowe typy rachunków: (gdzie konieczne, będziemy używali i do indeksowania grup a j do indeksowania obserwacji w każdej grupie : y ij ) Wewnątrz każdej grupy oznacza sumę ``wewnątrz grupy
 Wewnątrz każdej grupy oznacza sumę ``wewnątrz grupy")
10
Uwzględniające wszystkie grupy oznacza sumę we wszystkich grupach np. n* = i

11
UWAGA: Gdy rozmiary prób nie są równe nie jest średnią z k średnich!!! Ale można ją obliczyć jako = (n 1 y 1 + n 2 y 2 + …+n 3 y 3 ) / n*
 / n*.")
12
Wewnątrz grup (wypełniamy drugi rząd w tabeli) Suma kwadratów wewnątrz grup (SSW) Liczymy SS wewnątrz każdej grupy (itd. - SS 2, SS 3, …) SS 1 = SS 2 = … = 32, SS 3 = … = 46
 SS 1 = SS 2 = … = 32, SS 3 = … = 46.")
13
SSW = SS 1 +SS 2 +…+SS k = SSW = Stopnie swobody wewnątrz grup: dfw = n* - k dfw = Średnia suma kwadratów wewnątrz grup MSW = SSW / dfw MSW = To samo co uśredniona wariancja Dla przypomnienia dla dwóch prób

14
Uśrednione standardowe odchylenie sc = Pomiędzy grupami (wypełniamy pierwszy rząd tabeli) Porównujemy średnie grupowe do średniej całkowitej Ważone przez rozmiar grupy Suma kwadratów pomiędzy grupami (SSB) SSB =
 Porównujemy średnie grupowe do średniej całkowitej Ważone przez rozmiar grupy Suma kwadratów pomiędzy grupami (SSB) SSB =")
15
Stopnie swobody pomiędzy grupami (dfb) dfb = k – 1 dfb = Średnia suma kwadratów pomiędzy grupami (MSB) MSB = SSB/dfb MSB = Całkowite Całkowita suma kwadratów (SST) SST= SST=8 2 +1 2 +2 2 +…+8 2 +5 2 =348
 dfb = k – 1 dfb = Średnia suma kwadratów pomiędzy grupami (MSB) MSB = SSB/dfb MSB = Całkowite Całkowita suma kwadratów (SST) SST= SST= … =348")
16
Uwaga: SST = SSW+SSB 348 = 120 + 228 Zwykle nie trzeba liczyć SST z definicji Całkowita liczba stopni swobody (dft) dft = n* – 1 dft = Uwaga: dft = dfb+dfw 10 = 2 + 8
 dft = n* – 1 dft = Uwaga: dft = dfb+dfw 10 = 2 + 8")
17
Tablica ANOV-y SSdfMS Between Within Total

18
Ta tabela będzie dostępna na kolokwium i egzaminie: SSdfMS Pomiędzy SSB= dfb = k – 1SSB/dfb Wewnątrz SSW=dfw = n* – kSSW/dfw Całkowite SST= dft = n* – 1

19
Test F Dane dla k 2 populacji lub zabiegów są niezależne Dane w każdej populacji mają rozkład normalny ze średnią i dla populacji i, i tym samym odchyleniem standardowym

20
Testujemy H 0 : 1 = 2 = 3 = … = k (wszystkie średnie są sobie równe) vs. H A : nie wszystkie średnie są sobie równe (H A jest niekierunkowa ale obszar odrzuceń będzie jednostronny) Kroki: Obliczenie tabeli ANOV-y Testowanie
 Kroki: Obliczenie tabeli ANOV-y Testowanie.")
21
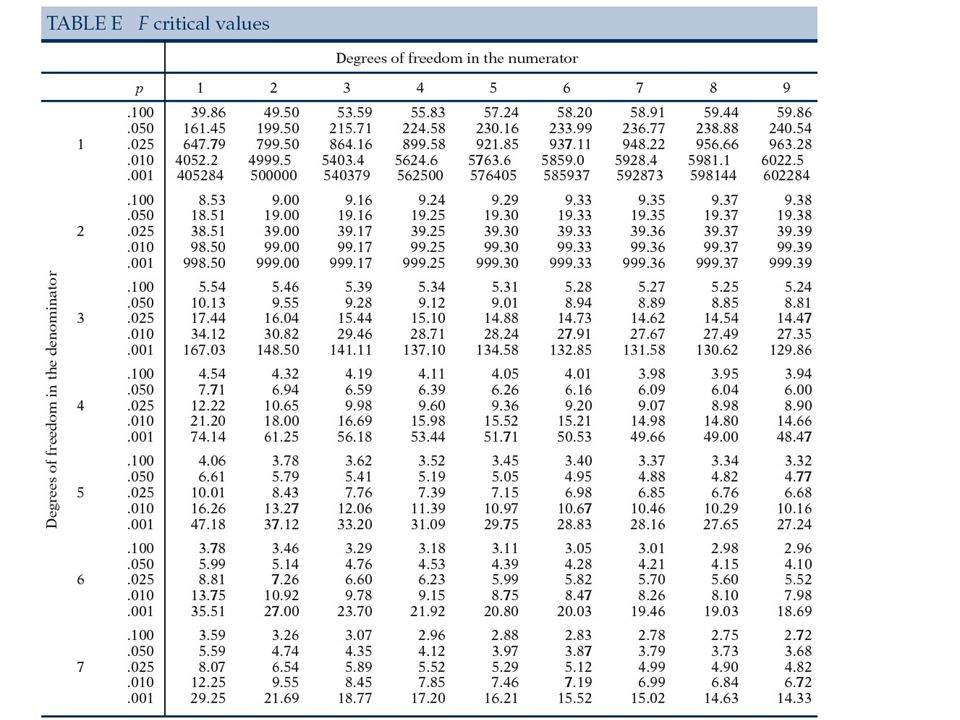
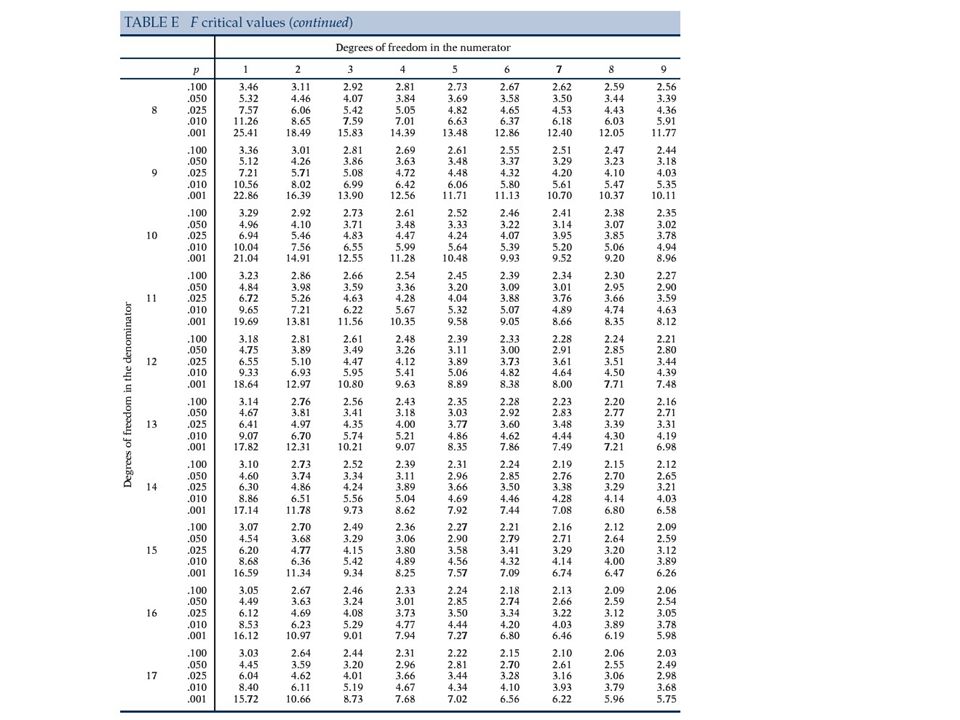
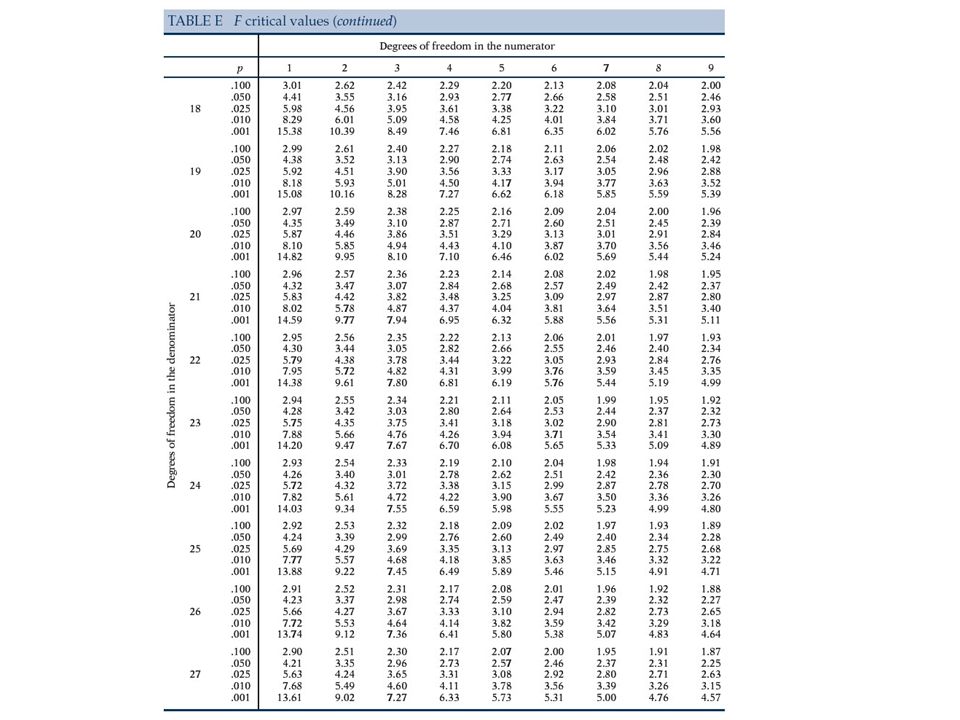
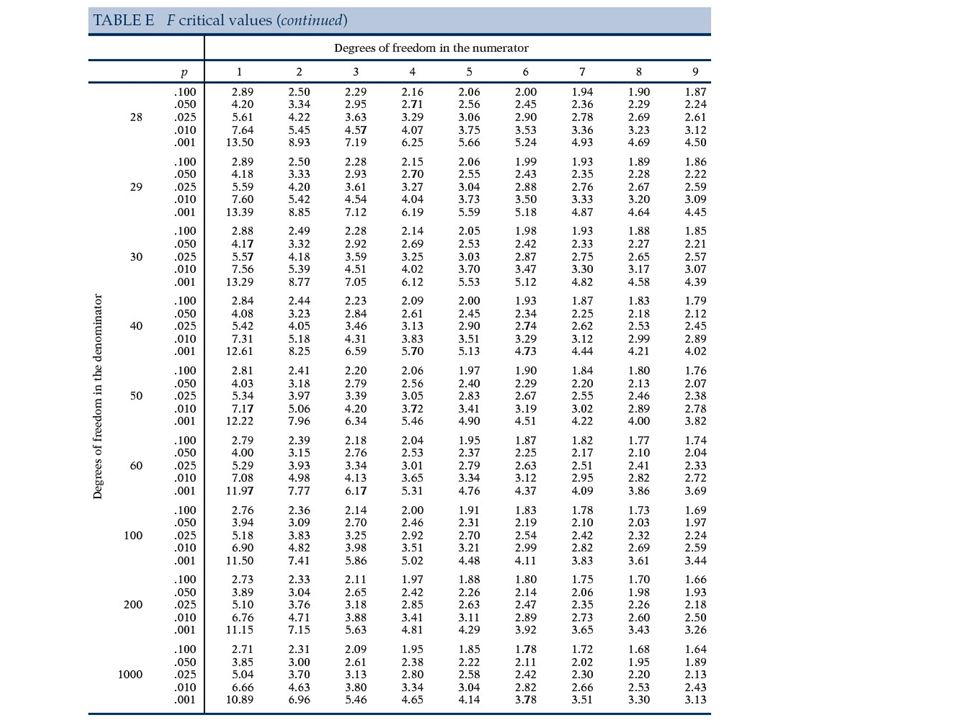
Jak opisać F test Zdefinować wszystkie H 0 podać za pomocą wzoru i słownie H A tylko słownie Statystyka testowa F s = MSB/MSW przy H 0, F s ma rozkład Snedecora z dfb, dfw stopniami swobody Na kolejnych slajdach podane są wartości krytyczne z książki D.S. Moore i G. P. McCabe ``Introduction to the Practice of Statistics "numerator df" = dfb i "denominator df" = dfw.

26
Odrzucamy H 0 gdy zaobserwowane F s > F krytyczne Przykładowy wniosek - Na poziomie istotności α (nie) mamy przesłanki aby twierdzić, że grupy różnią się poziomem badanej cechy.
 mamy przesłanki aby twierdzić, że grupy różnią się poziomem badanej cechy.")
27
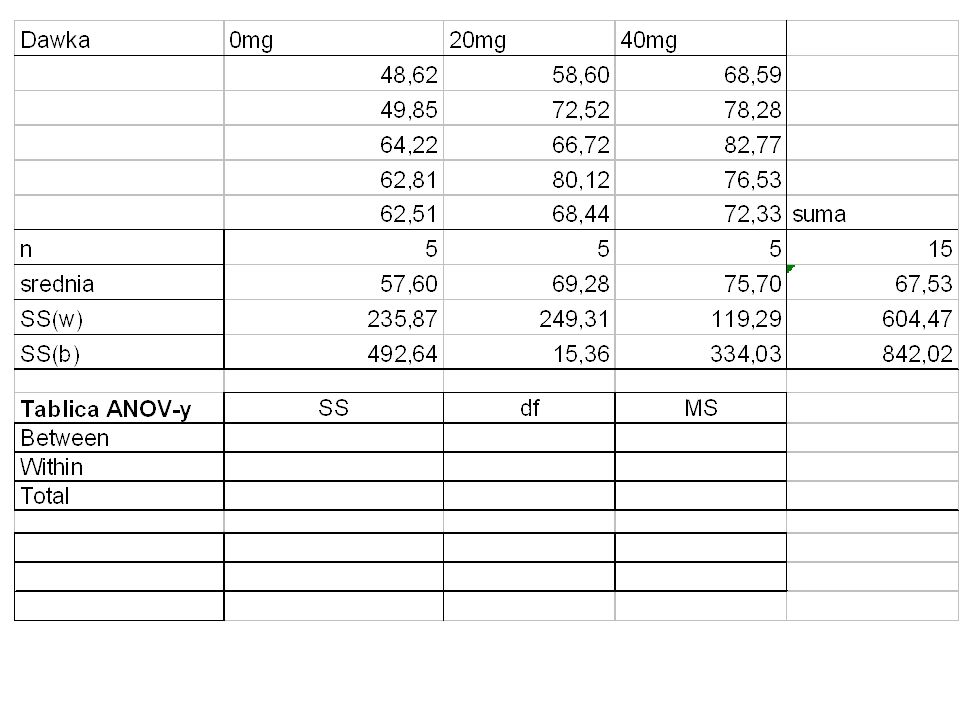
Przykład: Losową próbę 15 zdrowych mężczyzn podzielono losowo na 3 grupy składające się z 5 mężczyzn. Przez tydzień otrzymywali oni lekarstwo Paxil w dawkach 0, 20 i 40 mg dziennie. Po tym czasie zmierzono im poziom serotoniny. Czy Paxil wpływa na poziom serotoniny u zdrowych, młodych mężczyzn ? Niech 1 będzie średnim poziomem serotoniny u mężczyzn przyjmujących 0 mg Paxilu. Niech 2 będzie średnim poziomem serotoniny u mężczyzn przyjmujących 20 mg Paxilu. Niech 3 będzie średnim poziomem serotoniny u mężczyzn przyjmujących 40 mg Paxilu.

28
H 0 : 1 = 2 = 3 ; średni poziom serotoniny nie zależy od dawki Paxilu H A : średni poziom serotoniny nie jest ten sam we wszystkich grupach (albo średni poziom serotoniny zależy od dawki Paxilu). Zastosujemy F-Test

30
Fs = MSB / MSW przy H 0 ma rozkład Testujemy na poziomie istotności = 0.05. Wartość krytyczna F. 05 =. Obserwujemy F s = Wniosek:

31
Na jakiej zasadzie to działa ? Dla przypomnienia: Test Studenta patrzy na różnicę między średnimi ( y 1 - y 2 ) Dzieli ją przez miarę rozrzutu tej różnicy (SE y1- y2 ) Jeżeli ( y 1 - y 2 ) jest duże w porównaniu do do SE to statystyka testu Studenta jest duża i odrzucamy H 0.
 Dzieli ją przez miarę rozrzutu tej różnicy (SE y1- y2 ) Jeżeli ( y 1 - y 2 ) jest duże w porównaniu do do SE to statystyka testu Studenta jest duża i odrzucamy H 0..")
32
Dla testu F, Liczymy ``uśredniony kwadrat różnicy między średnimi (MSB) Dzielimy go przez oszacowanie zróżnicowania w próbie (MSW) Jeżeli MSB jest duże w porównaniu do MSW wówczas statystyka testu F jest duża i odrzucamy H 0. Test F jest analogiczny do testu Studenta ale umożliwia jednoczesne porównanie kilku średnich.

33
Could actually do an F-test with only 2 samples Statystyka testu F dla dwóch prób jest równa kwadratowi statystyki testu Studenta Decyzje i p-wartości są dokładnie takie same dla obu testów.

34
Porównania pomiędzy poszczególnymi grupami Test Studenta i korekta Bonferoniego ? Poszczególne testy w ANOV-ie nie są niezależne. Korekta Bonferoniego jest na ogół zbyt konserwatywne i daje małą moc. Możemy wykorzystać procedurę Newmana – Keulsa.

35
Newman-Keuls Procedure Sample sizes for each treatment group should be same Procedure –Construct an array of means in increasing order –Find q i from table 11 (df=dfw) and compute R i = q i sqrt(MSW/n) (R i is the critical value), n=number of observation in each treatment group
 and compute R i = q i sqrt(MSW/n) (R i is the critical value), n=number of observation in each treatment group")
36
–The pairwise comparison Compare the difference between the largest and smallest of the k sample means with the critical value R k. If the difference is smaller than R k the corresponding null hypothesis is not rejected and the line is drawn under the entire array of means, if the difference is larger than R k than proceed to the next step.

37
–Ignore the smallest mean and repeat the procedure for remaining subarray of (k- 1) means. Ignore the largest mean and repeat the the procedure for other (k-1) means. (Use a separate line each time). –Continue by looking at all subarrays of (k-2) means etc. Dont test within any subarray that has already been underlined. –When the procedure is complete, those pairs of means which are not connected by an underline correspond to null hypotheses that have been rejected.
 means. (Use a separate line each time). –Continue by looking at all subarrays of (k-2) means etc. Dont test within any subarray that has already been underlined. –When the procedure is complete, those pairs of means which are not connected by an underline correspond to null hypotheses that have been rejected..")
38
Example Blood chemistry in rats DietABCDE mean40.040.732.929.648.8 SourceDfSSMS Between4894.80223.70 Within15319.3521.79 Total191214.15

39
Ordered array diet D C A B E mean 29.6 32.9 40.0 40.7 48.8 Scale factor = sqrt(MSW/n) = sqrt(21.29/4) = 2.307 q i = 3.01 3.67 4.08 4.37 R i = 6.9 8.5 9.4 10.1 Largest – smallest: Mean(E) – Mean(D) =19.2 > R 5 =10.1 Reject null H 0 : D = E
 = sqrt(21.29/4) = q i = R i = Largest – smallest: Mean(E) – Mean(D) =19.2 > R 5 =10.1 Reject null H 0 : D = E")
40
Value of iComparisonConclusion 548.829.6=19.2>10.1Reject 448.8-32.9=15.9>9.4Reject 440.7-29.6=11.1>9.4Reject 348.8-40=8.8>8.5Reject 340.7-32.9=7.8<8.5Do not reject Line from C to B 340-29.6=10.4>8.5Reject 248.8-40.7=8.1>6.9Reject 232.9-29.6=3.3<6.9Do not reject Line from D to C

41
Two-way ANOVA One way ANOVA model y ij = +γ i + ij, ij ~independent N(0, 2 ) μ- grand population mean μ i – population mean for group i γ i = μ i – μ H 0 : 1 = 2 = 3 = … = k is equivalent to H 0 : γ 1 = γ 2 = γ 3 = … = γ k =0
 μ- grand population mean μ i – population mean for group i γ i = μ i – μ H 0 : 1 = 2 = 3 = … = k is equivalent to H 0 : γ 1 = γ 2 = γ 3 = … = γ k =0")
42
Two-way ANOVA model Randomized block design Treatment effect, Block effect Model –Y ijk = + γ i + j + ijk Hypothesis –H 0 : γ 1 = γ 2 = γ 3 = … = γ k =0 (no treatment effect) –H 1 : Not H 0 (some of γs are different from zero)
 –H 1 : Not H 0 (some of γs are different from zero)")
43
Decomposition of SS Sum of squares between blocks SS(total) = SS(within)+SS(between)+SS(block) df(total) = df(within)+df(between)+df(block) Df(block)=b-1 = number of blocks -1
 = SS(within)+SS(between)+SS(block) df(total) = df(within)+df(between)+df(block) Df(block)=b-1 = number of blocks -1")
44
ANOVA table Source df SS MS F-ratio Between k-1 SSBt MSBt=SSBt/(k-1) Block b-1 SSBl MSBl= SSBl/(b-1) Within n-k-b+1 SSW MSW=SSW/(n-k-b+1) F=MSBt/MSW Total n-1 SST
 Block b-1 SSBl MSBl= SSBl/(b-1) Within n-k-b+1 SSW MSW=SSW/(n-k-b+1) F=MSBt/MSW Total n-1 SST")
45
Example (plant height) Low AcidHigh AcidControlBlock Mean Block11.581.102.471.717 Block21.151.052.151.450 Block31.270.501.461.077 Block41.251.002.361.537 Block51.001.501.001.167 n555 Trt mean1.251.031.888
 Low AcidHigh AcidControlBlock Mean Block Block Block Block Block n555 Trt mean")
46
Build ANOVA table Grand mean = 1.389 SSBt (SS treatment) 5(1.25-1.389) 2 + …+5(1.888-1.389) 2 =1.986 –MSBt = 1.986/(3-1)=.993 SSBl (SS block) 3(1.717-1.389) 2 + …+3(1.167- 1.389) 2 =0.840 –MSBl = 0.840/(5-1)=.210
 5( ) 2 + …+5( ) 2 =1.986 –MSBt = 1.986/(3-1)=.993 SSBl (SS block) 3( ) 2 + …+3( ) 2 =0.840 –MSBl = 0.840/(5-1)=.210")
47
SSW = SST – SSBt – SSBl = 1.452 df(SSW) = 14-2-4 = 8, MSW = 1.452/8=0.182 F s = MSBt / MSW =.993/.182 = 5.47 df for numerator=2, df for denominator=8 0.02 < P-value < 0.05 Reject H 0 at the significance level α=0.05. At the significance level α=0.05 there is enough evidence to say that the acid content has an influence on the growth of alfalfa plants.





>")


>")






 stanowi rozszerzenie testu t-Studenta w przypadku porównywanie większej liczby grup. Podział na grupy (czyli.>")





