Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Wykład 13 Estymacja wartości oczekiwanej zmiennej zależnej.
``Pasmo’’ ufności dla prostej regresji Przedziały predykcyjne Analiza wariancji

2
Estymacja E(Yh) E(Yh) = μh = β0 + β1Xh, wartość oczekiwana Y gdy X=Xh
estymujemy E(Yh) za pomocą = b0 + b1Xh
 za pomocą. = b0 + b1Xh.")
3
Teoria estymacji E(Yh)
ma rozkład normalny o wartości oczekiwanej μh (jest estymatorem nieobciążonym) i wariancji σ2( )=
 i wariancji σ2( )=")
4
Toria estymacji E(Yh) (2)
Normalność wynika z faktu, że = b0 + b1Xh jest liniową kombinacją Yi

5
Estymujemy σ2( ) za pomoca
t= ~ t(n-2)
")
6
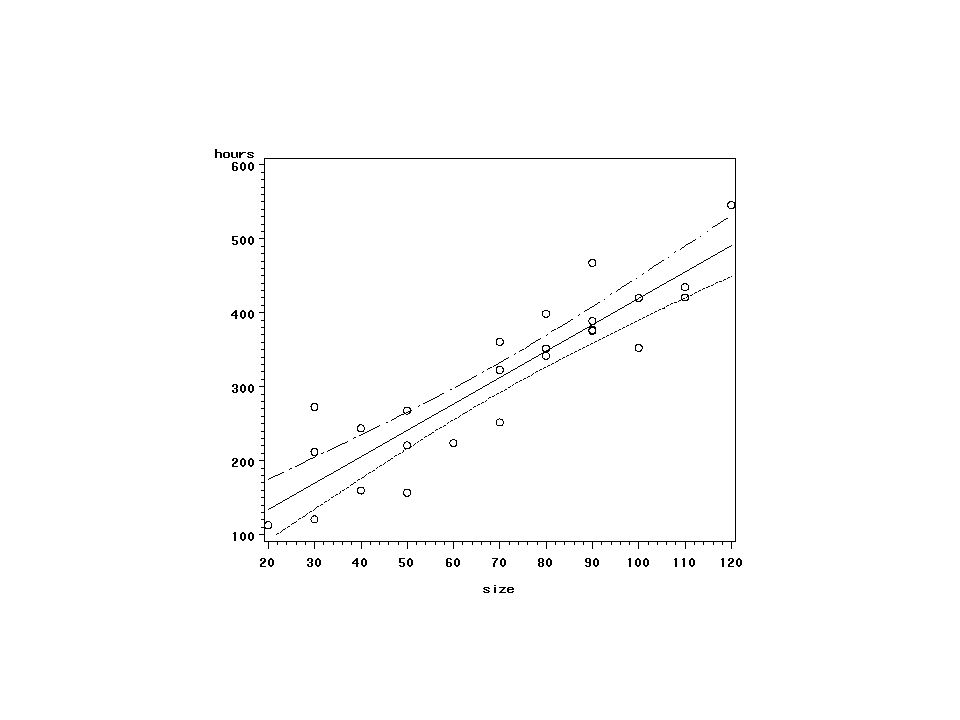
95% przedział ufności dla E(Yh)
± tc s( ) gdzie tc = t(.025, n-2) a s( ) =
 gdzie tc = t(.025, n-2) a s( ) =")
7
data a1; infile ‘../data/ch01ta01.dat'; input size hours; data a2; size=65; output; size=100; output; data a3; set a1 a2; proc print data=a3; proc reg data=a3; model hours=size/clm; run;

8
Dep Var Predicted Obs size hours Value Std Error Mean Predict % CL Mean

9
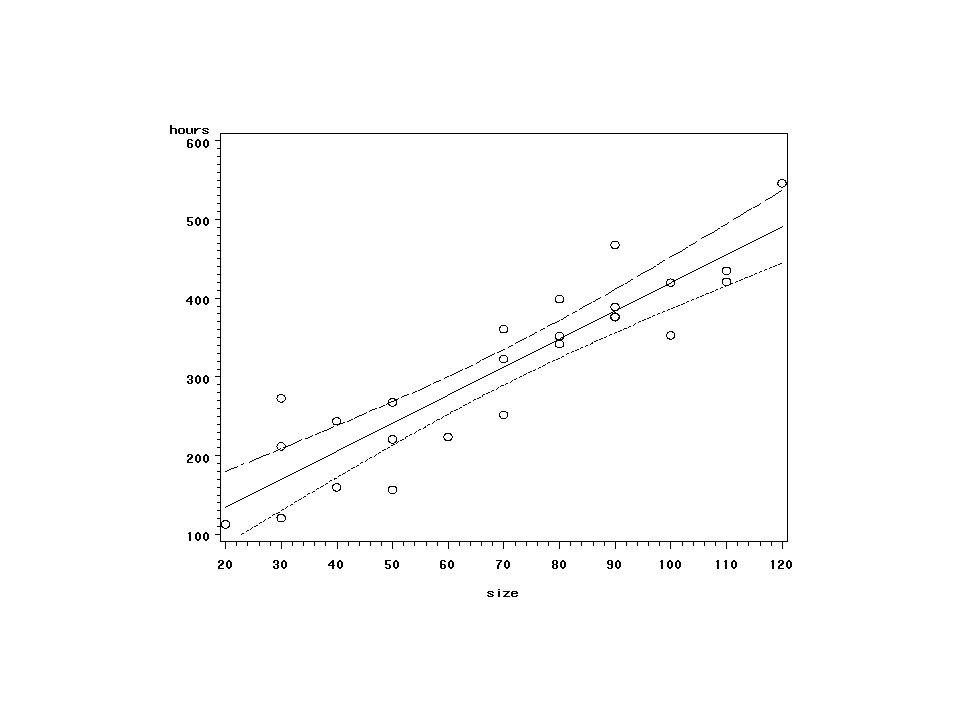
``Pasmo’’ ufności dla prostej regresji
± Ws( ) gdzie W2=2F(1-α; 2, n-2) Wartości krytyczne leżą na hiperboli
 gdzie W2=2F(1-α; 2, n-2) Wartości krytyczne leżą na hiperboli.")
10
``Pasmo’’ ufności dla prostej regresji
``Pasmo’’ ufności związane jest z obszarem ufności dla (β0, β1 ), który jest elipsą. Możemy obliczyć wartość alfa, dla której odpowiednie tc da te same wyniki Zajdziemy W2 i odpowiednie alfa dla tc, tak aby W = tc
, który jest elipsą. Możemy obliczyć wartość alfa, dla której odpowiednie tc da te same wyniki. Zajdziemy W2 i odpowiednie alfa dla tc, tak aby W = tc.")
11
data a1; n=25; alpha=.10; dfn=2; dfd=n-2; w2=2*finv(1-alpha,dfn,dfd); w=sqrt(w2); alphat=2*(1-probt(w,dfd)); tc=tinv(1-alphat/2,dfd); output; proc print data=a1; run;
; output; proc print data=a1; run;")
12
Obs n alpha dfn dfd w w alphat tc

13
data a2; infile‘../data/ch01ta01.dat'; input size hours;
symbol1 v=circle i=rlclm97; proc gplot data=a2; plot hours*size; run;

15
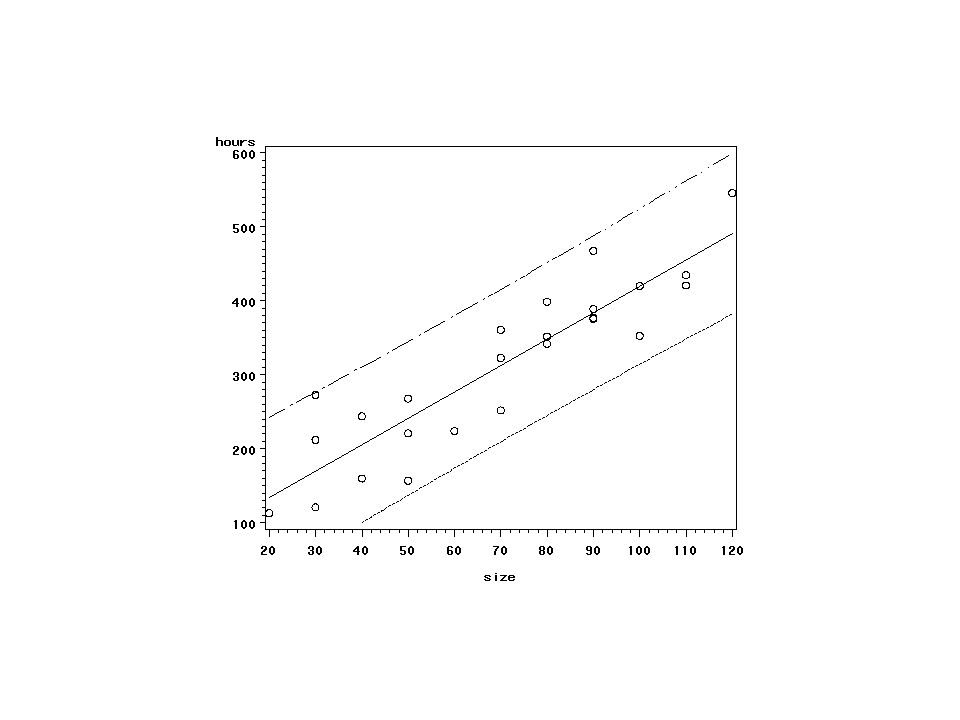
Predykcja Yh(new) Yh = β0 + β1Xh + ξh Var(Yh - )=Var Yh + Var = σ2+Var
S2(pred)= (Yh )/s(pred) ~ t(n-2)
= (Yh - )/s(pred) ~ t(n-2)")
16
data a1; infile ‘../data/ch01ta01.dat'; input size hours; data a2; size=65; output; size=100; output; data a3; set a1 a2; proc print data=a3; proc reg data=a3; model hours=size/cli; run;

17
Dep Var Predicted Obs size hours Value Std Error Mean Predict % CL Predict

18
Uwagi Błąd standardowy (Std Error Mean Predict)na tym wydruku to, s2( ), a nie s2(pred) Przedział predykcyjny jest szerszy (często znacznie) niż przedział ufności dla wartości oczekiwanej
 niż przedział ufności dla wartości oczekiwanej.")
19
95% przedział ufności dla E(Yh) i 95% przedział predykcyjny dla Yh
± tc s( ) ± tc s(pred) gdzie tc = t(.025, n-2)
 ± tc s(pred) gdzie tc = t(.025, n-2)")
20
data a1; infile ‘. /data/ch01ta01
data a1; infile ‘../data/ch01ta01.dat'; input size hours; symbol1 v=circle i=rlclm95; proc gplot data=a1; plot hours*size; run; symbol1 v=circle i=rlcli95; proc gplot data=a1; plot hours*size; run;quit;

23
Analiza wariancji (ANOVA)
(Całkowity) rozrzut Y opisujemy za pomocą Σ(Yi – )2 Rozrzut ten wynika z dwóch przyczyn Zależności od X (model) Zakłóceń losowych
 rozrzut Y opisujemy za pomocą Σ(Yi – )2. Rozrzut ten wynika z dwóch przyczyn. Zależności od X (model) Zakłóceń losowych.")
24
ANOVA (Total) SST = Σ(Yi – )2 dfT = n-1 MST = SST/dfT
 SST = Σ(Yi – )2 dfT = n-1 MST = SST/dfT")
25
ANOVA (Total) (2) MST to zwykły estymator wariancji Y gdy nie ma zmiennych wyjaśniających SAS (w wersji angileskiej) używa nazwy Corrected Total Nieskorygowana suma kwadratów to ΣYi2

26
ANOVA (Model) SSM = Σ( )2 dfM = 1 (za nachylenie) MSM = SSM/dfM
 SSM = Σ( - )2 dfM = 1 (za nachylenie) MSM = SSM/dfM")
27
ANOVA (Error) SSE = Σ(Yi – )2 dfE = n-2 MSE = SSE/dfE
MSE jest estymatorem warunkowej wariancji Y, przy ustalonym X

28
ANOVA Source df SS MS Model 1 Σ( - )2 SSM/dfM
Error n-2 Σ(Yi – ) SSE/dfE Total n-1 Σ(Yi – ) SST/dfT
2 SSE/dfE. Total n-1 Σ(Yi – )2 SST/dfT.")
29
ANOVA (2) Source df SS MS F P Model 1 SSM MSM MSM/MSE .nn
Error n-2 SSE MSE Total n-1

30
Wartości oczekiwane MSM, MSE to zmienne losowe
E(MSM) = σ2 + β12Σ(Xi – )2 E(MSE) = σ2 Gdy H0 zachodzi, β1 = 0, E(MSM) = E(MSE)
 = σ2 + β12Σ(Xi – )2. E(MSE) = σ2. Gdy H0 zachodzi, β1 = 0, E(MSM) = E(MSE)")
31
Test F F=MSM/MSE ~ F(dfM, dfE) = F(1, n-2)
Gdy H0 nie zachodzi, β i MSM jest zwykle większe niż MSE Odrzucamy H0 dla dużych wartości F: F F(α, dfM, dfE) = F(.05, 1, n-2) W praktyce używamy p-wartości
 = F(.05, 1, n-2) W praktyce używamy p-wartości.")
32
Test F (2) Gdy H0 nie zachodzi, statystyka F ma niecentralny rozkład F
Jest to podstawą do obliczeń mocy Przypomnijmy, że t = b1/s(b1) testuje H0 Można pokazać, że t2 = F Oba testy zwracają te same p-wartości
 testuje H0. Można pokazać, że t2 = F. Oba testy zwracają te same p-wartości.")
33
data a1; infile ‘h:/STAT512/ch01ta01.txt'; input size hours; proc reg data=a1; model hours=size; run;

34
Sum of Mean Source DF Squares Square Model Error C Total F Value Pr > F <.0001

35
Par St Var DF Est Err t Pr>|t| Int size <.0001

36
Ogólne testy liniowe Porównujemy dwa modele
Yi = β0 + β1Xi + ξi (model pełny) Yi = β0 + ξi (model zredukowany) Porównujemy za pomocą SSEs: SSE(F), SSE(R) F=((SSE(R) - SSE(F))/(dfE(R) - dfE(F)))/ MSE(F)
 Yi = β0 + ξi (model zredukowany) Porównujemy za pomocą SSEs: SSE(F), SSE(R) F=((SSE(R) - SSE(F))/(dfE(R) - dfE(F)))/ MSE(F)")
37
Prosta regresja liniowa
SSE(R)= Σ(Yi-b0)2= Σ(Yi- )2=SST SSE(F)=SSE dfE(R)=n-1, dfE(F)=n-2, dfE(R )-dfE(F )=1 F=(SST-SSE)/MSE=SSM/MSE
= Σ(Yi-b0)2= Σ(Yi- )2=SST. SSE(F)=SSE. dfE(R)=n-1, dfE(F)=n-2, dfE(R )-dfE(F )=1. F=(SST-SSE)/MSE=SSM/MSE.")
38
R2 , r2 r – klasyczny estymator współczynnika korelacji
r2 = R2 =SSM/SST = 1 – SSE/SST Rozrzut wyjaśniony i niewyjaśniony

39
Sum of Mean Source DF Squares Square Model Error C Total F Value Pr > F <.0001

40
R-Square (SAS) = SSM/SST = /307203 Adj R-Sq (SAS) =1-MSE/MST =1-2383/(307203/24)
 =1-MSE/MST. =1-2383/(307203/24) .")
Podobne prezentacje




>")


>")





 zmiennej>")





