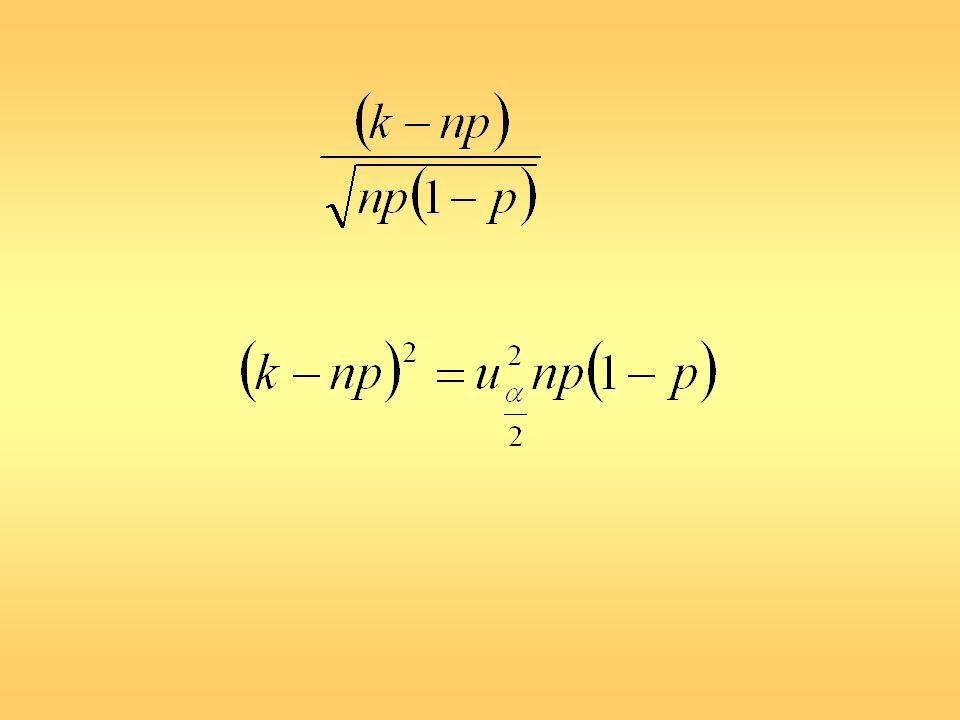Pobierz prezentację
This is a modal window.
1
ESTYMACJA PRZEDZIAŁOWA

2
Przedział ufności dla wartości średniej m populacji.

3
Przedział ufności dla wartości średniej m populacji.
Algorytm Model I Populacja ma rozkład N(m, σ), wartość przeciętna m – nieznany parametr, odchylenie standardowe σ – znany parametr. wartość odczytaną z tablicy kwantyli rozkładu N(0,1).
, wartość przeciętna. m – nieznany parametr, odchylenie standardowe. σ – znany parametr. wartość odczytaną z tablicy kwantyli rozkładu N(0,1).")
4
Przedział ufności dla wartości średniej m populacji.
Algorytm Model II Populacja ma rozkład N(m, σ), m, σ – nieznane parametry, próba mała - n 30 . wartość kwantyla rzędu rozkładu Studenta o n-1 stopniach swobody
, m, σ – nieznane parametry, próba mała - n 30 . wartość kwantyla rzędu rozkładu Studenta o n-1 stopniach swobody.")
5
Przedział ufności dla wartości średniej m populacji.
Algorytm Model III Populacja ma rozkład N(m, σ) bądź dowolny inny o średniej m i o wariancji skończonej S2 = σ 2, m, σ – nieznane parametry, próba duża - n > 30 . wartość odczytaną z tablicy kwantyli rozkładu N(0,1).
 bądź dowolny inny o średniej m i o wariancji skończonej. S2 = σ 2, m, σ – nieznane parametry, próba duża - n > 30 . wartość odczytaną z tablicy kwantyli rozkładu N(0,1).")
6
dla odchylenia standardowego
Przedział ufności dla wariancji i odchylenia standardowego σ populacji. Model I Algorytm Dana jest populacja generalna o rozkładzie normalnym N(m, σ); parametry m i σ są nieznane. Należy oszacować wariancję populacji σ 2 , n 30 . są odpowiednimi kwantylami rozkładu 2 o n-1 stopniach swobody dla wariancji dla odchylenia standardowego
; parametry m i σ są nieznane. Należy oszacować wariancję populacji σ 2 , n 30 . są odpowiednimi kwantylami rozkładu 2 o n-1 stopniach swobody. dla wariancji. dla odchylenia standardowego.")
7
Przedział ufności dla wariancji i odchylenia standardowego σ populacji.
Model II Algorytm Dana jest populacja generalna o rozkładzie normalnym N(m, σ); parametry m i σ są nieznane, n > 30 . wartość odczytaną z tablicy kwantyli 1 – ½ rozkładu N(0,1). przedział ufności dla parametru b – odchylenia standardowego
; parametry m i σ są nieznane, n > 30 . wartość odczytaną z tablicy kwantyli 1 – ½ rozkładu N(0,1). przedział ufności dla parametru b – odchylenia standardowego.")
8
Pobieramy wstępną próbę o liczności n0 i obliczamy:
Wielkość próby potrzebna do oszacowania parametru m z zadaną dokładnością. Szukamy na danym poziomie ufności 1 – takiej minimalnej liczby prób, aby otrzymać przedział ufności dla wartości przeciętnej o długości nie większej niż 2k. Zakładajmy, że badana populacja ma rozkład N(m,b), gdzie m i b są nieznanymi parametrami. Pobieramy wstępną próbę o liczności n0 i obliczamy:
, gdzie m i b są nieznanymi parametrami. Pobieramy wstępną próbę o liczności n0 i obliczamy:")
9
Jeżeli r n0, to pozostajemy przy wybranej próbce o liczności n0.
Jeżeli r > n0, to do próbki wstępnej dobieramy jeszcze co najmniej n1 elementów, gdzie n1 = [r] - n0 +1. W przypadku, gdy znamy wartość σ rozkładu populacji, możemy wyznaczyć liczność próby n bezpośrednio z nierówności

13
Przedziały ufności dla parametru p w rozkładzie dwumianowym

14
Przedziały ufności dla parametru p w rozkładzie dwumianowym

17
Testy parametryczne Populacja generalna ma rozkład N(m,), odchylenie standardowe jest znane. Nieznany jest parametr m, dla którego stawiamy hipotezę H0: m=m0, przeciwko hipotezie H1:
, odchylenie standardowe jest znane. Nieznany jest parametr m, dla którego stawiamy hipotezę H0: m=m0, przeciwko hipotezie H1:")
18
Populacja generalna ma rozkład N(m,), odchylenie standardowe nie jest znane. Hipoteza H0: m=m0, przeciwko hipotezie H1:

19
Testy dla wariancji H0: H1:

20
Dla dużych n

21
DZIĘKUJĘ ZA UWAGĘ