Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Analiza skupień – czyli grupowanie danych podobnych do siebie
Agnieszka Nowak - Brzezińska

2
Inne metody analizy danych DM
Metody eksploracji danych odkrywanie asocjacji odkrywanie wzorców sekwencji klasyfikacja analiza skupień - grupowanie szeregi czasowe wykrywanie zmian i odchyleń Grupowanie jest to podział zbioru obiektów na podzbiory taki by podobieństwo obiektów należących do jednego podzbioru było największe a obiektów należących do różnych podzbiorów najmniejsze.

3
Grupowanie – analiza skupień
Na czym polega grupowanie ? Obiekt jest przydzielony do skupienia, którego środek ciężkości leży najbliżej w sensie odległości euklidesowej.

4
Analiza skupień – cluster analysis
Uczenie nienadzorowane dany jest zbiór uczący, w którym obiekty nie są poklasyfikowane celem jest wykrycie nieznanych klasyfikacji, podobieństw między obiektami jak znajdować podobieństwo ? Miary odległości, Miary podobieństwa. X4 : X22:

6
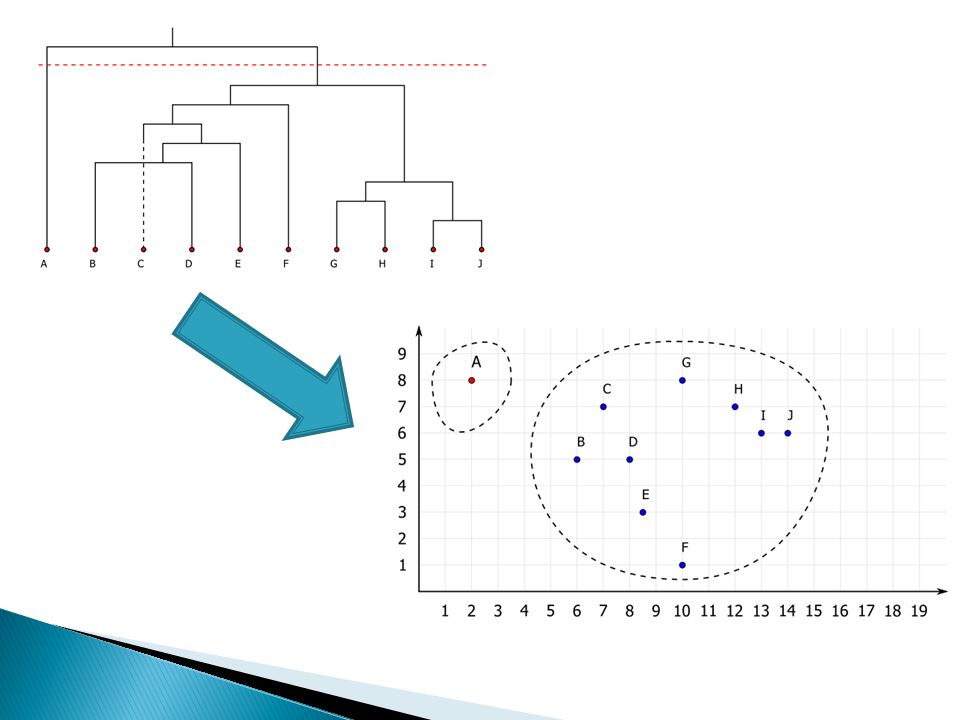
Analiza skupień – przykład

7
Klasyfikacja - czyli podział zbiorów obiektów na skupienia.
Analiza skupień – to proces podziału danych na podzbiory zwane klasami (skupieniami) z punktu widzenia określonego kryterium Klasyfikacja - czyli podział zbiorów obiektów na skupienia. dany jest zbiór uczący, w którym obiekty nie są poklasyfikowane, celem jest wykrycie nieznanych klasyfikacji, podobieństw między obiektami. Powstałe grupy (skupienia) są zespołami obiektów badanej serii bardziej podobnych do siebie (wewnątrz grupy) niż do pozostałych obiektów (między grupami).
 z punktu widzenia określonego kryterium. Klasyfikacja - czyli podział zbiorów obiektów na skupienia. dany jest zbiór uczący, w którym obiekty nie są poklasyfikowane, celem jest wykrycie nieznanych klasyfikacji, podobieństw między obiektami. Powstałe grupy (skupienia) są zespołami obiektów badanej serii bardziej podobnych do siebie (wewnątrz grupy) niż do pozostałych obiektów (między grupami).")
8
ustalenie standardu opisu badanego obiektu – zespołu
Warunki: ustalenie standardu opisu badanego obiektu – zespołu diagnostycznych cech, które dobrze opisują zmienność badanych, określenie sposobu porównywania obiektów. Inność (rozróżnialność obiektów). Można określić na dwa sposoby: jako różnicę (czyli odległość d), lub z drugiej strony jako podobieństwo p.
. Można określić na dwa sposoby: jako różnicę (czyli odległość d), lub z drugiej strony. jako podobieństwo p.")
9
Odległość euklidesowa
Metody obliczania odległości i podobieństwa Nazwa Wzór opis Odległość miejska wartość bezwzględna z prostej różnicy między wartościami i-tych cech dla badanych obiektów x i y Odległość euklidesowa pierwiastek z kwadratu różnicy między wartościami cech dla badanych obiektów x i y Odległość Czebyszewa największa różnica między znormalizowanymi cechami (znormalizowanymi, aby ich wartości były porównywalne) badanych obiektów x i y gdzie: xi,yi - to wektory wartości cech porównywanych obiektów w przestrzeni p-wymiarowej, gdzie odpowiednio wektory wartości to: oraz
 badanych obiektów x i y. gdzie: xi,yi - to wektory wartości cech porównywanych obiektów w przestrzeni p-wymiarowej, gdzie odpowiednio wektory wartości to: oraz.")
10
Metody obliczania odległości i podobieństwa cd.
Metody obliczania podobieństw (współczynników podobieństwa) są mniej liczne. Dwa najczęściej używane współczynniki podobieństwa to: współczynnik korelacji liniowej Pearsona odległość kątowa Im większa wartość współczynnika podobieństwa, tym bardziej podobne do siebie są badane obiekty, zaś przy maksymalnej wartości p = 1 obiekty stają się identyczne.
 są mniej liczne. Dwa najczęściej używane współczynniki podobieństwa to: współczynnik korelacji liniowej Pearsona. odległość kątowa. Im większa wartość współczynnika podobieństwa, tym bardziej podobne do siebie są badane obiekty, zaś przy maksymalnej wartości p = 1 obiekty stają się identyczne.")
11
graficzne - na przykład diagramy Czekanowskiego,
Rodzaje algorytmów: graficzne - na przykład diagramy Czekanowskiego, hierarchiczne (aglomeracyjne, deglomeracyjne), k-optymalizacyjne –(nie-hierarchiczne) seria dzielona jest na k zbiorów obiektów, przy czym obiekt może należeć tylko do jednego ze zbiorów, a liczba k jest zwykle podawana przez badacza.
, k-optymalizacyjne –(nie-hierarchiczne) seria dzielona jest na k zbiorów obiektów, przy czym obiekt może należeć tylko do jednego ze zbiorów, a liczba k jest zwykle podawana przez badacza.")
12
1. minimalizacja zmienności wewnątrz skupień,
Algorytmy k-optymalizacyjne... Obiekt jest przydzielony do skupienia, którego środek ciężkości leży najbliżej w sensie odległości euklidesowej. Cel klasyfikacji: 1. minimalizacja zmienności wewnątrz skupień, 2. maksymalizacja zmienności między skupieniami. Przebieg: 1. Wyznaczenie k początkowych skupień przez badacza 2. Przydzielenie obiektów do najbliższych im skupień Kolejno (iteracyjnie) powtarzane przenoszenie obiektów między skupieniami tak, aby uzyskać najlepszy podział na grupy.
 powtarzane przenoszenie obiektów między skupieniami tak, aby uzyskać najlepszy podział na grupy.")
14
nastąpi stabilizacja struktury klas.
Warunek końca procesu optymalizacji: zostanie przekroczona ustalona z góry maksymalna liczba iteracji (kroków), lub nastąpi stabilizacja struktury klas. Kryterium oceny jakości podziału serii obiektów na grupy jest tzw. funkcja podziału mająca zwykle postać sumy odległości euklidesowych obiektów od środków ciężkości właściwych im grup. gdzie: to odległość euklidesowa danego punktu p od centrum grupy
, lub. nastąpi stabilizacja struktury klas. Kryterium oceny jakości podziału serii obiektów na grupy jest tzw. funkcja podziału mająca zwykle postać sumy odległości euklidesowych obiektów od środków ciężkości właściwych im grup. gdzie: to odległość euklidesowa danego punktu p od centrum grupy.")
15
Tworzenie skupień – co jest potrzebne ?
Analiza skupień – popularne algorytmy algorytm k-means algorytm k-medoids Tworzenie skupień – co jest potrzebne ? Zbiór obiektów opisanych atrybutami, Doprowadzenie do porównywalności atrybutów (standaryzacja,normalizacja), Wybór miary odległości (odległość Euklidesowa, metryka Czebyszewa, odległość miejska, odległość potęgowa, i inne).
, Wybór miary odległości (odległość Euklidesowa, metryka Czebyszewa, odległość miejska, odległość potęgowa, i inne).")
16
K-średnich

17
Opcje wyboru wstępnych centrów skupień mogą być następujące:
Liczba k – jak ją określić ? Opcje wyboru wstępnych centrów skupień mogą być następujące: losowe przypisanie elementów do k zadeklarowanych skupień, Maksymalizacja odległości miedzy skupieniami, Obserwacje przy stałym interwale, Pierwsze k obserwacji

18
Obiekty to punkty w d-wymiarowej przestrzeni wektorowej.
ALGORYTM K-MEANS (K-ŚREDNICH) - [J. McQueen] Inicjalizacja – wykonać wstępny podział obiektów na k – skupień (wybór k – wiele możliwości) Obiekty to punkty w d-wymiarowej przestrzeni wektorowej. Centroid c:środek wszystkich punktów w skupieniu C Miara dopasowania do skupienia C: Miara dopasowania grupowania ogółem:
 - [J. McQueen] Inicjalizacja – wykonać wstępny podział obiektów na k – skupień (wybór k – wiele możliwości) Obiekty to punkty w d-wymiarowej przestrzeni wektorowej. Centroid c:środek wszystkich punktów w skupieniu C. Miara dopasowania do skupienia C: Miara dopasowania grupowania ogółem:")
19
Dzielimy zbiór na K grup w sposób losowy.
Pseudokod algorytmu (4 kroki): Dzielimy zbiór na K grup w sposób losowy. Liczymy środek (centroid) każdej grupy. Dokonujemy ponownego podziału obiektów, przypisując je do tej grupy, której środek leży najbliżej. 4. Powtarzamy od 2 póki następują zmiany przyporządkowania.
: Dzielimy zbiór na K grup w sposób losowy. Liczymy środek (centroid) każdej grupy. Dokonujemy ponownego podziału obiektów, przypisując je do tej grupy, której środek leży najbliżej. 4. Powtarzamy od 2 póki następują zmiany przyporządkowania.")
20
Przykład: K=2 Przydziel każdy obiekt do najbliżej grupy Wylicz nowe
środki skupień K=2 Kolejna iteracja Kolejna iteracja Losowo wybierz K obiektów jako wejściowe środki skupień Ponownie oblicz Środki skupień

21
Stosunkowo niewielka złożoność obliczeniowa, Prosta idea.
Ocena metody k-średnich: Zalety: Stosunkowo niewielka złożoność obliczeniowa, Prosta idea. Wady: Szum w danych i obiekty odległe mogą zniekształcać centroidy, Początkowy wybór wpływa na wyniki

22
Algorytm jest zbyt wrażliwy na tzw. obiekty odległe – outliers,
W czym tkwi problem z metodą k-średnich ? Algorytm jest zbyt wrażliwy na tzw. obiekty odległe – outliers, Metoda k-medoids –zamiast tworzyć centroidy (średnie z odległości) – tworzy medoidy – te obiekty ze zbioru n, które w danym skupieniu są najbardziej centralne – tzn. ich odległość od wszystkich pozostałych w danym skupieniu jest najmniejsza. PAM (Partitioning Around Medoids) – algorytm grupowania metodą k-reprezentantów.
 – tworzy medoidy – te obiekty ze zbioru n, które w danym skupieniu są najbardziej centralne – tzn. ich odległość od wszystkich pozostałych w danym skupieniu jest najmniejsza. PAM (Partitioning Around Medoids) – algorytm grupowania metodą k-reprezentantów.")
23
Rozszerzenie idei algorytmu k-means (modyfikacja algorytmu k-means)
ALGORYTM K-MEDOIDS [Kaufman & Rousseeuw, 1990r.] Rozszerzenie idei algorytmu k-means (modyfikacja algorytmu k-means) Cel – znaleźć reprezentatywne obiekty dla skupień, zwane medoidami. Punkty medoidalne są wymieniane z innymi, jeszcze nie wybranymi, tak aby polepszyć jakość grupowania. Parametry: Medoid mc: obiekt reprezentatywny w skupieniu C Miara dopasowania do skupienia C: Miara dopasowania grupowania ogółem:
 Cel – znaleźć reprezentatywne obiekty dla skupień, zwane medoidami. Punkty medoidalne są wymieniane z innymi, jeszcze nie wybranymi, tak aby polepszyć jakość grupowania. Parametry: Medoid mc: obiekt reprezentatywny w skupieniu C. Miara dopasowania do skupienia C: Miara dopasowania grupowania ogółem:")
24
K-medoidów

25
Wybrać k- obiektów reprezentatywnych (medoidów)
Przebieg algorytmu (5 kroków): Wybrać k- obiektów reprezentatywnych (medoidów) Dopasuj każdy z pozostałych (nie będących medoidami) obiektów do najbardziej podobnych klastrów i oblicz TDcurrent. Dla każdej pary (medoidM, nie-medoidN) oblicz wartość TDNM. Wybierz ten nie-medoidN, dla którego TDN M jest minimalne Jeśli TDNM jest mniejsze niż: Zamień N z M, Ustaw TDcurrent:= TDNM wróć do kroku 2 5. Koniec.
: Wybrać k- obiektów reprezentatywnych (medoidów) Dopasuj każdy z pozostałych (nie będących medoidami) obiektów do najbardziej podobnych klastrów i oblicz TDcurrent. Dla każdej pary (medoidM, nie-medoidN) oblicz wartość TDNM. Wybierz ten nie-medoidN, dla którego TDN M jest minimalne. Jeśli TDNM jest mniejsze niż: Zamień N z M, Ustaw TDcurrent:= TDNM. wróć do kroku Koniec.")
26
Typowy przebieg PAM – metodą k-medoid’ów
Total cost=20 Przydziel Każdy z pozostałych obiektów do najbliższego medoidu Odgórnie wybierz K obiektów jako początkowe MEDOIDY K=2 Powtarzaj dopóki są jakieś zmiany Losowo wybierz jeden obiekt Orandom Total cost=26 Oblicz Koszt zmiany Zamień obiekt bieżący z Orandom Jeśli to polepszy jakość grup

27
Początkowy wybór nie wpływa na wyniki Odporność na szum w danych Wady:
Ocena metody k-medoids Zalety: Dobrze sobie radzi z “ostańcami” (ang. outliers)– obiekty odległe, izolowane Początkowy wybór nie wpływa na wyniki Odporność na szum w danych Wady: Nie radzi sobie z dużymi zbiorami danych Wykonanie jest kosztowne dla dużych wartości n-obiektów i k-skupień.
– obiekty odległe, izolowane. Początkowy wybór nie wpływa na wyniki. Odporność na szum w danych. Wady: Nie radzi sobie z dużymi zbiorami danych. Wykonanie jest kosztowne dla dużych wartości n-obiektów i k-skupień.")
28
O(k(n-k)(n-k)) O(k(n-k)2)
Złożoność obliczeniowa: Algorytm k-means O(tnk) O(nk) gdzie: t – liczba iteracji k – liczba skupień n – liczba obiektów Algorytm k-medoids O(k(n-k)(n-k)) O(k(n-k)2)
 O(nk) gdzie: t – liczba iteracji. k – liczba skupień. n – liczba obiektów. Algorytm k-medoids. O(k(n-k)(n-k)) O(k(n-k)2)")
29
Porównanie obydwu metod:
Algorytm k-medoids jest bardziej wytrzymały (odporny) na szumy i odległe obiekty, Algorytm k-means jest tańszy (bardziej efektywny) pod względem czasu przetwarzania, K-means jest zbyt wrażliwy na obiekty odległe (ang. outliers) – co może zniekształcać dane, Zatem zamiast brać średnią wartość - bierze się najbardziej centralny obiekt jako punkt odniesienia (medoid).
 na szumy i odległe obiekty, Algorytm k-means jest tańszy (bardziej efektywny) pod względem czasu przetwarzania, K-means jest zbyt wrażliwy na obiekty odległe (ang. outliers) – co może zniekształcać dane, Zatem zamiast brać średnią wartość - bierze się najbardziej centralny obiekt jako punkt odniesienia (medoid).")
30
Metody hierarchiczne – aglomeracyjne

31
Przebieg grupowania AHC:
Przebieg grupowania obiektów w ramach metod aglomeracyjnych odbywa się w następujących krokach: Utwórz n klas zawierających pojedyncze obiekty. Oblicz wartość pewniej miary podobieństwa (odległości) dla wszystkich par klas. Połącz dwie klasy najbardziej podobne. Jeśli wszystkie obiekty należą do jednej klasy, to zakończ pracę. W przeciwnym przypadku przejdź do kroku 2.
 dla wszystkich par klas. Połącz dwie klasy najbardziej podobne. Jeśli wszystkie obiekty należą do jednej klasy, to zakończ pracę. W przeciwnym przypadku przejdź do kroku 2.")
32
Algorytm grupowania: Po każdej iteracji mamy coraz mniej grup,
Mając macierz D=[dij] (i,j = 1,2,...,n) wyznaczamy element najmniejszy (szukamy pary skupień najmniej odległych od siebie): dpq = min i,j {dij} (i,j = 1,2,...,n), p<q. Skupienia Gp i Gq łączymy w jedno nowe skupienie, nadając mu numer Gp:= Gp Gq. Z macierzy D usuwamy wiersz i kolumnę o numerach q oraz podstawiamy n:=n-1. Wyznaczamy odległości dpj (j=1,2,...,n) utworzonego skupienia Gp od wszystkich pozostałych skupień, stosownie do wybranej metody. Wartości dpj wstawia się do macierzy D w miejsce p-tego wiersza (w miejsce p-tej kolumny wstawiamy elementy djp). Powtarza się kroki 1-4 aż do momentu, gdy wszystkie obiekty utworzą jedno skupienie (tzn. gdy n=1). Po każdej iteracji mamy coraz mniej grup, coraz mniejszą macierz odległości.
 wyznaczamy element najmniejszy (szukamy pary skupień najmniej odległych od siebie): dpq = min i,j {dij} (i,j = 1,2,...,n), p<q. Skupienia Gp i Gq łączymy w jedno nowe skupienie, nadając mu numer. Gp:= Gp Gq. Z macierzy D usuwamy wiersz i kolumnę o numerach q oraz podstawiamy n:=n-1. Wyznaczamy odległości dpj (j=1,2,...,n) utworzonego skupienia Gp od wszystkich pozostałych skupień, stosownie do wybranej metody. Wartości dpj wstawia się do macierzy D w miejsce p-tego wiersza (w miejsce p-tej kolumny wstawiamy elementy djp). Powtarza się kroki 1-4 aż do momentu, gdy wszystkie obiekty utworzą jedno skupienie (tzn. gdy n=1). Po każdej iteracji mamy coraz mniej grup, coraz mniejszą macierz odległości.")
33
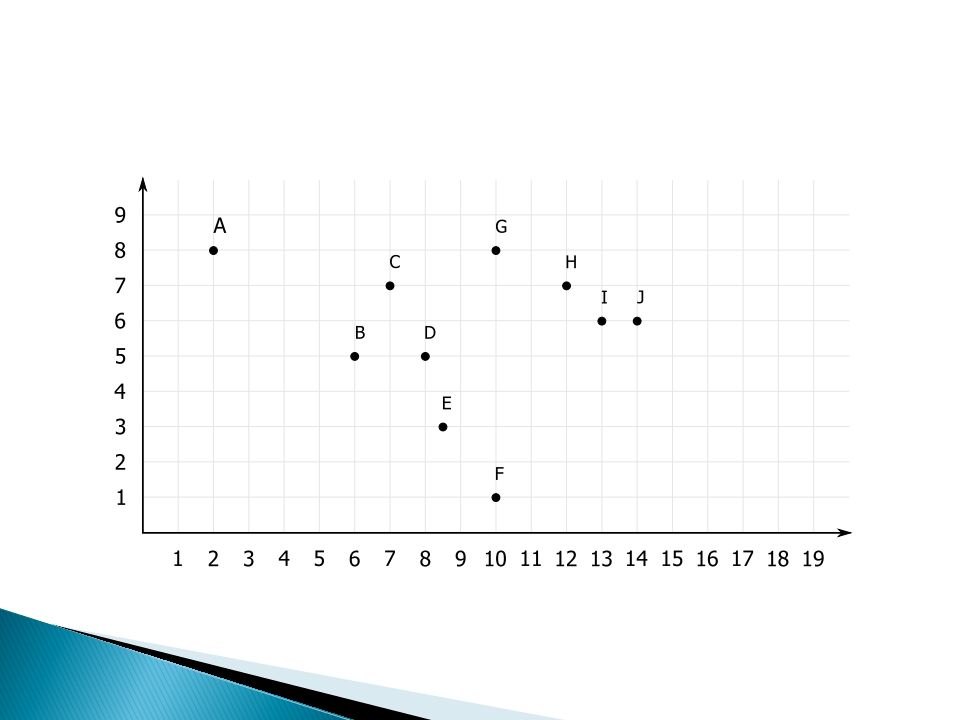
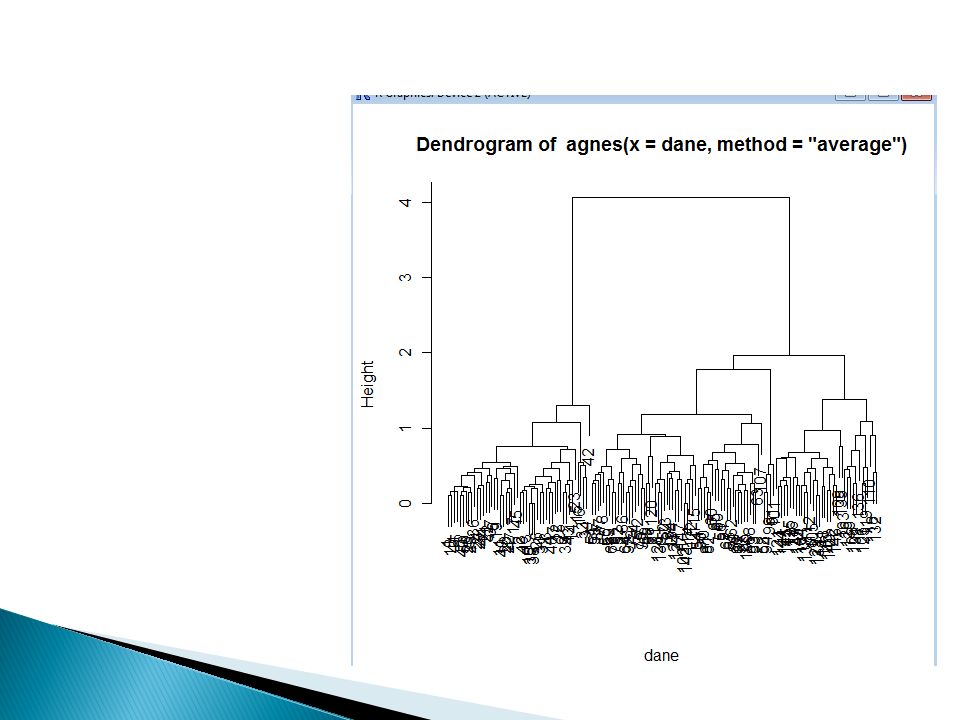
Graficzna ilustracja grupowania AHC
{o1,o2,o3,o4,o5,o6,o7,o8} o1 o2 o3 o4 o5 o6 o7 o8 Rys. Przykład dendrogramu

34
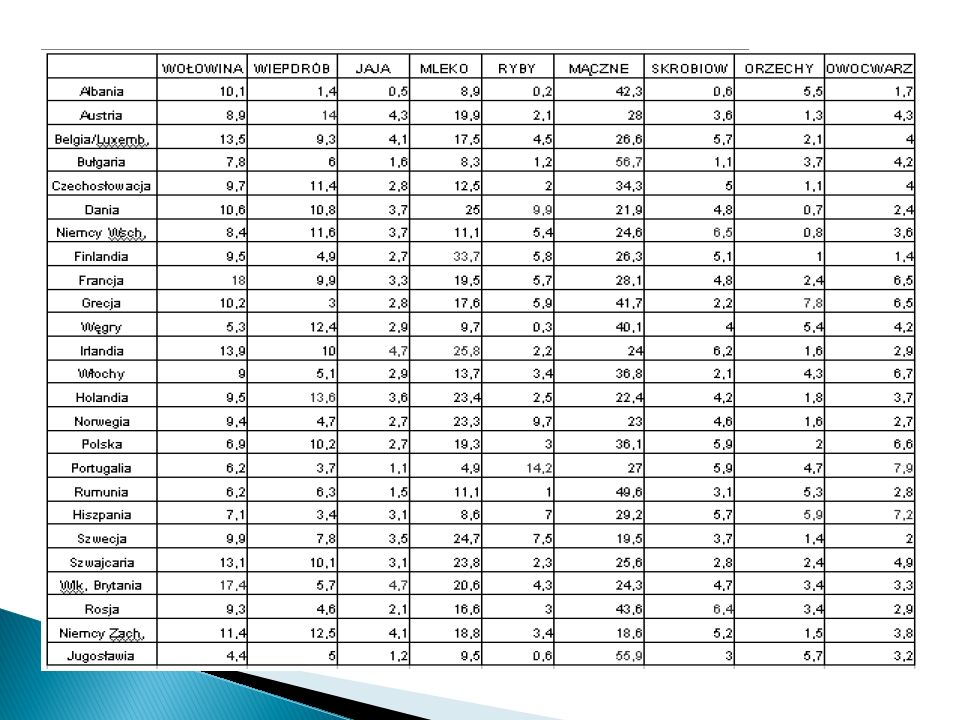
Surowe dane: (przykład)
VAR 1 VAR 2 1 3 2 8 5 4 6 7 9 10 Docelowo: Dużo więcej obiektów i dużo więcej cech te obiekty opisujących.

35
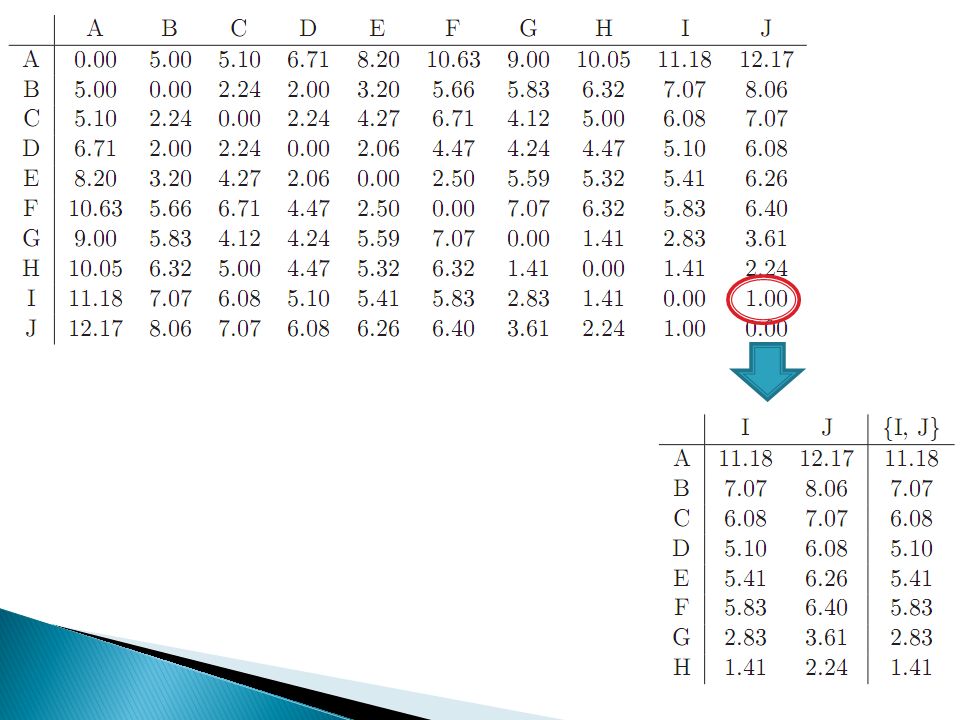
Macierz odległości euklidesowych (standaryzowanych)
P_1 P_2 P_3 P_4 P_5 P_6 P_7 P_8 P_9 P_10 P_ , ,00 2,00 5, ,12 1, ,83 6,08 6,40 P_2 5, ,40 7,00 1, ,21 5, ,00 8,49 4,00 P_3 4,00 6, ,47 5, ,00 3, ,10 2,24 5,00 P_4 2,00 7, , , ,12 2, ,62 6,08 8,06 P_5 5,10 1, ,83 7, ,71 5, ,00 7,81 3,00 P_6 4,12 7, ,00 4,12 6, , ,08 2,00 6,00 P_7 1,00 5, ,00 2,24 5, , ,39 5,10 5,83 P_8 5,83 3, ,10 7,62 2, ,08 5, ,71 1,00 P_9 6,08 8, ,24 6,08 7, ,00 5, , ,32 P_10 6,40 4, ,00 8,06 3, ,00 5, ,00 6,

36
1 iteracja 1 Szukaj minimalnej odległości... P_17 P_1 P_17 P_7 P_1 P_2
5 4 6,4 2 7 4,47 5.1 1 5.83 7.07 4.12 7.21 6.71 3 2.24 3.16 7.62 6.08 5.39 8.49 7.81 6.4 8.06 6 6.32 P_17 P_1 P_17 P_7 1 Szukaj minimalnej odległości...

37
2 iteracja Szukaj minimalnej odległości... P_25 P_25 1 P_17 P_2 P_3
5 3 6,4 2 7 4,47 1 5.83 7.07 3.16 7.21 4.12 6.71 5.39 5.1 7.62 6.08 8.49 2.24 7.81 4 8.06 6 6.32 P_25 P_25 P_2 P_5 1 Szukaj minimalnej odległości...

38
3 iteracja Szukaj minimalnej odległości... P_36 P_36 P_3 P_6 P_17 P_25
5 3 5,83 2 7 4,47 3.16 6.71 1 4.12 5.39 5.1 7.62 6.08 7.81 2.24 5.83 8.06 6 6.32 P_36 P_36 P_3 P_6 1 Szukaj minimalnej odległości...

39
4 iteracja Szukaj minimalnej odległości... P_8 P_10 P_17 P_25 P_36 P_4
5 3 5,83 2 7 4,12 5.39 5.1 7.62 7.81 6.08 6.71 5.83 8.06 1 6.32 P_810 P_810 P_8 P_10 1 Szukaj minimalnej odległości...

40
5 iteracja Szukaj minimalnej odległości... P_4 P_17 P_25 P_36 P_4
5 3 5,83 2 7 4,12 5.39 7.62 5.1 7.81 6.08 6.71 P_174 P_17 P_174 P_4 2 Szukaj minimalnej odległości...

41
6 iteracja Szukaj minimalnej odległości... P_174 P_25 P_36 P_810 P_9 5
5 3 5,83 5.39 2 5.1 7.81 6.71 P_25810 P_25810 P_25 P_810 2 Szukaj minimalnej odległości...

42
7 iteracja Szukaj minimalnej odległości... P_174 P_25810 P_36 P_9 5 3
5 3 5.1 6.71 2 P_369 P_369 P_36 P_9 2 Szukaj minimalnej odległości...

43
Powstanie jedna grupa P_17436925810
8 iteracja P_174369 P_174 P_25810 P_369 5 3 Powstanie jedna grupa P_ 9 iteracji algorytmu P_174369 P_174 P_369 3 Szukaj minimalnej odległości... P_174369 P_25810 5 9 iteracja Szukaj minimalnej odległości...

44
Przebieg aglomeracji Odległość Łączone obiekty: 1 P_1, P_7 P_2, P_5
Pojedyncze wiązanie Odległości euklidesowe Odległość Łączone obiekty: 1 P_1, P_7 P_2, P_5 P_3, P_6 P_8, P_10 2 P_1, P_7, P_4 P_2, P_5, P_8, P_10 P_3, P_6, P_9 3 P_1, P_7, P_4, P_3, P_6, P_9 5 P_1, P_7, P_4, P_3, P_6, P_9, P_2, P_5, P_8, P_10

45
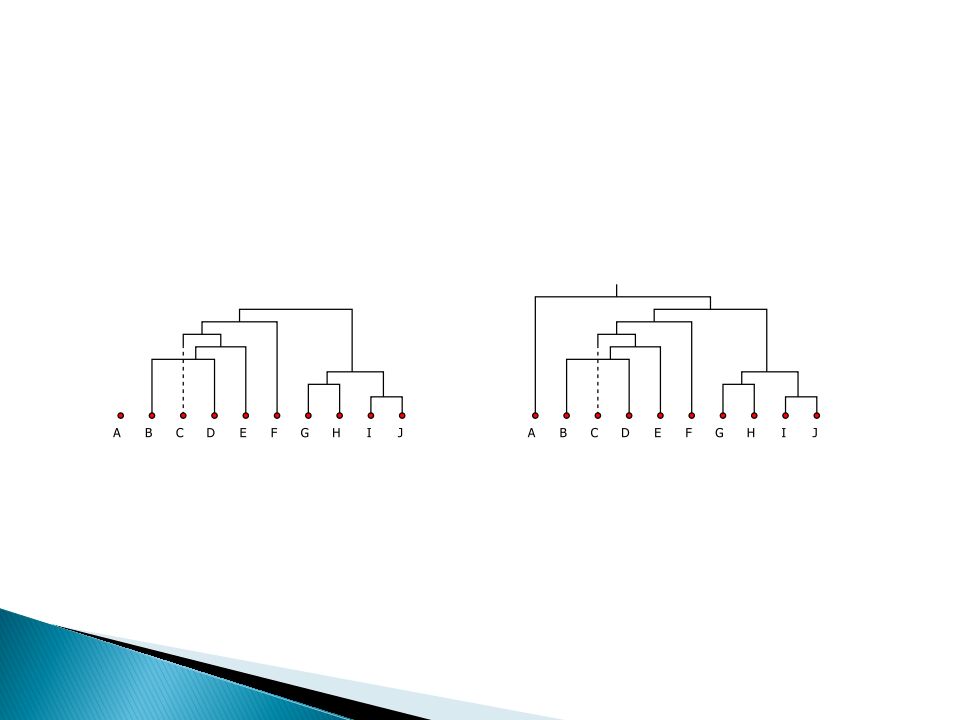
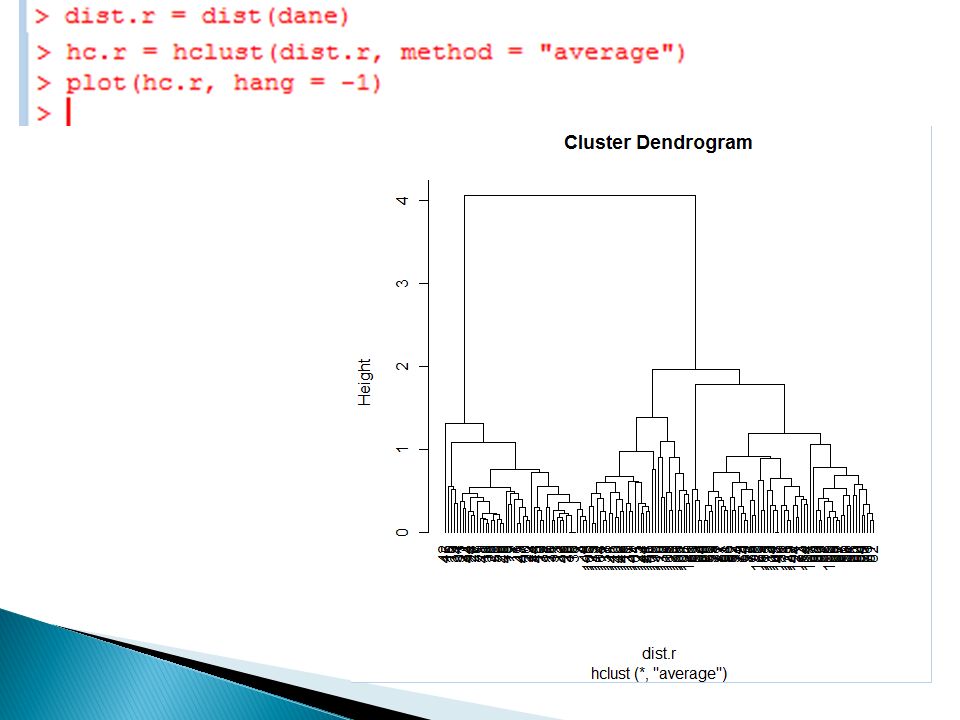
Dendrogram

46
Odległości międzygrupowe wybranych metod aglomeracyjnych
Metoda najbliższego sąsiedztwa Metoda najdalszego sąsiedztwa Metoda mediany

47
Metoda średniej grupowej
Odległości międzygrupowe...(c.d.) Metoda średniej grupowej Metoda środka ciężkości Metoda J.H. Warda
 Metoda średniej grupowej. Metoda środka ciężkości. Metoda J.H. Warda.")
48
Najbliższego sąsiedztwa Najdalszego sąsiedztwa
Ogólna formuła wyznaczania odległości podczas łączenia skupień Gp i Gq w nowe skupienie dla hierarchicznych procedur grupowania to: Wielkości ap, aq,b,c są parametrami przekształcenia charakterystycznymi dla różnych metod tworzenia skupień. Wartości tych parametrów są przedstawione w tabeli nr 1. Metoda ap aq b c Najbliższego sąsiedztwa 0,5 -0,5 Najdalszego sąsiedztwa Mediany -0,25 Średniej grupowej Środka ciężkości Warda

49
Wykres przebiegu aglomeracji:

50
Warunek zatrzymania aglomeracji – kiedy ?

56
Metody hierarchiczne - podziałowe

57
Aglomeracyjne tworzenie skupień kontra inne metody
HIERARCHICAL CLUSTERING - korzysta z macierzy odległości - tworzy drzewo obiektów (dendrogram) - nie wymaga podawania na wstępie liczby skupień Ale wymaga określenia warunku zakończenia algorytmu Wady AHC: - duża złożoność obliczeniowa – co najmniej O(n2) - k-means k-medoid AHC Złożoność Obliczeniowa O(tkn) O(kn) Wady Wrażliwość na obiekty odległe. Wymagana liczba k-skupień Wymaga podania liczby k-skupień Wymaga podania warunku końca, np. współczynnika maksymalnej opłacalności zalety Prosta struktura, stosunkowo mała złożoność obliczeniowa Bardziej efektywna niż k-means bo szuka reprezentanów i nie jest tak wrażliwa na obiekty odległe Nie wymaga podania liczby grup, bardziej efektywna i popularna Co najmniej O(n2) O(k(n-k)2)
 - nie wymaga podawania na wstępie liczby skupień. Ale wymaga określenia warunku zakończenia algorytmu. Wady AHC: - duża złożoność obliczeniowa – co najmniej O(n2) - k-means. k-medoid. AHC. Złożoność. Obliczeniowa. O(tkn) O(kn) Wady. Wrażliwość na obiekty odległe. Wymagana liczba k-skupień. Wymaga podania liczby k-skupień. Wymaga podania warunku końca, np. współczynnika maksymalnej opłacalności. zalety. Prosta struktura, stosunkowo mała złożoność obliczeniowa. Bardziej efektywna niż k-means bo szuka reprezentanów i nie jest tak wrażliwa na obiekty odległe. Nie wymaga podania liczby grup, bardziej efektywna i popularna. Co najmniej O(n2) O(k(n-k)2)")
60
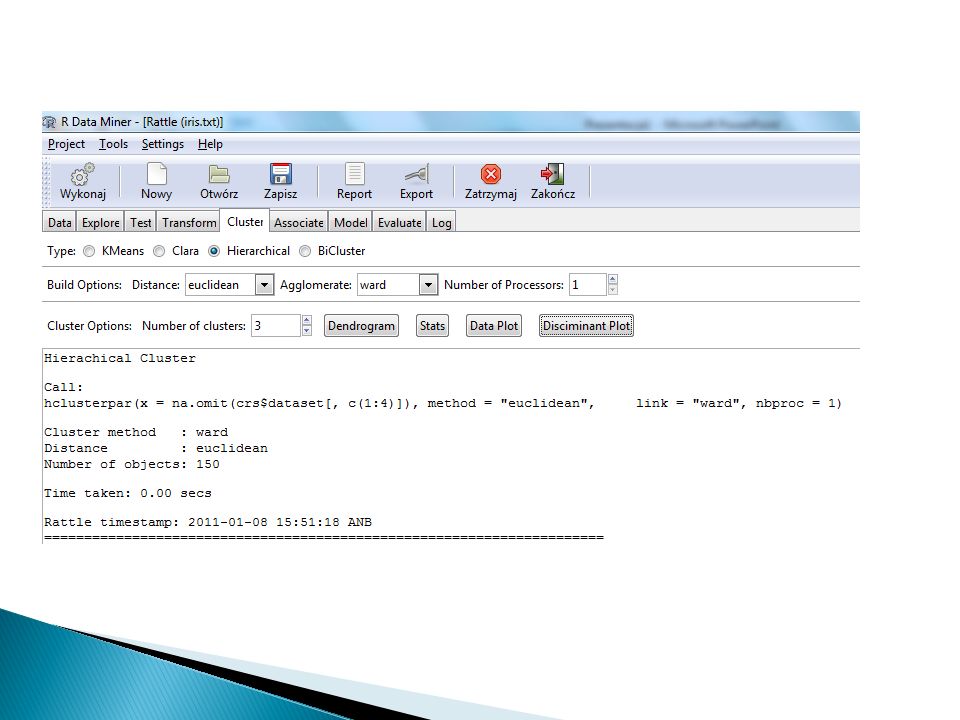
Jakie narzędzia ? Rattle R TraceIs MS Excel

61
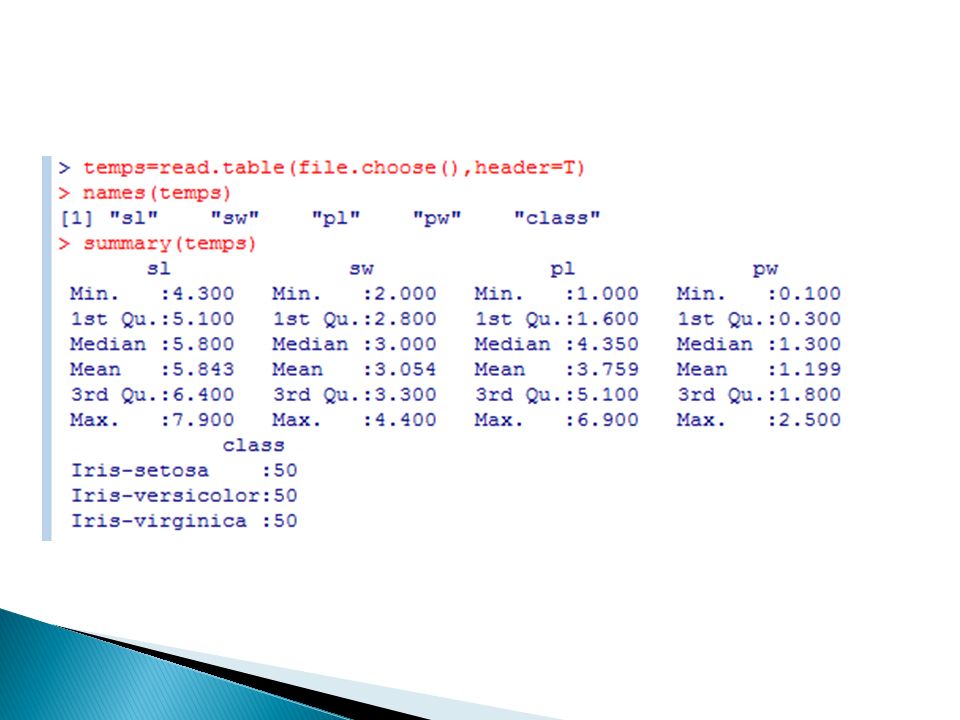
Rattle Krok 1: Załadowanie danych

62
Metody niehierarchiczne

63
Krok 2: wybór liczby skupień

64
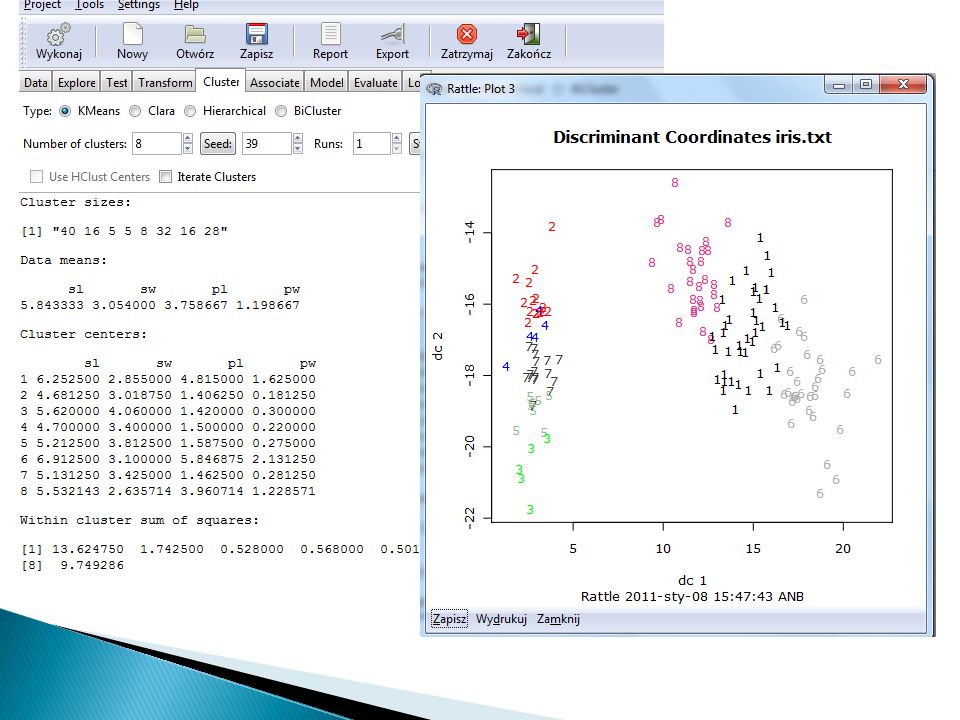
K=3

66
K=8

67
K=2

68
K=2

69
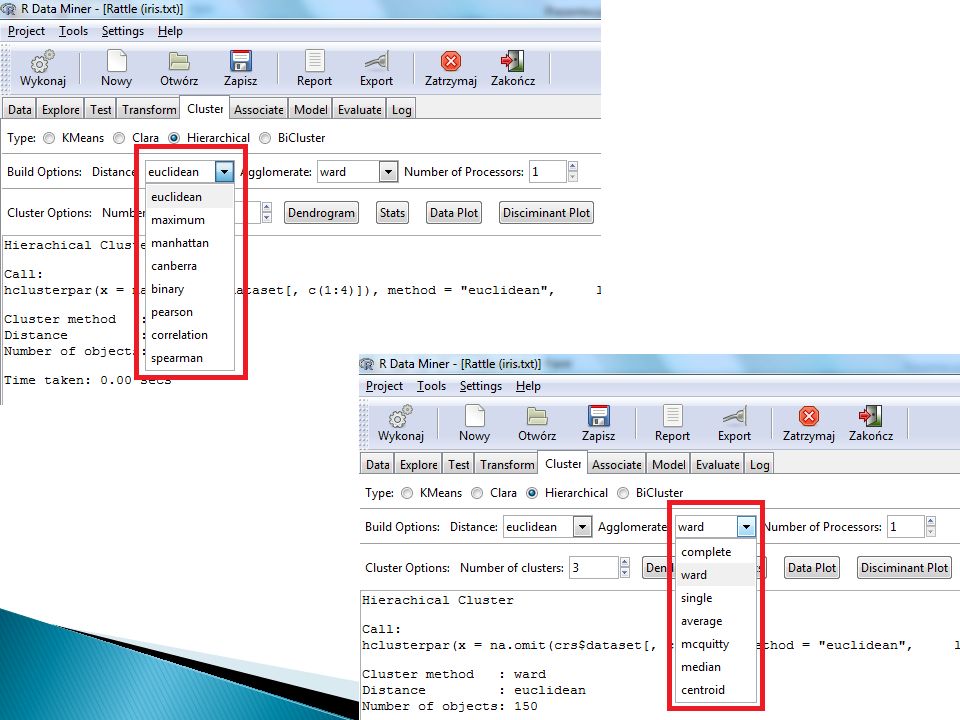
Metody hierarchiczne

72
K=3

73
K=3

74
Mclust- Plot Model-Based Clustering Results
plot.Mclust(x, data, dimens = c(1, 2), scale = FALSE, ...) Parametry: x - rezultat. data – dane wejściowe. dimens – wymiary przestrzeni danych. scale – wartość TRUE lub FALSE. Domyślnie „false” – oznacza ze wybrane wymiary nie mają być prezentowane w tej samej skali. Wartość: Możliwe są opcje: wartość BIC dla wybranej licby skupień. Jeśli dane są wielowymiarowe (>2)prezentowane są mieszaniny współrzędnych i prezentowane są parami – wszystkie kombinacje
, scale = FALSE, ...) Parametry: x - rezultat. data – dane wejściowe. dimens – wymiary przestrzeni danych. scale – wartość TRUE lub FALSE. Domyślnie „false – oznacza ze wybrane wymiary nie mają być prezentowane w tej samej skali. Wartość: Możliwe są opcje: wartość BIC dla wybranej licby skupień. Jeśli dane są wielowymiarowe (>2)prezentowane są mieszaniny współrzędnych i prezentowane są parami – wszystkie kombinacje.")
75
Hc - Model-based Hierarchical Clustering
Agglomerative hierarchical clustering based on maximum likelihood criteria for MVN mixture models parameterized by eigenvalue decomposition. hc(modelName, data, ...) modelName – typ modelu: "E" : equal variance (one-dimensional) "V" : spherical, variable variance (one-dimensional) "EII": spherical, equal volume "VII": spherical, unequal volume "EEE": ellipsoidal, equal volume, shape, and orientation "VVV": ellipsoidal, varying volume, shape, and orientation Data – dane (muszą być ilościowe)
 modelName – typ modelu: E : equal variance (one-dimensional) V : spherical, variable variance (one-dimensional) EII : spherical, equal volume VII : spherical, unequal volume EEE : ellipsoidal, equal volume, shape, and orientation VVV : ellipsoidal, varying volume, shape, and orientation. Data – dane (muszą być ilościowe)")
76
Emclust - BIC for Model-Based Clustering
BIC for EM initialized by hierarchical clustering for parameterized Gaussian mixture models. EMclust(data, G, emModelNames, hcPairs, subset, eps, tol, itmax, equalPro, warnSingular, ...) G – liczba składowych dla których liczymy BIC emModelNames: "E" for spherical, equal variance (one-dimensional) "V" for spherical, variable variance (one-dimensional) "EII": spherical, equal volume "VII": spherical, unequal volume "EEI": diagonal, equal volume, equal shape "VEI": diagonal, varying volume, equal shape "EVI": diagonal, equal volume, varying shape "VVI": diagonal, varying volume, varying shape "EEE": ellipsoidal, equal volume, shape, and orientation "EEV": ellipsoidal, equal volume and equal shape "VEV": ellipsoidal, equal shape "VVV": ellipsoidal, varying volume, shape, and orientation hcPairs - A matrix of merge pairs for hierarchical clustering such as produced by function hc. subset - A logical or numeric vector specifying the indices of a subset of the data to be used in the initial hierarchical clustering phase. eps - A scalar tolerance for deciding when to terminate computations due to computational singularity in covariances. Smaller values of eps allow computations to proceed nearer to singularity. The default is .Mclust\$eps. tol - A scalar tolerance for relative convergence of the loglikelihood. The default is .Mclust\$tol. itmax - An integer limit on the number of EM iterations. The default is .Mclust\$itmax. equalPro - Logical variable indicating whether or not the mixing proportions are equal in the model. The default is .Mclust\$equalPro. warnSingular - A logical value indicating whether or not a warning should be issued whenever a singularity is encountered. The default is warnSingular=FALSE. ... Provided to allow lists with elements other than the arguments can be passed in indirect or list calls with do.call.
 G – liczba składowych dla których liczymy BIC. emModelNames: E for spherical, equal variance (one-dimensional) V for spherical, variable variance (one-dimensional) EII : spherical, equal volume VII : spherical, unequal volume EEI : diagonal, equal volume, equal shape VEI : diagonal, varying volume, equal shape EVI : diagonal, equal volume, varying shape VVI : diagonal, varying volume, varying shape EEE : ellipsoidal, equal volume, shape, and orientation EEV : ellipsoidal, equal volume and equal shape VEV : ellipsoidal, equal shape VVV : ellipsoidal, varying volume, shape, and orientation hcPairs - A matrix of merge pairs for hierarchical clustering such as produced by function hc. subset - A logical or numeric vector specifying the indices of a subset of the data to be used in the initial hierarchical clustering phase. eps - A scalar tolerance for deciding when to terminate computations due to computational singularity in covariances. Smaller values of eps allow computations to proceed nearer to singularity. The default is .Mclust\$eps. tol - A scalar tolerance for relative convergence of the loglikelihood. The default is .Mclust\$tol. itmax - An integer limit on the number of EM iterations. The default is .Mclust\$itmax. equalPro - Logical variable indicating whether or not the mixing proportions are equal in the model. The default is .Mclust\$equalPro. warnSingular - A logical value indicating whether or not a warning should be issued whenever a singularity is encountered. The default is warnSingular=FALSE. ... Provided to allow lists with elements other than the arguments can be passed in indirect or list calls with do.call.")
77
Agnes - Agglomerative Nesting (Hierarchical Clustering)
agnes(x, diss = inherits(x, "dist"), metric = "euclidean", stand = FALSE, method = "average", par.method, keep.diss = n < 100, keep.data = !diss) x data matrix or data frame, or dissimilarity matrix, depending on the value of the diss argument. diss logical flag: if TRUE (default for dist or dissimilarity objects), then x is assumed to be a dissimilarity matrix. If FALSE, then x is treated as a matrix of observations by variables. metric character string specifying the metric to be used for calculating dissimilarities between observations. The currently available options are "euclidean" and "manhattan". Euclidean distances are root sum-of-squares of differences, and manhattan distances are the sum of absolute differences. If x is already a dissimilarity matrix, then this argument will be ignored. stand logical flag: if TRUE, then the measurements in x are standardized before calculating the dissimilarities. Measurements are standardized for each variable (column), by subtracting the variable's mean value and dividing by the variable's mean absolute deviation. If x is already a dissimilarity matrix, then this argument will be ignored. method character string defining the clustering method. The six methods implemented are "average" ([unweighted pair-]group average method, UPGMA), "single" (single linkage), "complete" (complete linkage), "ward" (Ward's method), "weighted" (weighted average linkage) and its generalization "flexible" which uses (a constant version of) the Lance-Williams formula and the par.method argument. Default is "average".
, metric = euclidean , stand = FALSE, method = average , par.method, keep.diss = n < 100, keep.data = !diss) x data matrix or data frame, or dissimilarity matrix, depending on the value of the diss argument. diss logical flag: if TRUE (default for dist or dissimilarity objects), then x is assumed to be a dissimilarity matrix. If FALSE, then x is treated as a matrix of observations by variables. metric character string specifying the metric to be used for calculating dissimilarities between observations. The currently available options are euclidean and manhattan . Euclidean distances are root sum-of-squares of differences, and manhattan distances are the sum of absolute differences. If x is already a dissimilarity matrix, then this argument will be ignored. stand logical flag: if TRUE, then the measurements in x are standardized before calculating the dissimilarities. Measurements are standardized for each variable (column), by subtracting the variable s mean value and dividing by the variable s mean absolute deviation. If x is already a dissimilarity matrix, then this argument will be ignored. method character string defining the clustering method. The six methods implemented are average ([unweighted pair-]group average method, UPGMA), single (single linkage), complete (complete linkage), ward (Ward s method), weighted (weighted average linkage) and its generalization flexible which uses (a constant version of) the Lance-Williams formula and the par.method argument. Default is average .")
78
Clara - Clustering Large Applications
clara(x, k, metric = "euclidean", stand = FALSE, samples = 5, sampsize = min(n, * k), trace = 0, medoids.x = TRUE, keep.data = medoids.x, rngR = FALSE) stand - logical, indicating if the measurements in x are standardized before calculating the dissimilarities. Measurements are standardized for each variable (column), by subtracting the variable's mean value and dividing by the variable's mean absolute deviation. samples integer, number of samples to be drawn from the dataset. sampsize - integer, number of observations in each sample. sampsize should be higher than the number of clusters (k) and at most the number of observations (n = nrow(x)). trace integer indicating a trace level for diagnostic output during the algorithm. medoids.x logical indicating if the medoids should be returned, identically to some rows of the input data x. If FALSE, keep.data must be false as well, and the medoid indices, i.e., row numbers of the medoids will still be returned (i.med component), and the algorithm saves space by needing one copy less of x. keep.data logical indicating if the (scaled if stand is true) data should be kept in the result. Setting this to FALSE saves memory (and hence time), but disables clusplot()ing of the result. Use medoids.x = FALSE to save even more memory. rngR logical indicating if R's random number generator should be used instead of the primitive clara()-builtin one. If true, this also means that each call to clara() returns a different result – though only slightly different in good situations.
, trace = 0, medoids.x = TRUE, keep.data = medoids.x, rngR = FALSE) stand - logical, indicating if the measurements in x are standardized before calculating the dissimilarities. Measurements are standardized for each variable (column), by subtracting the variable s mean value and dividing by the variable s mean absolute deviation. samples integer, number of samples to be drawn from the dataset. sampsize - integer, number of observations in each sample. sampsize should be higher than the number of clusters (k) and at most the number of observations (n = nrow(x)). trace integer indicating a trace level for diagnostic output during the algorithm. medoids.x logical indicating if the medoids should be returned, identically to some rows of the input data x. If FALSE, keep.data must be false as well, and the medoid indices, i.e., row numbers of the medoids will still be returned (i.med component), and the algorithm saves space by needing one copy less of x. keep.data logical indicating if the (scaled if stand is true) data should be kept in the result. Setting this to FALSE saves memory (and hence time), but disables clusplot()ing of the result. Use medoids.x = FALSE to save even more memory. rngR logical indicating if R s random number generator should be used instead of the primitive clara()-builtin one. If true, this also means that each call to clara() returns a different result – though only slightly different in good situations.")
79
diana DIvisive ANAlysis Clustering
diana(x, diss = inherits(x, "dist"), metric = "euclidean", stand = FALSE, keep.diss = n < 100, keep.data = !diss) diss logical flag: if TRUE (default for dist or dissimilarity objects), then x will be considered as a dissimilarity matrix. If FALSE, then x will be considered as a matrix of observations by variables stand logical; if true, the measurements in x are standardized before calculating the dissimilarities. Measurements are standardized for each variable (column), by subtracting the variable's mean value and dividing by the variable's mean absolute deviation. If x is already a dissimilarity matrix, then this argument will be ignored. keep.data logicals indicating if the dissimilarities and/or input data x should be kept in the result. Setting these to FALSE can give much smaller results and hence even save memory allocation time. Details
, metric = euclidean , stand = FALSE, keep.diss = n < 100, keep.data = !diss) diss logical flag: if TRUE (default for dist or dissimilarity objects), then x will be considered as a dissimilarity matrix. If FALSE, then x will be considered as a matrix of observations by variables. stand logical; if true, the measurements in x are standardized before calculating the dissimilarities. Measurements are standardized for each variable (column), by subtracting the variable s mean value and dividing by the variable s mean absolute deviation. If x is already a dissimilarity matrix, then this argument will be ignored. keep.data logicals indicating if the dissimilarities and/or input data x should be kept in the result. Setting these to FALSE can give much smaller results and hence even save memory allocation time. Details.")
80
Fanny- Fuzzy Analysis Clustering
fanny(x, k, diss = inherits(x, "dist"), memb.exp = 2, metric = c("euclidean", "manhattan", "SqEuclidean"), stand = FALSE, iniMem.p = NULL, cluster.only = FALSE, keep.diss = !diss && !cluster.only && n < 100, keep.data = !diss && !cluster.only, maxit = 500, tol = 1e-15, trace.lev = 0) x data matrix or data frame, or dissimilarity matrix, depending on the value of the diss argument. In case of a matrix or data frame, each row corresponds to an observation, and each column corresponds to a variable. All variables must be numeric. Missing values (NAs) are allowed. In case of a dissimilarity matrix, x is typically the output of daisy or dist. Also a vector of length n*(n-1)/2 is allowed (where n is the number of observations), and will be interpreted in the same way as the output of the above-mentioned functions. Missing values (NAs) are not allowed. k integer giving the desired number of clusters. It is required that 0 < k < n/2 where n is the number of observations. diss logical flag: if TRUE (default for dist or dissimilarity objects memb.exp number r strictly larger than 1 specifying the membership exponent used in the fit criterion; see the ‘Details’ below. Default: 2 which used to be hardwired inside FANNY. metric character string specifying the metric to be used for calculating dissimilarities between observations. Options are "euclidean" (default), "manhattan", and "SqEuclidean". Euclidean distances are root sum-of-squares of differences, and manhattan distances are the sum of absolute differences, and "SqEuclidean", the squared euclidean distances are sum-of-squares of differences. Using this last option is equivalent (but somewhat slower) to computing so called “fuzzy C-means”. iniMem.p numeric n * k matrix or NULL (by default); can be used to specify a starting membership matrix maxit, tol maximal number of iterations and default tolerance for convergence (relative convergence of the fit criterion) for the FANNY algorithm
, memb.exp = 2, metric = c( euclidean , manhattan , SqEuclidean ), stand = FALSE, iniMem.p = NULL, cluster.only = FALSE, keep.diss = !diss && !cluster.only && n < 100, keep.data = !diss && !cluster.only, maxit = 500, tol = 1e-15, trace.lev = 0) x data matrix or data frame, or dissimilarity matrix, depending on the value of the diss argument. In case of a matrix or data frame, each row corresponds to an observation, and each column corresponds to a variable. All variables must be numeric. Missing values (NAs) are allowed. In case of a dissimilarity matrix, x is typically the output of daisy or dist. Also a vector of length n*(n-1)/2 is allowed (where n is the number of observations), and will be interpreted in the same way as the output of the above-mentioned functions. Missing values (NAs) are not allowed. k integer giving the desired number of clusters. It is required that 0 < k < n/2 where n is the number of observations. diss logical flag: if TRUE (default for dist or dissimilarity objects. memb.exp number r strictly larger than 1 specifying the membership exponent used in the fit criterion; see the ‘Details’ below. Default: 2 which used to be hardwired inside FANNY. metric character string specifying the metric to be used for calculating dissimilarities between observations. Options are euclidean (default), manhattan , and SqEuclidean . Euclidean distances are root sum-of-squares of differences, and manhattan distances are the sum of absolute differences, and SqEuclidean , the squared euclidean distances are sum-of-squares of differences. Using this last option is equivalent (but somewhat slower) to computing so called fuzzy C-means . iniMem.p numeric n * k matrix or NULL (by default); can be used to specify a starting membership matrix. maxit, tol maximal number of iterations and default tolerance for convergence (relative convergence of the fit criterion) for the FANNY algorithm.")
81
Pam-Partitioning Around Medoids Description
pam(x, k, diss = inherits(x, "dist"), metric = "euclidean", medoids = NULL, stand = FALSE, cluster.only = FALSE, do.swap = TRUE, keep.diss = !diss && !cluster.only && n < 100, keep.data = !diss && !cluster.only, trace.lev = 0) do.swap logical indicating if the swap phase should happen. The default, TRUE, correspond to the original algorithm. On the other hand, the swap phase is much more computer intensive than the build one for large n, so can be skipped by do.swap = FALSE. keep.diss, keep.data logicals indicating if the dissimilarities and/or input data x should be kept in the result. Setting these to FALSE can give much smaller results and hence even save memory allocation time. trace.lev integer specifying a trace level for printing diagnostics during the build and swap phase of the algorithm. Default 0 does not print anything; higher values print increasingly more.
, metric = euclidean , medoids = NULL, stand = FALSE, cluster.only = FALSE, do.swap = TRUE, keep.diss = !diss && !cluster.only && n < 100, keep.data = !diss && !cluster.only, trace.lev = 0) do.swap logical indicating if the swap phase should happen. The default, TRUE, correspond to the original algorithm. On the other hand, the swap phase is much more computer intensive than the build one for large n, so can be skipped by do.swap = FALSE. keep.diss, keep.data logicals indicating if the dissimilarities and/or input data x should be kept in the result. Setting these to FALSE can give much smaller results and hence even save memory allocation time. trace.lev integer specifying a trace level for printing diagnostics during the build and swap phase of the algorithm. Default 0 does not print anything; higher values print increasingly more.")
82
kmeans

83
kmeans

84
kmeans

85
pam

86
hclust

87
agnes

89
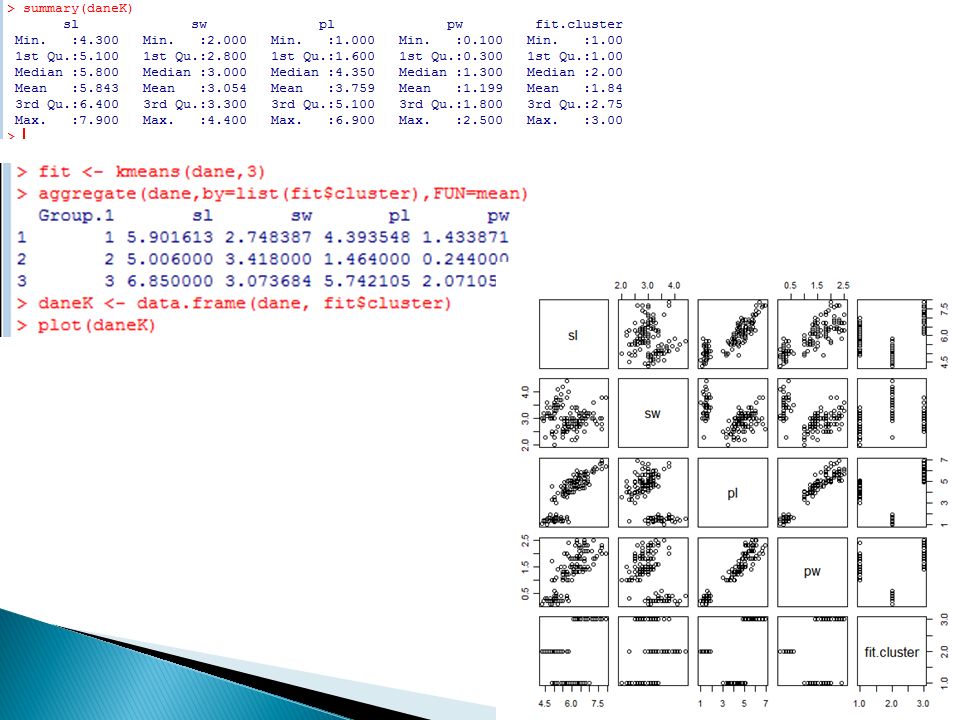
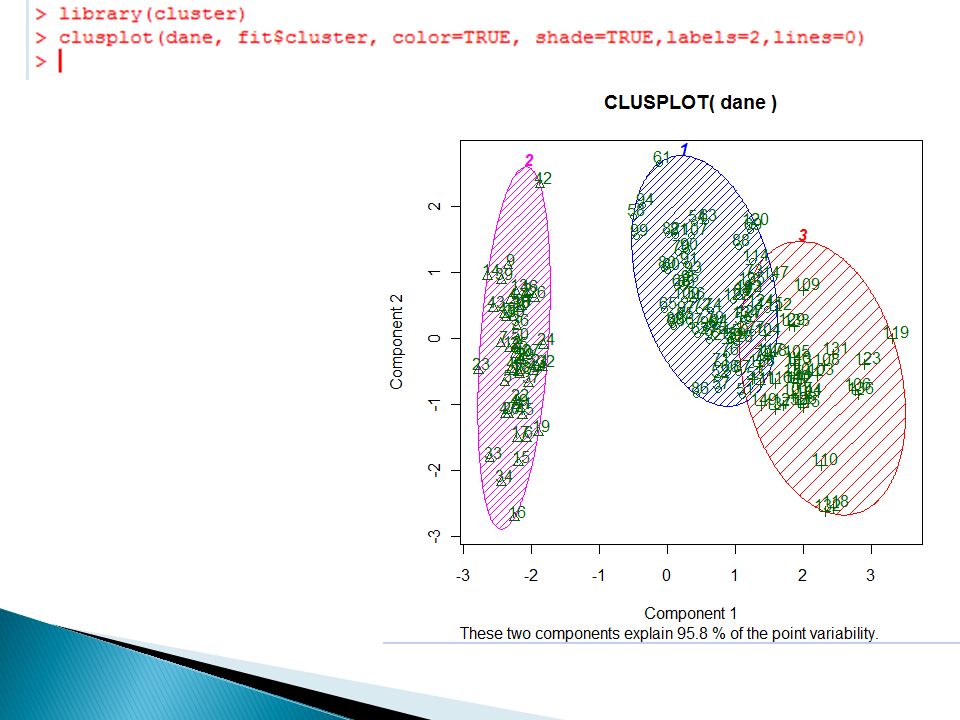
otrzymamy dla każdej z obserwacji w zbiorze (przypomnijmy, że jest ich 150) numer grupy do której ta obserwacja należy. Widzimy więc, że obserwacje o numerach od 1 do 50 są przyporządkowane grupie 1, zaś pozostałe 100 obserwacji jest w miarę równomiernie rozłożone między grupy 2 i 3.

93
# Determine number of clusters wss <- (nrow(mydata)-1)
# Determine number of clusters wss <- (nrow(mydata)-1)*sum(apply(mydata,2,var)) for (i in 2:15) wss[i] <- sum(kmeans(mydata, centers=i)$withinss) plot(1:15, wss, type="b", xlab="Number of Clusters", ylab="Within groups sum of squares") # K-Means Cluster Analysis fit <- kmeans(mydata, 5) # 5 cluster solution # get cluster means aggregate(mydata,by=list(fit$cluster),FUN=mean) # append cluster assignment mydata <- data.frame(mydata, fit$cluster)
-1)*sum(apply(mydata,2,var)) for (i in 2:15) wss[i] <- sum(kmeans(mydata, centers=i)$withinss) plot(1:15, wss, type= b , xlab= Number of Clusters , ylab= Within groups sum of squares ) # K-Means Cluster Analysis fit <- kmeans(mydata, 5) # 5 cluster solution # get cluster means aggregate(mydata,by=list(fit$cluster),FUN=mean) # append cluster assignment mydata <- data.frame(mydata, fit$cluster)")
97
validating cluster solutions
The function cluster.stats() in the fpc package provides a mechanism for comparing the similarity of two cluster solutions using a variety of validation criteria (Hubert's gamma coefficient, the Dunn index and the corrected rand index) # comparing 2 cluster solutions library(fpc) cluster.stats(d, fit1$cluster, fit2$cluster) where d is a distance matrix among objects, and fit1$cluster and fit$cluster are integer vectors containing classification results from two different clusterings of the same data.
 in the fpc package provides a mechanism for comparing the similarity of two cluster solutions using a variety of validation criteria (Hubert s gamma coefficient, the Dunn index and the corrected rand index) # comparing 2 cluster solutions library(fpc) cluster.stats(d, fit1$cluster, fit2$cluster) where d is a distance matrix among objects, and fit1$cluster and fit$cluster are integer vectors containing classification results from two different clusterings of the same data.")
98
> fit <- kmeans(dane,3) > fit2 <- kmeans(dane,4)
> cluster.stats(d, fit$cluster, fit2$cluster) $n [1] 150 $cluster.number [1] 3 $cluster.size [1] $diameter [1] $average.distance [1] $median.distance [1] $separation [1] $average.toother [1]
 $n [1] 150 $cluster.number [1] 3 $cluster.size [1] $diameter [1] $average.distance [1] $median.distance [1] $separation. [1] $average.toother. [1]")
99
$g2 NULL $g3 $pearsongamma [1] 0.7144752 $dunn [1] 0.0988074 $entropy
$separation.matrix [,1] [,2] [,3] [1,] [2,] [3,] $average.between [1] $average.within [1] $n.between [1] 7356 $n.within [1] 3819 $within.cluster.ss [1] $clus.avg.silwidths $avg.silwidth [1] $g2 NULL $g3 $pearsongamma [1] $dunn [1] $entropy [1] $wb.ratio [1] $ch [1] $corrected.rand [1] $vi [1]
![$g2 NULL $g3 $pearsongamma [1] $dunn [1] $entropy](http://slideplayer.pl/slide/808448/1/images/99/%24g2+NULL+%24g3+%24pearsongamma+%5B1%5D+%24dunn+%5B1%5D+%24entropy.jpg "$separation.matrix. [,1] [,2] [,3] [1,] [2,] [3,] $average.between. [1] $average.within. [1] $n.between. [1] $n.within. [1] $within.cluster.ss. [1] $clus.avg.silwidths $avg.silwidth. [1] $g2. NULL. $g3. $pearsongamma. [1] $dunn. [1] $entropy. [1] $wb.ratio. [1] $ch. [1] $corrected.rand. [1] $vi. [1]")
100
Traceis

102
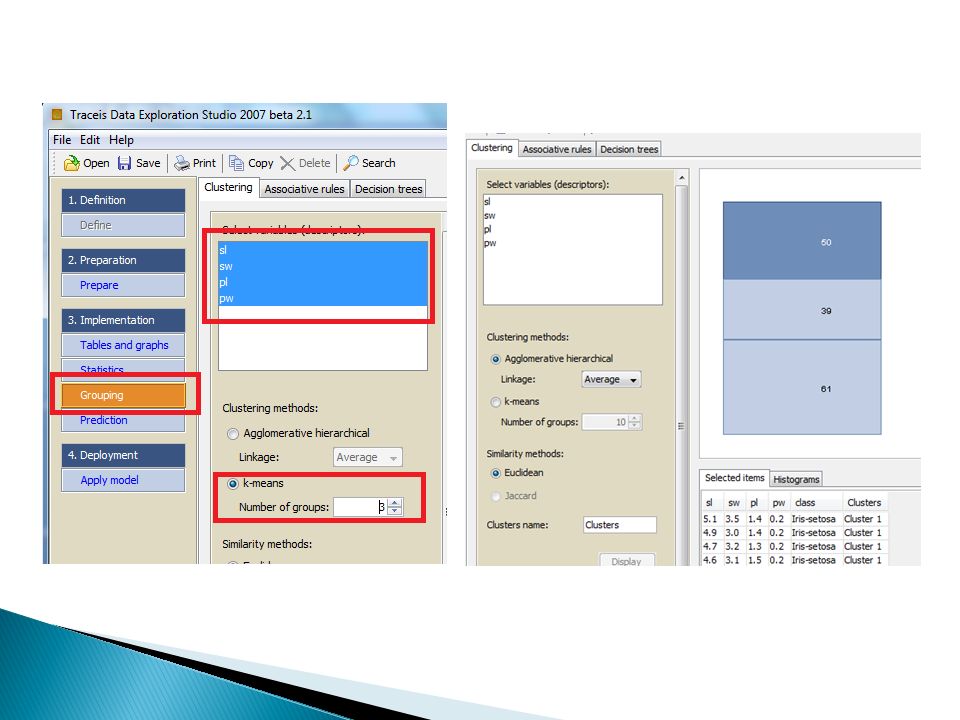
K-średnich

103
AHC

104
Podsumowanie Co to jest grupowanie ?
Jak dzielimy algorytmy ? Kiedy stosować hierarchiczne a kiedy k-optymalizacyjne ? Jak ustalać liczbę k ? Jakie są wady metod grupowania ? Jakie narzędzia pozwalają na analizę skupień ? Czy są jakieś wymogi co do typu danych podlegających grupowaniu ?

105
Następny wykład: Testowanie hipotez statystycznych
Dziękuję za uwagę Następny wykład: Testowanie hipotez statystycznych

Podobne prezentacje