Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
STATYSTYKA MATEMATYCZNA wykład 1 - wprowadzenie Dr Aldona Migała-Warchoł

2
Warunkiem zaliczenia przedmiotu jest uzyskanie co najmniej połowy punktów z zaliczenia wykładu. Zaliczenie to przeprowadzone zostanie w formie pisemnej (zadania). Liczba punktów decyduje o ocenie: 0 - 14 pkt. – ndst 15 - 17 pkt. – dst 18 - 20 pkt. – + dst 21 - 23 pkt. – db 24 - 26 pkt. – + db 27 - 30 pkt. – bdb Warunki zaliczenia przedmiotu
. Liczba punktów decyduje o ocenie: pkt. – ndst pkt. – dst pkt. – + dst pkt. – db pkt. – + db pkt. – bdb Warunki zaliczenia przedmiotu.")
3
Statystyka to nauka, której przedmiotem zainteresowania są metody pozyskiwania i prezentacji, a przede wszystkim analizy danych opisujących zjawiska masowe. Statystyka matematyczna zajmuje się metodami wnioskowania o całej zbiorowości generalnej na podstawie badania jej części losowej, zwanej próbą. STATYSTYKA

4
a)umożliwia dokładniejszy sposób opisu interesującej nas rzeczywistości, b) umożliwia formułowanie uogólnień na podstawie uzyskanych wyników analizy, c) pozwala na przewidywanie rozwoju zjawisk w przyszłości, czyli pobudza do prognoz, d) dostarcza narzędzi do porządkowania informacji o zjawiskach. Statystyka:

5
Chcemy poznać średnią płacę (w zł) siedmiu osób, które zatrudnione są w określonym dziale danej firmy: 1000; 1500; 1200; 1200; 1200; 1100; 20000. zł Czy obliczenie wartości średniej arytmetycznej w taki właśnie sposób oddaje istotę analizowanego problemu? Przykłady zastosowań statystyki

6
Zmiana skali na osiach układu współrzędnych powoduje drastyczne zmiany w ocenie przebiegu funkcji: Przykłady te pokazują, że statystyka w rękach szarlatanów jest niebezpieczna. Trzeba pamiętać, że wyniki wszelkich obliczeń zawsze należy łączyć ze zdrowym rozsądkiem.

7
Miary statystyczne można podzielić na następujące kategorie: Miary położenia – służą m.in. do określania wartości zmiennej, wokół której skupiają się pozostałe wartości zmiennej. W tej kategorii szczególnie ważne są miary tendencji centralnej, nazywane miarami przeciętnymi. Poniżej przykład rozkładu dwóch zmiennych różniących się wartościami średnimi.

8
Miary zmienności – służą analizie stopnia zróżnicowania wartości zmiennej. Miary zmienności wskazują, czy część lub większość obserwacji jest skoncentrowana wokół wartości centralnej, czy też są one rozproszone. Poniżej przykład rozkładu dwóch zmiennych różniących się wartością miar zmienności.

9
Miary asymetrii – służą ocenie stopnia skośności wartości zmiennej. Poniżej przykład rozkładu dwóch zmiennych różniących się skośnością. Miary koncentracji – służą do badania nierównomierności rozkładu ogólnej sumy wartości zmiennej pomiędzy poszczególne jednostki zbiorowości.

10
Zbiorowość statystyczna, nazywana też populacją statystyczną - zbiór elementów (osób, przedmiotów, zdarzeń) podobnych, lecz nie identycznych pod względem określonej cechy, poddanych badaniom statystycznym. PODSTAWOWE POJĘCIA STATYSTYKI

11
Element zbiorowości statystycznej (populacji statystycznej) jest nazywany jednostką statystyczną. Liczba jednostek statystycznych, czyli elementów zbiorowości, jest nazywana liczebnością zbiorowości. PODSTAWOWE POJĘCIA STATYSTYKI

12
Badanie statystyczne to proces pozyskiwania danych na temat rozkładu cechy statystycznej w populacji. Badanie może mieć charakter: pełny - badanie obejmuje całą populację częściowy - odbywa się na pewnych (zazwyczaj losowo) wybranych elementach populacji, czyli próbie losowej, zazwyczaj reprezentatywnej dla populacji BADANIE STATYSTYCZNE
 wybranych elementach populacji, czyli próbie losowej, zazwyczaj reprezentatywnej dla populacji BADANIE STATYSTYCZNE.")
13
Schemat badania statystycznego obejmuje następujące kroki: Krok 1. projektowanie BADANIA, Krok 2. gromadzenie materiału statystycznego, Krok 3. opracowanie materiału statystycznego, Krok 4. analiza statystyczna. CEL, PRZEDMIOT I SCHEMAT BADAŃ STATYSTYCZNYCH

14
PRÓBA Próba jest to każdy niepusty podzbiór zbiorowości generalnej, który poddawany jest badaniu i który stanowi podstawę do formułowania wniosków o całej zbiorowości generalnej. Warunkiem formułowania znaczących wniosków w odniesieniu do całej zbiorowości generalnej jest reprezentatywność próby. Reprezentatywność próby oznacza, że powinna ona stanowić swego rodzaju miniaturę zbiorowości generalnej, zachowującą wszystkie własności jej struktury.

15
Przyjmuje się, że dla zapewnienia reprezentatywności próby wystarczy, aby była ona losowa i dostatecznie liczna. Próba jest losowa wówczas, gdy każdy element zbiorowości generalnej ma jednakową szansę trafienia do próby. Oszacowania parametrów zbiorowości generalnej uzyskiwane na podstawie badania próby są tym dokładniejsze im liczniejsza jest próba.

16
Cel badania jest możliwy do osiągnięcia wówczas, gdy jednostki statystyczne są precyzyjnie określone pod względem: -rzeczowym (przedmiot badań), -przestrzennym (miejsce badań), -czasowym (okres badań).
, -przestrzennym (miejsce badań), -czasowym (okres badań).")
17
Ostatecznym celem stosowania metod statystycznych jest otrzymanie użytecznych informacji na temat zjawiska, którego dotyczą. Istotne jest, aby badania statystyczne były zaplanowane w sposób nie budzący zastrzeżeń. Ich cel powinien być określony zrozumiale i szczegółowo. Materiał statystyczny powinien zaś być wiarygodny i przejrzysty.

18
Cecha statystyczna (nazywana też zmienną) to właściwość elementów zbiorowości statystycznej będąca przedmiotem badania statystycznego. CECHA STATYSTYCZNA

19
Cecha statystyczna Klasyfikacja cech statystycznych ilościowa (mierzalna) wyrażone za pomocą liczb jakościowa (niemierzalna) wyrażona w sposób opisowy. skokowa przyjmuje skończoną lub przeliczalną liczbę wartości ciągła - może przyjąć każdą wartość z określonego przedziału liczbowego

20
Zbiorowość statystyczna Klasyfikacja zbiorowości statystycznych Skończona Ma skończoną liczbę jednostek; np. 50 firm farmaceutycznych Nieskończona Ma nieskończona lub niemożliwą do ustalenia liczbę jednostek statystycznych; Np. zbiorowość mikroorganizmów, klienci odwiedzający centrum handlowe

21
Zbiorowość statystyczna Klasyfikacja zbiorowości statystycznych Jednowymiarowa badana ze względu na jedną cechę np. firmy farmaceutyczne badane ze względu na wielkość obrotów Wielowymiarowa badana jednocześnie ze względu na kilka cech np. firmy farmac. w których badamy zależność wielkości obrotów od liczby przedstawicieli handlowych

22
Zbiorowość statystyczna Klasyfikacja zbiorowości statystycznych Względnie jednorodna Jej podzbiorowości mało różnią się własnościami np. zbiorowość gospodarstw 2 – osobowych badana ze względu na tygodniowe wydatki na żywność Niejednorodna Jej podzbiorowości wyraźnie różnią się własnościami np. zbiorowość gospodarstw o różnej wielkości badana ze względu na tygodniowe wydatki na żywność

23
Zbiorowość statystyczna Klasyfikacja zbiorowości statystycznych Statyczna Wszystkie jednostki statystyczne pochodzą z tego samego okresu np. firmy farmaceutyczne zarejestrowane we wrześniu 2012 r., spółki na giełdzie notowane 15.06.2012 r. Dynamiczna Jednostki statystyczne pochodzą z różnych okresów np. kolejne sesje giełdowe w październiku 2012 r.

24
Analiza współzależności Współczynnik korelacji liniowej Pearsona Współczynnik korelacji rang Spearmana Analiza zależności Liniowa funkcja regresji

25
Zależność przyczynowa Zależność przyczynowa – rodzaj zależności, w której jesteśmy w stanie wskazać, która ze zmiennych stanowi przyczynę zmian, a która ilustruje skutek. Przykładem zależności przyczynowej może być związek pomiędzy stażem pracy (przyczyna) i wysokością zarobków (skutek).
 i wysokością zarobków (skutek)..")
26
Zależność pozorna Zależność pozorna – pomiędzy dwoma zjawiskami wydaje się istnieć zależność, ale jest ona wywołana istnieniem wspólnej przyczyny. Przykładowo waga i poziom cholesterolu w organizmie wydają się być powiązane ze sobą, niemniej jednak jest to zależność pozorna. W rzeczywistości posiadają wspólną przyczynę – ilość i rodzaj spożywanych produktów.

27
Zmienna niezależna (zmienna X) – zmienna która wywołuje zmiany, stanowi ich przyczynę. Zmienna zależna (zmienna Y) – zmienna, której wartości są w mniejszym lub większym stopniu kształtowane przez zmienną niezależną (zmienne niezależne). Wykres korelacyjny (rozrzutu) – dla każdego i-tego przypadku nanosimy na układ współrzędnych punkt o współrzędnych (X i, Y i ), gdzie Xi i Yi to kolejne wartości badanych zmiennych.
 – zmienna, której wartości są w mniejszym lub większym stopniu kształtowane przez zmienną niezależną (zmienne niezależne). Wykres korelacyjny (rozrzutu) – dla każdego i-tego przypadku nanosimy na układ współrzędnych punkt o współrzędnych (X i, Y i ), gdzie Xi i Yi to kolejne wartości badanych zmiennych..")
28
Kowariancja to miara natężenia współzależności dwóch cech. Znak kowariancji informuje o charakterze współzależności – dodatni oznacza zgodne kierunki zmian, ujemny – kierunki zmian przeciwne. Kowariancja

29
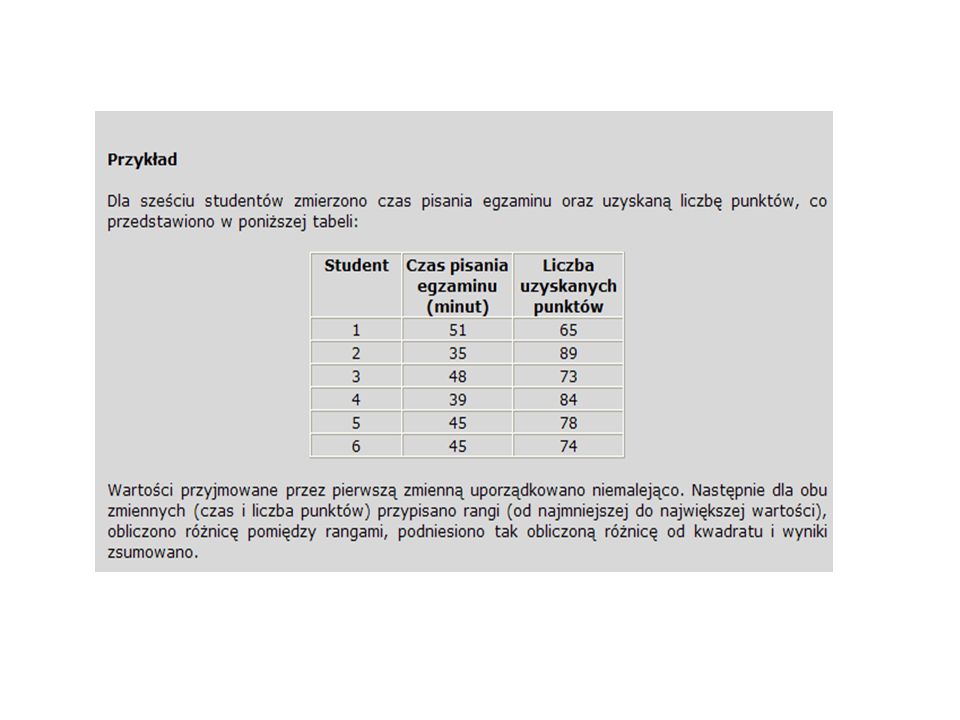
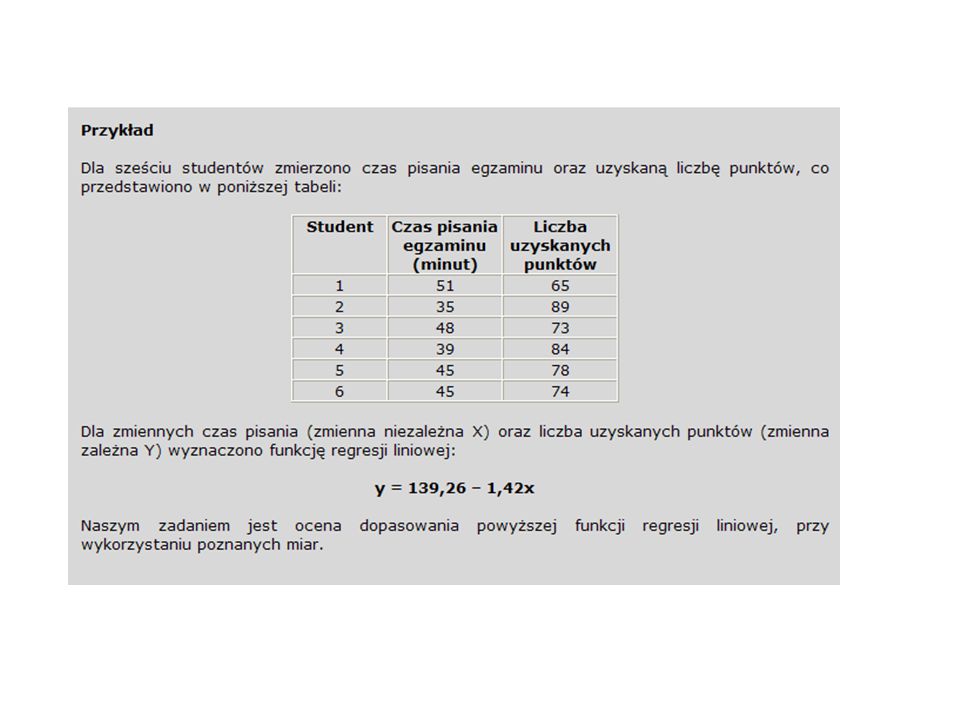
Przykład Dla sześciu studentów zmierzono czas pisania egzaminu oraz uzyskaną liczbę punktów. Obliczenia rozpoczynamy od ustalenia średnich dla zmiennej X (czas pisania) oraz Y (liczba punktów):
 oraz Y (liczba punktów):.")
31
Współczynnik korelacji liniowej r Współczynnik korelacji liniowej r przyjmuje wartości z przedziału. Gdy r = 0, oznacza to, że cechy nie są skorelowane. O doskonałej współzależności między cechami mówimy wówczas, gdy r przyjmuje wartość „-1” (korelacja doskonała ujemna) lub „1” (korelacja doskonała dodatnia).
 lub „1 (korelacja doskonała dodatnia)..")
33
Współczynnik korelacji liniowej Pearsona Współczynnik korelacji liniowej Pearsona przyjmuje wartości z przedziału od -1 do +1. Jeżeli współczynnik korelacji liniowej wynosi: mniej niż 0,2 to brak związku liniowego między badanymi zmiennymi, 0,2 – 0,4 zależność liniowa wyraźna, lecz niska, 0,4 – 0,7 zależność umiarkowana, 0,7 – 0,9 zależność znacząca, powyżej 0,9 zależność bardzo silna. Analogicznie interpretujemy wartości współczynnika mniejsze od zera, z tą różnicą, że wówczas mamy do czynienia z ujemną zależnością.

34
Współczynnik korelacji rang Spearmana służy do opisu siły korelacji dwóch cech, w przypadku gdy: Cechy są mierzalne, a badana zbiorowość jest nieliczna. Cechy mają charakter jakościowy i istnieje możliwość ich uporządkowania. Współczynnik korelacji rang Spearmana stosuje się do analizy współzależności obiektów pod względem cechy dwuwymiarowej (X, Y).
..")
35
Kolejne etapy wyznaczania współczynnika korelacji rang Spearmana są następujące: 1.Jednostki danej zbiorowości statystycznej, ze względu na wielkość odpowiadającej im pierwszej cechy, porządkuje się. 2.Tak uporządkowanym ze względu na pierwszą cechę jednostkom, przypisuje się kolejne numery począwszy od 1. Jeżeli kilka jednostek ma tę samą wielkość cechy, wtedy z odpowiadających im kolejnych rang oblicza się średnią arytmetyczną i przydziela wszystkim jednostkom, z których ta średnia została obliczona. Następna jednostka otrzymuje już najbliższą, niewykorzystaną dotąd rangę. Ostatni numer powinien równać się łącznej liczbie jednostek. 3.Następnie dla jednostek drugiej cechy w analogiczny sposób przypisuje się numery począwszy od 1 (dla jednostki o najniższej lub najwyższej wartości).
..")
36
Wzór na współczynnik korelacji rang Spearmana jest następujący: gdzie: d i = r 1i – r 2i, r 1i – ranga i-tego obiektu w pierwszym uporządkowaniu, r 2i – ranga i-tego obiektu w drugim uporządkowaniu, n – liczba badanych obiektów. Współczynnik korelacji rang Spearmana przyjmuje wartości z przedziału. Im bliższy jest on liczbie 1 lub -1, tym silniejsza jest analizowana zależność.

38
Warto zauważyć, że czas pisania dla studentów 5 i 6 jest taki sam i wynosi 45 minut. Jest to trzeci i czwarty czas pisania egzaminu, w związku z czym przypisujemy jednakowe rangi stanowiące średnią arytmetyczną wartości 3 i 4. Student Czas pisania egzaminu (ranga r 1i ) Liczba uzyskanych punktów (ranga r 2i ) Różnica rang d i = r 1i -r 2i Różnica rang podniesiona do kwadratu d i 2 216-525 425-39 63,530,50,25 53,54-0,50,25 35239 161525 Suma68,5
 Liczba uzyskanych punktów (ranga r 2i ) Różnica rang d i = r 1i -r 2i Różnica rang podniesiona do kwadratu d i ,530,50,25 53,54-0,50, Suma68,5.")
39
Obliczoną sumę kwadratów różnic podstawiamy do wzoru: Współczynnik równy świadczy o istnieniu bardzo wyraźnej negatywnej zależności pomiędzy czasem pisania egzaminu a ilością punktów. Im student dłużej pisze, tym statystycznie rzec biorąc otrzymuje mniej punktów (co można wytłumaczyć faktem, że najlepiej przygotowani studenci kończą pisać egzamin wcześniej).
..")
40
Zależność pomiędzy jedną lub większą liczbą zmiennych niezależnych a zmienną zależną przedstawiamy w postaci tak zwanej funkcji regresji. Poniżej przedstawiono przykłady wykorzystania modeli regresji do rozwiązywania praktycznych problemów: Określenie zależności pomiędzy wiekiem, poziomem wykształcenia (mierzonym na przykład przez liczbę lat poświęconych na naukę), stażem pracy a wysokością zarobków w danej branży. Określenie wpływu działań marketingowych (mierzonych na przykład wydatkami na reklamy telewizyjne, prasowe, billboardy, etc.) na przyszłą sprzedaż produktu. Określenie wpływu wieku, wagi, aktywności ruchowej (mierzonej na przykład liczbą godzin w tygodniu przeznaczoną na uprawianie sportu) a kondycją fizyczną (mierzoną na przykład wynikiem biegu na 1km).
, stażem pracy a wysokością zarobków w danej branży. Określenie wpływu działań marketingowych (mierzonych na przykład wydatkami na reklamy telewizyjne, prasowe, billboardy, etc.) na przyszłą sprzedaż produktu. Określenie wpływu wieku, wagi, aktywności ruchowej (mierzonej na przykład liczbą godzin w tygodniu przeznaczoną na uprawianie sportu) a kondycją fizyczną (mierzoną na przykład wynikiem biegu na 1km)..")
41
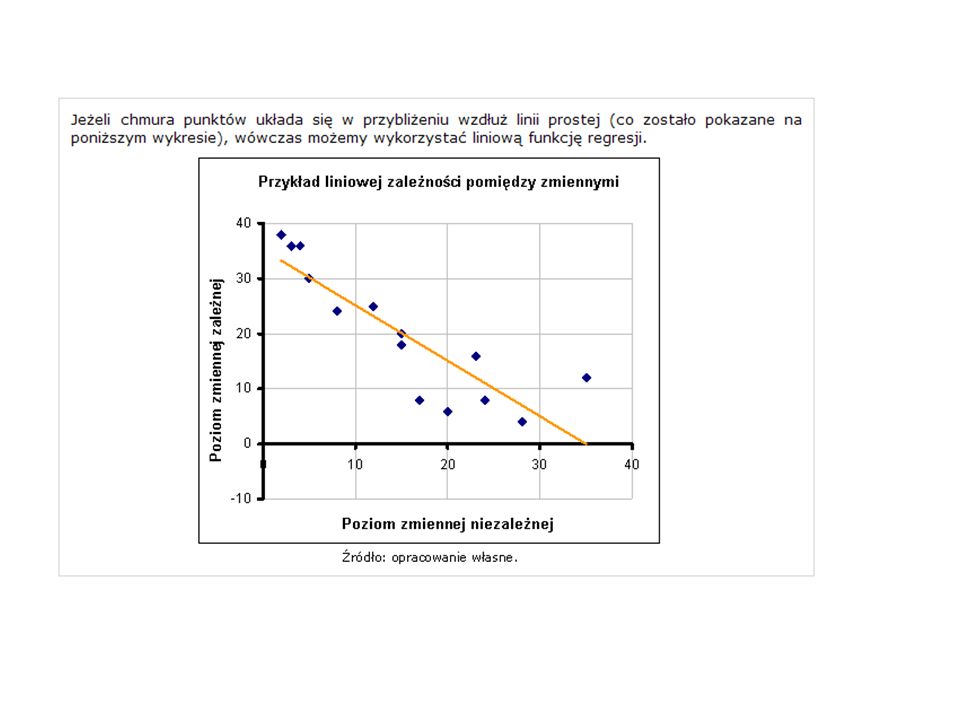
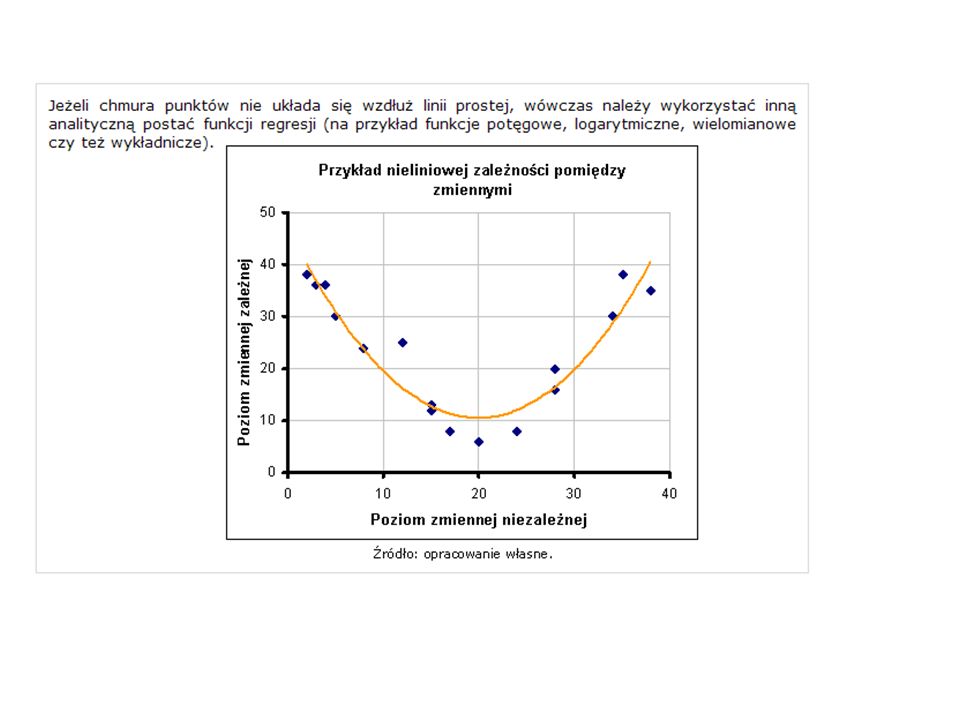
Funkcja regresji - to narzędzie do badania powiązań między zmiennymi. Dużym problemem jest wybór postaci analitycznej funkcji dla analizowanego zagadnienia. Ułatwieniem może być sporządzenie m.in. wykresu rozrzutu, gdzie dla każdej (i-tej) pary wartości zmiennej niezależnej (X) i zmiennej zależnej (Y) tworzymy punkt o współrzędnych Xi, Yi. Jeżeli zmiennych niezależnych jest więcej, wówczas konstruujemy odpowiednio większą ilość wykresów rozrzutu, przedstawiających zależność pomiędzy każdą zmienną niezależną (oś odciętych) a zmienną zależną (oś rzędnych). Z wykresu (wykresów) odczytujemy prawdopodobny rodzaj zależności pomiędzy zmiennymi niezależnymi a zmienną zależną.
 pary wartości zmiennej niezależnej (X) i zmiennej zależnej (Y) tworzymy punkt o współrzędnych Xi, Yi. Jeżeli zmiennych niezależnych jest więcej, wówczas konstruujemy odpowiednio większą ilość wykresów rozrzutu, przedstawiających zależność pomiędzy każdą zmienną niezależną (oś odciętych) a zmienną zależną (oś rzędnych). Z wykresu (wykresów) odczytujemy prawdopodobny rodzaj zależności pomiędzy zmiennymi niezależnymi a zmienną zależną..")
44
Naszym zadaniem jest wyznaczenie parametrów liniowej funkcji regresji, o ogólnej postaci: y = a + bx Gdzie: y - wartość przewidywana na podstawie wartości x a - parametr a jest nazywany wyrazem wolnym i odpowiada wartości funkcji y dla argumentu x = 0 b - współczynnik kierunkowy, który decyduje o tym, czy funkcja jest rosnąca, czy malejąca oraz jak szybko następują zmiany (jeśli b jest dodatnie, to funkcja jest rosnąca – to znaczy, im większe wartości zmiennej x, tym większe wartości funkcji, czyli y) Do wyznaczenia parametrów tej funkcji (a i b) wykorzystuje się metodę najmniejszych kwadratów.
 Do wyznaczenia parametrów tej funkcji (a i b) wykorzystuje się metodę najmniejszych kwadratów.")
46
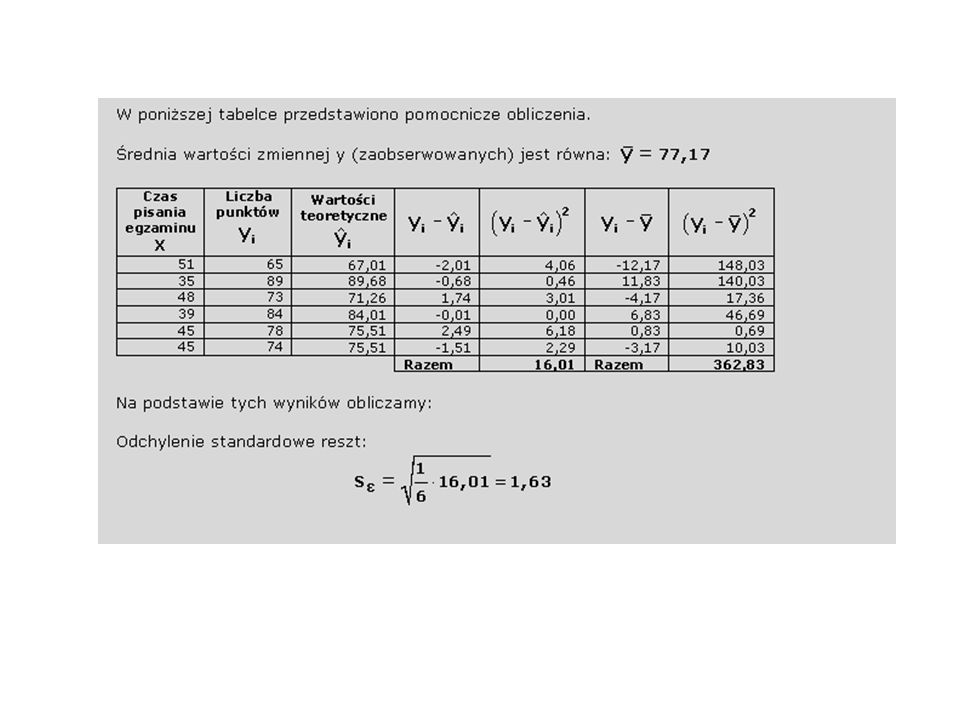
Po wyznaczeniu parametrów funkcji regresji liniowej należy ocenić poziom dopasowania funkcji regresji do rzeczywistych danych. Sprowadza się to do odniesienia generowanych przez funkcję regresji wartości teoretycznych do wartości zaobserwowanych. Wykorzystuje się w tym celu szereg miar, do najczęściej stosowanych należą: odchylenie standardowe reszt, współczynnik zbieżności oraz współczynnik determinacji. Wartości teoretyczne obliczamy podstawiając do funkcji regresji liniowej wartości zmiennej niezależnej X. Przykład Dla pewnej funkcji regresji liniowej: y = 250 – 2x Obliczamy wartości teoretyczne dla zmiennej niezależnej x równej 10 oraz 11. Dla x = 10 otrzymujemy: y = 250 – 2*10 = 230 Dla x = 11 otrzymujemy: y = 250 – 2*11 = 228

51
Współczynnik zbieżności: Współczynnik determinacji: Oszacowane powyżej miary świadczą o bardzo wysokim poziomie dopasowania funkcji regresji. Wartości teoretyczne zmiennej Y (liczba punktów) obliczone na podstawie funkcji regresji odchylają się od wartości rzeczywistych zaledwie o 1,63 punktu. Na podstawie wartości współczynnika determinacji wnioskujemy, że 95,59% zmienności zmiennej Y (liczba punktów) wynika ze zmienności zmiennej X (czas pisania egzaminu).
 obliczone na podstawie funkcji regresji odchylają się od wartości rzeczywistych zaledwie o 1,63 punktu. Na podstawie wartości współczynnika determinacji wnioskujemy, że 95,59% zmienności zmiennej Y (liczba punktów) wynika ze zmienności zmiennej X (czas pisania egzaminu)..")
Podobne prezentacje







 ogół rzeczywistych jednostek, o których chcemy uzyskać informacje.>")




 do zakresu komórek w innym skoroszycie Możliwości efektywnego stosowania odwołań zewnętrznych Odwołania zewnętrzne.>")











