Pobierz prezentację
1
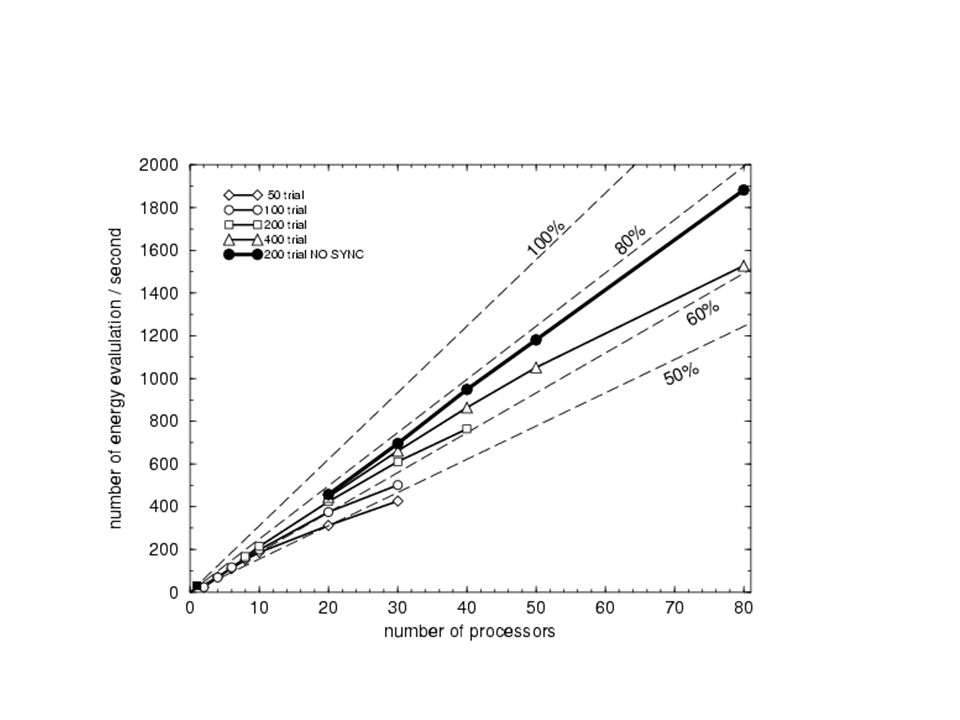
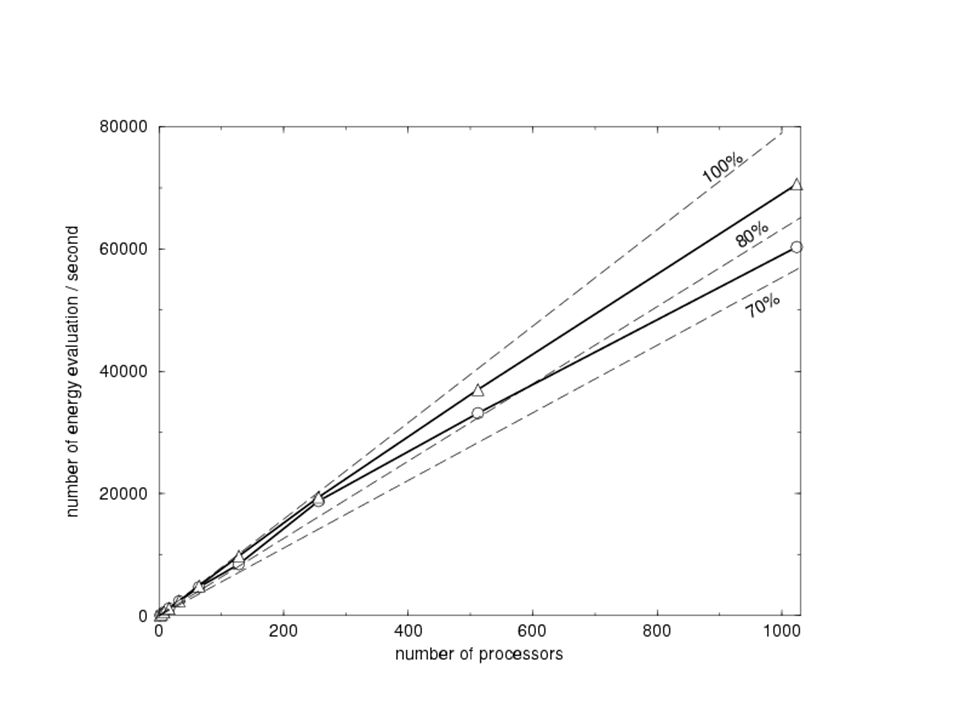
Współczynnik przyspieszenia n - wielkość zadania p - liczba procesorów T(n,p) – czas wykonania
 – czas wykonania")
2
Prawo Amdahla n) – udział części sekwencyjnej
 – udział części sekwencyjnej")
3
Sprawność programu równoległego w(n) – ilość operacji związanych z wykonywaniem obliczeń h(n,p) – narzuty na komunikacje
 – ilość operacji związanych z wykonywaniem obliczeń h(n,p) – narzuty na komunikacje")
4
Oprogramowanie do obliczeń równoległych System operacyjny Języki wysokiego poziomu Kompilatory Biblioteki procedur numerycznych Biblioteki do sterowania zadaniami Narzędzia do wspomagania programowania, uruchamiania i profilowania

5
Paradygmaty programowania równoległego Możliwe rzadkie używanie bariery Minimalizacja czasu zajmowanego przez mechanizmy synchronizacji (pamięć wspólna) Minimalizacja czasu zajmowanego przez mechanizmy komunikacji (pamięć rozproszona)
 Minimalizacja czasu zajmowanego przez mechanizmy komunikacji (pamięć rozproszona)")
8
Stopień ziarnistości obliczeń równoległych Ziarnistość opisuje ilość operacji obliczeniowych między punktami synchronizacji Ilość danych przypadająca na procesor, częstotliwość komunikacji i synchronizacji Grube ziarno, ang. coarse grain Drobne ziarno, ang. fine grain

9
Maszyny z pamięcią wspólną Procesy –Mechanizmy komunikacji międzyprocesowej (IPC) Mechanizm wątków (thread) –Tworzenie, niszczenie, identyfikacja, punkty synchronizacji (zamek, semafor) –Lokalne zmienne wątku Dyrektywy kompilatora Standard OpenMP
 Mechanizm wątków (thread) –Tworzenie, niszczenie, identyfikacja, punkty synchronizacji (zamek, semafor) –Lokalne zmienne wątku Dyrektywy kompilatora Standard OpenMP")
10
SUBROUTINE MULKJI(A,B,C,N) C C Multiply A=B*C using index order K/J/I C DIMENSION A(N,N),B(N,N),C(N,N) C TIME3=TIMEF() CALL SECOND(TIME1) CMIC$ DO ALL SHARED(N, A, B, C) PRIVATE(K, J, I) DO 30 K=1,N DO 20 J=1,N CDIR$ IVDEP DO 10 I=1,N A(I,K)=A(I,K)+B(I,J)*C(J,K) 10 CONTINUE 20 CONTINUE 30 CONTINUE CALL SECOND(TIME2) TIME4=TIMEF() TEMP=(TIME4-TIME3)/1000.0 WRITE(*,(1X,A,I5,A,G14.6,A,G14.6)) *'MULIJK - N=',N,' CPU=',TIME2-TIME1,' Elapsed=',TEMP RETURN END
 C C Multiply A=B*C using index order K/J/I C DIMENSION A(N,N),B(N,N),C(N,N) C TIME3=TIMEF() CALL SECOND(TIME1) CMIC$ DO ALL SHARED(N, A, B, C) PRIVATE(K, J, I) DO 30 K=1,N DO 20 J=1,N CDIR$ IVDEP DO 10 I=1,N A(I,K)=A(I,K)+B(I,J)*C(J,K) 10 CONTINUE 20 CONTINUE 30 CONTINUE CALL SECOND(TIME2) TIME4=TIMEF() TEMP=(TIME4-TIME3)/ WRITE(*,(1X,A,I5,A,G14.6,A,G14.6)) * MULIJK - N= ,N, CPU= ,TIME2-TIME1, Elapsed= ,TEMP RETURN END")
12
Maszyny z pamięcią lokalną High Performance Fortran (HPF) język dyrektyw zrównoleglających (data parallelism) Linda: globalna baza danych (tuple space) out,eval,in,inp,rd,rdp Parallel Virtual Machine (PVM) Message Passing Interface (MPI)
 język dyrektyw zrównoleglających (data parallelism) Linda: globalna baza danych (tuple space) out,eval,in,inp,rd,rdp Parallel Virtual Machine (PVM) Message Passing Interface (MPI)")
13
PROGRAM main IMPLICIT NONE INTEGER N PARAMETER (N=1000) INTEGER i, procnum(N), procsum(N), sum1, sum2 !HPF$ DISTRIBUTE PROCNUM(BLOCK) !HPF$ ALIGN PROCSUM(I) WITH PROCNUM(I) FORALL (i = 1:N) procnum(i) = i sum1 = SUM(procnum) PRINT *, 'Sum using global reduction is ', sum1 procsum = 0 DO i = 1, N procnum = CSHIFT(procnum,1) procsum = procsum + procnum END DO sum2 = procsum(1) PRINT *, 'Sum using local shifts is ', sum2 FORALL (i = 1:N) procnum(i) = procsum(i) - procsum(1) END FORALL IF (SUM(procnum).EQ. 0) THEN PRINT *, 'Array values are the same.' ELSE PRINT *, 'OOPS! Array values are not the same!' ENDIF STOP END
 THEN PRINT *, Array values are the same. ELSE PRINT *, OOPS. Array values are not the same! ENDIF STOP END.")
14
PVM 1989 Oak Ridge National Laboratory Komputery połączone siecią tworzą równoległą maszynę wirtualną Biblioteka procedur i funkcji do tworzenia procesów użytkownika oraz przesyłania komunikatów miedzy procesami

15
MPI 1993 spotkania producentów i użytkowników maszyn równoległych Standard interfejsu do przesyłania komunikatów opracowany przez MPI Forum MPI jest nadzbiorem funkcji oferowanych przez PVM wszystkie procesy maja wspólny kod

16
Charakterystyka standardowego interfejsu przesyłania wiadomości MPI: Kod jest napisany w zwyczajnym języku programowania (Fortran 77, Fortran 90, C, C++); przesyłanie wiadomości jest realizowane poprzez wywołanie odpowiednich procedur lub funkcji. Wszystkie zmienne są lokalne dla danego procesora; inny procesor może je uzyskać tylko poprzez wymianę wiadomości. Zwykle każdy procesor realizuje ten sam program wykonywalny (Single Program Multiple Data; SPMD), jednak występuje podział na procesor (procesory) nadzorujące (master) oraz robotników (workers) lub niewolników (slaves); realizują one inne fragmenty kodu, niż master. IF (ME == MASTER) THEN CALL SUB_MASTER(parametry) ELSE CALL SUB_WORKER(parametry) ENDIF W celu umożliwienia realizacji innych części kodu przez dany procesor lub grupę procesorów, każdy procesor ma własny identyfikator (0, 1,..., NPROC-1).
, jednak występuje podział na procesor (procesory) nadzorujące (master) oraz robotników (workers) lub niewolników (slaves); realizują one inne fragmenty kodu, niż master. IF (ME == MASTER) THEN CALL SUB_MASTER(parametry) ELSE CALL SUB_WORKER(parametry) ENDIF W celu umożliwienia realizacji innych części kodu przez dany procesor lub grupę procesorów, każdy procesor ma własny identyfikator (0, 1,..., NPROC-1)..")
17
Konstrukcja systemu przesyłania wiadomości

18
Definicja i konstrukcja wiadomości Wiadomość: pakiet danych przemieszczających się między procesorami. Podobnie jak list czy faks, oprócz właściwych przesyłanych danych musi ona być opakowana w kopertę (zawierać nagłówek) umożliwiający jej dostarczenie do właściwego odbiorcy :kopertę
 umożliwiający jej dostarczenie do właściwego odbiorcy :kopertę.")
19
KopertaKoperta musi zawierać następujące informacje dla systemu przesyłania wiadomości: Procesor wysyłający Lokalizacja źródła wiadomości Typ przesyłanych danych Długość przesyłanych danych Procesor(y) odbierające Lokalizacja odbiorcy wiadomości Wielkość buforu odbiorcy
 odbierające Lokalizacja odbiorcy wiadomości Wielkość buforu odbiorcy")
20
Rodzaje przesyłania wiadomości W zależności od zachowania nadawcy po wysłaniu wiadomości, przesyłanie dzielimy na: Asynchroniczne (asynchronous send) - nadawca wysyła wiadomość i nie interesuje się jej dalszymi losami. Można to porównać do wysłania okolicznościowej kartki do dalszego znajomego. Synchroniczne - (synchronous send) nadawca żąda potwierdzenia dotarcia wiadomości. W zależności od dalszej jego akcji dalszy podział jest następujący: Wstrzymujące (blocking send) - nadawca wstrzymuje dalszą akcję do czasu potwierdzenia dotarcia wiadomości (można to porównać z wysyłaniem faksu lub rozmową telefoniczną). W MPI ten tryb wysyłania wiadomości jest standardem. Niewstrzymujące (nonblocking send) - nadawca po wysłaniu wiadomości może wykonywać coś innego, po czym sprawdza, czy wiadomość dotarła. Realizacja operacji niewstrzymujących jest kontynuowana po powrocie do programu wywołującego. Po każdej instrukcja przesyłania niewstrzymującego powinna następować odpowiadająca jej instrukcja oczekiwania na potwierdzenie odbioru wiadomości. Jeżeli instrukcja oczekiwania jest kolejną instrukcją po instrukcji wysłania, jest to równoważne przesyłaniu ``wstrzymującemu''
 nadawca żąda potwierdzenia dotarcia wiadomości. W zależności od dalszej jego akcji dalszy podział jest następujący: Wstrzymujące (blocking send) - nadawca wstrzymuje dalszą akcję do czasu potwierdzenia dotarcia wiadomości (można to porównać z wysyłaniem faksu lub rozmową telefoniczną). W MPI ten tryb wysyłania wiadomości jest standardem. Niewstrzymujące (nonblocking send) - nadawca po wysłaniu wiadomości może wykonywać coś innego, po czym sprawdza, czy wiadomość dotarła. Realizacja operacji niewstrzymujących jest kontynuowana po powrocie do programu wywołującego. Po każdej instrukcja przesyłania niewstrzymującego powinna następować odpowiadająca jej instrukcja oczekiwania na potwierdzenie odbioru wiadomości. Jeżeli instrukcja oczekiwania jest kolejną instrukcją po instrukcji wysłania, jest to równoważne przesyłaniu ``wstrzymującemu .")
21
Asynchroniczne wysyłanie wiadomości (nadawca jedynie wie, że wiadomość została wysłana)
")
22
Synchroniczne przesyłanie wiadomości (nadawca otrzymuje potwierdzenie dotarcia wiadomości)
")
23
Niewstrzymujące przesyłanie wiadomości ( nonblocking send)
")
24
Komunikacja zbiorowa (kolektywna) W MPI podstawowym trybem komunikacji jest tryb międzypunktowy od procesora do procesora. Dla ułatwienia pisania złożonych programów równoległych, które wymagają zebrania danych od wszystkich procesorów, rozesłania danych przez nadzorcę do robotników, synchronizacji procesorów, itp. wprowadzono tryb komunikacji zbiorowej, realizowany przez odpowiednie procedury MPI. Trzy najczęściej spotykane sytuacje: synchronizacja, broadcast (rozesłanie danych) i redukcja (zgrupowanie danych) są zilustrowane na poniższych rysunkach.tryb międzypunktowy Bariera - synchronizacja procesów
 i redukcja (zgrupowanie danych) są zilustrowane na poniższych rysunkach.tryb międzypunktowy Bariera - synchronizacja procesów.")
25
Broadcast - jeden procesor przesyła dane do pozostałych

26
Redukcja - procesory przekazują dane do jednego, np. w celu ich zsumowania

27
Kompilacja z użyciem bibliotek MPI Najprościej: użyć odpowiedniego skryptu wywołującego kompilator z dołączaniem bibliotek MPI: mpif77 - Fortran 77 mpicc - C mpiCC - C++ Poniżej podany jest przykład linii polecenia dla kompilacji kodu źródłowego programu hello w Fortranie 77. mpif77 -o hello hello.f Makefile FC = /usr/bin/g77 INSTALL_DIR=/opt/scali FFLAGS = -c ${OPT} -I$(INSTALL_DIR)/include LIBS = -L$(INSTALL_DIR)/lib_pgi -L$(INSTALL_DIR)/lib -lmpi -lfmpi.SUFFIXES:.f.f.o: ${FC} ${FFLAGS} $*.f hello: hello.o ${FC} -o hello $(LIBS) hello.o
/include LIBS = -L$(INSTALL_DIR)/lib_pgi -L$(INSTALL_DIR)/lib -lmpi -lfmpi.SUFFIXES:.f.f.o: ${FC} ${FFLAGS} $*.f hello: hello.o ${FC} -o hello $(LIBS) hello.o.")
28
Pisanie kodów żródłowych z użyciem MPI - inicjalizacja, zakończenie, informacje o przydzielonych procesorach. W każdym żródle muszą się znaleźć definicje zawarte w pliku mpi.h (C) lub mpif.h (Fortran); plik ten musi być zaspecyfikowany jako pierwszy plik include. Program musi zawsze zawierać instrukcję inicjalizacji MPI (MPI_Init) i zakończenia MPI (MPI_Finalize). Komunikacja między procesorami oraz inne funkcje MPI są realizowane poprzez wywołanie odpowiednich procedur.MPI_InitMPI_Finalize Ogólna postać wywołania procedur MPI jest następująca: C: ierr = MPI_Xyyyyy( parametry ) lub MPI_Xyyyyy( parametry ) Zmienna ierr typu int jest kodem wyjścia z procedury; 0 oznacza zakończenie poprawne. Należy zwrócić uwagę, że nazwa procedury MPI zaczyna się od MPI_X, gdzie X jest pierwszą literą nazwy procedury (zawsze duża litera); dalsza część nazwy jest pisana małymi literami. Fortran (77 lub 90): CALL MPI_XYYYYY( parametry, IERROR ) Podobnie jak w wersji C, IERROR (zmienna typu INTEGER) jest kodem wyjścia. Zgodnie z konwencją Fortranu, wielkość liter w nazwie procedury nie odgrywa roli.
 lub mpif.h (Fortran); plik ten musi być zaspecyfikowany jako pierwszy plik include. Program musi zawsze zawierać instrukcję inicjalizacji MPI (MPI_Init) i zakończenia MPI (MPI_Finalize). Komunikacja między procesorami oraz inne funkcje MPI są realizowane poprzez wywołanie odpowiednich procedur.MPI_InitMPI_Finalize Ogólna postać wywołania procedur MPI jest następująca: C: ierr = MPI_Xyyyyy( parametry ) lub MPI_Xyyyyy( parametry ) Zmienna ierr typu int jest kodem wyjścia z procedury; 0 oznacza zakończenie poprawne. Należy zwrócić uwagę, że nazwa procedury MPI zaczyna się od MPI_X, gdzie X jest pierwszą literą nazwy procedury (zawsze duża litera); dalsza część nazwy jest pisana małymi literami. Fortran (77 lub 90): CALL MPI_XYYYYY( parametry, IERROR ) Podobnie jak w wersji C, IERROR (zmienna typu INTEGER) jest kodem wyjścia. Zgodnie z konwencją Fortranu, wielkość liter w nazwie procedury nie odgrywa roli..")
29
Przykład programu z użyciem bibliotek MPI (C): #include "mpi.h" #include int main( argc, argv ) int argc; char **argv; { int rank, size; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); printf( "Hello world! I'm %d of %d\n",rank, size ); MPI_Finalize(); return 0; }
; MPI_Finalize(); return 0; }.")
30
Przykład programu z użyciem bibliotek MPI (Fortran 77): program main include "mpif.h" integer rank, size call MPI_Init( ierr ) call MPI_Comm_rank( MPI_COMM_WORLD, rank, ierr ) call MPI_Comm_size( MPI_COMM_WORLD, size, ierr ) print 10, rank, size call MPI_Finalize(ierr); 10 format("Hello world! I'm",i3," of",i3) return end
 return end.")
31
program main include 'mpif.h' integer rank, size, to, from, tag, count, i, ierr integer src, dest integer st_source, st_tag, st_count integer status(MPI_STATUS_SIZE) double precision data(100) call MPI_INIT( ierr ) call MPI_COMM_RANK( MPI_COMM_WORLD, rank, ierr ) call MPI_COMM_SIZE( MPI_COMM_WORLD, size, ierr ) print *, 'Process ', rank, ' of ', size, ' is alive' dest = size - 1 src = 0 if (rank.eq. src) then to = dest count = 10 tag = 2001 do 10 i=1, 10 10 data(i) = i call MPI_SEND( data, count, MPI_DOUBLE_PRECISION, to, + tag, MPI_COMM_WORLD, ierr ) else if (rank.eq. dest) then tag = MPI_ANY_TAG count = 10 from = MPI_ANY_SOURCE call MPI_RECV( data, count, MPI_DOUBLE_PRECISION, from, + tag, MPI_COMM_WORLD, status, ierr ) print *, rank, ' received', (data(i),i=1,10) endif call MPI_FINALIZE( ierr ) end
 then to = dest count = 10 tag = 2001 do 10 i=1, data(i) = i call MPI_SEND( data, count, MPI_DOUBLE_PRECISION, to, + tag, MPI_COMM_WORLD, ierr ) else if (rank.eq. dest) then tag = MPI_ANY_TAG count = 10 from = MPI_ANY_SOURCE call MPI_RECV( data, count, MPI_DOUBLE_PRECISION, from, + tag, MPI_COMM_WORLD, status, ierr ) print *, rank, received , (data(i),i=1,10) endif call MPI_FINALIZE( ierr ) end.")
32
#include "mpi.h" #include int main( argc, argv ) int argc; char **argv; { int rank, size, to, from, tag, count, i, ierr; int src, dest; int st_source, st_tag, st_count; MPI_Status status; double data[100]; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); printf("Process %d of %d is alive\n",rank,size); dest = size - 1; src = 0; if (rank == src) { to = dest; count = 10; tag = 2001; for (i=0;i<10;i++) { data[i] = i+1; } MPI_Send( data, count, MPI_DOUBLE_PRECISION, to,tag, MPI_COMM_WORLD ); }else if (rank == dest) { tag = MPI_ANY_TAG; count = 10; from = MPI_ANY_SOURCE; MPI_Recv( data, count, MPI_DOUBLE_PRECISION, from,tag, MPI_COMM_WORLD, &status ); printf("%d received ",rank); for (i=0;i<10;i++) printf ("%10.5f",data[i]); printf("\n"); } MPI_Finalize(); return 0; }
![#include mpi.h #include int main( argc, argv ) int argc; char **argv; { int rank, size, to, from, tag, count, i, ierr; int src, dest; int st_source, st_tag, st_count; MPI_Status status; double data[100]; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); printf( Process %d of %d is alive\n ,rank,size); dest = size - 1; src = 0; if (rank == src) { to = dest; count = 10; tag = 2001; for (i=0;i<10;i++) { data[i] = i+1; } MPI_Send( data, count, MPI_DOUBLE_PRECISION, to,tag, MPI_COMM_WORLD ); }else if (rank == dest) { tag = MPI_ANY_TAG; count = 10; from = MPI_ANY_SOURCE; MPI_Recv( data, count, MPI_DOUBLE_PRECISION, from,tag, MPI_COMM_WORLD, &status ); printf( %d received ,rank); for (i=0;i<10;i++) printf ( %10.5f ,data[i]); printf( \n ); } MPI_Finalize(); return 0; }](http://images.slideplayer.pl/2/832983/slides/slide_32.jpg "#include mpi.h #include int main( argc, argv ) int argc; char **argv; { int rank, size, to, from, tag, count, i, ierr; int src, dest; int st_source, st_tag, st_count; MPI_Status status; double data[100]; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); printf( Process %d of %d is alive\n ,rank,size); dest = size - 1; src = 0; if (rank == src) { to = dest; count = 10; tag = 2001; for (i=0;i<10;i++) { data[i] = i+1; } MPI_Send( data, count, MPI_DOUBLE_PRECISION, to,tag, MPI_COMM_WORLD ); }else if (rank == dest) { tag = MPI_ANY_TAG; count = 10; from = MPI_ANY_SOURCE; MPI_Recv( data, count, MPI_DOUBLE_PRECISION, from,tag, MPI_COMM_WORLD, &status ); printf( %d received ,rank); for (i=0;i<10;i++) printf ( %10.5f ,data[i]); printf( \n ); } MPI_Finalize(); return 0; }")