Pobierz prezentację
1
Systemy Wspomagania Decyzji

2
Zagadnienia omawiane na kursie
Sieci neuronowe (wykład 1 i 2) Algorytmy genetyczne i ewolucyjne (wykład 3 i 4) Systemy ekspertowe (wykład 5)
 Algorytmy genetyczne i ewolucyjne (wykład 3 i 4) Systemy ekspertowe (wykład 5)")
3
Sieci neuronowe Sieci neuronowe to matematyczne i obliczeniowe modele, których budowa została zainspirowana strukturą i funkcjonowaniem biologicznych sieci neuronowych. Zbudowane są z połączonych grup sztucznych neuronów. W większości przypadków są układami adaptacyjnymi, które potrafią zmieniać swoją strukturę w oparciu o zewnętrzne lub wewnętrzne informacje, które przepływają przez sieć w fazie uczenia. Podstawowym elementem obliczeniowym takiej sieci jest sztuczny neuron.

4
Uproszczony schemat neuronu biologicznego

5
Sztuczny neuron bez funkcji aktywacji
x1 x3 x2 w1 w3 w2 Sumator wyjście, y

6
Przykład 0,7 0,5 Sumator 1,2 -0,2 2,89 2,3 1,0 Jest to przykład neuronu liniowego. Można pominąć funkcję aktywacji.

7
Ogólny neuron nieliniowy
dowolna nieliniowa funkcja aktywacji x1 x3 x2 w1 w3 w2 Sumator Funkcja aktywacji wyjście

8
Zauważmy, że w przypadku gdy funkcja aktywacji ma postać
to neuron nieliniowy staje się liniowym, gdyż

9
Neuron z funkcją progową
1 -1 (Inna nazwa to funkcja Heaviside’a)
")
10
Przykłady funkcji aktywacji
Funkcja bipolarna Funkcja unipolarna

11
Funkcji aktywacji bipolarna
+1 -1

12
Funkcja sigmoidalna Wykres dla b=1.

13
S Poniżej jest przedstawiony schemat perceptronu wejście wyjście x0=1
-1 xn wn

14
Oznaczenia Wektory: Dodawanie wektorów i mnożenie przez skalar (liczbę): gdzie Iloczyn skalarny:
: gdzie Iloczyn skalarny:")
15
Funkcja aktywacji perceptronu
Rysunkowy schemat perceptronu sugeruje następującą funkcję aktywacji W literaturze spotyka się także (może nawet częściej) inną definicję W gruncie rzeczy nie ma tu zasadniczej różnicy, gdyż perceptron służy do klasyfikacji: czy sygnał wejściowy (reprezentowany przez punkt lub wektor) należy do jednej klasy czy do drugiej.
 inną definicję. W gruncie rzeczy nie ma tu zasadniczej różnicy, gdyż perceptron służy do klasyfikacji: czy sygnał wejściowy (reprezentowany przez punkt lub wektor) należy do jednej klasy czy do drugiej.")
16
Cześć liniowa perceptronu (sumator, S)
Dla danych wag perceptronu w1, …, wn oraz progu -b, gdy impulsy wejściowe są równe x1, …, xn, to pobudzenie neuronu jest równe Używając symbolu iloczynu skalarnego możemy to zapisać też tak gdzie

17
Istota działania perceptronu
Funkcja aktywacji rozróżnia dwa przypadki: (i) s > 0, (ii) s ≤ 0, zatem to co jest kluczowe w działaniu perceptronu sprowadza się do klasyfikacji punktów (wektorów) x=(x1,…,xn) wg poniższych nierówności: Oznacza to, że punkty x spełniające nierówność (i) będą klasyfikowane do jednej kategorii a punkty spełniające nierówność (ii) do drugiej.
 s > 0, (ii) s ≤ 0, zatem to co jest kluczowe w działaniu perceptronu sprowadza się do klasyfikacji punktów (wektorów) x=(x1,…,xn) wg poniższych nierówności: Oznacza to, że punkty x spełniające nierówność (i) będą klasyfikowane do jednej kategorii a punkty spełniające nierówność (ii) do drugiej.")
18
Algorytm uczenia perceptronu
Uczenie sieci polega na dobieraniu wag tak, aby dla zadanych impulsów wejściowych otrzymywać oczekiwane wartości wyjściowe z neuronów. Za chwilę zajmiemy się prostym przypadkiem (mamy tylko jeden neuron) poszukiwania wag wi oraz progu b dla perceptronu. Dany mamy ciąg uczący, który składa się z dowolnej skończonej liczby wektorów oraz dodatkowych informacji mówiących do której z dwóch klas te wektory należą. Tę dodatkową informację będziemy reprezentować symbolem d (d=+1 (pierwsza klasa) lub d=-1 (druga klasa)). Przy numeracji kolejnych wektorów uczących użyjemy indeksów górnych, np. x(2), aby odróżniać się od numerowania składowych wektora (indeksy dolne). Mamy więc ciąg uczący Liczba elementów ciągu uczącego (długość ciągu) oznaczamy przez T: T=liczba par uczących w epoce
 poszukiwania wag wi oraz progu b dla perceptronu. Dany mamy ciąg uczący, który składa się z dowolnej skończonej liczby wektorów oraz dodatkowych informacji mówiących do której z dwóch klas te wektory należą. Tę dodatkową informację będziemy reprezentować symbolem d (d=+1 (pierwsza klasa) lub d=-1 (druga klasa)). Przy numeracji kolejnych wektorów uczących użyjemy indeksów górnych, np. x(2), aby odróżniać się od numerowania składowych wektora (indeksy dolne). Mamy więc ciąg uczący. Liczba elementów ciągu uczącego (długość ciągu) oznaczamy przez T: T=liczba par uczących w epoce.")
19
Algorytm uczenia perceptronu
Losujemy wagi początkowe w1, …,wn oraz próg b. Dla t=1 do t=T wykonujemy 3., 4., 5. Na wejście podajemy kolejny wektor uczące x=x(t) i obliczamy y=f(s(x)). Porównujemy wartość wyjściową y z oczekiwaną wartością d=dt z ciągu uczącego. Dokonujemy modyfikacji wag: 5.1 Jeżeli y≠d, to w := w + d·x, b=b+d. 5.2 Jeżeli y=d, to wagi pozostają bez zmian. 6. Jeżeli w 4. była choć jedna modyfikacja, to wracamy do 2. 7. Koniec. Uwagi: 1) Zauważmy, że w p. 5.1) operacja w:=w+d·x oznacza tak naprawdę w:=w+x, b=b+1 lub w:=w-x, b=b-1. 2) Tak naprawdę to nie musimy obliczać wartości y=f(s) w p. 2. Wystarczy sprawdzać warunek: s=w○x+b > 0.
 i obliczamy y=f(s(x)). Porównujemy wartość wyjściową y z oczekiwaną wartością d=dt z ciągu uczącego. Dokonujemy modyfikacji wag: 5.1 Jeżeli y≠d, to w := w + d·x, b=b+d. 5.2 Jeżeli y=d, to wagi pozostają bez zmian. 6. Jeżeli w 4. była choć jedna modyfikacja, to wracamy do Koniec. Uwagi: 1) Zauważmy, że w p. 5.1) operacja w:=w+d·x oznacza tak naprawdę w:=w+x, b=b+1 lub w:=w-x, b=b-1. 2) Tak naprawdę to nie musimy obliczać wartości y=f(s) w p. 2. Wystarczy sprawdzać warunek: s=w○x+b > 0.")
21
Przykładowy plik z danymi, n=2
perceptron-input.txt 3 2 1 2 2 0 6 4 -2 8 -2 0 0 0 Dla początkowych wag w1=2 w2=2 b=-4, wynik uczenia perceptronu daje: w1=8 w2=3 b=-17. Zastosowano 10 epok uczenia.

22
Uwagi do implementacji
Zbiór danych do nauki (samples) ma liczność T=numOfSamples. Zbiór tych wektorów, czyli ciąg jest przechowywany w tablicy dwuwymiarowej double test[LIMIT][N], gdzie N=n (czyli liczba wejść perceptronu). Należy więc sprawdzać warunek Wektory uczące są przechowywane wierszami: i-ty wiersz w tablicy test to i-ty wektor uczący (w C indeksowanie jednak zaczynamy od zera, czyli t=0,…,T-1): Pierwszy wektor, t=0. x1 x2 xn 2 3 … -1 5 -2 7 Ostatni wektor, t=T-1.
 ma liczność T=numOfSamples. Zbiór tych wektorów, czyli ciąg. jest przechowywany w tablicy dwuwymiarowej double test[LIMIT][N], gdzie N=n (czyli liczba wejść perceptronu). Należy więc sprawdzać warunek. Wektory uczące są przechowywane wierszami: i-ty wiersz w tablicy test to i-ty wektor uczący (w C indeksowanie jednak zaczynamy od zera, czyli t=0,…,T-1): Pierwszy wektor, t=0. x1. x2. xn … Ostatni wektor, t=T-1.")
23
Wczytywanie danych (uproszczona funkcja, n=NUM=2)
void get_data() { char* fileName = "perceptron-input.txt"; FILE *fp; int i, posnum, negnum; double x, y; if ((fp = fopen(fileName,"r")) == NULL) { printf ("Could not open file. Quitting ..."); exit(1);} /* Total number of learning vectors */ numOfSamples = 0; /* read the first group */ fscanf(fd, "%d", &posnum); for (i = 0; i < posnum; i++) { fscanf(fp, "%lf %lf", &x, &y); test[numOfSamples][0] = x; test[numOfSamples][1] = y; d[numOfSamples++] = 1; /* 1 for first group */ } /* read the second group */ fscanf(fp, "%d", &negnum); for (i = 0; i < negnum; i++) { fscanf(fd, "%lf %lf", &x, &y); test[numOfSamples][0] = x; test[numOfSamples][1] = y; d[numOfSamples++] = -1; /* -1 for second group */
 { char* fileName = perceptron-input.txt ; FILE *fp; int i, posnum, negnum; double x, y; if ((fp = fopen(fileName, r )) == NULL) { printf ( Could not open file. Quitting ... ); exit(1);} /* Total number of learning vectors */ numOfSamples = 0; /* read the first group */ fscanf(fd, %d , &posnum); for (i = 0; i < posnum; i++) { fscanf(fp, %lf %lf , &x, &y); test[numOfSamples][0] = x; test[numOfSamples][1] = y; d[numOfSamples++] = 1; /* 1 for first group */ } /* read the second group */ fscanf(fp, %d , &negnum); for (i = 0; i < negnum; i++) { fscanf(fd, %lf %lf , &x, &y); test[numOfSamples][0] = x; test[numOfSamples][1] = y; d[numOfSamples++] = -1; /* -1 for second group */")
24
Przykład klasyfikacji perceptronowej

25
S S Neuron typu adaline x0=1 w0 x1 w1 x2 w2 1 y -1 xn wn
w(t+1)=w(t)+hdx(t) d
=w(t)+hdx(t) d.")
26
Neuron typu adaline Model neuronu typu adaline (ang. Adapitive Linear Neuron) został zaproponowany przez Bernarda Widrowa. Schemat ogólny jest pokazany na rysunku. Funkcja aktywacji przyjmowana jest zazwyczaj jako bipolarna (zwana też signum od słowa znak) gdzie Wyrażenie na s czasami zapisujemy w sposób zwarty wprowadzając rozszerzony wektor wag tak, aby zawierał próg b oraz rozszerzony wektor wejściowy zawierający dodatkowo jeden impuls x0=1: Wtedy
 został zaproponowany przez Bernarda Widrowa. Schemat ogólny jest pokazany na rysunku. Funkcja aktywacji przyjmowana jest zazwyczaj jako bipolarna (zwana też signum od słowa znak) gdzie. Wyrażenie na s czasami zapisujemy w sposób zwarty wprowadzając rozszerzony wektor wag tak, aby zawierał próg b oraz rozszerzony wektor wejściowy zawierający dodatkowo jeden impuls x0=1: Wtedy.")
27
Budowa tego neuronu jest bardzo podobna do modelu perceptronu, a jedyna różnica dotyczy algorytmu uczenia. Sposób obliczania sygnału wyjściowego jest taki sam jak w klasycznym perceptronie, natomiast przy uczeniu neuronu adaline porównuje się sygnał wzorcowy d z sygnałem s na wyjściu części liniowej neuronu, co daje następujący błąd Uczenie (dobór wag) sprowadza się do minimalizacji funkcji błędu zdefiniowanej wzorem (średni błąd kwadratowy):
 sprowadza się do minimalizacji funkcji błędu zdefiniowanej wzorem (średni błąd kwadratowy):")
28
Zgodnie z algorytmem – zaproponowanym przez Widrowa – do minimalizacji funkcji błędu stosuje się metodę największego spadku (podobnie jest dla neuronu sigmoidalnego). Tak więc wagi w neuronie typu adaline modyfikujemy następująco w którym h jest współczynnikiem uczenia, E(w) to zdefiniowana poprzednio funkcja błędu. Współczynnik h na ogół dobiera się eksperymentalnie. Pamiętajmy, że w powyższym wzorze występuje rozszerzony wektor wag, a zatem mamy w0=b.
 to zdefiniowana poprzednio funkcja błędu. Współczynnik h na ogół dobiera się eksperymentalnie. Pamiętajmy, że w powyższym wzorze występuje rozszerzony wektor wag, a zatem mamy w0=b.")
29
Gradientowa metoda największego spadku

30
Obliczamy pochodną Zatem wzór na modyfikację wag przybiera postać Powyższa reguła jest szczególnym przypadkiem tzw. reguły delta (w tym przypadku nie uwzględniamy funkcji aktywacji neuronu).
.")
31
Do uczenia neuronu będziemy potrzebowali ciągu uczącego
gdzie x(t) to wektor sygnałów wejściowych, dt to oczekiwane wartość wyjście (1). Podstawowy krok modyfikacji wag, tj. przejście od wektora uczącego t do t+1, ma postać (w zapisie wektorowym) W zapisie dla poszczególnych składowych mamy (pamiętajmy, że w0=b, x0=1)
 to wektor sygnałów wejściowych, dt to oczekiwane wartość wyjście (1). Podstawowy krok modyfikacji wag, tj. przejście od wektora uczącego t do t+1, ma postać (w zapisie wektorowym) W zapisie dla poszczególnych składowych mamy (pamiętajmy, że w0=b, x0=1)")
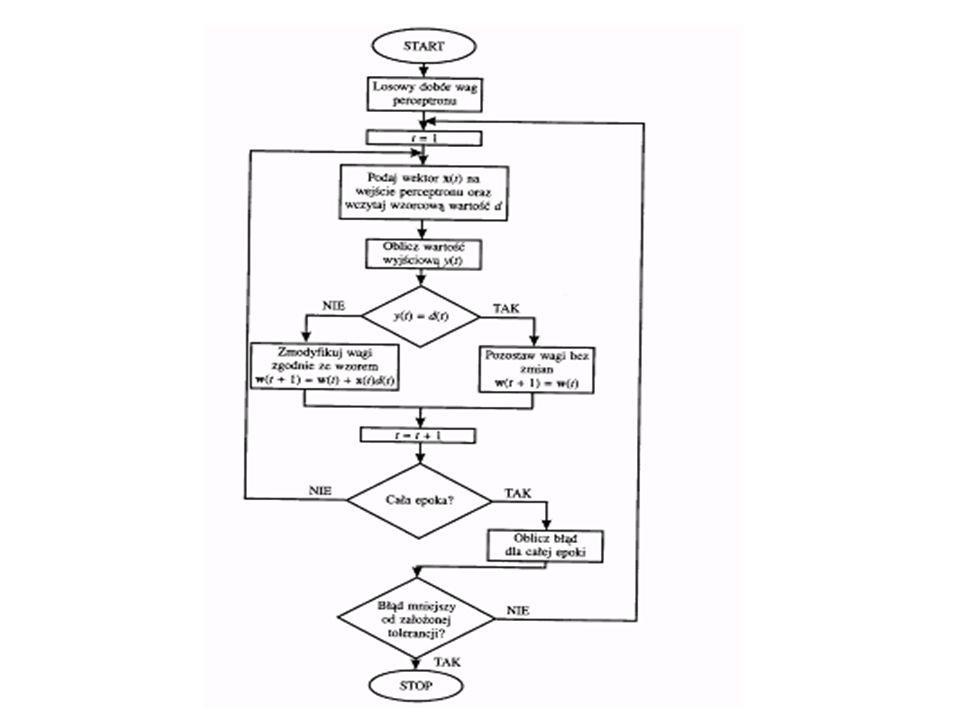
32
Schemat blokowy algorytmu uczenia neuronu typu adaline.

33
Optymalny dobór wag w1, w2, w3 i progu b=w0 jest następujący:
Przykład. Zastosować procedurę uczenia neuronu typu adaline o trzech wejściach (n=3). Posłużyć się danymi z poniższej tabeli. x1 x2 x3 d 1 -1 Optymalny dobór wag w1, w2, w3 i progu b=w0 jest następujący: -0,25; -0,25; 0,75; 0,25. Wypisywać wartości po każdej epoce. Przetestować współczynnik uczenia h=0,1 oraz h=0,001.
. Posłużyć się danymi z poniższej tabeli. x1. x2. x3. d Optymalny dobór wag w1, w2, w3 i progu b=w0 jest następujący: -0,25; -0,25; 0,75; 0,25. Wypisywać wartości po każdej epoce. Przetestować współczynnik uczenia h=0,1 oraz h=0,001.")
34
Model adaline (podsumowanie)
Dany jest ciąg uczący W ciągu tym x(t) oznacza wektor sygnałów wejściowych a dt oznacza żądaną wartość wyjścia z neuronu. Algorytm uczenia (wersja reguły delta) ma postać
 oznacza wektor sygnałów wejściowych a dt oznacza żądaną wartość wyjścia z neuronu. Algorytm uczenia (wersja reguły delta) ma postać.")
35
Wpływ współczynnika uczenia h na jakość wag
W obu przypadkach wagi początkowe były zerowe (wi=0, b=0). Wynik działania metody adaline: liczba epok=1000, h=0,1: Wynik działania metody adaline: liczba epok=1000, h=0,01:
. Wynik działania metody adaline: liczba epok=1000, h=0,1: Wynik działania metody adaline: liczba epok=1000, h=0,01:")
36
S S Model neuronu sigmoidalnego x0=1 w0 x1 w1 x2 w2 xn wn
w(t+1)=w(t)+h(d-f(s(t))f’(s(t))x(t) d
=w(t)+h(d-f(s(t))f’(s(t))x(t) d.")
37
Neuron sigmoidalny Funkcja aktywacji jest następująca gdzie
jest zadanym parametrem. Zatem wartość sygnału wyjściowego jest dana wzorem

38
Wyrażenie na s możemy zapisać w sposób bardziej zwarty wprowadzając rozszerzony wektor wag tak, aby zawierał próg b=q oraz rozszerzony wektor wejściowy zawierający dodatkowo jeden impuls x0=1: Wtedy

39
Miarę błędu E(w) definiujemy jako kwadrat różnicy wartości wzorcowej i wartości otrzymanej na wyjściu przy aktualnych wagach Do uczenia używa się reguły największego spadku. Ale teraz – w odróżnieniu od modelu adaline – uwzględniamy także funkcję aktywacji. Wagi uaktualniamy zgodnie ze wzorem metody największego spadku gdzie to gradient funkcji wielu zmiennych E(w)=E(w0,…,wn).
=E(w0,…,wn).")
40
Rozpisując wzór na modyfikacje wag na poszczególne składowe otrzymujemy
w którym h jest współczynnikiem uczenia, E(w) to zdefiniowana poprzednio funkcja błędu. Współczynnik h na ogół dobiera się eksperymentalnie. Pamiętajmy, że w powyższym wzorze występuje rozszerzony wektor wag, a zatem mamy w0=b=q.
 to zdefiniowana poprzednio funkcja błędu. Współczynnik h na ogół dobiera się eksperymentalnie. Pamiętajmy, że w powyższym wzorze występuje rozszerzony wektor wag, a zatem mamy w0=b=q.")
41
Obliczamy pochodną Pochodna funkcji sigmoidalnej (liczyliśmy na wykładzie 01) f’(s) wyraża się przez samą funkcję f (s) wzorem
 f’(s) wyraża się przez samą funkcję f (s) wzorem.")
42
Zatem wzór na modyfikację wag przybiera postać
Powyższa reguła jest szczególnym przypadkiem tzw. reguły delta (w tym przypadku uwzględniamy funkcję aktywacji neuronu).
.")
43
Do uczenia neuronu będziemy potrzebowali ciągu uczącego
gdzie x(t) to wektor sygnałów wejściowych, dt to oczekiwane wartość wyjście. Podstawowy krok modyfikacji wag, tj. przejście od wektora uczącego t do t+1, ma postać (w zapisie wektorowym) W zapisie dla poszczególnych składowych mamy (pamiętajmy, że w0=b, x0=1)
 to wektor sygnałów wejściowych, dt to oczekiwane wartość wyjście. Podstawowy krok modyfikacji wag, tj. przejście od wektora uczącego t do t+1, ma postać (w zapisie wektorowym) W zapisie dla poszczególnych składowych mamy (pamiętajmy, że w0=b, x0=1)")
44
S S Model neuronu Hebba x0=1 w0 x1 w1 x2 w2 y xn wn w(t+1)=w(t)+hyx(t)
=w(t)+hyx(t)")
45
Budowa neuronu Hebba jest podobna jak w przypadku adaline czy sigmoidalnego, ale charakteryzuje się specyficzną metodą uczenia, znaną jako reguła Hebba. Reguła ta występuje w wersji z nauczycielem i bez nauczyciela. Donald O. Hebb badając działanie komórek nerwowych zauważył, że powiązanie dwóch komórek jest wzmacniane, jeśli obie są pobudzane w tym samym czasie. Sformułował to tak: Jeżeli akson komórki A bierze systematycznie udział w pobudzaniu komórki B powodującym jej aktywację, to wywołuje to zmianę metaboliczną w jednej lub obu tych komórkach, która prowadzi do wzrostu skuteczności pobudzania komórki B przez komórkę A. Szczególnie interesująca jest wersja uczenia bez nauczyciela (czasami mówi się „bez nadzoru” od ang. unsupervised). Oznacza to, że na wejście neuronu podawane są tylko „zadania” – bez wskazówek dotyczących rozwiązania.
. Oznacza to, że na wejście neuronu podawane są tylko „zadania – bez wskazówek dotyczących rozwiązania.")
46
Zgodnie z regułą Hebba modyfikacja wagi wi — czyli Dwi — jest proporcjonalna do iloczynu sygnału wejściowego oraz wyjściowego: Tak więc podstawowy krok procedury uczenia ma postać

47
Pewnym problemem w podstawowej metodzie Hebba jest to, że wagi maja tendencję do przyjmowania dużych wartości, gdyż w każdym cyklu uczącym dodajemy przyrosty Dw: Jedną z metod poprawy tej reguły jest użycie tzw. współczynnika zapominania 0<g<1, który zmniejsza znaczenie aktualnych wag. Zmodyfikowana reguła Hebba ma postać Współczynnik zapominania g stanowi najczęściej niewielki procent stałej uczenia h. Typowe wartości to g<0,1.

48
Neuron Hebba występuje także w wersji z nauczycielem
Neuron Hebba występuje także w wersji z nauczycielem. Wtedy modyfikacja wag w cyklu uczenia ma postać Gdzie d oznacza sygnał wzorcowy Tak więc podstawowy krok procedury uczenia ma postać

49
Przykład Przykład dotyczy reguły Hebba bez nauczyciela. Dysponujemy tylko wektorami wejściowymi – nie są znane wartości na wyjściu. Współczynnik uczenia h=1. Wykonać trening dla dwóch przypadków funkcji aktywacji: funkcja signum oraz funkcja sigmoidalna (przyjąć b=1).
.")
50
Przykład Przykład dotyczy uczenia neuronu z wykorzystaniem reguły Hebba z nauczycielem. Zadanie polega na modyfikacji wag, aby rozpoznawać cyfry 1 i 4. Białym pikselom przypisujemy -1, a czarnym +1.

51
Otrzymujemy następujące dwa wektory ciągu uczącego:
Jako funkcję aktywacji użyjemy funkcji typu signum współczynnik uczenia h=0,2, a wagi początkowe zerowe (w1=w2=0).
.")
52
Przykład 3 W przykładzie zaprezentujemy uczenie bez nauczyciela z zapominaniem, zastosowane do sieci złożonej z czterech neuronów o nieliniowości typu skok jednostkowy. Każdy neuron jest połączony z wszystkimi składowymi wektora wejściowego x. Zakładamy, że wagi polaryzacji są stałe i równe -0,5: Początkowe wartości wag mają wartości: Ciąg uczący składa się z następujących wektorów: Każdy wiersz odpowiada wagom odpowiedniego neuronu. Przyjmujemy stałą uczenia h=0,1 i współczynnik zapominania g=h/3. Funkcja aktywacji:

53
Ilustracja połączeń neuronów do Przykładu 3.

54
Po kilkunastu cyklach uczących otrzymujemy następująca macierz wag:
Oznacza to, że wagi między wejściem 2 i neuronem 4 oraz między wejściem 4 i neuronem 2 zostały wzmocnione. Sieć nauczyła się rozpoznawać samoczynnie pewne związki między wejściem 2 i neuronem 4 oraz między wejściem 4 i neuronem 2.

55
Sieć wielowarstwowa

56
Sieć wielowarstwową tworzą neurony ułożone w wielu warstwach, przy czym oprócz warstwy wejściowej i wyjściowej istnieje co najmniej jedna warstwa ukryta. Czasami sieć taka określa się mianem perceptronu wielowarstwowego. Teraz przeanalizujemy dokładniej szczególny przypadek – sieć o jednej warstwie ukrytej.

57
Oznaczenia wagi w warstwie numer 1 (ukryta) dla połączenia: j-ty sygnał do i-tego neuronu wagi w warstwie numer 2 (wyjściowa) dla połączenie: od j-tego neuronu w warstwie 1 do i-tego w warstwie 2 liczba sygnałów wejściowych do sieci liczba neuronów w warstwie ukrytej (warstwa 1) liczba neuronów w warstwie wyjściowej (= liczba wyjść z sieci) rozszerzony wektor wejść (x0=1) oczekiwane wyjście wartości aktualnie generowane przez sieć na wyjściu wartości aktualnie generowane przez warstwę ukrytą funkcja aktywacji poszczególnych neuronów sieci (zakładamy, że jest różniczkowalna)
 dla połączenie: od j-tego neuronu w warstwie 1 do i-tego w warstwie 2. liczba sygnałów wejściowych do sieci. liczba neuronów w warstwie ukrytej (warstwa 1) liczba neuronów w warstwie wyjściowej (= liczba wyjść z sieci) rozszerzony wektor wejść (x0=1) oczekiwane wyjście. wartości aktualnie generowane przez sieć na wyjściu. wartości aktualnie generowane przez warstwę ukrytą. funkcja aktywacji poszczególnych neuronów sieci (zakładamy, że jest różniczkowalna)")
58
Wzory do algorytmu propagacji wstecznej

59
Działanie algorytmu propagacji wstecznej dla sieci jednokierunkowej z jedną warstwa ukrytą jest następujące. Mamy dany ciąg par wektorów: gdzie (Pamiętajmy, że w obliczeniach rozszerzamy wektor x(t) o jedną pozycję na początku tak, aby x0(t)=1. Wtedy oczywiście x(t)RN+1). Jedna epoka polega na wykorzystaniu całego ciągu uczącego. Zatem mamy pętlę, w której wykorzystujemy wzory z poprzedniego slajdu:
 o jedną pozycję na początku tak, aby x0(t)=1. Wtedy oczywiście x(t)RN+1). Jedna epoka polega na wykorzystaniu całego ciągu uczącego. Zatem mamy pętlę, w której wykorzystujemy wzory z poprzedniego slajdu:")
60
Jeżeli funkcja aktywacji neuronów w sieci jest typu sigmoidalnego, to
oraz pochodna