Pobierz prezentację
1
Wykład 6 Dwie niezależne próby
Często porównujemy wartości pewnej zmiennej w dwóch populacjach. Przykłady: Grupa zabiegowa i kontrolna Lekarstwo a placebo Pacjenci biorący dwa podobne lekarstwa Mężczyźni a kobiety Dwie różne linie genetyczne

2
Rozkład cechy Y w populacji 1 jest
N(1, 1). Bierzemy próbę o rozmiarze n1, Rozkład cechy Y w populacji 2 jest N(2, 2). Bierzemy próbę o rozmiarze n2,
. Bierzemy próbę o rozmiarze n1, Rozkład cechy Y w populacji 2 jest. N(2, 2). Bierzemy próbę o rozmiarze n2,")
3
Podstawowe pytanie: Jaka jest różnica między średnimi w populacjach: 1-2 ?
Idea: znaleźć PU dla 1 - 2 jest estymatorem 1- 2 i będzie środkiem przedziału ufności. Należy jeszcze wyznaczyć SE.

4
Standardowy błąd dla różnicy dwóch średnich
Jak policzyć SE dla ? Istnieją dwa sposoby: uśredniony (łączony) i nieuśredniony (niełączony) (ang. pooled, unpooled) Gdy n1 = n2 obie metody dają te same wyniki Na ogół będziemy używać niełączonego SE Metodę łączonego SE zastosujemy, gdy będzie można założyć, że 1=2 (albo gdy o to poprosi wykładowca) W obu przypadkach SE liczone jest przy pomocy s1, s2, oraz n1, n2
 i nieuśredniony (niełączony) (ang. pooled, unpooled) Gdy n1 = n2 obie metody dają te same wyniki. Na ogół będziemy używać niełączonego SE. Metodę łączonego SE zastosujemy, gdy będzie można założyć, że 1=2 (albo gdy o to poprosi wykładowca) W obu przypadkach SE liczone jest przy pomocy s1, s2, oraz n1, n2.")
5
Metoda zwykła (niełączona)
Liczymy SE1 = i SE2 = osobno w obu próbach. Obliczamy nieuśrednione SE:

6
Metoda łączona Znajdujemy sumę kwadratów odchyleń dla obu prób: ,
uśrednioną wariancję: sc2 = , a następnie uśrednione (łączone) SE: (U)SE=
 SE: (U)SE= .")
7
Przykład: próba 1: n1 = 15, y1 = 75, SS1 = 600

8
Wyniki z obu metod nie są takie same, ale są dość podobne.
Zauważmy, że mieliśmy tu s1 = 6.55 i s2 = (Gdy s1=s2, oba rachunki dają to samo SE i PU.)
")
9
Przedział ufności dla 1 – 2
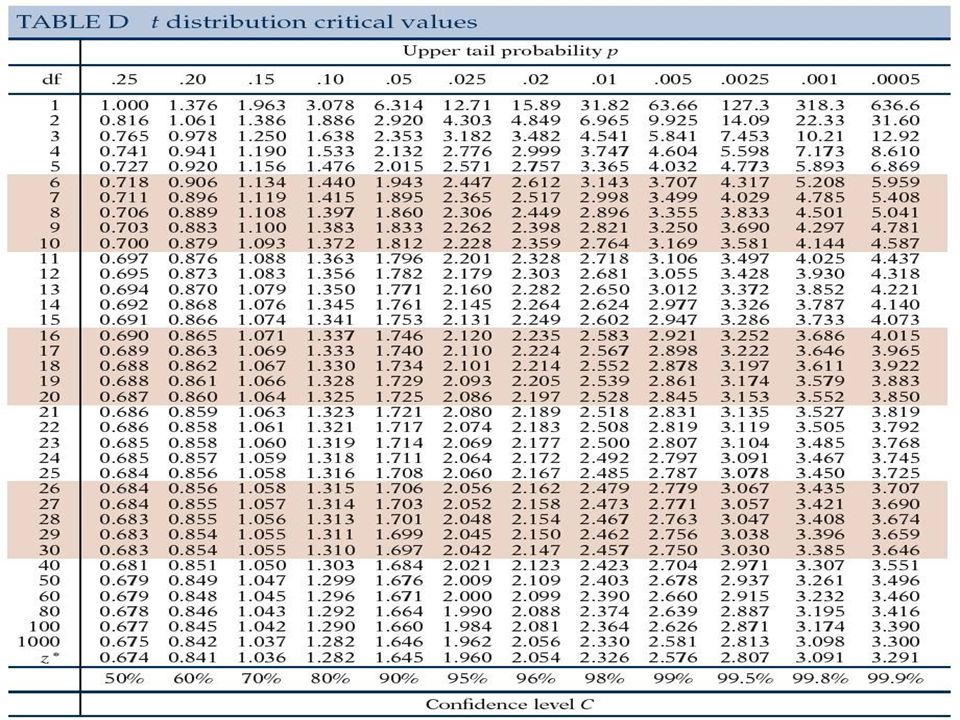
Skonstruujemy przedział ufności dla 1 – 2 Przypomnienie: PU dla : y t/2 SEy = (estymator) (kwantyl)(SE) Estymator dla 1 - 2 : y1-y2 Potrzebujemy t/2 : Ile użyć stopni swobody? (Wzoru nie trzeba pamiętać, będzie podawany.) df=
 (kwantyl)(SE) Estymator dla 1 - 2 : y1-y2. Potrzebujemy t/2 : Ile użyć stopni swobody (Wzoru nie trzeba pamiętać, będzie podawany.) df=")
10
Liczba stopni swobody wyliczona z poprzedniego wzoru nie będzie większa niż n1 + n2 – 2; w przybliżonych oblicze-niach często stosujemy df = n1 + n2 – 2 stosujemy też gdy możemy założyć. Nie mniejsza niż minimum z wartości n1–1 i n2–1. Jeżeli możemy założyć, że wariancje w obu grupach są równe to stosujemy uśredniony estymator wariancji i df = n1 + n2 – 2.

11
Stosujemy ``nieuśredniony’’ SE, o ile w zadaniu nie będzie specjalnie wymagane użycie (U)SE.
PU na poziomie ufności (1-) dla 1 - 2: (y1-y2) t(df)/2 SE(y1-y2)
 dla 1 - 2: (y1-y2) t(df)/2 SE(y1-y2)")
12
Przykład (cd) Skonstruuj 95% PU dla 1 - 2 y1 –y2 = 75 – 55 = 20
SE1 = ; SE2 = 1.826 df=

13
Oblicz przedział ufności jeszcze raz wykorzystując ``uśredniony’’ SE.

14
Przykład % PU dla 1 - 2 Rośliny hodowane w różnych warunkach oświetleniowych. Ciemno Jasno n 22 21 y 1.76 2.46 SE 0.5 0.7

15
“1” – populacja/próba hodowana przy słabym oświetleniu
“2” – populacja/próba hodowana przy mocnym oświetleniu Oblicz 95% PU dla 1 - 2.

16
Przedziały ufności: Interpretacja
Nasz PU zawiera wartości zarówno dodatnie jak i ujemne? Jak to zinterpretować ?

17
Testowanie hipotez Idea
Chcemy odpowiedzieć na pytanie naukowe dotyczące pewnej (lub pewnych) populacji Decyzję podejmujemy w oparciu o próbę - dysponujemy informacją fragmentaryczną W rezultacie możemy popełnić błąd przy podejmowaniu decyzji Chcemy zminimalizować p-stwo błędu
 populacji. Decyzję podejmujemy w oparciu o próbę - dysponujemy informacją fragmentaryczną. W rezultacie możemy popełnić błąd przy podejmowaniu decyzji. Chcemy zminimalizować p-stwo błędu.")
18
Typowe pytania: Pytania o wartości parametrów Dla populacji o rozkładzie Bernoulliego. Czy p-stwo sukcesu wynosi ½? („Czy moneta jest symetryczna/uczciwa?”) Czy p-stwo sukcesu wynosi p0 ? (p0 – pewna konkretna, interesująca nas wartość)
 Czy p-stwo sukcesu wynosi p0 (p0 – pewna konkretna, interesująca nas wartość)")
19
Dla rozkładu normalnego:
Czy średnia w populacji wynosi 0? Czy średnia w populacji wynosi 93? Czy średnia w populacji wynosi 0 ? (0 – konkretna, interesująca nas wartość). Dla dwóch populacji normalnych Czy średnie wartości cechy w obu populacjach są sobie równe ? Czy różnica między średnimi w obu populacjach wynosi 0? Czy różnica między średnimi w obu populacjach wynosi 0 ?
. Dla dwóch populacji normalnych. Czy średnie wartości cechy w obu populacjach są sobie równe Czy różnica między średnimi w obu populacjach wynosi 0 Czy różnica między średnimi w obu populacjach wynosi 0")
20
Na te pytania są dwie możliwe odpowiedzi – tak albo nie (prawda albo fałsz).
Pytania dotyczą całej populacji, do której na ogół nie mamy dostępu. Nasza decyzja, którą podejmujemy w oparciu o próbę, jest zagrożona błędem. Sposób formułowania odpowiedzi Zamiast: „Prawda” mówimy: „W oparciu o tę próbę nie możemy wykluczyć postawionej hipotezy”. Przykład: „Przeprowadzone badania nie potwierdzają, że badane populacje mają różny średni poziom badanej cechy.” (Ale nie można wykluczyć, że jest różnica).
.")
21
Zamiast: „Nieprawda” należałoby mówić: „Jest to mało prawdopodobne” albo: „Gdyby postawiona hipoteza była prawdziwa, to uzyskany wynik (z próby) byłby bardzo mało prawdopodobny. Dlatego odrzucamy tę hipotezę.” (Ale możemy się mylić). Przykład:”Przeprowadzone badanie potwierdza tezę, że badane populacje różnią się średnią wartością badanej cechy.” (Odrzucamy hipotezę o równości średnich). Wprowadzimy później ilościowy sposób motywowania takich decyzji (p-wartość).
. Wprowadzimy później ilościowy sposób motywowania takich decyzji (p-wartość).")
22
Analogia: czujnik dymu
Instalujemy czujniki dymu, aby ostrzegły nas przed pożarem. Nie są to idealne wykrywacze pożarów. Reagują na cząstki dymu w powietrzu. Mogą być w dwu możliwych stanach – CICHO i GŁOŚNO Nasz dom może być w dwu możliwych stanach – nie ma pożaru albo jest pożar

23
Możemy podjąć dwie decyzje: zostać albo uciekać
System ostrzegania może popełnić dwa błędy Jest GŁOŚNO choć nie ma pożaru (na przykład przypaliliśmy grzankę) Jest CICHO choć jest pożar (zła lokalizacja, zużyta bateria,…) Decyzję uzależniamy od stanu wykrywaczy dymu (CICHO – zostajemy, GŁOŚNO – uciekamy).
 Jest CICHO choć jest pożar (zła lokalizacja, zużyta bateria,…) Decyzję uzależniamy od stanu wykrywaczy dymu (CICHO – zostajemy, GŁOŚNO – uciekamy).")
24
Na ogół nie ma pożaru i wykrywacz jest CICHO, więc nie reagujemy (dobra decyzja).
Czasami nie ma pożaru a wykrywacz jest GŁOŚNO, więc uciekamy (błędna decyzja – strata czasu) – błąd I-go rodzaju. Czasami jest pożar a wykrywacz jest CICHO więc zostajemy (zła decyzja – niebezpieczeństwo) – błąd II-go rodzaju. Czasami jest pożar i wykrywacz jest GŁOŚNO więc uciekamy (dobra decyzja).
 – błąd I-go rodzaju. Czasami jest pożar a wykrywacz jest CICHO więc zostajemy (zła decyzja – niebezpieczeństwo) – błąd II-go rodzaju. Czasami jest pożar i wykrywacz jest GŁOŚNO więc uciekamy (dobra decyzja).")
25
Notacja: Hipotezy Stan wyjściowy, ``nie ma pożaru’’, nazywamy hipotezą zerową Drugi możliwy stan, ``pożar’’, nazywamy hipotezą alternatywną H0 to skrót dla hipotezy zerowej HA to skrót dla hipotezy alternatywnej

26
Decyzje Nasze decyzje wyrażamy w odniesieniu do hipotezy zerowej H0:
Decyzja „uciekamy” odpowiada odrzuceniu H0, tzn. odrzucamy stanowisko, że nie ma pożaru. Decyzja „zostajemy” odpowiada nieodrzuceniu H0. Decyzję podejmujemy w oparciu o zachowanie czujnika dymu, którego rolę w dalszym ciągu przejmie statystyka testowa, czyli pewna wielkość obliczona z próby.

27
Gdy wykrywacz jest GŁOŚNO to mówimy, że wynik testu jest ``istotny’’
Gdy wykrywacz jest GŁOŚNO to mówimy, że wynik testu jest ``istotny’’. Definicja: Istotny wynik powoduje odrzucenie H0. Gdy wykrywacz jest CICHO to wynik testu jest ``nieistotny’’ i nie odrzucamy H0.

28
Podsumowanie analogii
Hipotezy: H0 = nie ma pożaru, HA = pożar Statystyka testowa: nieistotna=CICHO, istotna=GŁOŚNO Decyzja: nie odrzucamy H0 = zostajemy, odrzucamy H0 = uciekamy Błąd I rodzaju: odrzucamy H0, choć jest prawdziwa=uciekamy, choć nie ma pożaru Błąd II rodzaju: nie odrzucamy H0, choć prawdziwa jest HA = zostajemy, choć jest pożar

29
Zauważmy, że H0 jest bardziej precyzyjna niż HA: np
Zauważmy, że H0 jest bardziej precyzyjna niż HA: np. gdy HA jest prawdziwa, to pożar może być dowolnej wielkości Wykrywacze dymu mają pewną ustaloną czułość – reagują na określoną ilość dymu w powietrzu. Jeżeli wykrywacz jest zbyt czuły, to będzie często powodował fałszywe alarmy (błędy I rodzaju). Jeżeli nie jest dość czuły, to nie będzie się włączał, kiedy potrzeba – błędy II rodzaju.
. Jeżeli nie jest dość czuły, to nie będzie się włączał, kiedy potrzeba – błędy II rodzaju.")
30
Zwiększając czułość zmniejszamy p-stwo błędu II rodzaju, ale zwiększamy p-stwo błędu I rodzaju.
Dobór czułości testu powinien zależeć od konsekwencji błędów! Jak opisać czułość testu? „Poziom istotności” (α) to p-stwo błędu I rodzaju. Poziom istotności powinno się ustalić jeszcze przed przeprowadzeniem eksperymentu. β – p-stwo błędu II rodzaju (zależy np. od wielkości pożaru)
 to p-stwo błędu I rodzaju. Poziom istotności powinno się ustalić jeszcze przed przeprowadzeniem eksperymentu. β – p-stwo błędu II rodzaju (zależy np. od wielkości pożaru)")
31
Hipoteza zerowa H0 = 0 = 0 (-0 = 0) 1 = 2 (1–2 = 0)
Zwykle prosta i specyficzna Będziemy ją odrzucali albo nie Przykłady: = 0 = 0 (-0 = 0) 1 = 2 (1–2 = 0) 1 - 2 = 0 p = p0 Uwaga: Aby kontrolować błąd I rodzaju należy znać rozkład statystyki testowej przy H0.
 1 = 2 (1–2 = 0) 1 - 2 = 0. p = p0. Uwaga: Aby kontrolować błąd I rodzaju należy znać rozkład statystyki testowej przy H0.")
32
Hipoteza alternatywna HA
W jakimś sensie przeciwna do H0 Na ogół bardziej ogólna niż H0 (np.. nieznany rozmiar pożaru) „odrzucenie H0" oznacza, że wierzymy w HA „nie odrzucenie H0" oznacza, że nie mamy dość silnych dowodów przemawiających za HA. Nie jest to to samo co udowodnienie prawdziwości H0 (tego na ogół nie potrafimy zrobić przy pomocy statystyki).
 „odrzucenie H0 oznacza, że wierzymy w HA. „nie odrzucenie H0 oznacza, że nie mamy dość silnych dowodów przemawiających za HA. Nie jest to to samo co udowodnienie prawdziwości H0 (tego na ogół nie potrafimy zrobić przy pomocy statystyki).")
33
Przykłady HA: 0 > 0 < 0 1 2 (1 - 2 0) 1 > 2 (1 - 2 > 0) 1 < 2 (1 - 2 < 0) Rozkład statystyki testowej przy HA powinien być inny niż przy H0 (wykrywacz powinien być GŁOŚNO, a nie CICHO, gdy mamy pożar).
.")
34
Przykład ilustracyjny
Załóżmy, że mamy próbę z populacji o rozkładzie normalnym. Niech (nieznane) oznacza jego średnią. Chcemy przetestować H0: = 5 przeciw alternatywie HA: 5
 oznacza jego średnią. Chcemy przetestować. H0: = 5. przeciw alternatywie. HA: 5.")
35
Możemy skonstruować przedział ufności dla w oparciu o dane
Możemy skonstruować przedział ufności dla w oparciu o dane. Taki przedział ufności powinien zawierać . Zatem jeżeli przedział ufności nie zawiera 5, to odrzucimy H0 na korzyść HA. Jeżeli przedział ufności zawiera 5, to oznacza, że nie możemy odrzucić H0. Ponieważ jednak PU zawiera także wiele innych wartości niż 5, zatem nie mamy wystarczających podstaw, aby twierdzić, że H0 jest prawdziwa.

36
PU na poziomie (1-) jest dany wzorem
y t/2 SE. Sprawdzimy, czy zawiera on 5.

37
Równoważnie wystarczy wyznaczyć statystykę testową (y – 5)/SE i sprawdzić, czy zawiera się ona w przedziale –t/2 and +t/2 Jeżeli tak, to statystyka jest nieistotna i nie odrzucamy H0. Jeżeli nie to statystyka jest istotna i odrzucamy H0. Zbiór (-∞ , –t/2) U (+t/2 , ∞) nazywamy obszarem krytycznym (obszarem odrzuceń). Jeżeli statystyka testowa znajdzie się w obszarze krytycznym, to odrzucamy H0. Zauważmy, że postać statystyki testowej zależy od H0 (stąd pochodzi 5).
 U (+t/2 , ∞) nazywamy obszarem krytycznym (obszarem odrzuceń). Jeżeli statystyka testowa znajdzie się w obszarze krytycznym, to odrzucamy H0. Zauważmy, że postać statystyki testowej zależy od H0 (stąd pochodzi 5).")
38
Rozkład statystyki testowej przy H0
ma rozkład Zwykle nie znamy σ i zastępujemy je przez s (y-)/SE ma rozkład Studenta z n-1 stopniami swobody (przy H0) Tak więc, jeżeli H0 jest prawdziwa to = 5 i (y-5)/SE ma rozkład
/SE ma rozkład Studenta z n-1 stopniami swobody (przy H0) Tak więc, jeżeli H0 jest prawdziwa to = 5. i (y-5)/SE ma rozkład")
39
Zwykle statystykę testową wybieramy tak, abyśmy umieli podać jej rozkład przy H0.
Co się stanie, jeżeli prawdziwa jest HA?: Wtedy ≠ 5 i rozkład statystyki (y-5) będzie skoncentrowany w okolicach (-5) zamiast w okolicach 0.
 będzie skoncentrowany w okolicach (-5) zamiast w okolicach 0.")
40
Poziom istotności Poziom istotności - = P-stwo błędu I-go rodzaju (odrzucenie H0 gdy jest prawdziwa; fałszywy dodatni wynik testu). Załóżmy, że H0 jest prawdziwa. Jakie jest p-stwo, że statystyka testowa znajdzie się w zbiorze krytycznym (-∞ , –t/2) U (+t/2 ,∞)?
 U (+t/2 ,∞)")
41
α wybieramy przed przystąpieniem do testowania. Typowe wartości α to 0
α wybieramy przed przystąpieniem do testowania. Typowe wartości α to 0.05, 0.01 lub 0.1. Możemy jednak stosować inne wartości. Wybór α powinien zależeć od konsekwencji błędów I-go i II-go rodzaju. Wartość krytyczna – wartość leżąca na granicy obszaru krytycznego.

42
W naszym przykładzie rozbiliśmy zbiór krytyczny na dwie symetryczne części
(-∞ , –t/2) i (+t/2 ,∞). Postępujemy tak ponieważ HA: ≠ 5 , jest symetryczna (niekierunkowa). Jesteśmy zainteresowani zarówno alternatywami dla których < 5 jak i > 5. Czasami rozważamy alternatywy kierunkowe, takie jak HA: > 5. W tym przypadku obszar krytyczny ma postać: (+t ,∞). Czasami rozważamy alternatywy kierunkowe, takie jak HA: < 5. W tym przypadku obszar krytyczny ma postać: (-∞ , –t).
 i (+t/2 ,∞). Postępujemy tak ponieważ HA: ≠ 5 , jest symetryczna (niekierunkowa). Jesteśmy zainteresowani zarówno alternatywami dla których < 5 jak i > 5. Czasami rozważamy alternatywy kierunkowe, takie jak HA: > 5. W tym przypadku obszar krytyczny ma postać: (+t ,∞). Czasami rozważamy alternatywy kierunkowe, takie jak HA: < 5. W tym przypadku obszar krytyczny ma postać: (-∞ , –t).")
43
Testy Studenta Jest kilka typów testów Studenta. Mają podobną strukturę, ale służą do testowania różnych hipotez i różnią się nieco postacią statystyki testowej. Trzy podstawowe typy testów Studenta to : Test dla jednej próby, dla dwóch niezależnych prób i dla dwóch prób zależnych. Każdy z tych testów może być kierunkowy (alternatywa jednostronna) lub niekierunkowy (alternatywa dwustronna).
 lub niekierunkowy (alternatywa dwustronna).")
44
Test studenta dla pojedynczej próby, niekierunkowy
Przykład 1 (fikcyjny): Czy średnia prędkość aut na ulicy Mickiewicza jest różna od 50 km/h? Zmierzono prędkość 32 aut: Prędkość aut w km/h n średnia s 32 66 5.5
: Czy średnia prędkość aut na ulicy Mickiewicza jest różna od 50 km/h Zmierzono prędkość 32 aut: Prędkość aut w km/h. n. średnia. s")
46
Test Studenta dla jednej próby, kierunkowy
Bardziej interesujące pytanie: Czy średnia prędkość aut jest większa od 50 km/h?

47
Uwaga! Decyzja o rodzaju hipotezy alternatywnej (kierunkowa lub nie) powinna być podjęta zanim spojrzymy na dane liczbowe zebrane dla jej weryfikacji. Może być natomiast podjęta na podstawie innych, np. historycznych danych lub na podstawie profilu zainteresowań, ogólnych oczekiwań itp.
 powinna być podjęta zanim spojrzymy na dane liczbowe zebrane dla jej weryfikacji. Może być natomiast podjęta na podstawie innych, np. historycznych danych lub na podstawie profilu zainteresowań, ogólnych oczekiwań itp.")
48
Test studenta dla pojedynczej próby, też kierunkowy
Czy średnia prędkość aut na ulicy Mickiewicza jest mniejsza niż 50 km/h?

49
Test Studenta dla dwóch niezależnych prób, niekierunkowy
Badacze chcą stwierdzić, czy obecność pewnego enzymu (G6PD) jest związana z rozwojem artretyzmu (RA). Aby to zbadać, wybrano losowo 14 pacjentów chorych na artretyzm i utworzono grupę kontrolną z 17 zdrowych dorosłych. U każdej z badanych osób zmierzono poziom G6PD we krwi. Wyniki podano w jednostkach/gram Hgb (Hgb=hemoglobina).
 jest związana z rozwojem artretyzmu (RA). Aby to zbadać, wybrano losowo 14 pacjentów chorych na artretyzm i utworzono grupę kontrolną z 17 zdrowych dorosłych. U każdej z badanych osób zmierzono poziom G6PD we krwi. Wyniki podano w jednostkach/gram Hgb (Hgb=hemoglobina).")
50
1 – średni poziom G6PD u osób chorych na artretyzm
RA Grupa kontrolna średnia 17.8 12.3 SD 3.2 2.84 Zakładając, że poziom G6PD w badanych populacjach ma w przybliżeniu rozkład normalny porównaj średnie poziomy G6PD u osób chorych na artretyzm i u osób zdrowych używając odpowiedniego testu Studenta i liczby stopni swobody df = n1 + n2 – 2. Rozwiązanie Pytanie naukowe: Czy średni poziom enzymu G6PD u osób chorych na artretyzm jest taki sam jak u zdrowych osób? Oznaczenia: 1 – średni poziom G6PD u osób chorych na artretyzm 2 – średni poziom G6PD u zdrowych osób

52
Test Studenta dla dwóch niezależnych prób, kierunkowy
Lekarstwo uśmierzające ból zostało przetestowane na grupie 50 kobiet cierpiących na bóle poporodowe. 25 losowo wybranych kobiet dostało lekarstwo, a pozostałych 25 placebo. Dla każdej kobiety wyliczono wskaźnik uśmierzenia bólu w oparciu o wynik cogodzinnego wywiadu. Zakres zmienności tego wskaźnika był pomiędzy 0 (ból bez zmian) do 56 (całkowite uśmierzenie bólu na 8 godzin). Wyniki badań zawarte są w poniższej tabeli. Zakładając, że wskaźnik uśmierzenia bólu ma w obu populacjach rozkład normalny zweryfikuj hipotezę o przydatności badanego lekarstwa.
 do 56 (całkowite uśmierzenie bólu na 8 godzin). Wyniki badań zawarte są w poniższej tabeli. Zakładając, że wskaźnik uśmierzenia bólu ma w obu populacjach rozkład normalny zweryfikuj hipotezę o przydatności badanego lekarstwa.")
53
Pytanie: Czy lekarstwo redukuje ból bardziej efektywnie niż placebo ?
Wskaźnik uśmierzenia bólu n średnia SD placebo 25 25.32 12.05 lekarstwo 31.96 13.78 Pytanie: Czy lekarstwo redukuje ból bardziej efektywnie niż placebo ?

55
P-wartość: wprowadzenie
Przed przystąpieniem do testowania należy wybrać poziom istotności . Odrzucamy H0 gdy statystyka testowa jest istotna, tzn. znajdzie się w obszarze odrzuceń. Ten obszar to zbiór wartości w „ogonie/ogonach’’ rozkładu Studenta taki, że całka z gęstości rozkładu Studenta po tym zbiorze wynosi . Nieco paradoksalnie, może się zdarzyć, że hipoteza odrzucona na poziomie istotności =0.05 nie będzie odrzucona, jeżeli użyjemy = 0.01.

56
Przykład: Stosujemy dwustronny test Studenta z 18 df na poziomie istotności = Wart. kryt. = Statystyka testowa wyliczona w oparciu o dane wynosi ts = 2.3. Wniosek: Patrycja woli użyć = Wart. kryt,.= Patrycja użyła tych samych danych, więc ts =..... Jak uzgodnić wynik testowania z kimś, kto użył innej wartości ?

57
P-wartość: cd. Czego potrzeba, aby podjąć decyzję?
Tablicy rozkładu Studenta, aby ustalić wartość krytyczną (niezależne od danych). Wartości statystyki testowej ts (zależne od danych). Czy Patrycja mogłaby uniknąć wyszukiwania nowej wartości krytycznej? Tak. Wystarczy podać jej tzw. P-wartość dla naszej statystyki/danych. Znajomość P-wartości umożliwia podjęcie decyzji przy każdym poziomie istotności α bez wyszukiwania wartości krytycznych.
. Wartości statystyki testowej ts (zależne od danych). Czy Patrycja mogłaby uniknąć wyszukiwania nowej wartości krytycznej Tak. Wystarczy podać jej tzw. P-wartość dla naszej statystyki/danych. Znajomość P-wartości umożliwia podjęcie decyzji przy każdym poziomie istotności α bez wyszukiwania wartości krytycznych.")
58
P-wartość: definicja. P-wartość to prawdopodobieństwo, że przy prawdziwej hipotezie zerowej wartość statystyki przyjmie wartość bardziej ekstremalną, niż zaobserwowana w badanej próbie. Dla dwustronnego testu Studenta P-wartość to całka z gęstości rozkładu Studenta na prawo od +| ts| i na lewo od -| ts|. Dla testów jednostronnych P-wartość to całka po jednej stronie zaobserwowanej statystyki w kierunku wyspecyfikowanym przez alternatywę: Przy HA : 1 > 2, P-wartość to całka na prawo od ts. Przy HA : 1 < 2, P-wartość to całka na lewo od ts.

59
Przykład, cd. Przy 18 df i ts = 2.3, P-wartość dla testu dwustronnego wynosi Jest to całka z gęstości rozkładu Studenta na prawo od +2.3 i na lewo od -2.3. Jak używamy P-wartości: Porównujemy ją z : Gdy P-wartość < , to Gdy P-wartość > , to

60
Tak więc mówimy Patrycji, że P-wartość wynosi 0
Tak więc mówimy Patrycji, że P-wartość wynosi i ona wie od razu, że na poziomie istotności = A my wiemy, że na poziomie istotności α = P-wartość warto podać razem z wynikiem testu. Na przykład: „To badanie na poziomie istotności 0.05 potwierdza (P-wartość=0.034), że
, że")
61
Szacowanie P-wartości
P-wartość można obliczyć przy pomocy komputera, korzystając z dystrybuanty rozkładu Studenta. P-wartość można także oszacować (w przybliżeniu) korzystając z tablic rozkładu Studenta. W tym wypadku należy znaleźć wartości krytyczne sąsiadujące z zaobserwowaną wartością statystyki. Szukana P-wartość leży pomiędzy poziomami istotności odpowiadającymi tym wartościom krytycznym.
 korzystając z tablic rozkładu Studenta. W tym wypadku należy znaleźć wartości krytyczne sąsiadujące z zaobserwowaną wartością statystyki. Szukana P-wartość leży pomiędzy poziomami istotności odpowiadającymi tym wartościom krytycznym.")
63
Kontynuacja przykładu
Oszacuj p-wartość dla dwustronnego testu Studenta, jeżeli wartość statystyki testowej wynosi 2.3 a liczba stopni swobody df=18.

64
Hipoteza alternatywna
Testy Studenta Hipoteza Zerowa Hipoteza alternatywna df ts (1-) PU dwustronne jednostronne H0 HA Obszar Kryt. Jedna Próba = 0 0 ts <- t/2 ts > t/2 < 0 ts <- t n-1 dla : y t/2SEy > 0 ts > t Dwie Niezależne Próby 1 = 2 1 2 1 < 2 ts < -t n1+n2-2 albo podany wzór dla 1-2: y1 –y2 t/2SEy1-y2 1 > 2 Zależne ts < –t/2 ts <-t nd – 1 y1 –y2 t/2SEd
 PU. dwustronne. jednostronne. H0. HA. Obszar. Kryt. Jedna. Próba. = 0. 0. ts <- t/2. ts > t/2. < 0. ts <- t n-1. dla : y t/2SEy. > 0. ts > t Dwie. Niezależne. Próby. 1 = 2. 1 2. 1 < 2. ts < -t n1+n2-2. albo. podany. wzór. dla 1-2: y1 –y2 t/2SEy1-y2. 1 > 2. Zależne. ts < –t/2. ts <-t nd – 1. y1 –y2 t/2SEd.")








>")

>")



 stanowi rozszerzenie testu t-Studenta w przypadku porównywanie większej liczby grup. Podział na grupy (czyli.>")








>")