Pobierz prezentację
1
Ontologie Monika Nawrot Agnieszka Janowska Akademia Górniczo-Hutnicza Kraków 2006

2
Ontologia Ontologia - podstawowy dział filozofii, który stara się odpowiadać na pytania o strukturę rzeczywistości i problematykę związaną z pojęciami bytu, istoty, istnienia i jego sposobów, przedmiotu i jego własności, przyczynowości, czasu, przestrzeni, konieczności i możliwości.

3
Ontologia Ontologia – w informatyce oznacza określony sposób formalizacji wiedzy, którego celem jest zapewnienie jednoznaczności przekazu wiedzy na temat określonej rzeczywistości. W tym celu wykorzystuje się kategoryzację oraz hierarchizację.

4
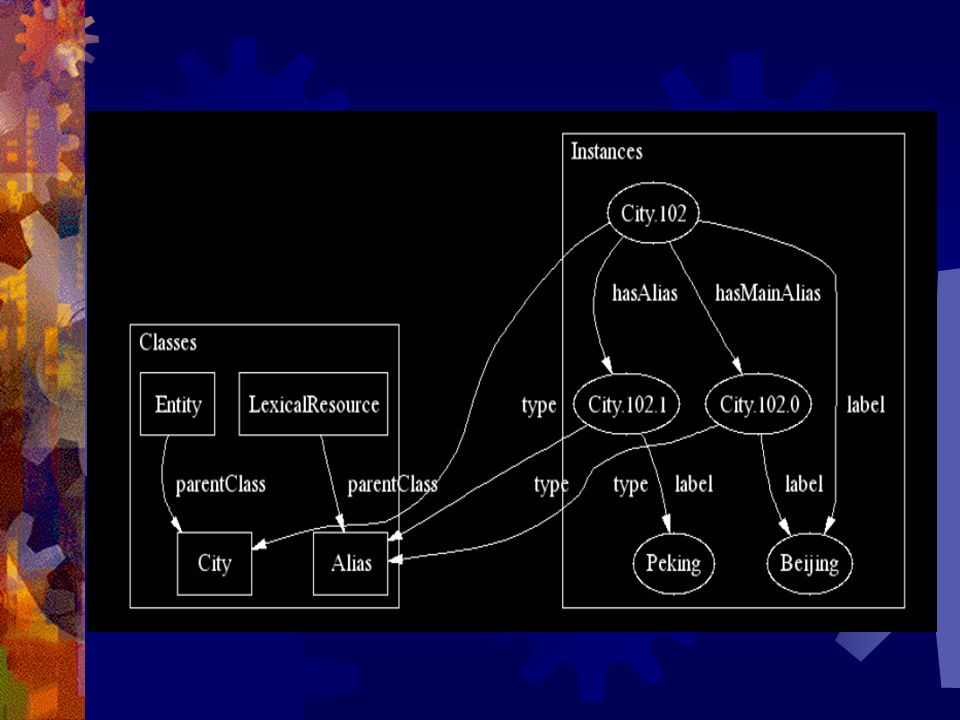
Ontologia Kategoryzacja – zdolność przyporządkowania symbolu występującego w komunikacie do określonej grupy obiektów, które to obiekty posiadają określone cechy, np. „kot” – klasa kotów, pojęcie kot (ang. concept). Zestaw tych grup można określić jako zewnętrzny model pojmowania świata.
. Zestaw tych grup można określić jako zewnętrzny model pojmowania świata..")
5
Ontologia Hierarchizacja – umiejscowienie określonej klasy w hierarchicznej strukturze. Instancja klasy poza oczywistymi charakterystykami wynikającymi z przynależności do klasy posiada także cechy dziedziczone z klas nadrzędnych.

6
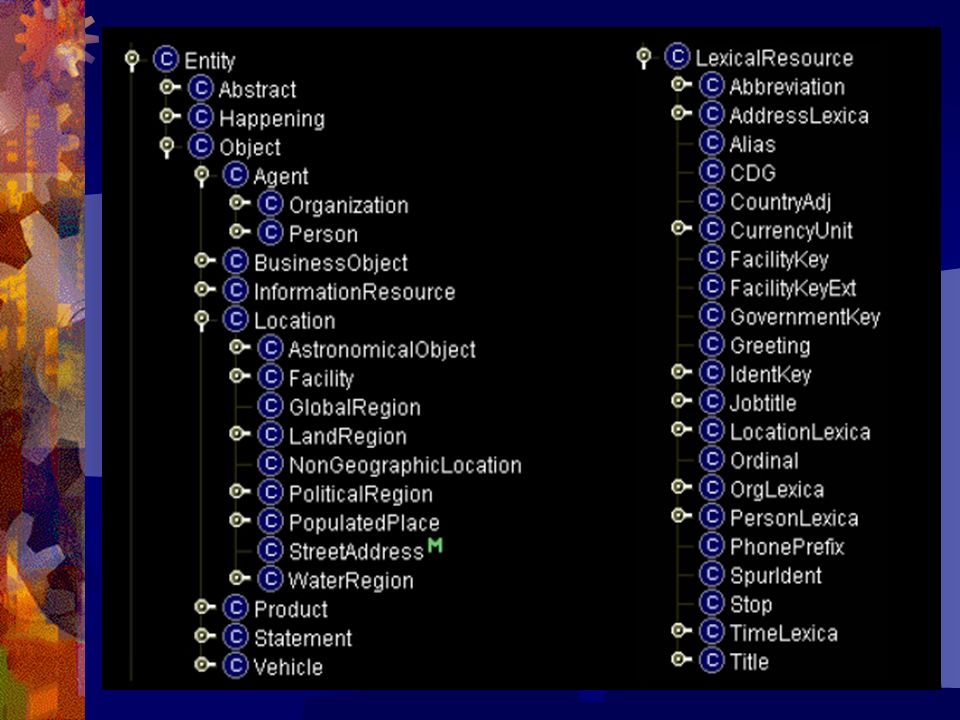
Ontologie Języki: - RDF (Resource Description Framework) - OWL (Web Ontology Language) OWL Lite OWL DL (rozszerzenie OWL Lite) OWL Full (rozszerzenie OWL DL) - DAML (DARPA Agent Markup Language)
 - OWL (Web Ontology Language) OWL Lite OWL DL (rozszerzenie OWL Lite) OWL Full (rozszerzenie OWL DL) - DAML (DARPA Agent Markup Language)")
7
Ontologie w tekstach Automatyczna budowa ontologii na podstawie tekstu – Ontology Learning Information Extraction – wspomaganie wydobywania wiedzy z tekstu Information Retrieval – wspomaganie wyszukiwania i grupowania dokumentów Automatyczne generowanie odpowiedzi na zapytania

8
Ontology Learning Półautomatyczna generacja, eksploracja i ekstrakcja ontologii z różnych zasobów (ustrukturalizowanych i nieustrukturalizowanych) Przetwarzanie języka naturalnego (Natural Language Processing) Eksploracja danych (Data Mining) Mnogość algorytmów
 Przetwarzanie języka naturalnego (Natural Language Processing) Eksploracja danych (Data Mining) Mnogość algorytmów")
9
Ontologie a Inormation Extraction Wykorzystanie ontologii przy ekstrakcji wiedzy: są niezbędne jako element procesu „zrozumienia” przy uzyskiwaniu informacji z tekstu Wykorzystanie metod ekstrakcji wiedzy przy projektowaniu ontologii: pomogają w „zasiedlaniu” ontologii (wypełnianiu ontologii instancjami pojęć – ontology population) oraz wzbogacaniu ontologii o nowe pojęcia
 oraz wzbogacaniu ontologii o nowe pojęcia")
10
Ontotext Laboratorium technologii semantycznych firmy Sirma prowadzące prace badawcze nad: - Ontologiami - Reprezentacją wiedzy (Information Retrieval) - Ekstrakcją wiedzy (Information Extraction) - Sieciami semantycznymi
 - Ekstrakcją wiedzy (Information Extraction) - Sieciami semantycznymi")
11
Ontotext Współuczestniczy w projektach badawczych: On-To-Knowledge SWWS Vision OntoWeb DIP SEKT Prestospace Infrawebs

12
SEKT (Semantic Knowledge Technologies)
")
13
SEKT Cele SEKT: -zniesienie granic pomiędzy zarządzaniem dokumentem i jego zawartością -pożądana wiedza powinna być automatycznie dostarczana właściwym ludziom we właściwym czasie

14
SEKT SEKT łączy: -Metadane bazujące na ontologii (Ontology-based Metadata) -Technologię Języka Naturalnego (Human Language Technology) -Odkrywanie Wiedzy (Knowledge Discovery)
 -Technologię Języka Naturalnego (Human Language Technology) -Odkrywanie Wiedzy (Knowledge Discovery)")
15
SEKT SEKT i Ontotext: -zarządzanie ontologią -generacja ontologii -generacja metadanych -architektura systemu -interfejs systemu

16
SEKT

17
To jest Sam, 33-letni makler z Londynu. Sam ma 200 klientów...

18
KIM (Knowledge and Information Management)
")
19
KIM Semantyczne adnotacje jednostek nazwanych w nieustrukturyzowanych i na wpół ustrukturyzowanych tekstach Automatyczne linkowanie do wpisów w bazie wiedzy Indeksowanie i wydobywanie dokumentów Obsługa zapytań i eksploracja zebranej wiedzy Analiza popularności i ranking jednostek

20
KIM

21
Wykorzystane technologie: Sesame RDF(S) repozytorium – przechowywanie i obsługa zapytań GATE – Information Extraction, niektóre elementy Lucene IR – indeksowanie i Information Retrieval PROTON – wysoko-poziomowa ontologia stworzona na potrzeby projektu (250 klas, 100 właściwości) KIM Knowledge Base – przechowywanie wpisów jednostek nazwanych (Named Entities) – wypełniona wstępnie ok. 200 tys. jednostek

22
KIM IE

23
Adnotacje semantyczne w tekście GATE (tokenizer, tagger części mowy, mechanizm podziału zdania) Wbudowane leksykony Gramatyki szablonów oparte na ontologiach, nie na konkretnych zbiorach nazwanych jednostek (instancjach) Automatyczne uzupełnianie bazy wiedzy o nowo rozpoznane jednostki i relacje między nimi
 Wbudowane leksykony Gramatyki szablonów oparte na ontologiach, nie na konkretnych zbiorach nazwanych jednostek (instancjach) Automatyczne uzupełnianie bazy wiedzy o nowo rozpoznane jednostki i relacje między nimi")
26
KAON Text-To-Onto KAON (Karlsruhe Ontology Management Infrastructure) Text-To-Onto
 Text-To-Onto")
27
KAON Tworzenie, przechowywanie, edytowanie i rozwijanie ontologii Wspomaganie tworzenia aplikacji opartych na ontologiach Text-To-Onto – moduł wspomagający automatyczne tworzenie ontologii – Ontology Learning from Text

28
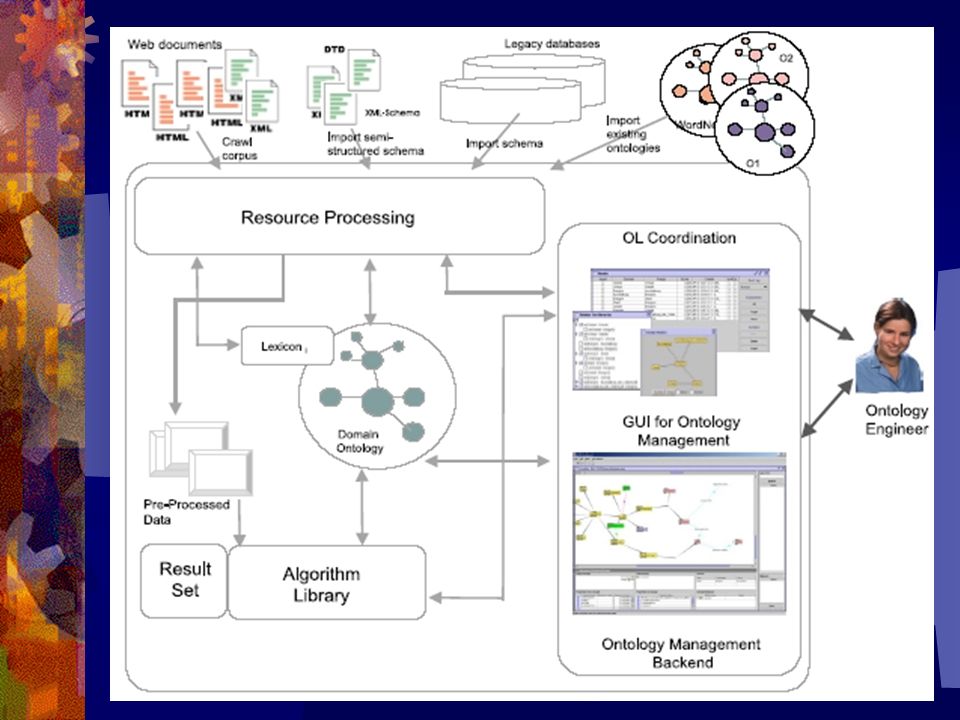
KAON Text-To-Onto Komponenty: Zarządzanie ontologią: manualna obsługa ontologii – zarządzanie istniejącymi ontologiami, przeglądanie, modyfikacja, sprawdzanie poprawności Przetwarzanie zasobów: zestaw narzędzi do wstępnej obróbki dostarczonych tekstów wejściowych Biblioteka algorytmów: zestaw algorytmów do ekstrakcji informacji zgodnie z dostarczonym modelem ontologii Moduł organizacyjny: pozwala na interakcję z innymi komponentami, np. przygotowanie zasobów, wybór algorytmów, itp.

30
Text-To-Onto Przetwarzanie zasobów: Stworzenie zbioru wstępnie przetworzonych danych dostosowanych do algorytmów ekstraktujących dane dla ontologii System przetwarzania języka naturalnego – obejmuje tokenizer, analizę leksykalną, morfologiczną, prunning, stemming, rozpoznawanie jednostek nazwanych, tagger części mowy, wbudowane leksykony wyrażeń (GATE)
")
31
Text-To-Onto Algorytmy ekstrakcji ontologii: Działają na wstępnie przetworzonych danych Różne algorytmy mogą dawać różne wyniki dla tych samych danych wejściowych Działają w oparciu o dostarczony model ontologii

32
Text-To-Onto Lexical Entry and Concept Extraction – metoda statystyczna (TFIDF – Term Frequency – Inverted Document Frequency), opiera się na założeniu, że w tekstach dotyczących danego obszaru wiedzy słowa kluczowe (terminy) pojawiają się często, a więc ekstrakcja instancji klas dla danej ontologii odbywa się na podstawie często powtarzających się terminów, na tej też podstawie tworzy się nowe pojęcia, którymi uzupełnia się ontologię danej domeny (jakkolwiek terminy pojawiające się często w zbyt wielu dokumentach są oceniane jako mniej ważne)
, opiera się na założeniu, że w tekstach dotyczących danego obszaru wiedzy słowa kluczowe (terminy) pojawiają się często, a więc ekstrakcja instancji klas dla danej ontologii odbywa się na podstawie często powtarzających się terminów, na tej też podstawie tworzy się nowe pojęcia, którymi uzupełnia się ontologię danej domeny (jakkolwiek terminy pojawiające się często w zbyt wielu dokumentach są oceniane jako mniej ważne)")
33
Text-To-Onto Extraction of Taxonomic Relations Klasteryzacja – łączenie podobnych terminów w klastry i tworzenie pojęć na ich podstawie, metoda statystyczna, mogą być różne miary podobieństwa terminów Klasyfikacja – mając wstępną hierarchię możemy podporządkowywać nowe terminy pod istniejące już węzły, metoda statystyczna (Support Vector Machines, k Nearest Neighbor) Wzorce leksykalno-syntaktyczne – skanowanie tekstu w poszukiwaniu predefiniowanych wzorców – wyrażeń regularnych, najczęściej pozwala to na ekstrakcję pewnych semantycznych relacji, metoda heurystyczna
 Wzorce leksykalno-syntaktyczne – skanowanie tekstu w poszukiwaniu predefiniowanych wzorców – wyrażeń regularnych, najczęściej pozwala to na ekstrakcję pewnych semantycznych relacji, metoda heurystyczna")
34
Text-To-Onto Ontology Pruning – metoda pozbywania się zbędnych terminów (np. zbyt ogólnych lub niecharakterystycznych) z ontologii danego obszaru wiedzy poprzez porównywanie częstotliwości ich występowania w tekstach specjalistycznych i ogólnych
 z ontologii danego obszaru wiedzy poprzez porównywanie częstotliwości ich występowania w tekstach specjalistycznych i ogólnych.")
35
Dziękujemy za uwagę