Genetyczne systemy uczące się GBML - (genetic-based machine learning systems) Systemy uczące się z użyciem metod genetycznych Regułowe systemy uczące się Systemy LCS (learning classifier systems)
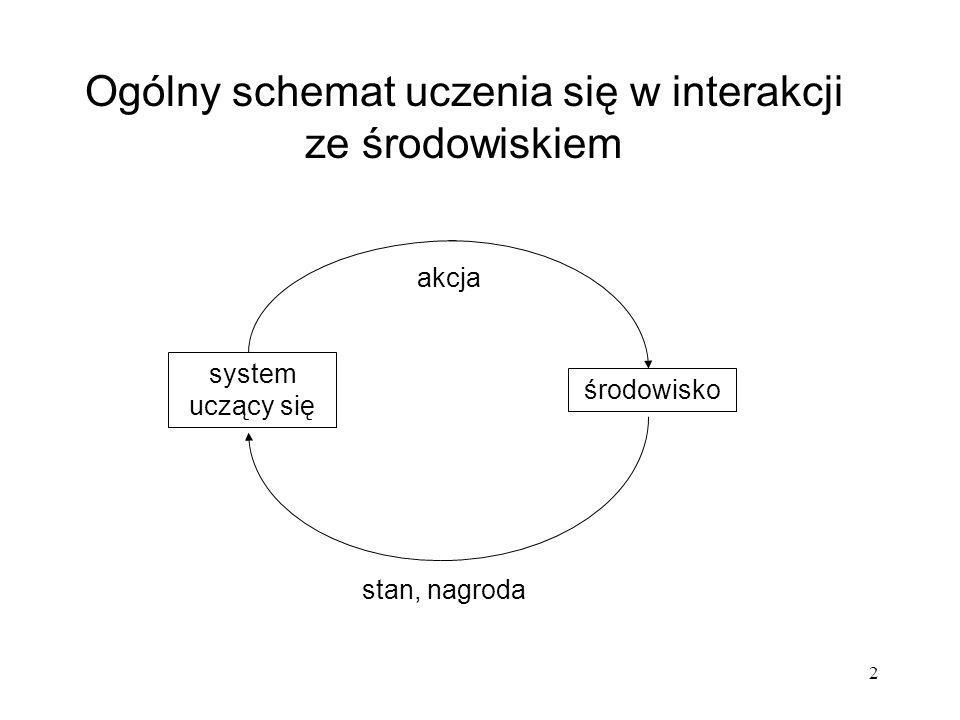
Ogólny schemat uczenia się w interakcji ze środowiskiem akcja system uczący się środowisko stan, nagroda
Środowisko Cechy środowiska w sztucznych systemach uczących się: przydziela nagrody i wyznacza bieżący stan jest niezależne od ucznia, czyli oznacza wszystko to, na co uczeń nie ma wpływu Typy środowisk: stacjonarne / niestacjonarne (zmienne w czasie) deterministyczne / niedeterministyczne - taka sama akcja może spowodować przejście do różnych stanów lub uzyskanie różnych nagród z tym, że wartości oczekiwane nagród i prawdopodobieństwa przejść są stałe o parametrach ciągłych / dyskretnych o pełnej informacji o stanie (własność Markowa) / o niepełnej informacji o stanie
Typy optymalizacji Ze względu na sposób modyfikacji rozwiązań: globalna - potraktowanie każdego rozwiązania jako całości np. jako pojedynczego osobnika w populacji rozproszona (lokalna) - dekompozycja rozwiązania na fragmenty, które poddawane są optymalizacji na podstawie lokalnych i globalnych nagród (wymaga systemu przypisywania zasług) przykłady zastosowań optymalizacji rozproszonej: Uczenie ze wzmocnieniem w wieloetapowych procesach decyzyjnych Regułowe systemy uczące się - LCS
Przykłady zadań optymalizacyjnych Sterowanie odwróconym wahadłem Środowisko: stacjonarne deterministyczne spełniona własność Markowa system sterujący Optymalizacja globalna: do sterowania służy sieć neuronowa zwracająca wartość siły dla podanego stanu, każda sieć (osobnik) oceniana jest na podstawie 1000 kroków sterowania, zbiór sieci traktowany jest jako populacja w algorytmie genetycznym Optymalizacja rozproszona: uczenie ze wzmocnieniem - oceniana jest każda para <stan,akcja> lub każdy stan regułowy system uczący się – oceniane są poszczególne reguły sterowania
Przykłady zadań optymalizacyjnych Gry planszowe Środowisko: spełniona własność Markowa stacjonarne i deterministyczne – przy ustalonym algorytmie gry przeciwnika niestacjonarne i niedeterministyczne – gdy przeciwnikiem jest system uczący się lub człowiek
Przykłady zadań optymalizacyjnych - cd * Sterowanie robotem w środowisku o dużej liczbie możliwych stanów Środowisko: stacjonarne i deterministyczne własność Markowa niespełniona w bardzo dużym stopniu
Przykład - sterowanie robotem - cd * Założenia: robot może się przesuwać o jedno pole w 8 kierunkach, nagrody i pułapki są niewidoczne, można je wykryć tylko na podstawie układu ścian. układy ścian w przypadku nagrody lub pułapki mogą różnić się pomiędzy sobą środowisko w procesie uczenia może być nieco inne niż w procesie testowania (konieczne uogólnianie)
Optymalizacja rozproszona w stosunku do optymalizacji globalnej zalety : mniejsza złożoność pamięciowa w porównaniu z optymalizacją globalną większa efektywność w środowiskach niestacjonarnych i o dużej liczbie stanów (możliwych reguł) wady : problemy z zapewnieniem współpracy poszczególnych podrozwiązań oraz ich oceną (uśrednianie ocen z różnych stanów, przypisanie zasług) duża liczba parametrów algorytmu
Regułowe systemy uczące się - analogia do systemów ekspertowych Wnioskowanie w przód z zastosowaniem reguły odrywania (modus ponens): ((jeśli A to B) oraz zachodzi A) to B Baza wiedzy: 1. A B C 2. B F C D 3. D E G 4. E H 5. H 6. G 7. C 8. F Wnioskowanie: 9. (5)(4) E 10. (9)(6)(3) D 11. (8)(7)(10) B 12. (11)(7)(1) A 1-4 - reguły 5-8 - fakty pierwotne 9-12 - fakty wtórne
Regułowy system uczący się - części składowe Układ przetwarzania komunikatów - szczególny przypadek systemu produkcji System przypisywania zasług (ocen) Algorytm genetyczny
Prosty regułowy system uczący się - układ przetwarzania komunikatów Informacja o stanie środowiska jest przechwytywana przez detektory i zamieniana na tzw. komunikaty zewnętrzne (fakty pierwotne), które zostają umieszczone na liście komunikatów (faktów). Komunikaty są postaci: <komunikat> ::= {0,1}m, gdzie m - ustalona długość komunikatu. Komunikat może uaktywnić jeden lub więcej klasyfikatorów (reguł), o ile pasuje do ich części warunkowej. Klasyfikator (regułę produkcji) można przedstawić jako: <klasyfikator> ::= <warunek>:<komunikat>, gdzie część warunkowa składa się z symboli 3-elementowego alfabetu: <warunek> ::= {0,1,#}m Symbol # może zostać dopasowany do dowolnego symbolu na wejściu Reguły, których część warunkowa pasuje do komunikatu mogą odpalać równolegle, umieszczając komunikaty na liście komunikatów o ile liczba komunikatów nie przekroczy pojemności listy komunikatów k. Możliwych jest też wiele innych rozwiązań.
Prosty regułowy system uczący się - układ przetwarzania komunikatów - przykład Przykładowa baza reguł: 1.) 01##:0000 2.) 00#0:1100 3.) 11##:1000 4.) ##00:0001 Ciąg produkcji gdy na wejściu pojawi się komunikat zewnętrzny (z) 0111 można przedstawić w następującej postaci: (numer komunikatu) komunikat, (numer reguły) komunikat (jego numer) (z) 0111,(1) 0000 (a) (a) 0000,(2) 1100 (b) (a) 0000,(4) 0001 (c) (b) 1100,(3) 1000 (d) (b) 1100,(4) 0001 (e) (d) 1000,(4) 0001 (f)
Globalne a rozproszone regułowe systemy uczące się Systemy globalne (typu Pittsburgh) cały system regułowy jest traktowany jako pojedynczy osobnik w populacji nie wymagają systemu przypisywania zasług Systemy rozproszone (typu Michigan) każda reguła (klasyfikator) jest traktowana jako pojedynczy osobnik 14 14
Prosty regułowy system uczący się LCS - układ przetwarzania komunikatów - schemat
Regułowy system uczący się LCS - system przypisywania zasług Funkcje: ukierunkowanie poszukiwań poprzez wybór klasyfikatorów przynoszących większe zyski lub bardziej dokładnych ocena reguły w algorytmie genetycznym (fitness) Przykładowe algorytmy: drużyny kubełkowej (bucket brigade) Q-learning
Przypisywanie zasług - bucket brigade Algorytm drużyny kubełkowej (bucket brigade) działa na zasadzie rynku usług informatycznych - funkcje: Rozdzielanie nagrody otrzymanej od środowiska pomiędzy reguły biorące udział w procesie wnioskowania - izba rozrachunkowa (clearinghouse) Wybór reguł z listy reguł biorących udział w przetargu (auction) na produkcję komunikatu na podstawie ich oferty B (bid) proporcjonalnej do siły S. Wygranie przetargu przez klasyfikator oznacza konieczność wpłaty wartości oferty B na rzecz klasyfikatorów, które dostarczyły komunikaty pasujące do jego warunku: Bi = CbidSi
Przypisywanie zasług - bucket brigade Siła reguły w kolejnym kroku czasowym: gdzie P - opłata za uaktywnienie, R - nagroda, T - podatek faworyzujący klasyfikatory produktywne: Efektywna wysokość oferty (uwzględniana w tylko w trakcie przetargu) często zawiera szum losowy w celu zapewnienia lepszej eksploracji reguł:
Prosty Regułowy system uczący się - symulacja Cbid=0.1, Ctax=0.0, poj. listy komunikatów = 2, komunikat zewnętrzny z = 0111 komunikaty dopasowanie reguła oferta siła 01##:0000 200 z 20 180 0000 220 00#0:1100 200 200 1 20 180 1100 11##:1000 200 200 200 2 20 ##00:0001 200 200 1 20 180 0001 2 18 t=0 t=1 t=2 komunikaty dopasowanie nagroda od środowiska reguła oferta siła t=3 t=4 t=5 01##:0000 220 220 220 00#0:1100 218 218 218 11##:1000 180 1000 196 196 ##00:0001 162 0001 3 16 146 0001 196 50
bucket brigade - analiza stabilności * Siła reguły w kolejnym kroku czasowym: Siła aktywnej reguły w kolejnym kroku czasowym: Po usunięciu Ri otrzymujemy siłę w n-tym kroku czasowym: wobec tego spełniony powinien być warunek:
bucket brigade - analiza stabilności - cd * Po uwzględnieniu nagród: Uwzględniając warunki stacjonarności dla pewnego ciągu kroków: oraz korzystając ze wzoru na sumę ciągu geometrycznego otrzymujemy wartości stacjonarne siły i oferty:
Regułowy system uczący się - algorytm genetyczny Uruchamianie - co pewną liczbę kroków - interakcji ze środowiskiem Wartość przystosowania reguły (fitness) proporcjonalna do jej siły Reprodukcja z zachowaniem różnorodności populacji (nie szukamy jednego najlepszego rozwiązania, ale najlepszej grupy współpracujących reguł): Model ze ściskiem Metody niszowe
Regułowy system uczący się - przykład Aproksymacja funkcji multipleksera sześciobitowego: Na podstawie dwóch pierwszych bitów obliczany jest adres, zwracany jest bit z o podanym adresie z bloku danych (w tym przypadku jest to bit równy 1 o adresie 3. 1
Regułowy system uczący się - przykład Kompletny zestaw reguł:
Regułowy system uczący się - przykład Hierarchia domniemań: Przyjmując nieco inną funkcję oferty: gdzie f(Sp) jest funkcją specyficzności reguły (liczby pozycji określonych w części warunkowej), można uzyskać prostszy zestaw reguł: ###000:0 ##0#01:0 #0##10:0 0###11:0 ######:1 zakładając, że reguła ostatnia o najmniejszej specyficzności odpala tylko wtedy, gdy nie odpala żadna z 4 pierwszych reguł.
Regułowy system uczący się - rozszerzenia podział na grupy reguł: wejściowe (detektory), wewnętrzne oraz wyjściowe (efektory) rozszerzenie części warunkowej reguł o blok związany np. z dodatkową informacją ukierunkowującą działanie: <warunek> := <stan wewnętrzny> <warunek dopasowania> przekazywanie wartości zmiennych pomiędzy częścią lewą i prawą reguły (klasyfikatora) operacja kreacji - jeśli żadna z reguł nie pasuje do bieżącego komunikatu to tworzony jest reguła z częścią warunkową pasującą do bieżącego komunikatu oraz z wybraną losowo akcją operacja częściowego przecięcia dwóch reguł system XCS (Wilson, 1995) – przystosowanie zależne od dokładności predykcji a nie siły reguły, Q-learning makroklasyfikatory – grupowanie kopii takiego samego klasyfikatora w systemie przetwarzania komunikatów i przypisania zasług
Operacja częściowego przecięcia Kolejność działań: Wybierane są losowo dwie reguły o tej samej akcji Wybierany jest losowo fragment części warunkowej reguł W przypadku niezgodności, na danej pozycji umieszczany jest symbol # Przykład: 100##001110#0#001:6 100##0##1#0#0#001:6 01#1101#100#111#0:6 01#110##1#0#111#0:6 ^ ^ Zastosowanie: Uogólnianie reguł
System ANIMAT (Wilson, 1985) * Środowisko: T - drzewo F - pożywienie przykładowe otoczenie 3x3: TFT...... przypisania: T -> 01, F -> 11, . -> 00 przykładowy komunikat: 011101000000000000 możliwe akcje: {0,...,7}, w zależności od kierunku ruchu przykładowa reguła: 0#11010##000#00#00:2
* System ANIMAT Innowacje: zastosowanie metody ruletki do wyboru reguły spośród reguł zgodnych z komunikatem wejściowym przekazywanie sumy ofert podzbioru reguł zgodnych o tej samej akcji na rzecz reguł aktywnych w poprzednim kroku (podobieństwo do algorytmu Q-learning) operacja kreacji operacja częściowego przecięcia uwzględnienie czasu oczekiwania na wypłatę (oprócz siły) przy wyborze reguły, dzięki czemu faworyzowane są reguły pozwalające na szybsze uzyskanie nagród
* System ANIMAT Średnie wyniki: średni czas poszukiwania pożywienia przy błądzeniu przypadkowym = 41 kroków średni czas dojścia do pożywienia przy pełnej wiedzy = 2.2 kroku
System typu ANIMAT * Sterowanie robotem w środowisku o dużej liczbie możliwych stanów
Regułowy system uczący się (LCS) – typu Animat - wersja 1 * Regułowy system uczący się (LCS) – typu Animat - wersja 1
* Działanie regułowego systemu uczącego się (LCS) - wersja ze stanami wewnętrznymi
Regułowe systemy uczące się – zalety i wady Tworzenie wewnętrznego modelu zachowań Uogólnienie wiedzy - przez zastosowanie symbolu # - ważne w środowiskach niestacjonarnych, z wiedzą niepełną lub w przypadku dużej liczby stanów, zmuszającej do uogólniania zachowań Możliwość wykorzystania wielu typów systemów produkcji np. z wykorzystaniem dodatkowych warunków (monitorowanie środowiska, realizowanie operacji dwuargumentowych), zmiennych, dodatkowych instrukcji itd. Możliwość wyjaśniania zależności w bazie wiedzy Odkrywanie reguł - dzięki zastosowaniu algorytmu genetycznego Przetwarzanie rozproszone - równoległe Wady: Stała długość reguł Problemy związane z podziałem nagród Długi czas uczenia w przypadku obliczeń szeregowych