Pobierz prezentację
1
Badania marketingowe na rynkach produktów sektora wysokich technologii Wybrane metody analizy danych

2
Miary klasyczne są obliczane jako wypadkowe wartości wszystkich wariantów cechy występujących u badanych jednostek zbiorowości, podczas gdy miary pozycyjne wskazują na określoną pozycję jednostek.

3
Średnia arytmetyczna jest to wartość cechy, którą posiadałaby każda jednostka zbiorowości, gdyby podział sumy wartości cech był równomierny tzn. u każdej jednostki zbiorowości występowałaby ta sama wartość cechy.

4
W przypadku szeregu szczegółowego korzysta się z relacji: Dla szeregu rozdzielczego o przedziałach klasowych, w których zmienna reprezentująca badaną cechę statystyczną jest skokowa, a przedziały klasowe jednojednostkowe (punktowe) stosuje się wzór na tzw. średnią ważoną: natomiast w przypadku zmiennych ciągłych występujących w szeregu rozdzielczym o przedziałach klasowych wielojednostkowych, średnią arytmetyczną wyznacza się jako:

5
Załóżmy, że mamy szereg statystyczny, zawierający 10 obserwacji dotyczących wieku studentów IV roku, o następującej postaci: 19, 20, 20, 20, 20, 21, 21, 22, 23, 24. Suma wartości zmiennej stąd średnia arytmetyczna wynosi:

6
Wyznaczmy średnią arytmetyczną wieku studentów na podstawie poniższego szeregu rozdzielczego:

7
W celu wyznaczenia średniej arytmetycznej należy wyznaczyć sumę iloczynów wartości zmiennych x i przez liczbę studentów będących w konkretnym wieku n i. Następnie dzieląc sumę: przez liczbę obserwacji n = 30, otrzymujemy średnią arytmetyczną równą 21 lat.

8
Wyznaczmy średnią arytmetyczną na podstawie danych z szeregu.

9
W tym celu należy więc wyznaczyć środki przedziałów klasowych Dzieląc sumę przez n=494, otrzymujemy

10
Warto zwrócić uwagę na kilka podstawowych własności średniej arytmetycznej. Jest wypadkową wszystkich wartości badanej cechy, związku z czym nie może być niższa od najmniejszej wartości zaobserwowanej w badaniu i nie może być wyższa od wartości największej. Wartość średniej zależy nie od liczebności klas, lecz od ich wzajemnej proporcji. W praktyce oznacza to, że można ją również wyznaczyć z takich szeregów, gdzie zamiast liczebności mamy wskaźniki struktury, a otrzymane wyniki będą jednakowe.

11
Suma odchyleń wartości badanej cechy od średniej arytmetycznej jest równa zeru. Suma kwadratów odchyleń poszczególnych wartości zmiennych badanej cechy od średniej arytmetycznej rozkładu jest najmniejsza. Oznacza to, że suma kwadratów odchyleń poszczególnych wartości zmiennej rozkładu od wartości różnej od średniej będzie zawsze większa.

12
Nie wyznaczamy średniej arytmetycznej kiedy największe liczebności skupiają się wokół najniższych lub najwyższych wartości cechy. Niekiedy średnia arytmetyczna wprowadza po prostu błąd. Dzieje się tak wówczas, gdy wyznaczamy średnią ze zbiorów niejednorodnych oraz gdy występują obserwacje nietypowe, ponieważ średnia arytmetyczna zaciera różnice indywidualne.

13
Natomiast dla zbiorowości z jednostkami nietypowymi można policzyć średnią arytmetyczną odrzucając jednostki nietypowe pod warunkiem, że nie stanowią one co najwyżej 5% liczebności całej zbiorowości. Zbiory niejednorodne mają rozkłady z kilkoma ośrodkami dominującymi.

14
W przypadku, gdy przedziały klasowe (pierwszy i ostatni) są otwarte, a ich liczebności są stosunkowo małe, można dokonać umownego ich zamknięcia i ustalić wartości środków przedziałów. Nie można jednak tak postąpić w przypadku, gdy udział liczebności otwartych przedziałów w ogólnej sumie liczebności jest znaczny, oznacza to jeśli one nie przekraczają 5% liczebności całej zbiorowości.

15
Mediana jest miarą pozycyjną, która rozdziela całą populację na dwie liczebnie równe części w ten sposób, że w jednej z nich znajdują się jednostki o wartościach niższych lub równych od mediany, a w drugiej o wartościach wyższych lub równych od mediany.

16
Wynika z tego, że w celu znalezienia mediany trzeba: najpierw uporządkować zbiorowość według wielkości jej elementów, tzn. od ich wartości najmniejszej do największej (lub odwrotnie). Przedziały skrajne mogą pozostać otwarte, gdyż nie mają one bezpośredniego wpływu na wartość mediany. W tym m.in. przejawia się wyższość tej miary nad średnią arytmetyczną.
. Przedziały skrajne mogą pozostać otwarte, gdyż nie mają one bezpośredniego wpływu na wartość mediany. W tym m.in. przejawia się wyższość tej miary nad średnią arytmetyczną..")
17
W celu wyznaczenia mediany obliczamy numer mediany według wzoru: W przypadku gdy numer mediany jest liczbą niecałkowitą zaokrąglamy go w górę do pierwszej liczby całkowitej. Następnie w szeregu znajdujemy jednostkę o numerze mediany i jej wartość jest medianą.

18
Medianę można wyznaczyć nawet z szeregów, w których przedziały skrajne są otwarte i nie można ich umownie zamknąć w celu obliczenia średniej arytmetycznej. W szeregach o dużej asymetrii, a także w innych przypadkach, kiedy nie można posłużyć się średnią arytmetyczną do liczbowej charakterystyki przeciętnego poziomu zjawiska, należy wykorzystywać medianę.

19
W podobny sposób jak mediana (kwartyl drugi) skonstruowane są dwa pozostałe kwartyle (wartości ćwiartkowe). Kwartyl pierwszy (Q 1 ) jest to wartość jednostki, która dzieli szereg w taki sposób, że 1/4 jednostek ma od niej wartości nie większe, a 3/4 nie mniejsze. Kwartyl trzeci (Q 3 ) to taka wartość, od której 3/4 jednostek zbiorowości ma wartości nie większe od Q 3, a 1/4 nie mniejsze. Numery odpowiadające kwartylom znajdujemy według wzorów:
 jest to wartość jednostki, która dzieli szereg w taki sposób, że 1/4 jednostek ma od niej wartości nie większe, a 3/4 nie mniejsze. Kwartyl trzeci (Q 3 ) to taka wartość, od której 3/4 jednostek zbiorowości ma wartości nie większe od Q 3, a 1/4 nie mniejsze. Numery odpowiadające kwartylom znajdujemy według wzorów:.")
20
Dla uporządkowanego szeregu liczącego 7 elementów postaci: 1, 3, 3, 5, 6, 7, 9 Gdyby odrzucić ostatnią obserwację, to dla 6-cio elementowego szeregu 1, 3, 3, 5, 6, 7

21
W przypadku liczebnie dużej zbiorowości, ujętej w szereg rozdzielczy, przy poszukiwaniu mediany wykorzystuje się szereg skumulowanych liczebności. Mediana znajduje się wówczas w grupie, w której skumulowane liczebności przekraczają lub co najmniej osiągają numer kolejny jednostki środkowej. Wyznaczanie mediany komplikuje się, jeśli wartości cechy są przedstawione w przedziałach klasowych. Za pomocą kumulacji możemy ustalić, w którym przedziale znajduje się środkowa jednostka, natomiast trudno jest ustalić, która z wartości tego przedziału jest medianą.

22
W sposób przybliżony obliczamy medianę opierając się na wzorze interpolacyjnym: gdzie: x 0 - dolna granica przedziału mediany, h 0 - rozpiętość przedziału mediany, n 0 - liczebność przedziału mediany, N Me - numer mediany, n sk-1 - suma liczebności wszystkich przedziałów klasowych poprzedzających przedział mediany.

23
Wyznaczmy medianę dla danych z tabeli:

24
Dominanta, moda Najpopularniejszą wśród miar przeciętnych pozycyjnych jest dominanta, zwana niekiedy wartością dominującą, modalną (modą). Dominantą nazywamy taką wartość zmiennej, której odpowiada największa liczba spostrzeżeń, czyli jest ona najczęściej występującą wartością zmiennej, reprezentującej określony wariant badanej cechy. Dominanta jest wygodną charakterystyką zbiorowości. Można ją stosować zarówno do cech niemierzalnych jak i mierzalnych.

25
Mając zbiór indywidualnych informacji, łatwo można wyznaczyć dominantę przez zliczenie jednostek o danej wartości cechy. Wariant cechy, który ma największą częstotliwość jest dominantą. Jeżeli dysponujemy szeregiem z przedziałami klasowymi, możemy wówczas łatwo dostrzec, który przedział ma dominującą liczebność.

26
W celu wyznaczenia przybliżonej wartości dominanty na podstawie szeregu rozdzielczego o przedziałach klasowych wielojednostkowych korzysta się z następującego wzoru: gdzie: x 0 - dolna granica przedziału dominanty, n 0 - liczebność przedziału dominanty, n -1 - liczebność przedziału poprzedzającego przedział dominanty, n +1 - liczebność przedziału następującego po przedziale dominanty, h 0 - rozpiętość przedziału dominanty.

27
Miary dyspersji dzieli się na dwie podstawowe grupy: – bezwzględne (absolutne) miary zmienności, które są wielkościami mianowanymi (podobnie jak miary średnie) – względne (relatywne) miary zmienności, które są wielkościami niemianowanymi lub mogą być wyrażone w procentach.
 miary zmienności, które są wielkościami mianowanymi (podobnie jak miary średnie) – względne (relatywne) miary zmienności, które są wielkościami niemianowanymi lub mogą być wyrażone w procentach.")
28
Najprostszą miarą rozproszenia jest rozstęp, nazywany inaczej obszarem zmienności, który jest wyznaczany jako różnica między najwyższą i najniższą wartością cechy w badanej zbiorowości statystycznej, czyli:

29
Rozstęp jest używany tylko przy wstępnej analizie danych, ponieważ opierając się na dwóch skrajnych wartościach trudno jest określić rzeczywistą dyspersję występującą w badanej zbiorowości.

30
Popularnym miernikiem dyspersji jest wariancja która nie ma interpretacji ekonomicznej: w przypadku szeregu szczegółowego dla szeregu rozdzielczego punktowego dla szeregu rozdzielczego z przedziałami klasowymi

31
Innym często stosowanym miernikiem dyspersji jest odchylenie standardowe. Wyznacza się je jako pierwiastek kwadratowy z wariancji, będącej średnią arytmetyczną kwadratów odchyleń poszczególnych wartości zbiorowości statystycznej od ich średniej arytmetycznej.

32
Pozycyjną, bezwzględną miarą dyspersji jest odchylenie ćwiartkowe Q będące połową różnicy między kwartylem trzecim a kwartylem pierwszym :.

33
Odchylenie ćwiartkowe, standardowe nie mogą być one używane do porównań dwu zbiorowości. Do tych celów używa się np. współczynniki zmienności.

34
Współczynniki zmienności Definiuje się je jako stosunek wartości miary dyspersji do średniej. Współczynnik zmienności oparty na odchyleniu standardowym postaci: Współczynnik zmienności oblicza się również dla odchylenia ćwiartkowego:.

35
Ich wartość, wyrażona w procentach, należy do przedziału 15 - 35 %. Jeżeli wartość współczynnika zmienności osiąga 60%, mówimy, że zmienność jest ogromna, co dowodzi, iż mamy do czynienia ze zbiorowością względnie niejednorodną z punktu widzenia badanej cechy.

36
Miary asymetrii Wskaźnik asymetrii (zwany również miernikiem skośności) dla szeregu symetrycznego jest równy zero. W szeregach asymetrycznych miernik skośności może być większy lub mniejszy od zera, mówimy wówczas o asymetrii prawostronnej (dodatniej) lub asymetrii lewostronnej (ujemnej).
 lub asymetrii lewostronnej (ujemnej)..")
37
Współczynnik skośności określa zarówno kierunek, jak i siłę asymetrii i wyznacza się go: dla miar klasycznych dla miar pozycyjnych

38
Współczynniki skośności są miarami niemianowanymi i unormowanymi, co umożliwia porównywanie asymetrii różnych rozkładów. Poza przypadkami skrajnej asymetrii wartości współczynników asymetrii W s, A s wahają się w przedziale, w przypadku szeregu symetrycznego przyjmują one wartość zero.

39
Miary asymetrii Wskaźnik asymetrii (zwany również miernikiem skośności) dla szeregu symetrycznego jest równy zero. W szeregach asymetrycznych miernik skośności może być większy lub mniejszy od zera, mówimy wówczas o asymetrii prawostronnej (dodatniej) lub asymetrii lewostronnej (ujemnej).
 lub asymetrii lewostronnej (ujemnej)..")
40
Rys. 1 Przykład szeregu symetrycznego

41
Rys. 2 Szereg o asymetrii dodatniej (prawostronnej)
")
42
Rys. 3 Szereg asymetryczny ujemnie (lewostronnie)
")
43
W szeregu symetrycznym przy asymetrii lewostronnej przy prawostronnej

44
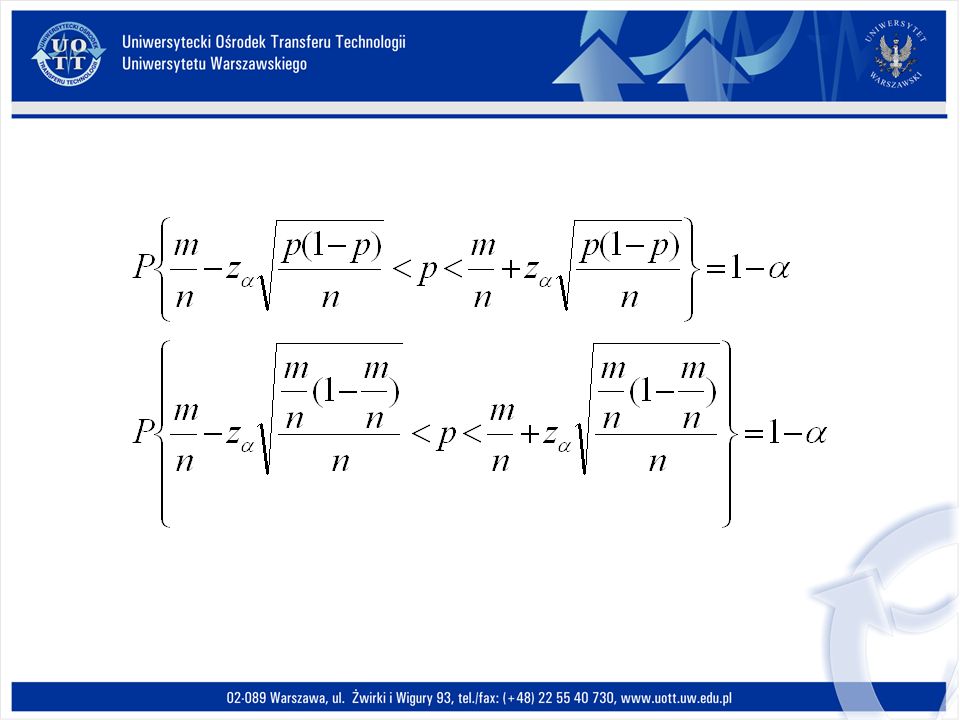
Estymacja przedziałowa parametrów jednej zmiennej Przedział ufności dla średniej m populacji normalnej ze znanym odchyleniem standardowym. Załóżmy, że próba losowa prosta (X1,X2,X3,...Xm) została pobrana z populacji generalnej o rozkładzie N(m, ), gdzie średnia m jest nieznana, natomiast odchylenie standardowe jest znane. Zadaniem naszym jest zbudowanie przedziału ufności dla średniej m przy współczynniku ufności 1-.
 została pobrana z populacji generalnej o rozkładzie N(m, ), gdzie średnia m jest nieznana, natomiast odchylenie standardowe jest znane. Zadaniem naszym jest zbudowanie przedziału ufności dla średniej m przy współczynniku ufności 1-..")
46
Przedział ufności dla średniej m w populacji normalnej z nieznanym odchyleniem standardowym. Niech cecha X ma w populacji rozkład N(m, ), gdzie zarówno średnia m, jak i odchylenie standardowe są nieznane. Z populacji tej pobrano próbę prosta (X1, X2,...,Xn) na podstawie której mamy zbudować przy współczynniku ufności 1- przedział ufności dla średniej m w populacji.
, gdzie zarówno średnia m, jak i odchylenie standardowe są nieznane. Z populacji tej pobrano próbę prosta (X1, X2,...,Xn) na podstawie której mamy zbudować przy współczynniku ufności 1- przedział ufności dla średniej m w populacji..")
48
Przedział ufności dla wariancji o odchylenia standardowego. Niech populacja generalna ma rozkład N(m, ) o nieznanych parametrach m i. Z populacji tej pobrano próbę losowa prosta (X1,X2,...,Xn). Na jej podstawie mamy zbudować przy współczynniku ufności 1- przedział ufności dla nieznanej wariancji 2. Estymatorem parametru 2 jest wariancja z próby S 2.
 o nieznanych parametrach m i. Z populacji tej pobrano próbę losowa prosta (X1,X2,...,Xn). Na jej podstawie mamy zbudować przy współczynniku ufności 1- przedział ufności dla nieznanej wariancji 2. Estymatorem parametru 2 jest wariancja z próby S 2..")
50
Przedział ufności dla prawdopodobieństwa. W badaniach statystycznych często spotykamy się z cechami jakościowymi, niemierzalnymi. Zachodzi wówczas konieczność szacowania m.in.. Frakcji elementów mających wyróżniona cechę w populacji generalnej. Frakcja ta (zwana też wskaźnikiem struktury) jest w swej istocie prawdopodobieństwem sukcesu. Estymatorem prawdopodobieństwa p w populacji generalnej jest wskaźnik struktury W=m/n, gdzie m jest liczba jednostek w próbie mających wyróżnioną cechę, natomiast n jest liczebnością próby.
 jest w swej istocie prawdopodobieństwem sukcesu. Estymatorem prawdopodobieństwa p w populacji generalnej jest wskaźnik struktury W=m/n, gdzie m jest liczba jednostek w próbie mających wyróżnioną cechę, natomiast n jest liczebnością próby..")
52
Parametryczne testy istotności: 52 parametryczne i nieparametryczne –parametryczne – testujemy parametr (np. średnią) –nieparametryczne – testujemy zjawisko (prawidłowość) – np. test niezależności
 –nieparametryczne – testujemy zjawisko (prawidłowość) – np. test niezależności.")
53
Hipotezy statystyczne 53 Hipoteza statystyczna to każde przypuszczenie weryfikowane na podstawie n-elementowej próby Hipotezą zerową, oznaczoną przez H 0, jest hipoteza o wartości jednego z parametrów populacji (lub wielu) –Tę hipotezę traktujemy jako prawdziwą, dopóki nie uzyskamy informacji dostatecznych do zmiany naszego stanowiska Hipotezą alternatywną, oznaczoną przez H 1, jest hipoteza przypisująca parametrowi (parametrom) populacji wartość inną niż podaje to hipoteza zerowa
 –Tę hipotezę traktujemy jako prawdziwą, dopóki nie uzyskamy informacji dostatecznych do zmiany naszego stanowiska Hipotezą alternatywną, oznaczoną przez H 1, jest hipoteza przypisująca parametrowi (parametrom) populacji wartość inną niż podaje to hipoteza zerowa")
54
54 Sprawdzianem lub statystyką testu –nazywamy statystkę z próby, której wartość obliczona na podstawie wyników obserwacji jest wykorzystywana do ustalenia czy możemy hipotezę zerową odrzucić czy jej odrzucić nie możemy.

55
Test dla średniej w populacji dla dużej próby (n > 30) H 0 : = 0 H 1 : 0 Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -u /2 ) (u /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do R
 H 0 : = 0 H 1 : 0 Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -u /2 ) (u /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do R")
56
Test dla średniej w populacji dla małej próby (n 30) H 0 : = 0 H 1 : 0 Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -t /2 ) (t /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do R ma rozkład t o n-1 stopniach swobody
 H 0 : = 0 H 1 : 0 Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -t /2 ) (t /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do R ma rozkład t o n-1 stopniach swobody")
57
Test dla porównania dwóch wartości oczekiwanych dwóch populacji przy dużych próbach (n 1 > 30 i n 2 > 30) H 0 : = H 1 : Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -u /2 ) (u /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do R dwie badane populacje mają rozkład normalny N( 1, 1 ) oraz N( 2, 2 )
 H 0 : = H 1 : Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -u /2 ) (u /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do R dwie badane populacje mają rozkład normalny N( 1, 1 ) oraz N( 2, 2 )")
58
Test dla porównania dwóch wartości oczekiwanych dwóch populacji przy małych próbach (n 1 30 i n 2 30) H 0 : = H 1 : Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -t /2 ) (t /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do R dwie badane populacje mają rozkład normalny N( 1, 1 ) oraz N( 2, 2 ), nieznane odchylenia ma rozkład t o n 1 + n 2 - 2 stopniach swobody
 H 0 : = H 1 : Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -t /2 ) (t /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka t należy do R dwie badane populacje mają rozkład normalny N( 1, 1 ) oraz N( 2, 2 ), nieznane odchylenia ma rozkład t o n 1 + n stopniach swobody")
59
Test hipotezy o wskaźniku frakcji w populacji (n > 100) H 0 : p= p 0 H 1 : p p 0 jeśli próba jest duża, to rozkład frakcji w próbie jest rozkładem normalnym o średniej p i odchyleniu pq/n Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -u /2 ) (u /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do R
 H 0 : p= p 0 H 1 : p p 0 jeśli próba jest duża, to rozkład frakcji w próbie jest rozkładem normalnym o średniej p i odchyleniu pq/n Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -u /2 ) (u /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do R")
60
Test hipotezy o wskaźnikach frakcji w dwóch populacjach (każde n > 100) H 0 : p 1 = p 2 H 1 : p 1 p 2 Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -u /2 ) (u /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do R gdzie:
 H 0 : p 1 = p 2 H 1 : p 1 p 2 Poziom istotności: (zazwyczaj przyjmowany: 0,05; 0,01) Statystyka testu: Obszar krytyczny: R = (- ; -u /2 ) (u /2 ; + ) Reguła decyzyjna: hipotezę zerową odrzucić, jeśli statystyka u należy do R gdzie:")
61
Testy losowości Weryfikują hipotezę, że dobór jednostek do próby był jednakowyWeryfikują hipotezę, że dobór jednostek do próby był jednakowy

62
Test serii Stevensa 1. Ho: Dobór jednostek do próby jest losowy H1:Dobór jednostek do próby nie jest losowy 2. Procedura testowa: 2a. Wyznaczamy na podstawie uporządkowanych danych medianę 2b. Danym nieuporządkowanym przyporządkowujemy następujące oznaczenia: A gdy x<Me B gdy x>Me 0 gdy x=Me (zera pomijamy w dalszej analizie) Statystyką testową jest liczba serii (k)
 Statystyką testową jest liczba serii (k).")
63
Seria – ciąg identycznych symboli (A lub B)Seria – ciąg identycznych symboli (A lub B) np. AAAA B A BBk=4 AAA 0 A BBB 0 AA k=3 AAA 0 A BBB 0 AA k=3

64
3. Ustalamy poziom istotności 4. Obszar krytyczny testu jest zawsze dwustronny. Odczytujemy z rozkładu liczby serii wartości krytyczne 5. Podejmujemy decyzję

65
Przykład 1: Wylosowano 12 spółek i zbadano cenę ich akcji (w zł). Otrzymano następujące wyniki: 74,5 191,0 55,5 5,15 36,4 35,0 46,0 10,9 7,35 6,65 173,5 26,0. Czy dobór spółek do próby był losowy? Wysuniętą hipotezę zweryfikuj na poziomie istotności 0,05.

66
Rozwiązanie: Ho: dobór jednostek do próby jest losowy H1:Dobór jednostek do próby nie jest losowy Wyznaczamy medianę: Poz. Me=(n+1)/2=6,5 Me=35,7 Danym pierwotnym przypisujemy litery A, B, 0 kolejnym obserwacjom
/2=6,5 Me=35,7 Danym pierwotnym przypisujemy litery A, B, 0 kolejnym obserwacjom.")
67
Obliczamy liczbę serii:Obliczamy liczbę serii: k=8k=8 Poziom istotności 0,05Poziom istotności 0,05 Odczytujemy wartości krytyczne:Odczytujemy wartości krytyczne:

68
Porównujemy wartość statystyki z próby z wartościami krytycznymi:Porównujemy wartość statystyki z próby z wartościami krytycznymi: Brak podstaw do odrzucenia hipotezy zerowej, która mówi, że dobór jednostek do próby był losowy.Brak podstaw do odrzucenia hipotezy zerowej, która mówi, że dobór jednostek do próby był losowy. 310 8

69
Testy zgodności: Weryfikują hipotezę o zgodności rozkładu empirycznego (rozkładu z próby losowej) z rozkładem teoretycznym (np. normalnym, dwumianowym itp.) lub inaczej ujmując – dotyczą postaci rozkładu badanej cechy w populacji.Weryfikują hipotezę o zgodności rozkładu empirycznego (rozkładu z próby losowej) z rozkładem teoretycznym (np. normalnym, dwumianowym itp.) lub inaczej ujmując – dotyczą postaci rozkładu badanej cechy w populacji.
 lub inaczej ujmując – dotyczą postaci rozkładu badanej cechy w populacji.Weryfikują hipotezę o zgodności rozkładu empirycznego (rozkładu z próby losowej) z rozkładem teoretycznym (np. normalnym, dwumianowym itp.) lub inaczej ujmując – dotyczą postaci rozkładu badanej cechy w populacji..")
70
Testy zgodności (normalności) 1.Test Kołmogorowa- Smirnowa (D) (próby małe n<100, zmienna ciągła) 2. Test - Kołmogorowa (próby duże n 100, zmienna ciągła) 3.Test 2 (wszystkie zmienne, szeregi rozdzielcze o dużych liczebnościach w przedziałach, próby duże)
 3.Test 2 (wszystkie zmienne, szeregi rozdzielcze o dużych liczebnościach w przedziałach, próby duże).")
71
Etapy testów zgodności (aproksymacja rozkładu normalnego): 1. Ustalamy parametry rozkładu normalnego 2. Standaryzujemy prawe (górne) granice przedziałów (poza ostatnim) 3. Odczytujemy wartości dystrybuant z tablicy rozkładu normalnego (jako ostatnią dystrybuantę przyjmujemy wartość 1) 4a. Z dystrybuant obliczamy skumulowane wartości teoretyczne (test Chi-kwadrat) lub 4b. Obliczamy dystrybuanty empiryczne (test Kołmogorowa)
 granice przedziałów (poza ostatnim) 3. Odczytujemy wartości dystrybuant z tablicy rozkładu normalnego (jako ostatnią dystrybuantę przyjmujemy wartość 1) 4a. Z dystrybuant obliczamy skumulowane wartości teoretyczne (test Chi-kwadrat) lub 4b. Obliczamy dystrybuanty empiryczne (test Kołmogorowa).")
72
Etapy testów zgodności (c.d.): 5. Obliczamy wartość statystyki testowej 6 a. Odczytujemy wartość krytyczną z tablic Lub 6 b. Obliczamy prawdopodobieństwo testu 7. Podejmujemy decyzję

73
Przykład 1:

74
Wiek w latach Liczba osób ZF(Z)niskF(X) 15-252 -1,380,083320,11760,0343 25-353 -0,460,322450,29410,0283 35-456 0,460,6776110,64710,0305 45-555 1,380,9167160,94120,0245 55-651 x1171,00000,0000 Suma17xxxx
niskF(X) ,380,083320,11760, ,460,322450,29410, ,460, ,64710, ,380, ,94120, x1171,00000,0000 Suma17xxxx")
75
0,206 0,0343 Brak podstaw do odrzucenia hipotezy zerowej o zgodności rozkładu wieku inwestorów z rozkładem normalnym.

76
Przykład 2: I sposób (test - Kołmogorowa)
")
77
Wiek w latach Liczba osób ZF(Z)niskF(X) 15-2520 -1,380,0833200,11760,0343 25-3530 -0,460,3224500,29410,0283 35-4560 0,460,67761100,64710,0305 45-5550 1,380,91671600,94120,0245 55 i więcej10 x11701,00000,0000 Suma170xxxx
niskF(X) ,380, ,11760, ,460, ,29410, ,460, ,64710, ,380, ,94120, i więcej10 x11701,00000,0000 Suma170xxxx")
78
1,36 0,447 Brak podstaw do odrzucenia hipotezy zerowej o zgodności rozkładu wieku inwestorów z rozkładem normalnym.

79
Przykład 2: II sposób (test Chi - kwadrat)
")
80
Wiek w latach Liczba osób ZF(Z) 15-2520 -1,380,083314,16 28,25 25-3530 -0,460,322454,8140,6522,14 35-4560 0,460,6776115,1960,3859,62 45-5550 1,380,9167155,8440,6561,50 55 i więcej10 x117014,167,06 Suma170xxx 178,57
 ,380,083314,16 28, ,460,322454,8140,6522, ,460, ,1960,3859, ,380, ,8440,6561,50 55 i więcej10 x117014,167,06 Suma170xxx 178,57")
81
1,36 8,57 Brak podstaw do odrzucenia hipotezy zerowej o zgodności rozkładu wieku inwestorów z rozkładem normalnym.

82
Testy jednorodności Weryfikują hipotezę o zgodności dwóch rozkładów empirycznych ze sobą (oba rozkłady pochodzą z tej samej populacji)Weryfikują hipotezę o zgodności dwóch rozkładów empirycznych ze sobą (oba rozkłady pochodzą z tej samej populacji)
Weryfikują hipotezę o zgodności dwóch rozkładów empirycznych ze sobą (oba rozkłady pochodzą z tej samej populacji)")
83
Testy jednorodności Test serii Walda – WolfowitzaTest serii Walda – Wolfowitza (próby niezależne, małe, dane szczegółowe) Test 2 (Snedeckora)Test 2 (Snedeckora) (próby niezależne, duże, szeregi rozdzielcze o licznych przedziałach, wszystkie rodzaje cech) Test Kołmogorowa - Smirnowa ( )Test Kołmogorowa - Smirnowa ( ) (próby niezależne, duże, tylko cechy ilościowe ciągłe) Test znaków (Dixona - Mooda)Test znaków (Dixona - Mooda) (próby zależne, małe, dane szczegółowe, cechy ilościowe ciągłe)
 Test 2 (Snedeckora)Test 2 (Snedeckora) (próby niezależne, duże, szeregi rozdzielcze o licznych przedziałach, wszystkie rodzaje cech) Test Kołmogorowa - Smirnowa ( )Test Kołmogorowa - Smirnowa ( ) (próby niezależne, duże, tylko cechy ilościowe ciągłe) Test znaków (Dixona - Mooda)Test znaków (Dixona - Mooda) (próby zależne, małe, dane szczegółowe, cechy ilościowe ciągłe)")
84
Przykład: Liczba zgonów niemowląt wg wieku w losowo wybranych próbach w 1989 roku i 1990 roku. WiekLiczba niemowląt 19891990 0 dni11273 1-6132135 7-132721 14-201117 21-2989 1-2 m-ce2826 3-52437 6-112421 Razem366339 Czy rozkłady zgonów niemowląt według wieku w obu badanych próbach są takie same? =0.05

85
Test jednorodności chi-kwadrat

86
WiekLiczba niemowląt 19891990 0 dni11273 67,81 06-sty132135 65,26 13-lip2721 15,19 14-201117 4,32 21-2989 3,76 1-2 m-ce2826 14,52 05-mar2437 9,44 11-cze2421 12,80 Razem366339 193,10

87
14,067 0,018 Brak podstaw do odrzucenia hipotezy zerowej o jednorodności rozkładu zgonów niemowląt.

88
Przykład:

89
2 4 Brak podstaw do odrzucenia hipotezy zerowej o identyczności rozkładów wagi przed i po kuracji.

90
Klasyczny model regresji liniowej

91
Model ekonometryczny jest równaniem (lub układem równań), które przedstawia zasadnicze powiązanie ilościowe między rozpatrywanymi zjawiskami ekonomicznymi.
, które przedstawia zasadnicze powiązanie ilościowe między rozpatrywanymi zjawiskami ekonomicznymi.")
92
Ze względu na rolę zjawisk ekonomicznych w modelu ekonometrycznym można wyróżnić zjawisko ekonomiczne wyjaśniane przez model (czyli zmienną objaśnianą) zjawiska, które oddziałują na zmienną objaśnianą (czyli zmienne objaśniające)
 zjawiska, które oddziałują na zmienną objaśnianą (czyli zmienne objaśniające)")
93
Dane dotyczące sprzedaży oprogramowania Tygodnie Sprzedaż oprogramowania w szt. Cena jednego programu (zl.) Wydatki na reklamę (zl.) YX1X1 X2X2 1101,39 2627 351,75 4121,514 5101,615 6 1,212 751,66 8121,410 917115 10201,121
 Wydatki na reklamę (zl.) YX1X1 X2X2 1101, , , , , , , ,121.")
94
Modele ekonometryczne można sklasyfikować według różnych kryteriów: 1. Liczby równań w modelu model jednorównaniowy model wielorównaniowy 2. Liczby zmiennych objaśniających modele z jedną zmienną objaśniającą modele z wieloma zmiennymi objaśniającymi 3. Postaci analitycznej modele liniowe modele nieliniowe 4. Roli czynnika czasu w równaniach modelu modele statyczne modele dynamiczne

95
Wykres rozrzutu zmiennych X 1 i Y (cena i ilość sprzedaży)
")
96
Wykres rozrzutu zmiennych X 2 i Y (sprzedaż i reklama)
")
97
Obser- wacje Zmienna objaśniana (zależna) Zmienne objaśniające (niezależne) YX1X1 X2X2 XkXk 1Y1Y1 X 11 X 12 X 1k 2Y2Y2 X 21 X 22 X 2k 3Y3Y3 X 31 X 32 X 3k …………… nYnYn X n1 X n2 X nk
 Zmienne objaśniające (niezależne) YX1X1 X2X2 XkXk 1Y1Y1 X 11 X 12 X 1k 2Y2Y2 X 21 X 22 X 2k 3Y3Y3 X 31 X 32 X 3k …………… nYnYn X n1 X n2 X nk")
98
Obliczenie współczynników korelacji

99
Macierz współczynników korelacji YX1X1 X2X2 Y1 X1X1 -0,861 X2X2 0,89-0,651

100
Y X1X1 X2X2 1 2 Okrąg Y reprezentuje wariancje zmiennej zależnej Okręgi X 1 i X 2 reprezentują wariancje zmiennych niezależnych Obszar 1 odpowiada tej części wariancji Y, która poprzez model wyjaśnia zmienność X 1 Obszar 2 odpowiada tej części wariancji Y, która poprzez model wyjaśnia zmienność X 2

101
Y X1X1 X2X2 1 2 Sytuacja, gdy nie ma korelacji między zmiennymi X 1 i X 2

102
Y X1X1 X2X2 Sytuacja, gdy zmienne niezależne X 1 i X 2 również skorelowane (obszar 3) 3 Powoduje to, iż część wariancji Y może zostać przypisana jednocześnie zmienności X 1 lub X 2
 3 Powoduje to, iż część wariancji Y może zostać przypisana jednocześnie zmienności X 1 lub X 2")
103
Y X1X1 X2X2 Zwykle wymaga się dodatkowo, aby współczynnik korelacji pomiędzy zmiennymi niezależnymi był mniejszy od współczynnika korelacji pomiędzy Y a X

104
Y Y Y Y X1X1 X1X1 X1X1 X1X1 X2X2 X2X2 X2X2 X2X2 b a c d

105
Macierz współczynników korelacji YX1X1 X2X2 Y1 X1X1 -0,861 X2X2 0,89-0,651

106
Liniowy model regresji wielu zmiennych Y – zmienna objaśniana X k – zmienne objaśniające β 0 β 1 …β k – nieznane parametry strukturalne modelu ε - składnik losowy k – numeruje kolejne zmienne objaśniające

107
Metoda najmniejszych kwadratów opiera się na koncepcji poszukiwania takich wartości b 0 b 1 … b k parametrów strukturalnych β 0, β 1 … β k przy których suma kwadratów reszt osiąga minimum

108
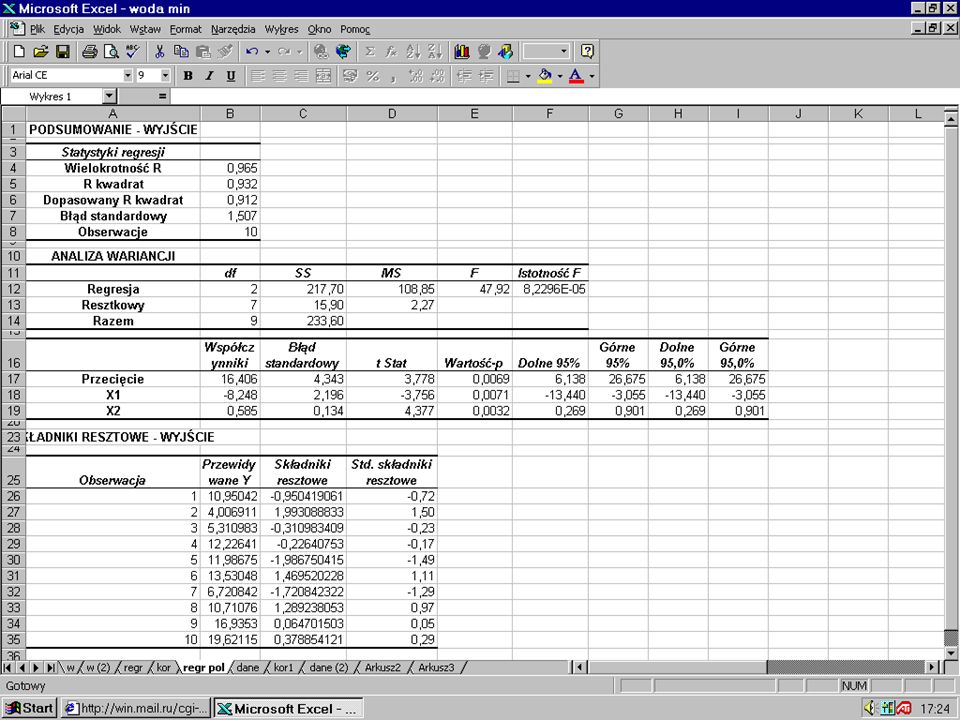
b 1 = -8,248b 0 = 16,406 Ŷ = 16,406 – 8,248 X 1 + 0,585 X 2 b 2 = 0,585

110
Weryfikacja modelu ekonometrycznego 1. Badanie dopasowania modelu do danych obserwowanych współczynnik determinacji i współczynnik zbieżności współczynnik zmienności losowej 2. Badanie istotności parametrów strukturalnych β i test t-Studenta test F 3. Badanie własności odchyleń losowych losowość składnika losowego normalność rozkładu składnika losowego jednorodność wariancji składnika losowego autokorelacja składnika losowego

111
1. Badanie dopasowania modelu do danych obserwowanych

112
Dokładność dopasowania prostej metodą najmniejszych kwadratów Punktem wyjścia przy dokonywaniu pomiaru dokładności dopasowania prostej regresji do danych empirycznych jest następujący podział odchylenia obserwowanej wartości Y i od średniej Y ̅

113
Pierwszy z tych składników (Ŷ i – ) można traktować jako tę część całkowitego odchylenia Y i od, która jest wyjaśniona regresją Y względem X. Drugi składnik (Y i - Ŷ i ) jest resztą e i dla x=x i, a zatem jest to ta część całkowitego odchylenia Y i od Y, która nie została wyjaśniona regresją Y względem X
 jest resztą e i dla x=x i, a zatem jest to ta część całkowitego odchylenia Y i od Y, która nie została wyjaśniona regresją Y względem X.")
114
Analogiczna równość zachodzi także dla sum kwadratów odpowiednich odchyleń

119
YX1X2Ŷ(Y-Ŷ)(Y-Ŷ)^2 101,3910,95-0,950,90 6274,012,003,98 51,755,31-0,310,10 121,51412,22-0,220,05 101,61511,98-1,983,94 151,21213,531,472,17 51,666,72-1,722,96 121,41010,711,291,67 1711516,930,070,00 201,12119,620,380,15 Suma0,0215,90 Dane SSE
(Y-Ŷ)^2 101,3910,95-0,950, ,012,003,98 51,755,31-0,310,10 121,51412,22-0,220,05 101,61511,98-1,983,94 151,21213,531,472,17 51,666,72-1,722,96 121,41010,711,291, ,930,070,00 201,12119,620,380,15 Suma0,0215,90 Dane SSE")
121
Sum of Squares SSE SST SSR

122
SST r2r2 SSR

123
r2r2r2r2 r

124
(współczynnik korelacji) 2 = współczynnik determinacji (r) 2 = r 2 (0,965) 2 = 0,932
 2 = współczynnik determinacji (r) 2 = r 2 (0,965) 2 = 0,932")
125
YX1X2Ŷ(Y-Ŷ)(Y-Ŷ)^2 101,3910,95-0,950,90 6274,012,003,98 51,755,31-0,310,10 121,51412,22-0,220,05 101,61511,98-1,983,94 151,21213,531,472,17 51,666,72-1,722,96 121,41010,711,291,67 1711516,930,070,00 201,12119,620,380,15
(Y-Ŷ)^2 101,3910,95-0,950, ,012,003,98 51,755,31-0,310,10 121,51412,22-0,220,05 101,61511,98-1,983,94 151,21213,531,472,17 51,666,72-1,722,96 121,41010,711,291, ,930,070,00 201,12119,620,380,15")
126
r 2 bliskie 1 r 2 bliskie 0

127
Stopnie swobody Przez stopnie swobody rozumie się liczbę niezależnych wyników obserwacji pomniejszoną o liczbę związków, które łączą wyniki obserwacji ze sobą Liczba stopni swobody wskazuje, jak wiele niezależnych informacji zawartych w n niezależnych wartościach y 1, y 2, …, y n jest potrzebnych do zestawienia danej sumy kwadratów

130
liczba stopni swobody 2 10-2-1 10- 1 n

133
Wartość średnia kwadratów reszt Suma kwadratów Stopnie swobody Wartość średnia kwadratów Regresja SSRkMSR = SSR / k Resztkowy SSEn-k-1 MSE = SSE / (n-k-1) Razem SSTn-1
 Razem SSTn-1")
134
Wartość średnia kwadratów reszt Mean of Squares Wartość średnia kwadratów SSE n-k-1

136
SMSE

138
X̅X̅ Przedział ufności dla linii regresji linia regresji

139
2. Badanie istotności parametrów strukturalnych β i

141
Test t-Studenta Badanie istotności parametrów strukturalnych modelu polega na weryfikacji hipotez postaci H 0 : β j = 0 H A : β j 0 parametr β j nieistotnie różni się od zera zmienna objaśniająca X j nieistotnie wpływa na zmienną objaśnianą Y parametr β j istotnie różni się od zera zmienna objaśniająca X j istotnie wpływa na zmienną objaśnianą Y

143
b0b0 b1b1 S b1 t b1

144
-3,76

145
Wartość p Wartość p jest krytycznym poziomem istotności dla testu t- Studenta Wartość p jest poziomem prawdopodobieństwa przy którym nie ma podstaw do odrzucenia hipotezy zerowej H 0 Przyjmując, że poziom istotności ustala się zwykle jako 5% (0,05), hipoteza zerową jest odrzucona, gdy wartość p 0,05
, hipoteza zerową jest odrzucona, gdy wartość p 0,05")
146
0,007 0,05 p 0,05 Hipotezę H o odrzucamy

147
Wartość p jest mniejsza od 0,05, wobec tego parametr b 1 jest istotny na poziomie istotności 5% p 0,05

148
Test F Badanie istotności parametrów strukturalnych testem F polega na badaniu istotności wszystkich parametrów strukturalnych łącznie H 0 : β 1 = β 2 = … = β k = 0 parametr β 1 nieistotnie różni się od β 2, β k, zera zmienna objaśniająca X nieistotnie wpływa na zmienną objaśnianą Y H A : β j 0 parametr β j istotnie różni się od zera zmienna objaśniająca X istotnie wpływa na zmienną objaśnianą Y

150
MSR Test F MSE F

151
47,9

152
8,23*10 -5 0,05 Istotność F 0,05 Hipotezę H o odrzucamy

153
Istotność Fjest mniejsza od 0,05, wobec tego parametr b1 jest istotny na poziomie istotności 5% Istotność F jest mniejsza od 0,05, wobec tego parametr b1 jest istotny na poziomie istotności 5% Istotność F 0,05 Hipotezę H o odrzucamy

157
Interpretacja oznaczeń wyników analizy regresji w Excel t Stat – wartość testu t-Studenta, służące do badania istotności parametrów strukturalnych Wartość-p – wartość prawdopodobieństwa empirycznego (prawdopodobieństwo zdarzenia, że statystyka t b znajdzie się w przedziale ufności prawdziwość hipotezy zerowej H 0 )
")
158
Proces przekształcania modeli nieliniowych w liniową transformację nosi nazwę linearyzacji. Należy zwrócić uwagę, że określając postać analityczną modelu ekonometrycznego należy kierować się wyborem funkcji jak najmniej skomplikowanej pod względem matematycznym. Prostota modelu wiąże się z reguły z bardziej czytelną jego interpretacją ekonomiczną. Dlatego też, jeżeli jest to tylko merytorycznie uzasadnione stosuje się w pierwszej kolejności modele liniowe, w następnej nieliniowe z liniową transformantą, a dopiero w ostateczności modele nieliniowe sensu stricto.

159
Transformacja liniowa jest zatem rozwiązaniem kompromisowym. Z jednej strony dążymy do pełnej merytorycznej poprawności postaci analitycznej, a z drugiej liczymy się zawsze z możliwościami szacunku parametrów modelu. Znane i stosunkowo proste metody estymacji parametrów modeli ekonometrycznych zakładają z reguły liniowość modelu (lub przynajmniej liniowość modelu względem parametrów, niekoniecznie zmiennych). Przykładem funkcji nieliniowych, które są liniowe względem parametrów a nieliniowe względem zmiennych są funkcje wielomianowe
. Przykładem funkcji nieliniowych, które są liniowe względem parametrów a nieliniowe względem zmiennych są funkcje wielomianowe.")
160
Funkcje nieliniowe nie zawsze spełniają ten wymóg. Jeżeli wymóg ten nie jest spełniony, wówczas uciekamy się do transformacji liniowej, polegającej na sprowadzeniu funkcji nieliniowych do liniowych za pomocą zamiany zmiennych, albo też za pomocą podstawień. Warunkiem koniecznym (jednak nie dostatecznym) zastosowania procedury transformacji liniowej jest wymóg, aby liczba parametrów modelu nieliniowego była co najmniej równa k+1 (gdzie k – liczba zmiennych modelu).
 zastosowania procedury transformacji liniowej jest wymóg, aby liczba parametrów modelu nieliniowego była co najmniej równa k+1 (gdzie k – liczba zmiennych modelu)..")
161
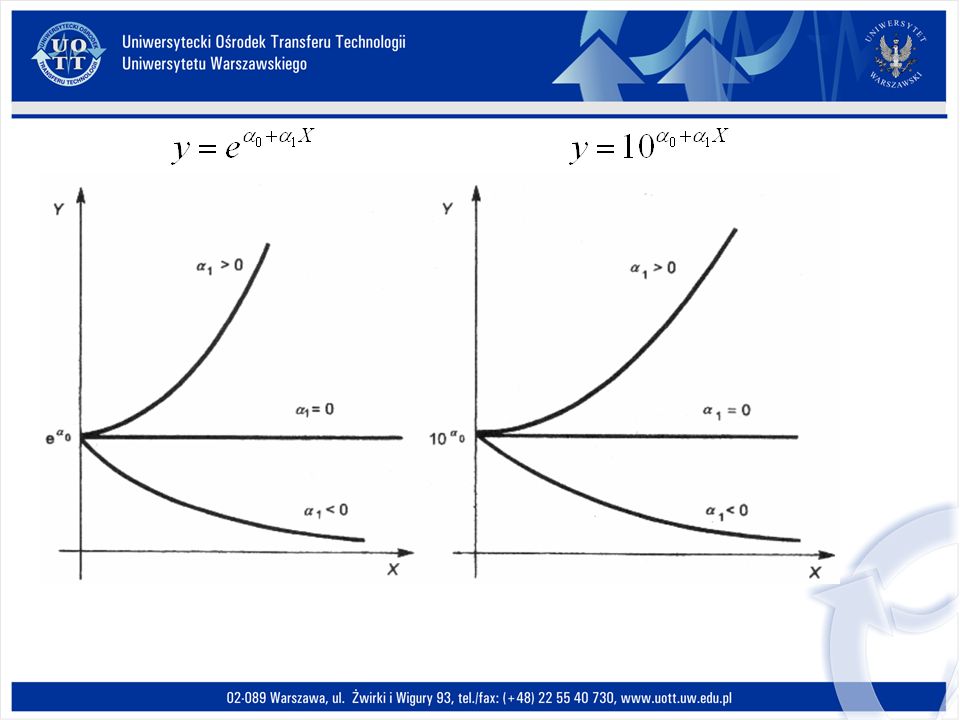
Jej postać analityczna jest następująca: Y=α 0 α 1 X, przy założeniu, że α 0 >0, α 1 >0. Przekształcenie do postaci liniowej odbywa się poprzez logarytmowanie. Zatem linearyzacja przebiega następująco: Funkcja wykładnicza

162
Funkcja wykładnicza znajduje najczęściej zastosowanie jako model tendencji rozwojowej (w którym występuje tylko jedna zmienna objaśniająca – zmienna czasowa t). Ponadto ma zastosowanie: - w przypadku, gdy tempo wzrostu danej wielkości jest stałe, na przykład w badaniu dynamiki dochodu narodowego; - w analizie rynku, przy badaniu na dobra nowe, w fazie rozpowszechniania; -jest także jedną z typowych funkcji kosztów całkowitych.

163
przy założeniu, że α 0 >0, α 1 >0.

165
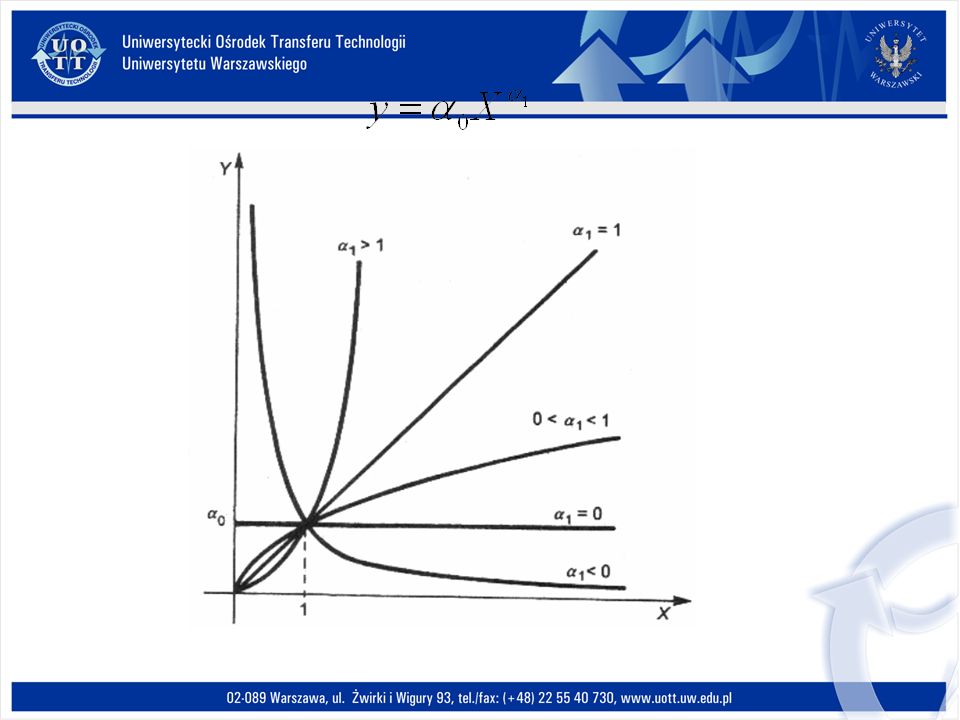
Funkcja potęgowa jednej zmiennej ma postać: Y=α 0 X α1. Przekształcenie do postaci liniowej odbywa się podobnie jak w przypadku funkcji wykładniczej: Funkcja potęgowa

166
Funkcja potęgowa jest jedną z najczęściej stosowanych postaci, gdyż nadaje się do opisu różnego rodzaju zależności, zarówno liniowych jak i krzywoliniowych. Tego typu funkcja ma zastosowanie: - w analizie rynku przy badaniu popytu na dobra nowe, wówczas α 1 >0 oraz gdy dane dobro rośnie ale w tempie malejącym; - dla α 1 >0 dobrze aproksymuje zależność indywidualnej wydajności pracy od czasu dojazdu do pracy; - w demometrii, przy szacowaniu potencjału życiowego ludności.

168
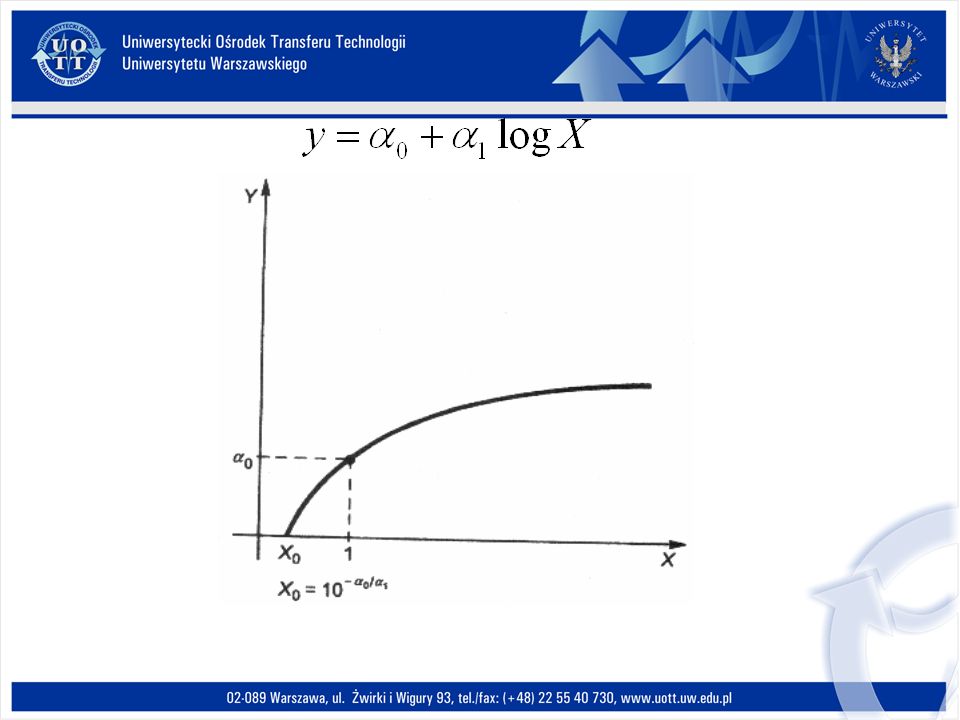
Postać analityczna w tym wypadku wygląda następująco: Y=α 0 +α 1 logX, przy założeniu, że α 0 >0, α 1 >0. Sprowadzenie funkcji do postaci liniowej odbywa się poprzez odpowiednie podstawienia. Funkcja logarytmiczna

169
Zastosowania w tym przypadku są następujące: - dla α 1 >0 dobrze aproksymuje krzywe Engla dla dóbr wyższego rzędu (dóbr względnie luksusowych lub inaczej półluksusowych), gdy popyt na te dobra rośnie, ale w tempie malejącym; - opisuje udział procentowy pracowników na przykład inżynieryjno-technicznych w stosunku do ogółu zatrudnionych w przemyśle; - dla α 0 =0, α 1 >0 jest funkcją kosztów całkowitych – jest to konsekwencją hipotezy, że funkcja kosztów całkowitych jest funkcją odwrotną do funkcji produkcji.
, gdy popyt na te dobra rośnie, ale w tempie malejącym; - opisuje udział procentowy pracowników na przykład inżynieryjno-technicznych w stosunku do ogółu zatrudnionych w przemyśle; - dla α 0 =0, α 1 >0 jest funkcją kosztów całkowitych – jest to konsekwencją hipotezy, że funkcja kosztów całkowitych jest funkcją odwrotną do funkcji produkcji.")
171
Dla funkcji hiperbolicznej postać analityczna jest często następująca: Y=α 0 +α 1, przy założeniu, że α 1 >0. W wyniku podstawienia otrzymujemy następującą postać zlinearyzowaną: Dla α 0 0, α 1 >0 jest funkcją kosztów przeciętnych, gdy funkcja kosztów całkowitych jest funkcją liniową. Funkcja hiperboliczna

172
przy założeniu, że α 1 >0.

173
Zastosowanie tego typu funkcji ma miejsce głównie w ekonometrycznej analizie kosztów produkcji. Dla przykładu wielomian stopnia trzeciego ma postać: Y=α 0 +α 1 X 1 + α 2 X 2 2 +α 3 X 3 3, A jego wykres, gdy parametry spełniają warunki: α 0 >0, α 1 >0, α 3 >0, α 2 0, α 1 >0, α 3 >0, α 2 <0, α 2 2 <3α 1 α 3. Funkcja wielomianowa

174
Wielomian stopnia drugiego ma przebieg zmienności dobrze znany z elementarnego kursu matematyki. Y=α 0 +α 1 X 1 + α 2 X 2 2, I tak dla α 2 0 dobrze opisuje zależności indywidualnej wydajności pracy od wieku pracownika, przebieg zmienności tej funkcji jest z reguły zgodny z obserwacjami empirycznymi – najpierw wydajność pracy rośnie coraz szybciej, a później coraz wolniej (optymalny wiek produkcyjny), a następnie maleje coraz to szybciej i wreszcie coraz to wolniej dążąc do zera, gdy x->. Tego typu funkcję linearyzujemy również metodą podstawiania.
, a następnie maleje coraz to szybciej i wreszcie coraz to wolniej dążąc do zera, gdy x->. Tego typu funkcję linearyzujemy również metodą podstawiania..")
175
Zmienną objaśniającą w modelu logistycznym jest często czas, jest to więc model tendencji rozwojowej: Funkcja logistyczna

176
Opisane wcześniej modele nieliniowe były sprowadzane do modelu regresji liniowej przez transformację zmiennych lub przekształcenie całego modelu. Występują jednak również także zależności nieliniowe, które wymagają specyficznych metod przekształceń i szacowania parametrów. Przykładem takiego modelu jest krzywa logistyczna, która znajduje zastosowanie w badaniach makro- i mikroekonomicznych. W makroekonomii służy często do opisu wzrostu gospodarki narodowej lub liczebności populacji ludzkiej, w zagadnieniach mikroekonomicznych zaś jest dobrą aproksymantą funkcji popytu. Funkcja ta pisuje zjawiska, które charakteryzują się przechodzeniem od szybkiego wzrostu do coraz wolniejszego tempa, które stabilizuje się na pewnym poziomie, zwanym poziomem nasycenia.

177
Dziękuję za uwagę! Dr Tomasz Krawczyk Uniwersytecki Ośrodek Transferu Technologii Uniwersytetu Warszawskiego tkrawczyk@uott.uw.edu.pl






























 Miary asymetrii.>")
>")





 Średnia arytmetyczna (dla szeregu szczegółowego) Średnią arytmetyczną nazywamy sumę wartości zmiennej wszystkich jednostek.>")


