Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
MPI: podstawy i komunikacja punktowa

2
Charakterystyka standardowego interfejsu przesyłania wiadomości MPI: Kod jest napisany w „zwyczajnym” języku programowania (Fortran 77, Fortran 90, C, C++); przesyłanie wiadomości jest realizowane poprzez wywołanie odpowiednich procedur lub funkcji. Wszystkie zmienne są lokalne dla danego procesora; inny procesor może je uzyskać tylko poprzez wymianę wiadomości. Zwykle każdy procesor realizuje ten sam program wykonywalny (Single Program Multiple Data; SPMD), jednak występuje podział na procesor (procesory) nadzorujące (master) oraz „robotników” (workers) lub „niewolników” (slaves); realizują one inne fragmenty kodu, niż master. IF (ME == MASTER) THEN CALL SUB_MASTER(parametry) ELSE CALL SUB_WORKER(parametry) ENDIF W celu umożliwienia realizacji innych części kodu przez dany procesor lub grupę procesorów, każdy procesor ma własny identyfikator (0, 1,..., NPROC-1).
, jednak występuje podział na procesor (procesory) nadzorujące (master) oraz „robotników (workers) lub „niewolników (slaves); realizują one inne fragmenty kodu, niż master. IF (ME == MASTER) THEN CALL SUB_MASTER(parametry) ELSE CALL SUB_WORKER(parametry) ENDIF W celu umożliwienia realizacji innych części kodu przez dany procesor lub grupę procesorów, każdy procesor ma własny identyfikator (0, 1,..., NPROC-1)..")
3
Konstrukcja systemu przesyłania wiadomości

4
Kompilacja z użyciem bibliotek MPI Najprościej: użyć odpowiedniego skryptu wywołującego kompilator z dołączaniem bibliotek MPI: mpif77 - Fortran 77 mpicc - C mpiCC - C++ Poniżej podany jest przykład linii polecenia dla kompilacji kodu źródłowego programu hello w Fortranie 77. mpif77 -o hello hello.f Makefile FC = /usr/bin/g77 INSTALL_DIR=/opt/scali FFLAGS = -c ${OPT} -I$(INSTALL_DIR)/include LIBS = -L$(INSTALL_DIR)/lib_pgi -L$(INSTALL_DIR)/lib -lmpi -lfmpi.SUFFIXES:.f.f.o: ${FC} ${FFLAGS} $*.f hello: hello.o ${FC} -o hello $(LIBS) hello.o
/include LIBS = -L$(INSTALL_DIR)/lib_pgi -L$(INSTALL_DIR)/lib -lmpi -lfmpi.SUFFIXES:.f.f.o: ${FC} ${FFLAGS} $*.f hello: hello.o ${FC} -o hello $(LIBS) hello.o.")
5
Pisanie kodów żródłowych z użyciem MPI - inicjalizacja, zakończenie, informacje o przydzielonych procesorach. W każdym żródle muszą się znaleźć definicje zawarte w pliku mpi.h (C) lub mpif.h (Fortran); plik ten musi być zaspecyfikowany jako pierwszy plik include. Program musi zawsze zawierać instrukcję inicjalizacji MPI (MPI_Init) i zakończenia MPI (MPI_Finalize). Komunikacja między procesorami oraz inne funkcje MPI są realizowane poprzez wywołanie odpowiednich procedur.MPI_InitMPI_Finalize Ogólna postać wywołania procedur MPI jest następująca: C: ierr = MPI_Xyyyyy( parametry ) lub MPI_Xyyyyy( parametry ) Zmienna ierr typu int jest kodem wyjścia z procedury; 0 oznacza zakończenie poprawne. Należy zwrócić uwagę, że nazwa procedury MPI zaczyna się od MPI_X, gdzie X jest pierwszą literą nazwy procedury (zawsze duża litera); dalsza część nazwy jest pisana małymi literami. Fortran (77 lub 90): CALL MPI_XYYYYY( parametry, IERROR ) Podobnie jak w wersji C, IERROR (zmienna typu INTEGER) jest kodem wyjścia. Zgodnie z konwencją Fortranu, wielkość liter w nazwie procedury nie odgrywa roli.
 lub mpif.h (Fortran); plik ten musi być zaspecyfikowany jako pierwszy plik include. Program musi zawsze zawierać instrukcję inicjalizacji MPI (MPI_Init) i zakończenia MPI (MPI_Finalize). Komunikacja między procesorami oraz inne funkcje MPI są realizowane poprzez wywołanie odpowiednich procedur.MPI_InitMPI_Finalize Ogólna postać wywołania procedur MPI jest następująca: C: ierr = MPI_Xyyyyy( parametry ) lub MPI_Xyyyyy( parametry ) Zmienna ierr typu int jest kodem wyjścia z procedury; 0 oznacza zakończenie poprawne. Należy zwrócić uwagę, że nazwa procedury MPI zaczyna się od MPI_X, gdzie X jest pierwszą literą nazwy procedury (zawsze duża litera); dalsza część nazwy jest pisana małymi literami. Fortran (77 lub 90): CALL MPI_XYYYYY( parametry, IERROR ) Podobnie jak w wersji C, IERROR (zmienna typu INTEGER) jest kodem wyjścia. Zgodnie z konwencją Fortranu, wielkość liter w nazwie procedury nie odgrywa roli..")
6
Przykład programu z użyciem bibliotek MPI (C): #include "mpi.h" #include int main( argc, argv ) int argc; char **argv; { int rank, size, resultlen; char nodename[31]; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); MPI_Get_processor_name( nodename, &resultlen ); printf( "Hello world! I'm %d of %d my name is %s\n", rank, size, nodename ); MPI_Finalize(); return 0; }
![Przykład programu z użyciem bibliotek MPI (C): #include mpi.h #include int main( argc, argv ) int argc; char **argv; { int rank, size, resultlen; char nodename[31]; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); MPI_Get_processor_name( nodename, &resultlen ); printf( Hello world.](http://images.slideplayer.pl/15/4792233/slides/slide_6.jpg "I m %d of %d my name is %s\n , rank, size, nodename ); MPI_Finalize(); return 0; }.")
7
Przykład programu z użyciem bibliotek MPI (Fortran 77): program main include "mpif.h" integer rank, size, resultlen character*32 nodename call MPI_Init( ierr ) call MPI_Comm_rank( MPI_COMM_WORLD, rank, ierr ) call MPI_Comm_size( MPI_COMM_WORLD, size, ierr ) call MPI_Get_processor_name( nodename, resultlen, ierr ) print 10, rank, size, nodename call MPI_Finalize(ierr); 10 format("Hello world! I'm",i3," of",i3," my name is ",a8) return end
 return end.")
8
Wyniki etoh:~/MPI/Cw1/F77> mpirun -np 4 -nolocal hello Hello world! I'm 3 of 4 my name is mm17 Hello world! I'm 2 of 4 my name is mm16 Hello world! I'm 1 of 4 my name is mm15 Hello world! I'm 0 of 4 my name is mm14

9
Komunikacja punktowa: rodzaje, tryby i stosowanie Komunikacja punktowa: wymiana wiadomości pomiędzy dwoma procesami.

10
Definicja i konstrukcja wiadomości Wiadomość: pakiet danych przemieszczających się między procesorami. Podobnie jak list czy faks, oprócz właściwych przesyłanych danych musi ona być opakowana w „kopertę” (zawierać nagłówek) umożliwiający jej dostarczenie do właściwego odbiorcy :kopertę
 umożliwiający jej dostarczenie do właściwego odbiorcy :kopertę.")
11
KopertaKoperta musi zawierać następujące informacje dla systemu przesyłania wiadomości: Procesor wysyłający Lokalizacja źródła wiadomości Typ przesyłanych danych Długość przesyłanych danych Procesor(y) odbierające Lokalizacja odbiorcy wiadomości Wielkość buforu odbiorcy
 odbierające Lokalizacja odbiorcy wiadomości Wielkość buforu odbiorcy")
12
#include "mpi.h" #include int main( argc, argv ) int argc; char **argv; { int rank, size, to, from, tag, count, i, ierr; int src, dest; int st_source, st_tag, st_count; MPI_Status status; double data[100]; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); printf("Process %d of %d is alive\n",rank,size); dest = size - 1; src = 0; if (rank == src) { to = dest; count = 10; tag = 2001; for (i=0;i<10;i++) { data[i] = i+1; } MPI_Send( data, count, MPI_DOUBLE_PRECISION, to,tag, MPI_COMM_WORLD ); }else if (rank == dest) { tag = MPI_ANY_TAG; count = 10; from = MPI_ANY_SOURCE; MPI_Recv( data, count, MPI_DOUBLE_PRECISION, from,tag, MPI_COMM_WORLD, &status ); printf("%d received ",rank); for (i=0;i<10;i++) printf ("%10.5f",data[i]); printf("\n"); } MPI_Finalize(); return 0; }
![#include mpi.h #include int main( argc, argv ) int argc; char **argv; { int rank, size, to, from, tag, count, i, ierr; int src, dest; int st_source, st_tag, st_count; MPI_Status status; double data[100]; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); printf( Process %d of %d is alive\n ,rank,size); dest = size - 1; src = 0; if (rank == src) { to = dest; count = 10; tag = 2001; for (i=0;i<10;i++) { data[i] = i+1; } MPI_Send( data, count, MPI_DOUBLE_PRECISION, to,tag, MPI_COMM_WORLD ); }else if (rank == dest) { tag = MPI_ANY_TAG; count = 10; from = MPI_ANY_SOURCE; MPI_Recv( data, count, MPI_DOUBLE_PRECISION, from,tag, MPI_COMM_WORLD, &status ); printf( %d received ,rank); for (i=0;i<10;i++) printf ( %10.5f ,data[i]); printf( \n ); } MPI_Finalize(); return 0; }](http://images.slideplayer.pl/15/4792233/slides/slide_12.jpg "#include mpi.h #include int main( argc, argv ) int argc; char **argv; { int rank, size, to, from, tag, count, i, ierr; int src, dest; int st_source, st_tag, st_count; MPI_Status status; double data[100]; MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); printf( Process %d of %d is alive\n ,rank,size); dest = size - 1; src = 0; if (rank == src) { to = dest; count = 10; tag = 2001; for (i=0;i<10;i++) { data[i] = i+1; } MPI_Send( data, count, MPI_DOUBLE_PRECISION, to,tag, MPI_COMM_WORLD ); }else if (rank == dest) { tag = MPI_ANY_TAG; count = 10; from = MPI_ANY_SOURCE; MPI_Recv( data, count, MPI_DOUBLE_PRECISION, from,tag, MPI_COMM_WORLD, &status ); printf( %d received ,rank); for (i=0;i<10;i++) printf ( %10.5f ,data[i]); printf( \n ); } MPI_Finalize(); return 0; }")
13
Proces wysyłający: źródło wysyła wiadomość do procesu przyjmującego: celu. Oba procesy muszą się znajdować w obrębie komunikatora zaspecyfikowanego w instrukcji wysyłania i przyjmowania. Proces celowy jest identyfikowany poprzez jego rząd. Wiadomości są przyjmowane w kolejności, w jakiej zostały wysłane. Charakterystyka komunikacji punktowej

14
Rodzaje komunikacji punktowej (dotyczą i nadawcy i odbiorcy) Komunikacja wstrzymująca (blocking communication) – powrót z funkcji wysyłanie/odbieranie następuje po zakończeniu operacji, tj. funkcja czeka na wynik swego działania. Komunikacja niewstrzymująca (nonblocking communication) – powrót z funkcji wysyłanie/odbieranie następuje natychmiast, tj. funkcja nie czeka na wynik swego działania.
 – powrót z funkcji wysyłanie/odbieranie następuje natychmiast, tj. funkcja nie czeka na wynik swego działania..")
15
Tryby komunikacji puntowej (dotyczą jedynie nadawcy) 1.Standardowy (Standard) wysyłanie nie jest zsynchronizowane z odbiorem; nie zakłada się buforowania wiadomości przez MPI. 2.Synchroniczny (Synchronous) proces wysyłający czeka aż wiadomość zostanie odebrana. 3.Buforowany (Buffered) buforowanie wiadomości jest kontrolowane przez programistę. 4.Gotowości (Ready) przy wysyłaniu zakłada się, że proces odbierający już zainicjował procedurę odbioru wiadomości.
 proces wysyłający czeka aż wiadomość zostanie odebrana. 3.Buforowany (Buffered) buforowanie wiadomości jest kontrolowane przez programistę. 4.Gotowości (Ready) przy wysyłaniu zakłada się, że proces odbierający już zainicjował procedurę odbioru wiadomości..")
16
Prototypy procedur obsługi komunikacji punktowej Podstawowe: MPI_Send – wysyłanie; MPI_Recv – odbiór. Bardziej zaawansowane ale ułatwiające życie: MPI_Wait – oczekiwanie na zakończenie wysyłania/odbioru; MPI_Test – sprawdzanie zakończenia wysyłania/odbioru; MPI_Probe – sprawdzanie rozmiaru i innych cech wiadomości bez jej odbierania. Bardzo zaawansowane, ważne przy optymalizacji komunikacji: MPI_Send_init – otwarcie „gorącej linii”; MPI_Start – rozpoczęcie przesyłania przez „gorącą linię”.

17
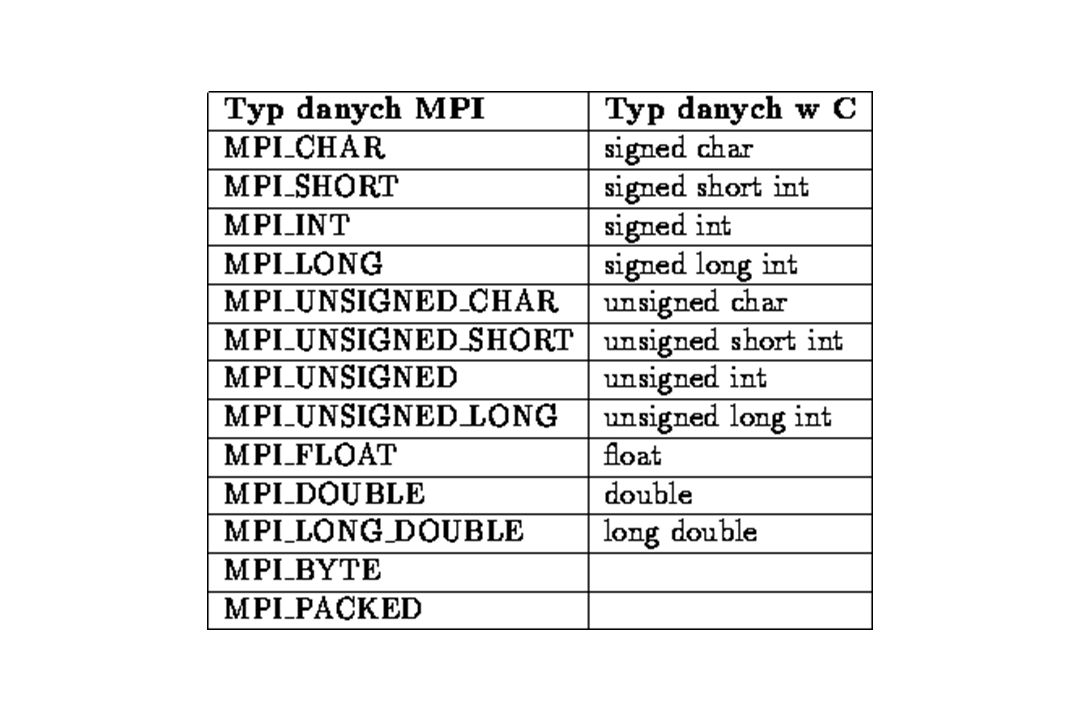
Standardowa procedura wysyłania MPI_SendMPI_Send( buf, count, datatype, dest, tag, comm ) buf - zmienna zawierająca wysyłane dane count - liczba wysyłanych danych datatype - typ wysyłanych danych (patrz niżej) dest - rząd (numer) procesu celowego tag - identyfikator („pieczątka”) wiadomości comm – komunikator C: int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) Fortran: MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
 buf - zmienna zawierająca wysyłane dane count - liczba wysyłanych danych datatype - typ wysyłanych danych (patrz niżej) dest - rząd (numer) procesu celowego tag - identyfikator („pieczątka ) wiadomości comm – komunikator C: int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) Fortran: MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR")
18
Standardowa procedura odbioru MPI_RecvMPI_Recv( buf, count, datatype, source, tag, comm, status ) buf - zmienna, do której przychodzą przyjmowane dane count - liczba elementów przychodzących danych datatype - typ przychodzących danych source - rząd (numer) procesora, który wysłał wiadomość tag - identyfikator wiadomości (jeżeli jest zaspecyfikowany explicite, zostanie odebrana wiadomość posiadająca ten właśnie identyfikator) comm - komunikator status - tablica o rozmiarze MPI_STATUS_SIZE zawierająca informacje o przychodzącej wiadomości
 buf - zmienna, do której przychodzą przyjmowane dane count - liczba elementów przychodzących danych datatype - typ przychodzących danych source - rząd (numer) procesora, który wysłał wiadomość tag - identyfikator wiadomości (jeżeli jest zaspecyfikowany explicite, zostanie odebrana wiadomość posiadająca ten właśnie identyfikator) comm - komunikator status - tablica o rozmiarze MPI_STATUS_SIZE zawierająca informacje o przychodzącej wiadomości")
19
C: int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) Fortran: MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR) BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR
 Fortran: MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR) BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR")
20
Identyfikatory pełniące rolę „gwiazdek”: MPI_ANY_SOURCE – jakikolwiek proces; MPI_ANY_TAG – jakakolwiek pieczątka.

23
status(MPI_TAG) – pieczątka odbieranej wiadomości status(MPI_SOURCE) – rząd procesu wysyłającego Informacja o rozmiarze odbieranej wiadomości: MPI_GET_COUNT(status, datatype, count) datatype – typ danych zawartych w odbieranej wiadomości count – rozmiar odbieranej wiadomości C: int MPI_Get_count(MPI_Status status, MPI_Datatype datatype, int *count) Fortran: MPI_GET_COUNT(STATUS, DATATYPE, COUNT, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR Uzyskiwanie informacji o odbieranej wiadomości z tablicy status
 – pieczątka odbieranej wiadomości status(MPI_SOURCE) – rząd procesu wysyłającego Informacja o rozmiarze odbieranej wiadomości: MPI_GET_COUNT(status, datatype, count) datatype – typ danych zawartych w odbieranej wiadomości count – rozmiar odbieranej wiadomości C: int MPI_Get_count(MPI_Status status, MPI_Datatype datatype, int *count) Fortran: MPI_GET_COUNT(STATUS, DATATYPE, COUNT, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR Uzyskiwanie informacji o odbieranej wiadomości z tablicy status")
24
Przykład: obliczanie drugich pochodnych funkcji jednej zmiennej metodą ilorazów różnicowych

25
integer i,n double precision pi parameter(pi=3.1415, n=100) double precision x(n),dx,xx(n) dx=2*pi/n do i=1,n x(i)=cos(i*dx) enddo do i=2,n-1 xx(i)=(x(i-1)-2*x(i)+x(i+1))/(dx*dx) enddo xx(1)=(x(n)-2*x(1)+x(2))/(dx*dx) xx(n)=(x(n-1)-2*x(n)+x(1))/(dx*dx) do i=1,n print *,i*dx,x(i),xx(i) enddo stop end f(x) = cos(x) Przedział [0,2 ] dzielimy na n części. Przy obliczaniu ilorazów różnicowych odpowiadających punktom z końców przedziału korzystamy z okresowości funkcji cosinus. Kod szeregowy (Fortran 77) Kolor czerwony: funkcja; kolor zielony: druga pochodna
![integer i,n double precision pi parameter(pi=3.1415, n=100) double precision x(n),dx,xx(n) dx=2*pi/n do i=1,n x(i)=cos(i*dx) enddo do i=2,n-1 xx(i)=(x(i-1)-2*x(i)+x(i+1))/(dx*dx) enddo xx(1)=(x(n)-2*x(1)+x(2))/(dx*dx) xx(n)=(x(n-1)-2*x(n)+x(1))/(dx*dx) do i=1,n print *,i*dx,x(i),xx(i) enddo stop end f(x) = cos(x) Przedział [0,2 ] dzielimy na n części.](http://images.slideplayer.pl/15/4792233/slides/slide_25.jpg "Przy obliczaniu ilorazów różnicowych odpowiadających punktom z końców przedziału korzystamy z okresowości funkcji cosinus. Kod szeregowy (Fortran 77) Kolor czerwony: funkcja; kolor zielony: druga pochodna.")
26
Podział punktów siatki pomiędzy procesory oraz zaplanowanie komunikacji Każdy procesor dostaje do obliczenia wartości funkcji w m kolejnych punktach; całkowita liczba punktów wynosi m*nproc. Każdy procesor oblicza wartości ilorazów różnicowych w przypisanych sobie punktach; do obliczenia ilorazu w punkcie pierwszym pobiera wartość funkcji od lewego sąsiada a do obliczenia ilorazu w punkcie ostatnim od prawego sąsiada; analogicznie wysyła swoim sąsiadom wymagane przez nich dane. Lewym sąsiadem procesora pierwszego jest procesor ostatni a prawym sąsiadem ostatniego pierwszy (periodyczność). Każdy procesor wykonuje sumarycznie dwie operacje wysyłania i dwie odbioru.
. Każdy procesor wykonuje sumarycznie dwie operacje wysyłania i dwie odbioru..")
27
include 'mpif.h' integer ierr,rank,size,req(4),stat(MPI_STATUS_SIZE) integer i,n double precision pi parameter(pi=3.1415, n=10) double precision x(n),dx,y(n),right,left call MPI_INIT( ierr ) call MPI_COMM_RANK( MPI_COMM_WORLD, rank, ierr ) call MPI_COMM_SIZE( MPI_COMM_WORLD, size, ierr ) dx=2*pi/(n*size) do i=1,n x(i)=cos(n*dx*rank+i*dx) enddo iright=mod(size+rank+1,size) ileft=mod(size+rank-1,size) call MPI_SEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_SEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) do i=2,n-1 y(i)=(x(i-1)-2*x(i)+x(i+1))/(dx*dx) enddo y(1)=(left-2*x(1)+x(2))/(dx*dx) y(n)=(x(n-1)-2*x(n)+right)/(dx*dx) do i=1,n print *,rank,n*dx*rank+i*dx,x(i),y(i) enddo call MPI_FINALIZE(ierr) stop end Pierwsza wersja kodu równoległego – prosta ale nie spełnia wymogów bezpieczeństwa
,stat(MPI_STATUS_SIZE) integer i,n double precision pi parameter(pi=3.1415, n=10) double precision x(n),dx,y(n),right,left call MPI_INIT( ierr ) call MPI_COMM_RANK( MPI_COMM_WORLD, rank, ierr ) call MPI_COMM_SIZE( MPI_COMM_WORLD, size, ierr ) dx=2*pi/(n*size) do i=1,n x(i)=cos(n*dx*rank+i*dx) enddo iright=mod(size+rank+1,size) ileft=mod(size+rank-1,size) call MPI_SEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_SEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) do i=2,n-1 y(i)=(x(i-1)-2*x(i)+x(i+1))/(dx*dx) enddo y(1)=(left-2*x(1)+x(2))/(dx*dx) y(n)=(x(n-1)-2*x(n)+right)/(dx*dx) do i=1,n print *,rank,n*dx*rank+i*dx,x(i),y(i) enddo call MPI_FINALIZE(ierr) stop end Pierwsza wersja kodu równoległego – prosta ale nie spełnia wymogów bezpieczeństwa")
28
call MPI_SEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) Wersja bardziej bezpieczna – odpowiednia kolejność wysyłania i odbioru Wersja niedziałająca (deadlock) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_SEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr)
,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) Wersja bardziej bezpieczna – odpowiednia kolejność wysyłania i odbioru Wersja niedziałająca (deadlock) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_SEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr)")
29
W sytuacjach takich jak w powyższym przykładzie dla uproszczenia kodu warto zastosować funkcję MPI_Sendrecv łączącą operacje wysyłania i odbioru MPI_SENDRECV(sendbuf, sendcount, sendtype, dest, sendtag, recvbuf, recvcount, recvtype, source, recvtag, comm, status) sendbuf – początkowy adres bufora wysyłanych danych; sendcount – liczba elementów wysyłanych danych; sendtype – typ danych wysyłanych; dest – rząd procesu celowego; sendtag – pieczątka wysyłanej wiadomości; recvbuf – początkowy adres bufora odbieranej wiadomości; recvcount – liczba elementów odbieranych danych; recvtype – typ odbieranych danych; source – rząd procesu wysyłającego; recvtag - pieczątka odbieranej wiadomości; comm – komunikator; status – status odebranej wiadomości.
 sendbuf – początkowy adres bufora wysyłanych danych; sendcount – liczba elementów wysyłanych danych; sendtype – typ danych wysyłanych; dest – rząd procesu celowego; sendtag – pieczątka wysyłanej wiadomości; recvbuf – początkowy adres bufora odbieranej wiadomości; recvcount – liczba elementów odbieranych danych; recvtype – typ odbieranych danych; source – rząd procesu wysyłającego; recvtag - pieczątka odbieranej wiadomości; comm – komunikator; status – status odebranej wiadomości.")
30
C: int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, MPI_Datatype recvtag, MPI_Comm comm, MPI_Status *status) Fortran: MPI_SENDRECV(SENDBUF, SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVBUF, RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, STATUS, IERROR) SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR
 Fortran: MPI_SENDRECV(SENDBUF, SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVBUF, RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, STATUS, IERROR) SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR")
31
call MPI_SENDRECV(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, left,1,MPI_DOUBLE_PRECISION, ileft,1, & MPI_COMM_WORLD, stat, ierr) call MPI_SENDRECV(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 2, right,1,MPI_DOUBLE_PRECISION, iright,2, & MPI_COMM_WORLD, stat, ierr) call MPI_SENDRECV(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, left,1,MPI_DOUBLE_PRECISION, ileft,1, & MPI_COMM_WORLD, stat, ierr) call MPI_SENDRECV(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, right,1,MPI_DOUBLE_PRECISION, iright,1, & MPI_COMM_WORLD, stat, ierr) Prawidłowy kod wykorzystujący MPI_Sendrecv (wysyłamy do innego procesu niż ten, od którego odbieramy) Nieprawidłowy kod wykorzystujący MPI_Sendrecv prowadzący do zablokowania (wysyłamy do tego samego procesu co ten, od którego odbieramy)
,1,MPI_DOUBLE_PRECISION, iright, & 1, left,1,MPI_DOUBLE_PRECISION, ileft,1, & MPI_COMM_WORLD, stat, ierr) call MPI_SENDRECV(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 2, right,1,MPI_DOUBLE_PRECISION, iright,2, & MPI_COMM_WORLD, stat, ierr) call MPI_SENDRECV(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, left,1,MPI_DOUBLE_PRECISION, ileft,1, & MPI_COMM_WORLD, stat, ierr) call MPI_SENDRECV(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, right,1,MPI_DOUBLE_PRECISION, iright,1, & MPI_COMM_WORLD, stat, ierr) Prawidłowy kod wykorzystujący MPI_Sendrecv (wysyłamy do innego procesu niż ten, od którego odbieramy) Nieprawidłowy kod wykorzystujący MPI_Sendrecv prowadzący do zablokowania (wysyłamy do tego samego procesu co ten, od którego odbieramy)")
32
Zaawansowane zagadnienia komunikacji punktowej

33
MPI_ISEND(buf, count, datatype, dest, tag, comm, request) buf, count, datatype, dest, tag, comm – jak dla wysyłania wstrzymującego request – zmienna mówiąca o stanie zakończenia operacji wysyłania Niewstrzymujące wysyłanie wiadomości C: int MPI_Isend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) Fortran 77: MPI_ISEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST,IERROR) BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
 buf, count, datatype, dest, tag, comm – jak dla wysyłania wstrzymującego request – zmienna mówiąca o stanie zakończenia operacji wysyłania Niewstrzymujące wysyłanie wiadomości C: int MPI_Isend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) Fortran 77: MPI_ISEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST,IERROR) BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR")
34
Niewstrzymujące odbieranie wiadomości MPI_IRECV (buf, count, datatype, source, tag, comm, request) C: int MPI_Irecv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request) Fortran: MPI_IRECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR) BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR
 C: int MPI_Irecv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request) Fortran: MPI_IRECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR) BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR")
35
Funkcje stowarzyszone z funkcjami niewstrzymującego wysyłania/odbioru MPI_WAIT(request, status) – oczekiwanie na zakończenie wysyłania/odbioru zadanego przez request; MPI_WAITANY (count, array_of_requests, index, status) – oczekiwanie na zakończenie któregokolwiek z procesów wysyłania/odbioru zadanych w tablicy array_of_requests, status pierwszego zakończonego procesu jest w zmiennej status; MPI_WAITSOME(incount, array_of_requests, outcount, array_of_indices, array_of_statuses) – oczekiwanie na zakończenie któregokolwiek z procesów wysyłania/odbioru zadanych w tablicy array_of_requests, statusy zakończonych procesów są zebrane w tablicy array_of_statuses; MPI_WAITALL( count, array_of_requests, array_of_statuses) – oczekiwanie na zakończenie wszystkich procesów wysyłania/odbioru zadanych w tablicy array_of_requests.
 – oczekiwanie na zakończenie wysyłania/odbioru zadanego przez request; MPI_WAITANY (count, array_of_requests, index, status) – oczekiwanie na zakończenie któregokolwiek z procesów wysyłania/odbioru zadanych w tablicy array_of_requests, status pierwszego zakończonego procesu jest w zmiennej status; MPI_WAITSOME(incount, array_of_requests, outcount, array_of_indices, array_of_statuses) – oczekiwanie na zakończenie któregokolwiek z procesów wysyłania/odbioru zadanych w tablicy array_of_requests, statusy zakończonych procesów są zebrane w tablicy array_of_statuses; MPI_WAITALL( count, array_of_requests, array_of_statuses) – oczekiwanie na zakończenie wszystkich procesów wysyłania/odbioru zadanych w tablicy array_of_requests.")
36
MPI_TEST(request, flag, status) – sprawdzanie stanu wykonania operacji wysyłania/odbioru danej przez request; MPI_TESTANY(count, array_of_requests, index, flag, status) MPI_TESTALL(count, array_of_requests, flag, array_of_statuses) MPI_PROBE(source, tag, comm, status) – sprawdzenie stanu operacji wysłania/odbioru pochodzącej od procesora source o pieczątce tag; MPI_IPROBE(source, tag, comm, flag, status) – jak wyżej tylko niewstrzymująca.
 – sprawdzanie stanu wykonania operacji wysyłania/odbioru danej przez request; MPI_TESTANY(count, array_of_requests, index, flag, status) MPI_TESTALL(count, array_of_requests, flag, array_of_statuses) MPI_PROBE(source, tag, comm, status) – sprawdzenie stanu operacji wysłania/odbioru pochodzącej od procesora source o pieczątce tag; MPI_IPROBE(source, tag, comm, flag, status) – jak wyżej tylko niewstrzymująca.")
37
integer ierr,rank,size,req(4),stat(MPI_STATUS_SIZE) iright=mod(size+rank+1,size) ileft=mod(size+rank-1,size) call MPI_IRECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, req(1), ierr) call MPI_IRECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, req(2), ierr) call MPI_ISEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, req(3), ierr) call MPI_ISEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, req(4), ierr) do i=2,n-1 y(i)=(x(i-1)-2*x(i)+x(i+1))/(dx*dx) enddo call MPI_WAITALL(2,req,stat,ierr)
,stat(MPI_STATUS_SIZE) iright=mod(size+rank+1,size) ileft=mod(size+rank-1,size) call MPI_IRECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, req(1), ierr) call MPI_IRECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, req(2), ierr) call MPI_ISEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, req(3), ierr) call MPI_ISEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, req(4), ierr) do i=2,n-1 y(i)=(x(i-1)-2*x(i)+x(i+1))/(dx*dx) enddo call MPI_WAITALL(2,req,stat,ierr)")
38
Kolejność odbieranych wiadomości Zgodność typów przysyłanych danych –MPI_BYTE też musi być zgodny u nadawcy i odbiorcy –wyjątek MPI_PACKED –automatyczna konwersja w środowisku heterogenicznym, ale nie zdefiniowana pomiędzy językami np. C-Fortran Zgodność identyfikatorów –tag= 0...MPI_TAG_UB>=32767 Wielkość odbieranej wiadomości nie musi być zgodna z rozmiarem bufora odbiorcy (błąd w przypadku przepełnienia); MPI_PROBE pozwala sprawdzić wielkośćwiadomości bez jej odbierania
; MPI_PROBE pozwala sprawdzić wielkośćwiadomości bez jej odbierania.")
39
Poprawny kod CALL MPI_COMM_RANK(comm, rank, ierr) IF(rank.EQ.0) THEN CALL MPI_SEND(a(1), 10, MPI_REAL, 1, tag, comm, ierr) ELSE CALL MPI_RECV(b(1), 15, MPI_REAL, 0, tag, comm, status, ierr) END IF Błędny kod CALL MPI_COMM_RANK(comm, rank, ierr) IF(rank.EQ.0) THEN CALL MPI_SEND(a(1), 10, MPI_REAL, 1, tag, comm, ierr) ELSE CALL MPI_RECV(b(1), 40, MPI_BYTE, 0, tag, comm, status, ierr) END IF
 IF(rank.EQ.0) THEN CALL MPI_SEND(a(1), 10, MPI_REAL, 1, tag, comm, ierr) ELSE CALL MPI_RECV(b(1), 15, MPI_REAL, 0, tag, comm, status, ierr) END IF Błędny kod CALL MPI_COMM_RANK(comm, rank, ierr) IF(rank.EQ.0) THEN CALL MPI_SEND(a(1), 10, MPI_REAL, 1, tag, comm, ierr) ELSE CALL MPI_RECV(b(1), 40, MPI_BYTE, 0, tag, comm, status, ierr) END IF")
40
MPI_PACK i MPI_UNPACK Funkcja MPI_PACK umieszcza dane różnych typów w buforze zdefiniowanym przez użytkownika który pózniej można przesłać korzystając z typu MPI_PACKED Wiadomość o dowolnym typie można wysłać/odebrać korzystając z typu MPI_PACKED Funkcja MPI_UNPACK umieszcza odebrane dane typu MPI_PACKED w zmiennej określonego typu

41
MPI_PACK(inbuf, incount, datatype, outbuf, outsize, position, comm) [ IN inbuf] zmienna zawierając dane wejściowe [ IN incount] ilość danych wejsciowych [ IN datatype] typ danych wejściowych [ OUT outbuf] bufor danych [ IN outsize] rozmiar bufora danych w bajtach [ INOUT position] bierząca pozycja w buforze w bajtach [ IN comm] komunikator int MPI_Pack(void* inbuf, int incount, MPI_Datatype datatype, void *outbuf, int outsize, int *position, MPI_Comm comm) MPI_PACK(INBUF, INCOUNT, DATATYPE, OUTBUF, OUTSIZE, POSITION, COMM, IERROR) INBUF(*), OUTBUF(*) INTEGER INCOUNT, DATATYPE, OUTSIZE, POSITION, COMM, IERROR
![MPI_PACK(inbuf, incount, datatype, outbuf, outsize, position, comm) [ IN inbuf] zmienna zawierając dane wejściowe [ IN incount] ilość danych wejsciowych [ IN datatype] typ danych wejściowych [ OUT outbuf] bufor danych [ IN outsize] rozmiar bufora danych w bajtach [ INOUT position] bierząca pozycja w buforze w bajtach [ IN comm] komunikator int MPI_Pack(void* inbuf, int incount, MPI_Datatype datatype, void *outbuf, int outsize, int *position, MPI_Comm comm) MPI_PACK(INBUF, INCOUNT, DATATYPE, OUTBUF, OUTSIZE, POSITION, COMM, IERROR) INBUF(*), OUTBUF(*) INTEGER INCOUNT, DATATYPE, OUTSIZE, POSITION, COMM, IERROR](http://images.slideplayer.pl/15/4792233/slides/slide_41.jpg "MPI_PACK(inbuf, incount, datatype, outbuf, outsize, position, comm) [ IN inbuf] zmienna zawierając dane wejściowe [ IN incount] ilość danych wejsciowych [ IN datatype] typ danych wejściowych [ OUT outbuf] bufor danych [ IN outsize] rozmiar bufora danych w bajtach [ INOUT position] bierząca pozycja w buforze w bajtach [ IN comm] komunikator int MPI_Pack(void* inbuf, int incount, MPI_Datatype datatype, void *outbuf, int outsize, int *position, MPI_Comm comm) MPI_PACK(INBUF, INCOUNT, DATATYPE, OUTBUF, OUTSIZE, POSITION, COMM, IERROR) INBUF(*), OUTBUF(*) INTEGER INCOUNT, DATATYPE, OUTSIZE, POSITION, COMM, IERROR")
42
MPI_UNPACK(inbuf, insize, position, outbuf, outcount, datatype, comm) [ IN inbuf] bufor zawierając dane wejściowe [ IN insize] rozmiar bufora w bajtach [ INOUT position] bierząca pozycja w buforze w bajtach [ OUT outbuf] zmienna dla danych wyjściowych [ IN outcount] ilość danych wyjściowych [ IN datatype] typ danych wyjściowych [ IN comm] komunikator int MPI_Unpack(void* inbuf, int insize, int *position, void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm) MPI_UNPACK(INBUF, INSIZE, POSITION, OUTBUF, OUTCOUNT, DATATYPE, COMM, IERROR) INBUF(*), OUTBUF(*) INTEGER INSIZE, POSITION, OUTCOUNT, DATATYPE, COMM, IERROR
![MPI_UNPACK(inbuf, insize, position, outbuf, outcount, datatype, comm) [ IN inbuf] bufor zawierając dane wejściowe [ IN insize] rozmiar bufora w bajtach [ INOUT position] bierząca pozycja w buforze w bajtach [ OUT outbuf] zmienna dla danych wyjściowych [ IN outcount] ilość danych wyjściowych [ IN datatype] typ danych wyjściowych [ IN comm] komunikator int MPI_Unpack(void* inbuf, int insize, int *position, void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm) MPI_UNPACK(INBUF, INSIZE, POSITION, OUTBUF, OUTCOUNT, DATATYPE, COMM, IERROR) INBUF(*), OUTBUF(*) INTEGER INSIZE, POSITION, OUTCOUNT, DATATYPE, COMM, IERROR](http://images.slideplayer.pl/15/4792233/slides/slide_42.jpg "MPI_UNPACK(inbuf, insize, position, outbuf, outcount, datatype, comm) [ IN inbuf] bufor zawierając dane wejściowe [ IN insize] rozmiar bufora w bajtach [ INOUT position] bierząca pozycja w buforze w bajtach [ OUT outbuf] zmienna dla danych wyjściowych [ IN outcount] ilość danych wyjściowych [ IN datatype] typ danych wyjściowych [ IN comm] komunikator int MPI_Unpack(void* inbuf, int insize, int *position, void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm) MPI_UNPACK(INBUF, INSIZE, POSITION, OUTBUF, OUTCOUNT, DATATYPE, COMM, IERROR) INBUF(*), OUTBUF(*) INTEGER INSIZE, POSITION, OUTCOUNT, DATATYPE, COMM, IERROR")
43
MPI_PACK_SIZE(incount, datatype, comm, size) [ IN incount] ilość danych wejściowych dla MPI_PACK [ IN datatype] typ danych wejściowych [ IN comm] komunikator [ OUT size] potrzebny rozmiar bufora w MPI_PACK w bajtach int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size) MPI_PACK_SIZE(INCOUNT, DATATYPE, COMM, SIZE, IERROR) INTEGER INCOUNT, DATATYPE, COMM, SIZE, IERROR
![MPI_PACK_SIZE(incount, datatype, comm, size) [ IN incount] ilość danych wejściowych dla MPI_PACK [ IN datatype] typ danych wejściowych [ IN comm] komunikator [ OUT size] potrzebny rozmiar bufora w MPI_PACK w bajtach int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size) MPI_PACK_SIZE(INCOUNT, DATATYPE, COMM, SIZE, IERROR) INTEGER INCOUNT, DATATYPE, COMM, SIZE, IERROR](http://images.slideplayer.pl/15/4792233/slides/slide_43.jpg "MPI_PACK_SIZE(incount, datatype, comm, size) [ IN incount] ilość danych wejściowych dla MPI_PACK [ IN datatype] typ danych wejściowych [ IN comm] komunikator [ OUT size] potrzebny rozmiar bufora w MPI_PACK w bajtach int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size) MPI_PACK_SIZE(INCOUNT, DATATYPE, COMM, SIZE, IERROR) INTEGER INCOUNT, DATATYPE, COMM, SIZE, IERROR")
44
int position, i, j, a[2]; char buff[1000];.... MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if (myrank == 0) { / * SENDER CODE */ position = 0; MPI_Pack(&i,1,MPI_INT,buff,1000,&position,MPI_COMM_WORLD); MPI_Pack(&j,1,MPI_INT,buff,1000,&position,MPI_COMM_WORLD); MPI_Send(buff, position, MPI_PACKED, 1, 0, MPI_COMM_WORLD); } else /* RECEIVER CODE */ MPI_Recv( a, 2, MPI_INT, 0, 0, MPI_COMM_WORLD) }
![int position, i, j, a[2]; char buff[1000];....](http://images.slideplayer.pl/15/4792233/slides/slide_44.jpg "MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if (myrank == 0) { / * SENDER CODE */ position = 0; MPI_Pack(&i,1,MPI_INT,buff,1000,&position,MPI_COMM_WORLD); MPI_Pack(&j,1,MPI_INT,buff,1000,&position,MPI_COMM_WORLD); MPI_Send(buff, position, MPI_PACKED, 1, 0, MPI_COMM_WORLD); } else /* RECEIVER CODE */ MPI_Recv( a, 2, MPI_INT, 0, 0, MPI_COMM_WORLD) }.")
45
● Działanie funkcji biblioteki MPI jest zdefiniowane przez specyfikację MPI Standard 1.1 i 2.0 a nie przez konkretną implementację ● Implementacje mogą się różnić w szczegółach nie zdefiniowanych przez MPI Standard, co pozwala na dostosowanie implementacji do sprzętu (np. MPICHG2 jest dostosowany do pracy w rozproszonym środowisku GRID) ● Nie należy korzystać z cech obecnych jedynie w konkretnej implementacji przy tworzeniu przenośnych kodów równoległych
 ● Nie należy korzystać z cech obecnych jedynie w konkretnej implementacji przy tworzeniu przenośnych kodów równoległych.")
46
Tryb standardowy Specyfikacja nie definiuje czy komunikacja bedzie buforowana czy nie Charakter nielokalny - zakończenie może zależeć od odbiorcy Większość implementacji zapewnia buforowanie w zależności od rozmiaru wiadomości Przenośne programy nie powinny bazować na buforowaniu w trybie standardowym

47
Tryb buforowany Bufor u nadawacy jest definiowany przez programistę MPI_BUFFER_ATTACH Charakter lokalny - zakończenie zależy jedynie od odbiorcy Może doprowadzić do podwójnego buforowania i związanych z tym dodatkowych operacji dostępu do pamięci MPI_PACK_SIZE + MPI_BSEND_OVERHEAD

48
MPI_BUFFER_ATTACH( buffer, size) [ IN buffer] początkowy adres bufora [ IN size] rozmiar bufora w bajtach int MPI_Buffer_attach( void* buffer, int size) MPI_BUFFER_ATTACH( BUFFER, SIZE, IERROR) BUFFER(*) INTEGER SIZE, IERROR MPI_BUFFER_DETACH( buffer_addr, size) [ OUT buffer_addr] początkowy adres bufora [ OUT size] rozmiar bufora w bajtach int MPI_Buffer_detach( void* buffer_addr, int* size) MPI_BUFFER_DETACH( BUFFER_ADDR, SIZE, IERROR) BUFFER_ADDR(*) INTEGER SIZE, IERROR
![MPI_BUFFER_ATTACH( buffer, size) [ IN buffer] początkowy adres bufora [ IN size] rozmiar bufora w bajtach int MPI_Buffer_attach( void* buffer, int size) MPI_BUFFER_ATTACH( BUFFER, SIZE, IERROR) BUFFER(*) INTEGER SIZE, IERROR MPI_BUFFER_DETACH( buffer_addr, size) [ OUT buffer_addr] początkowy adres bufora [ OUT size] rozmiar bufora w bajtach int MPI_Buffer_detach( void* buffer_addr, int* size) MPI_BUFFER_DETACH( BUFFER_ADDR, SIZE, IERROR) BUFFER_ADDR(*) INTEGER SIZE, IERROR](http://images.slideplayer.pl/15/4792233/slides/slide_48.jpg "MPI_BUFFER_ATTACH( buffer, size) [ IN buffer] początkowy adres bufora [ IN size] rozmiar bufora w bajtach int MPI_Buffer_attach( void* buffer, int size) MPI_BUFFER_ATTACH( BUFFER, SIZE, IERROR) BUFFER(*) INTEGER SIZE, IERROR MPI_BUFFER_DETACH( buffer_addr, size) [ OUT buffer_addr] początkowy adres bufora [ OUT size] rozmiar bufora w bajtach int MPI_Buffer_detach( void* buffer_addr, int* size) MPI_BUFFER_DETACH( BUFFER_ADDR, SIZE, IERROR) BUFFER_ADDR(*) INTEGER SIZE, IERROR")
49
Tryb synchroniczny Brak buforowania u nadawacy Charakter nielokalny - zakończenie zależy zawsze od odbiorcy Zakończenie działania u nadawcy gwarantuje że odbiorca rozpoczął przyjmowanie wiadomości W przypadku komunikacji blokującej u nadawcy i odbiorcy zapewnia pełną synchronizację komunikacji

50
Tryb gotowości Może się rozpocząć tylko jeśli odbiorca już czeka na wiadomość, w innym przypadku zachowanie jest nie zdefiniowane przez specyfikację Charakter lokalny - zakończenie operacji nie gwarantuje ze wiadomość jest odebrana Pozwala zaoszczędzić część operacji synchronizacji (handshaking) W poprawnym programie zastapienie MPI_Rsend przez MPI_Send nie powinno wpłynąć na efekt działania poza szybkością komunikacji
 W poprawnym programie zastapienie MPI_Rsend przez MPI_Send nie powinno wpłynąć na efekt działania poza szybkością komunikacji")
51
Przykładowa implementacja Tryb gotowości - wysyłanie natychmiastowe Tryb synchroniczny - nadawca wysyła najpierw prośbę o potwierdzenie gotowości odbiorcy Tryb standardowy - dla małych wiadomości wysyłanie natychmiastowe z buforowaniem na poziomie sprzętu a dla większych jak w trybie synchronicznym Tryb buforowany - skopiowanie wiadomości do bufora i wykonanie wysyłania nieblokującego

52
CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank.EQ.0) THEN CALL MPI_BSEND(buf1, count, MPI_REAL, 1, tag, comm, ierr) CALL MPI_BSEND(buf2, count, MPI_REAL, 1, tag, comm, ierr) ELSE ! rank.EQ.1 CALL MPI_RECV(buf1, count, MPI_REAL, 0, MPI_ANY_TAG, comm, status, ierr) CALL MPI_RECV(buf2, count, MPI_REAL, 0, tag, comm, status, ierr) END IF CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank.EQ.0) THEN CALL MPI_BSEND(buf1, count, MPI_REAL, 1, tag1, comm, ierr) CALL MPI_SSEND(buf2, count, MPI_REAL, 1, tag2, comm, ierr) ELSE ! rank.EQ.1 CALL MPI_RECV(buf1, count, MPI_REAL, 0, tag2, comm, status, ierr) CALL MPI_RECV(buf2, count, MPI_REAL, 0, tag1, comm, status, ierr) END
 CALL MPI_RECV(buf2, count, MPI_REAL, 0, tag, comm, status, ierr) END IF CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank.EQ.0) THEN CALL MPI_BSEND(buf1, count, MPI_REAL, 1, tag1, comm, ierr) CALL MPI_SSEND(buf2, count, MPI_REAL, 1, tag2, comm, ierr) ELSE . rank.EQ.1 CALL MPI_RECV(buf1, count, MPI_REAL, 0, tag2, comm, status, ierr) CALL MPI_RECV(buf2, count, MPI_REAL, 0, tag1, comm, status, ierr) END.")
53
double precision x(n),dx,y(n),right,left,bufor(100)..... call MPI_BUFFER_ATTACH(bufor,100,ierr)..... call MPI_BSEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_BSEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) Wersja bezpieczna – buforowanie danych w MPI_BSEND
..... call MPI_BSEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_BSEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) Wersja bezpieczna – buforowanie danych w MPI_BSEND.")
54
call MPI_SSEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SSEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) Wersja bardziej bezpieczna – odpowiednia kolejność wysyłania i odbioru lecz nie zadziała w trybie synchronicznym (deadlock)
,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SSEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) Wersja bardziej bezpieczna – odpowiednia kolejność wysyłania i odbioru lecz nie zadziała w trybie synchronicznym (deadlock)")
55
if (mod(rank,2).eq.0) then call MPI_SSEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SSEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) else call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SSEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SSEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) endif
.eq.0) then call MPI_SSEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SSEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) else call MPI_RECV(left,1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SSEND(x(n),1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, ierr) call MPI_RECV(right,1,MPI_DOUBLE_PRECISION, iright, & 1, MPI_COMM_WORLD, stat, ierr) call MPI_SSEND(x(1),1,MPI_DOUBLE_PRECISION, ileft, & 1, MPI_COMM_WORLD, ierr) endif")
56
Tryb gotowości

57
Gorąca linia (persistent communication) Pozwala na dodatkową optymalizację przesyłania danych jeśli lista argumentów jest taka sama Rozdzielenie inicjalizacji gorącej linii (funkcja MPI_SEND_INIT i MPI_RECV_INIT) od samego przesyłania danych MPI_START Wyłączenie gorącej linii (MPI_REQUEST_FREE) jest możliwe po zakończeniu komunikacji Możliwe jest użycie różnych trybów komunikacji Gorąca może współpracować ze zwyczajnymi instrukcjami komunikacji punktowej
 Pozwala na dodatkową optymalizację przesyłania danych jeśli lista argumentów jest taka sama Rozdzielenie inicjalizacji gorącej linii (funkcja MPI_SEND_INIT i MPI_RECV_INIT) od samego przesyłania danych MPI_START Wyłączenie gorącej linii (MPI_REQUEST_FREE) jest możliwe po zakończeniu komunikacji Możliwe jest użycie różnych trybów komunikacji Gorąca może współpracować ze zwyczajnymi instrukcjami komunikacji punktowej")
58
MPI_SEND_INIT(buf, count, datatype, dest, tag, comm, request) [ IN buf] zmienna do wysłania [ IN count] ilość elementów do wysłania [ IN datatype] typ elementów [ IN dest] odbiorca [ IN tag] identyfikator wiadomości [ IN comm] komunikator [ OUT request] wskaźnik pozwalający na dowołanie się do tej instrukcji int MPI_Send_init(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) MPI_SEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) BUF(*) INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
![MPI_SEND_INIT(buf, count, datatype, dest, tag, comm, request) [ IN buf] zmienna do wysłania [ IN count] ilość elementów do wysłania [ IN datatype] typ elementów [ IN dest] odbiorca [ IN tag] identyfikator wiadomości [ IN comm] komunikator [ OUT request] wskaźnik pozwalający na dowołanie się do tej instrukcji int MPI_Send_init(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) MPI_SEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) BUF(*) INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR](http://images.slideplayer.pl/15/4792233/slides/slide_58.jpg "MPI_SEND_INIT(buf, count, datatype, dest, tag, comm, request) [ IN buf] zmienna do wysłania [ IN count] ilość elementów do wysłania [ IN datatype] typ elementów [ IN dest] odbiorca [ IN tag] identyfikator wiadomości [ IN comm] komunikator [ OUT request] wskaźnik pozwalający na dowołanie się do tej instrukcji int MPI_Send_init(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) MPI_SEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) BUF(*) INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR")
59
MPI_RECV_INIT( buf, count, datatype, source, tag, comm, request) [ OUT buf] zmienna dla odbieranych danych [ IN count] ilość elementów [ IN datatype] typ danych [ IN source] nadawca [ IN tag] identyfikator wiadomości [ IN comm] komunikator [ OUT request] wskaźnik pozwalający na dowołanie się do tej instrukcji int MPI_Recv_init(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request) MPI_RECV_INIT(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR) BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR
![MPI_RECV_INIT( buf, count, datatype, source, tag, comm, request) [ OUT buf] zmienna dla odbieranych danych [ IN count] ilość elementów [ IN datatype] typ danych [ IN source] nadawca [ IN tag] identyfikator wiadomości [ IN comm] komunikator [ OUT request] wskaźnik pozwalający na dowołanie się do tej instrukcji int MPI_Recv_init(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request) MPI_RECV_INIT(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR) BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR](http://images.slideplayer.pl/15/4792233/slides/slide_59.jpg "MPI_RECV_INIT( buf, count, datatype, source, tag, comm, request) [ OUT buf] zmienna dla odbieranych danych [ IN count] ilość elementów [ IN datatype] typ danych [ IN source] nadawca [ IN tag] identyfikator wiadomości [ IN comm] komunikator [ OUT request] wskaźnik pozwalający na dowołanie się do tej instrukcji int MPI_Recv_init(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request) MPI_RECV_INIT(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR) BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR")
60
MPI_START(request) [ INOUT request] wskaźnik do instrukji inicjalizującej gorąca linię int MPI_Start(MPI_Request *request) MPI_START(REQUEST, IERROR) INTEGER REQUEST, IERROR MPI_STARTALL( count, array_of_requests) [ IN count] wielkość tablicy ze wskaźnikami [ INOUT array_of_requests] tablica ze wskaźnik do instrukji inicjalizującej gorąca linię int MPI_Startall(int count, MPI_Request *array_of_requests) MPI_STARTALL(COUNT, ARRAY_OF_REQUESTS, IERROR) INTEGER COUNT, ARRAY_OF_REQUESTS(*), IERROR
![MPI_START(request) [ INOUT request] wskaźnik do instrukji inicjalizującej gorąca linię int MPI_Start(MPI_Request *request) MPI_START(REQUEST, IERROR) INTEGER REQUEST, IERROR MPI_STARTALL( count, array_of_requests) [ IN count] wielkość tablicy ze wskaźnikami [ INOUT array_of_requests] tablica ze wskaźnik do instrukji inicjalizującej gorąca linię int MPI_Startall(int count, MPI_Request *array_of_requests) MPI_STARTALL(COUNT, ARRAY_OF_REQUESTS, IERROR) INTEGER COUNT, ARRAY_OF_REQUESTS(*), IERROR](http://images.slideplayer.pl/15/4792233/slides/slide_60.jpg "MPI_START(request) [ INOUT request] wskaźnik do instrukji inicjalizującej gorąca linię int MPI_Start(MPI_Request *request) MPI_START(REQUEST, IERROR) INTEGER REQUEST, IERROR MPI_STARTALL( count, array_of_requests) [ IN count] wielkość tablicy ze wskaźnikami [ INOUT array_of_requests] tablica ze wskaźnik do instrukji inicjalizującej gorąca linię int MPI_Startall(int count, MPI_Request *array_of_requests) MPI_STARTALL(COUNT, ARRAY_OF_REQUESTS, IERROR) INTEGER COUNT, ARRAY_OF_REQUESTS(*), IERROR")
Podobne prezentacje