Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Cluster Analysis and Self-Organizing Maps Analiza skupień i metody SOM
Trevor Hastie, Robert Tibshirani Jerome Friedman The Element of Statistical Learning Data Mining, Inference and Prediction Cluster Analysis and Self-Organizing Maps Analiza skupień i metody SOM Marta Leniewska

2
Przykład klasteryzacji

3
Reprezentacja danych x1, …, xN
Macierze podobieństwa D (N×N) Symetryczne, dij 0, dii = 0, Obiekty xi Rp Różnica na atrybucie Atrybut ilościowy: Porządkowy: zamiana na ilościowy Nominalny: macierze podobieństwa L (M×M) między wartościami atrybutu
 Symetryczne, dij 0, dii = 0, Obiekty xi Rp. Różnica na atrybucie. Atrybut ilościowy: Porządkowy: zamiana na ilościowy. Nominalny: macierze podobieństwa L (M×M) między wartościami atrybutu.")
4
Różnice między obiektami
Wpływ atrybutu Xj na (średnia różnica między obiektami) błąd kwadratowy: - estymator Var(Xj) z próby Równe wpływy atrybutów: Wyróżnianie pewnych atrybutów Brakujące wartości atrybutów: pomijanie, wprowadzanie, nowa wartość zmiennej
 błąd kwadratowy: - estymator Var(Xj) z próby. Równe wpływy atrybutów: Wyróżnianie pewnych atrybutów. Brakujące wartości atrybutów: pomijanie, wprowadzanie, nowa wartość zmiennej.")
5
Algorytmy kombinatoryczne
Ustalone z góry K < N klastrów Cel: funkcja k = C(i) minimalizująca rozrzut wewn. = W(C) + B(C) Ilość podziałów N danych na K klastrów Liczba Stirlinga 2 rodz. S(10,4) = S(19,4) 1010 Algorytmy znajdujące lokalne minima
 minimalizująca rozrzut wewn. = W(C) + B(C) Ilość podziałów N danych na K klastrów. Liczba Stirlinga 2 rodz. S(10,4) = S(19,4) Algorytmy znajdujące lokalne minima.")
6
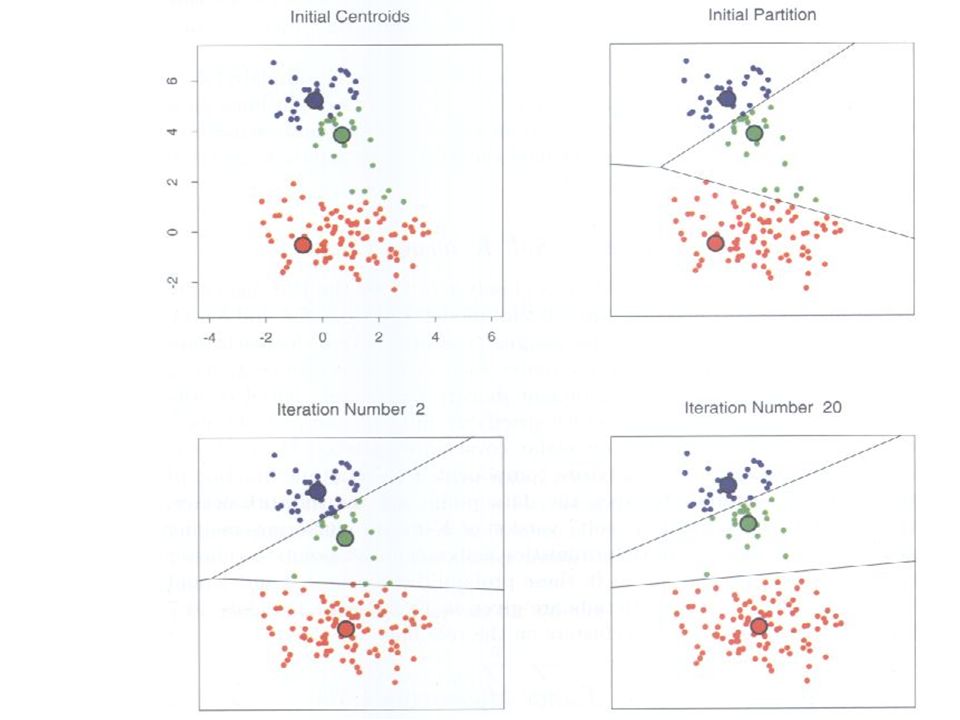
Algorytm K średnich Założenia: atrybuty ilościowe, miara zróżnicowania: kwadrat odległości euklidesowej, Nk – ilość elementów klastra k Kryterium: Znaleźć min centra mk dla wybranych klastrów C (średnie), koszt ~ (ilość elementów klastra) Znaleźć min podział na klastry C Do braku zmian C, zbiega do min lokalnego
, koszt ~ (ilość elementów klastra) Znaleźć min podział na klastry C. Do braku zmian C, zbiega do min lokalnego.")
8
Inne wersje K średnich Wersja probabilistyczna: algorytm EM – dopasowanie do modelu mieszaniny rozkładów Gaussa. Wersja ulepszona: żadna pojedyncza zmiana przypisania obserwacji do klastra nie polepszy wyniku.

9
Zastosowanie – kompresja
Podział na bloki po m pixeli – wektory w Rm Aproksymacja bloków centrami klastrów Obraz skompresowany: log2K na blok + mK czyli log2K/8m oryginału Lepiej przy zastosowaniu teorii Shannona Działa bo wiele bloków wygląda tak samo Miara deformacji obrazu - straty

10
Przykład Sir Ronald A. Fisher (1890-1962) oryginał K = 200, m = 4,
0,239 oryginału, Deformacja: 0,89 K = 4, m = 4, 0,063 oryginału, Deformacja: 16,95

11
Rozmyte K średnich • • • • • •
Rozmyty pseudopodział – rozmyty K podział P = {A1, ..., AK} Przykład N=3, K=2 P = {A1, A2} A1 = 0.6/x1 + 1/x /x3 A2 = 0.4/x1 + 0/x /x3 • 1.0 • 0.8 • 0.6 • 0.4 0.2 • • 0.0 x1 x2 x3

12
Rozmyte K średnich Centrum rozmytego klastra Ai Minimalizacja
v R, v > 1 Minimalizacja wskaźnika Znaleźć centra dla wybranych klastrów P(t-1) Znaleźć podział na klastry P(t) zmiana Ak(xi) Kryterium stopu:
 Znaleźć podział na klastry P(t) zmiana Ak(xi) Kryterium stopu:")
13
C.d. v 1, uogólnienie K średnich v , bardziej rozmyty
xi1 x3 x15 x6 x12 v 1, uogólnienie K średnich v , bardziej rozmyty zbieżny dla każdego v (1, ) Przykład K = 2 v = 1,25 x2 x7 x8 x9 x5 x11 x14 x4 x10 x1 x13 xi2 i A1(xi) A2(xi)
 Przykład. K = 2. v = 1,25. x2. x7. x8. x9. x5. x11. x14. x4. x10. x1. x13. xi2. i. A1(xi) A2(xi)")
14
Algorytm K medoidów Medoid – element centralny
Uogólnienie K średnich na dowolne atrybuty i odległości. Kryterium: Znaleźć min centra xik dla wybranych klastrów C (medoidy) koszt dla klastra ~ (ilość elementów klastra)2 Znaleźć min podział na klastry C
 koszt dla klastra ~ (ilość elementów klastra)2. Znaleźć min podział na klastry C.")
15
Przykład K medoidów 12 krajów K = 3 USA, ISR, FRA, EGY, BEL
ZAI, IND, BRA YUG, USS, CUB, CHI

16
Inna wersja – CLARA Kilka (np. m = 5) próbek liczności 40+2K
Dla każdej próbki – minimalizacja bezp. przez iteracyjne zmiany medoidów (PAM) Koszt iteracji = O(K(N-K)2) Wybór tego z m układów medoidów który jest najlepszy dla wszystkich danych
 Koszt iteracji = O(K(N-K)2) Wybór tego z m układów medoidów który jest najlepszy dla wszystkich danych.")
17
Kwestie praktyczne Wybór K* początkowych centrów Estymacja K*
Podać centra lub indeksy lub koder C Losowo lub krokowo minimalizując kryterium Estymacja K* Rozrzut w klastrach ~ 1/K Rozrzut dla K<K* i dla K>K* K* odpowiada zgięciu wykresu

18
Statystyka Gap 1,5 1,0 0,5 0,0

19
Metody hierarchiczne Nie wymagają K, tylko miary odległości między grupami obserwacji Klastry na poziomie M tworzone przez łączenie klastrów z poziomu M-1 Poziom min: N klastrów {xi}, poziom max: {x1, ..., xN} Strategie aglomeracyjne i dzielące, N poziomów Uporządkowany ciąg poziomów ~ podziałów Wybór poziomu np. statystyka Gap

20
Dendrogram

21
Dendrogram jako opis danych
Ocena reprezentacyjności: wspólczynnik korelacji między dii’ a Cii’ Cii wysokość pierwszego wspólnego klastra N różnych na N(N-1)/2 Cii’ <= {Cik, Ci’k} (trójkąty równoramienne)
/2. Cii’ <= {Cik, Ci’k} (trójkąty równoramienne)")
22
Metody aglomeracyjne Od singletonów, do 1 klastra
Miary odległości między klastrami G i H: Single Linkage – najmniejsza odległość Complete Linkage – największa odległość Group Avarage – średnia odległość

23
GA, CL, SL - dendrogramy

24
Przykład

25
Metody dzielące Gdy chcemy otrzymać mało klastrów
Ciąg podziałów metodą K=2 średnich/medoidów Zależy od początkowej konfiguracji w każdym kroku Nie zawsze otrzymamy własność monotoniczności Albo Obiekt najbardziej odległy od reszty w klastrze G do klastra H Obserwacje bliższe H niż G: najbliższa H do H Klaster do podziału – max średnica, lub średni rozrzut wewnętrzny Do singletonów lub nierozróżnialności w klastrach

26
Hierarchiczne metody rozmyte
Rozmyta relacja równoważności R na X2 R(x,x) = 1 R(x,y) = R(y,x) x,yX x,zX -cut rozmytego zbioru A: A = {x | A(x) } 0,2A = {x1, x2}, 0,4A = {x1} A(x) • 0.4 • 0.2 0.0 x1 x2
 = 1 R(x,y) = R(y,x) x,yX. x,zX. -cut rozmytego zbioru A: A = {x | A(x) } 0,2A = {x1, x2}, 0,4A = {x1} A(x) • 0.4. • x1. x2.")
27
Hierarchiczne metody rozmyte
R to crisp relacja równoważności – pary podobne Znaleźć odpowiednią relację R (lub relację kompatybilności i jej tranzytywne domknięcie) gdzie q > 0, Tranzytywne domknięcie R to RT = R(n-1)
 gdzie q > 0, Tranzytywne domknięcie R to RT = R(n-1)")
28
Przykład dla q=2 xi2 x3 x2 x4 x1 x5 xi1

29
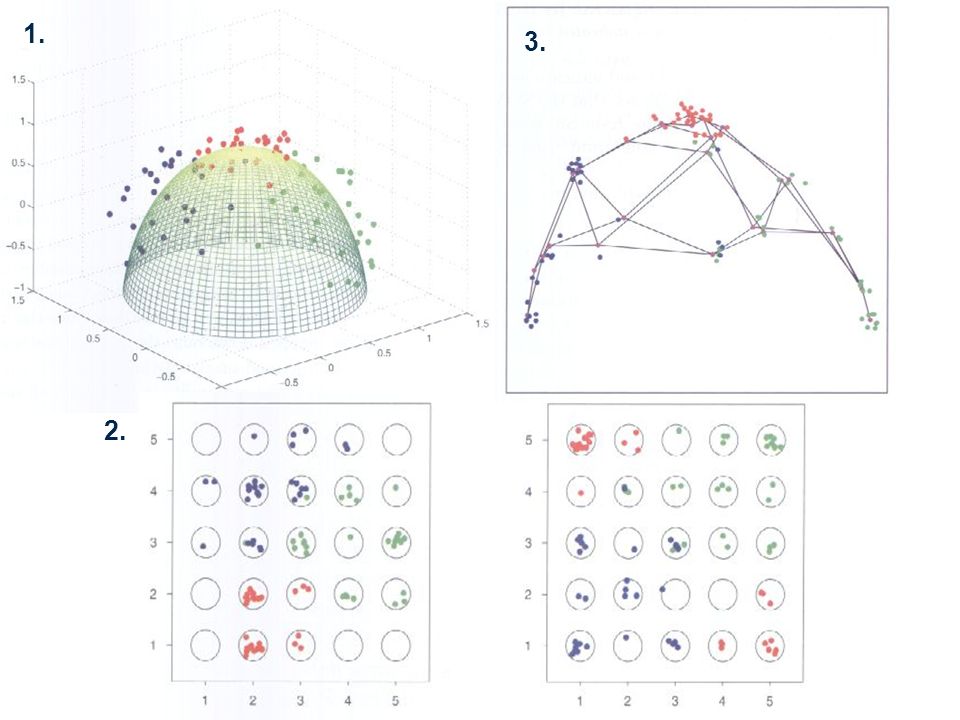
Self-Organizing Maps Wersja K średnich – prototypy na 1 lub 2 wymiarowej rozmaitości w przestrzeni atrybutów, mapowanie obserwacji na rozmaitość Macierz K prototypów mj Rp, o współrzędnych lj R2 Inicjalizacja – np. na płaszczyźnie wyznaczonej metodą głównych składowych Regularne rozmieszczenie prototypów na płaszczyźnie Wyginanie płaszczyzny

30
Algorytm SOM Znajdź mj najbliższy xi w Rp
Przesuń bliskich sąsiadów mj wg. lj do xi Wskaźnik uczenia maleje od 1 do 0 Próg r maleje od R do 1 Albo: przesunięcie zależne od odległości do mj Sąsiedztwo mj zawiera tylko mj K średnich

31
1. 3. 2.
32
SOM aproksymacją K średnich
Porównać błędy rekonstrukcji: Przykład: porównanie z K = 25 średnich

33
Zastosowanie WEBSOM – rzutowanie artykułów z newsgroup wg. tematyki
WEBSOM – rzutowanie artykułów z newsgroup wg. tematyki artykuł jako wektor wystąpień ustalonych terminów opcja zoom

34
Średnica zbioru punktów
• • • • • • • • • • • • • • • • •

35
Średnia zbioru punktów
• • • • • • • •

36
Medoid zbioru punktów • • • • • • • •

37
Odległość międzygrupowa

Podobne prezentacje