Pobierz prezentację
1
GEOSTATYSTYKA I ANALIZA PRZESTRZENNA Wykład dla III roku Geografii specjalność - geoinformacja
Alfred Stach Instytut Geoekologii i Geoinformacji Wydział Nauk Geograficznych i Geologicznych UAM

2
Podstawy krigingu Problem:
Estymacja wartości ciągłej cechy z w dowolnej lokalizacji u z wykorzystaniem jedynie istniejących n danych z na obszarze badań A : {z(ua), a=1, ...., n} Rozwiązanie: Kriging to nazwa własna grupy algorytmów opartych na uogólnionej regresji metodą najmniejszych kwadratów, przyjęta przez geostatystyków dla uhonorowania pionierskich prac południowoafrykańskiego geologa Danie Krige (1951)
, a=1, ...., n} Rozwiązanie: Kriging to nazwa własna grupy algorytmów opartych na uogólnionej regresji metodą najmniejszych kwadratów, przyjęta przez geostatystyków dla uhonorowania pionierskich prac południowoafrykańskiego geologa Danie Krige (1951)")
3
Podstawy krigingu Wszystkie estymatory krigingowe są wariantami podstawowej formuły regresji liniowej zgodnie z poniższym wzorem: gdzie: (u) jest wagą przypisaną do danej z(u), która jest interpretowana jako realizacja Zmiennej Losowej Z(u). Wartości m(u) i m(u) to oczekiwane wartości ZL Z(u) i Z(u).
 jest wagą przypisaną do danej z(u), która jest interpretowana jako realizacja Zmiennej Losowej Z(u). Wartości m(u) i m(u) to oczekiwane wartości ZL Z(u) i Z(u).")
4
Podstawy krigingu Ilość danych używanych do estymacji oraz ich wagi mogą się zmieniać przy kolejnych lokalizacjach. W praktyce używane jest jedynie n(u) danych leżących najbliżej lokalizacji punktu estymacji, to jest dane znajdujące się w określonym sąsiedztwie/oknie W(u) mający swoje centrum w u. Interpretacja nieznanej wartości z(u) i wartosci danych z(u) jako realizacji ZL Z(u) i Z(u) pozwala na zdefiniowanie błędu estymacji jako zmiennej losowej Z*(u) – Z(u). Wszystkie zalety krigingu wynikają z tego samego założenia minimalizacji wariancji (błędu) estymacji przy respektowaniu warunku nieobciążenia estymatora, czyli:
 danych leżących najbliżej lokalizacji punktu estymacji, to jest dane znajdujące się w określonym sąsiedztwie/oknie W(u) mający swoje centrum w u. Interpretacja nieznanej wartości z(u) i wartosci danych z(u) jako realizacji ZL Z(u) i Z(u) pozwala na zdefiniowanie błędu estymacji jako zmiennej losowej Z*(u) – Z(u). Wszystkie zalety krigingu wynikają z tego samego założenia minimalizacji wariancji (błędu) estymacji przy respektowaniu warunku nieobciążenia estymatora, czyli:")
5
Podstawy krigingu jest minimalizowany przy uwzględnieniu ograniczenia, że: Estymacja za pomocą krigingu może się różnić ze względu na przyjęty model Funkcji Losowej Z(u). Przyjmuje się zazwyczaj, że FL Z(u) można rozłożyć na dwa komponenty: trend m(u) i resztę R(u):
. Przyjmuje się zazwyczaj, że FL Z(u) można rozłożyć na dwa komponenty: trend m(u) i resztę R(u):")
6
Podstawy krigingu Składowa resztowa jest modelowana jako stacjonarna FL o średniej równej zero i kowariancji CR(h): Oczekiwana wartość ZL Z w lokalizacji u jest zatem równa wartości składowej trendu w tej lokalizacji:

7
Podstawy krigingu W zależności od przyjętego modelu trendu m(u) możemy wyróżnić trzy warianty krigingu: 1. Prosty kriging (Simple Kriging) zakłada że średnia m(u) jest znana i stała na całym analizowanym obszarze A : 2. Zwykły kriging (Ordinary Kriging) uwzględnia lokalne fluktuacje średniej, ograniczając domenę stacjonarności średniej do lokalnego sąsiedztwa (ruchomego okna) W(u): w przeciwieństwie do SK w tym przypadku średnia jest traktowana jako nieznana.
 zakłada że średnia m(u) jest znana i stała na całym analizowanym obszarze A : 2. Zwykły kriging (Ordinary Kriging) uwzględnia lokalne fluktuacje średniej, ograniczając domenę stacjonarności średniej do lokalnego sąsiedztwa (ruchomego okna) W(u): w przeciwieństwie do SK w tym przypadku średnia jest traktowana jako nieznana.")
8
Czy lokalna średnia jest w przypadku danych satelitarnych ze Spitsbergenu stała?
Próbka losowa, zmienna b3n_03b Próbka losowa, zmienna b1_03b

9
Podstawy krigingu 3. Kriging z trendem (Kriging with a Trend model) zakłada że nieznana lokalna średnia m(u´) zmienia się stopniowo wewnątrz każdego lokalnego sąsiedztwa (okna) W(u), a zatem również w całym obszarze A . Składowa trendu jest modelowana jako liniowa funkcja współrzędnych fk(u): Współczynniki ak(u´) są nieznane, lecz zakłada się, że są one stałe w obrębie każdego lokalnego sąsiedztwa W(u). Przyjęto, że f0(u´) = 1, tak więc przypadek gdzie K = 0 jest odpowiednikiem zwykłego krigingu (stała lecz nieznana średnia a0).
 zakłada że nieznana lokalna średnia m(u´) zmienia się stopniowo wewnątrz każdego lokalnego sąsiedztwa (okna) W(u), a zatem również w całym obszarze A . Składowa trendu jest modelowana jako liniowa funkcja współrzędnych fk(u): Współczynniki ak(u´) są nieznane, lecz zakłada się, że są one stałe w obrębie każdego lokalnego sąsiedztwa W(u). Przyjęto, że f0(u´) = 1, tak więc przypadek gdzie K = 0 jest odpowiednikiem zwykłego krigingu (stała lecz nieznana średnia a0).")
10
Prosty kriging (SK) Modelowanie składowej trendu (-owej) m(u) jako znanej stacjonarnej średniej m pozwala na zapisanie formuły estymatora jako liniowej kombinacji (n(u)+1) danych: n(u) ZL Z(u) i wartości średniej m: n(u) wag jest w taki sposób wyznaczane, aby zminimalizować wariancję błędów uwzględnia-jąc kryterium nieobciążenia estymatora.
 m(u) jako znanej stacjonarnej średniej m pozwala na zapisanie formuły estymatora jako liniowej kombinacji (n(u)+1) danych: n(u) ZL Z(u) i wartości średniej m: n(u) wag jest w taki sposób wyznaczane, aby zminimalizować wariancję błędów uwzględnia-jąc kryterium nieobciążenia estymatora.")
11
Prosty kriging Estymator prostego krigingu (SK) jest z góry nieobciążony ponieważ średni błąd jest równy 0. Używając pierwszej formy zapisu estymatora SK możemy stwierdzić, że: Estymacja metodą prostego krigingu wykonywana jest za pomocą układu n(u) równań liniowych znanych pod nazwą układu zwykłych równań, które można zapisać używając kowariancji zmiennej z w postaci:
 jest z góry nieobciążony ponieważ średni błąd jest równy 0. Używając pierwszej formy zapisu estymatora SK możemy stwierdzić, że: Estymacja metodą prostego krigingu wykonywana jest za pomocą układu n(u) równań liniowych znanych pod nazwą układu zwykłych równań, które można zapisać używając kowariancji zmiennej z w postaci:")
12
Prosty kriging – notacja macierzowa
Wariancja błędu – wariancja SK: Prosty kriging – notacja macierzowa Układ równań SK można również zapisać w postaci macierzowej: Gdzie KSK jest macierzą kowariancji danych o wymiarach n(u) n(u), SK jest wektorem wag SK, a kSK jest wektorem kowariancji dane-do-nieznanej
 n(u), SK jest wektorem wag SK, a kSK jest wektorem kowariancji dane-do-nieznanej.")
13
Prosty kriging – notacja macierzowa

14
Prosty kriging – notacja macierzowa
Wagi krigingowe wymagane do estymacji SK są obliczane przez mnożenie odwrotności macierzy kowariancji danych przez wektor kowariancji dane-do-nieznanej: Odpowiedni zapis macierzowy wariancji krigingowej SK jest następujący:

15
Podstawowe cechy estymatora SK
Prosty kriging System równań SK ma jednoznaczne rozwiązanie i wynikowa wariancja krigingowa jest dodatnia, jeżeli macierz kowariancji KSK = [C(u - u)] jest pozytywnie określona, czyli w praktyce: żadna para danych nie ma takiej samej lokalizacji: u u dla zastosowano dopuszczalny model kowariancji C(h) Podstawowe cechy estymatora SK Jest to estymator wierny – to znaczy, że wartość estymowana w lokalizacji punktu danych jest jemu równa, Jeśli lokalizacja estymacji znajduje się poza zasięgiem autokorelacji w stosunku najbliższego punktu danych wartość estymowana jest równa stacjonarnej średniej m
] jest pozytywnie określona, czyli w praktyce: żadna para danych nie ma takiej samej lokalizacji: u u dla zastosowano dopuszczalny model kowariancji C(h) Podstawowe cechy estymatora SK. Jest to estymator wierny – to znaczy, że wartość estymowana w lokalizacji punktu danych jest jemu równa, Jeśli lokalizacja estymacji znajduje się poza zasięgiem autokorelacji w stosunku najbliższego punktu danych wartość estymowana jest równa stacjonarnej średniej m.")
16
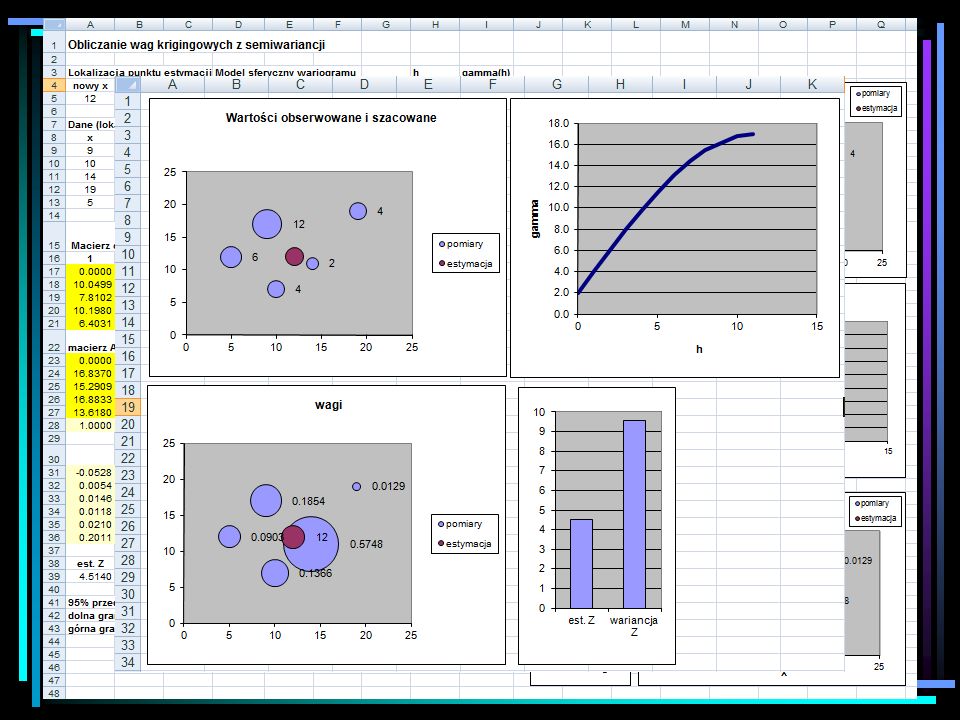
Prosty kriging – przykłady
Estymacja cechy w punkcie 0 za pomocą danych pomiarowych z punktów 1,2 i 3. Korzystając z relacji: C(h) = C(0) - (h)
 = C(0) - (h)")
17
Prosty kriging – przykłady
Prosty kriging dla modelu z zerowym efektem nuggetowym i izotropowym wariogramem sferycznym o trzech różnych zasięgach. Zasięg Waga 1 2 3 1 0,781 0,012 0,065 5 0,648 -0,027 0,001 10 0,000

18
Prosty kriging – przykłady
Prosty kriging dla modelu z izotropowym wariogramem sferycznym o zasięgu 10 jednostek odległości i trzech różnych względnych udziałach wariancji nuggetowej Nugget= Waga 1 2 3 0% 0,781 0,012 0,065 25% 0,468 0,203 0,064 75% 0,172 0,130 0,053 100% 0,000

19
Prosty kriging – przykłady
Prosty kriging dla sferycznego modelu z 25% nuggetem i zasięgiem głównej osi wynoszącym 10 jednostek odległości w przypadku trzech różnych stosunków anizotropii Anizo- tropia= Waga 1 2 3 1:1 0,468 0,203 0,064 2:1 0,395 0,087 0,141 5:1 0,152 -0,055 0,232 20:1 0,000 0,239

20
Prosty przykład estymacji SK
Dane jednowymiarowe: profil 7 punktów b1_03b przy Y = 240 m Izotropowy model semiwariancji obliczony dla wszystkich 256 danych

21
Prosty przykład estymacji SK
Dane jednowymiarowe: profil dla Y = 240 m

22
Prosty kriging – zmienna b1_03b

23
Prosty kriging – zmienna b1_03b

24
Prosty kriging – zmienna b1_03b

25
Zwykły kriging – Ordinary Kriging
Ponieważ zazwyczaj średnia lokalna wartość cechy zmienia się w sposób istotny w ramach analizowanego obszaru opracowano algorytm, który limituje stacjonarność średniej do lokalnego sąsiedztwa W(u) z centrum w punkcie estymacji. Próbka losowa, zmienna b1_03b
 z centrum w punkcie estymacji. Próbka losowa, zmienna b1_03b.")
26
Zwykły kriging Liniowy estymator jest w tym przypadku definiowany jako liniowa kombinacja n(u) Zmiennych Losowych Z(u) plus stała średnia lokalna m(u): Nieznana średnia lokalna m(u) jest odfiltrowana z liniowego estymatora przez wymuszenia sumowania się wag krigingowych do 1. Estymator zwykłego krigingu ZOK jest w tej sytuacji zapisany jako liniowa kombinacja tylko n(u) ZL Z(u):
 Zmiennych Losowych Z(u) plus stała średnia lokalna m(u): Nieznana średnia lokalna m(u) jest odfiltrowana z liniowego estymatora przez wymuszenia sumowania się wag krigingowych do 1. Estymator zwykłego krigingu ZOK jest w tej sytuacji zapisany jako liniowa kombinacja tylko n(u) ZL Z(u):")
27
Zwykły kriging Ponownie n(u) wag jest określane w taki sposób, aby zminimalizować wariancję błędów zachowując ograniczenie nieobciążenia estymatora. Minimalizacja wariancji błędów przy uwzględnieniu ograniczenia nieobciążenia estymatora wymaga zdefiniowania zmiennej L(u), który jest funkcją wag danych oraz parametru Lagrange 2OK(u):
 wag jest określane w taki sposób, aby zminimalizować wariancję błędów zachowując ograniczenie nieobciążenia estymatora. Minimalizacja wariancji błędów przy uwzględnieniu ograniczenia nieobciążenia estymatora wymaga zdefiniowania zmiennej L(u), który jest funkcją wag danych oraz parametru Lagrange 2OK(u):")
28
Zwykły kriging Optymalne wagi uzyskuje się zerując każdą z (n(u)+1) cząstkowych pierwszych pochodnych. Układ zwykłego krigingu zawiera (n(u)+1) równań liniowych z (n(u)+1) niewiadomych: n(u) wag oraz parametru Lagrange OK(u), który zapewnia ograniczenie wartości wag: Mimo założenia, że średnia m(u) jest stacjonarna jedynie wewnątrz lokalnego sąsiedztwa W(u) kowariancję resztową określa się na podstawie globalnej kowariancji wyliczonej ze wszystkich dostępnych danych, zgodnie ze wzorem:
+1) równań liniowych z (n(u)+1) niewiadomych: n(u) wag oraz parametru Lagrange OK(u), który zapewnia ograniczenie wartości wag: Mimo założenia, że średnia m(u) jest stacjonarna jedynie wewnątrz lokalnego sąsiedztwa W(u) kowariancję resztową określa się na podstawie globalnej kowariancji wyliczonej ze wszystkich dostępnych danych, zgodnie ze wzorem:")
29
Zwykły kriging Minimalną wariancję błędów, zwaną wariancją OK, uzyskuje się ze wzoru:

30
Zwykły kriging Biorąc pod uwagę zależność, że C(h) = C(0) – (h), układ równań OK można zapisać za pomocą wartości semiwariogramu: Ze względu na warunek nieobciążenia estymatora składową C(0), czyli wariancję próby można usunąć z pierwszych n(u) równań i uzyskać następujący układ:
, czyli wariancję próby można usunąć z pierwszych n(u) równań i uzyskać następujący układ:")
31
Zwykły kriging Należy podkreślić, że w przeciwieństwie do SK układ równań zwykłego krigingu może być przedstawiony jedynie z użyciem kowariancji, ponieważ w SK nie ma ograniczenia dotyczącego wartości wag punktów. Zastosowanie w obliczeniach semiwariogramu pozwala „odfiltrować” nieznaną lokalną średnią m(u), uznaną za stałą w lokalnym sąsiedztwie W(u). Operujemy bowiem nie na wartościach bezwzględnych cechy, ale na różnicach między głową a ogonem:
, uznaną za stałą w lokalnym sąsiedztwie W(u). Operujemy bowiem nie na wartościach bezwzględnych cechy, ale na różnicach między głową a ogonem:")
32
Zwykły kriging Ze względu na efektywność obliczeniową układ równań krigingu rozwiązuje się zazwyczaj za pomocą kowariancji. Są jednakże modele semiwariogramu (np. potęgowy), które nie mają odpowiednika w kowariancjach. Dla tego typu nieograniczonych modeli semiwariogramu zdefiniowano tzw. „pseudokowariancję” polegającą na odjęciu wartości modelu semiwariogramu (h) od jakiejkolwiek dodatniej wartości A, takiej że A – (h) 0, h. Ponownie, warunek nieobciążenia estymatora pozwala na pominięcie stałej A w układzie równań OK, które zapisane zostają jedynie za pomocą pseudokowariancji. Tak więc praktyka geostatystyczna polega na: 1. Obliczeniu i modelowaniu semiwariogramu 2. Rozwiązaniu wszystkich układów równań OK przy użyciu (pseudo) kowariancji
, które nie mają odpowiednika w kowariancjach. Dla tego typu nieograniczonych modeli semiwariogramu zdefiniowano tzw. „pseudokowariancję polegającą na odjęciu wartości modelu semiwariogramu (h) od jakiejkolwiek dodatniej wartości A, takiej że A – (h) 0, h. Ponownie, warunek nieobciążenia estymatora pozwala na pominięcie stałej A w układzie równań OK, które zapisane zostają jedynie za pomocą pseudokowariancji. Tak więc praktyka geostatystyczna polega na: 1. Obliczeniu i modelowaniu semiwariogramu. 2. Rozwiązaniu wszystkich układów równań OK przy użyciu (pseudo) kowariancji.")
33
E{Z}-Kriging – Ordinary Kriging explained

35
Zwykły kriging Zamiast szacować wartość cechy z, można również chcieć estymować i przedstawić w postaci mapy lokalne średnie cechy. Daje to możliwość oceny lokalnych odchyleń od globalnej średniej i daje wygładzony obraz zmienności przestrzennej analizowanego zjawiska. Estymator OK można tak przekształcić aby szacować za pomocą jego lokalną średnią. Uzyskuje się wtedy następujący układ (n(u) + 1) liniowych równań: Dla każdych dwóch lokalizacji u i u' należących do tego samego lokalnego sąsiedztwa W(u) uzyskuje się wówczas ten sam wynik:
 + 1) liniowych równań: Dla każdych dwóch lokalizacji u i u należących do tego samego lokalnego sąsiedztwa W(u) uzyskuje się wówczas ten sam wynik:")
36
Prosty kriging a Zwykły kriging
Algorytm zwykłego krigingu jest zazwyczaj preferowany w stosunku do prostego krigingu ponieważ nie wymaga on znajomości ani stacjonarności średniej na całym obszarze A. Zwykły kriging z lokalnym sąsiedztwem szukania polega na: oszacowaniu lokalnej średniej w każdej lokalizacji u przy zastosowaniu zwykłego krigingu do danych należących do sąsiedztwa W(u), a następnie, zastosowaniu estymatora SK przy użyciu wyliczonej średniej lokalnej zamiast stacjonarnej średniej globalnej Relację między estymatorami SK i OK można zatem zapisać:
, a następnie, zastosowaniu estymatora SK przy użyciu wyliczonej średniej lokalnej zamiast stacjonarnej średniej globalnej. Relację między estymatorami SK i OK można zatem zapisać:")
37
Prosty kriging a Zwykły kriging
Różnica pomiędzy szacunkiem z w lokalizacji u za pomocą prostego i zwykłego krigingu jest spowodowana przez odchylenia lokalnej średniej od średniej globalnej m. Mówiąc ściślej ponieważ jest zazwyczaj dodatnie, estymacje OK są niższe niż SK na obszarach o niskich wartościach cechy, gdzie średnia lokalna jest niższa od globalnej. I przeciwnie, szacunki dokonane zwykłym krigingiem są wyższe niż uzyskane za pomocą SK w obszarach wysokich wartości, gdzie lokalna średnia jest większa od globalnej średniej. Różnica pomiędzy estymacjami i wzrasta w miarę jak waga średniej wzrasta, to jest w miarę jak lokalizacja u punktu estymacji znajduje się coraz dalej od lokalizacji pomiarów.

38
Prosty kriging a Zwykły kriging – przykład
Dane jednowymiarowe: profil dla Y = 240 m

39
Walidacja estymacji metodą krigingu
Wyniki estymacji pokazują tylko przybliżony obraz rzeczywistości (model), który zawsze będzie się od niej różnił. Im mniejsza jest ta różnica (błąd estymacji), tym lepszy model struktury przestrzennej (semiwariancji) użyty do estymacji i lepiej dobrane parametry obliczeń. Stopień poprawności modelu najlepiej ocenić porównując wartości estymowane z rzeczywistymi. Można tego dokonać zbierając dodatkowe próbki lub też używając zbioru wcześniej opróbowanych lokalizacji. W tym wypadku pierwsze rozwiązanie jest dość czasochłonne i wymaga dodatkowych nakładów finansowych, co skłania do oceny poprawności modelu za pomocą posiadanego już zbioru danych poprzez walidację podzbiorem (ang. jackknifing) albo kroswalidację (ang. cross-validation).
, który zawsze będzie się od niej różnił. Im mniejsza jest ta różnica (błąd estymacji), tym lepszy model struktury przestrzennej (semiwariancji) użyty do estymacji i lepiej dobrane parametry obliczeń. Stopień poprawności modelu najlepiej ocenić porównując wartości estymowane z rzeczywistymi. Można tego dokonać zbierając dodatkowe próbki lub też używając zbioru wcześniej opróbowanych lokalizacji. W tym wypadku pierwsze rozwiązanie jest dość czasochłonne i wymaga dodatkowych nakładów finansowych, co skłania do oceny poprawności modelu za pomocą posiadanego już zbioru danych poprzez walidację podzbiorem (ang. jackknifing) albo kroswalidację (ang. cross-validation).")
40
Walidacja podzbiorem (ang. jackknifing)
Walidacja podzbiorem sprowadza się do podziału zbioru opróbowanych lokalizacji n na podzbiory o różnej wielkości – większy wykorzystujemy do estymacji wartości danej cechy z dla wszystkich lokalizacji ze zbioru mniejszego, który nie bierze udziału w analizie. Jest to preferowana metoda, ponieważ dzięki temu zbiór walidacyjny jest zawsze niezależny od danych użytych do estymacji. Jednakże walidacja podzbiorem wiąże się z usunięciem z obliczeń części oryginalnych danych pomiarowych. Wymaga też użycia zbioru na tyle dużego, aby ilość danych w drugim podzbiorze umożliwiała obliczenie wiarygodnych statystyk jakości estymacji

41
Kroswalidacja (ang. cross-validation)
Kroswalidacja natomiast wykorzystuje do obliczeń struktury przestrzennej i modelowania wszystkie dane. Polega ona na podziale zbioru opróbowanych lokalizacji n na dwa podzbiory: „konstrukcji”, zawierającym n-1 pomiarów danej cechy z oraz „walidacji”, w którym znajduje się 1 pomiar z danej lokalizacji (u). Następnie używając podzbioru konstrukcji dokonuje się estymacji wartości cechy z dla lokalizacji z podzbioru walidacji. Procedurę należy powtórzyć tyle razy, ile jest pomiarów, za każdym razem odrzucając próbkę z innej lokalizacji („losowanie ze zwracaniem”) W efekcie uzyskuje się n estymacji dla n pomiarów danej cechy z, które można ze sobą porównać obliczając statystyki jakości estymacji
. Następnie używając podzbioru konstrukcji dokonuje się estymacji wartości cechy z dla lokalizacji z podzbioru walidacji. Procedurę należy powtórzyć tyle razy, ile jest pomiarów, za każdym razem odrzucając próbkę z innej lokalizacji („losowanie ze zwracaniem ) W efekcie uzyskuje się n estymacji dla n pomiarów danej cechy z, które można ze sobą porównać obliczając statystyki jakości estymacji.")
42
Kroswalidacja (ang. cross-validation)
Niewątpliwą wadą kroswalidacji jest użycie do walidacji tego samego zbioru danych, co do modelowania i estymacji. W konsekwencji cała analiza od początku do końca opiera się na tych samych danych. W związku z tym za każdym razem uzyskujemy wyniki dla lokalizacji, w których wartość cechy jest znana. Nie zawsze jednak zebrane dane odzwierciedlają charakterystykę całego obszaru badań (np. na skutek preferencyjnego opróbowania). Dlatego też może się okazać, że model, który w procedurze kroswalidacji daje bardzo dobre wyniki, nie będzie odpowiedni do estymacji pomiędzy opróbowanymi lokalizacjami, czyli w miejscach o nieznanej wartości cechy.
. Dlatego też może się okazać, że model, który w procedurze kroswalidacji daje bardzo dobre wyniki, nie będzie odpowiedni do estymacji pomiędzy opróbowanymi lokalizacjami, czyli w miejscach o nieznanej wartości cechy.")
43
Kroswalidacja (ang. cross-validation)
Z kolei główną zaletą kroswalidacji jest to, iż wykorzystuje ona wszystkie oryginalne dane pomiarowe, dzięki czemu możliwa jest walidacja zbiorów o niewielkiej liczebności. Najpopularniejszym zastosowaniem kroswalidacji jest, związana z oceną poprawności modelu, optymalizacja jego parametrów. Polega ona na porównaniu kilku modeli pod względem obliczonych dla każdego z nich statystyk jakości estymacji i wybraniu tego, który ma najlepiej oddaje rzeczywistość. Kroswalidację można również wykorzystać do oceny wpływu właściwości zbioru danych na jakość estymacji. W tym wypadku konieczna jest dość duża ilość zestawów danych, dla których zestawia się statystyki globalne i lokalne zbiorów z statystykami jakości estymacji i na tej podstawie wyprowadza model regresji.

44
Statystyki jakości estymacji
Statystyki jakości estymacji służą do porównania wyników estymacji. Dzięki nim można ustalić, który model estymacji daje najlepsze wyniki dla danego zestawu danych. Statystyki te pozwalają na ocenę kolejnych modeli pod względem dwóch podstawowych pojęć dotyczących jakości estymacji: dokładności oraz precyzji estymacji. Dokładność jest to stopień w jakim wartości estymowane są zgodne z rzeczywistością. Natomiast precyzja to zgodność kolejnych wyników względem siebie. W związku z tym, jeśli przy kilku kolejnych estymacjach ich wyniki są do siebie podobne, ale różnią się od wartości prawdziwych, to znaczy, że model jest precyzyjny, ale niedokładny. A jeżeli kolejne wartości są zbliżone do rzeczywistych, ale różnią się od siebie w sposób istotny, to model jest dokładny, ale nieprecyzyjny. Dopiero w przypadku, gdy kolejne wartości są podobne do prawdziwych i do siebie, wtedy model ten można określić jako dokładny i precyzyjny.

45
Statystyki jakości estymacji
Błąd – definiuje się go jako różnicę między wartością estymowaną a rzeczywistą. Błąd często nazywamy też resztą. Jest on miarą dokładności – określa na ile wartość estymowana różni się od zmierzonej. Jeżeli błąd jest dodatni wtedy prawdziwa wartość została przeszacowana, jeśli ujemny, mamy do czynienia z niedoszacowaniem Błąd minimalny, maksymalny oraz amplituda błędów – zawierają informację o tym jakiego rzędu są największe odchylenia (zarówno in plus, jak i in minus) oraz jaka jest między nimi różnica. Pomagają określić precyzję estymacji. Średni błąd (ang. mean error, ME) – jest miarą obciążenia estymatora. W sytuacji idealnej powinien wynosić 0. Jeśli istotnie różni się od 0, oznacza to, że estymator regularnie zawyża lub zaniża szacowane wartości. Jednakże nawet w przypadku, gdy średni błąd jest równy 0 nie ma pewności, co do nieobciążenia estymatora. Ma to miejsce, np. w sytuacji, gdy dużo małych błędów ujemnych jest kompensowanych przez jeden duży błąd dodatni. Średnia będzie zbliżona do 0, ale estymator i tak będzie obciążony. Dlatego też warto zawsze zwrócić uwagę na symetrię rozkładu błędów (histogram), wykres rozrzutu wartości rzeczywistych i estymowanych, a także obliczyć procentowy udział błędów dodatnich i ujemnych.
 oraz jaka jest między nimi różnica. Pomagają określić precyzję estymacji. Średni błąd (ang. mean error, ME) – jest miarą obciążenia estymatora. W sytuacji idealnej powinien wynosić 0. Jeśli istotnie różni się od 0, oznacza to, że estymator regularnie zawyża lub zaniża szacowane wartości. Jednakże nawet w przypadku, gdy średni błąd jest równy 0 nie ma pewności, co do nieobciążenia estymatora. Ma to miejsce, np. w sytuacji, gdy dużo małych błędów ujemnych jest kompensowanych przez jeden duży błąd dodatni. Średnia będzie zbliżona do 0, ale estymator i tak będzie obciążony. Dlatego też warto zawsze zwrócić uwagę na symetrię rozkładu błędów (histogram), wykres rozrzutu wartości rzeczywistych i estymowanych, a także obliczyć procentowy udział błędów dodatnich i ujemnych.")
46
Statystyki jakości estymacji
Wariancja i odchylenie standardowe błędów informują o ich rozrzucie. Przyjmuje się, iż im mniejszy rozrzut błędów tym większa dokładność i precyzja estymacji. Oznacza to, że pożądane są jak najmniejsze wartości wariancji i odchylenia standardowego. Średni błąd oraz rozrzut nie są niezależne. Toteż często można poprawić estymator poprzez zmniejszenie zróżnicowania błędów (redukcję rozrzutu) kosztem jego niewielkiego obciążenia. Statystyki jakości estymacji, które uwzględniają zarówno rozrzut, jak i obciążenie rozkładu błędów to średni błąd bezwzględny (ang. mean absolute error, MAE) i średni błąd kwadratowy (ang. mean squared error, MSE) oraz pierwiastek średniego błędu kwadratowego (ang. root mean squared error, RMSE). RMSE również określa dokładność modelu. Im mniejsze przyjmuje wartości, tym lepiej. Poprzez spierwiastkowanie MSE następuję powrót do skali obliczeń, jednakże na skutek wcześniejszego potęgowania wzmacnia się znaczenie dużych błędów.
 kosztem jego niewielkiego obciążenia. Statystyki jakości estymacji, które uwzględniają zarówno rozrzut, jak i obciążenie rozkładu błędów to średni błąd bezwzględny (ang. mean absolute error, MAE) i średni błąd kwadratowy (ang. mean squared error, MSE) oraz pierwiastek średniego błędu kwadratowego (ang. root mean squared error, RMSE). RMSE również określa dokładność modelu. Im mniejsze przyjmuje wartości, tym lepiej. Poprzez spierwiastkowanie MSE następuję powrót do skali obliczeń, jednakże na skutek wcześniejszego potęgowania wzmacnia się znaczenie dużych błędów.")
47
Statystyki jakości estymacji
Standaryzowany błąd (SE) – tj. błąd, którego standaryzacja odbywa się poprzez podzielenie go przez wariancję krigingową. Przyjmuje się , że powinien on mieścić się w przedziale [-2,5;2,5] przy 99% przedziale ufności i rozkładzie normalnym. Wtedy wyniki estymacji są wówczas uznawane za wiarygodne. Histogram standaryzowanych kwadratów reszt pomaga w stwierdzeniu, czy estymator jest obciążony, czy nie. Standaryzowany błąd również określa dokładność estymacji poprzez porównanie wartości estymowanych i rzeczywistych. Porównanie to jest łatwiejsze i efektywniejsze niż w przypadku zwykłych błędów, gdyż wartości zostały sprowadzone do jednej skali. Ma to miejsce dzięki dzieleniu przez wariancję krigingowa. Sama w sobie nie jest ona miarą jakości estymacji, gdyż nie informuje ani o jej dokładności, ani o precyzji, ale o rozkładzie przestrzennym pomiarów. Dlatego też stosuje się ją głównie do standaryzacji
 – tj. błąd, którego standaryzacja odbywa się poprzez podzielenie go przez wariancję krigingową. Przyjmuje się , że powinien on mieścić się w przedziale [-2,5;2,5] przy 99% przedziale ufności i rozkładzie normalnym. Wtedy wyniki estymacji są wówczas uznawane za wiarygodne. Histogram standaryzowanych kwadratów reszt pomaga w stwierdzeniu, czy estymator jest obciążony, czy nie. Standaryzowany błąd również określa dokładność estymacji poprzez porównanie wartości estymowanych i rzeczywistych. Porównanie to jest łatwiejsze i efektywniejsze niż w przypadku zwykłych błędów, gdyż wartości zostały sprowadzone do jednej skali. Ma to miejsce dzięki dzieleniu przez wariancję krigingowa. Sama w sobie nie jest ona miarą jakości estymacji, gdyż nie informuje ani o jej dokładności, ani o precyzji, ale o rozkładzie przestrzennym pomiarów. Dlatego też stosuje się ją głównie do standaryzacji.")
48
Statystyki jakości estymacji
Średni standaryzowany kwadrat reszt (ang. mean square standard residual, MSSR) .Idealnie średni standaryzowany kwadrat reszt jest równy 1. Zakłada się, że im bliżej 1, tym większa wiarygodność oraz dokładność modelu i jego parametrów. Wykres rozrzutu wartości rzeczywistych i estymowanych (wykres rozrzutu - ang. scatterplot) jest kolejną miarą dokładności estymacji. Punkty na wykresie tworzą chmurę, która układa się wzdłuż linii 45º. Im mniej wartości estymowane różnią się od prawdziwych, tym znajdują się bliżej tej linii. Łatwo w ten sposób zauważyć wszystkie wartości odstające. Syntetyczną miarą bliskości punktów do linii 45º jest współczynnik korelacji.
 .Idealnie średni standaryzowany kwadrat reszt jest równy 1. Zakłada się, że im bliżej 1, tym większa wiarygodność oraz dokładność modelu i jego parametrów. Wykres rozrzutu wartości rzeczywistych i estymowanych (wykres rozrzutu - ang. scatterplot) jest kolejną miarą dokładności estymacji. Punkty na wykresie tworzą chmurę, która układa się wzdłuż linii 45º. Im mniej wartości estymowane różnią się od prawdziwych, tym znajdują się bliżej tej linii. Łatwo w ten sposób zauważyć wszystkie wartości odstające. Syntetyczną miarą bliskości punktów do linii 45º jest współczynnik korelacji.")
49
Statystyki jakości estymacji - wykresy
Histogram standaryzowanych błędów estymacji

50
Statystyki jakości estymacji - wykresy
Wykres rozrzutu i korelacja wartości rzeczywistych i estymacji

51
Statystyki jakości estymacji - wykresy
Wykres rozrzutu i korelacja standaryzowanych błędów i wartości estymowanych

52
Statystyki jakości estymacji – wybór modelu i optymalizacja obliczeń (zanieczyszczenie kadmem gleb na terenie Jury Szwajcarskiej ) ppm (mg/kg)
")
53
Statystyki jakości estymacji – wybór modelu i optymalizacja obliczeń (zanieczyszczenie kadmem gleb na terenie Jury Szwajcarskiej)
")
54
Statystyki jakości estymacji – wybór modelu i optymalizacja obliczeń (zanieczyszczenie kadmem gleb na terenie Jury Szwajcarskiej)
")
55
Statystyki jakości estymacji – wybór modelu i optymalizacja obliczeń (zanieczyszczenie kadmem gleb na terenie Jury Szwajcarskiej)
")
56
Statystyki jakości estymacji – wybór modelu i optymalizacja obliczeń (zanieczyszczenie kadmem gleb na terenie Jury Szwajcarskiej)
")