Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Analiza informacji meteorologicznych Wykład 5
Krzysztof Markowicz Instytut Geofizyki UW

2
Asymilacja Danych Meteorologicznych
To proces znajdywania reprezentacji modelu „najbardziej zgodnej” z obserwacjami meteorologicznymi. Asymilacja danych jest procesem polegającym na uzupełnieniu niekompletnych danych w pewnym modelu opisującym system dynamiczny Głównym problemem asymilacji danych są zróżnicowane źródła danych meteorologicznych: pomiary in-situ, pomiary satelitarnych, radarowe, lidarowych wykonywane w różnym czasie i w różnych miejscach na kuli ziemskiej. Np. Jak asymilować dane o odbiciowości radarowej do modeli numerycznych prognoz pogody? Asymilacja danych jest bardzo złożonym procesem i można ją rozdzielić na dwa procesy; (a) pierwszy etap polega na sprawdzeniu jakości danych - to jest etap skomplikowany, ale prosty do zrozumienia. Chodzi o wyeliminowanie oczywistych błędów pomiarowych; (b) drugim i ważniejszym etapem jest uzgodnienie danych i wykorzystanie informacji dostępnej z poprzednich godzin czy z poprzednich dni. Jest to skomplikowany proces polegający na całościowej analizie danych dość często z wykorzystaniem modelu prognoz numerycznych.
 pierwszy etap polega na sprawdzeniu jakości danych - to jest etap skomplikowany, ale prosty do zrozumienia. Chodzi o wyeliminowanie oczywistych błędów pomiarowych; (b) drugim i ważniejszym etapem jest uzgodnienie danych i wykorzystanie informacji dostępnej z poprzednich godzin czy z poprzednich dni. Jest to skomplikowany proces polegający na całościowej analizie danych dość często z wykorzystaniem modelu prognoz numerycznych.")
13
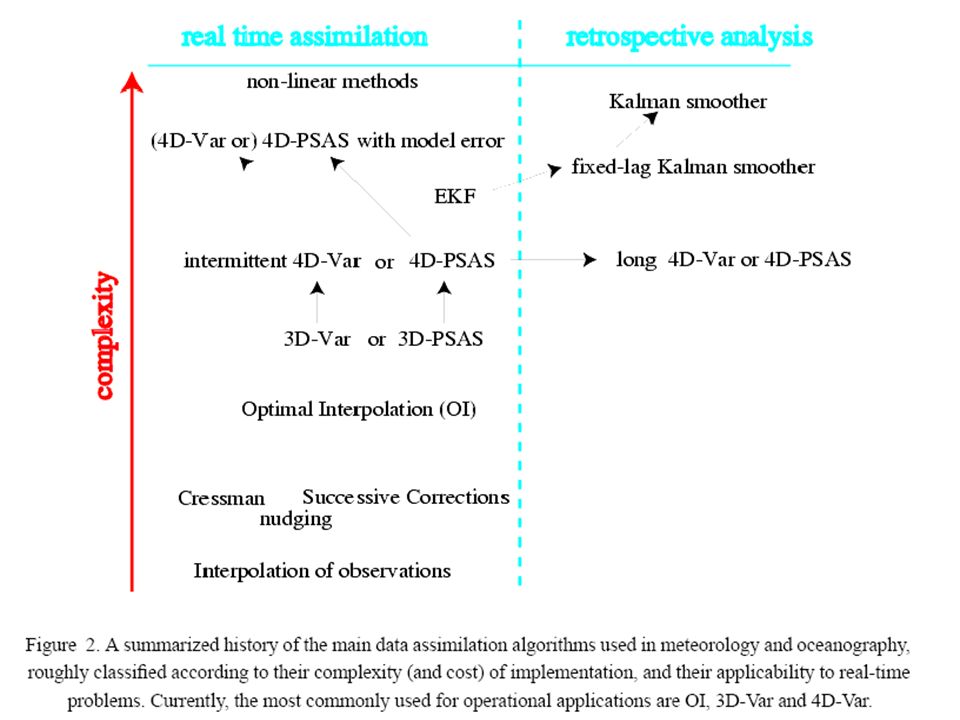
Zarys historii Pierwsze metody asymilacji danych nosiły nazwą analizy obiektywnej (np. algorytm Cressmana, 1959). Było to podejście przeciwne do metod subiektywnych opierających się na analizie pól meteorologicznych przez synoptyka Metody obiektywne wykorzystywały przybliżenia oparte na prostych technikach interpolacyjnych. Są to metody 2 lub 3D. Podobne metody w 4D (z czasem) noszą nazwę "nudging" (np. w modelu MM5) Bazują one na idei relaksacji Newtona, która ma za zadanie dodanie we właściwych członach równań dynamicznych modelu, różnicy pomiędzy obliczonymi zmiennymi meteorologicznymi a wartościami obserwacyjnymi. Człony te mają ujemny znak co pozwala utrzymywać obliczone wartości zmiennych (wektora stanu) w sąsiedztwie wartości obserwowanych (wektora obserwacji).
. Było to podejście przeciwne do metod subiektywnych opierających się na analizie pól meteorologicznych przez synoptyka. Metody obiektywne wykorzystywały przybliżenia oparte na prostych technikach interpolacyjnych. Są to metody 2 lub 3D. Podobne metody w 4D (z czasem) noszą nazwę nudging (np. w modelu MM5) Bazują one na idei relaksacji Newtona, która ma za zadanie dodanie we właściwych członach równań dynamicznych modelu, różnicy pomiędzy obliczonymi zmiennymi meteorologicznymi a wartościami obserwacyjnymi. Człony te mają ujemny znak co pozwala utrzymywać obliczone wartości zmiennych (wektora stanu) w sąsiedztwie wartości obserwowanych (wektora obserwacji).")
14
Przełomowe stało się wprowadzenie do asymilacji danych statystycznej (optymalnej) interpolacji przez L. Gandin (1963). Metoda jego bazowała na idei Kolmogorov. Jest ona pewnym rodzajem analizy regresyjnej, która wykorzystuje informacje o przestrzennym rozkładzie funkcji kowariancyjnych błędów pierwszego przybliżenia (wcześniejszej prognozy) oraz rzeczywistego pola meteorologicznego. Chociaż funkcje te nigdy jednak nie są znane to stosuje się szereg ich przybliżeń. Optymalna interpolacja odpowiada zredukowanej wersji filtru Kalmana, gdy macierze kowariancji nie są liczone z równań dynamiki a wyznaczane na podstawie kolejnych przybliżeń pół. Wprowadzenie filtru Kalmana do asymilacji 4D jest bardzo trudnym zadaniem i wymaga rozwiązania dodatkowo ogromnej ilości równań: ~N*N~1012 , gdzie N=Nx*Ny*Nz jest rozmiarem wektora stanu, typowy rozmiar domeny obliczeniowej : Nx~100, Ny~100, Nz~100

15
W celu uniknięcia tego problemu stosuje się specjalne wersje filtru Kalmana np
Reduced-Rank Kalman filters (RRSQRT) Kolejnym rozszerzeniem metod 4D-Var jest wykorzystanie przybliżenia wariacyjnego (Le Dimet and Talagrand, 1986 wcześniej opracowane przez G. Marchuk) Uwzględnia ono fakt, iż pola meteorologiczne spełniają równania dynamiki zawarte w model prognoz pogody. Tym samym minimalizują funkcjonał opisujący ich różnice w stosunku do obserwacji. Jak pokazał Lorenz, 1986 wszystkie wspomniane powyżej metody 4D są równoważne (przy pewnych założeniach ) minimalizacji pewnej funkcji kosztu. W praktyce założenia te nigdy nie są jednak spełnione.
 Kolejnym rozszerzeniem metod 4D-Var jest wykorzystanie przybliżenia wariacyjnego (Le Dimet and Talagrand, 1986 wcześniej opracowane przez G. Marchuk) Uwzględnia ono fakt, iż pola meteorologiczne spełniają równania dynamiki zawarte w model prognoz pogody. Tym samym minimalizują funkcjonał opisujący ich różnice w stosunku do obserwacji. Jak pokazał Lorenz, 1986 wszystkie wspomniane powyżej metody 4D są równoważne (przy pewnych założeniach ) minimalizacji pewnej funkcji kosztu. W praktyce założenia te nigdy nie są jednak spełnione.")
16
Gwałtowny rozwój metody asymilacji danych meteorologicznych do numerycznych prognoz pogody związany jest z dwoma zagadnieniami: wykorzystaniem obecnych obserwacji do poprawienia jakości prognozy dla różnych skal przestrzennych (od skali planetarnej do skali ulic miasta) oraz czasowych wykorzystanie równych typów dostępnych obserwacji (sodary, radary,lidary), które intensywnie rozwijają się Ciągle aktualnym pytaniem pozostaje: czy asymilacja danych pozwoli na przezwyciężenie trudności z prognozowaniem stanów atmosfery?
 oraz czasowych. wykorzystanie równych typów dostępnych obserwacji (sodary, radary,lidary), które intensywnie rozwijają się. Ciągle aktualnym pytaniem pozostaje: czy asymilacja danych pozwoli na przezwyciężenie trudności z prognozowaniem stanów atmosfery")
17
Do czego używamy asymilacji danych
Globalne i lokalne mapy synoptyczne (Primary -Constrained Product) Niezmierzone wielkości (Primary - Derived Product) Wiatr ageostroficzny, pionowe profile, Wyznaczane wielkości: Ruch pionowy / dywergencja, cyrkulacja residualna, diabatyczne oraz radiacyjne własności, ozon troposferyzny Inicjalizacja prognozy Poprawki radiacyjne w metodach teledetekcyjnych “Background,” (a priori profile dla metod teledetekcyjnych) Monitoring Kalibracja przyrządów Ocena jakości obserwacji Walidacja i ocena modeli
 Niezmierzone wielkości (Primary - Derived Product) Wiatr ageostroficzny, pionowe profile, Wyznaczane wielkości: Ruch pionowy / dywergencja, cyrkulacja residualna, diabatyczne oraz radiacyjne własności, ozon troposferyzny. Inicjalizacja prognozy. Poprawki radiacyjne w metodach teledetekcyjnych Background, (a priori profile dla metod teledetekcyjnych) Monitoring. Kalibracja przyrządów. Ocena jakości obserwacji. Walidacja i ocena modeli.")
18
Główne strategie asymilacji danych
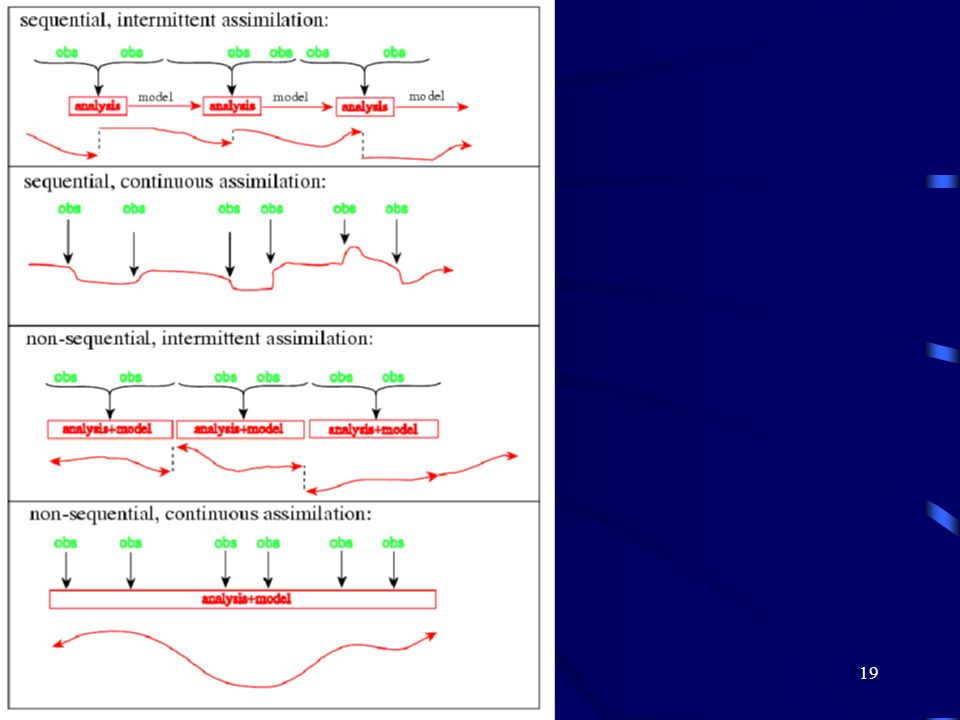
Wykorzystuje się dwa główne podejścia: asymilacja sekwencyjna, w której wykorzystuje się obserwacje wykonane przed rozpoczęciem analizy, która jest częścią „real-time assymilation systems”. asymilacja niesekwencyjna w której również obserwacje z „przyszłości są wykorzystywane. Ma to miejcie w tzw. re-analize. Podział ze względu na metody nieciągła (intermittent), w której obserwacje asymilowane są małymi porcjami co jest technicznie wygodną techniką ciągła (continuous), w której asymilowane są dane obserwacyjne z znacznie dłuższego okresu czasu. Pozawala to na korekcje wektora stanu i jego wygładzanie co jest fizycznie bardziej realistyczne.
, w której obserwacje asymilowane są małymi porcjami co jest technicznie wygodną techniką. ciągła (continuous), w której asymilowane są dane obserwacyjne z znacznie dłuższego okresu czasu. Pozawala to na korekcje wektora stanu i jego wygładzanie co jest fizycznie bardziej realistyczne.")
21
Definicje podstawowych wielkości
Wektor stanu (x) opisujący stan układu. Jego związek z rzeczywistym stanem układu zależy od dyskretyzacji co z matematycznego punktu widzenia związane jest z wyborem bazy. Wyróżniamy więc: xt – rzeczywisty (prawdziwy) wektor stanu (true state vector) xb- wektor informacji a priori lub „background” będącym oszacowaniem rzeczywistości przed wykonaniem analizy xa – poszukiwany wektor (analiza) Problem analizy sprowadza się do znalezienia poprawek do stanu podstawowego xb
 opisujący stan układu. Jego związek z rzeczywistym stanem układu zależy od dyskretyzacji co z matematycznego punktu widzenia związane jest z wyborem bazy. Wyróżniamy więc: xt – rzeczywisty (prawdziwy) wektor stanu (true state vector) xb- wektor informacji a priori lub „background będącym oszacowaniem rzeczywistości przed wykonaniem analizy. xa – poszukiwany wektor (analiza) Problem analizy sprowadza się do znalezienia poprawek do stanu podstawowego xb.")
22
Terminologia: informacje a priori / a posteriori
Informacje a priori – zawierają dane o systemie przed wykonaniem obserwacji. Są to najczęściej dane klimatologiczne (background) lub wynik wcześniejszej prognozy. Informacje a posteriori (po fakcie)– określają naszą znajomość systemu (wektora stanu) po wykonaniu obserwacji.
 lub wynik wcześniejszej prognozy. Informacje a posteriori (po fakcie)– określają naszą znajomość systemu (wektora stanu) po wykonaniu obserwacji.")
23
Obserwacje Wektor obserwacji: y
Operator obserwacji H, pozwala dokonać transformacji od wektora stanu (zdefiniowanego w modelu) do wektora obserwacji. W praktyce jest to operator związany interpolacją od dyskretnych punktów siatki modelu do nieregularnej sieci obserwacyjnej. H(x) – są wartościami obserwacyjnymi jakie uzyskalibyśmy gdyby wektor stanu był idealny i model pozbawiony był błędów. Głównym zadaniem asymilacji danych jest minimalizacja różnicy pomiędzy obserwacjami a wektorem stanu: y-H(x) Różnice tą możemy liczyć dla x=xb oraz dla x=xa (mówimy wówczas o analizie residualnej)
 do wektora obserwacji. W praktyce jest to operator związany interpolacją od dyskretnych punktów siatki modelu do nieregularnej sieci obserwacyjnej. H(x) – są wartościami obserwacyjnymi jakie uzyskalibyśmy gdyby wektor stanu był idealny i model pozbawiony był błędów. Głównym zadaniem asymilacji danych jest minimalizacja różnicy pomiędzy obserwacjami a wektorem stanu: y-H(x) Różnice tą możemy liczyć dla x=xb. oraz dla x=xa (mówimy wówczas o analizie residualnej)")
24
Błędy i niepewności Ze względu na błędy zawarte w obserwacjach i w polu pierwszego przybliżenia (np. dane klimatologiczne) musimy założyć pewien model błędów. Do tego celu wykorzystamy funkcji gęstości prawdopodobieństwa (pdf). Dla danego pierwszego przybliżenia xb tuż przed wykonaniem asymilacji mamy jeden wektor błędu, który oddziela to pole od pola rzeczywistego Jeśli moglibyśmy wykonać to bardzo wiele razy w tych samych warunkach ale z różna realizacją błędów moglibyśmy obliczyć statystyki (średnia, wariancje, histogram εb). Dla bardzo dużej liczby realizacji moglibyśmy wyznaczyć gęstość prawdopodobieństwa pdf i z niej wyznaczać wszystkie statystyki błędów.
 musimy założyć pewien model błędów. Do tego celu wykorzystamy funkcji gęstości prawdopodobieństwa (pdf). Dla danego pierwszego przybliżenia xb tuż przed wykonaniem asymilacji mamy jeden wektor błędu, który oddziela to pole od pola rzeczywistego. Jeśli moglibyśmy wykonać to bardzo wiele razy w tych samych warunkach ale z różna realizacją błędów moglibyśmy obliczyć statystyki (średnia, wariancje, histogram εb). Dla bardzo dużej liczby realizacji moglibyśmy wyznaczyć gęstość prawdopodobieństwa pdf i z niej wyznaczać wszystkie statystyki błędów.")
25
Błędy zerowego przybliżenia (background errors):
Związana z nim kowariancja: Nie zawierają one błędów dyskretyzacji Błędy obserwacyjne: Zawiera błędy powstałe w czasie wykonywania obserwacji, ale również związanie z konstrukcja operatora H a więc zawiera błędy dyskretyzacji. H(xt) nie jest perfekcyjnym obrazem prawdziwego stanu. Błędy analizy: Błąd wektora stanu dany jest przez ślad macierzy kowariancji. Naszym zadaniem jest minimalizacja tego błędu Średni błąd (obciążenie) określa błąd systematyczny. Niezerowa wartość wskazuje na problemy w systemie asymilacji danych i może być związanym z dryfem modelu czy błędami systematycznym obserwacji.
 nie jest perfekcyjnym obrazem prawdziwego stanu. Błędy analizy: Błąd wektora stanu dany jest przez ślad macierzy kowariancji. Naszym zadaniem jest minimalizacja tego błędu. Średni błąd (obciążenie) określa błąd systematyczny. Niezerowa wartość wskazuje na problemy w systemie asymilacji danych i może być związanym z dryfem modelu czy błędami systematycznym obserwacji.")
26
Macierz kowariancji Jeśli wektora stanu ma wymiar n wówczas macierz kowariancji ma wymiar n x n, elementy diagonalne są wariancjami dla poszczególnych zmiennych. Elementy pozadiagonalne są kowariancją poszczególnych elementów wektora. Marzcież jest dodatnio określona: xTAx>0 dla x>0, oraz ma dodatnie własności własne. W przypadku gdy dokonujemy liniowej transformacji P wektora stanu macierz kowariancji B po transformacji ma postać: PBPT.

27
Praktyczne wyznaczanie błędów
Statystyki błędów są funkcjami procesów fizycznych rządzących sytuacjami meteorologicznymi oraz własnościami sieci obserwacyjnej. Zależą one również od naszej znajomości a priori błędów. Generalnie mamy tylko jedna możliwości oszacowania statystyki błędów. Musimy założyć stacjonarności w czasie i jednorodność w przestrzeni statystyki błędów. Dzięki czemu dostajemy wiele realizacji błędów i możemy wyznaczamy empiryczne statystyki. Podejście takie ma sens klimatologiczny.

28
Analiza Cressman’a To jedno z najprostszych podejść asymilacja danych, w którym zmienne modelu przyjmują wartości na podstawie obserwacji meteorologicznych w najbliższym ich otoczeniu. Po za tym obszarem wektor stanu modelu ustawiany jest na podstawie danych klimatologicznych lub wcześniejszej prognozy modelu.

29
Zakładamy, że składowe wektor stanu modelu opisywane są przez zmienne skalarne określone w punktach węzłowych modelu. xb – wektor stanu określony na podstawie klimatologii (background) lub wcześniejszej prognozy, xb(i) – jest tym samym wektorem prze- interpolowanym do punktu i, y(i) – wektor obserwacji (i=1,2,…,n), xa - wektor modelu określony w punktach siatki j, d – jest odległością pomiędzy punktami i oraz j, funkcja wagowa w(i,j) wynosząca 1 dla punktu siatki modelu (i=j) oraz malejąca z odległością osiągającą wartość zero poza tzw. promieniem wpływu (di,j >R). Istnieje wiele odmian metody Cressman’a, w których definiuje się różne postacie funkcji wagowej w.
 lub wcześniejszej prognozy, xb(i) – jest tym samym wektorem prze- interpolowanym do punktu i, y(i) – wektor obserwacji (i=1,2,…,n), xa - wektor modelu określony w punktach siatki j, d – jest odległością pomiędzy punktami i oraz j, funkcja wagowa w(i,j) wynosząca 1 dla punktu siatki modelu (i=j) oraz malejąca z odległością osiągającą wartość zero poza tzw. promieniem wpływu (di,j >R). Istnieje wiele odmian metody Cressman’a, w których definiuje się różne postacie funkcji wagowej w.")
30
W metodzie „successive correction” funkcja wagowa może mieć wartość mniejszą od jedności w punkcie siatki modelu (i=j) co oznacza, że zarówno wartość klimatyczna jak i obserwacyjna ma wkład do wartości osiąganej w tym punkcie siatki. Słabe strony metod Cressman’a Jeśli posiadamy wcześniejszy wektor stanu modelu o wysokiej jakości i nie chcemy modyfikować przez słabej jakości dane obserwacyjne Nie jest oczywiste jak oddalając się od punktu obserwacyjnego dokonać relaksacji do danych klimatycznych Analiza powinna uwzględniać znane własności rzeczywistości (zależności pomiędzy zmiennymi, równowagę hydrostatyczna) a metoda ta nie uwzględnia tego Błędy obserwacyjne mogą generować niefizyczne stany modelu.
 a metoda ta nie uwzględnia tego. Błędy obserwacyjne mogą generować niefizyczne stany modelu.")
31
Nasze oczekiwania Asymilacje powinniśmy zacząć od stanu o wysokiej jakości (opartym np. na wcześniejszej prognozie) zwanym pierwszym (startowym) przybliżeniem (first guess) Jeśli sieć obserwacji jest gęsta wówczas zakładamy, że prawdziwy stan znajduje się „blisko” średniej wartości z tych obserwacji. Musimy dokonać kompromisu pomiędzy pierwszy przybliżeniem a wartościami pochodzącymi z obserwacji. Analiza powinna wygładzać nasze pole, gdyż wiemy, że taka jest cecha pól meteorologicznych. Gdy odchodzimy od punktu obserwacyjnego analiza powinna gładko przejść do pierwszego przybliżenia. Analiza powinna uwzględniać znane własności fizyczne opisujące stan atmosfery. Chcemy minimalizować różnice pomiędzy analizą a prawdziwym stanem.
 zwanym pierwszym (startowym) przybliżeniem (first guess) Jeśli sieć obserwacji jest gęsta wówczas zakładamy, że prawdziwy stan znajduje się „blisko średniej wartości z tych obserwacji. Musimy dokonać kompromisu pomiędzy pierwszy przybliżeniem a wartościami pochodzącymi z obserwacji. Analiza powinna wygładzać nasze pole, gdyż wiemy, że taka jest cecha pól meteorologicznych. Gdy odchodzimy od punktu obserwacyjnego analiza powinna gładko przejść do pierwszego przybliżenia. Analiza powinna uwzględniać znane własności fizyczne opisujące stan atmosfery. Chcemy minimalizować różnice pomiędzy analizą a prawdziwym stanem.")
32
Interpolacja statystyczna – metoda najmniejszych kwadratów
Zakładamy: zmienność operatora obserwacji H w otoczeniu pierwszego przybliżenia jest liniowa: H(x)-H(xb)=H(x-xb), H jest operatorem linowym Nietrywialne postacie macierzy kowariancji B i R Średnie błędy są zerowe:
-H(xb)=H(x-xb), H jest operatorem linowym. Nietrywialne postacie macierzy kowariancji B i R. Średnie błędy są zerowe:")
33
Błędy nie są skorelowane:
Analiza liniowa: poszukujemy poprawek do pierwszego przybliżenia, które zależą liniowo od różnicy pierwszego przybliżenia i obserwacji. Analiza optymalna: poszukujemy wektora stanu, który w sensie odchylenia średnio-kwadratowego jest najbliżej stanu rzeczywistego. Z metody najmniejszych kwadratów otrzymujemy: K jest macierzą wagową Macierz kowariancji błędu w ogólnym przypadku dana jest wzorem: Dla metody najmniejszych kwadratów ma postać:

34
Jest ona równoważna metodzie optymizacyjno - wariacyjnej
gdzie J jest funkcją kosztu analizy, Jb jest czynnikiem związanym z pierwszym przybliżeniem zaś Jo z obserwacjami. Jeśli funkcje gęstości prawdopodobieństwa błędów pierwszego przybliżenie oraz obserwacji są gaussowskie wówczas xa jest estymatorem rzeczywistego stanu xt w sensie maksymalnego prawdopodobieństwa.

35
Dowód poprawności wzorów metody najmniejszych kwadratów
Minimalizacja funkcji kosztu odpowiada zerowej pochodnej funkcji kosztów dla optymalnego wektora stanu xa. To można łatwo pokazać wykonując elementarne mnożenia macierzy K Łatwo można pokazać, że postać ta jest identyczna ze wzorem pokazanym w metodzie najmniejszych kwadratów, gdyż

36
Realizacja metody najmniejszych kwadratów
W obecnych modelach wektor stanu x jest rzędu n=107 Liczba obserwacji p=105 dla każdej analizy. Dlatego problem z punktu matematycznego jest niedookreślony.

37
Uwagi do założeń Założenie dodatnio określoności macierzy kowariancji B i R jest spełnione w „dobrze” postawionych problemach asymilacji. Jeśli B nie jest dodatnio określona transformujemy ją do bazy ortogonalnej. Co oznacza, że pierwsze przybliżenie jest idealne. Jeśli R nie jest dodatnio określona to macierz K jest dobrze określona a analiza będzie równa obserwacji w punkcie siatki. Jednak metoda wariacyjna w tym przypadku nie może być używana. Średnie błędy przeważnie nie są zerowe. Jednak jeśli są znane mogą być odjęte od pierwszego przybliżenia oraz pola obserwacji. Jeśli nie są znane analiza nie będzie optymalna. Dlatego istotne staje się monitorowanie średniego odchylenia przybliżenia zerowego w czasie asymilacji. Założenie, że błędy nie są skorelowane jest najczęściej spełnione, ponieważ błędy pierwszego przybliżenia oraz błędy obserwacji są zupełnie niezależne. Jednak w przypadku metod odwrotnych używanych np. w obserwacjach satelitarnych może istnieć niezerowa korelacja ze względu na fakt iż w metodach odwrotnych wykorzystuje się informacje z pierwszego przybliżenia.

38
Uwagi do liniowości operatora H
Założenie liniowości jest potrzebne do wyprowadzenia wyrażenia na macierz K. W praktyce H może nie być liniowa ale możemy dokonać linearyzacji w sąsiedztwie wektora przybliżenia zerowego. Bardziej ogólnie, możemy dokonać rozwiniecie w szereg Taylora Operator H zwany jest stycznym W przypadku metody najmniejszy kwadratów wymagamy aby: Problem nieliniowości operatora H nie jest związany z błędami obserwacyjnymi ale z błędami pierwszego przybliżenia, które w asymilacji sekwencyjnej są błędami wcześniejszej prognozy i zależą od zasięgu prognozy i jakości modelu.

39
Teoria Bayesa W podejściu Bayesa używamy pojęcia prawdopodobieństwa do opisu naszej wiedzy na temat wektora stanu oraz obserwacji. Twierdze Bayesa : opisuje prawdopodobieństwo warunkowe Jeśli A jest zdarzeniem x=xt, B jest zdarzeniem y=yo wówczas rozkład prawdopodobieństwa a posteriori (po fakcie) wektora stanu dla nowej obserwacji yo wynosi:
 wektora stanu dla nowej obserwacji yo wynosi:")
40
Bayesowskie oszacowanie wektora stanu odpowiada maksymalnemu prawdopodobieństwu a posteriori zgodnie z poprzednim wzorem. Celem naszej analizy jest wyznaczenie stanu o maksymalnym prawdopodobieństwie a posteriori znając rozkład prawdopodobieństwa dla pierwszego przybliżenia (tła) oraz dla obserwacji. Zakładamy, że rzeczywisty wektor stanu jest realizacją procesu losowego zdefiniowanego przez wielowymiarowy rozkład Gaussa.

41
Korzystając z tw. Bayesa otrzymujemy:
Szukamy więc wektora stanu, dla którego prawdopodobieństwo warunkowe osiąga maksimum co odpowiada minimalnej wartości funkcji kosztu J.

42
Podsumowanie Mamy dwie możliwości zdefiniowania analizy statystycznej:
(1) Gdy znamy macierze kowariancji błędów pierwszego przybliżenia oraz obserwacji i wyprowadzamy równania analizy wymagając aby całkowita wariancja błędów analizy była minimalna. (2) Gdy zakładamy gaussowskie rozkłady gęstości prawdopodobieństwa dla pierwszego przybliżenia i wyprowadzamy równania analizy opisujący wektor stanu o maksymalnym prawdopodobieństwie. Oba przybliżenia prowadzą do matematycznie równoważnych algorytmów Z punktu widzenia numerycznego mają one różne własności.
 Gdy znamy macierze kowariancji błędów pierwszego przybliżenia oraz obserwacji i wyprowadzamy równania analizy wymagając aby całkowita wariancja błędów analizy była minimalna. (2) Gdy zakładamy gaussowskie rozkłady gęstości prawdopodobieństwa dla pierwszego przybliżenia i wyprowadzamy równania analizy opisujący wektor stanu o maksymalnym prawdopodobieństwie. Oba przybliżenia prowadzą do matematycznie równoważnych algorytmów. Z punktu widzenia numerycznego mają one różne własności.")
43
Przykład – ilustracja metody najmniejszych kwadratów – przypadek skalarny
Chcemy oszacować temperaturę powietrza w pokoju na podstawie wskazań termometru o znanej dokładności σo (odchylenie standardowe). W wyniku pomiaru otrzymaliśmy wartość To. Jeśli nie mamy żadnych innych dodatkowych informacji najlepsze oszacowanie temperatur powietrza wynosi oczywiście To z dokładnością σo . Załóżmy, że posiadamy dokładne pomiary z dnia ubiegłego, które możemy traktować jako informację a priori (pierwsze przybliżenie) Tb , σb. Nie trudno domyśleć się, że kombinacja liniowa wartości To oraz Tb pozwoli nam na lepsze oszacowanie nieznanej temperatury rzeczywistej Tt. Rozpatrzmy temperaturę będąca średnią ważona: oraz wariancja gdzie założyliśmy że błędy nie są ze sobą skorelowane
. W wyniku pomiaru otrzymaliśmy wartość To. Jeśli nie mamy żadnych innych dodatkowych informacji najlepsze oszacowanie temperatur powietrza wynosi oczywiście To z dokładnością σo . Załóżmy, że posiadamy dokładne pomiary z dnia ubiegłego, które możemy traktować jako informację a priori (pierwsze przybliżenie) Tb , σb. Nie trudno domyśleć się, że kombinacja liniowa wartości To oraz Tb pozwoli nam na lepsze oszacowanie nieznanej temperatury rzeczywistej Tt. Rozpatrzmy temperaturę będąca średnią ważona: oraz wariancja. gdzie założyliśmy że błędy nie są ze sobą skorelowane.")
44
Jest to równoważne minimalizacji funkcji kosztu
Zakładamy wartość k minimalizując wartość błędu zgodnie ze wzorem Jest to równoważne minimalizacji funkcji kosztu W przypadku malej dokładności pomiaru (σo>>σb), k=0 W przypadku dużej dokładności pomiaru (σo <<σb), k=1 Gdy (σo =σb), k=0.5 W pozostałych przypadkach wartość analizy będzie średnią ważoną pomiędzy obserwacja a informacją a priori.
, k=0. W przypadku dużej dokładności pomiaru. (σo <<σb), k=1. Gdy (σo =σb), k=0.5. W pozostałych przypadkach wartość analizy będzie średnią ważoną pomiędzy obserwacja a informacją a priori.")
45
Wariancja analizy wyraża się wzorem
błąd analizy jest zawsze mniejszy niż błędy obserwacji i informacji a priori razem wzięte.

46
Wyznaczanie macierzy kowariancji błędów
Poprawne wyznaczenie macierzy kowariancji błędów obserwacyjnych oraz zerowego przybliżenia jest kluczowe dla procesu asymilacji danych. Poza wariancjami (wyrazy diagonalne macierzy korelacji) również współczynniki korelacji są istotne gdyż decydują o tym jak dane obserwacyjne będą wygładzane w przestrzeni modelu gdy istnieje niedopasowanie rozdzielczości modelu oraz gęstości sieci obserwacyjnej.
 również współczynniki korelacji są istotne gdyż decydują o tym jak dane obserwacyjne będą wygładzane w przestrzeni modelu gdy istnieje niedopasowanie rozdzielczości modelu oraz gęstości sieci obserwacyjnej.")
47
Wariancja błędów danych obserwacyjnych
Często zakłada się, że błędy wielkości pomiarowych nie są ze sobą skorelowane. Założenie to jest często racjonalne jednak w przypadku takich pomiarów jak: radiosondażowe czy satelitarne może nie być spełnione. Powinno unikać się sytuacji gdy wartości obserwacyjne zawierają błędy statystyczne. Generalnie jednak wyznaczanie macierzy kowariancji błędów obserwacyjnych R jest trudnym zadaniem. Dlatego w większości modeli macierz R jest diagonalna.

48
Wariancja błędów informacji a priori
Błędne oszacowanie wariacji błędów pierwszego przybliżenia prowadzi do zbyt małych lub zbyt dużych poprawek (innowacji) w procesie asymilacji danych w kolejnych (analysis increment). W przypadku metody najmniejszych kwadratów jedynie względna wartość wariancji błędów obserwacyjnych i pierwszego przybliżenia jest istotna. Jednak bezwzględne wartości wariancji mogą być istotne gdy dokonujemy kontroli jakości danych obserwacyjnych.
 w procesie asymilacji danych w kolejnych (analysis increment). W przypadku metody najmniejszych kwadratów jedynie względna wartość wariancji błędów obserwacyjnych i pierwszego przybliżenia jest istotna. Jednak bezwzględne wartości wariancji mogą być istotne gdy dokonujemy kontroli jakości danych obserwacyjnych.")
49
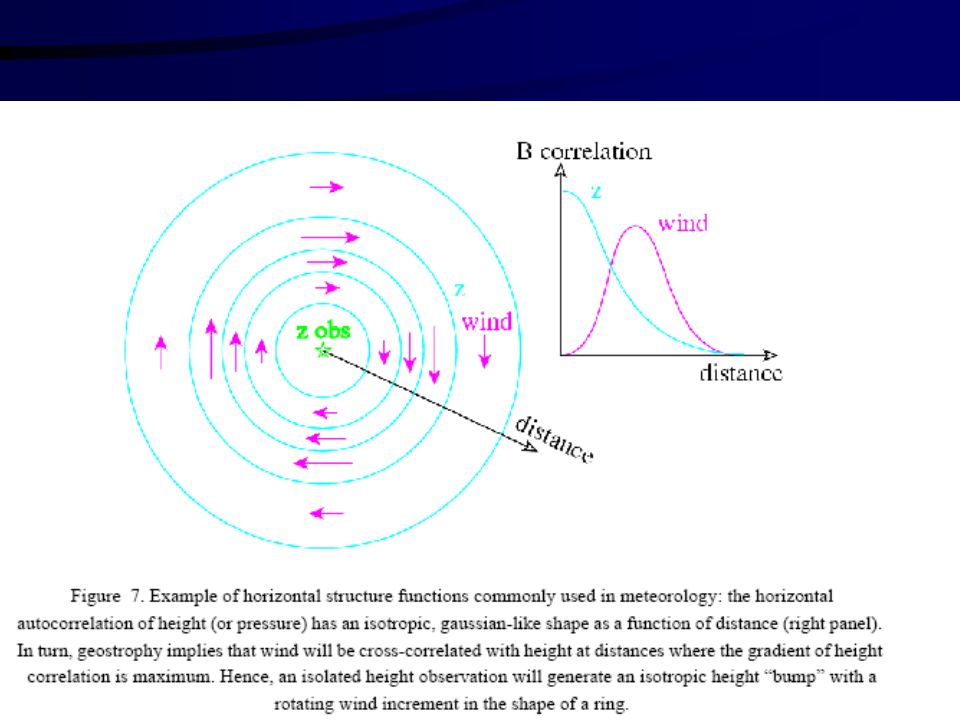
Korelacje błędów informacji a priori
są istotne ze względu na: Rozkład stacji obserwacyjnych W obszarach o rzadkiej gęstości sieci stacji pomiarowych kolejne poprawki analizy są określone przez strukturę macierzy kowariancji (dla pojedynczej obserwacji są one dane przez wielkość BHT). Tak wiec współczynniki korelacji macierzy B mówią jak informacje pochodzące ze stacji pomiarowej są propagowane na ich otoczenie. Wygładzanie informacji W przypadku gęstych sieci obserwacyjnych istotne staje się wygładzanie informacji, które jednak zależy od samego pola meteorologicznego. Inaczej wygładzać powinno się obszary frontowe a inaczej gdzie mamy antycykloniczny charakter cyrkulacji.
. Tak wiec współczynniki korelacji macierzy B mówią jak informacje pochodzące ze stacji pomiarowej są propagowane na ich otoczenie. Wygładzanie informacji. W przypadku gęstych sieci obserwacyjnych istotne staje się wygładzanie informacji, które jednak zależy od samego pola meteorologicznego. Inaczej wygładzać powinno się obszary frontowe a inaczej gdzie mamy antycykloniczny charakter cyrkulacji.")
50
(3) Różne typy równowag występujących w atmosferze
W modelu zwykle mamy znacznie więcej stopni swobody niż w rzeczywistości. Np. w dużej skali przeważnie mamy równowagę hydrostatyczną, zaś w obszarach poza tropikalnych odchylenie wiatru od równowagi geostroficznej jest niewielkie. Tak, więc jedna zmienna obserwacyjna w modelu zwiera informacje o pozostałych, które są z nią powiązane. Np. pole przypowierzchniowego wiatru pozwala skorygować pole ciśnienia przy założeniu, że wiatr w pewnym obszarze jest geostroficzny.

52
(4) źle uwarunkowanie problemu asymilacji
Często do zmiennych kontrolnych modelu umieszcza się dodatkowe parametry, które nie są bezpośrednio mierzone i mają za zadanie strojenie modelu. (5) zależność funkcji strukturalnych od rodzaju przepływu Macierz kowariancji błędów pierwszego przybliżenia B zależy od błędów wcześniejszej prognozy (lub analizy) zarówno ze względu na wariancje błędów ale i korelacje. Przepływy meteorologiczne mają charakter deterministyczny i możemy w nich dopatrywać się różnego rodzaju fal, które propagują się w określony sposób co powinno być odzwierciedlone w błędach pierwszego przybliżenia. Jeśli związane z nimi informacje są wbudowane w współczynniki korelacji macierzy B wówczas obserwowane wielkości mogą być dokładniej dystrybuowane w przestrzenni zmiennych modelu.
 zależność funkcji strukturalnych od rodzaju przepływu. Macierz kowariancji błędów pierwszego przybliżenia B zależy od błędów wcześniejszej prognozy (lub analizy) zarówno ze względu na wariancje błędów ale i korelacje. Przepływy meteorologiczne mają charakter deterministyczny i możemy w nich dopatrywać się różnego rodzaju fal, które propagują się w określony sposób co powinno być odzwierciedlone w błędach pierwszego przybliżenia. Jeśli związane z nimi informacje są wbudowane w współczynniki korelacji macierzy B wówczas obserwowane wielkości mogą być dokładniej dystrybuowane w przestrzenni zmiennych modelu.")
53
Wyznaczenie wariancji błędów
Jest to trudne zadanie ze względu na fakt, że błędy te nie są obserwowane w sposób bezpośredni. Mogą być obliczone jedynie w sensie statystycznym i to pod pewnymi warunkiem. Najlepszym źródłem błędów w systemie opisującym asymilacje danych jest różnica obserwacji i pierwszego przybliżenia: y-H(xb) Analiza błędów może być wykonywana przy użyciu kilku metod.
 Analiza błędów może być wykonywana przy użyciu kilku metod.")
54
Metoda obserwacyjna Hollingwortha-Lonnberga.
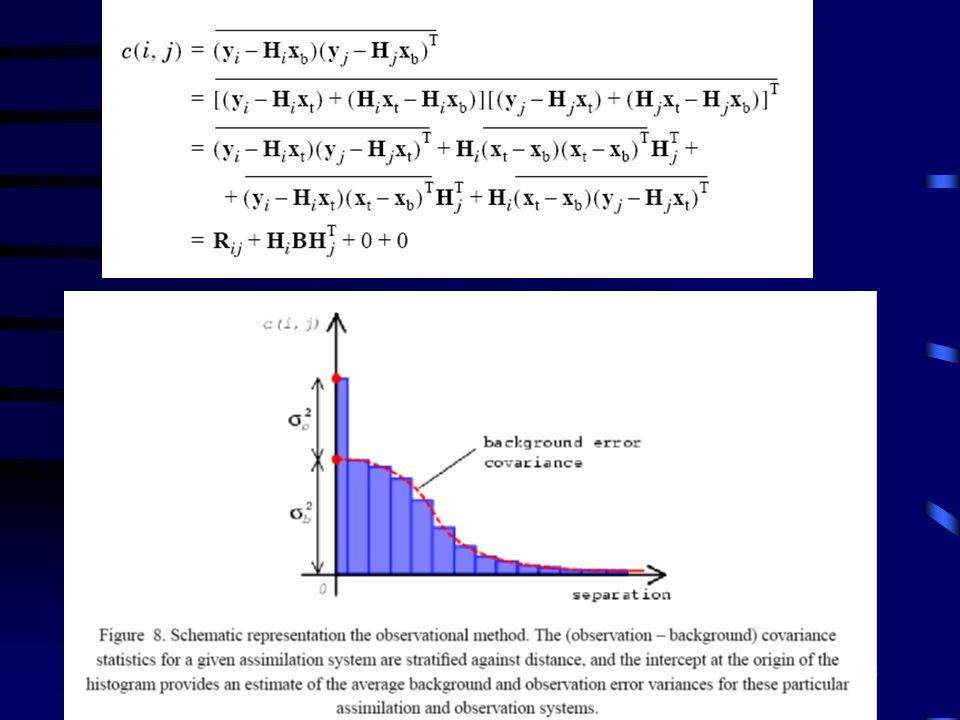
Metoda ta wykorzystuje różnice pomiędzy polem background (a priori) oraz polem obserwacyjnym dla których sieć obserwacyjna jest na tyle gęsta aby dostarczać informacji dla wielu skal przestrzennych. Obliczamy histogram kowariancji pierwszego przybliżenia i obserwacji jako funkcje odległości (separacja). Przy zerowej separacji histogram dostarcza nam informacji o błędach pierwszego przybliżenia i obserwacji. Dla niezerowej separacji dostarcza nam informacji o średnim współczynniki korelacji błędu pierwszego przybliżenia. Jeśli i oraz j są dwoma punktami obserwacyjnymi to wówczas kowariancja różnicy pierwszego przybliżenia i obserwacji dana jest wzorem:
 oraz polem obserwacyjnym dla których sieć obserwacyjna jest na tyle gęsta aby dostarczać informacji dla wielu skal przestrzennych. Obliczamy histogram kowariancji pierwszego przybliżenia i obserwacji jako funkcje odległości (separacja). Przy zerowej separacji histogram dostarcza nam informacji o błędach pierwszego przybliżenia i obserwacji. Dla niezerowej separacji dostarcza nam informacji o średnim współczynniki korelacji błędu pierwszego przybliżenia. Jeśli i oraz j są dwoma punktami obserwacyjnymi to wówczas kowariancja różnicy pierwszego przybliżenia i obserwacji dana jest wzorem:")
56
Jeśli założymy ze nie ma korelacji pomiędzy błędami obserwacyjnymi oraz błędami pierwszego przybliżenia ostatnie 2 czynniki są równe zero. Pierwszy czynnik jest kowariancją błędu obserwacji dla stacji i oraz j. Drugi czynnik zaś kowariancją błędów pierwszego przybliżenia interpolowanego do tych punktów (przy założeniu, że oba błędy są jednorodne)
")
57
Jeśli i=j, c(i,j)=σo2(i)+σb2(i)
Jeśli ij oraz błędy obserwacyjne nie są skorelowane: c(i,j)=covb(i,j). Jeśli błędy obserwacyjne są skorelowane nie jest możliwe rozwikłanie informacji o macierzach R i B bez dodatkowych założeń. Przy tych samych założeniach i jeśli punkty i oraz j są blisko siebie wówczas Możemy obliczyć kowariancję pola obserwacyjnego”
=covb(i,j). Jeśli błędy obserwacyjne są skorelowane nie jest możliwe rozwikłanie informacji o macierzach R i B bez dodatkowych założeń. Przy tych samych założeniach i jeśli punkty i oraz j są blisko siebie wówczas. Możemy obliczyć kowariancję pola obserwacyjnego")
58
Obliczanie macierzy korelacji błędów pierwszego przybliżenia
Pozadiagonalne elementy macierzy B są najtrudniejsze do wyznaczenia. Muszą one definiować dodatnio określoną macierz kowariancji. Ponadto macierz B wymaga aby zawierała kilka własności fizycznych: Wpół. korelacji muszą być gładkie w przestrzeni Współ. korelacji muszą zbiegać do zera dla dużych odległości Współczynniki korelacji nie powinny wykazywać nieuzasadnionych zmienności ze względu na kierunek czy lokalizacje. Najbardziej fundamentalne stany równowagi muszą być odzwierciedlone w macierzy B Współ. korelacji nie powinny prowadzić do nierzeczywistych wariancji błędów pierwszego przybliżenia dla wszystkich parametrów jakie są obserwowane.

59
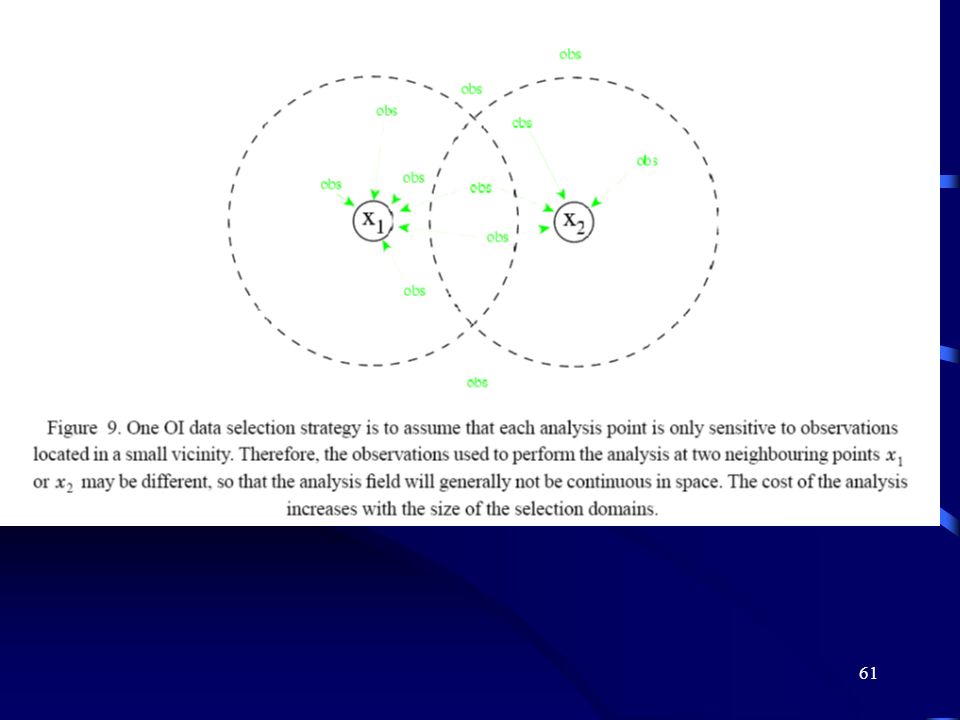
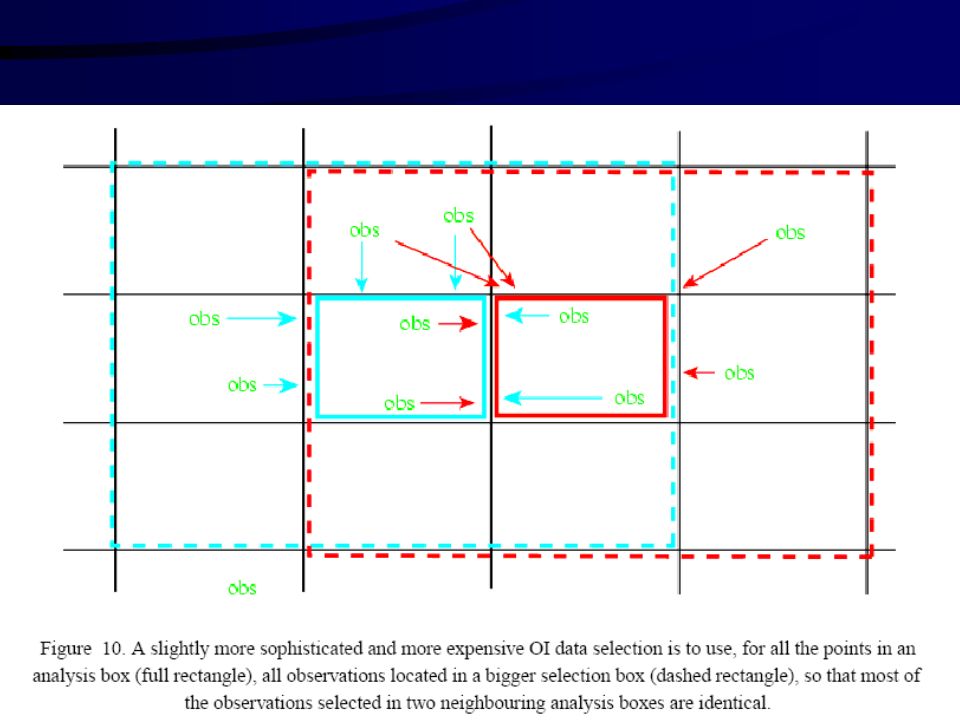
Analiza optymalna -Optimal interpolation Analysis (OI)
Fundamentalną hipoteza metody OI jest stwierdzenie, iż dla każdej zmiennej modelu tylko kilka obserwacji jest istotnych dla oszacowania innowacji (kolejnej poprawki) analizy. Jest to realizowane w następujący sposób: Dla każdej zmiennej stanu x(i) wybieramy małą liczbę pi obserwacji używając kryteriów empirycznych. Dla każdego ciągu punktów pi obliczamy: różnice [y-H(xb)]i pi kowariancji błędów przybliżenia zerowego (i-ty wiersz macierzy BHT) pomiędzy zmienną modelu x(i) a zmianą modelu interpolowaną dla pi do punktów obserwacyjnych.
 analizy. Jest to realizowane w następujący sposób: Dla każdej zmiennej stanu x(i) wybieramy małą liczbę pi obserwacji używając kryteriów empirycznych. Dla każdego ciągu punktów pi obliczamy: różnice [y-H(xb)]i. pi kowariancji błędów przybliżenia zerowego (i-ty wiersz macierzy BHT) pomiędzy zmienną modelu x(i) a zmianą modelu interpolowaną dla pi do punktów obserwacyjnych.")
60
Podmacierz kowariancji (pi x pi) pierwszego przybliżenia oraz obserwacji ( HBHT+R)
(3) Odwracamy powyższą podmacierz (4) Mnożymy ją przez i-ty wiersz macierzy BHT w celu obliczenia odpowiedniego wiersza macierzy K (patrz wzór na macierz K) Główna zaleta metody OI jest prostota implementacji oraz relatywnie niski koszt obliczeń jeśli dokonana się prawidłowych założeń. W metodzie OI poszukujemy macierzy wagowej K, która minimalizuje kowariancje błędów analizy!!
 Odwracamy powyższą podmacierz. (4) Mnożymy ją przez i-ty wiersz macierzy BHT w celu obliczenia odpowiedniego wiersza macierzy K (patrz wzór na macierz K) Główna zaleta metody OI jest prostota implementacji oraz relatywnie niski koszt obliczeń jeśli dokonana się prawidłowych założeń. W metodzie OI poszukujemy macierzy wagowej K, która minimalizuje kowariancje błędów analizy!!")
63
Przykłady I Rozważmy problem skalarny, w którym mamy jeden punkt pomiarowy y zlokalizowany w punkcie analizy oraz znamy pierwsze przybliżenie xb. Dodatkowo zakładamy iż znamy statystyki błędów wielkości y oraz xb. Analiza dana jest wzorem: w terminologii metody OI mamy:

64
Wariancja analizy Zakładając następujące wartości
Wartość analizy jest pomiędzy wartościami pierwszego przybliżenia oraz wartości pomiarowej, przy czym bliżej tej ostatniej (ze względu na mniejszy błąd) Wartość analizy ma większe prawdopodobieństwo i mniejszą wariancje niż wartości pierwszego przybliżenia oraz obserwacji.
 Wartość analizy ma większe prawdopodobieństwo i mniejszą wariancje niż wartości pierwszego przybliżenia oraz obserwacji.")
65
Przykład II Rozważmy jeden punkt obserwacyjny oraz dwa punkty analizy zlokalizowane pomiędzy punktem obserwacyjnym Znamy wartości przybliżenia zerowego w tych punktach: xb1, xb2. Dokonujemy liniowej interpolacji do punktu obserwacyjnego: Błąd obserwacji: Założyliśmy jest współ. korelacji

66
Wektora analizy dany jest wzorem:
Rozważamy trzy przypadki: (1) Punkt obserwacyjny jest zlokalizowany w pierwszym punkcie siatki (=1) ponadto błędy pierwszego przybliżenie w punkcie siatki 1 oraz 2 nie są skorelowane (=0) Rozwiązanie w punkcie (1) jest tożsame z uzyskanym w poprzednim przykładzie zaś w punkcie (2) jest równe pierwszemu przybliżeniu gdyż nie mamy tam żadnej informacji obserwacyjnej.
 Punkt obserwacyjny jest zlokalizowany w pierwszym punkcie siatki (=1) ponadto błędy pierwszego przybliżenie w punkcie siatki 1 oraz 2 nie są skorelowane (=0) Rozwiązanie w punkcie (1) jest tożsame z uzyskanym w poprzednim przykładzie zaś w punkcie (2) jest równe pierwszemu przybliżeniu gdyż nie mamy tam żadnej informacji obserwacyjnej.")
67
(2) Punkt obserwacyjny jest zlokalizowany w pierwszym punkcie siatki (=1) jednak błędy pierwszego przybliżenie w punkcie siatki 1 oraz 2 są skorelowane (0) W punkcie (1) rozwiązanie jest analogiczne jak poprzednio. W punkcie (2) jest równe pierwszemu przybliżeniu plus współczynnik korelacji mnożony przez innowacje analizy. W tym przypadku widzimy jaka rolę ogrywa współczynnik korelacji w dystrybucji przestrzennej wartości obserwacyjnej. (3) Punkt obserwacyjny jest zlokalizowany pomiędzy pierwszym i drugim punktem siatki (1) zaś błędy pierwszego przybliżenie w punkcie siatki 1 oraz 2 nie są skorelowane (=0)
 rozwiązanie jest analogiczne jak poprzednio. W punkcie (2) jest równe pierwszemu przybliżeniu plus współczynnik korelacji mnożony przez innowacje analizy. W tym przypadku widzimy jaka rolę ogrywa współczynnik korelacji w dystrybucji przestrzennej wartości obserwacyjnej. (3) Punkt obserwacyjny jest zlokalizowany pomiędzy pierwszym i drugim punktem siatki (1) zaś błędy pierwszego przybliżenie w punkcie siatki 1 oraz 2 nie są skorelowane (=0)")
68
W ostatnim przypadku innowacja analizy jest proporcjonalna odpowiednio do oraz -1.
Z ogólnego rozwiązania w tym przykładzie wynika, że operator interpolacji oraz współczynnik korelacji błędów mają wkład do wartości analizy W przypadku gdy mamy n punktów siatki operator liniowej interpolacji wpływa na wartości analizy tylko w sąsiedztwie obserwacji podczas gdy współczynnik korelacji błędów odpowiada za dystrybucję informacji obserwacyjnych tak daleko jak tylko ma on wartości niezerowe.

69
Przykład III – pole ciśnienia
Załóżmy, że mamy stacje obserwacyjne tylko na lądzie (czerwone punkty) i chcemy wyznaczyć wartość ciśnienia w punkcie A. Wykorzystując analizę obiektywną która w tym przypadku jest zwykłą ekstrapolacją danych obserwacyjnych. Jest ona odzwierciedleniem spadku ciśnienia w kierunku linii brzegowej. Dlatego też otrzymujemy wartość ciśnienia w punkcie A równą 974 hPa. Podczas gdy poprawna wartość wynosi 986 hPa!
 i chcemy wyznaczyć wartość ciśnienia w punkcie A. Wykorzystując analizę obiektywną która w tym przypadku jest zwykłą ekstrapolacją danych obserwacyjnych. Jest ona odzwierciedleniem spadku ciśnienia w kierunku linii brzegowej. Dlatego też otrzymujemy wartość ciśnienia w punkcie A równą 974 hPa. Podczas gdy poprawna wartość wynosi 986 hPa!")
70
Przykład IV - OI Rozważmy prosty przykład optymalnej interpolacji wartości obserwacyjnych. Początkowo wszystkie trzy punkty obserwacyjne są w jednakowej odległość od siebie oraz pozbawione są błędów. W tym przypadku wszystkie schematy analizy obiektywnej prowadzą do jednakowych wag W.

71
Jeśli zaczniemy przesuwać punkty 2 i 3 w stronę siebie
Jeśli zaczniemy przesuwać punkty 2 i 3 w stronę siebie. Zmianie ulegać będą również wagi W. W metodzie OI obserwacje w punktach 1 i 2 stają się bardziej skorelowane. Przez co zawierają mniej niezależnych informacji co prowadzi do redukcji wag.

72
Podsumowanie – analiza obiektywna

73
Schematic of Data Assimilation System
Observation minus Forecast Data Stream 1 (Assimilation) Statistical Analysis Analysis & (Observation Minus Analysis) Error Covariance Quality Control Data Stream 2 (Monitoring) Model Forecast Forecast / Simulation
 Statistical. Analysis. Analysis. & (Observation. Minus. Analysis) Error. Covariance. Quality Control. Data Stream 2. (Monitoring) Model. Forecast. Forecast / Simulation.")
74
Goddard Ozone Data Assimilation System
TOMS/SBUV POAM/MIPAS Ozone Data Sciamachy MLS Obs - Forecast Analysis Increments Forecast & Observation Error Models Statistical Analysis Q.C. Statistical Analysis Tracer Model Short-term Forecast (15 minutes) Winds Temperature HALOE Sondes “Analysis” Long-term forecast BALANCE, BALANCE, BALANCE!
 Winds. Temperature. HALOE. Sondes. Analysis Long-term forecast. BALANCE, BALANCE, BALANCE!")
Podobne prezentacje