Pobierz prezentację
1
Wprowadzenie System rozproszony jest kolekcją niezależnych, autonomicznych komputerów, które dla użytkownika prezentują się jak jeden komputer. Można wyróżnic dwa aspekty tej definicji: sprzętowy – komputery są autonomiczne użytkownika – dla użytkownika system sprawia wrażenie jakby pracował na jednym komputerze.

2
Klasyfikacja Architektur Równoległych
ze względu na mechanizm sterowania - SIMD - MIMD ze względu na organizacje przestrzeni adresowej - architektura message-passing - architektura ze współdzielona pamięcią - UMA - NUMA Ze względu na charakter sieci połączeniowej - statyczne - dynamiczne ze względu ziarnistość procesora - coarse-grain - medium-grain - fine-grain

3
Architektura ze współdzieloną pamięcią
Sieć połączeniowa Sieć połączeniowa P M M P P M M M P P M UMA NUMA

4
Typowa architektura message-passing
Sieć Połączeniowa P M P - Procesor M - Pamięć

5
Dynamiczne sieci połączeniowe
System z przełącznicą krzyżową Architektura szynowa Wielostanowa sieć połączeń

6
System z przełącznicą krzyżową
Pp-1 M0 M1 M2 M3 Element przełączający P4

7
Architektura Szynowa Pamięć Główna Szyna Procesor Procesor Procesor

8
Wielostanowa sieć połączeń
Banki Pamięci Stan 1 Stan 2 Stan n 1 p-1 b-1 Procesory

9
Koszt & Wydajność Wydajność Liczba procesorów przełącznica
wielostanowa szyna Koszt

10
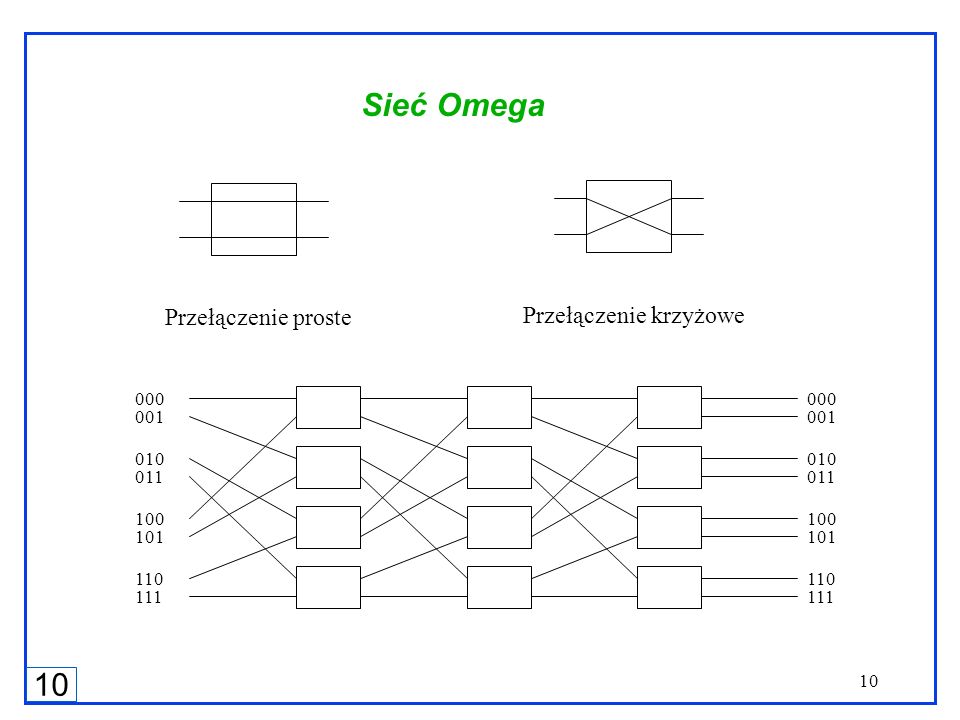
Sieć Omega Przełączenie proste Przełączenie krzyżowe 000 000 001 001
010 010 011 011 100 100 101 101 110 110 111 111
11
Sieć typu Mesh – krata (2D, 3D, z zapętleniami)
Sieci Statyczne Sieć pełna Sieć typu gwiazda Sieć typu magistrala Sieć typu Ring Sieć typu Mesh – krata (2D, 3D, z zapętleniami) Sieć typu Hypercube (Hiperkostka)
 Sieć typu Hypercube (Hiperkostka)")
12
Dwu-wymiarowa siec typu Mesh Dwu wymiarowa sieć Mesh z zapętleniami
Sieci Statyczne Sieć typu gwiazda Siec pełna Sieć typu magistrala Sieć typu ring Dwu-wymiarowa siec typu Mesh Dwu wymiarowa sieć Mesh z zapętleniami

13
Trzy wymiarowa sieć typu Mesh (krata) Sieć typu drzewo binarne
Sieci Statyczne Trzy wymiarowa sieć typu Mesh (krata) Procesor Element przełączający Sieć typu drzewo binarne
 Procesor. Element. przełączający. Sieć typu drzewo binarne.")
14
Sieć Hypercube (hiperkostka)
000 001 011 100 101 110 111 00 10 010 1 01 11 0-D hypercube 1-D hypercube 2-D hypercube 3-D hypercube 0100 1100 0110 1110 0000 0010 1000 1010 0101 0111 1101 1111 0001 0011 1001 1011 4-D hypercube

15
Miary Wydajności Czas wykonania równoległego (Tpar) jest czasem pomiędzy momentem rozpoczęcia obliczeń do momentu gdy ostatni procesor zakończy obliczenia Przyspieszenie (S) jest definiowane jako stosunek czasu niezbędnego do rozwiązania problemu z wykorzystaniem jednego procesora (Tseq) do czasu potrzebnego do rozwiązania tego samego problemu z wykorzystaniem systemu równoległego o "p" procesorach (Tpar) względne - Tseq jest czasem wykonania algorytmu równoległego na jednym z procesorów systemu wieloprocesorowego rzeczywiste - Tseq jest czasem wykonania „najlepszego” algorytmu sekwencyjnego na jednym z procesorów systemu równoległego bezwględne - Tseq jest czasem wykonania „najlepszego” algorytmu sekwencyjnego na „najlepszym” komputerze sekwencyjnym
 jest czasem pomiędzy momentem rozpoczęcia obliczeń do momentu gdy ostatni procesor zakończy obliczenia. Przyspieszenie (S) jest definiowane jako stosunek czasu niezbędnego do rozwiązania problemu z wykorzystaniem jednego procesora (Tseq) do czasu potrzebnego do rozwiązania tego samego problemu z wykorzystaniem systemu równoległego o p procesorach (Tpar) względne - Tseq jest czasem wykonania algorytmu równoległego na jednym z procesorów systemu wieloprocesorowego. rzeczywiste - Tseq jest czasem wykonania „najlepszego algorytmu sekwencyjnego na jednym z procesorów systemu równoległego. bezwględne - Tseq jest czasem wykonania „najlepszego algorytmu sekwencyjnego na „najlepszym komputerze sekwencyjnym.")
16
Miary Wydajności Efektywność programu równoległego (E) jest definiowana jako stosunek przyśpieszenia do liczby procesorów Koszt jest zwykle definiowany jako iloczyn równoległego czasu przetwarzania i liczby procesorów. Skalowalność systemu równoległego jest miarą jego zdolności do zwiększenia przyśpieszenia proporcjonalnie do liczby procesorów.

17
Amdahl’s Law – software approach
Kiedy wykonujemy program równoległy możemy wyróżnić dwie części: część sekwencyjną (Pseq), która musi się wykonywać tylko na jednym procesorze oraz część równoległą (1-Pseq), która jest wykonywana niezależnie na wielu procesorach. Załóżmy, że jeśli wykonujemy ten program na jednym procesorze czas jego wykonania wynosi t1 (czas wykonania sekwencyjnego). Niech p oznacza liczbę procesorów użytych podczas równoległego wykonania programu, wtedy jego czas wykonania równoległego wyraża się wzorem: Stąd przyspieszenie wyraża się wzorem
, która musi się wykonywać tylko na jednym procesorze oraz część równoległą (1-Pseq), która jest wykonywana niezależnie na wielu procesorach. Załóżmy, że jeśli wykonujemy ten program na jednym procesorze czas jego wykonania wynosi t1 (czas wykonania sekwencyjnego). Niech p oznacza liczbę procesorów użytych podczas równoległego wykonania programu, wtedy jego czas wykonania równoległego wyraża się wzorem: Stąd przyspieszenie wyraża się wzorem.")
18
Gustafson Speedup Załóżmy, że czas wykonania programu równoległego z uzyciem p procesorów wyraża się wzorem Pseq + Ppar = 1, gdzie Pseq oznacza sekwencyjną część programu, a Ppar równoległą. Czas wykonania sekwencyjnego (z użyciem jednego procesora) wynosi Pseq + p*Ppar Stąd otrzymujemy następująca formułę na przyspieszenie
 wynosi Pseq + p*Ppar. Stąd otrzymujemy następująca formułę na przyspieszenie.")
19
Skalowalność Systemów Równoległych
Rozważmy problem dodawania n liczb z wykorzystaniem architektury Hypercube W pierwszym kroku każdy z procesorów dodaje lokalnie n/p liczb, w kolejnych krokach połowa z wyliczonych sum częściowych jest przesyłana do sąsiednich procesorów i następnie wykonywana jest operacja dodawania. Procedura się kończy gdy jeden wyróżniony procesor wyliczy sumę końcową (p oznacza liczbę procesorów) Załóżmy, że czasy dodania dwóch liczb oraz komunikacji pomiędzy sąsiednimi procesorami są równe i wynoszą jedną umowną jednostkę czasu. Stąd dodanie n/p liczb na każdym z procesorów wynosi n/p - 1 Podobnie „p” sum częściowych jest dodawanych w log2p krokach (jedno dodawanie i jedno przesłanie)
 Załóżmy, że czasy dodania dwóch liczb oraz komunikacji pomiędzy sąsiednimi procesorami są równe i wynoszą jedną umowną jednostkę czasu. Stąd dodanie n/p liczb na każdym z procesorów wynosi n/p - 1. Podobnie „p sum częściowych jest dodawanych w log2p krokach (jedno dodawanie i jedno przesłanie)")
20
Skalowalność Systemów Równoległych
Stąd łączny czas przetwarzania równoległego może być aproksymowany przez: Ponieważ czas wykonania sekwencyjnego można aproksymować przez n wzory na przyspieszenie i efektywność są następujące: Powyższe równania mogą być użyte do wyliczenia przyspieszenia i efektywności dla każdej pary n i p.

21
Skalowalność Systemów Równoległych
zależność liniowa n = 512 n = 320 n = 192 n = 64 S p Przyśpieszenie w funkcji liczby procesorów

22
Skalowalność Systemów Równoległych
Efektywność jako funkcja n i p n p = p = p = p = 16 p = 32 Dla danego problemu o stałym rozmiarze, przyspieszenie nie rośnie liniowo wraz ze zwiększającą się liczba procesorów Dla stałej liczby procesorów rośnie przyspieszenie i efektywność gdy zwiększamy rozmiaru problemu.

23
Skalowalność Systemów Równoległych
System równoległy jest skalowalny jeśli utrzymuje stałą efektywność przy jednoczesnym zwiększanie się liczby procesorów oraz rozmiaru problemu. Skalowalność systemu równoległego jest miarą jego zdolności do zwiększenia przyśpieszenia proporcjonalnie do liczby procesorów. Skalowalność odzwierciedla zdolność systemu równoległego do efektywnego wykorzystania zwiększającej się liczby procesorów.

24
Który z komputerów jest lepszy ? O ile ?
Inne problemy Który z komputerów jest lepszy ? O ile ? Czy każdy z programów jest równie ważny ?


, gdzie X jest liczbą osób w rodzinie, a Y liczbą izb w mieszkaniu. Niech f.r.p. tej zmiennej.>")


















