Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Algorytmy i Struktury Danych
Wykład 4

2
Kopiec

3
Kopiec [ang. heap] Struktura drzewa binarnego
Wartość każdego węzła jest większa bądź równa wartości węzłów potomnych innymi słowy rodzic (węzeł nadrzędny) jest starszy niż dzieci (węzły podrzędne). Inne nazwy to sterta, stóg.
![Kopiec [ang. heap] Struktura drzewa binarnego](http://slideplayer.pl/slide/2763792/10/images/3/Kopiec+%5Bang.+heap%5D+Struktura+drzewa+binarnego.jpg "Wartość każdego węzła jest większa bądź równa wartości węzłów potomnych innymi słowy rodzic (węzeł nadrzędny) jest starszy niż dzieci (węzły podrzędne). Inne nazwy to sterta, stóg.")
4
Kopiec implementacja tablicowa oraz indeksy do wierzchołków
korzeń – 1, ojciec dowolnego wierzchołka i – i/2 (dzielenie całkowite), lewy syn wierzchołka i – 2*i, prawy syn wierzchołka i – 2*i+1.
, lewy syn wierzchołka i – 2*i, prawy syn wierzchołka i – 2*i+1.")
5
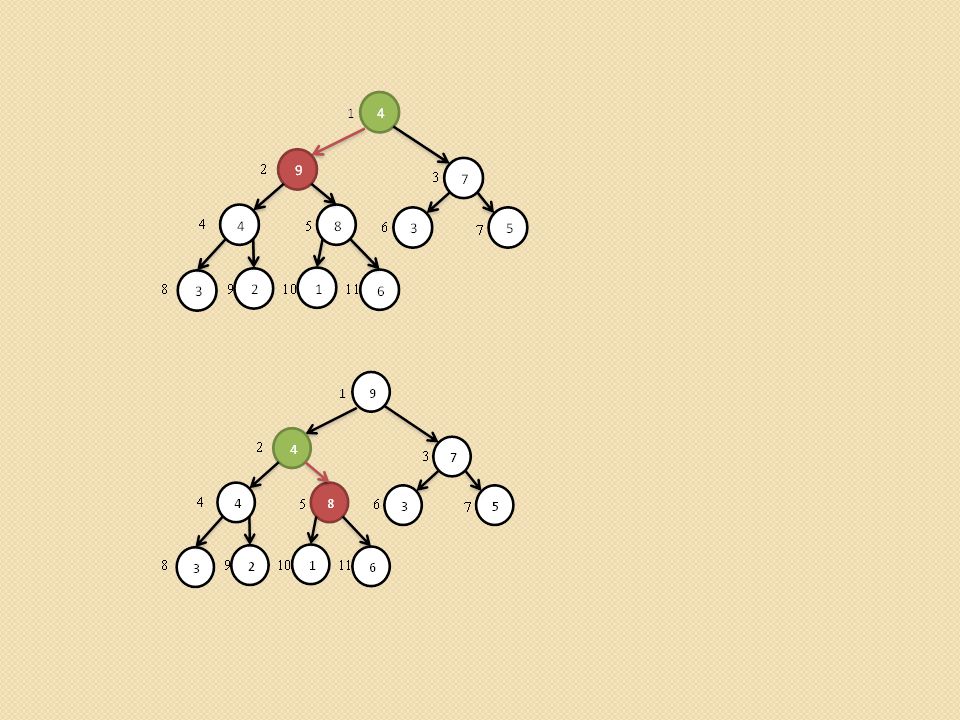
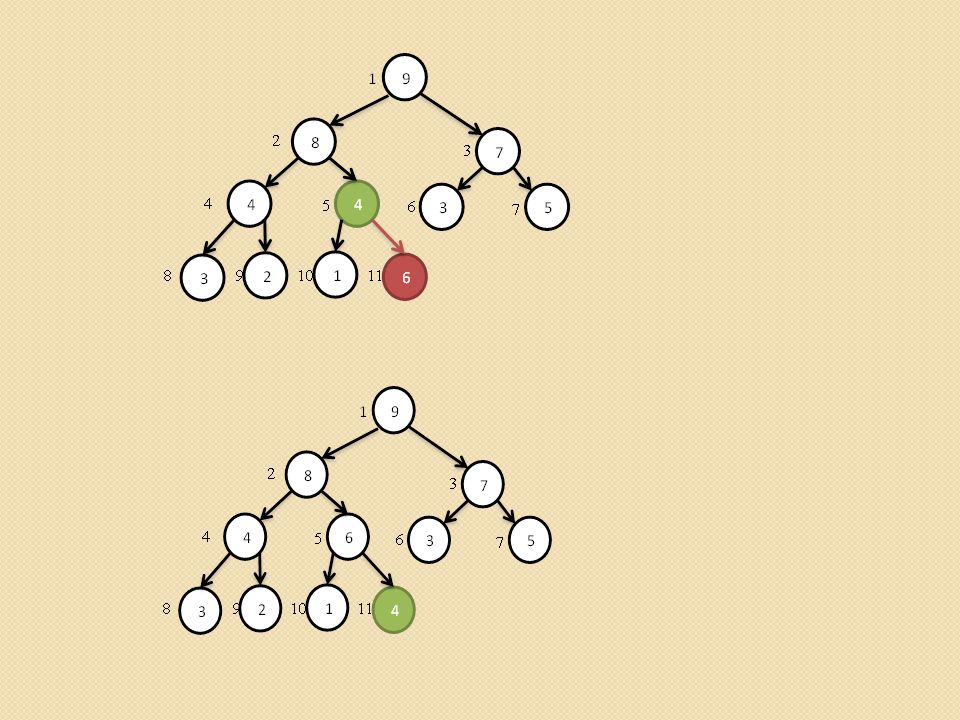
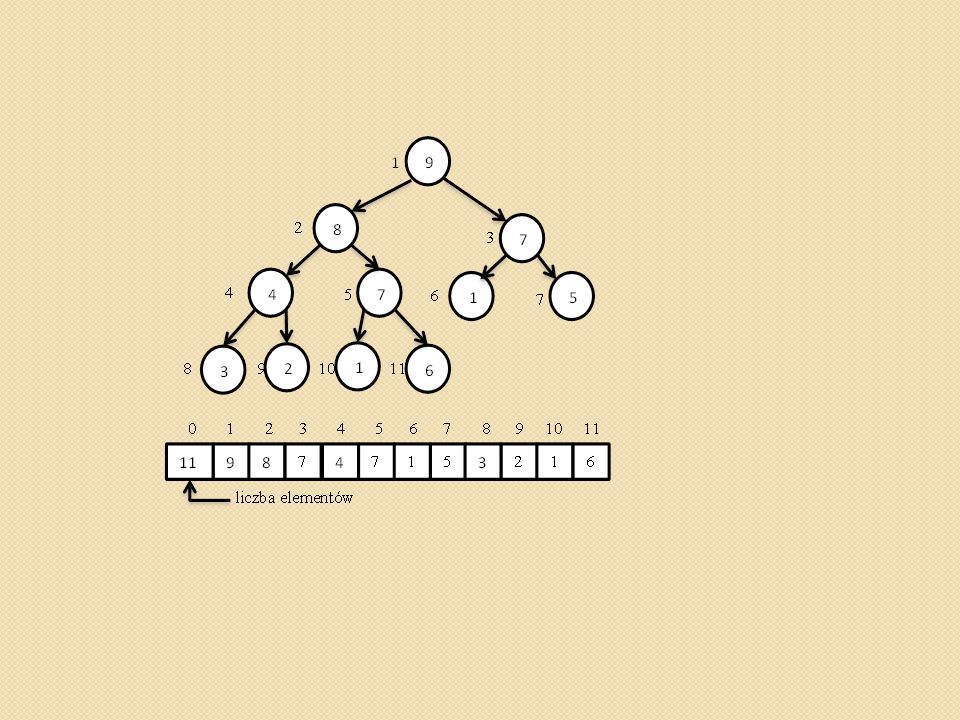
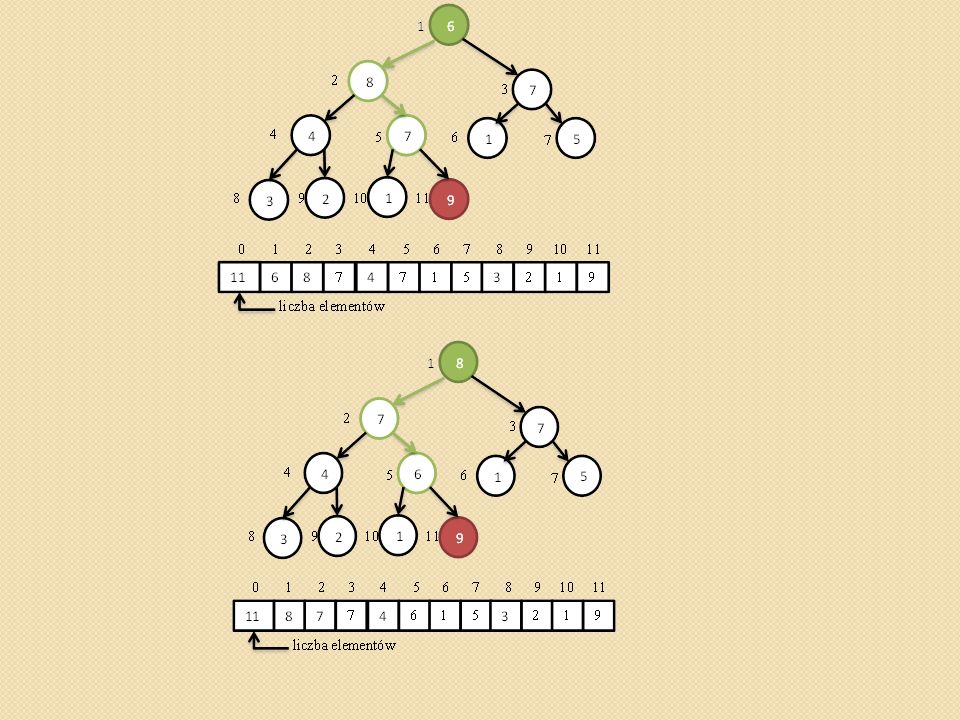
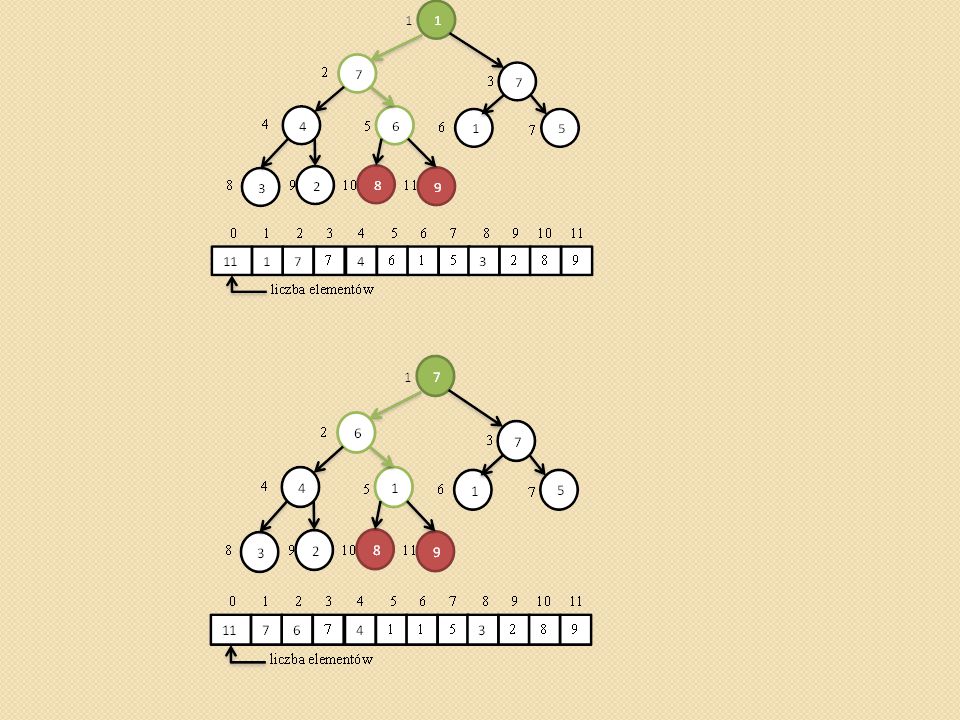
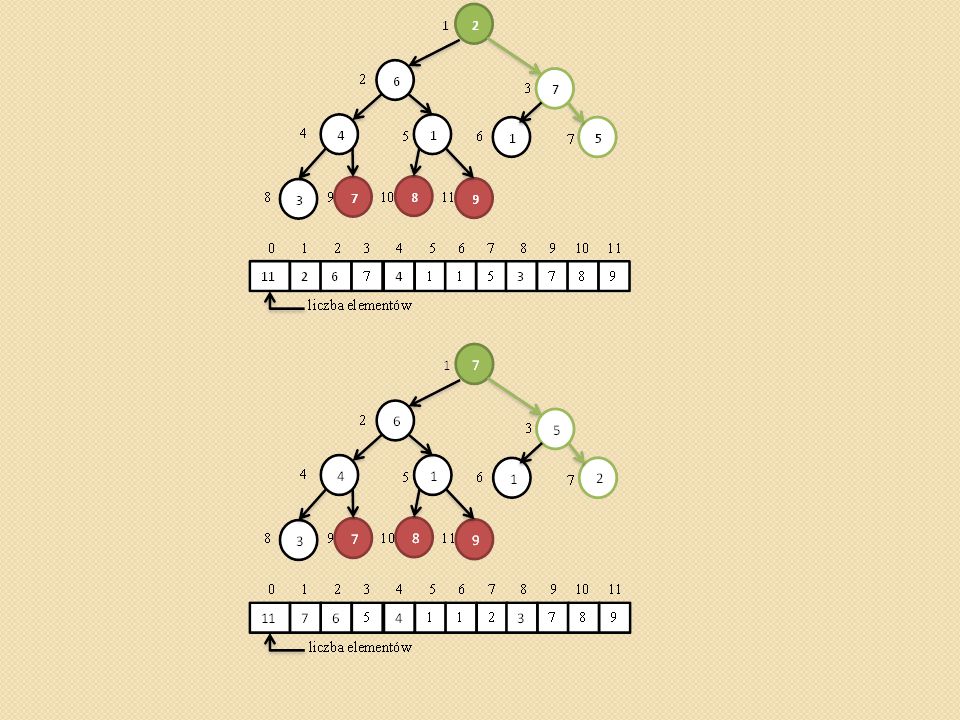
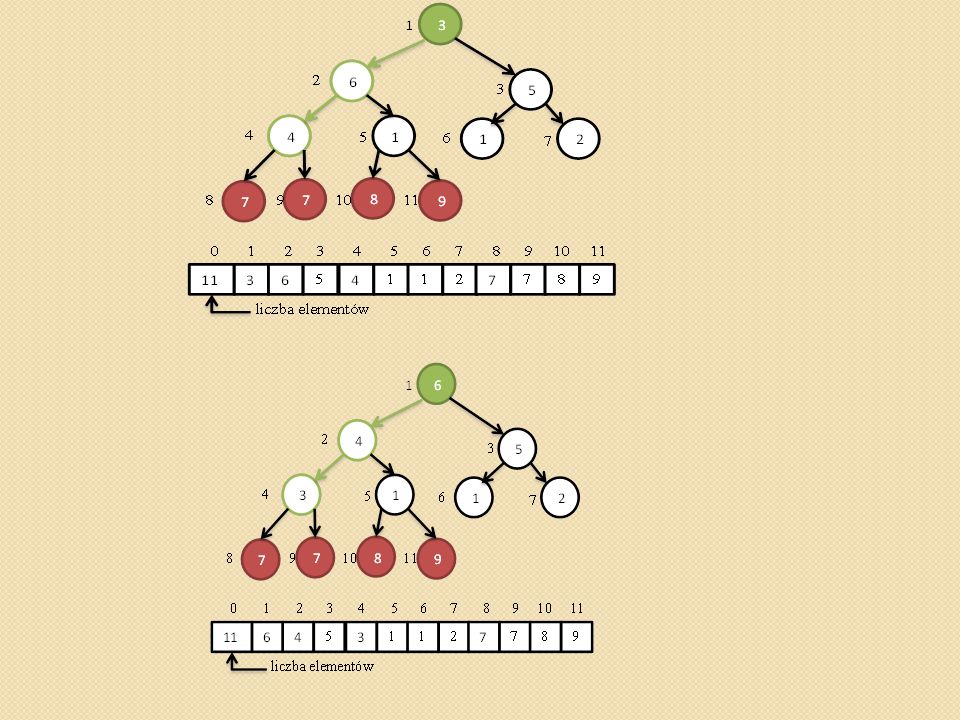
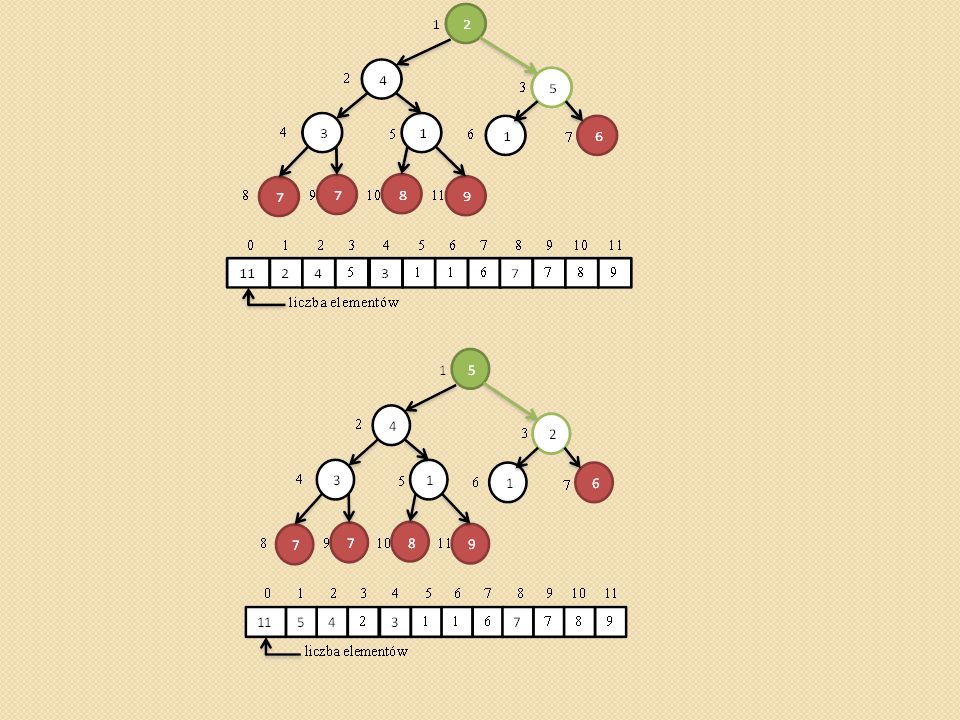
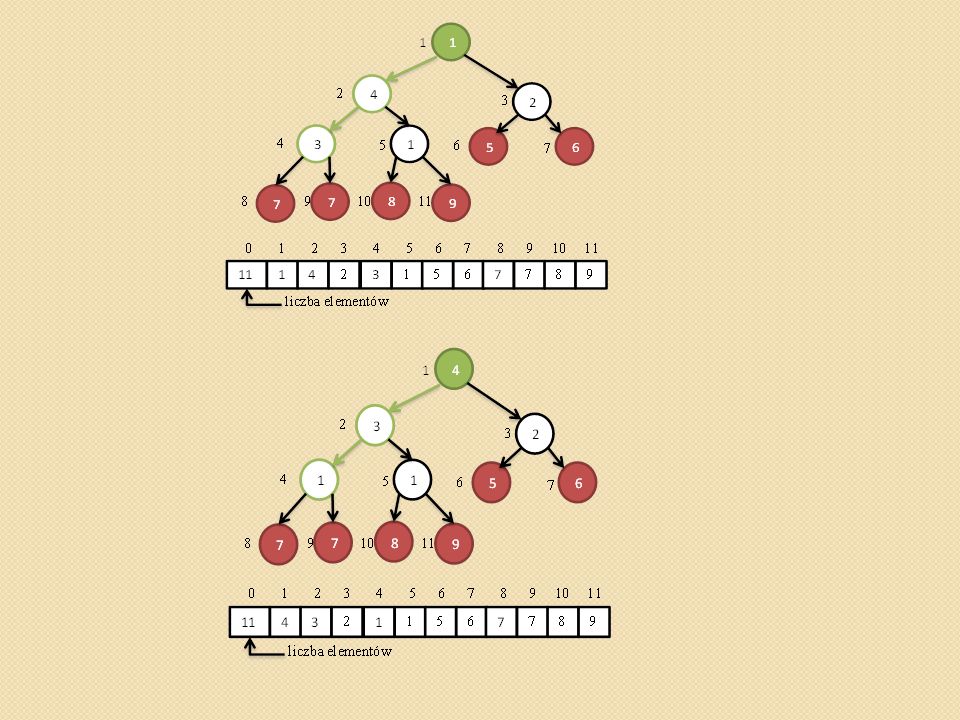
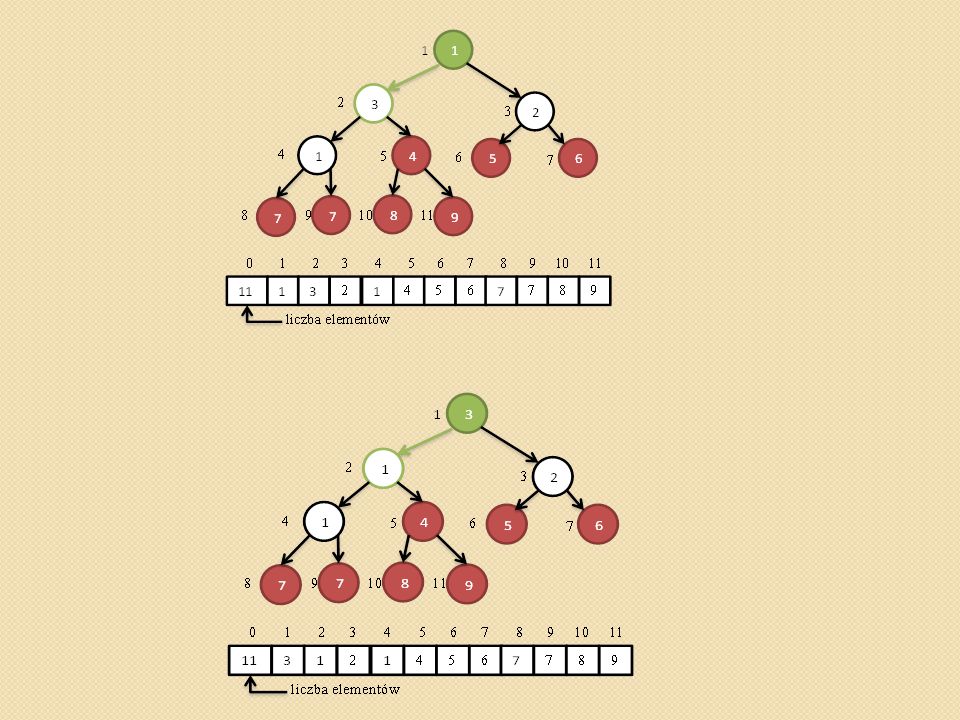
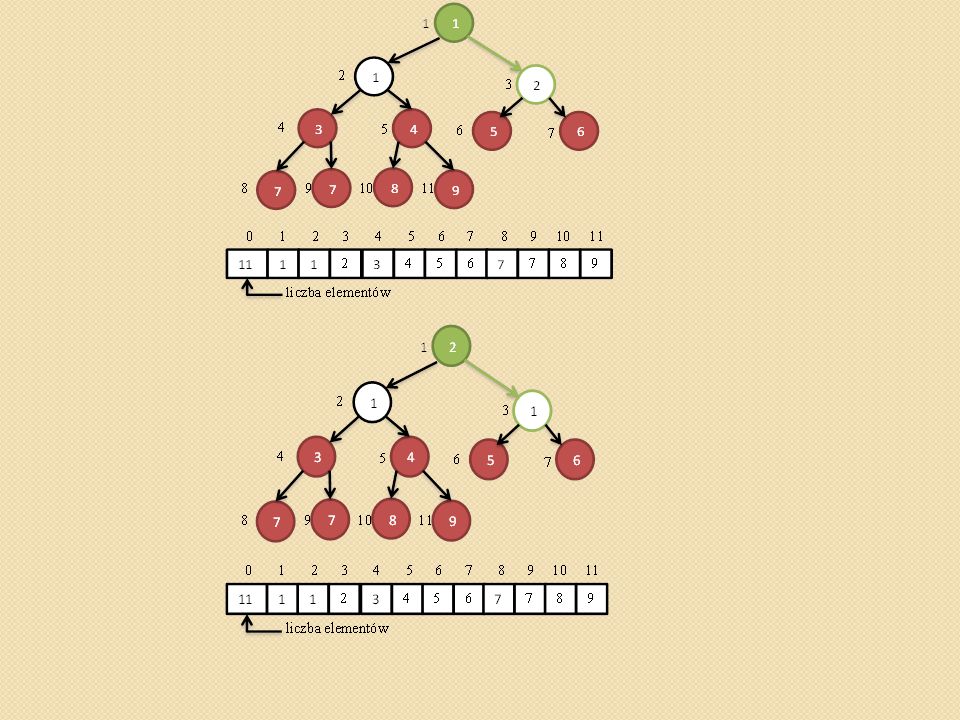
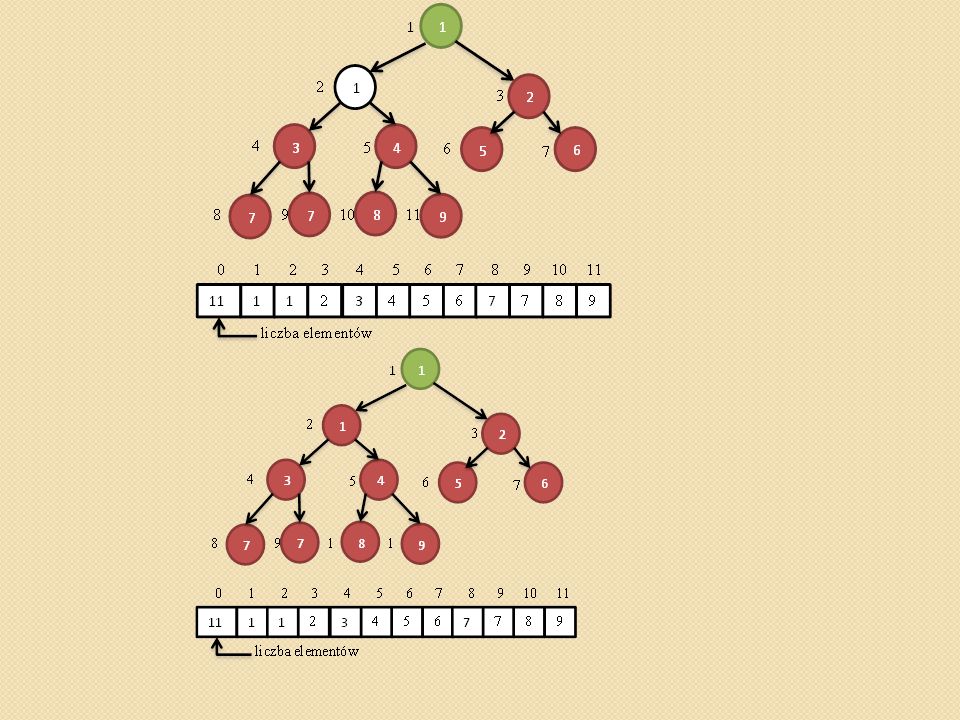
Przywracanie własności kopca (ang. heapify,).
void heapify(int heap[], int i) { /* heap[0] przechowuje rozmiar kopca maks - indeks do najwiekszego elementu i – indeks do ojca l- indeks do lewego syna, p – indeks do prawego syna */ Szukamy największego elementu spośród heap[i], heap[l], heap[p]. Jego indeks zapamiętujemy z zmiennej maks. Jednocześnie sprawdzamy czy l oraz p nie przekroczyły rozmiaru tablicy heap[] Jeśli maks różne od i to zamieniamy heap[maks] z heap[i] i wywołujemy procedurę heapify(heap, maks) }
 { /* heap[0] przechowuje rozmiar kopca maks - indeks do najwiekszego elementu i – indeks do ojca l- indeks do lewego syna, p – indeks do prawego syna */ Szukamy największego elementu spośród heap[i], heap[l], heap[p]. Jego indeks zapamiętujemy z zmiennej maks. Jednocześnie sprawdzamy czy l oraz p nie przekroczyły rozmiaru tablicy heap[] Jeśli maks różne od i to zamieniamy heap[maks] z heap[i] i wywołujemy procedurę heapify(heap, maks) }")
8
Budowanie kopca (Build heap)
void build_heap(int heap[]) { Elementowi heap[0] przypisz rozmiar kopca Zaczynając od ojca ostatniego elementu idąc do korzenia wywołaj procedurę heapify dla każdego elementu }
 { Elementowi heap[0] przypisz rozmiar kopca. Zaczynając od ojca ostatniego elementu idąc do korzenia. wywołaj procedurę heapify dla każdego elementu. }")
13
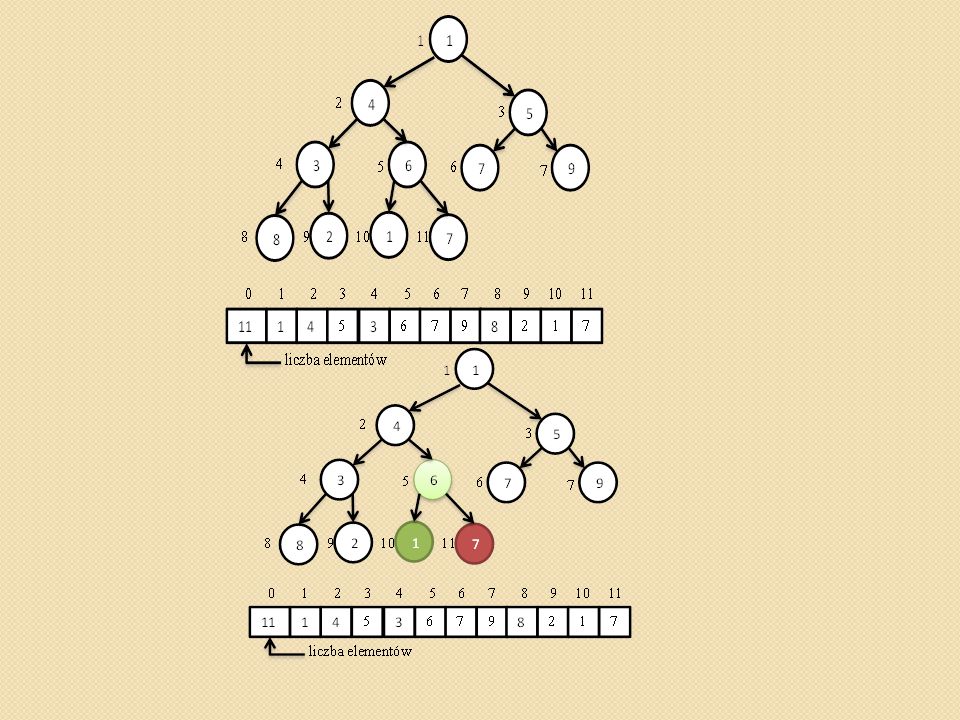
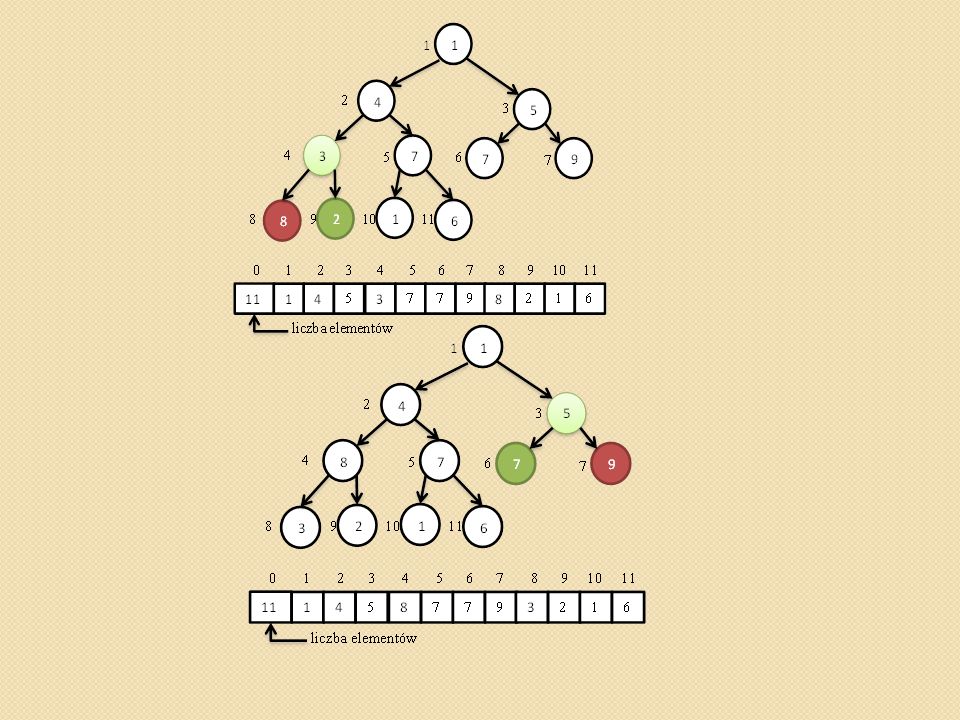
Sortowanie przez kopcowanie (heapsort)
void heapsort(int heap[]) { Zbuduj kopiec Zaczynając od ostatniego elementu kontynuuj do pierwszego Zamień ostatni element z pierwszym, Usuń ostatni element z kopca Przywróć własność kopca zaczynając od korzenia. }
 { Zbuduj kopiec Zaczynając od ostatniego elementu kontynuuj do pierwszego Zamień ostatni element z pierwszym, Usuń ostatni element z kopca Przywróć własność kopca zaczynając od korzenia. }")
23
Kolejka priorytetowa typu max
To struktura danych służąca do reprezentowania zbioru S elementów, z których każdy ma przyporządkowana wartość zwaną kluczem. Kolejka priorytetowa typu max to kolejka wykorzystująca kopiec typu max (własność rodzic jest starszy niż dzieci)
")
24
Operacje INSERT(S, x) – wstawia element x do zbioru S. Równoważny zapis S=SU{x}, MAXIMUM(s) – zwraca element zbioru S o największym kluczu EXTRACT-MAX(S) – usuwa i zwraca jednocześnie element zbioru S o największym kluczu. INCREASE-KEY(S, x, k) – zmienia wartość klucza elementu x na nową wartość k, o której zakłada się, że jest nie mniejsza niż aktualna wartość klucza x.
 – usuwa i zwraca jednocześnie element zbioru S o największym kluczu. INCREASE-KEY(S, x, k) – zmienia wartość klucza elementu x na nową wartość k, o której zakłada się, że jest nie mniejsza niż aktualna wartość klucza x.")
25
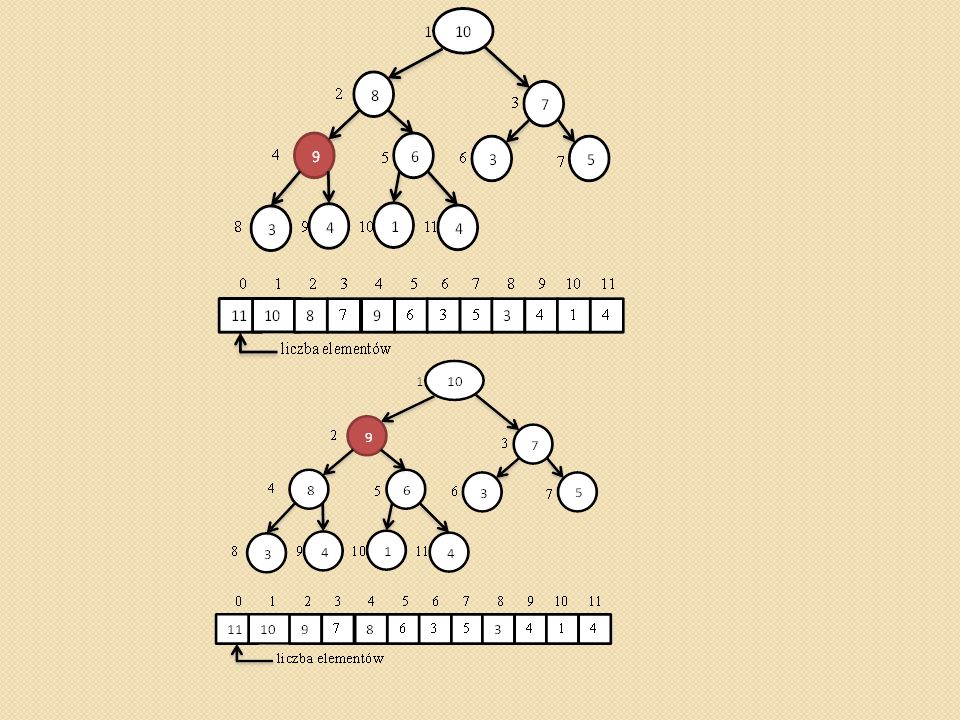
Operacje - pseudokod void HEAP-MAXIMUM(int heap[]) { return heap[1]; }
Czas działania: (1). void HEAP-EXTRACT-MAX(int heap[]) If heap[0]<=0 cout<<”Kopiec jest pusty”; max=kopiec[1]; kopiec[1]=kopiec[kopiec[0]]; kopiec[0]--; HEAPIFY(kopiec,1); return MAX; Czas działania: (lgn).
![Operacje - pseudokod void HEAP-MAXIMUM(int heap[]) { return heap[1]; }](http://slideplayer.pl/slide/2763792/10/images/25/Operacje+-+pseudokod+void+HEAP-MAXIMUM%28int+heap%5B%5D%29+%7B+return+heap%5B1%5D%3B+%7D.jpg "Czas działania: (1). void HEAP-EXTRACT-MAX(int heap[]) If heap[0]<=0. cout<< Kopiec jest pusty ; max=kopiec[1]; kopiec[1]=kopiec[kopiec[0]]; kopiec[0]--; HEAPIFY(kopiec,1); return MAX; Czas działania: (lgn).")
26
Operacje cd. - pseudokod
void HEAP-INCREASE-KEY-(int heap, int i, int key) { If key<kopiec[i]; cout<<”nowy klucz jest mniejszy od aktualnego klucza”; kopiec[i]=key; while (i>1) i (kopiec[ojciec(i)]<kopiec[i]) zamień kopiec[i] z kopiec[ojciec(i)] i=ojciec(i) } void MAX-HEAP-INSERT(int kopiec[], int key) kopiec[0]++; kopiec[kopiec[0]]=-∞; HEAP-INCREASE-KEY(kopiec,kopiec[0],key) } Czas działania: (lgn).
 { If key<kopiec[i]; cout<< nowy klucz jest mniejszy od aktualnego klucza ; kopiec[i]=key; while (i>1) i (kopiec[ojciec(i)]<kopiec[i]) zamień kopiec[i] z kopiec[ojciec(i)] i=ojciec(i) } void MAX-HEAP-INSERT(int kopiec[], int key) kopiec[0]++; kopiec[kopiec[0]]=-∞; HEAP-INCREASE-KEY(kopiec,kopiec[0],key) } Czas działania: (lgn).")
27
MAX-HEAP-INSERT

29
Kolejka priorytetowa typu min
Operacje: INSERT, MINIMUM EXTRACT-MIN DECREASE-KEY Wykorzystanie jako symulator zdarzeń

30
Algorytmy zachłanne Dokonuje wyboru, który w danej chwili wydaje się najkorzystniejszy. Lokalnie jest to optymalny wybór z nadzieją, że doprowadzi to do globalnego optymalnego rozwiązania. Nie zawsze jednak udaje się znaleźć optymalne rozwiązanie, chociaż dla wielu problemów jest ono wystarczające

31
Podstawy strategii zachłannej
Przedstawiamy problem optymalizacyjny w sposób, by dokonanie wyboru pozostawiało jeden podproblem do rozwiązania. Udowadniamy, że istnieje zawsze rozwiązanie optymalne pierwotnego problemu, za pomocą wyboru zachłannego, co oznacza, że jest to wybór bezpieczny. Demonstrujemy własność optymalnej struktury, pokazując, że wybierając w sposób zachłanny, to, co pozostaje, jest podproblemem, dla którego optymalne rozwiązanie wraz z dokonanym przez nas wyborem daje optymalne rozwiązanie pierwotnego problemu.

32
Własności Podczas gdy w dynamicznym programowaniu w każdym kroku podejmuje się decyzje, które zależą od rozwiązań lokalnych problemów w programowaniu zachłannym wybiera się opcję, która wydaję się najlepsza w danym kroku i dopiero potem rozwiązuje się podproblem. Stąd wybory podejmowane w zachłannych algorytmach mogą zależeć od dotychczasowych decyzji ale nie będą uzależnione od przyszłych wyborów ani od rozwiązań podproblemów. Optymalna podstruktura oznacza, że optymalne rozwiązanie problemu zawiera w sobie optymalne rozwiązania prodproblemów. Jest ona ważna zarówno dla algorytmów dynamicznych jak i zachłannych.

33
Schemat działania void greedy(W) { Rozw=; while(nie Znalazlem(Rozw) i W≠) Xi=Wybierz(W); if Pasuje(X) Rozw=Rozw{X}; } If Znalazlem(Rozw) return Rozw; else cout<<”nie ma rozwiązania”; Gdzie: W– zbiór danych wejściowych, Rozw – zbiór, który posłuży do konstrukcji rozwiązania, X- element zbioru Wybierz(D) – funkcja wybierająca optymalnie element ze zbioru D i usuwająca go z niego, Pasuje(X) – Czy wybierając X uda się skompletować rozwiązanie cząstkowe, aby odnaleźć, co najmniej jedno rozwiązanie globalne? Znalazlem(S) – Czy S jest rozwiązaniem zadania?
 { Rozw=; while(nie Znalazlem(Rozw) i W≠) Xi=Wybierz(W); if Pasuje(X) Rozw=Rozw{X}; } If Znalazlem(Rozw) return Rozw; else cout<< nie ma rozwiązania ; Gdzie: W– zbiór danych wejściowych, Rozw – zbiór, który posłuży do konstrukcji rozwiązania, X- element zbioru Wybierz(D) – funkcja wybierająca optymalnie element ze zbioru D i usuwająca go z niego, Pasuje(X) – Czy wybierając X uda się skompletować rozwiązanie cząstkowe, aby odnaleźć, co najmniej jedno rozwiązanie globalne Znalazlem(S) – Czy S jest rozwiązaniem zadania")
34
Programowanie dynamiczne a zachłanne

35
Problem plecakowy Dyskretny Po ang. (0-1 knapsack problem). Mamy do dyspozycji n przedmiotów. Każdy przedmiot i jest wart vi złotych i waży wi kilogramów. Zarówno vi jak i wi są nieujemne i całkowite. Nasze zadanie polega na spakowaniu do plecaka jak najbardziej wartościowych przedmiotów ale tak by nie przekroczyć W kilogramów. Uwaga przedmioty pakujemy w całości, więc musimy zdecydować czy dany przedmiot bierzemy (tak – 1) do plecaka czy nie bierzemy (nie – 0). Ponadto możemy użyć każdy przedmiot tylko jeden raz. Ciągły Ponownie mamy do dyspozycji n przedmiotów o odpowiednich wartościach i wadze. I tak samo jak poprzednio ładujemy plecak. Jednak tym razem możemy zabierać części ułamkowe przedmiotów (np. gdy mamy czekoladę to zamiast całej tabliczki bierzemy kilka jej kostek).
. Mamy do dyspozycji n przedmiotów. Każdy przedmiot i jest wart vi złotych i waży wi kilogramów. Zarówno vi jak i wi są nieujemne i całkowite. Nasze zadanie polega na spakowaniu do plecaka jak najbardziej wartościowych przedmiotów ale tak by nie przekroczyć W kilogramów. Uwaga przedmioty pakujemy w całości, więc musimy zdecydować czy dany przedmiot bierzemy (tak – 1) do plecaka czy nie bierzemy (nie – 0). Ponadto możemy użyć każdy przedmiot tylko jeden raz. Ciągły Ponownie mamy do dyspozycji n przedmiotów o odpowiednich wartościach i wadze. I tak samo jak poprzednio ładujemy plecak. Jednak tym razem możemy zabierać części ułamkowe przedmiotów (np. gdy mamy czekoladę to zamiast całej tabliczki bierzemy kilka jej kostek).")
36
Problem plecakowy

37
Dyskretny problem plecakowy

38
Ciągły problem plecakowy

39
Kody Huffmana Kody Huffmana służą do kompresji danych i dają oszczędności rzędu od 20% do 90%. Do kodowania wykorzystuje się częstotliwość występowania znaków. Częstotliwość zapisuje się w postaci liczby całkowitej lub w postaci ułamka oznaczającego prawdopodobieństwo wystąpienia liczby. Można też wykorzystać tabelę z obliczoną częstotliwością występowania liter dla danego języka np. polskiego lub angielskiego. Takie tabele wykorzystuje się też przy łamaniu szyfrów. Kod Huffmana jest kodem prefiksowym. Oznacza to, że żadne słowo kodowe nie może być prefiksem innego słowa kodowego .

40
Kodowanie znaków - przykład
Mamy dany plik z 100 znakami i danymi częstotliwościami występowania poszczególnych liter. Każdy znak możemy zakodować za pomocą kodu binarnego (w skrócie kodu) w postaci ciągu bitów zwanego słowem kodowym. znak a b c d e f częstość 46 11 12 17 8 6 słowo kodowe o stałej długości 000 001 010 011 100 101 słowo kodowe o zmiennej długości 110 1110 1111
 w postaci ciągu bitów zwanego słowem kodowym. znak. a. b. c. d. e. f. częstość słowo kodowe o stałej długości słowo kodowe o zmiennej długości")
41
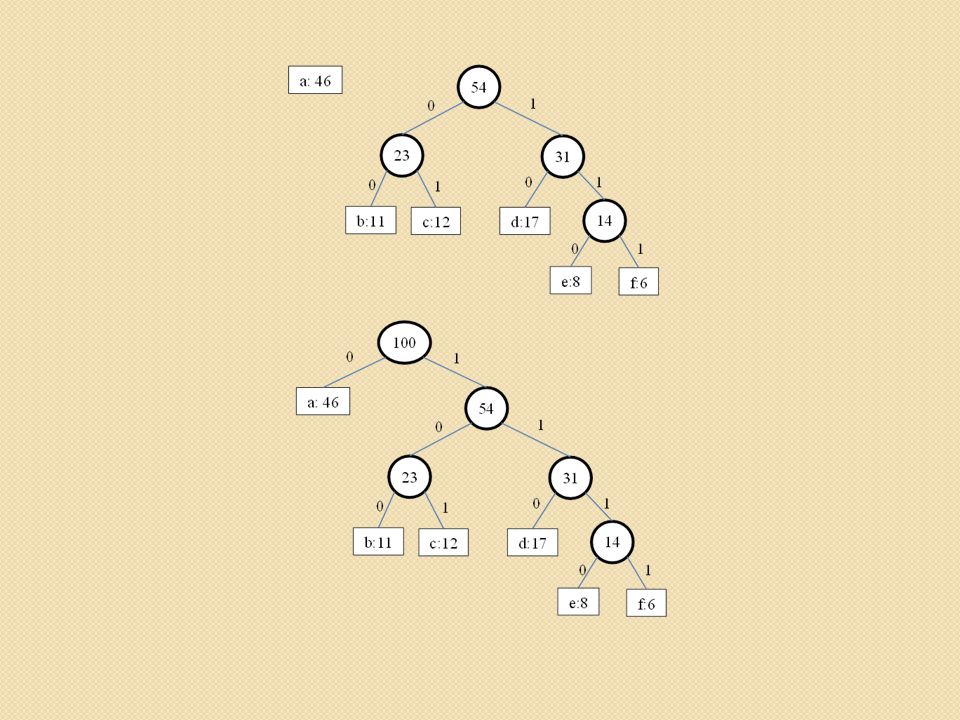
Kod Huffmana Podany kod będziemy reprezentować za pomocą drzewa binarnego, którego liście będą zawierać zakodowane znaki, natomiast binarne słowo kodowe dla znaku będzie odczytane jako prosta ścieżka od korzenia do danego znaku. Przyjmiemy, że 0 będzie oznaczać, „przejście do lewego syna” a 1 „przejście do prawego syna” w drzewie. Optymalny kod jest zawsze reprezentowany przez regularne drzewo binarne, w którym każdy węzeł wewnętrzny ma dwóch synów. Jeśli nasz alfabet oznaczymy przez C to drzewo optymalnego kodu prefiksowego ma dokładnie |C| liści, po jednym dla każdej litery alfabetu oraz dokładnie |C|-1 węzłów wewnętrznych.

42
Wzór na liczbę bitów potrzebnych do zakodowanie pliku:
𝐵 𝑇 = 𝑐∈𝐶 𝑧 𝑐 ∙ 𝑑 𝑇 (𝑐) gdzie: zc – częstotliwość wystąpienia znaku c, dT(c) oznacza głębokość liścia znaku c w drzewie T, jest to także długość słowa kodowego dla znaku c. c – znak z alfabetu C
 gdzie: zc – częstotliwość wystąpienia znaku c, dT(c) oznacza głębokość liścia znaku c w drzewie T, jest to także długość słowa kodowego dla znaku c. c – znak z alfabetu C.")
43
Obliczanie kodu Huffmana
Przyjmijmy, że C jest zbiorem n znaków i że każdy znak cC jest obiektem o znanej częstotliwości (liczbie wystąpień) zc. Algorytm buduje drzewo T, odpowiadające optymalnemu kodowi metodą wstępującą – od liści do korzenia. Rozpoczynamy od zbioru |C| liści i wykonujemy |C|-1 „scaleń” aż otrzymamy końcowe drzewo. W algorytmie korzystamy z kolejki priorytetowej Q typu min, z atrybutami z w roli kluczy, do wyznaczania dwóch obiektów o najmniejszej liczbie wystąpień, które należy scalić. W wyniku tego działania otrzymujemy nowy obiekt, którego liczba wystąpień to suma liczby wystąpień jego składowych
 zc. Algorytm buduje drzewo T, odpowiadające optymalnemu kodowi metodą wstępującą – od liści do korzenia. Rozpoczynamy od zbioru |C| liści i wykonujemy |C|-1 „scaleń aż otrzymamy końcowe drzewo. W algorytmie korzystamy z kolejki priorytetowej Q typu min, z atrybutami z w roli kluczy, do wyznaczania dwóch obiektów o najmniejszej liczbie wystąpień, które należy scalić. W wyniku tego działania otrzymujemy nowy obiekt, którego liczba wystąpień to suma liczby wystąpień jego składowych.")
44
znak a b c d e f częstość 46 11 12 17 8 6

47
Pseudokod void Huffman (string C) { n=|C| Q=C
for(int i=1; i<n; i++) utwórz nowy węzeł t t.left=x=EXTRACT-MIN(Q) t.right=y=EXTRACT-MIN(Q) t.z=x.z+y.z INSERT(Q) return EXTRACT-MIN(Q) }
 utwórz nowy węzeł t. t.left=x=EXTRACT-MIN(Q) t.right=y=EXTRACT-MIN(Q) t.z=x.z+y.z. INSERT(Q) return EXTRACT-MIN(Q) }")
48
Dekodowanie Przykładowy tekst: | 0 | 1111 | 100 | 100 | 0 | 0 a a f b b b a a

49
Tablice z haszowaniem Haszowanie- często nazywane też jest mieszaniem lub rozpraszaniem. W kompilatorach utrzymuje się tablicę symboli, w której kluczami elementów są dowolne ciągi znaków odpowiadające identyfikatorom. Tablica z haszowaniem jest strukturą służącą do reprezentacji słowników. Wyszukiwanie elementu w tablicy z haszowaniem może trwać tyle i le wyszukiwanie na liście z dowiązaniami - (n) w najgorszym wypadku to w praktyce daje znakomite wyniki. Tablica z haszowaniem jest uogólnieniem zwyczajnej tablicy. Adresowanie bezpośrednie umożliwia uzyskanie dostępu do dowolnej pozycji w tablicy w czasie O(1). Jednak rozmiar takiej tablicy zależny jest od każdej możliwej wartości klucza. Natomiast w tablicy z haszowaniem rozmiar zwykle jest proporcjonalny do liczby elementów, które zawiera. Indeks tablicy, pod którym znajduje się element, nie jest jego kluczem ale może być obliczony na podstawie klucza.
 w najgorszym wypadku to w praktyce daje znakomite wyniki. Tablica z haszowaniem jest uogólnieniem zwyczajnej tablicy. Adresowanie bezpośrednie umożliwia uzyskanie dostępu do dowolnej pozycji w tablicy w czasie O(1). Jednak rozmiar takiej tablicy zależny jest od każdej możliwej wartości klucza. Natomiast w tablicy z haszowaniem rozmiar zwykle jest proporcjonalny do liczby elementów, które zawiera. Indeks tablicy, pod którym znajduje się element, nie jest jego kluczem ale może być obliczony na podstawie klucza.")
50
Tablice z adresowaniem bezpośrednim
Adresowanie bezpośrednie jest prostą metodą, która jest skuteczna przy małej liczbie kluczy. Załóżmy że mamy klucze w zbiorze (Uniwersum kluczy) U={0,1,…,m-1} wówczas możemy tablicę reprezentować jako tablicę T[0..m-1], W której każdej pozycji odpowiada klucz należący do zbioru U. Na pozycji k w tablicy znajduje się wskaźnik do elementu o kluczu k. Jeśli do zbioru nie należy żaden element o kluczu k, to T[k]=NIL. Przy dużym uniwersum kluczy U przechowywanie w pamięci komputera tablicy T o rozmiarze |U| może okazać się nie możliwe.
 U={0,1,…,m-1} wówczas możemy tablicę reprezentować jako tablicę T[0..m-1], W której każdej pozycji odpowiada klucz należący do zbioru U. Na pozycji k w tablicy znajduje się wskaźnik do elementu o kluczu k. Jeśli do zbioru nie należy żaden element o kluczu k, to T[k]=NIL. Przy dużym uniwersum kluczy U przechowywanie w pamięci komputera tablicy T o rozmiarze |U| może okazać się nie możliwe.")
51
Operacje void DIRECT-ADDRESS-SEARCH(int T[m], int k) { return T[k] }
void DIRECT-ADDRESS-INSERT(int T[m], int k) T[x.key]=x void DIRECT-ADDRESS-DELETE(int T[m], int k) T[x.key]=NIL Każda z tych operacji działa w czasie O(1).
![Operacje void DIRECT-ADDRESS-SEARCH(int T[m], int k) { return T[k] }](http://slideplayer.pl/slide/2763792/10/images/51/Operacje+void+DIRECT-ADDRESS-SEARCH%28int+T%5Bm%5D%2C+int+k%29+%7B+return+T%5Bk%5D+%7D.jpg "void DIRECT-ADDRESS-INSERT(int T[m], int k) T[x.key]=x. void DIRECT-ADDRESS-DELETE(int T[m], int k) T[x.key]=NIL. Każda z tych operacji działa w czasie O(1).")
52
Tablice z haszowaniem Pamięć zajmowaną przez tablicę z haszowaniem można ograniczyć do (|K|), a wyszukiwanie w takiej tablicy nadal będzie działać w czasie O(1). W tablicy z adresowaniem bezpośrednim, element o kluczu k umieszcza się na pozycji o indeksie k. Natomiast w tablicy z haszowaniem element ten trafia na pozycję h(k) – gdzie h to funkcja haszująca, która oblicza pozycję klucza k. Funkcja ha odwzorowuje uniwersum kluczy U w zbiór pozycji tablicy z haszowaniem T[0..m-1] w sposób: h:U{0,1,…,m-1}, gdzie przeważnie rozmiar m tablicy z haszowaniem jest znacznie mniejszy niż |U|. Mówimy, że element o kluczu k jest haszowany na pozycję h(k); mówimy także, że h(k) jest wartością haszującą klucza k.
, a wyszukiwanie w takiej tablicy nadal będzie działać w czasie O(1). W tablicy z adresowaniem bezpośrednim, element o kluczu k umieszcza się na pozycji o indeksie k. Natomiast w tablicy z haszowaniem element ten trafia na pozycję h(k) – gdzie h to funkcja haszująca, która oblicza pozycję klucza k. Funkcja ha odwzorowuje uniwersum kluczy U w zbiór pozycji tablicy z haszowaniem T[0..m-1] w sposób: h:U{0,1,…,m-1}, gdzie przeważnie rozmiar m tablicy z haszowaniem jest znacznie mniejszy niż |U|. Mówimy, że element o kluczu k jest haszowany na pozycję h(k); mówimy także, że h(k) jest wartością haszującą klucza k.")
53
Tablice z haszowaniem

54
Rozwiązywanie kolizji metodą łańcuchową

55
Operacje słownikowe tablicy T
void CHAINED-HASH-INSERT(int t[], int x) wstaw x na początek listy T[h(x.key)] void CHAINED-HASH-SEARCH(int T[], int k) wyszukaj element o kluczu k na liście T[h(k)] void CHAINED-HASH-DELETE(int T[], int x) usuń x z listy T[h(x.key)]
 wstaw x na początek listy T[h(x.key)] void CHAINED-HASH-SEARCH(int T[], int k) wyszukaj element o kluczu k na liście T[h(k)] void CHAINED-HASH-DELETE(int T[], int x) usuń x z listy T[h(x.key)]")
56
Niech będzie dana tablica T o m pozycjach, w której znajduje się n elementów. Wówczas jej współczynnik zapełnienia określamy jako n/m tj. średnia liczba elementów w łańcuchu. Jeżeli losowo wybrany element z jednakowym prawdopodobieństwem trafia na każdą z m pozycji, niezależnie od tego, gdzie trafiają inne elementy to nazywa się to prostym równomiernym haszowaniem.

57
Funkcje haszujące - cechy
Funkcja haszująca powinna przede wszystkim spełniać założenie prostego równomiernego haszowania: losowo wybrany klucz jest z jednakowym prawdopodobieństwem odwzorowywany na każdą z m pozycji, niezależnie od odwzorowań innych kluczy. W praktyce rzadko udaje się spełnić ten warunek gdyż rzadko znamy rozkład prawdopodobieństwa pojawiania się kluczy. Jeśli znamy rozkład prawdopodobieństwa pojawiania się kluczy możemy je wykorzystać do wyboru funkcji haszującej. Z reguły funkcje haszujące wybiera się tak, by jej wartości były maksymalnie nie zależne od możliwych wzorców mogących występować w danych. Ponadto czasem wymaga się silniejszych warunków niż tylko proste równomierne haszowanie. Na przykład wymaga się aby „bliskim” (w pewnym sensie) kluczom odpowiadały znacznie od siebie oddalone wartości funkcji haszującej. Większość funkcji haszujących ma dziedzinę będącą zbiorem liczb naturalnych N={0,1,2,…}. Jeśli zaś kucze nie są liczbami naturalnymi to należy ustalić ich odwzorowanie w zbiór liczb naturalnych. Jeśli mamy klucze w postaci ciągów znaków to można każdemu znakowi przyporządkować odpowiadający mu kod ASCII.
 kluczom odpowiadały znacznie od siebie oddalone wartości funkcji haszującej. Większość funkcji haszujących ma dziedzinę będącą zbiorem liczb naturalnych N={0,1,2,…}. Jeśli zaś kucze nie są liczbami naturalnymi to należy ustalić ich odwzorowanie w zbiór liczb naturalnych. Jeśli mamy klucze w postaci ciągów znaków to można każdemu znakowi przyporządkować odpowiadający mu kod ASCII.")
58
Haszowanie modularne Dla klucza k daje wartość będącą resztą z dzielenie k przez m, gdzie m to liczba pozycji w tablicy. Można to zapisać wzorem: h(k)=k mod m. Jeśli w tablicy z haszowaniem jest m=12 pozycji, to dla klucza k=100 mamy h(k) =4. Należy dobrze wybrać wartość m. Jeśli m będzie potęgą 2czyli m=2p, to h(k) będzie liczbą, która powstaje z p najmniej znaczących bitów liczby k. Również wybór m=2p-1 jest zły, ponieważ permutacja znaków w k nie mienia wartości funkcji haszującej. Dlatego lepiej na m wybierać liczby pierwsze, które nie są zbyt bliskie potęgom 2.
=k mod m. Jeśli w tablicy z haszowaniem jest m=12 pozycji, to dla klucza k=100 mamy h(k) =4. Należy dobrze wybrać wartość m. Jeśli m będzie potęgą 2czyli m=2p, to h(k) będzie liczbą, która powstaje z p najmniej znaczących bitów liczby k. Również wybór m=2p-1 jest zły, ponieważ permutacja znaków w k nie mienia wartości funkcji haszującej. Dlatego lepiej na m wybierać liczby pierwsze, które nie są zbyt bliskie potęgom 2.")
59
Haszowanie przez mnożenie
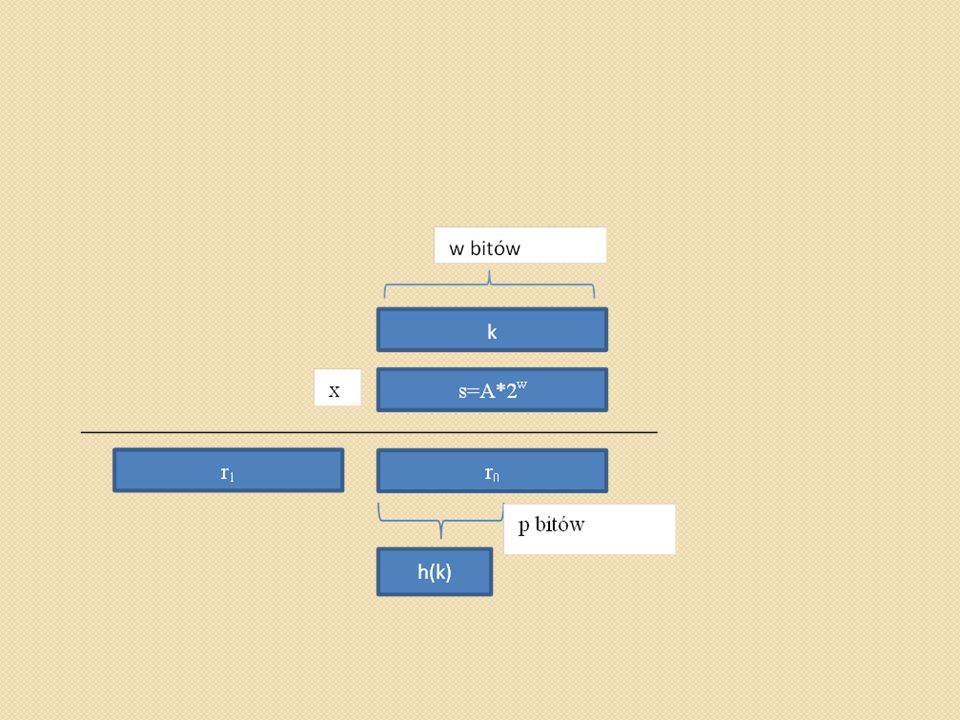
Obliczenia przeprowadza się w dwóch krokach. Najpierw klucz k mnożymy przez stałą A z przedziału 0<A<1 i wyznaczamy część ułamkową liczby kA. Potem mnożymy uzyskaną wartość przez m a z uzyskanego wyniku wyciągamy wartość funkcji podłoga. Zapiszemy to następująco: h(k)=m(kA mod 1) gdzie kA mod 1 to część ułamkowa kA, czyli kA-kA. Wartość m nie ma szczególnego znaczenia. Zwykle, ze względu na łatwość implementacji komputerowej, wybiera się ją jako pewną potęgę 2, czyli m=2p dla pewnej liczby naturalnej p. Niech słowo maszynowe ma długość w bitów oraz k mieści się w jednym słowie. Natomiast niech A będzie ułamkiem postaci s/2w, gdzie s jest liczbą całkowitą z przedziału 0<s<2w. W pierwszej kolejności mnoży się k przez w-bitową liczbę całkowitą s=A*2w. Wynik stanowi 2w-bitowa liczba r12w+r0, gdzie r1 jest bardziej znaczącym, a r0 mniej znaczącym słowem iloczynu. Szukana p-bitowa wartość funkcji haszującej składa się z p najbardziej znaczących bitów liczby r0.
=m(kA mod 1) gdzie kA mod 1 to część ułamkowa kA, czyli kA-kA. Wartość m nie ma szczególnego znaczenia. Zwykle, ze względu na łatwość implementacji komputerowej, wybiera się ją jako pewną potęgę 2, czyli m=2p dla pewnej liczby naturalnej p. Niech słowo maszynowe ma długość w bitów oraz k mieści się w jednym słowie. Natomiast niech A będzie ułamkiem postaci s/2w, gdzie s jest liczbą całkowitą z przedziału 0<s<2w. W pierwszej kolejności mnoży się k przez w-bitową liczbę całkowitą s=A*2w. Wynik stanowi 2w-bitowa liczba r12w+r0, gdzie r1 jest bardziej znaczącym, a r0 mniej znaczącym słowem iloczynu. Szukana p-bitowa wartość funkcji haszującej składa się z p najbardziej znaczących bitów liczby r0.")
61
Adresowanie otwarte W metodzie adresowania otwartego wszystkie elementy przechowuje się wprost w tablicy. Każda pozycja w tablicy zawiera wiec albo element zbioru albo wartość NIL. Wyszukiwanie elementu związane jest z systematycznym przeszukiwaniem tablicy element po elemencie. Efektem będzie znaleziony element lub informacja że go nie ma w tablicy. Brak jest dodatkowych list oraz przechowywania elementów poza tablicą. W adresowaniu otwartym, współczynnik zapełnienia nie może nigdy przekroczyć 1, aby nie nastąpiło przepełnienie tablicy.

62
Funkcja haszującą będzie miała postać:
h:U{0,1,…,m-1}{0,1,…,m-1} o własności takiej , że dla każdego klucza k ciąg pozycji (ciąg kontrolny klucza k) <h(k,0), h(k,1), …, h(k,m-1)> jest permutacją pozycji <0,1, …, m-1>.
 <h(k,0), h(k,1), …, h(k,m-1)> jest permutacją pozycji <0,1, …, m-1>.")
63
Dodawanie void HASH-INSERT(int T[], int k) { i=0 do{ j=h(k,i) if T[j]==NIL T[j]=k return j else i++ }while(i!=m) cout<< „tablica z haszowaniem jest pełna”; }
 { i=0 do{ j=h(k,i) if T[j]==NIL T[j]=k return j else i++ }while(i!=m) cout<< „tablica z haszowaniem jest pełna ; }")
64
Wyszukiwanie int HASH-SEARCH(int T[], int k) { i=0 do{ j=h(k,i)
if T[j]==k return j i++ }while (T[j]!=NIL)||(i!=m) return NIL }
![Wyszukiwanie int HASH-SEARCH(int T[], int k) { i=0 do{ j=h(k,i)](http://slideplayer.pl/slide/2763792/10/images/64/Wyszukiwanie+int+HASH-SEARCH%28int+T%5B%5D%2C+int+k%29+%7B+i%3D0+do%7B+j%3Dh%28k%2Ci%29.jpg "if T[j]==k. return j. i++ }while (T[j]!=NIL)||(i!=m) return NIL. }")
65
Gdy mamy do czynienia z adresowaniem otwartym w tablicach z haszowaniem, nie możemy po prostu usunąć klucza z pozycji i oznaczyć ją jako wolną przez wpisanie adresu NIL. Gdybyśmy tak zrobili to odcięlibyśmy dostęp do kluczy k, przy wstawianiu których odwiedzona została pozycja i i była wówczas zajęta. Problem można rozwiązać wpisując na tę pozycję specjalną stałą DELETED zamiast NIL. Procedura HASH- SEARCH gdy natknie się na pozycję DELETED powinna dalej kontynuować poszukiwania, natomiast procedura HASH-INSERT może potraktować pozycję jako wolną i wstawić w nią nowy klucz.

66
Sposoby obliczania ciągów kontrolnych
adresowanie liniowe, adresowanie kwadratowe haszowanie dwukrotne.

67
Adresowanie liniowe W metodzie adresowania liniowego dla zwykłej funkcji haszującej h’:U{0,1,…,m-1}, nazywanej pomocniczą funkcją haszującą, stosuje się funkcję: h(k,i)=(h’(k)+i) mod m dla i=0,1,…,m-1. Dla danego klucza k jego ciąg kontrolny zaczyna się od pozycji T[h’(k)], czyli od pozycji wyznaczonej przez funkcję pomocniczą. następną pozycją w tym ciągu jest T[h’(k)+1] itd. aż do pozycji T[m-1]. Dalej występują pozycje T[0], T[1], …, T[h’(k)-1]. Ponieważ pierwsza pozycja w ciągu wyznacza cały ciąg jednoznacznie, w metodzie adresowania liniowego jest więc generowanych tylko m różnych ciągów kontrolnych. Ten sposób adresowania jest łatwy w realizacji ma jednak wadę polegającą na tendencji do grupowania się pozycji zajętych(tzw. grupowanie pierwotne).
=(h’(k)+i) mod m. dla i=0,1,…,m-1. Dla danego klucza k jego ciąg kontrolny zaczyna się od pozycji T[h’(k)], czyli od pozycji wyznaczonej przez funkcję pomocniczą. następną pozycją w tym ciągu jest T[h’(k)+1] itd. aż do pozycji T[m-1]. Dalej występują pozycje T[0], T[1], …, T[h’(k)-1]. Ponieważ pierwsza pozycja w ciągu wyznacza cały ciąg jednoznacznie, w metodzie adresowania liniowego jest więc generowanych tylko m różnych ciągów kontrolnych. Ten sposób adresowania jest łatwy w realizacji ma jednak wadę polegającą na tendencji do grupowania się pozycji zajętych(tzw. grupowanie pierwotne).")
68
Adresowanie kwadratowe
Adresowanie kwadratowe wykorzystuje funkcję haszująco postaci: h(k,i)=(h’(k)+c1i+c2i2) mod m, gdzie h’ jest pomocniczą funkcją haszującą, c1 i c2 są pewnymi dodatnimi stałymi, a i=0,1,…,m-1. Pierwszą odwiedzoną pozycją jest T[h’(k)]; kolejno rozpatrywane pozycje są oddalone od początkowej o wielkość zależną od kwadratu numeru pozycji i w ciągu kontrolnym. Chociaż metoda ta jest lepsza od adresowania liniowego to trzeba narzucić pewne warunki na liczby c1, c2 i m. Jeśli jednak dwa klucze mają takie same początkowe pozycje, to i całe ich ciągi kontrolne są równe, ponieważ z h(k1,0)=h(k2,0) wynika, że h(k1,i)=h(k2,i). Jest to kolejne grupowanie zwane grupowaniem wtórnym.
=(h’(k)+c1i+c2i2) mod m, gdzie h’ jest pomocniczą funkcją haszującą, c1 i c2 są pewnymi dodatnimi stałymi, a i=0,1,…,m-1. Pierwszą odwiedzoną pozycją jest T[h’(k)]; kolejno rozpatrywane pozycje są oddalone od początkowej o wielkość zależną od kwadratu numeru pozycji i w ciągu kontrolnym. Chociaż metoda ta jest lepsza od adresowania liniowego to trzeba narzucić pewne warunki na liczby c1, c2 i m. Jeśli jednak dwa klucze mają takie same początkowe pozycje, to i całe ich ciągi kontrolne są równe, ponieważ z h(k1,0)=h(k2,0) wynika, że h(k1,i)=h(k2,i). Jest to kolejne grupowanie zwane grupowaniem wtórnym.")
69
Haszowanie dwukrotne Funkcja haszująca w haszowaniu dwukrotnym ma postać: h(k,i)=(h1(k)+ih2(k)) mod m, gdzie h1 i h 2 są pomocniczymi funkcjami haszującymi. Pierwszą pozycją w ciągu kontrolnym klucza k jest T[h1(k)]; kolejna pozycja jest oddalona od poprzedniej o h2(k) modulo m. Ciąg kontrolny zależy tutaj na dwa sposoby od k, to znaczy, że zależy zarówno od pozycji początkowej jak i od kroku, z jakim przeglądamy tablicę. Aby mieć gwarancję, że w razie potrzeby przeszukana zostanie cała tablica, musimy zapewnić, że wartość h2(k) jest względnie pierwsza z rozmiarem tablicy m.
]; kolejna pozycja jest oddalona od poprzedniej o h2(k) modulo m. Ciąg kontrolny zależy tutaj na dwa sposoby od k, to znaczy, że zależy zarówno od pozycji początkowej jak i od kroku, z jakim przeglądamy tablicę. Aby mieć gwarancję, że w razie potrzeby przeszukana zostanie cała tablica, musimy zapewnić, że wartość h2(k) jest względnie pierwsza z rozmiarem tablicy m.")
70
Bibliografia Cormen Thomas; Leiserson Charles; Rivest Ronald; Stein Clifford, „Wprowadzenie do Algorytmów”, Wydawnictwo Naukowe PWN, Warszawa 2012, Wróblewski Piotr, „Algorytmy, Struktury Danych i Techniki Programowania”, Wydawnictwo Helion, Gliwice 2010 Banachowski Lech, Diks Krzysztof, Rytter Wojciech, „Algorytmy i Struktury danych”, Wydawnictwa Naukowo-Techniczne, Warszawa 1996.

Podobne prezentacje