Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Programowanie procesorów graficznych Piotr Białas Wydział Fizyki, Astronomii i Informatyki Stosowanej Zakład Technologii Gier

2
Wyklad 1 Wprowadzenie do architektury CUDA Compute Unified Device Architecture

3
CUDA registers Shared Global memory (L2 cached) Texture memory (L1 cached) registers Shared Compute Unified Device Architecture Multiprocesor scalar procesor Texture cacheCache Constant memory (L1 cached)
 Texture memory (L1 cached) registers Shared Compute Unified Device Architecture Multiprocesor scalar procesor Texture cacheCache Constant memory (L1 cached)")
5
CUDA registers Shared Global memory registers Shared Compute Unified Device Architecture Multiprocesor scalar procesor Texture cacheCacheTexture cache Mój laptop (stary:) Quadro NVS 140M; 2 multiprocesors Compute Capability 1.1 8192 registers 16KB shared memory 6-8KB texture cache
 Quadro NVS 140M; 2 multiprocesors Compute Capability registers 16KB shared memory 6-8KB texture cache")
6
CUDA registers Shared Global memory registers Shared Compute Unified Device Architecture Multiprocesor scalar procesor Texture cacheCacheTexture cache GTX 280; 30 multiprocesors Compute Capability 1.3 double precision 16384 registers 660GFlops (float) 1GB RAM 140GB/s
 1GB RAM 140GB/s")
7
SIMT registers Shared Single Instructions Multiple Threads Multiprocesor Jeden program na karcie (zwany kernel) wykonywany jest współbieżnie w wielu wątkach. Każdy wątek posiada swój unikatowy identyfikator. To jest jedyna różnica pomiędzy wątkami.

8
SIMT registers Shared Single Instructions Multiple Threads Multiprocesor Wątki zorganizowane są w bloki wątków Każdy blok wykonywany jest na jednym multiprocesorze

9
SIMT registers Shared Single Instructions Multiple Threads Multiprocesor Wątki zorganizowane są w bloki wątków Każdy blok wykonywany jest na jednym multiprocesorze (ale multiprocesor może obsługiwać na raz więcej niż jeden blok)
")
10
SIMT registers Shared Single Instructions Multiple Threads Multiprocesor Wątki z jednego bloku mogą korzystać z tej samej pamięci współdzielonej i mogą się synchronizować

11
SIMT registers Shared Single Instructions Multiple Threads Multiprocesor Każdy wątek posiada swoje rejestry (niewspółdzielone)
")
12
SIMT registers Shared Single Instructions Multiple Threads Multiprocesor Bloki magą być 1,2 lub 3 wymiarowe W jednym bloku może się wykonywać 512 wątków

13
Blok wątków Wątki w bloku podzielone są na grupy zwane warp. Warp zawiera 32 wątki które wykonują się jednocześnie (nie wiem skąd się bierze czynnik 4) (hyperthreading?) Jeden warp zachowuje się jak SIMD (albo procesor wektorowy)
 (hyperthreading ) Jeden warp zachowuje się jak SIMD (albo procesor wektorowy).")
14
Instrukcje warunkowe powodują że wątki w jednym warp-ie muszą na siebie czekać

15
Różne warp-y w jednym bloku są wykonywane na jednym multiprocesorze współbieżnie. Warto umieszczać w jednym bloku więcej niż jeden warp, aby umożliwić multiprocesorowi lepsze wykorzystanie procesorów

16
Sieci Bloków Bloki wątków zorganizowane są w sieci bloków Sieci bloków mogą być 1 lub 2 wymiarowe Wywołując jądro podajemy rozmiar bloku wątków i romziar sieci bloków. Bloki umieszczane są (automatycznie) na multiprocesorach. Na jednym multiprocesorze może być wykonywane naraz kilka bloków (max 8 ). Liczba bloków na jednym procesorze jest ograniczona przez rozmiar współdzielonej pamięci i ograniczenia na liczę aktywnych warpów (24 / 32 ) i wątków (768 / 1024 )
 na multiprocesorach. Na jednym multiprocesorze może być wykonywane naraz kilka bloków (max 8 ). Liczba bloków na jednym procesorze jest ograniczona przez rozmiar współdzielonej pamięci i ograniczenia na liczę aktywnych warpów (24 / 32 ) i wątków (768 / 1024 ).")
17
Random numbers ● I am using the Tausworthe something... routine published in „Graphics Gems 3”. ● Its uses 4 seeds. ● We need one number generator per thread.

18
void run() { unsigned int mem_size = sizeof( FLOAT) * N_WALKERS; FLOAT* host_walkers = (float*) malloc( mem_size); for( unsigned int i = 0; i < N_WALKERS; ++i) { host_walkers[i] = 0.0; } FLOAT* device_walkers; cudaMalloc( (void**) &device_walkers, mem_size); cudaMemcpy( device_walkers,host_walkers, mem_size, cudaMemcpyHostToDevice) ); > cudaMemcpy( host_walkers,device_walkers, mem_size, cudaMemcpyDeviceToHost) ); for(int i=0;i<N_WALKERS;i++) { fprintf(stdout,"%.12g\n",host_walkers[i]); } free( host_walkers); cudaFree(device_walkers); } void run() { unsigned int mem_size = sizeof( FLOAT) * N_WALKERS; FLOAT* host_walkers = (float*) malloc( mem_size); for( unsigned int i = 0; i < N_WALKERS; ++i) { host_walkers[i] = 0.0; } FLOAT* device_walkers; cudaMalloc( (void**) &device_walkers, mem_size); cudaMemcpy( device_walkers,host_walkers, mem_size, cudaMemcpyHostToDevice) ); > cudaMemcpy( host_walkers,device_walkers, mem_size, cudaMemcpyDeviceToHost) ); for(int i=0;i<N_WALKERS;i++) { fprintf(stdout,"%.12g\n",host_walkers[i]); } free( host_walkers); cudaFree(device_walkers); }
![void run() { unsigned int mem_size = sizeof( FLOAT) * N_WALKERS; FLOAT* host_walkers = (float*) malloc( mem_size); for( unsigned int i = 0; i < N_WALKERS; ++i) { host_walkers[i] = 0.0; } FLOAT* device_walkers; cudaMalloc( (void**) &device_walkers, mem_size); cudaMemcpy( device_walkers,host_walkers, mem_size, cudaMemcpyHostToDevice) ); > cudaMemcpy( host_walkers,device_walkers, mem_size, cudaMemcpyDeviceToHost) ); for(int i=0;i<N_WALKERS;i++) { fprintf(stdout, %.12g\n ,host_walkers[i]); } free( host_walkers); cudaFree(device_walkers); } void run() { unsigned int mem_size = sizeof( FLOAT) * N_WALKERS; FLOAT* host_walkers = (float*) malloc( mem_size); for( unsigned int i = 0; i < N_WALKERS; ++i) { host_walkers[i] = 0.0; } FLOAT* device_walkers; cudaMalloc( (void**) &device_walkers, mem_size); cudaMemcpy( device_walkers,host_walkers, mem_size, cudaMemcpyHostToDevice) ); > cudaMemcpy( host_walkers,device_walkers, mem_size, cudaMemcpyDeviceToHost) ); for(int i=0;i<N_WALKERS;i++) { fprintf(stdout, %.12g\n ,host_walkers[i]); } free( host_walkers); cudaFree(device_walkers); }](http://images.slideplayer.pl/41/11486538/slides/slide_18.jpg "void run() { unsigned int mem_size = sizeof( FLOAT) * N_WALKERS; FLOAT* host_walkers = (float*) malloc( mem_size); for( unsigned int i = 0; i < N_WALKERS; ++i) { host_walkers[i] = 0.0; } FLOAT* device_walkers; cudaMalloc( (void**) &device_walkers, mem_size); cudaMemcpy( device_walkers,host_walkers, mem_size, cudaMemcpyHostToDevice) ); > cudaMemcpy( host_walkers,device_walkers, mem_size, cudaMemcpyDeviceToHost) ); for(int i=0;i<N_WALKERS;i++) { fprintf(stdout, %.12g\n ,host_walkers[i]); } free( host_walkers); cudaFree(device_walkers); } void run() { unsigned int mem_size = sizeof( FLOAT) * N_WALKERS; FLOAT* host_walkers = (float*) malloc( mem_size); for( unsigned int i = 0; i < N_WALKERS; ++i) { host_walkers[i] = 0.0; } FLOAT* device_walkers; cudaMalloc( (void**) &device_walkers, mem_size); cudaMemcpy( device_walkers,host_walkers, mem_size, cudaMemcpyHostToDevice) ); > cudaMemcpy( host_walkers,device_walkers, mem_size, cudaMemcpyDeviceToHost) ); for(int i=0;i<N_WALKERS;i++) { fprintf(stdout, %.12g\n ,host_walkers[i]); } free( host_walkers); cudaFree(device_walkers); }")
19
Invoking the kernel dim3 grid( N_BLOCKS_X, N_BLOCKS_Y, N_BLOCKS_Z); dim3 threads( N_THREADS_X, N_THREADS_Y, N_THREADS_Z); walker_kernel >> ( device_walkers,seeds.d_seeds(),N_STEPS); cudaError_t err=cudaGetLastError(); if(cudaSuccess!=err) { fprintf(stderr,"failed! %s\n",cudaGetErrorString(err)); exit(-1); } dim3 grid( N_BLOCKS_X, N_BLOCKS_Y, N_BLOCKS_Z); dim3 threads( N_THREADS_X, N_THREADS_Y, N_THREADS_Z); walker_kernel >> ( device_walkers,seeds.d_seeds(),N_STEPS); cudaError_t err=cudaGetLastError(); if(cudaSuccess!=err) { fprintf(stderr,"failed! %s\n",cudaGetErrorString(err)); exit(-1); }
); exit(-1); } dim3 grid( N_BLOCKS_X, N_BLOCKS_Y, N_BLOCKS_Z); dim3 threads( N_THREADS_X, N_THREADS_Y, N_THREADS_Z); walker_kernel >> ( device_walkers,seeds.d_seeds(),N_STEPS); cudaError_t err=cudaGetLastError(); if(cudaSuccess!=err) { fprintf(stderr, failed. %s\n ,cudaGetErrorString(err)); exit(-1); }.")
20
● Kernel invocations are asynchronuos. ● The kernels can be assigned to streams. ● Kernels in each stream are executed one after each other. ● By default every kernel is assigned to stream zero. ● Copying also waits for previous kernels to finish.

21
__global__ void walker_kernel( FLOAT* global_walkers, unsigned *global_seeds, size_t n_steps) { const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(global_seeds+4*boffset+4*tid); } } __global__ void walker_kernel( FLOAT* global_walkers, unsigned *global_seeds, size_t n_steps) { const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(global_seeds+4*boffset+4*tid); } }
![__global__ void walker_kernel( FLOAT* global_walkers, unsigned *global_seeds, size_t n_steps) { const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(global_seeds+4*boffset+4*tid); } } __global__ void walker_kernel( FLOAT* global_walkers, unsigned *global_seeds, size_t n_steps) { const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(global_seeds+4*boffset+4*tid); } }](http://images.slideplayer.pl/41/11486538/slides/slide_21.jpg "__global__ void walker_kernel( FLOAT* global_walkers, unsigned *global_seeds, size_t n_steps) { const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(global_seeds+4*boffset+4*tid); } } __global__ void walker_kernel( FLOAT* global_walkers, unsigned *global_seeds, size_t n_steps) { const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(global_seeds+4*boffset+4*tid); } }")
22
Timing 50000x 2^16 walkers x86 CUDA 34s3.7s x86 CUDA 34s3.7s

23
__global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ unsigned shared_seeds[4*N_THREADS_PER_BLOCK]; const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; copy_seeds_from_global(shared_seeds,global_seeds,4*boffset,tid); for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(shared_seeds+4*tid); } copy_seeds_to_global(global_seeds,shared_seeds,4*boffset,tid); } __global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ unsigned shared_seeds[4*N_THREADS_PER_BLOCK]; const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; copy_seeds_from_global(shared_seeds,global_seeds,4*boffset,tid); for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(shared_seeds+4*tid); } copy_seeds_to_global(global_seeds,shared_seeds,4*boffset,tid); }
![__global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ unsigned shared_seeds[4*N_THREADS_PER_BLOCK]; const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; copy_seeds_from_global(shared_seeds,global_seeds,4*boffset,tid); for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(shared_seeds+4*tid); } copy_seeds_to_global(global_seeds,shared_seeds,4*boffset,tid); } __global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ unsigned shared_seeds[4*N_THREADS_PER_BLOCK]; const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; copy_seeds_from_global(shared_seeds,global_seeds,4*boffset,tid); for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(shared_seeds+4*tid); } copy_seeds_to_global(global_seeds,shared_seeds,4*boffset,tid); }](http://images.slideplayer.pl/41/11486538/slides/slide_23.jpg "__global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ unsigned shared_seeds[4*N_THREADS_PER_BLOCK]; const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; copy_seeds_from_global(shared_seeds,global_seeds,4*boffset,tid); for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(shared_seeds+4*tid); } copy_seeds_to_global(global_seeds,shared_seeds,4*boffset,tid); } __global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ unsigned shared_seeds[4*N_THREADS_PER_BLOCK]; const unsigned int bid = N_BLOCKS_X*blockIdx.y+blockIdx.x; const unsigned int tid = N_THREADS_Y*N_THREADS_X*threadIdx.z+ N_THREADS_X*threadIdx.y+threadIdx.x; const unsigned boffset=bid*N_THREADS_PER_BLOCK; copy_seeds_from_global(shared_seeds,global_seeds,4*boffset,tid); for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { global_walkers[boffset*N_WALKERS_PER_THREAD+tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd(shared_seeds+4*tid); } copy_seeds_to_global(global_seeds,shared_seeds,4*boffset,tid); }")
24
__device__ void copy_seeds_from_global(unsigned *sh_seeds, unsigned *gl_seeds,size_t offset,size_t tid) { sh_seeds[4*tid ]=gl_seeds[offset+4*tid]; sh_seeds[4*tid+1]=gl_seeds[offset+4*tid+1]; sh_seeds[4*tid+2]=gl_seeds[offset+4*tid+2]; sh_seeds[4*tid+3]=gl_seeds[offset+4*tid+3]; } __device__ void copy_seeds_from_global(unsigned *sh_seeds, unsigned *gl_seeds,size_t offset,size_t tid) { sh_seeds[4*tid ]=gl_seeds[offset+4*tid]; sh_seeds[4*tid+1]=gl_seeds[offset+4*tid+1]; sh_seeds[4*tid+2]=gl_seeds[offset+4*tid+2]; sh_seeds[4*tid+3]=gl_seeds[offset+4*tid+3]; } __device__ void copy_seeds_to_global(unsigned *gl_seeds, unsigned *sh_seeds,size_t offset,size_t tid) { gl_seeds[offset+4*tid] =sh_seeds[4*tid ]; gl_seeds[offset+4*tid+1]=sh_seeds[4*tid+1]; gl_seeds[offset+4*tid+2]=sh_seeds[4*tid+2]; gl_seeds[offset+4*tid+3]=sh_seeds[4*tid+3]; } __device__ void copy_seeds_to_global(unsigned *gl_seeds, unsigned *sh_seeds,size_t offset,size_t tid) { gl_seeds[offset+4*tid] =sh_seeds[4*tid ]; gl_seeds[offset+4*tid+1]=sh_seeds[4*tid+1]; gl_seeds[offset+4*tid+2]=sh_seeds[4*tid+2]; gl_seeds[offset+4*tid+3]=sh_seeds[4*tid+3]; }
![__device__ void copy_seeds_from_global(unsigned *sh_seeds, unsigned *gl_seeds,size_t offset,size_t tid) { sh_seeds[4*tid ]=gl_seeds[offset+4*tid]; sh_seeds[4*tid+1]=gl_seeds[offset+4*tid+1]; sh_seeds[4*tid+2]=gl_seeds[offset+4*tid+2]; sh_seeds[4*tid+3]=gl_seeds[offset+4*tid+3]; } __device__ void copy_seeds_from_global(unsigned *sh_seeds, unsigned *gl_seeds,size_t offset,size_t tid) { sh_seeds[4*tid ]=gl_seeds[offset+4*tid]; sh_seeds[4*tid+1]=gl_seeds[offset+4*tid+1]; sh_seeds[4*tid+2]=gl_seeds[offset+4*tid+2]; sh_seeds[4*tid+3]=gl_seeds[offset+4*tid+3]; } __device__ void copy_seeds_to_global(unsigned *gl_seeds, unsigned *sh_seeds,size_t offset,size_t tid) { gl_seeds[offset+4*tid] =sh_seeds[4*tid ]; gl_seeds[offset+4*tid+1]=sh_seeds[4*tid+1]; gl_seeds[offset+4*tid+2]=sh_seeds[4*tid+2]; gl_seeds[offset+4*tid+3]=sh_seeds[4*tid+3]; } __device__ void copy_seeds_to_global(unsigned *gl_seeds, unsigned *sh_seeds,size_t offset,size_t tid) { gl_seeds[offset+4*tid] =sh_seeds[4*tid ]; gl_seeds[offset+4*tid+1]=sh_seeds[4*tid+1]; gl_seeds[offset+4*tid+2]=sh_seeds[4*tid+2]; gl_seeds[offset+4*tid+3]=sh_seeds[4*tid+3]; }](http://images.slideplayer.pl/41/11486538/slides/slide_24.jpg "__device__ void copy_seeds_from_global(unsigned *sh_seeds, unsigned *gl_seeds,size_t offset,size_t tid) { sh_seeds[4*tid ]=gl_seeds[offset+4*tid]; sh_seeds[4*tid+1]=gl_seeds[offset+4*tid+1]; sh_seeds[4*tid+2]=gl_seeds[offset+4*tid+2]; sh_seeds[4*tid+3]=gl_seeds[offset+4*tid+3]; } __device__ void copy_seeds_from_global(unsigned *sh_seeds, unsigned *gl_seeds,size_t offset,size_t tid) { sh_seeds[4*tid ]=gl_seeds[offset+4*tid]; sh_seeds[4*tid+1]=gl_seeds[offset+4*tid+1]; sh_seeds[4*tid+2]=gl_seeds[offset+4*tid+2]; sh_seeds[4*tid+3]=gl_seeds[offset+4*tid+3]; } __device__ void copy_seeds_to_global(unsigned *gl_seeds, unsigned *sh_seeds,size_t offset,size_t tid) { gl_seeds[offset+4*tid] =sh_seeds[4*tid ]; gl_seeds[offset+4*tid+1]=sh_seeds[4*tid+1]; gl_seeds[offset+4*tid+2]=sh_seeds[4*tid+2]; gl_seeds[offset+4*tid+3]=sh_seeds[4*tid+3]; } __device__ void copy_seeds_to_global(unsigned *gl_seeds, unsigned *sh_seeds,size_t offset,size_t tid) { gl_seeds[offset+4*tid] =sh_seeds[4*tid ]; gl_seeds[offset+4*tid+1]=sh_seeds[4*tid+1]; gl_seeds[offset+4*tid+2]=sh_seeds[4*tid+2]; gl_seeds[offset+4*tid+3]=sh_seeds[4*tid+3]; }")
25
Timing 50000 x 2^16 walkers x86 CUDACUDA(shared) 34s3.7s 0.7s x86 CUDACUDA(shared) 34s3.7s 0.7s
 34s3.7s 0.7s x86 CUDACUDA(shared) 34s3.7s 0.7s")
26
Bank conflicts ● Shared memory is divided into 16 banks. ● Consecutive 32bit words belong to different banks. ● Fetching seeds generate a 4way bank conflict. ● But we do not need shared memory in this case.

27
Registers __global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ float shared_walkers[N_THREADS_PER_BLOCK*N_WALKERS_PER_THREAD];.... unsigned z1=global_seeds[4*boffset+4*tid]; unsigned z2=global_seeds[4*boffset+4*tid+1]; unsigned z3=global_seeds[4*boffset+4*tid+2]; unsigned z4=global_seeds[4*boffset+4*tid+3]; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { shared_walkers[tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd_np(z1,z2,z3,z4); } global_seeds[4*boffset+4*tid] =z1; global_seeds[4*boffset+4*tid+1]=z2; global_seeds[4*boffset+4*tid+2]=z3; global_seeds[4*boffset+4*tid+3]=z4; __global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ float shared_walkers[N_THREADS_PER_BLOCK*N_WALKERS_PER_THREAD];.... unsigned z1=global_seeds[4*boffset+4*tid]; unsigned z2=global_seeds[4*boffset+4*tid+1]; unsigned z3=global_seeds[4*boffset+4*tid+2]; unsigned z4=global_seeds[4*boffset+4*tid+3]; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { shared_walkers[tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd_np(z1,z2,z3,z4); } global_seeds[4*boffset+4*tid] =z1; global_seeds[4*boffset+4*tid+1]=z2; global_seeds[4*boffset+4*tid+2]=z3; global_seeds[4*boffset+4*tid+3]=z4;
![Registers __global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ float shared_walkers[N_THREADS_PER_BLOCK*N_WALKERS_PER_THREAD];....](http://images.slideplayer.pl/41/11486538/slides/slide_27.jpg "unsigned z1=global_seeds[4*boffset+4*tid]; unsigned z2=global_seeds[4*boffset+4*tid+1]; unsigned z3=global_seeds[4*boffset+4*tid+2]; unsigned z4=global_seeds[4*boffset+4*tid+3]; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { shared_walkers[tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd_np(z1,z2,z3,z4); } global_seeds[4*boffset+4*tid] =z1; global_seeds[4*boffset+4*tid+1]=z2; global_seeds[4*boffset+4*tid+2]=z3; global_seeds[4*boffset+4*tid+3]=z4; __global__ void walker_kernel( FLOAT* global_walkers,unsigned *global_seeds,size_t n_steps) { __shared__ float shared_walkers[N_THREADS_PER_BLOCK*N_WALKERS_PER_THREAD];.... unsigned z1=global_seeds[4*boffset+4*tid]; unsigned z2=global_seeds[4*boffset+4*tid+1]; unsigned z3=global_seeds[4*boffset+4*tid+2]; unsigned z4=global_seeds[4*boffset+4*tid+3]; for(int j=0;j<n_steps;j++) for(size_t i = 0;i< N_WALKERS_PER_THREAD;++i) { shared_walkers[tid*N_WALKERS_PER_THREAD+i] += 1.0-2*rnd_np(z1,z2,z3,z4); } global_seeds[4*boffset+4*tid] =z1; global_seeds[4*boffset+4*tid+1]=z2; global_seeds[4*boffset+4*tid+2]=z3; global_seeds[4*boffset+4*tid+3]=z4;.")
28
Timing 50000 x 2^16 walkers x86 CUDACUDA(shared) cuda(registers) 34s3.7s 0.7s 0.5s 13GFlops x86 CUDACUDA(shared) cuda(registers) 34s3.7s 0.7s 0.5s 13GFlops
 cuda(registers) 34s3.7s 0.7s 0.5s 13GFlops x86 CUDACUDA(shared) cuda(registers) 34s3.7s 0.7s 0.5s 13GFlops")
29
Mmożenie macierzy A A B B C C C C

30
Podejście „naiwne”: jeden wątek liczy jeden element macierzy wynikowej Global memory thread

31
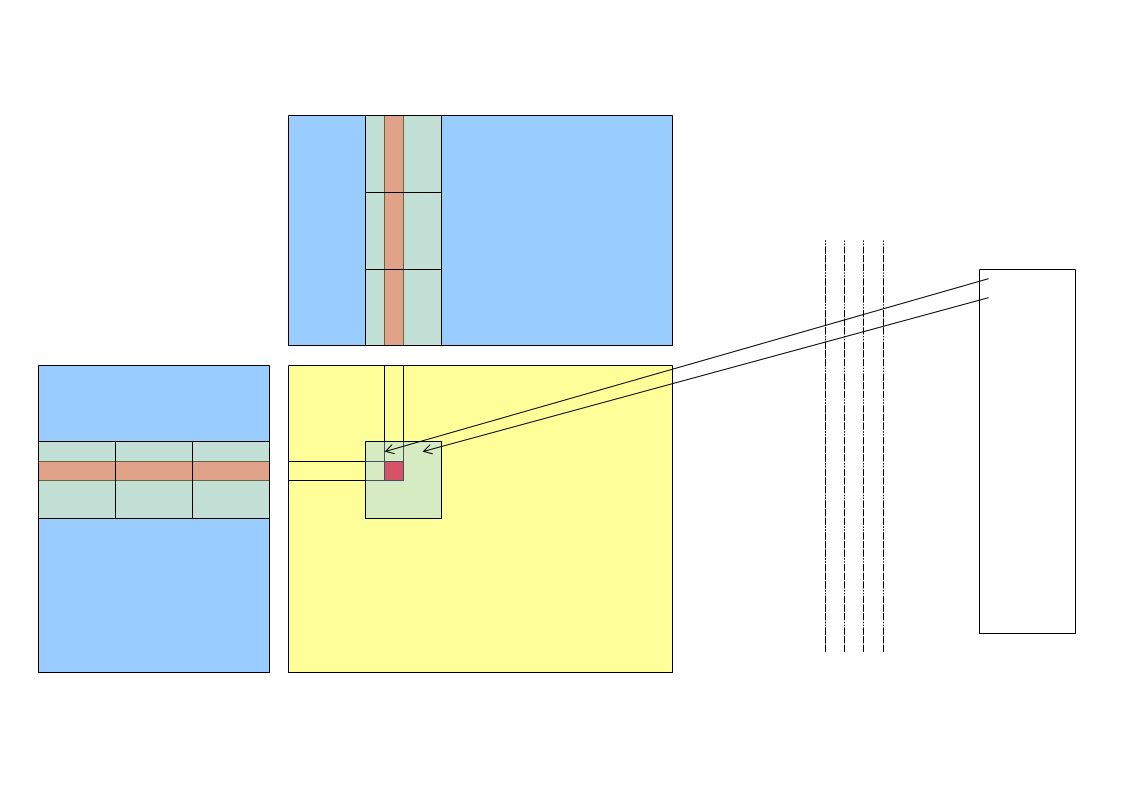
Dostęp do pamięci – Coalesced access Jeśli wątki z połówki warpu (16 wątków) żądają dostępu do pamięci globalnej karty to żądanie dotyczące tego samego segmentu (64 lub 128 bytowych) są łączone w jedną transakcję. To BARDZO przyspiesza szybkość transferu:)
.")
32
Dostęp do pamięci – Coalesced access 4 bajtowe słowo Jedna transkacja 64 bajtowa

33
Dostęp do pamięci – Coalesced access 4 bajtowe słowo Jedna transakcja 128 bajtow

34
Dostęp do pamięci – Coalesced access 4 bajtowe słowo Dwie transakcje 64 bajtowe

35
Dostęp do pamięci – Coalesced access 4 bajtowe słowo Dwie transakcje 128 i 64 bajtowa

36
Dostęp do pamięci – Coalesced access 4 bajtowe słowo Dwie transakcje 128 bajtowe

37
Dostęp do pamięci – Coalesced access 4 bajtowe słowo Dwie transakcje 128 bajtowe

38
Jeden wątek pobiera jeden wektor (3 floaty) przekształca go i zapisuje z powrotem. __global__ array_of_vectors(float *mem) { float v[3]; size_t offset =3*(blockIdx.x*blockDim.x + threadIdx.x); v[0]=mem[offset]; v[1]=mem[offset+1]; v[2]=mem[offset+2]; //do something mem[offset] =v[0]; mem[offset+1]=v[1]; mem[offset+2]=v[2]; } __global__ array_of_vectors(float *mem) { float v[3]; size_t offset =3*(blockIdx.x*blockDim.x + threadIdx.x); v[0]=mem[offset]; v[1]=mem[offset+1]; v[2]=mem[offset+2]; //do something mem[offset] =v[0]; mem[offset+1]=v[1]; mem[offset+2]=v[2]; }
 { float v[3]; size_t offset =3*(blockIdx.x*blockDim.x + threadIdx.x); v[0]=mem[offset]; v[1]=mem[offset+1]; v[2]=mem[offset+2]; //do something mem[offset] =v[0]; mem[offset+1]=v[1]; mem[offset+2]=v[2]; } __global__ array_of_vectors(float *mem) { float v[3]; size_t offset =3*(blockIdx.x*blockDim.x + threadIdx.x); v[0]=mem[offset]; v[1]=mem[offset+1]; v[2]=mem[offset+2]; //do something mem[offset] =v[0]; mem[offset+1]=v[1]; mem[offset+2]=v[2]; }.")
39
2 transkacje: 128bajtowa i 64 bajtowa v[0]=mem[offset];
![2 transkacje: 128bajtowa i 64 bajtowa v[0]=mem[offset];](http://images.slideplayer.pl/41/11486538/slides/slide_39.jpg "2 transkacje: 128bajtowa i 64 bajtowa v[0]=mem[offset];")
40
2 transkacje: 128bajtowa i 64 bajtowa v[1]=mem[offset+1];
![2 transkacje: 128bajtowa i 64 bajtowa v[1]=mem[offset+1];](http://images.slideplayer.pl/41/11486538/slides/slide_40.jpg "2 transkacje: 128bajtowa i 64 bajtowa v[1]=mem[offset+1];")
41
2 transkacje: 128bajtowa i 64 bajtowa v[2]=mem[offset+2];
![2 transkacje: 128bajtowa i 64 bajtowa v[2]=mem[offset+2];](http://images.slideplayer.pl/41/11486538/slides/slide_41.jpg "2 transkacje: 128bajtowa i 64 bajtowa v[2]=mem[offset+2];")
42
Jeden wątek pobiera jeden wektor (3 floaty) przekształca go i zapisuje z powrotem. __global__ structure_of_arrays(float *mem_x,float *mem_y, float *mem_z) { float v[3]; size_t offset =(blockIdx.x*blockDim.x + idx); v[0]=mem_x[offset]; v[1]=mem_y[offset]; v[2]=mem_z[offset]; // do something mem_x[offset]=v[0]; mem_y[offset]=v[1]; mem_z[offset]=v[2]; } __global__ structure_of_arrays(float *mem_x,float *mem_y, float *mem_z) { float v[3]; size_t offset =(blockIdx.x*blockDim.x + idx); v[0]=mem_x[offset]; v[1]=mem_y[offset]; v[2]=mem_z[offset]; // do something mem_x[offset]=v[0]; mem_y[offset]=v[1]; mem_z[offset]=v[2]; }
 { float v[3]; size_t offset =(blockIdx.x*blockDim.x + idx); v[0]=mem_x[offset]; v[1]=mem_y[offset]; v[2]=mem_z[offset]; // do something mem_x[offset]=v[0]; mem_y[offset]=v[1]; mem_z[offset]=v[2]; } __global__ structure_of_arrays(float *mem_x,float *mem_y, float *mem_z) { float v[3]; size_t offset =(blockIdx.x*blockDim.x + idx); v[0]=mem_x[offset]; v[1]=mem_y[offset]; v[2]=mem_z[offset]; // do something mem_x[offset]=v[0]; mem_y[offset]=v[1]; mem_z[offset]=v[2]; }.")
43
v[0]=mem_x[offset] Jedna transakcja 64 bajtowa
![v[0]=mem_x[offset] Jedna transakcja 64 bajtowa](http://images.slideplayer.pl/41/11486538/slides/slide_43.jpg "v[0]=mem_x[offset] Jedna transakcja 64 bajtowa")
44
v[1]=mem_x[offset] Jedna transakcja 64 bajtowa
![v[1]=mem_x[offset] Jedna transakcja 64 bajtowa](http://images.slideplayer.pl/41/11486538/slides/slide_44.jpg "v[1]=mem_x[offset] Jedna transakcja 64 bajtowa")
45
v[2]=mem_x[offset] Jedna transakcja 64 bajtowa
![v[2]=mem_x[offset] Jedna transakcja 64 bajtowa](http://images.slideplayer.pl/41/11486538/slides/slide_45.jpg "v[2]=mem_x[offset] Jedna transakcja 64 bajtowa")
47
Shared memory

51
synchronise()
")
53
Różne bloki są automatycznie szeregowane na różne multiprocesory

54
__global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; __global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; __global__ oznacza jądro: funkcja wykonywana na karcie, wywoływana z hosta blockIdx i threadIdx : predefiniowane zmienne (3D) określające blok i wątek wewnątrz bloku
 { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; __global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; __global__ oznacza jądro: funkcja wykonywana na karcie, wywoływana z hosta blockIdx i threadIdx : predefiniowane zmienne (3D) określające blok i wątek wewnątrz bloku")
55
wAwA wB int aBegin = wA*BLOCK_SIZE*by; int aStep=BLOCK_SIZE; int bBegin= BLOCK_SIZE*bx; int bStep= BLOCK_SIZE*wB; int aBegin = wA*BLOCK_SIZE*by; int aStep=BLOCK_SIZE; int bBegin= BLOCK_SIZE*bx; int bStep= BLOCK_SIZE*wB; aBegin bBegin (bx,by)
")
56
wAwA wB int aBegin = wA*BLOCK_SIZE*by; int aStep=BLOCK_SIZE; int bBegin= BLOCK_SIZE*bx; int bStep= BLOCK_SIZE*wB; int aEnd=aBegin+wA-1; //?? int aBegin = wA*BLOCK_SIZE*by; int aStep=BLOCK_SIZE; int bBegin= BLOCK_SIZE*bx; int bStep= BLOCK_SIZE*wB; int aEnd=aBegin+wA-1; //?? aBegin bBegin (bx,by) aEnd
 aEnd.")
57
__global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... float Csub = 0.0f; for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; //ladowanie podbloków do pamięci współdzielonej As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads();.... } __global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... float Csub = 0.0f; for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; //ladowanie podbloków do pamięci współdzielonej As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads();.... }
 { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; //ladowanie podbloków do pamięci współdzielonej As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads();.... } __global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... float Csub = 0.0f; for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; //ladowanie podbloków do pamięci współdzielonej As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads();.... }.")
58
As[ty][tx]= A[a+wA*ty +tx]; Bs[ty][tx]= B[b+wB*ty +tx]; As[ty][tx]= A[a+wA*ty +tx]; Bs[ty][tx]= B[b+wB*ty +tx];
![As[ty][tx]= A[a+wA*ty +tx]; Bs[ty][tx]= B[b+wB*ty +tx]; As[ty][tx]= A[a+wA*ty +tx]; Bs[ty][tx]= B[b+wB*ty +tx];](http://images.slideplayer.pl/41/11486538/slides/slide_58.jpg "As[ty][tx]= A[a+wA*ty +tx]; Bs[ty][tx]= B[b+wB*ty +tx]; As[ty][tx]= A[a+wA*ty +tx]; Bs[ty][tx]= B[b+wB*ty +tx];")
59
__global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads(); for(int k=0;k<BLOCK_SIZE; ++k) { Csub+= As[ty][k]*Bs[k][tx]; } __global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads(); for(int k=0;k<BLOCK_SIZE; ++k) { Csub+= As[ty][k]*Bs[k][tx]; }
 { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads(); for(int k=0;k<BLOCK_SIZE; ++k) { Csub+= As[ty][k]*Bs[k][tx]; } __global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads(); for(int k=0;k<BLOCK_SIZE; ++k) { Csub+= As[ty][k]*Bs[k][tx]; }.")
60
int c = wB*BLOCK_SIZE*by + BLOCK_SIZE*bx; c

61
__global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads(); for(int k=0;k<BLOCK_SIZE; ++k) { Csub+= As[ty][k]*Bs[k][tx]; } int c = wB*BLOCK_SIZE*by + BLOCK_SIZE*bx; C[c+wB*ty+tx]=Csub; } __global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads(); for(int k=0;k<BLOCK_SIZE; ++k) { Csub+= As[ty][k]*Bs[k][tx]; } int c = wB*BLOCK_SIZE*by + BLOCK_SIZE*bx; C[c+wB*ty+tx]=Csub; }
 { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads(); for(int k=0;k<BLOCK_SIZE; ++k) { Csub+= As[ty][k]*Bs[k][tx]; } int c = wB*BLOCK_SIZE*by + BLOCK_SIZE*bx; C[c+wB*ty+tx]=Csub; } __global__ void Muld(float *A,float *B, int wA,int wB, int float *C) { //Block index int bx = blockIdx.x; int by = blockIdx.y; //Thread index int tx = threadIdx.x; int ty = threadIdx.y; //... Obliczenie aBegin, aEnd... for(int a = aBegin,b=bBegin; a<=aEnd; a+=aStep,b+=bStep) { __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx]=A[a+wA*ty +tx]; Bs[ty][tx]=B[b+wB*ty +tx]; __syncthreads(); for(int k=0;k<BLOCK_SIZE; ++k) { Csub+= As[ty][k]*Bs[k][tx]; } int c = wB*BLOCK_SIZE*by + BLOCK_SIZE*bx; C[c+wB*ty+tx]=Csub; }.")
62
void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; float *Ad; size= hA*wA*sizeof(float); cudaMalloc( (void**)&Ad,size); cudaMemcpy(Ad,A,size,CudaMemcpyHostToDevice); void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; float *Ad; size= hA*wA*sizeof(float); cudaMalloc( (void**)&Ad,size); cudaMemcpy(Ad,A,size,CudaMemcpyHostToDevice); cudaMalloc(void **devPtr,size_t count) alokuje count bytów na karcie i zwraca wskaznik do nich w *devPtr W przypadku niepowodzenia zwraca cudaMemoryAllocation cudaMalloc(void **devPtr,size_t count) alokuje count bytów na karcie i zwraca wskaznik do nich w *devPtr W przypadku niepowodzenia zwraca cudaMemoryAllocation
 { int size; float *Ad; size= hA*wA*sizeof(float); cudaMalloc( (void**)&Ad,size); cudaMemcpy(Ad,A,size,CudaMemcpyHostToDevice); void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; float *Ad; size= hA*wA*sizeof(float); cudaMalloc( (void**)&Ad,size); cudaMemcpy(Ad,A,size,CudaMemcpyHostToDevice); cudaMalloc(void **devPtr,size_t count) alokuje count bytów na karcie i zwraca wskaznik do nich w *devPtr W przypadku niepowodzenia zwraca cudaMemoryAllocation cudaMalloc(void **devPtr,size_t count) alokuje count bytów na karcie i zwraca wskaznik do nich w *devPtr W przypadku niepowodzenia zwraca cudaMemoryAllocation")
63
void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; float *Ad; size= hA*wA*sizeof(float); cudaMalloc( (void**)&Ad,size); cudaMemcpy(Ad,A,size,CudaMemcpyHostToDevice); float *Bd; size= hB*wB*sizeof(float); cudaMalloc( (void**)&Bd,size); cudaMemcpy(Bd,B,size,CudaMemcpyHostToDevice); float *Cd; size= hA*wB*sizeof(float); cudaMalloc( (void**)&Cd,size); void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; float *Ad; size= hA*wA*sizeof(float); cudaMalloc( (void**)&Ad,size); cudaMemcpy(Ad,A,size,CudaMemcpyHostToDevice); float *Bd; size= hB*wB*sizeof(float); cudaMalloc( (void**)&Bd,size); cudaMemcpy(Bd,B,size,CudaMemcpyHostToDevice); float *Cd; size= hA*wB*sizeof(float); cudaMalloc( (void**)&Cd,size);
 { int size; float *Ad; size= hA*wA*sizeof(float); cudaMalloc( (void**)&Ad,size); cudaMemcpy(Ad,A,size,CudaMemcpyHostToDevice); float *Bd; size= hB*wB*sizeof(float); cudaMalloc( (void**)&Bd,size); cudaMemcpy(Bd,B,size,CudaMemcpyHostToDevice); float *Cd; size= hA*wB*sizeof(float); cudaMalloc( (void**)&Cd,size); void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; float *Ad; size= hA*wA*sizeof(float); cudaMalloc( (void**)&Ad,size); cudaMemcpy(Ad,A,size,CudaMemcpyHostToDevice); float *Bd; size= hB*wB*sizeof(float); cudaMalloc( (void**)&Bd,size); cudaMemcpy(Bd,B,size,CudaMemcpyHostToDevice); float *Cd; size= hA*wB*sizeof(float); cudaMalloc( (void**)&Cd,size);")
64
void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; // Przydział pamięci dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE); dim3 dimGrid(wB/dimBlock.x,hA/dimBlock.y); Muld >(Ad,Bd,wA,wB,Cd); //Wywołanie asynchroniczne cudaThreadSynchronize(); cudaMemcpy(C,Cd,size,cudaMemcpyDeviceToHost); cudaFree(Ad); cudaFree(Bd); cudaFree(Cd); } void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; // Przydział pamięci dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE); dim3 dimGrid(wB/dimBlock.x,hA/dimBlock.y); Muld >(Ad,Bd,wA,wB,Cd); //Wywołanie asynchroniczne cudaThreadSynchronize(); cudaMemcpy(C,Cd,size,cudaMemcpyDeviceToHost); cudaFree(Ad); cudaFree(Bd); cudaFree(Cd); }
 { int size; // Przydział pamięci dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE); dim3 dimGrid(wB/dimBlock.x,hA/dimBlock.y); Muld >(Ad,Bd,wA,wB,Cd); //Wywołanie asynchroniczne cudaThreadSynchronize(); cudaMemcpy(C,Cd,size,cudaMemcpyDeviceToHost); cudaFree(Ad); cudaFree(Bd); cudaFree(Cd); } void Mul(const float *A, float *B, int hA, int wA, int wB) { int size; // Przydział pamięci dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE); dim3 dimGrid(wB/dimBlock.x,hA/dimBlock.y); Muld >(Ad,Bd,wA,wB,Cd); //Wywołanie asynchroniczne cudaThreadSynchronize(); cudaMemcpy(C,Cd,size,cudaMemcpyDeviceToHost); cudaFree(Ad); cudaFree(Bd); cudaFree(Cd); }")
65
6000x6000 matrix multiplication

Podobne prezentacje


 Klasy i obiekty.>")
 Przeciążanie operatorów.>")







![Uzupełnienie dot. przekazywania argumentów #include struct nowa { int f; char line[20000]; int k; } reprezentant; int main() { void funkcja7( struct nowa.](/1/400587/big_thumb.jpg "Uzupełnienie dot. przekazywania argumentów #include struct nowa { int f; char line[20000]; int k; } reprezentant; int main() { void funkcja7( struct nowa.>")







. n Zdarzenia mogą być proste lub złożone, co zostanie omówione.>")
