Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Segmentacja rynku i profilowanie segmentów Prof. dr hab. Eugeniusz Gatnar egatnar@mail.wz.uw.edu.pl

2
RÓSZKIEWICZ M. (2002), Metody ilościowe w badaniach marketingowych, PWN, Warszawa. GATNAR E., WALESIAK M. (2004), Metody statystycznej analizy wielowymiarowej w badaniach marketingowych, Wydawnictwo AE, Wrocław. WALESIAK M., GATNAR E. (2009), Statystyczna analiza danych z wykorzystaniem programu R, PWN, Warszawa. Literatura podstawowa:
, Metody statystycznej analizy wielowymiarowej w badaniach marketingowych, Wydawnictwo AE, Wrocław. WALESIAK M., GATNAR E. (2009), Statystyczna analiza danych z wykorzystaniem programu R, PWN, Warszawa. Literatura podstawowa:.")
3
Segmentacja rynku to podział konsumentów lub produktów na jednorodne grupy nazywane segmentami. Do tego celu wykorzystujemy metody taksonomiczne. Profilowanie segmentów oznacza znalezienie charakterystyki konsumentów lub produktów znajdujących się w poszczególnych segmentach rynku. Do tego celu wykorzystujemy metody dyskryminacyjne. Definicje

4
Do najczęściej używanych programów komputerowych realizujących analizę danych należą: SPSS (j. polski), STATISTICA (j. polski) R SAS MATLAB STATGRAPHICS SYSTAT i inne specjalistyczne Oprogramowanie:
, STATISTICA (j. polski) R SAS MATLAB STATGRAPHICS SYSTAT i inne specjalistyczne Oprogramowanie:.")
5
Metody taksonomiczne

6
Pozwala odkryć strukturę klas, tj. dokonać podziału zbioru obiektów S na klasy (grupy) o podobnych własnościach, na podstawie macierzy odległości lub podobieństwa między obiektami. Metody bezpośrednie (obszarowe) - przestrzeń klasyfikacji jest dzielona na rozłączne obszary zawierające obiekty podobne (leżące blisko siebie). Przestrzeń klasyfikacji - zbiór cech obiektów (X) należących do zbioru S, które podlegają klasyfikacji. Obszarami tymi mogą być hiperkostki, hiperkule, itp Taksonomia
 o podobnych własnościach, na podstawie macierzy odległości lub podobieństwa między obiektami. Metody bezpośrednie (obszarowe) - przestrzeń klasyfikacji jest dzielona na rozłączne obszary zawierające obiekty podobne (leżące blisko siebie). Przestrzeń klasyfikacji - zbiór cech obiektów (X) należących do zbioru S, które podlegają klasyfikacji. Obszarami tymi mogą być hiperkostki, hiperkule, itp Taksonomia.")
7
Pierwsza metoda taksonomii (1913) opracowana dla potrzeb antropologii. 1. Rysuje się diagram przyjmując odpowiednie symbole dla wyznaczonych poziomów podobieństwa (odległości), korzystając np. z kwartyli. 2. Porządkuje się diagram poprzez przestawianie wierszy i odpowiadających im kolumn tak, by symbole reprezentujące najmniejszą odległość (największe podobieństwo) leżały jak najbliżej głównej przekątnej. 3. Uporządkowany diagram pozwala wyznaczyć klasy obiektów podobnych. Metoda Czekanowskiego
, korzystając np. z kwartyli. 2. Porządkuje się diagram poprzez przestawianie wierszy i odpowiadających im kolumn tak, by symbole reprezentujące najmniejszą odległość (największe podobieństwo) leżały jak najbliżej głównej przekątnej. 3. Uporządkowany diagram pozwala wyznaczyć klasy obiektów podobnych. Metoda Czekanowskiego.")
8
Zalety: wizualizacja odległości. Wady: trudności w doborze poziomów podobieństw, niejednoznaczność końcowego podziału, duża pracochłonność dla dużej liczby obiektów.

9
optymalizacyjno-iteracyjne, które dokonują podziału zbioru obiektów na K wzajemnie rozłącznych podzbiorów, przy czym wartość parametru K jest podawana przez badacza, hierarchiczne, w ramach których skupienia tworzą binarne drzewa, których liście reprezentują poszczególne obiekty, a węzły - ich grupy, tj. skupienia wyższego poziomu zawierają w sobie skupienia z poziomu niższego, Metody taksonometryczne

10
aglomeracyjne, polegające na sukcesywnym łączeniu skupień (zakłada się, że początkowo każdy obiekt tworzy osobne skupienie), podziałowe, w ramach których początkowy zbiór obiektów (jedno skupienie) jest dzielony kolejno na dwie części, aż do momentu, gdy każdy obiekt znajdzie się w osobnej klasie. Metody te mogą być stosowane jedynie dla stosunkowo małego zbioru obiektów, tj. do 200 jednostek (ze względu na pojemność pamięci komputera, w której przechowywana jest macierz odległości). Metody hierarchiczne
. Metody hierarchiczne.")
11
UWAGA: Zmienne charakteryzujące klasyfikowane obiekty muszą zostać poddane standaryzacji.

12
Typową reprezentacją rezultatów działania tych metod są dendrogramy, będące drzewami binarnymi, których węzły odpowiadają utworzonym skupieniom. o1o1 o2o2 o3o3 o4o4 o5o5

13
Algorytm hierarchicznych metod aglomeracyjnych 1. Każdy obiekt stanowi osobną klasę (skupienie). 2. Na podstawie macierzy odległości pomiędzy skupieniami D=[d ij ] znajdź takie dwa skupienia A i B, które leżą najbliżej: 3. Połącz je w jedno skupienie A i usuń skupienie B (usuwając jednocześnie z macierzy D odpowiedni wiersz i kolumnę). 4. Oblicz na nowo odległości pomiędzy nowym skupieniem a wszystkimi pozostałymi, wstawiając ich wartości do macierzy D.
. 4. Oblicz na nowo odległości pomiędzy nowym skupieniem a wszystkimi pozostałymi, wstawiając ich wartości do macierzy D..")
14
5. Powtarzaj kroki 2- 4, aż do momentu, gdy pozostanie jedno skupienie obejmujące wszystkie obiekty (wymiar macierzy D zredukuje się do 1). W przypadku posługiwania się macierzą podobieństw, a nie odległości, szukane są skupienia najbardziej podobne do siebie, tj.
. W przypadku posługiwania się macierzą podobieństw, a nie odległości, szukane są skupienia najbardziej podobne do siebie, tj..")
15
Metody grupowania różnią się między sobą jedynie sposobem obliczania odległości pomiędzy skupieniami (krok nr 4). Jej ogólny zapis ma postać: W praktyce stosuje się kilka najbardziej popularnych, szczegółowych rozwiązań.

16
najbliższego sąsiedztwa (nearest neighbor), która odległość między skupieniami A i B traktuje jako odległość między dwoma najbliższymi obiektami należącymi do tych klas: A B X Xo X o o
, która odległość między skupieniami A i B traktuje jako odległość między dwoma najbliższymi obiektami należącymi do tych klas: A B X Xo X o o")
17
najdalszego sąsiedztwa (furthest neighbor), która ujmuje odległość między skupieniami A i B traktuje jako odległość między najbardziej odległymi obiektami należącymi do A i B: A B X o X X o o
, która ujmuje odległość między skupieniami A i B traktuje jako odległość między najbardziej odległymi obiektami należącymi do A i B: A B X o X X o o")
18
mediany (median clustering), tj. odległość między A i B to odległość środkowa (w sensie mediany) odległości między obiektami należącymi odpowiednio do A i B: A B X X o X o o
 odległości między obiektami należącymi odpowiednio do A i B: A B X X o X o o.")
19
środka ciężkości (centroid clustering), która odległość między skupieniami A i B traktuje jako odległość między ich środkami ciężkości gdzie to odpowiednio środki ciężkości skupienia A i skupienia B. A B X X o X o o

20
metoda Warda (Ward’s method), w której odległość między A i B definiowana jest jako średnia kwadratu odległości środków ciężkości klas:
, w której odległość między A i B definiowana jest jako średnia kwadratu odległości środków ciężkości klas:")
21
Ustalanie liczby klas w metodach hierarchicznych Podział dendrogramu należy dokonać w miejscu, gdzie odległości między łączonymi grupami są największe (najdłuższe gałęzie drzewa). Formalnie kryterium może mieć postać: Lub gdzie względna odległość jest największa (największy przyrost odległości): gdzie d i to długość i-tej gałęzi drzewa.
: gdzie d i to długość i-tej gałęzi drzewa..")
22
Można je wykorzystać w przypadku potrzeby dokonania klasyfikacji większej liczby obiektów (200 i więcej). Wymagają także od użytkownika podania liczby klas K, do których maja być przydzielone obiekty ze zbioru S. Ich istota polega na tym, że optymalizowana jest pewna funkcja jakości podziału obiektów. Najczęściej chodzi o to, by zróżnicowanie (mierzone np. za pomocą wariancji) obiektów w grupach było jak najmniejsze, zaś pomiędzy grupami - jak największe. Metody iteracyjno- optymalizacyjne
 obiektów w grupach było jak najmniejsze, zaś pomiędzy grupami - jak największe. Metody iteracyjno- optymalizacyjne.")
23
Grupowanie obiektów w ramach tych metod przebiega w trzech etapach: 1. Wyznacza się (np. losowo) K obiektów tworzących początkowe skupienia. 2. Kolejne obiekty przydziela się do tego skupienia, które leży najbliżej. 3. Przenosi się obiekty między skupieniami tak, by uzyskać poprawę jakości podziału. Kryterium stopu jest ujmowane w postaci maksymalnej liczby iteracji lub ustalonej wartości progowej miary jakości podziału. Proces klasyfikacji jest także przerywany, gdy w dwóch kolejnych iteracjach nie nastąpi zmiana struktury klas.
 K obiektów tworzących początkowe skupienia. 2. Kolejne obiekty przydziela się do tego skupienia, które leży najbliżej. 3. Przenosi się obiekty między skupieniami tak, by uzyskać poprawę jakości podziału. Kryterium stopu jest ujmowane w postaci maksymalnej liczby iteracji lub ustalonej wartości progowej miary jakości podziału. Proces klasyfikacji jest także przerywany, gdy w dwóch kolejnych iteracjach nie nastąpi zmiana struktury klas..")
24
Do najbardziej znanych optymalizacyjnych metod taksonometrycznych należą: K-średnich, K-medoidów, Wisharta, Thorndike’a. Najpopularniejszą metodą optymalizacyjną jest metoda K-średnich, zaproponowana przez J. MacQueena. W literaturze istnieje kilka jej odmian, np. SPSS realizuje wersję D.N. Sparksa, która polega na tym, że obiekt jest przydzielany do klasy, której środek ciężkości leży najbliżej (w sensie odległości euklidesowej).
..")
25
Metoda K-średnich obejmuje kroki: 1. Ustal liczbę skupień (K), liczbę iteracji (m) oraz wartość progową funkcji kryterium jakości podziału (p). 2. Oblicz współrzędne środków ciężkości dla poszczególnych klas. 3. Przydziel kolejny obiekt ze zbioru do tego skupienia, od którego dzieli go najmniejsza odległość (w sensie odległości euklidesowe). 4. Oblicz nową wartość funkcji kryterium. 5. Jeśli liczba iteracji została osiągnięta lub przekroczono wartość progową (p) zakończ działanie, traktując osiągnięty zbiór klas jako końcowy. W przeciwnym wypadku wykonaj kroki 2 - 4.
, liczbę iteracji (m) oraz wartość progową funkcji kryterium jakości podziału (p). 2. Oblicz współrzędne środków ciężkości dla poszczególnych klas. 3. Przydziel kolejny obiekt ze zbioru do tego skupienia, od którego dzieli go najmniejsza odległość (w sensie odległości euklidesowe). 4. Oblicz nową wartość funkcji kryterium. 5. Jeśli liczba iteracji została osiągnięta lub przekroczono wartość progową (p) zakończ działanie, traktując osiągnięty zbiór klas jako końcowy. W przeciwnym wypadku wykonaj kroki")
26
Funkcja kryterium jakości podziału zbioru obiektów to ogólna suma odległości obiektów od środka ciężkości klas, do których należą: gdzie to środek ciężkości j-tej grupy. Podlega ona minimalizacji. Jeżeli użytkownik nie zna współrzędnych środków ciężkości podanej liczby skupień, są one wyznaczane w ten sposób, by odpowiadały położeniu obiektów w przestrzeni cech.

27
W tym celu najpierw wybieranych jest K pierwszych obiektów ze zbioru i one tworzą zalążki skupień. Następnie pozostałe obiekty są przydzielane do skupień tak, by odległość euklidesowa od nich była jak najmniejsza. Jeśli odległość pomiędzy obiektem a środkiem ciężkości najbliższego skupienia jest większa niż odległość pomiędzy tym środkiem ciężkości, a środkami ciężkości pozostałych skupień, rozważany obiekt staje się środkiem ciężkości skupienia leżącego najbliżej. Tak wybrane zalążki skupień powinny być odpowiednio odległe od siebie i są traktowane jako wejściowe w metodzie K-średnich.

28
Ustalanie liczby klas Trzeba sprawdzić symulacyjnie, jaka liczba klas (np. 2, 3, 4, 5, itd.) daje najlepszą jakość podziału, tj. jak najmniejsze wariancje wewnątrz grup lub lepiej najmniejszy iloraz: Należy usunąć też klasy o względnie małej liczebności (w stosunku do liczebności zbioru S), np. jeden obiekt.
 daje najlepszą jakość podziału, tj. jak najmniejsze wariancje wewnątrz grup lub lepiej najmniejszy iloraz: Należy usunąć też klasy o względnie małej liczebności (w stosunku do liczebności zbioru S), np. jeden obiekt..")
29
Przykład

30
wartość aktywów netto udział kapitału zagranicznego liczba członków % członków płacących składki średnia wartość składki % aktywów zainwestowanych w akcje % aktywów zainwestowanych w bony skarbowe i obligacje opłata członkowska roczny wzrost wartości jednostki uczestnictwa stopa zwrotu

31
Wyniki

33
Analiza dyskryminacyjna (klasyczna)
")
34
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x Dane w przestrzeni cech

35
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x Zagadnienie dyskryminacji

36
Zagadnienie dyskryminacji (c.d.) Zbiór uczący Dyskryminacja Model Przykład zbioru uczącego: y To zbiór obiektów już uprzednio sklasyfikowanych, przy czym “klasa” może oznaczać wartości pewnej zmiennej nominalnej (np. posiadanie karty kredytowej).
..")
37
Proces klasyfikacji w ramach analizy dyskryminacyjnej odbywa się w dwóch etapach: Dyskryminacji, gdy na podstawie posiadanego zbioru uczącego, zawierającego poprawnie sklasyfikowane obiekty, znajdowane są charakterystyki klas. Klasyfikacji, gdy obiekty, których przynależność nie jest znana (należące do tzw. zbioru rozpoznawanego), są przydzielane do odpowiednich, znanych już, klas. Zagadnienie dyskryminacji (c.d.) Zbiór danych ModelKlasyfikacja
, są przydzielane do odpowiednich, znanych już, klas. Zagadnienie dyskryminacji (c.d.) Zbiór danych ModelKlasyfikacja.")
38
Modele dyskryminacyjne Jako pierwszy, problem dyskryminacji skupisk obiektów w wielowymiarowej przestrzeni cech rozważał Fisher, proponując zastosowanie w tym celu funkcji liniowych (Fisher, 1936). Rozpoczął on od opisu wspomnianych zbiorów obiektów w sposób podobny jak w analizie regresji. Każda klas była więc reprezentowana przez model liniowy:

39
Modele dyskryminacyjne (c.d.) Później starano się te zbiory (klasy) rozdzielać (dyskryminować) hiperpłaszczyznami, które maksymalizowały zestandaryzowane odległości między środkami ciężkości grup: Ta odległość osiąga maksimum, gdy:
 Później starano się te zbiory (klasy) rozdzielać (dyskryminować) hiperpłaszczyznami, które maksymalizowały zestandaryzowane odległości między środkami ciężkości grup: Ta odległość osiąga maksimum, gdy:")
40
Modele dyskryminacyjne (c.d.) Oś: jest tzw. zmienną kanoniczną lub kanoniczną funkcją dyskryminacyjną, zaś macierz: to połączona macierz kowariancji.

41
Modele dyskryminacyjne (c.d.) W przypadku „k” klas poszukujemy wektora a, który separuje: gdzie: Kryterium jakości dyskryminacji ma postać: gdzie B i W to odpowiednio macierze wariancji i kowariancji międzygrupowej i wewnątrzgrupowej. Wykorzystując metodę mnożników Lagrange’a dostajemy warunek istnienia ekstremum:

42
Modele dyskryminacyjne (c.d.) Rozwiązaniem są wartości własne: i wektory własne: macierzy: gdzie „s” wyznaczamy jako: Stąd funkcje dyskryminacyjne mają postać: i są nieskorelowane.
 Rozwiązaniem są wartości własne: i wektory własne: macierzy: gdzie „s wyznaczamy jako: Stąd funkcje dyskryminacyjne mają postać: i są nieskorelowane.")
43
Przykład - zbiór „Irys”

44
Wymagania Najczęściej stosowane w praktyce dyskryminanty liniowe wymagają spełnienia dwóch założeń dotyczących zmiennych reprezentujących cechy klasyfikowanych obiektów (Anderson, 1958): zmienne reprezentujące cechy obiektów muszą mieć łącznie wielowymiarowy rozkład normalny, macierze wariancji i kowariancji dla klas muszą być równe.
: zmienne reprezentujące cechy obiektów muszą mieć łącznie wielowymiarowy rozkład normalny, macierze wariancji i kowariancji dla klas muszą być równe.")
45
To, czy pierwsze z powyższych założeń jest spełnione, można sprawdzić stosując testy normalności rozkładu wielowymiarowego. Z kolei równość macierzy kowariancji poszczególnych klas można sprawdzić stosując np. test M Boxa, który jest uogólnieniem testu Bartletta równości macierzy wariancji. Test Boxa

46
Statystyka M ma postać: Test Boxa (c.d.) Przyjmuje ona wartości z przedziału [0,1]. Wartości bliskie „1” oznaczają równość macierzy kowariancji, zaś bliskie „0” - to, że są równe. Rozkład statystyki M jest bardzo czuły na naruszenia założenia o wielowymiarowym rozkładzie normalnym zmiennych reprezentujących cechy klasyfikowanych obiektów.
![Statystyka M ma postać: Test Boxa (c.d.) Przyjmuje ona wartości z przedziału [0,1].](http://images.slideplayer.pl/32/10148985/slides/slide_46.jpg "Wartości bliskie „1 oznaczają równość macierzy kowariancji, zaś bliskie „0 - to, że są równe. Rozkład statystyki M jest bardzo czuły na naruszenia założenia o wielowymiarowym rozkładzie normalnym zmiennych reprezentujących cechy klasyfikowanych obiektów..")
47
Box (1949) podał przybliżony jej rozkład. To znaczy, że: Test Boxa (c.d.) ma rozkład 2 o stopniach swobody. gdzie:
 ma rozkład 2 o stopniach swobody. gdzie:.")
48
Test Boxa (c.d.) Czasami wykorzystywany jest przybliżenie rozkładu statystyki M, które ma rozkład Fishera:
 Czasami wykorzystywany jest przybliżenie rozkładu statystyki M, które ma rozkład Fishera:")
49
Jeśli macierze wariancji i kowariancji w klasach nie są równe, lecz łączny rozkład zmiennych jest normalny, najlepiej stosować kwadratowe funkcje dyskryminacyjne: Jednak w przypadku małych prób oraz dyskryminacji obiektów (a nie zmiennych), można mimo wszystko wykorzystać funkcje liniowe. Dyskryminanty kwadratowe

50
Drzewa klasyfikacyjne (nieparametryczna)
")
51
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x Klasyczna dyskryminacja

52
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x Drzewa klasyfikacyjne (1)
")
53
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x Drzewa klasyfikacyjne (2)
")
54
Rekurencyjny podział przestrzeni x 1 <5 x 2 <4 x 1 >3 x1x1 x2x2 4 35 R1R1 R1R1 R2R2 R2R2 R3R3 R3R3 R4R4 R4R4

55
Rekurencyjny podział (c.d.) 1. Sprawdź, czy wszystkie obiekty w zbiorze uczącym S={(x 1,y 1 ), (x 2,y 2 ),....} należą do tej samej klasy (są jednorodne ze względu na zmienną „y”). Jeżeli tak, to zakończ podział. 2. W przeciwnym wypadku dokonaj wszystkich możliwych podziałów (tj. według każdej cechy x m ) zbioru S na rozłączne podzbiory S 1, S 2,..., S k. 3. Dokonaj oceny każdego z tych podziałów i wybierz najlepszy z nich. 4. Podziel zbiór S na podzbiory zgodnie z najlepszym podziałem i następnie wykonaj ten algorytm (kroki 1 - 4) dla każdego z podzbiorów S 1, S 2,..., S k.
, (x 2,y 2 ),....} należą do tej samej klasy (są jednorodne ze względu na zmienną „y ). Jeżeli tak, to zakończ podział. 2. W przeciwnym wypadku dokonaj wszystkich możliwych podziałów (tj. według każdej cechy x m ) zbioru S na rozłączne podzbiory S 1, S 2,..., S k. 3. Dokonaj oceny każdego z tych podziałów i wybierz najlepszy z nich. 4. Podziel zbiór S na podzbiory zgodnie z najlepszym podziałem i następnie wykonaj ten algorytm (kroki 1 - 4) dla każdego z podzbiorów S 1, S 2,..., S k..")
56
gdzie R k (dla k=1,...,K) to rozłączne obszary w przestrzeni cech, a k - parametry modelu, x - wektor cech (obiekt). Obszary definiowane są następująco: Parametry ustalane poprzez regułę majoryzacji: Model w postaci drzewa klasyfikacyjnego: Model

57
x 5 x 2 x 1 x 3..... S S1S1 SKSK S2S2... Dobór zmiennych do modelu 1) Należy wybrać zmienną x m, która powoduje największą redukcję zróżnicowania zbioru obiektów S: 2) Należy wybrać zmienną x m, która najsilniej wpływa na rozkład zmiennej „y” w uzyskanych podzbiorach S 1, S 2,..., S K. p(k) - frakcja obiektów w podzbiorze S k,
 Należy wybrać zmienną x m, która powoduje największą redukcję zróżnicowania zbioru obiektów S: 2) Należy wybrać zmienną x m, która najsilniej wpływa na rozkład zmiennej „y w uzyskanych podzbiorach S 1, S 2,..., S K. p(k) - frakcja obiektów w podzbiorze S k,.")
58
Miary heterogeniczności (H) (impurity measures) -entropia -wskaźnik zróżnicowania Giniego -błąd klasyfikacji gdzie: j=1,..., J oznacza klasę p(j|k) - frakcja obiektów w podzbiorze S k, które należą do klasy „j”
 (impurity measures) -entropia -wskaźnik zróżnicowania Giniego -błąd klasyfikacji gdzie: j=1,..., J oznacza klasę p(j|k) - frakcja obiektów w podzbiorze S k, które należą do klasy „j")
59
Miary korelacji - chi-kwadrat -symetryczny współczynnik Goodmana i Kruskala

60
Wartości zmiennej x m mogą generować odrębne obszary: mogą też być łączone w zbiory: wykształcenie pśw p ś,w wykształcenie p,ś w Podział wg zmiennych jakościowych podst.śred.wyższe podst.śred. wyższe podst.

61
Podział wg zmiennych ilościowych podział zbioru wartości zmiennej x m na 2 części: następuje dyskretyzacja zbioru wartości, tj. powstają więcej niż dwa przedziały: wydatki <=200 wydatki >200 <=200(200,600]>600

62
Wybór optymalnej wielkości drzewa Dwie pożądane cechy modeli: - maksymalnie duża precyzja predykcji, - prostota. Precyzję reprezentuje błąd klasyfikacji - e(D), zaś złożoność można mierzyć liczbą podzbiorów (liczbą liści - L(D)). Ponieważ im większe drzewo, tym mniejsza wartość błędu klasyfikacji, to należy zastosować miarę równoważącą obie własności modelu - R(D). Ma ona charakter funkcji, która pozwala uzyskać kompromis pomiędzy wielkością drzewa i precyzją klasyfikacji: Funkcja ta steruje procesem przycinania drzewa.
, zaś złożoność można mierzyć liczbą podzbiorów (liczbą liści - L(D)). Ponieważ im większe drzewo, tym mniejsza wartość błędu klasyfikacji, to należy zastosować miarę równoważącą obie własności modelu - R(D). Ma ona charakter funkcji, która pozwala uzyskać kompromis pomiędzy wielkością drzewa i precyzją klasyfikacji: Funkcja ta steruje procesem przycinania drzewa..")
63
Przycięcie drzewa (pruning) Procedura przycinania krawędzi drzewa polega na sprawdzaniu każdego wierzchołka w, nie będącego liściem (poczynając od dołu drzewa) i porównywaniu wielkości błędu dla niego oraz dla zawieszonego w nim drzewa podrzędnego D(w). Jeżeli usunięcie D(w) spowoduje redukcję błędu, to należy je wykonać.
 spowoduje redukcję błędu, to należy je wykonać..")
64
Zalety drzew klasyfikacyjnych metoda nieparametryczna, dowolna wielkość zbioru danych, nie wymaga selekcji zmiennych (są one dobierane automatycznie), zmienne mogą być mierzone na dowolnych skalach, jest niezmiennicza ze względu na przekształcenia zmiennych, odporna na wartości oddalone, dane mogą być niepełne (braki wartości).
, zmienne mogą być mierzone na dowolnych skalach, jest niezmiennicza ze względu na przekształcenia zmiennych, odporna na wartości oddalone, dane mogą być niepełne (braki wartości).")
65
Przykład Dane:ocena wniosków kredytowych: „dobry” lub „zły” Zmienne: wiek, stanowisko (praca), wynagrodzenie, karta kredytowa Źródło: Blake i inni, 1998 Obserwacje:323 osoby
, wynagrodzenie, karta kredytowa Źródło: Blake i inni, 1998 Obserwacje:323 osoby")
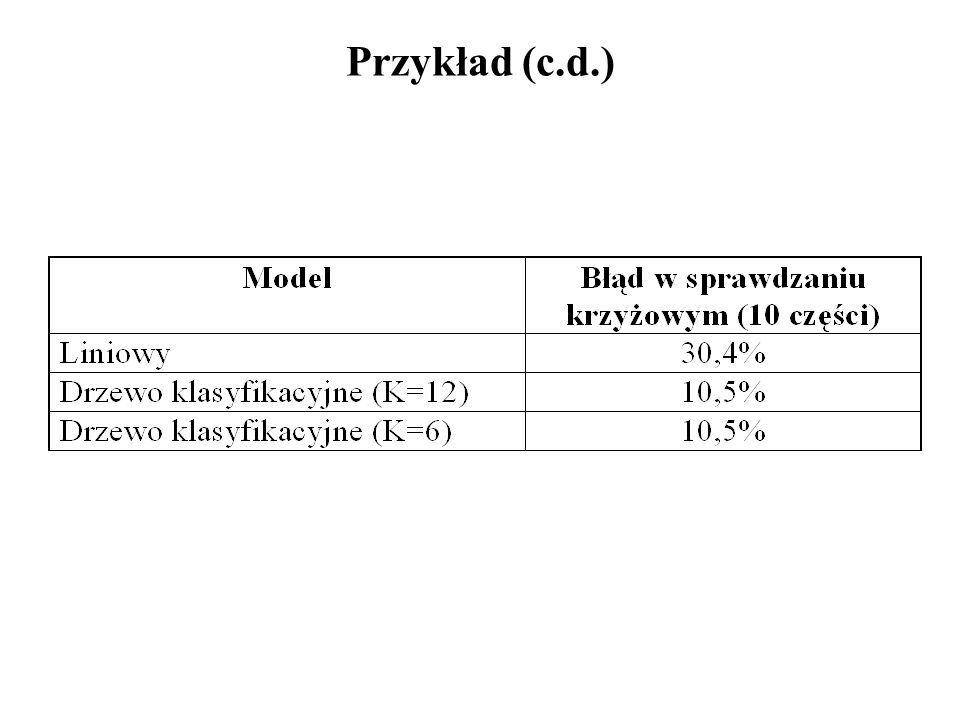
66
Przykład (c.d.)
")
68
IF (Rodzaj wynagradzania = "Miesięcznie") AND (Wiek IS MISSING OR (Wiek > "do 25 lat")) THEN Prediction = Dobry Probability = 0,990826 IF (Rodzaj wynagradzania != "Miesięcznie") AND (Wiek IS MISSING OR (Wiek <= "25 - 35 lat")) THEN Prediction = Zły Probability = 0,905063 IF (Rodzaj wynagradzania != "Miesięcznie") AND (Wiek NOT MISSING AND (Wiek > "25 - 35 lat")) THEN Prediction = Dobry Probability = 1,000000 IF (Rodzaj wynagradzania = "Miesięcznie") AND (Wiek NOT MISSING AND (Wiek <= "do 25 lat")) AND (Rodzaj pracy (stanowisko) != "Pracownik administracji" AND Rodzaj pracy (stanowisko) != "Kierownik") THEN Prediction = Zły Probability = 0,585366 IF (Rodzaj wynagradzania = "Miesięcznie") AND (Wiek NOT MISSING AND (Wiek <= "do 25 lat")) AND (Rodzaj pracy (stanowisko) = "Pracownik administracji" OR Rodzaj pracy (stanowisko) = "Kierownik") THEN Prediction = Dobry Probability = 1,000000
 AND (Wiek IS MISSING OR (Wiek > do 25 lat )) THEN Prediction = Dobry Probability = 0, IF (Rodzaj wynagradzania != Miesięcznie ) AND (Wiek IS MISSING OR (Wiek <= lat )) THEN Prediction = Zły Probability = 0, IF (Rodzaj wynagradzania != Miesięcznie ) AND (Wiek NOT MISSING AND (Wiek > lat )) THEN Prediction = Dobry Probability = 1, IF (Rodzaj wynagradzania = Miesięcznie ) AND (Wiek NOT MISSING AND (Wiek <= do 25 lat )) AND (Rodzaj pracy (stanowisko) != Pracownik administracji AND Rodzaj pracy (stanowisko) != Kierownik ) THEN Prediction = Zły Probability = 0, IF (Rodzaj wynagradzania = Miesięcznie ) AND (Wiek NOT MISSING AND (Wiek <= do 25 lat )) AND (Rodzaj pracy (stanowisko) = Pracownik administracji OR Rodzaj pracy (stanowisko) = Kierownik ) THEN Prediction = Dobry Probability = 1,000000")
Podobne prezentacje







>")











 Wykład 6/7: Analiza statystyczna wyników symulacyjnych Dr inż. Halina Tarasiuk (halina@tele.pw.edu.pl),>")
