Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Twarze sondażu Warsztat 2015 Skalowanie jedno-wymiarowe wprowadzenie Henryk Banaszak Zakład Statystyki, Demografii i Socjologii Matematycznej

2
Program Klasyczna teoria pomiaru Uogólniona teoria pomiaru Skalowanie: wskaźnik, cecha ukryta, funkcja skalująca. Typologia modeli skalowania: poziom pomiaru wskaźników: typ relacji miedzy wskaźnikami i cechą skalowaną: Problemy skalowania i sposoby ich rozwiązywania: Miejsce i rola r-ku p-twa i statystyki w modelu skalowania Przegląd wybranych modeli skalowania: Kumulatywne modele skalowania i ich generalizacje w IRT: Bogardus, Guttman, Mokken, Rasch Addytywne modele skalowania: Likert, Thurstone, klasyczna teoria testów Jednowymiarowa analiza czynnikowa jako model skalowania addytywnego: ograniczenia, problemy i rozwiązania Analiza skupień jako szczególny przypadek skalowania nominalnego Analiza ukrytej struktury Lazarsfelda Popularne modele identyfikacji skupień Probabilistyczne modele analizy skupień Oprogramowanie współczesnych modeli skalowania: Oprogramowanie IRT: MSP5, ICL, WinSteps, ProQuest, ParScale Moduły skalowania w popularnych pakietach statystycznych - R

3
P i S zapoznana problematyka metodologii badań sondażowych Pomiar i Skalowanie Zainstalować SPSS 22 (PS Imago 2) wraz z rozszerzeniem R (R Essentials) Zainstalować R
 wraz z rozszerzeniem R (R Essentials) Zainstalować R")
4
Pomiar Pomiarem w sensie klasycznym jest operacją polegającą na I.wykazaniu, że istnieje reguła, według której można przedmiotom przypisać liczby w taki sposób, aby na podstawie liczb przypisanych obiektom można było orzekać o zachodzeniu relacji empirycznych między nimi II.(oraz) ustaleniu na ile to przyporządkowanie jest jednoznaczne, w jakim stopniu można modyfikować przypisane obiektom liczby bez utraty informacji o własnościach obiektów, którą zawierają, a więc czy istnieje wiele równoważnych sposobów tego przyporządkowania Mierzenie jest zatem operacją polegającą na dowodzeniu twierdzeń. Aby pokazać, o czym wypowiadają się twierdzenia i na czym polega ich dowodzenie, problem pomiaru trzeba sformułować formalnie Aby pokazać, o czym wypowiadają się twierdzenia i na czym polega ich dowodzenie, problem pomiaru trzeba sformułować formalnie

5
Pomiar to reprezentowanie fizycznych własności obiektów przez liczby Fukcja pomiarowa f ustala odpowiedniość między empirycznymi i liczbowym systemem relacyjnym f : E = , R 1, R 2, …, R k - zbiór liczb, podzbiór zbioru liczb rzeczywistych R 1, R 2, …, R k - relacje między liczbami Liczzbowy system relacyjny E = , E 1, E 2, …, E k = { 1, 2, …., n } – zbiór obiektów empirycznych E 1, E 2, …, E k - relacje między obiektami empirycznymi Empiryczny system relacyjny każdemu obiektowi empirycznemu I przyporządkowuje liczbę f ( I ) każdej empirycznej relacji E 1, E 2, …, E k przyporządkowuje relację liczbową R 1, R 2, …, R k: relacjom empirycznym między obiektami odpowiadają relacje między przyporządkowanymi im liczbami f( ) f (E i ) = R i i E k j f ( i )R k ( j ), gdzie R k = f (E k )
 każdej empirycznej relacji E 1, E 2, …, E k przyporządkowuje relację liczbową R 1, R 2, …, R k: relacjom empirycznym między obiektami odpowiadają relacje między przyporządkowanymi im liczbami f( ) f (E i ) = R i i E k j f ( i )R k ( j ), gdzie R k = f (E k )")
6
11 22 33 Empiryczny system relacyjny = { 1, 2, 3 } E = , 11 22 33 11 011 22 001 33 000 Dwa liczbowe systemy relacyjne 1 = N 1 , < N 1 = {3, 5, 7} 3 < 5 < 7 2 = N 2 , < N 2 = {¼, ⅓, ⅞} ¼ < ⅓ < ⅞ liczby relacja mniejszości obiekty empiryczne empiryczna relacja bycia mniejszym Jakie przekształcenie przeprowadza 1 w 2 ? Reprezentacyjna koncepcja pomiaru (Stevens, 1946) 1 21 2 2 32 3 Relacje empiryczne trzeba ustalić praktycznie Relacje między sytemami liczbowymi mają charakter formalny
 1 21 2 2 32 3 Relacje empiryczne trzeba ustalić praktycznie Relacje między sytemami liczbowymi mają charakter formalny.")
7
11 22 33 11 011 22 001 33 000 E = , f 1 : E 1 f 1 ( 1 ) = 3 f 1 ( 2 ) = 5 f 1 ( 3 ) = 7 f 1 ( ) = N 1 = {3, 5, 7} 1 21 2 3 < 5 2 32 3 5 < 7 f 2 : E 2 f 2 ( 1 ) = ¼ f 2 ( 2 ) = ⅓ f 2 ( 3 ) = ⅞ f 2 ( ) = N 2 = {¼, ⅓, ⅞} 1 21 2 ¼ < ⅓ 2 32 3 ⅓ < ⅞ Funkcja pomiarowa. Na ile sposobów można zmierzyć własności tych samych obiektów? Jeden empiryczny system relacyjny – dwie funkcje pomiarowe. Co je łączy?

8
Dwa problemy klasycznej teorii pomiaru I.Problem istnienia II.Problem jednoznaczności Jakie formalne cechy musi mieć empiryczny system relacyjny, aby istniała dla niego funkcja pomiarowa Jeśli dla danego empirycznego systemu relacyjnego istnieje funkcja pomiarowa, to co można zrobić z jej wartościami aby nie utracić informacji o własnościach obiektów Roziązanie obu problemów polegaja na udowodzeniu twierdzeń Twierdzenia dotyczą formalnych własności empirycznego systemu relacyjnego E = , I.Jeśli relacja jest asymetryczna, spójna i przechodnia w , to istnieje funkcja pomiarowa f : E , gdzie = , < , taka, że: i j f ( i ) < f ( j ), II.Każdą rosnąca funkcja funkcji f jest również funkcją pomiarową: f( i ) < f( j ) g(f ( i )) < g(f( j ))
 < f ( j ), II.Każdą rosnąca funkcja funkcji f jest również funkcją pomiarową: f( i ) < f( j ) g(f ( i )) < g(f( j ))")
9
Klasyfikacja poziomów pomiaru – Typologia zmiennych statystycznych Empiryczny system relacyjnyOpis systemu relacyjnegoPrzykłady E = , klasyfikacja brak uporządkowania kategorii, brak jednostki pomiaru płeć, wyznanie, stan cywilny rasa E = , , klasyfikacja, porządek na klasach umożliwia uporządkowanie kategorii brak punktu zerowego i jednostki pomiaru poziom wykształcenia, skala twardości minerałów Mohsa, większość skal ocen i postaw E = , , , , klasyfikacja, porządek na klasach różnica, porządek na różnicach umożliwia porównywanie różnic określone arbitralnie: punkt zerowy i jednostka pomiaru temperatura w stopniach Celsjusza, data kalendarzowa, użyteczność, skala twardości metali Brinella E = , , , , , klasyfikacja, porządek na klasach różnica, porządek na różnicach składanie obiektów umożliwia porównywanie stosunków określony jednoznacznie punkt zerowy, arbitralna jednostka pomiaru staż pracy, wysokość zarobków, wzrost w cm

10
Klasyfikacja poziomów pomiaru – Typologia zmiennych statystycznych Empiryczny system relacyjnyWłasności relacjiWłasności funkcji pomiarowej E = , i j j i i j f( i ) = f ( j ) E = , , j.w. oraz i j ( j i ) ( i j j k ) i k j.w. oraz i j f ( i ) < f ( j ) E = , , , , j.w. oraz jest słabym porządkiem na parach obiektów ij, km : ij = ( i, j ), km = ( k, m ) j.w. oraz ij km f ( i ) - f ( j ) > f ( k ) - f ( m ) E = , , , , , j.w. oraz jest operacją składania (łączenia ze sobą) obiektów j.w. oraz i ( j k ) f ( i ) = f ( j ) + f ( k )
 ( i j j k ) i k j.w. oraz i j f ( i ) < f ( j ) E = , , , , j.w. oraz jest słabym porządkiem na parach obiektów ij, km : ij = ( i, j ), km = ( k, m ) j.w. oraz ij km f ( i ) - f ( j ) > f ( k ) - f ( m ) E = , , , , , j.w. oraz jest operacją składania (łączenia ze sobą) obiektów j.w. oraz i ( j k ) f ( i ) = f ( j ) + f ( k ).")
11
Relacje w zbiorze obiektów empirycznych, które trzeba empirycznie stwierdzić lub założyć System relacyjnyNazwa poziomu pomiaru Równoważność E = , nominalny Równoważność, Porządek E = , , porządkowy Równoważność Porządek Odległość obiektów Identyczność odległości Porządek odległości Operacja „dodawania” obiektów Różnica wyróżniona: „zero” E = , , , , interwałowy Rówoważność, Porządek Odległość obiektów Identyczność odległości Porządek odległości Operacja „dodawania” obiektów Różnica wyróżniona: „zero” Stosunek obiektów Identyczność stosunków Porządek stosunków Obiekt wyróżniony: „jedynka” E = , , , , , ilorazowy Klasyfikacja poziomów pomiaru – Typologia zmiennych statystycznych c.d.

12
Funkcja pomiarowa a zmienna statystyczna f 1 : E 1 f 1 ( 1 ) = 3 f 1 ( 2 ) = 5 f 1 ( 3 ) = 7 X( ) 11 3 11 5 11 7 X : N 1 E = , = { 1, 2, 3 } 1 = N 1 , < X( 1 ) = 3 X( 2 ) = 5 X( 3 ) = 7 N1N1 N 1 = {3, 5, 7} Funkcja pomiarowa Zmienna statystyczna
 = 3 f 1 ( 2 ) = 5 f 1 ( 3 ) = 7 X( ) 11 3 11 5 11 7 X : N 1 E = , = { 1, 2, 3 } 1 = N 1 , < X( 1 ) = 3 X( 2 ) = 5 X( 3 ) = 7 N1N1 N 1 = {3, 5, 7} Funkcja pomiarowa Zmienna statystyczna")
13
Klasyfikacja poziomów pomiaru – Typologia zmiennych statystycznych c.d. System relacyjnyDopuszczalne przekształcenia f Dopuszczalne statystyki E = , klasyfikacja g(f ( )), g: , g jest funkcją odwracalną modalna, entropia, entropijne współczynniki zależności E = , , klasyfikacja, porządek na klasach g(f( )), g: , g jest funkcją rosnącą jw. oraz mediana, współczynniki korelacji rangowej E = , , , , klasyfikacja, porządek na klasach różnica, porządek na różnicach g(f( )), g: , g jest funkcją liniową: g(f( )) = bf( )+a b > 0 jw. oraz średnia, wariancja, współczynnik korelacji liniowej, E = , , , , , klasyfikacja, porządek na klasach różnica, porządek na różnicach składanie obiektów g(f( )), g: , g jest funkcją podobieństwa: g(f( )) = bf( ) b > 0 jw.
), g: , g jest funkcją odwracalną modalna, entropia, entropijne współczynniki zależności E = , , klasyfikacja, porządek na klasach g(f( )), g: , g jest funkcją rosnącą jw. oraz mediana, współczynniki korelacji rangowej E = , , , , klasyfikacja, porządek na klasach różnica, porządek na różnicach g(f( )), g: , g jest funkcją liniową: g(f( )) = bf( )+a b > 0 jw. oraz średnia, wariancja, współczynnik korelacji liniowej, E = , , , , , klasyfikacja, porządek na klasach różnica, porządek na różnicach składanie obiektów g(f( )), g: , g jest funkcją podobieństwa: g(f( )) = bf( ) b > 0 jw..")
14
Poziom pomiaru zmiennej statystycznej określa klasa dopuszczalnych przekształceń jej wartości Zmienna statystyczna jest zawsze obserwowalna Specyfika zmiennej binarnej Każde różnowartościowe przekształcenie zmiennej dwuwartościowej jest przekształceniem liniowym

15
Uogólniona praktyczna koncepcja pomiaru w badaniach sondażowych

16
Rejestracja danych w badaniu sondażowym Porównywanie obiektów parami Deklaracja wartości zmiennej nominalnej Pytanie rozstrzygnięcia Porządkowanie zbioru obiektów Wymuszone reakcje porządkowe Deklaracja wartości zmiennej interwałowej Wybór k spośród n – wektor binarny Graf obciązony porządkowo Zdał – nie zdał Preferencja A nad B: zaufanie, ocena działalności Uporządkuj od najbardziej … do najmniej Na skali od 1 do k określ jak bardzo …. Zawód, wyznanie, stan cywilny, zamiar głosowania na Staż pracy, ile czasu przed TV, jak często robisz … Wskaż te obiekty, które są …… Jak bardzo intensywna jest relacja z każym z k obieków Zadanie rozwiązał na k punktów z n możliwych

17
problem istnienia struktury Uogólniony problem pomiaru rejestracja danych identyfikacja struktury danych zarejestrowanych pomiar jako wzór strukturalny problem stopnia rozmycia struktury problem jednoznaczności funkcji pomiarowej dla struktur nierozmytych Klasyfikacja E = , Porządek E = , , Odległość E = , , , , W porónywaniu parami zaresjestrowano powyższe reakcje respondenta. Jakie wartości zmiennej X można przyporządkować obiektom Do której z typowych struktur najbardziej podobna jest struktura relacji respondenta? Struktury typowe typowe wzory strukturalne

18
Problem skalowania Wskaźniki są wynikiem pomiaru znanego typu, co oznacza, że dla każdego z nich znany jest zakres dopuszczalnych analiz statystycznych, które można na nich wykonywać Zmienną ukrytą oraz obserwowalne wskaźniki typu X i wiąże relacja „bycia wskazywanym”: każdy ze wskaźników „wskazuje” zmienną ukrytą X1X1 X2X2 X3X3 XkXk Poziom pomiaru wskaźników ogranicza repertuar środków statystycznych, za pomocą których opisuje się związek zmiennej ukrytej ze wskaźnikami Związek wskaźników ze zmienną ukrytą jest elementem teorii zjawiska (własności) reprezentowanej przez Teoria
 reprezentowanej przez Teoria ")
19
Cechy ukryte są elementem teorii zjawiska, która wiąże obserwacje (wskaźniki) z konstruktem teoretycznym (cecha ukrytą) za pomocą relacji korespondencji. Skalowanie wynika z teorii cechy ukrytej Korespondencja: Skala Skalogram Model skalowania Własności wskaźników (X 1, X 2, X 3,..., X i,..., X k ) Własności cech ukrytych 1 2 m Relacje (zależności) między cechami obserwowalnymi i ukrytymi R X reguły wnioskowania o cechach ukrytych na podstawie cech obserwowalnych Teoria zjawiska
 Własności cech ukrytych 1 2 m Relacje (zależności) między cechami obserwowalnymi i ukrytymi R X reguły wnioskowania o cechach ukrytych na podstawie cech obserwowalnych Teoria zjawiska.")
20
Model skalowania jest elementem teorii empirycznej Teoria może być empirycznie sfalsyfikowana Skalowanie a falsyfikacja teorii Problem pomiaru: Czy empirycznie stwierdzone własności obiektów empirycznych dają się poprawnie reprezentować liczbowo Problem skalowania: Czy teoria empirycznie własności obiektów empirycznych, z której wynika model skalowania jest prawdziwa

21
W jaki sposób wyznaczyć wartości cechy ukrytej dla obiektu, kórego obserwowalne własności są znane Składowe problemu skalowania Wykonalność Test teorii, z której wywodzi się model skalowania Czy spełnione obiekty empiryczne mają własności zakładane przez model skalowania Czy łączny rozkład wskaźników (X 1, X 2, X 3,..., X i,..., X k ) ma własności postulowane przez model skalowania Askrypcja Jeśli tak, to skalowalność Algorytm skalowania algorytm wyliczania wartości zmiennej ukrytej na podstawie wartości wskaźników
 ma własności postulowane przez model skalowania Askrypcja Jeśli tak, to skalowalność Algorytm skalowania algorytm wyliczania wartości zmiennej ukrytej na podstawie wartości wskaźników")
22
Czym jest skalowanie Ogólny problem skalowania w wersji sformalizowanej ={ω 1, ω 2,..., ω n } (X 1, X 2, X 3,..., X i,..., X k ) : X1X1 X2X2 …..XkXk nn nn W zbiorowości zdefiniowano zestaw obserwowalnych zmiennych typu X i, nazywanych wskaźnikami nieobserwowalnej zmiennej Na podstawie łącznego rozkładu zmiennych –wskaźników wyznacz wartości zmiennej dla każdego obiektu badanej zbiorowości
 : X1X1 X2X2 …..XkXk nn nn W zbiorowości zdefiniowano zestaw obserwowalnych zmiennych typu X i, nazywanych wskaźnikami nieobserwowalnej zmiennej Na podstawie łącznego rozkładu zmiennych –wskaźników wyznacz wartości zmiennej dla każdego obiektu badanej zbiorowości")
23
I. Problem skalowalności 1. Jak dalece łączny rozkład wskaźników jest zgodny z modelem? Jak dobrze model pozwala odtwarzać łączny rozkład wskaźników? Czy zbiór wskaźników jest skalowalny, to znaczy, czy stopień zgodności danych z modelem jest wystarczający? II. Problem liczby wymiarów cechy ukrytej i relacji między nimi 2. Ile cech ukrytych (wymiarów zmiennej ukrytej) trzeba założyć aby dany zbiór wskaźników (w danym zbiorze obiektów) był skalowalny? 3. W jakich relacjach pozostają poszczególne wskaźniki z poszczególnymi wymiarami cechy ukrytej? 4. W jakich relacjach pozostają względem siebie wymiary cechy ukrytej III. Czy wszystkie wskaźniki są potrzebne? 5. Czy w zbiorze wskaźników są pozycje zbędne? Czy są wskaźniki (pozycje testu), z których bez szkody dla skalowalności można zrezygnować? IV. Jakie są własności diagnostyczne poszczególnych wskaźników? 6. Jakie są parametry wskaźników? Których wymiarów cechy ukrytej są wskaźnikami V. Jak skalować 7. Jak przyporządkować obiektom wartości zmiennej ukrytej ? [SCORE] VI. Jaki jest efekt skalowania 8. Jaki rozkład ma cecha ukryta w danym zbiorze obiektów? Poziom pomiarowy skali? Uniwersalne problemy skalowania
 trzeba założyć aby dany zbiór wskaźników (w danym zbiorze obiektów) był skalowalny. 3. W jakich relacjach pozostają poszczególne wskaźniki z poszczególnymi wymiarami cechy ukrytej. 4. W jakich relacjach pozostają względem siebie wymiary cechy ukrytej III. Czy wszystkie wskaźniki są potrzebne. 5. Czy w zbiorze wskaźników są pozycje zbędne. Czy są wskaźniki (pozycje testu), z których bez szkody dla skalowalności można zrezygnować. IV. Jakie są własności diagnostyczne poszczególnych wskaźników. 6. Jakie są parametry wskaźników. Których wymiarów cechy ukrytej są wskaźnikami V. Jak skalować 7. Jak przyporządkować obiektom wartości zmiennej ukrytej . [SCORE] VI. Jaki jest efekt skalowania 8. Jaki rozkład ma cecha ukryta w danym zbiorze obiektów. Poziom pomiarowy skali. Uniwersalne problemy skalowania.")
24
1.Niezmienniczość wyników skalowania przy dopuszczalnych poziomem pomiaru przekształceniach wskaźników; 2.Optymalność algorytmu skalowania, 3.Jednoznaczność i przekonywujące uzasadnienia dla decyzji, które trzeba podejmować rozwiązując problemy (1) - (8) wymienione wyżej. 1.Niezmienniczość wyników skalowania przy dopuszczalnych poziomem pomiaru przekształceniach wskaźników; 2.Optymalność algorytmu skalowania, 3.Jednoznaczność i przekonywujące uzasadnienia dla decyzji, które trzeba podejmować rozwiązując problemy (1) - (8) wymienione wyżej. Kryteria oceny modelu skalowania
 - (8) wymienione wyżej. Kryteria oceny modelu skalowania.")
25
Typologia jedno-wymiarowych modeli skalowania Binarne, Nominalne nominalna Porządkowenominalna Interwałowenominalna BinarneSkalogram Guttmana, Mokkenaporządkowa PorządkoweMokken Politomousporządkowa BinarneModele logistyczne 1PL, 2PL, 3PLinterwałowa PorządkoweRasch, Rating Scale, Partial Creditinterwałowa Interwałowe-porządkowa InterwałoweInterwałowa MIESZANE??????????????? Rodzaj relacji wiążacej wskaźniki z cecha skalowaną Poziom pomiaru wskaźników a poziom pomiaru skali

26
NURTY TEORII SKALOWANIA Kumulatywne Addytywne nominalne Mieszane Poziom pomiaru wskaźników binarne porządkowe interwałowe Typ relacji między cechą ukrytą a wskaźnikami

27
Model Poziom pomiaru wskaźników Rodzaj zależności wskaźników od cech ukrytych Poziom pomiaru cechy ukrytej Analiza ukrytej struktury Lazarsfelda Nominalny Binarny ProbabilistycznyNominalny Analiza skupień K-MeansInterwałowyDeterministyczyNominalny Segmentacja mclustInterwałowyProbabilistycznyNominalny Probabilistyczne metody analizy skupień Nominalny Binarny Interwałowy ProbabilistycznyNominalny Skalogram GuttmanaBinarnyDeterministyczyPorządkowy Skalogram Mokkena Binarny Porządkowy ProbabilistycznyPorządkowy Skalogram Rascha Binarny Porządkowy ProbabilistycznyInterwałowy Eksploracyjna analiza czynnikowa InterwałowyProbabilistycznyInterwałowy Model równań strukturalnychInterwałowyProbabilistycznyInterwałowy Popularne metody analizy danych - szczególne przypadki modeli skalowania

28
Analiza ukrytej struktury dla wskaźników binarnych Problem ukrytej struktury: 1.Znajdź taki rozkład k-wartościowej zmiennej Y definiującej członowy podział n- elementowego zbioru obiektów , przy którym dla każdej klasy podziału {Y=y j } reakcje na bodźce X 1, X 2, ….., X m są kompletnie stochastycznie niezależne: a)Wyznacz brzegowy rozkłada prawdopodobieństaw zmiennej Y b)Dla każdej klasy podziału {Y=y j } wyznacz warunkowe prawdopodobieństwa reakcji P(X i =x i |Y=y j ) c)Zadania a)-b) wykonaj tak, aby przy założeniu warunkowej niezależności reakcji wewnątrz klas {Y=y j } : P(X 1 =x 1 & X 2 =x 2 & ….. X m =x m |Y=y j ) = P(X 1 =x 1 |Y=y j )P(X 2 =x 2 |Y=y j ) …. P(X m =x m |Y=y j ) łączny rozkład zmiennych (X 1, X 2, ….., X m ) dawał się odtworzyć jak najdokładniej 2. Przyporządkuj wartości zmiennej Y obiektom zbioru tak, aby przy rozwiązaniu a)-c) zminimalizować funkcję błędu klasyfikacji
 = P(X 1 =x 1 |Y=y j )P(X 2 =x 2 |Y=y j ) …. P(X m =x m |Y=y j ) łączny rozkład zmiennych (X 1, X 2, ….., X m ) dawał się odtworzyć jak najdokładniej 2. Przyporządkuj wartości zmiennej Y obiektom zbioru tak, aby przy rozwiązaniu a)-c) zminimalizować funkcję błędu klasyfikacji.")
29
Analiza ukrytej struktury dla wskaźników binarnych – przykład - 1 Dane: PGSS, 1999 M ABORCJA: MEZATKA NIE CHCE WIECEJ DZIECI n 1 Tak 379 0,434 2 Nie 495 0,566 Total 874 P ABORCJA: PANNA, NIE CHCE MALZENSTWA n 1 Tak 310 0,355 2 Nie 564 0,645 Total 874 K ABORCJA: KOBIETA TAK CHCE n 1 Tak 287 0,328 2 Nie 587 0,672 Total 874 profil reakcjinp 1112470,283 112290,033 121210,024 122820,094 21190,010 212250,029 221100,011 2224510,516 Brzegowe rozkłady wskaźników M, P, K Łączny rozkład wskaźników M, P, K j P(X 1 = x 1i & X 2 =x 2i & X 3 =x 3i | = j ) *P( = j) jj P( = j ) MPK 111112122222121211212221 1 1 2 3 4 2 x 56 7 próba 0,2830,0330,0940,5160,0240,0100,029x model P(X i = 1 | = j )
 *P( = j) jj P( = j ) MPK x 56 7 próba 0,2830,0330,0940,5160,0240,0100,029x model P(X i = 1 | = j )")
30
Analiza ukrytej struktury dla wskaźników binarnych – przykład – 1 – cd. jj P( = j ) MPK 111112122222121211212221 1,3467,967,927,909 0,2830,0280,0020,0000,0220,0100,001 2,6533,033,073,091 0,0000,0050,0920,5160,0020,0010,0280,011 próba 0,2830,0330,0940,5160,0240,0100,029x model 0,2830,0330,0940,5160,0240,0100,0290,011 P(X i = 1 | = j ) j P(X 1 = x 1i & X 2 =x 2i & X 3 =x 3i | = j ) *P( = j) Profile > 111112122222121211212221 P(profil | = 1 ) 1,0000,8520,0240,0000,9210,9440,0340,067 P(profil | = 2 ) 0,0000,1480,9761,0000,0790,0560,9660,933 Klasa ukryta 1 1111 2 2222 P-two błędu0,0000,1480,0240,0000,0790,0560,0340,067 Rozwiązaniekonsekwencje Reguła wyznaczania przynależności do klasy ukrytej
 MPK ,3467,967,927,909 0,2830,0280,0020,0000,0220,0100,001 2,6533,033,073,091 0,0000,0050,0920,5160,0020,0010,0280,011 próba 0,2830,0330,0940,5160,0240,0100,029x model 0,2830,0330,0940,5160,0240,0100,0290,011 P(X i = 1 | = j ) j P(X 1 = x 1i & X 2 =x 2i & X 3 =x 3i | = j ) *P( = j) Profile > P(profil | = 1 ) 1,0000,8520,0240,0000,9210,9440,0340,067 P(profil | = 2 ) 0,0000,1480,9761,0000,0790,0560,9660,933 Klasa ukryta P-two błędu0,0000,1480,0240,0000,0790,0560,0340,067 Rozwiązaniekonsekwencje Reguła wyznaczania przynależności do klasy ukrytej.")
31
Analiza skupień dla wskaźników porządkowych LCA Cele i wartości życiowe pokolenia 18-29 wedle Diagnozy społecznej

32
Analiza skupień dla wskaźników interwałowych (mclust) Teoria nominalnej cechy ukrytej wskazywanej przez interwałowe zmienne obserwowalne MP2013 : „orientacje społeczne”: aktywność kulturalna – etyka – kapitały społeczne
 Teoria nominalnej cechy ukrytej wskazywanej przez interwałowe zmienne obserwowalne MP2013 : „orientacje społeczne : aktywność kulturalna – etyka – kapitały społeczne")
33
Skalowanie kumulatywne Bogardus Guttman Mokken Rasch Bogardus Guttman Mokken Rasch

34
Nieco historii Bogardus, 1926: skala uprzedzeń (dystansów) etnicznych Czy akceptuje Pan(i) [XXXXX] jako: Dystans społeczny względem grupy Spokrewnionego z Panem(ią) w wyniku małżeństwa [0-1] ?1 Pana(i) bliskiego przyjaciela [0-1] ?2 Pana(i) sąsiada mieszkającego na tej samej ulicy [0-1] ?3 Osoby wykonującej ten sam zawód co Pan(i) [0-1] ?4 Obywatela Pana(i) kraju [0-1] ?5 Turysty odwiedzającego Pana(i) kraj [0-1] ?6
![Nieco historii Bogardus, 1926: skala uprzedzeń (dystansów) etnicznych Czy akceptuje Pan(i) [XXXXX] jako: Dystans społeczny względem grupy Spokrewnionego z Panem(ią) w wyniku małżeństwa [0-1] 1 Pana(i) bliskiego przyjaciela [0-1] 2 Pana(i) sąsiada mieszkającego na tej samej ulicy [0-1] 3 Osoby wykonującej ten sam zawód co Pan(i) [0-1] 4 Obywatela Pana(i) kraju [0-1] 5 Turysty odwiedzającego Pana(i) kraj [0-1] 6](http://images.slideplayer.pl/28/9356605/slides/slide_34.jpg "Nieco historii Bogardus, 1926: skala uprzedzeń (dystansów) etnicznych Czy akceptuje Pan(i) [XXXXX] jako: Dystans społeczny względem grupy Spokrewnionego z Panem(ią) w wyniku małżeństwa [0-1] 1 Pana(i) bliskiego przyjaciela [0-1] 2 Pana(i) sąsiada mieszkającego na tej samej ulicy [0-1] 3 Osoby wykonującej ten sam zawód co Pan(i) [0-1] 4 Obywatela Pana(i) kraju [0-1] 5 Turysty odwiedzającego Pana(i) kraj [0-1] 6")
35
Skok wzwyż Kategoria zawodnika 180190200 Liczba udanych prób a0000 b1001 c1102 d1113

36
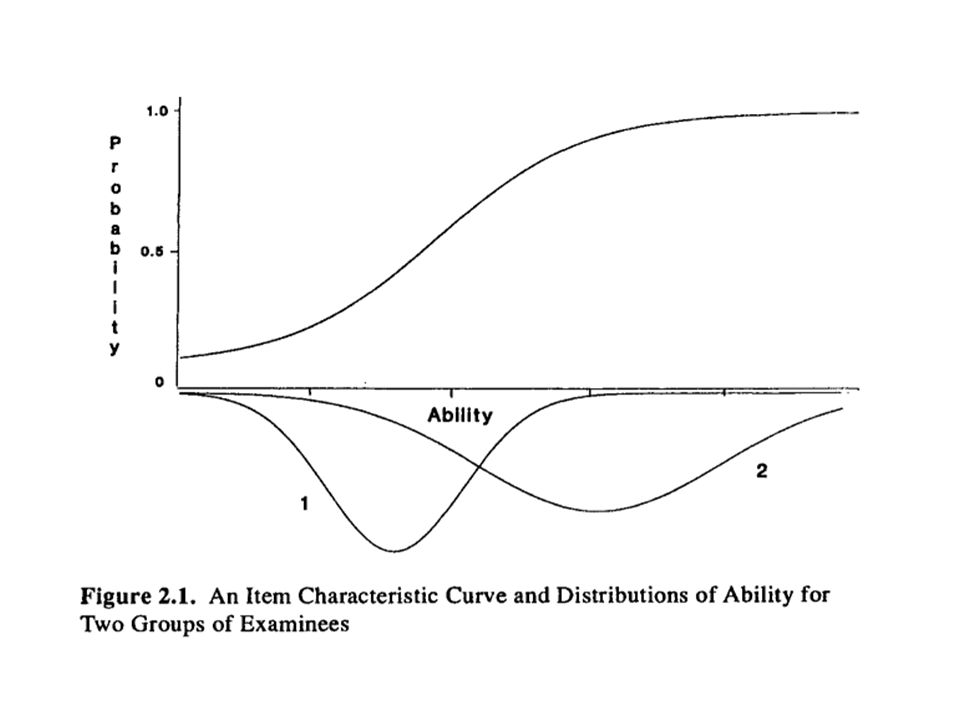
Funkcje reakcji na pozycje testu

37
Model skalowania w zapisie formalnym , , , , P = {ω 1, ω 2, ω 3,..., ω v,..., ω n } jest n-elementowym zbiorem obiektów, jest k-elementowym zbiorem binarnych wskaźników (X 1, X 2, X 3,..., X i,..., X k ), jest jednowymiarową zmienną ukrytą określoną w , jest ck-elementowym wektorem parametrów wskaźników (X 1,..., X k ), gdzie c=1, 2, 3,... oznacza liczbę parametrów pojedynczej funkcji reakcji; można też traktować jako funkcję, która wskaźnikom przyporządkowuje ich parametry, liczby rzeczywiste, P jest funkcją reakcji wiążącą prawdopodobieństwo P(X iv =x), x {0,1} reakcji obiektu ω v na wskaźnik X i z poziomem cechy ukrytej obiektu (ω v ) oraz poziomem trudności wskaźnika i .
, x {0,1} reakcji obiektu ω v na wskaźnik X i z poziomem cechy ukrytej obiektu (ω v ) oraz poziomem trudności wskaźnika i ..")
38
Skalogram Guttmana w wersji deterministycznej i probabilistycznej (porządek osób) Osoby różnią się pod względem poziomu „umiejętności” ( ) i można je ze względu na tę cechę uporządkować. (porządek wskaźników) Wskaźniki różnią się ze względu na stopień „trudności” ( ) i można je ze względu na tę własność uporządkować. (kumulatywność reakcji) każdy, kto zareagował pozytywnie/poprawnie na wskaźnik o pewnym stopniu trudności reaguje pozytywnie/poprawnie na wszystkie łatwiejsze wskaźniki:
 Wskaźniki różnią się ze względu na stopień „trudności ( ) i można je ze względu na tę własność uporządkować. (kumulatywność reakcji) każdy, kto zareagował pozytywnie/poprawnie na wskaźnik o pewnym stopniu trudności reaguje pozytywnie/poprawnie na wszystkie łatwiejsze wskaźniki:.")
39
Wskaźnik Liczba poprawnych odpowiedzi ProfilX1X1 X2X2 X3X3 A111 3 B110 2 C1012 D0112 E100 1 F0101 G0011 H000 0 Dopuszczalne i niedopuszczalne profile reakcji w skalogramie Guttmana Strukturalne zero X j trudny Suma 01 X i łatwy 0III1-p 1IIIIVp Suma1-qq1,00 Zielone profile: dopuszczalne X i łatwy X j trudny 00 01 10 11

40
Dane przykładowe h X1X2X3 1111 3 21113 31113 41113 51113 61113 7110 2 81102 91102 101102 11100 1 121001 130000 14101 2 151012 160112 17010 1 180101 190011 200011 141311 N( )P( ) 3 60,30 2 70,35 1 60,30 0 10,05 111110100000101011010001 p 111 p 110 p 100 p 000 p 101 p 011 p 010 p 001 0,300,200,100,050,100,050,10 64212122
P( ) 3 60, , , , p 111 p 110 p 100 p 000 p 101 p 011 p 010 p 001 0,300,200,100,050,100,050,")
41
Praktyka skalowania modelem Guttmana Oczekiwane częstości przy założeniu lokalnej niezależności Guttman j P(X 1 = x 1i & X 2 =x 2i & X 3 =x 3i | = j ) *P( = j) P(X i = 1 | = j ) 0,300,350,300,050,00 jj P( = j ) X1X1 X2X2 X3X3 X1X1 X2X2 X3X3 111110100000 C 101D 011F 010G 001 30,301111,00 0,00 20,351101,00 0,00 1,000,00 10,301001,000,00 1,000,00 00,050000,00 1,000,00 p1p1 p2p2 p3p3 p 111 p 110 p 100 p 000 p 101 p 011 p 010 p 001 0,700,650,55<==próba0,300,200,100,050,100,050,10 różnica 0,00-0,15-0,200,000,100,050,10 Wskaźnik Liczba poprawnych odpowiedzi ProfilX1X1 X2X2 X3X3 C1012 D0112 F0101 G0011 Współczynnik skalowalności = funkcja liczby (proporcji) profili niezgodnych w próbie Decyzja o skalowalności
 *P( = j) P(X i = 1 | = j ) 0,300,350,300,050,00 jj P( = j ) X1X1 X2X2 X3X3 X1X1 X2X2 X3X C 101D 011F 010G ,301111,00 0,00 20,351101,00 0,00 1,000,00 10,301001,000,00 1,000,00 00,050000,00 1,000,00 p1p1 p2p2 p3p3 p 111 p 110 p 100 p 000 p 101 p 011 p 010 p 001 0,700,650,55<==próba0,300,200,100,050,100,050,10 różnica 0,00-0,15-0,200,000,100,050,10 Wskaźnik Liczba poprawnych odpowiedzi ProfilX1X1 X2X2 X3X3 C1012 D0112 F0101 G0011 Współczynnik skalowalności = funkcja liczby (proporcji) profili niezgodnych w próbie Decyzja o skalowalności")
42
Skalogram Guttmana – podsumowanie własności 1poziom pomiaru wskaźnikówbinarne 2poziom pomiaru zmiennej ukrytejporządkowy 3 własności łącznego rozkładu wskaźników i cechy ukrytej kumulatywność reakcji bez-wyjątkowa lokalna niezależność reakcji 4 relacja między wskaźnikami i cechą ukrytą deterministyczna 5 algorytmu wyznaczania wartości cechy ukrytej Suma wartości wskaźników 6Kryterium oceny jakości skalowaniaAd hoc

43
I Jak dalece łączny rozkład wskaźników jest zgodny z modelem? Jak dobrze model pozwala odtwarzać łączny rozkład wskaźników? Czy zbiór wskaźników jest skalowalny, to znaczy, czy stopień zgodności danych z modelem jest wystarczający - II Ile cech ukrytych (wymiarów zmiennej ukrytej) trzeba założyć aby dany zbiór wskaźników (w danym zbiorze obiektów) był skalowalny? W jakich relacja pozostają względem siebie wymiary cechy ukrytej? Zakłada się, ze 1 cecha III W jakich relacjach pozostają poszczególne wskaźniki z poszczególnymi wymiarami cechy ukrytej? Czy w zbiorze wskaźników są pozycje zbędne? Czy są wskaźniki (pozycje testu), z których bez szkody dla skalowalności można zrezygnować? ? Usunąć wskaźniki o tym samym poziomie trudności; uczestniczący w mniejszej liczbie profili niezgodnych z modelem IV Jakie są parametry wskaźników? Trudność = frakcja „1” V Jak przyporządkować obiektom wartości zmiennej ukrytej ? Jaki rozkład ma cecha ukryta w danym zbiorze obiektów Suma wartości wskaźników Skalogram Guttmana – podsumowanie c.d.
 trzeba założyć aby dany zbiór wskaźników (w danym zbiorze obiektów) był skalowalny. W jakich relacja pozostają względem siebie wymiary cechy ukrytej. Zakłada się, ze 1 cecha III W jakich relacjach pozostają poszczególne wskaźniki z poszczególnymi wymiarami cechy ukrytej. Czy w zbiorze wskaźników są pozycje zbędne. Czy są wskaźniki (pozycje testu), z których bez szkody dla skalowalności można zrezygnować. Usunąć wskaźniki o tym samym poziomie trudności; uczestniczący w mniejszej liczbie profili niezgodnych z modelem IV Jakie są parametry wskaźników. Trudność = frakcja „1 V Jak przyporządkować obiektom wartości zmiennej ukrytej . Jaki rozkład ma cecha ukryta w danym zbiorze obiektów Suma wartości wskaźników Skalogram Guttmana – podsumowanie c.d..")
44
Czy skalogram Guttmana jest „dobrym modelem skalowania” 1.gwarantuje niezmienniczości wyników skalowania przy dopuszczalnych poziomem pomiaru przekształceniach wskaźników TAK 2.gwarantuje optymalności algorytmu skalowania ????? 3.gwarantuje jednoznaczność i przekonywujące uzasadnienia dla decyzji, które trzeba podejmować rozwiązując problemy (I) - (V) wymienione wyżej NIE
 - (V) wymienione wyżej NIE.")
45
Kumulatywność w wersji probabilistycznej

46
Założenia probabilistycznych modeli skalowania kumulatywnego a sytuacja testowania kompetencji Przykład: osoby rozwiązujące zadania testowe Obiekty różnią się parametrami istotnymi dla wyniku zdarzenia losowego Osoby różnią się poziomem kompetencji, łatwością z jaką rozwiązują zdania testowe Wskaźniki różnią parametrami istotnymi dla wyniku zdarzenia losowego Pytania testowe różnią się stopniem trudności, jaką sprawiają odpowiadającym, Obserwowalna reakcja obiektu na wskaźnik jest zdarzeniem losowym Osoby testowane reagują do pewnego stopnia przypadkowo: osoba bardzo kompetentna może nie odpowiedzieć na pytanie łatwe a osoba mało kompetentna może odpowiedzieć a pytanie trudne Zbiór możliwych reakcji i ich prawdopodobieństwa stanowią zmienną losową, której rozkład zależy od parametrów osoby i parametrów wskaźnika (zmienna losowa – funkcja reakcji) Szanse na poprawą odpowiedź osoby na pojedyncze pytanie testowe zależą zarazem od tego jak trudne jest to pytanie i jak kompetentna jest odpowiadająca na nie osoba Pojedyncza osoba odpowiada na kolejne pytanie testu „bez pamięci” o wynikach poprzednich odpowiedzi i wyłącznie w zależności od tego, jak trudne jest kolejne pytanie i jak kompetentna jest osoba
 Szanse na poprawą odpowiedź osoby na pojedyncze pytanie testowe zależą zarazem od tego jak trudne jest to pytanie i jak kompetentna jest odpowiadająca na nie osoba Pojedyncza osoba odpowiada na kolejne pytanie testu „bez pamięci o wynikach poprzednich odpowiedzi i wyłącznie w zależności od tego, jak trudne jest kolejne pytanie i jak kompetentna jest osoba")
47
Lokalna niezależność reakcji poziom cechy ukrytej osoby reagującej na wskaźniki jest taki sam bez względu na ich kolejność „podawania”, prawdopodobieństwa „poprawnych” reakcji na kolejne wskaźniki zależą wyłącznie od odległości między poziomem cechy ukrytej odpowiadającego i poziomem „trudności” wskaźników, prawdopodobieństwo serii reakcji na wskaźniki dla pojedynczej osoby jest równe iloczynowi prawdopodobieństw reakcji na każdy ze wskaźników z osobna.

48
Lokalna niezależność reakcji Kumulatywnośc reakcji reakcje na wskaźniki są stochastycznie pozytywnie zależne. reakcje na poszczególne wskaźniki w grupach osób o tym samym poziomie umiejętności są od siebie stochastycznie niezależne

49
Przykład skalogramu Guttmana

50
Model Mokkena Krzywe reakcji na trzy wskaźniki w modelu Mokkena

51
Skalogram Mokkena dla trzech wskaźników dychtomicznych

52
Konsekwencje założeń Mokkena - zależność wskaźników Macierz częstości łącznych – zera strulturalne

53
Statystyka dostateczna cechy ukrytej - jak u Guttmana – suma punktów Stopień zgodności danych z modelem Mokken scale – własności Współczynniki Loevinger

54
Skalogram Mokkena– podsumowanie własności 1poziom pomiaru wskaźnikówbinarne 2poziom pomiaru zmiennej ukrytejporządkowy 3 własności łącznego rozkładu wskaźników i cechy ukrytej kumulatywność reakcji probabilistyczna lokalna niezależność reakcji 4 relacja między wskaźnikami i cechą ukrytą probabilistyczna 5 algorytmu wyznaczania wartości cechy ukrytej Suma wartości wskaźników 6Kryterium oceny jakości skalowania?

55
I Jak dalece łączny rozkład wskaźników jest zgodny z modelem? Jak dobrze model pozwala odtwarzać łączny rozkład wskaźników? Czy zbiór wskaźników jest skalowalny, to znaczy, czy stopień zgodności danych z modelem jest wystarczający ? II Ile cech ukrytych (wymiarów zmiennej ukrytej) trzeba założyć aby dany zbiór wskaźników (w danym zbiorze obiektów) był skalowalny? W jakich relacja pozostają względem siebie wymiary cechy ukrytej? Zakłada się, ze 1 cecha III W jakich relacjach pozostają poszczególne wskaźniki z poszczególnymi wymiarami cechy ukrytej? Czy w zbiorze wskaźników są pozycje zbędne? Czy są wskaźniki (pozycje testu), z których bez szkody dla skalowalności można zrezygnować? ? Usunąć wskaźniki o tym samym poziomie trudności; uczestniczący w mniejszej liczbie profili niezgodnych z modelem IV Jakie są parametry wskaźników? Trudność = frakcja „1” V Jak przyporządkować obiektom wartości zmiennej ukrytej ? Jaki rozkład ma cecha ukryta w danym zbiorze obiektów Suma wartości wskaźników Skalogram Mokkena– podsumowanie c.d.
 trzeba założyć aby dany zbiór wskaźników (w danym zbiorze obiektów) był skalowalny. W jakich relacja pozostają względem siebie wymiary cechy ukrytej. Zakłada się, ze 1 cecha III W jakich relacjach pozostają poszczególne wskaźniki z poszczególnymi wymiarami cechy ukrytej. Czy w zbiorze wskaźników są pozycje zbędne. Czy są wskaźniki (pozycje testu), z których bez szkody dla skalowalności można zrezygnować. Usunąć wskaźniki o tym samym poziomie trudności; uczestniczący w mniejszej liczbie profili niezgodnych z modelem IV Jakie są parametry wskaźników. Trudność = frakcja „1 V Jak przyporządkować obiektom wartości zmiennej ukrytej . Jaki rozkład ma cecha ukryta w danym zbiorze obiektów Suma wartości wskaźników Skalogram Mokkena– podsumowanie c.d..")
56
Czy skalogram Mokkena jest „dobrym modelem skalowania” 1.gwarantuje niezmienniczości wyników skalowania przy dopuszczalnych poziomem pomiaru przekształceniach wskaźników TAK 2.gwarantuje optymalności algorytmu skalowania TAK 3.gwarantuje jednoznaczność i przekonywujące uzasadnienia dla decyzji, które trzeba podejmować rozwiązując problemy (I) - (V) wymienione wyżej ~
 - (V) wymienione wyżej ~")
57
I. Problem skalowalności Zalążkowe kryteria, często typu ad hoc pozwalają uznać zestaw wskaźników określonych w pewnej zbiorowości za nieskalowalny jeśli zdarzy się jedna z dwóch sytuacji : współczynnik Lovinger dla całego zestawu będzie niższy niż 0,3 (według Mokkena) albo, gdy macierze P 11 i P 00 będą zawierały wartości zbyt odległe od oczekiwanych, przy czym nie wiadomo co to znaczy "zbyt odległe". Trudno uznać powyższe kryteria rozstrzygania za dobrze uzasadnione, a ponadto oba te warunki są względnie od siebie niezależne. II. Problem liczby wymiarów cechy ukrytej i relacji między nimi Podobnie jak w modelu Guttmana, w skalogramie Mokkena nie ma procedury pozwalającej rozstrzygać tę kwestię. III. Czy wszystkie wskaźniki są potrzebne? Standardowy test dla identyczności populacyjnych proporcji dla zmiennych binarnych (test McNemara) pozwala z w zestawie wskaźników wyeliminować te, które są w nim zbędne, a decyzję przekonywująco, bo statystycznie, uzasadnić. Słabsze podstawy statystyczne ma decyzja o eliminacji z zestawu wskaźnika, dla którego współczynnik Loevinger H i przyjmuje wartość niższą niż 0,3. Niektórzy autorzy jako uzasadnienie decyzji o niekumulatywności rozkładów łącznych, w których występuje wskaźnik X i proponują używać statystyki testującej hipotezę, że współczynnik Loevingera H i dla tego wskaźnika ma w populacji wartość 0, przeciwko hipotezie, że tak nie jest. Zauważmy jednak, że w ten sposób testowana jest hipoteza o niezależności stochastycznej wskaźników a nie o zgodności ich rozkładu z konsekwencjami założenia podwójnej monotoniczności. IV. Jakie są własności diagnostyczne poszczególnych wskaźników? Test McNemara pozwala wykryć wskaźniki o identycznych własnościach diagnostycznych, o tym samym poziomie trudności. Innych parametrów własności diagnostycznych pytań wskaźnikowych skalogram Mokkena nie przewiduje V. Jak skalować - funkcja agregująca profile Mokken wykazał, że liczba poprawnych odpowiedzi jest statystyką dostateczną dla skalowanej cechy ukrytej. Jest to minimalny wymóg stawiany wszelkim procedurom estymacyjnym i dzięki jego spełnianiu można powiedzieć, że w modelu Mokkena oszacowuje się częstości rozkładu cechy ukrytej . Skalogram Mokkena - podsumowanie
 albo, gdy macierze P 11 i P 00 będą zawierały wartości zbyt odległe od oczekiwanych, przy czym nie wiadomo co to znaczy zbyt odległe . Trudno uznać powyższe kryteria rozstrzygania za dobrze uzasadnione, a ponadto oba te warunki są względnie od siebie niezależne. II. Problem liczby wymiarów cechy ukrytej i relacji między nimi Podobnie jak w modelu Guttmana, w skalogramie Mokkena nie ma procedury pozwalającej rozstrzygać tę kwestię. III. Czy wszystkie wskaźniki są potrzebne. Standardowy test dla identyczności populacyjnych proporcji dla zmiennych binarnych (test McNemara) pozwala z w zestawie wskaźników wyeliminować te, które są w nim zbędne, a decyzję przekonywująco, bo statystycznie, uzasadnić. Słabsze podstawy statystyczne ma decyzja o eliminacji z zestawu wskaźnika, dla którego współczynnik Loevinger H i przyjmuje wartość niższą niż 0,3. Niektórzy autorzy jako uzasadnienie decyzji o niekumulatywności rozkładów łącznych, w których występuje wskaźnik X i proponują używać statystyki testującej hipotezę, że współczynnik Loevingera H i dla tego wskaźnika ma w populacji wartość 0, przeciwko hipotezie, że tak nie jest. Zauważmy jednak, że w ten sposób testowana jest hipoteza o niezależności stochastycznej wskaźników a nie o zgodności ich rozkładu z konsekwencjami założenia podwójnej monotoniczności. IV. Jakie są własności diagnostyczne poszczególnych wskaźników. Test McNemara pozwala wykryć wskaźniki o identycznych własnościach diagnostycznych, o tym samym poziomie trudności. Innych parametrów własności diagnostycznych pytań wskaźnikowych skalogram Mokkena nie przewiduje V. Jak skalować - funkcja agregująca profile Mokken wykazał, że liczba poprawnych odpowiedzi jest statystyką dostateczną dla skalowanej cechy ukrytej. Jest to minimalny wymóg stawiany wszelkim procedurom estymacyjnym i dzięki jego spełnianiu można powiedzieć, że w modelu Mokkena oszacowuje się częstości rozkładu cechy ukrytej . Skalogram Mokkena - podsumowanie.")
58
Zmienna losowa o rozkładzie logistycznym

59
Funkcja logistyczna z parametrem a

60
Funkcja reakcji w modelu Rascha 1 PL

61
Warianty modelu Rascha 1PL: x 2PL: a,x 3PL: a,c, x

62
Funkcja informacyjna wskaźnika X i oraz całego testu (X 1, X 2, ……, X k ) Pojęcie funkcji informacyjnej wskaźnika i testu pełni w IRT rolę „rzetelności” w CTT Skalowanie jest estymacją parametrów modelu probabilistycznego odpowiadania na pytania testu. Estymacja dokonywane jest z błędem. Funkcja informacyjna zdaje sprawę z tego, jaki jest błąd estymacji niskich, średnich i wysokich wartości cechy ukrytej Funkcja informacyjna wskaźnika X i zależy od wariantu modelu:

63
wartość funkcji informacyjnej całego testu jest sumą wartości funkcji informacyjnych wszystkich wskaźników: błąd standardowy estymacji poziomu wartości cechy ukrytej Własności testu – rzetelność czyli dokładność oszacowań funkcja informacyjna wskaźnika X i jest odwrotnością wariancji jego estymatora. Jest miarą niepewności, z jaką przyporządkowujemy obiektowi wartość cechy ukrytej na podstawie jego reakcji na wskaźnik X i

64
Funkcja reakcji w modelu Rascha 1 PL

65
Estymacja modelu 1PL a założenia na temat rozkładu cechy ukrytej Statystyką dostateczną parametru osoby jest Statystyką dostateczną parametru wskaźmika jest Sumy r i s odwzorowują porządek obiektów i wskaźników ze względu na nasycenie cechy ukrytej Metody estymacji parametrów najprostszego modelu 1PL: Joint Maximum Likelihood – dla parametrów , jednocześnie Conditional Maximum Likelihood (CML) – dla parametru Modalny Estymator Bayesa (BME) dla parametru Metody estymacji parametrów najprostszego modelu 1PL: Joint Maximum Likelihood – dla parametrów , jednocześnie Conditional Maximum Likelihood (CML) – dla parametru Modalny Estymator Bayesa (BME) dla parametru Dla modeli 2PL oraz 3PL estymacja jest bardziej złożona
 – dla parametru Modalny Estymator Bayesa (BME) dla parametru Metody estymacji parametrów najprostszego modelu 1PL: Joint Maximum Likelihood – dla parametrów , jednocześnie Conditional Maximum Likelihood (CML) – dla parametru Modalny Estymator Bayesa (BME) dla parametru Dla modeli 2PL oraz 3PL estymacja jest bardziej złożona")
66
Funkcja informacyjna wskaźnika dychotomicznego w modelu 1PL -1,013

67
Funkcja informacyjna wskaźnika dychotomicznego w modelu 2PL -0,568 a1a1 6,374 -0,568

68
Przykład skalowania trzech wskaźników z pomoca modelu 1PL wynikają z modelu -1,013-0,743-0,243 P(X i = 1 | = j ) 0,290,200,110,060,120,090,080,05 jj P( = j ) X1X1 X2X2 X3X3 X1X1 X2X2 X3X3 111110100000101011010001 0,6490,301110,8400,8010,7090,480,200,050,010,120,090,040,02 0,0170,351100,7370,6810,5650,280,220,100,040,130,100,080,05 -0,5710,301000,6090,5430,4190,140,190,160,100,120,090,120,07 -1,1520,050000,4650,3990,2870,050,130,200,230,080,060,150,09 p1p1 p2p2 p3p3 p 111 p 110 p 100 p 000 p 101 p 011 p 010 p 001 0,700,650,55próba0,300,200,100,050,100,050,10 różnica0,010,00-0,01 -0,02-0,040,020,05
 0,290,200,110,060,120,090,080,05 jj P( = j ) X1X1 X2X2 X3X3 X1X1 X2X2 X3X ,6490,301110,8400,8010,7090,480,200,050,010,120,090,040,02 0,0170,351100,7370,6810,5650,280,220,100,040,130,100,080,05 -0,5710,301000,6090,5430,4190,140,190,160,100,120,090,120,07 -1,1520,050000,4650,3990,2870,050,130,200,230,080,060,150,09 p1p1 p2p2 p3p3 p 111 p 110 p 100 p 000 p 101 p 011 p 010 p 001 0,700,650,55próba0,300,200,100,050,100,050,10 różnica0,010,00-0,01 -0,02-0,040,020,05")
69
Przykład skalowania trzech wskaźników dychotomicznych za pomocą modelu 1PL -1,013-0,743-0,243

70
Przykład skalowania trzech wskaźników dychotomicznych za pomocą modelu 2PL -0,568-1,113-1,166 aiai 6,3740,6010,173 jj X1X1 X2X2 X3X3 30,285 111 20,157 110 2-0,065 101 1-0,125 100 2-0,804 011 1-0,829 010 1-0,904 001 0-0,942 000 p1p1 p2p2 p3p3 0,700,650,55

71
Przykład skalowania trzech wskaźników dychotomicznych za pomocą modelu 3PL jj X1X1 X2X2 X3X3 3 0,7973 111 2 0,6001 110 2 -0,0286 101 1 -0,0333 100 2 -0,7094 011 1 -0,7095 010 1 -0,7132 001 0 -0,7134 000 cici aiai P(X i = 1 | = ) X1X1 0,140-0,4288,4020,977 X2X2 0,4980,5614,6590,533 X3X3 0,4971,3584,3940,499
 X1X1 0,140-0,4288,4020,977 X2X2 0,4980,5614,6590,533 X3X3 0,4971,3584,3940,499")
72
Modele Rascha - podsumowanie I. Problem skalowalności Nawet proste modele Rascha umożliwiają testowanie (a więc i odrzucenie) hipotezy o skalowalności cechy ukrytej w danej zbiorowości za pomocą danego zestawu wskaźników. Podstawowym środkiem jest u statystyka testowa wywiedziona z ilorazu wiarygodności, która zazwyczaj używa ilorazów liczebności (częstości) empirycznych i przewidywanych przez model do badania stopnia zgodności danych z założeniami modelu. II. Problem liczby wymiarów cechy ukrytej i relacji między nimi Problem liczby wymiarów cechy ukrytej w prostych modelach skalowania nie daje się sformułować wprost jako problem statystyczny. Umożliwiają to dopiero modele złożone. III. Czy wszystkie wskaźniki są potrzebne? Decyzja o zbędności bądź niezbędności wskaźnika w zestawie jest w modelu Rascha uzasadniana nie tylko przy użyciu standardowych technik weryfikacji hipotez lecz także przez wyniki analizy informacyjnych własności pytań testowych. Funkcja ta pozwala kontrolować skutki przyłączania lub wyłączania wskaźników z zestawu dla precyzji estymacji poziomów cechy ukrytej. IV. Jakie są własności diagnostyczne poszczególnych wskaźników? Przebieg funkcji informacyjnej wskaźnika dostarcza wystarczających informacji aby odpowiedzieć na to pytanie. V. Jak skalować Funkcja agregacji profili reakcji w wartości cechy ukrytej jest wynikiem szacowania parametrów modelu. W rozwiniętych modelach Rascha może ona przyjmować tyle wartości ile jest różnych profili reakcji w empirycznym rozkładzie wskaźników. Oznacza to, iż problem jednoznaczności agregacji dla profili reakcji niezgodnych z zasadą kumulatywności w modelach Rascha nie powstaje.
 hipotezy o skalowalności cechy ukrytej w danej zbiorowości za pomocą danego zestawu wskaźników. Podstawowym środkiem jest u statystyka testowa wywiedziona z ilorazu wiarygodności, która zazwyczaj używa ilorazów liczebności (częstości) empirycznych i przewidywanych przez model do badania stopnia zgodności danych z założeniami modelu. II. Problem liczby wymiarów cechy ukrytej i relacji między nimi Problem liczby wymiarów cechy ukrytej w prostych modelach skalowania nie daje się sformułować wprost jako problem statystyczny. Umożliwiają to dopiero modele złożone. III. Czy wszystkie wskaźniki są potrzebne. Decyzja o zbędności bądź niezbędności wskaźnika w zestawie jest w modelu Rascha uzasadniana nie tylko przy użyciu standardowych technik weryfikacji hipotez lecz także przez wyniki analizy informacyjnych własności pytań testowych. Funkcja ta pozwala kontrolować skutki przyłączania lub wyłączania wskaźników z zestawu dla precyzji estymacji poziomów cechy ukrytej. IV. Jakie są własności diagnostyczne poszczególnych wskaźników. Przebieg funkcji informacyjnej wskaźnika dostarcza wystarczających informacji aby odpowiedzieć na to pytanie. V. Jak skalować Funkcja agregacji profili reakcji w wartości cechy ukrytej jest wynikiem szacowania parametrów modelu. W rozwiniętych modelach Rascha może ona przyjmować tyle wartości ile jest różnych profili reakcji w empirycznym rozkładzie wskaźników. Oznacza to, iż problem jednoznaczności agregacji dla profili reakcji niezgodnych z zasadą kumulatywności w modelach Rascha nie powstaje..")
73
Praktyczne problemy skalowania w modelu 3PL Wyznaczenie parametrów modeli reakcji 1.trudność pytania - , 2.poziom umiejętności osoby - , 3.własności dyskryminacyjne pytania - a 4.współczynnik odgadywania - c Wyznaczenie parametrów modeli reakcji 1.trudność pytania - , 2.poziom umiejętności osoby - , 3.własności dyskryminacyjne pytania - a 4.współczynnik odgadywania - c Ile umiejętności testujemy: identyfikacja liczby wymiarów testu Czy potrzebujemy wszystkich pytań: identyfikacja pytań zbędnych. Jak trafny jest test: problem kalibracji testu - co oznacza 100%? Jak rzetelny jest test - z jaką dokładnością mierzymy umiejętności? Ile umiejętności testujemy: identyfikacja liczby wymiarów testu Czy potrzebujemy wszystkich pytań: identyfikacja pytań zbędnych. Jak trafny jest test: problem kalibracji testu - co oznacza 100%? Jak rzetelny jest test - z jaką dokładnością mierzymy umiejętności?

74
W poszukiwaniu dobrego testu (a) Wszystkie pytania mają wysoką moc dyskryminacyjną, współczynniki a i znacznie przekraczają 1; (b) Wszystkie pytania charakteryzują się niewielkimi szansami na odgadnięcie poprawnej odpowiedzi - współczynniki c i są bliskie zera; (c) Poziomy trudności pytań obejmują całą skalę umiejętności, której poziom test ma diagnozować - liczba pytań z ujemnymi wartościami współczynnika b i jest zbliżona do liczby pytań, dla których jest on dodatni; (d) Dokładność oszacowania poziomu umiejętności ucznia jest wysoka i stała w całym zakresie umiejętności zdających test - krzywa informacyjna testu jest płaska nad całym obszarem diagnozowanych umiejętności. (a) Wszystkie pytania mają wysoką moc dyskryminacyjną, współczynniki a i znacznie przekraczają 1; (b) Wszystkie pytania charakteryzują się niewielkimi szansami na odgadnięcie poprawnej odpowiedzi - współczynniki c i są bliskie zera; (c) Poziomy trudności pytań obejmują całą skalę umiejętności, której poziom test ma diagnozować - liczba pytań z ujemnymi wartościami współczynnika b i jest zbliżona do liczby pytań, dla których jest on dodatni; (d) Dokładność oszacowania poziomu umiejętności ucznia jest wysoka i stała w całym zakresie umiejętności zdających test - krzywa informacyjna testu jest płaska nad całym obszarem diagnozowanych umiejętności. Dobry test to taki, w którym:
 Wszystkie pytania mają wysoką moc dyskryminacyjną, współczynniki a i znacznie przekraczają 1; (b) Wszystkie pytania charakteryzują się niewielkimi szansami na odgadnięcie poprawnej odpowiedzi - współczynniki c i są bliskie zera; (c) Poziomy trudności pytań obejmują całą skalę umiejętności, której poziom test ma diagnozować - liczba pytań z ujemnymi wartościami współczynnika b i jest zbliżona do liczby pytań, dla których jest on dodatni; (d) Dokładność oszacowania poziomu umiejętności ucznia jest wysoka i stała w całym zakresie umiejętności zdających test - krzywa informacyjna testu jest płaska nad całym obszarem diagnozowanych umiejętności. Dobry test to taki, w którym:.")
75
Formalna analiza własności testów

76
Wartości zmiennej ukrytej a jawne wyniki testu – porównanie arkuszy maturalnych

77
Krzywe informacyjne arkuszy poziomu podstawowego

78
Własności informacyjjne testów poziomu podstawowego

79
Problem wyboru arkusza najlepszego z testowanych

80
Arkusz PP1 – statystyka opisowa

81
Suma punktów a oszacowany poziom umiejętności

83
Które z pytań arkusza jest do wymiany

84
Fundamentalne problemy skalowania (testowania) dla skalowania jednowymiarowego kumulatywnego w wersji probabilistycznej Trafność pomiaru, testu, skali validity Jedno-wymiarowość w podzbiorach (DIF) Wysoki współczynnika skalowalności Większość wskaźników niezbędna Rzetelność pomiaru, testu, skali, wskaźnika reliability Wskaźnika - przebieg funkcji informacyjnej wskaźnika Skali – przebieg funkcji informacyjnej skali (testu)
 dla skalowania jednowymiarowego kumulatywnego w wersji probabilistycznej Trafność pomiaru, testu, skali validity Jedno-wymiarowość w podzbiorach (DIF) Wysoki współczynnika skalowalności Większość wskaźników niezbędna Rzetelność pomiaru, testu, skali, wskaźnika reliability Wskaźnika - przebieg funkcji informacyjnej wskaźnika Skali – przebieg funkcji informacyjnej skali (testu)")
85
Problemy skalowania jednowymiarowego (kumulatywnego w wersji probabilistycznej) Problemy fundamentalne Na jakiej skali mierzymy cechę ukrytą Jak stwierdzić wielo- wymiarowość skali Jak zweryfikować założenie lokalnej niezależności reakcji Czy losowość reakcji osoby na wskaźnik wynika z losowania próby czy też jest dyspozycją osoby badanej
 Problemy fundamentalne Na jakiej skali mierzymy cechę ukrytą Jak stwierdzić wielo- wymiarowość skali Jak zweryfikować założenie lokalnej niezależności reakcji Czy losowość reakcji osoby na wskaźnik wynika z losowania próby czy też jest dyspozycją osoby badanej")
86
Problemy skalowania jednowymiarowego (kumulatywnego w wersji probabilistycznej) Rozszerzenia formalne modelu reakcji Politomiczne (porządkowe) wskaźniki Wiele zmiennych ukrytych (wiele skal) Modele wielo- poziomowe Model z czasem reakcji 4 PL Model z uczeniem się Computerized Adaptive Testing Mieszanina wskaźników binarnych i politomicznych
 Rozszerzenia formalne modelu reakcji Politomiczne (porządkowe) wskaźniki Wiele zmiennych ukrytych (wiele skal) Modele wielo- poziomowe Model z czasem reakcji 4 PL Model z uczeniem się Computerized Adaptive Testing Mieszanina wskaźników binarnych i politomicznych")
87
Problemy skalowania jednowymiarowego (kumulatywnego w wersji probabilistycznej) Problemy estymacyjne Złożone schematy losowania osób testowanych Braki danych Efektywność metod estymacj parametrów dla modeli wielo-parametrycznych, wielo-skalowych wielo-poziomowych Miary stopnia dopasowania do danych – współczynniki skalowalności i ich rozkłady
 Problemy estymacyjne Złożone schematy losowania osób testowanych Braki danych Efektywność metod estymacj parametrów dla modeli wielo-parametrycznych, wielo-skalowych wielo-poziomowych Miary stopnia dopasowania do danych – współczynniki skalowalności i ich rozkłady")
88
Problemy skalowania jednowymiarowego (kumulatywnego w wersji probabilistycznej) Przykłady zastosowań IRT Testowanie osiągnięć szkolnych ETS PISA PIAAC Diagnostyka psychiatryczna Skalowanie kapitałów społecznych Skalowanie potencjału partycypacyjnego TOEFL GRE TALIS TIMSS
 Przykłady zastosowań IRT Testowanie osiągnięć szkolnych ETS PISA PIAAC Diagnostyka psychiatryczna Skalowanie kapitałów społecznych Skalowanie potencjału partycypacyjnego TOEFL GRE TALIS TIMSS")
89
Problemy skalowania jednowymiarowego (kumulatywnego w wersji probabilistycznej) Problemy wynikające z potrzeb praktycznych Badania międzynarodowe, między-kulturowe DIF Kalibracja Badania zmian Linkowanie Kotwiczenie własności diagnostyczne wskaźników PISA - TOEFL
 Problemy wynikające z potrzeb praktycznych Badania międzynarodowe, między-kulturowe DIF Kalibracja Badania zmian Linkowanie Kotwiczenie własności diagnostyczne wskaźników PISA - TOEFL")
90
Problemy skalowania jednowymiarowego (kumulatywnego w wersji probabilistycznej)
")
91
Oprogramowanie Komercyjne ProQuest PISA Parscale SSI WinStep Public Domain R: ICL eRm mirt ltm Journal of Statistical software lordif

93
Pomiar a skalowanie Zmienne obserwowalne i ukryte Poziom pomiaru – typy zmiennych Skalowanie I. Skalowalność II. Wymiarowość III. Wskaźniki niezbędne IV. Własności wskaźników V. Algorytm skalowania VI.Wynik skalowania I. Skalowalność II. Wymiarowość III. Wskaźniki niezbędne IV. Własności wskaźników V. Algorytm skalowania VI.Wynik skalowania

Podobne prezentacje















 stanowi rozszerzenie testu t-Studenta w przypadku porównywanie większej liczby grup. Podział na grupy (czyli.>")




