Pobierz prezentację
1
Nowe abstrakcje programowania rozproszonego
Wykład: Map Reduce Laboratoria: Hadoop Aftowicz Jakub Ciesielczyk Tomasz

2
Big Data Problemy Big Data Animacja 2 – bigdata rośnie.
Pytanie do publiczność czy ktoś wie kto wymyślił/opublikował mapreduce Animacja 3 –

3
MapReduce MapReduce Aftowicz Jakub Ciesielczyk Tomasz

4
Motywacje Page Rank – mnożenie dużych macierzy przez wektor
Przeglądanie i przeszukiwanie sieci społecznościowych (facebook – ponad miliard użytkowników). Grafy z miliardem węzłów oraz miliardami (bilionami) krawędzi. Analiza zawartości pobranych stron Tworzenie indeksów odwrotnych
. Grafy z miliardem węzłów oraz miliardami (bilionami) krawędzi. Analiza zawartości pobranych stron. Tworzenie indeksów odwrotnych.")
5
Przykład word count Ala ma kota. Ala ma psa. Pies ma Alę. słowo ilość
2 Ma 3 Kota 1 Psa Pies Alę słowo ilość Ala Ma Kota Psa Pies Alę

6
Word count – jedna maszyna
HashMap<String,Integer> wordCount = new HashMap<>();
;")
7
Word count – jedna maszyna
HashMap<String,Integer> wordCount = new HashMap<>(); for (Document document : documentSet){ String[] T = tokenize ( document ) ; }
; for (Document document : documentSet){ String[] T = tokenize ( document ) ; }")
8
Word count – jedna maszyna
HashMap<String,Integer> wordCount = new HashMap<>(); for (Document document : documentSet){ String[] T = tokenize ( document ) ; for(String token: T){ if (!wordCount.containsKey(token)){ wordCount.put(token,1); } else{ wordCount.put(token, wordCount.get(token)+1);
; for (Document document : documentSet){ String[] T = tokenize ( document ) ; for(String token: T){ if (!wordCount.containsKey(token)){ wordCount.put(token,1); } else{ wordCount.put(token, wordCount.get(token)+1);")
9
Word count – wiele maszyn
HashMap<String,Integer> wordCount = new HashMap<>(); for (Document document : documentSubSet){ String[] T = tokenize ( document ) ; for(String token: T){ if (!wordCount.containsKey(token)){ wordCount.put(token,1); } else{ wordCount.put(token, wordCount.get(token)+1); sendSecondStep(wordCount);
; for (Document document : documentSubSet){ String[] T = tokenize ( document ) ; for(String token: T){ if (!wordCount.containsKey(token)){ wordCount.put(token,1); } else{ wordCount.put(token, wordCount.get(token)+1); sendSecondStep(wordCount);")
10
Word count – wiele maszyn
Second step: HashMap<String,Integer> globalWordCount; for ( HashMap<String,Integer> wordCount : receivedWordCount) { add(globalWordCount , wordCount); }
 { add(globalWordCount , wordCount); }")
11
Word count – wiele maszyn
Aby procedura mogła zadziałać na grupie maszyn, musimy spełnić następujące funkcjonalności: Składowanie plików (fragmentów danych) na dyskach maszyn (documentSubSet) Zapisywanie dane do tabeli hashowych opartych o dyski twarde tak by nie być ograniczonym pamięcią RAM Podzielenie danych pośrednich (wordCount) z kroku pierwszego. Rozdysponowanie fragmentów danych do odpowiednich maszyn Sprawdzanie poprawności
 na dyskach maszyn (documentSubSet) Zapisywanie dane do tabeli hashowych opartych o dyski twarde tak by nie być ograniczonym pamięcią RAM. Podzielenie danych pośrednich (wordCount) z kroku pierwszego. Rozdysponowanie fragmentów danych do odpowiednich maszyn. Sprawdzanie poprawności.")
12
Word count – wiele maszyn
Co się stanie w przypadku awarii jednej ze stacji roboczych? Co się stanie w przypadku awarii zarządcy? Co się stanie w przypadku natrafienia na wadliwe dane? Jak należy rozproszyć dane? W jaki sposób zebrać wyniki?

13
MapReduce - Założenia Automatyczna dystrybucja danych programista tylko definiuje w jaki sposób odczytywać dane (np. podziel wiersz w pliku po średniku) Automatyczne zrównoleglenie zadań programista tylko pisze co chce zrobić (reducer) Automatyczne zarządzanie zadaniami zrównoleglenie wątków jest transparentne dla programisty
 Automatyczne zrównoleglenie zadań programista tylko pisze co chce zrobić (reducer) Automatyczne zarządzanie zadaniami zrównoleglenie wątków jest transparentne dla programisty.")
14
MapReduce - Założenia Odporność - implementacja powinna być niewrażliwa na awarię maszyn Automatyczna komunikacja „Load balancing” Skalowalność – skalowalny liniowo poprzez dodawanie kolejnych maszyn Dostępność – użycie na grupie normalnych maszyn (PC), chmura obliczeniowa typu Amazon, Beyond Implementacja mapReduce, nie wiem czy implementacja to dobre stwierdzenie. Dane powinny być przeliczone niezaleznie czy maszyna na ktorej były liczone uległa awarii
, chmura obliczeniowa typu Amazon, Beyond. Implementacja mapReduce, nie wiem czy implementacja to dobre stwierdzenie. Dane powinny być przeliczone niezaleznie czy maszyna na ktorej były liczone uległa awarii.")
15
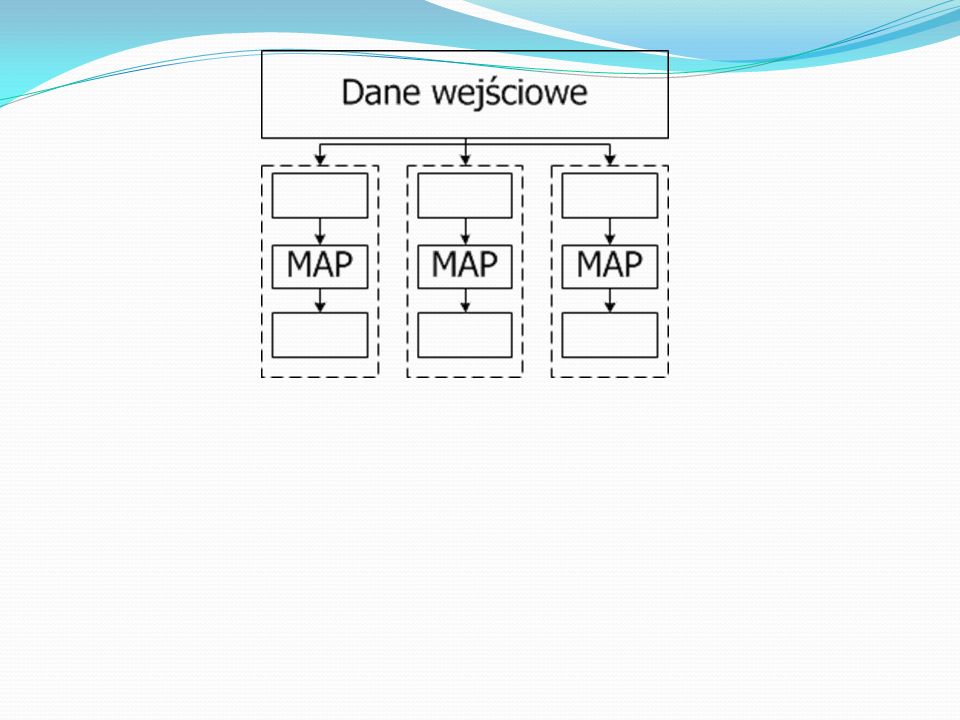
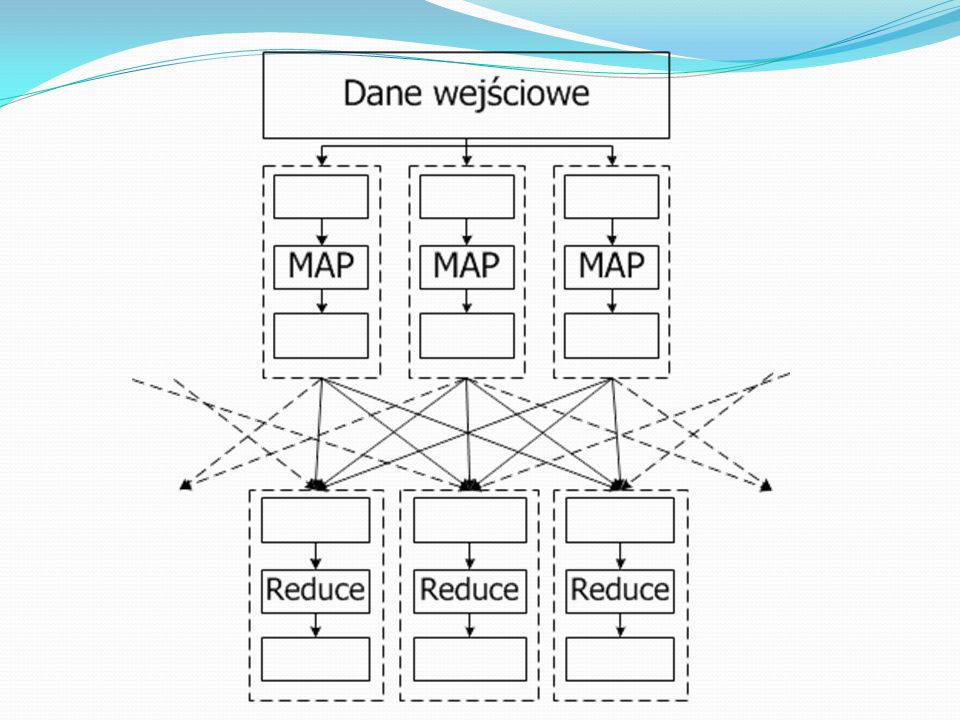
MapReduce - Idea Map Generowanie pary klucz-wartość
Reduce Łączy wartości związane z wcześniej wygenerowanymi kluczami „Dziel i zwyciężaj”

16
MapReduce - Idea Input Output Map Raw data-> (<key1,value1>)
List<key2,value2> Reduce <key2, (List<value2>) List<key3,val3>
 List<key3,val3>")
20
Word count – MapReduce public map ( String filename , String document ) { List<String> T = tokenize ( document ) ; for(String token: T){ emit (token , 1) ; }
 { List<String> T = tokenize ( document ) ; for(String token: T){ emit (token , 1) ; }")
21
Word count – MapReduce public reduce ( String token , List<Integer> values ) { Integer sum = 0; for(Integer value : values) sum = sum + value ; } emit (token , sum) ;
 { Integer sum = 0; for(Integer value : values) sum = sum + value ; } emit (token , sum) ;")
22
Mnożenie macierzy przez wektor
Zdefiniujmy macierz M o rozmiarze n x n o elementach mij oraz wektor V o długości n o elementach vj Wynikiem iloczynu M*V jest wektor X o długości n o elementach zdefiniowano: Macierz M jest przechowywana za pomocą trójki liczb (i, j, mij )
")
23
Mnożenie macierzy przez wektor
Załóżmy, że n jest duże, ale nie na tyle, żeby wektor nie zmieścił się w pamięci i jest dostępny w każdym Mapperze

24
Mnożenie macierzy przez wektor
Map: Przechowuje cały wektor v i fragment macierzy M. Z każdego elementu mij produkuje parę klucz-wartość <i, mij*vj> component Reduce Sumowanie wszystkich wartości dla danego klucza i (komórka wektora x). Wyjście : <i,xi> Klucz i w mapperze bo muszą trafic do jednej komorki wektora x
. Wyjście : <i,xi> Klucz i w mapperze bo muszą trafic do jednej komorki wektora x.")
25
Mnożenie macierzy przez wektor
Załóżmy, że n jest na tyle duże że wektor nie zmieścił się w pamięci Mappera i musi nastąpić jego podział Podzielmy zatem macierz na pionowe fragmenty o jednakowej szerokości, a następnie wektor na jednakową ilość poziomych fragmentów i-ty fragment macierzy będzie mnożony jedyni z elementami z i-tego fragmentu wektora

26
Mnożenie macierzy przez wektor

27
Mnożenie macierzy przez wektor
Map: Przechowuje fragment wektora v i macierzy M. Z każdego elementu mij produkuje parę klucz-wartość <i, mij*vj> component Reduce Sumowanie wszystkich wartości dla danego klucza i (komórka wektora x). Wyjście : <i,xi> Klucz i w mapperze bo muszą trafic do jednej komorki wektora x
. Wyjście : <i,xi> Klucz i w mapperze bo muszą trafic do jednej komorki wektora x.")
28
Korzyści… Umożliwia programistom bez doświadczenia z dziedziny systemów równoległych i rozproszonych, korzystanie z zasobów dużego systemu rozproszonego Ukrywa „niechlujne” szczegóły zrównoleglenia, obsługi błędów, rozproszenie danych i równoważenie obciążenia w bibliotece.

29
Awaria workera Master periodycznie pinguje każdego workera
Master oznacza wadliwego workera Wszystkie zadania Mapowania zlecone do tej pory danemu workerowi przywracane są do stanu Idle Wyniki przechowywane są lokalnie na maszynie która uległa awarii Ukończone zadania typu Reduce nie muszą być powtarzane Wyniki zadań Reduce przechowywane są w GFS

30
Awaria workera Kiedy zadanie Map zostaje przeniesione z workera A do B wszyscy workerzy wykonujący zadania typu Reduce zostają powiadomieni o zmianie Powtórne wykonanie podstawowym mechanizmem obsługi błędów MapReduce jest odporne na awarie wielu stacji roboczych naraz, przenosząc obliczenia na działające maszyny i kontynuąjąc przetwarzanie

31
Awaria Mastera Master może wykonywać Checkpointy
Po awarii nowa kopia Mastera może wystartować z ostatniego Checkpointu Jednak przy posiadaniu tylko jednego Mastera sznasa jego awarii jest niewielka… … dlatego implementacje przerywają przetwarzanie w przypadku awarii mastera

32
Ciekawostki i zalecenia
Problem „Maruderów” Wykonania „Pojedynczych” zadań się przeciągają Backup Tasks Do 44% wzrost czasu wykonania Problem „Złych Rekordów” Błędy w kodzie użytkownika powodujące awarie w wyniku przetwarzania pewnych danych Błędy w zewnętrznych bibliotekach Czasami dopuszczalne jest pominięcie niektórych rekordów

33
Ciekawostki i zalecenia
Partycjonowanie Domyślne (hash(key) mod R) Użytkownika Np. grupowanie po URL (hash(Hostname(urlkey)) mod R) Zasoby na jednym serwerze odpytywane przez jednego workera korzystamy z usprawnień protokołu HTTP i HTTPS Sortowanie (TeraSort)
 mod R) Użytkownika. Np. grupowanie po URL (hash(Hostname(urlkey)) mod R) Zasoby na jednym serwerze odpytywane przez jednego workera. korzystamy z usprawnień protokołu HTTP i HTTPS. Sortowanie (TeraSort)")
34
Ciekawostki i zalecenia
Combiner Kierowanie danych w paczkach do Reducerów Z reguły powiela kod Reducera Potrafi znacząco przyspieszyć rozwiązywani niektórych problemów MapReduce Np. word count wiele <the, 1> zagregowane do <the, k> Oszczędność przy wysyłaniu przez sieć

35
MapReduce: koszt i problemy
Wąskim gardłem dla MapReduce jest komunikacja danych po sieci Ilość zadań powinna być dużo większa od ilości workerów

36
MapReduce koszt i problemy
Dla maksymalnego zrównoleglenia mappery i reducery powinny być stateless, nie powinny zależeć od żadnych danych w obrębie zadania MapReduce. Nie jest możliwym sterowania porządkiem wykonywania zadań map i reduce. Faza reduce nie jest wykonywana przed zakończeniem fazy map Zakłada się, że wynik reducera jest mniejszy od wejścia mappera

37
MapReduce: koszt i problemy
Czy MapReduce/Hadoop rozwiąże moje problemy? tak, jeśli umiesz przekształcić algorytm do postać Map-Reduce „It is not a silver bullet to all the problems of scale, just a good technique to work on large sets of data when you can work on small pieces of that dataset in parallel „

38
SQL a MapReduce R,S – relacje (tabele) t, t’ : krotki
s – warunek selekcji A, B, C – podzbiór atrybutów a, b, c – wartości atrybutów dla danego podzbioru atrybutów

39
Selekcja Map Dla każdej krotki t w R sprawdź czy spełnia warunek selekcji s. Jeśli spełnia to produkuj parę klucz wartość: (t, t) Reduce Po prostu przekazuje dane na wyjście

40
Projekcja Map Dla każdej krotki t w R wyprodukuj krotkę t’ poprzez wyeliminowanie atrybutów spoza zbioru A. Wyjście (t,t’) Reduce Dla każdego klucza może być wiele krotek t’. Wejście (t’,[t’,…t’]). Wyjście: dla każdej krotki t’ wyprodukuj (t’,t’)
. Wyjście: dla każdej krotki t’ wyprodukuj (t’,t’)")
41
Suma (Union) Map wyjście: (t’,t’) dla każdej z relacji S i R Reduce
Dla każdego klucza t wyprodukuj (t,t)
")
42
Różnica Map Dla krotki t z relacji R wyprodukuj (t, name(R)). Dla krotki t z relacji S: (t, name(S)) Reduce Dla każdego klucza t : -jeśli lista wartości zawiera tylko name(R) to wyporodukuj (t, t) -jeśli lista wartości zawiera: [name(R), name(S)] lub [name(s)] lub [name(S), name(R)] nie produkuj nic
 to wyporodukuj (t, t) -jeśli lista wartości zawiera: [name(R), name(S)] lub [name(s)] lub [name(S), name(R)] nie produkuj nic.")
43
Przecięcie Map: dla każdej R lub S wyprodukuj (t, t) Reduce
Jeżeli klucz t ma parę wartości to wyprodukuj (t, t). W Przeciwnym wypadku nie produkuj nic
. W Przeciwnym wypadku nie produkuj nic.")
44
Natural Join Map dla każdej krotki (a, b) z R wyprodukuj (b,[name(R),a]). Dla każdej krotki (b, c) z S wyprodukuj (b,[name(S),c]) Reduce klucz b zawiązany jest z wartościami: [name(R),a] i [name(S),c]. Wygeneruj wszystkie możliwe pary: (b,a1,c1), (b,a2,c1), … , (b,an,cn).
![Natural Join Map. dla każdej krotki (a, b) z R wyprodukuj (b,[name(R),a]). Dla każdej krotki (b, c) z S wyprodukuj (b,[name(S),c])](http://slideplayer.pl/slide/806488/1/images/44/Natural+Join+Map.+dla+ka%C5%BCdej+krotki+%28a%2C+b%29+z+R+wyprodukuj+%28b%2C%5Bname%28R%29%2Ca%5D%29.+Dla+ka%C5%BCdej+krotki+%28b%2C+c%29+z+S+wyprodukuj+%28b%2C%5Bname%28S%29%2Cc%5D%29.jpg "Reduce. klucz b zawiązany jest z wartościami: [name(R),a] i [name(S),c]. Wygeneruj wszystkie możliwe pary: (b,a1,c1), (b,a2,c1), … , (b,an,cn).")
45
Grupowanie i Agregacja
Map Dana relacja R (A,B,C). Aby pogrupować ją po atrybucie A i zagregować po atrybucie B wyprodukuj parę (a,b) Reduce wejście: (a,[b1,b2 …]). Dla listy wartości przeprowadź funkcje agregacji, np. suma. Wyprodukuj parę (a, x) gdzie x to suma wszystkich wartości dla klucza a
. Aby pogrupować ją po atrybucie A i zagregować po atrybucie B wyprodukuj parę (a,b) Reduce wejście: (a,[b1,b2 …]). Dla listy wartości przeprowadź funkcje agregacji, np. suma. Wyprodukuj parę (a, x) gdzie x to suma wszystkich wartości dla klucza a.")
46
Hadoop Aftowicz Jakub Ciesielczyk Tomasz

47
Hadoop Implementacja OpenSource MapReduce
Pracuje w architekturze master/slave dla rozproszonych danych oraz rozproszonych obliczeń Uruchomienie Hadoopa wiąże się z uruchomieniem szeregiem różnych usług na serwerach dostępnych w sieci: NameNode, DataNode, Secondary NameNode, JobTracker, TaskTracker

48
Hadoop

49
Hadoop - NameNode Zarządza Hadoop File System (HDFS), kieruje niskopoziomowymi operacjami we/wyj na DataNode Śledzi podział danych (plików) na bloki, wie gdzie te bloki się znajdują NameNode zazwyczaj nie przechowuje żadnych danych oraz nie robi żadnych obliczeń dla procesu MapReduce W przypadku awarii NameNode HDFS nie działa. Można opcjonalnie użyć SecondaryNameNode
 na bloki, wie gdzie te bloki się znajdują. NameNode zazwyczaj nie przechowuje żadnych danych oraz nie robi żadnych obliczeń dla procesu MapReduce. W przypadku awarii NameNode HDFS nie działa. Można opcjonalnie użyć SecondaryNameNode.")
50
Hadoop – Secondary NameNode
Odpowiada za monitorowanie stanu HDFS Każda grupa komputerów/klaster? (cluster) ma jeden Secondary NameNode, który znajduje się na osobnej maszynie Różni się od NameNode tym że nie dostaje ani nie rejestruje żadnych danych w czasie rzeczywistym od HDFS. W zamian za to komunikuje się z NameNode, żeby zapisać stan HDFS (snapshot). Częstotliwość zapisu jest determinowana przez ustawienia klastra.
 ma jeden Secondary NameNode, który znajduje się na osobnej maszynie. Różni się od NameNode tym że nie dostaje ani nie rejestruje żadnych danych w czasie rzeczywistym od HDFS. W zamian za to komunikuje się z NameNode, żeby zapisać stan HDFS (snapshot). Częstotliwość zapisu jest determinowana przez ustawienia klastra.")
51
Hadoop – Job Tracker Łączy aplikację użytkownika z Hadoopem
Jak tylko kod jest dostarczony do klastra, JobTracker planuje wykonanie poprzez wybór plików do przetwarzania, przydziela różne zadania do węzłów. Monitoruje wykonywujące się zadania. W przypadku awarii JobTracker przydziela zadanie do innego węzła. Jest tylko jeden JobTracker na klaster Hadoopa Kiedy zadanie zostanie skończone przez maszynę, JobTracker aktualizuje status Jeśli padnie, wszystkie zadania zostają zatrzymane
![]()
52
Hadoop - DataNode Każda maszyna slave robi podstawowe zadania związane z HDFS: czytanie i pisanie bloków HDFS na lokalny system Nie ma replikacji danych w obrębie jednego DataNode DataNode może komunikować się z innymi DataNodami w celu replikowania bloków danych DataNodes ciągle informują NameNode o blokach danych, które aktualnie posiadają Aplikacja użytkownika może bezpośrednio odwoływać się do DataNode

53
Hadoop – Task Tracker TaskTrackers zarządza wykonywanie pojedynczego zadania na maszynie slave Pomimo, że jest tylko jeden TaskTracker na jeden węzeł to może stworzyć wiele JVM dla obsługi wielu mapperów czy reducerów równolegle TaskTracker cały czas komunikuje się JobTrackerem Jeśli JobTracker nie odbierze sygnału ‘hearbeat’ od TaskTrackera przez określony przedział czasowy to zakładana jest awaria maszyny slave i zadanie zostaje przekazane do innej maszyny
![]()
54
Plan laboratorium WordCount
Proste działania (średnie, sumy) na zbiorach danych Zapytania SQL Selection Group by Order by Natural join
 na zbiorach danych. Zapytania SQL. Selection. Group by. Order by. Natural join.")
55
WC w hadoopie public class WordCount extends Configured implements Tool{ public static class MapClass extends MapReduceBase implements Mapper<LongWriteable, Text, Text, IntWriteable> { private final static IntWriteable one = new IntWriteable(1); private Text word = new Text(); public void map(LongWriteable key, Text value, OutputCollextor<Text, IntWriteable> output, Reporter reporter) throws IOException{ String line=value.toString(); StringTokennizer itr = new StringTokenizer(line); while(itr.hasMoreTokens()){ word.set(itr.nextToken()); output.collect(word,one); }
; private Text word = new Text(); public void map(LongWriteable key, Text value, OutputCollextor<Text, IntWriteable> output, Reporter reporter) throws IOException{ String line=value.toString(); StringTokennizer itr = new StringTokenizer(line); while(itr.hasMoreTokens()){ word.set(itr.nextToken()); output.collect(word,one); }")
56
WC w hadoopie public static class Reduce extends MapReduceBase implements Text, IntWriteable, Text, IntWriteable> { public void reduce (Text key, Iterator<IntWritable> values, OutputCollextor<Text, IntWriteable> output, Reporter reporter) throws IOException{ int sum =0; while(values.hasNext()){ sum+=values.next().get(); } output.collect(key,new IntWritable(sum));
 throws IOException{ int sum =0; while(values.hasNext()){ sum+=values.next().get(); } output.collect(key,new IntWritable(sum));")
57
Pytania? ?

58
Dziękujemy za uwagę i zapraszamy na zajęcia laboratoryjne

59
Materiały




 - stanowi kod użytkownika przechowywany wewnątrz bazy i uruchamiany w określonych sytuacjach np.>")
















