Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
XML a bazy danych Eksploracja danych
Jacek Rumiński Kontakt: Katedra Inżynierii Biomedycznej, pk. 106, tel.: , fax: ,

2
Omówienie planu wykładów i ćwiczeń laboratoryjnych
Omówienie ogólnych zagadnień organizacyjnych

3
Język XML jako sposób zapisywania informacji źródłowych
Jacek Rumiński Kontakt: Katedra Inżynierii Biomedycznej, pk. 106, tel.: , fax: ,

4
Literatura pomocnicza:
XML, XSL, XPath – rekomendacje, specyfikacje i podręczniki na stronach oraz podręczniki drukowane o XML, np.: XML. Księga eksperta, Rusty Harold, Wydawnictwo Helion -XML a bazy danych:

5
Plan wykładu: Wprowadzenie – XML a bazy danych; Cele XML; Podstawowe definicje i pojęcia; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

6
XML - eXtensible Markup Language – Rozszerzalny Język Znaczników
Znaczników – dokument budowany jest w oparciu o elementy identyfikowane przez znaczniki (ang. tag) Język – dokument budowany jest zgodnie z określonymi zasadami składni, oraz w oparciu o zdefiniowany alfabet, czyli znaczniki Rozszerzalny – wykorzystywane w dokumencie elementy języka, znaczniki, projektowane są przez użytkownika (projektanta schematu dokumentu)
 Język – dokument budowany jest zgodnie z określonymi zasadami składni, oraz w oparciu o zdefiniowany alfabet, czyli znaczniki. Rozszerzalny – wykorzystywane w dokumencie elementy języka, znaczniki, projektowane są przez użytkownika (projektanta schematu dokumentu)")
7
Przykładowy dokument XML – widok uproszczony
element atrybut znacznik

8
Przykładowy dokument XML – widok pełny
wartość atrybutu wartość elementu

9
XML a bazy danych: XML jest uniwersalnym formatem składowania danych.
Dokument XML zawiera logicznie uporządkowane dane. Dokument XML może zawierać opisy wielokrotnych instancji tej samej klasy. Dokument XML jest bazą danych. XML nie jest systemem zarządzania bazami danych. Dokumenty XML lub dane dokumentów XML podlegają składowaniu w bazach danych.

10
Dane w pojedynczej strukturze hierarchicznej
Charakterystyka porównawcza XML z systemami zarządzania relacyjnymi bazami danych (SZRBD) XML SZRBD Dane w pojedynczej strukturze hierarchicznej Dane w wielu relacjach (tabelach) Węzły struktury (elementy) mogą posiadać wartość własną oraz liczne wartości atrybutów Komórki tabel przechowują pojedyncze wartości Elementy mogą być zagnieżdżone Wartości komórek są atomowe Kolejność elementów jest określona Kolejność krotek (wierszy) nie jest definiowana Schemat dokumentu jest opcjonalny Schemat bazy jest konieczny Bezpośrednie składowanie zbioru danych dokumentu w XML Dane dokumentu rozłożone na zbiór atrybutów/relacji Wyszukiwanie danych poprzez dedykowane języki, np.: XQuery Wyszukiwanie danych poprzez język SQL
 XML. SZRBD. Dane w pojedynczej strukturze hierarchicznej. Dane w wielu relacjach (tabelach) Węzły struktury (elementy) mogą posiadać wartość własną oraz liczne wartości atrybutów. Komórki tabel przechowują pojedyncze wartości. Elementy mogą być zagnieżdżone. Wartości komórek są atomowe. Kolejność elementów jest określona. Kolejność krotek (wierszy) nie jest definiowana. Schemat dokumentu jest opcjonalny. Schemat bazy jest konieczny. Bezpośrednie składowanie zbioru danych dokumentu w XML. Dane dokumentu rozłożone na zbiór atrybutów/relacji. Wyszukiwanie danych poprzez dedykowane języki, np.: XQuery. Wyszukiwanie danych poprzez język SQL.")
11
XML a bazy danych – podstawowe zadania:
Składowanie danych w dokumentach XML Składowanie dokumentów XML Wyszukiwanie dokumentów XML Wyszukiwanie danych z dokumentów XML

12
XML a bazy danych – scenariusze powiązań
Prezentacja dokumentu XML Transformacja i prezentacja w sieci WWW RDB1 Synteza dokumentu XML RDB2 Składowanie dokumentu XML NXD1 WWW RDB1 Rozbiór (analiza) dokumentu XML RDB2 NXD1 NXD – Native XML Database
 dokumentu. XML. RDB2. NXD1. NXD – Native XML Database.")
13
Plan wykładu: Wprowadzenie – XML a bazy danych; Cele XML; Podstawowe definicje i pojęcia; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

14
Podstawowe cele XML: XML powinien umożliwiać tworzenie dokumentów o strukturze wyznaczanej przez definiowane znaczniki, Dokument XML powinien być prosty i szybki do utworzenia, czytelny dla twórcy i łatwo interpretowany przez programy komputerowe, XML powinien być kompatybilny z SGML, Dokumenty XML powinny być łatwo wymieniane przez Internet i przetwarzane oraz prezentowane w ramach sieci WWW, XML powinien wspomagać różne typy aplikacji, Liczba cech opcjonalnych XML powinna być minimalna, Projektowanie dokumentu XML powinno umożliwiać weryfikację jego poprawności.

15
Popularność XML – dlaczego?
HTML jest językiem bardzo popularnym, i co ważniejsze znanym i stosowanym przez wiele osób (niekoniecznie informatyków). Dlaczego zatem XML? Problem z HTML: Ściśle określone znaczniki HTML służą do opisu prezentacji, nie do opisu danych. Przykładowo: Co oznacza fragment kodu: <td> </td> liczbę studentów na sali? wysokość czesnego? odległość pomiędzy Gdańskiem a Warszawą? hasło do ciekawego serwisu w Internecie?
. Dlaczego zatem XML Problem z HTML: Ściśle określone znaczniki HTML służą do opisu prezentacji, nie do opisu danych. Przykładowo: Co oznacza fragment kodu: <td> </td> liczbę studentów na sali wysokość czesnego odległość pomiędzy Gdańskiem a Warszawą hasło do ciekawego serwisu w Internecie")
16
Przykład kolejny: Dany jest fragment kodu HTML: <p><b>Jacek Rumiński</b> <br> Katedra Inżynierii Biomedycznej Przetworzenie kodu przez przeglądarkę wygeneruje wynik: Jacek Rumiński Czy maszyna (algorytm) jest w stanie zinterpretować ten kod? Czym jest ?
 jest w stanie zinterpretować ten kod Czym jest")
17
Jak w powyższym kodzie można znaleźć nazwę Katedry?
Algorytm 1. Jeśli <p> ma dwa <br> to po drugim <br> dany jest numer telefonu. Jak widać algorytm nie jest zbyt uniwersalny, co jest konsekwencją braku informacji wspomagającej interpretację w samym dokumencie HTML. Przechowanie powyższej informacji (HTML) w kodzie XML może wyglądać następująco: <pracownik> <imię>Jacek</imię> <nazwisko> Rumiński </nazwisko> <katedra> <nazwa>Katedra Inżynierii Biomedycznej</nazwa> </katedra> <kontakt> <telefon> </telefon> </pracownik>
 w kodzie XML może wyglądać następująco: <pracownik> <imię>Jacek</imię> <nazwisko> Rumiński </nazwisko> <katedra> <nazwa>Katedra Inżynierii Biomedycznej</nazwa> </katedra> <kontakt> <telefon> </telefon> </pracownik>")
18
Dany wyżej kod XML jest czytelny dla twórcy i potencjalnego użytkownika. Łatwo też stworzyć algorytm interpretujący treść, np.: Algorytm 2. Jeśli nazwa elementu jest „telefon” to jego treść jest numerem telefonu. Dane zapisane w dokumencie XML mogą być zaprezentowane dokładnie w taki sam sposób jak dla wcześniejszego przykładu z HTML, oraz na miliony innych sposobów. Charakterystyczną cechą dokumentów XML jest więc separacja opisu danych od opisu ich prezentacji, definiowanej poza XML. Można zatem wygenerować HTML z opisem prezentacji danych z dokumentu XML. XML jest bardziej uporządkowany niż HTML, nie umożliwia przykładowo: przeplatania znaczników, omijania znaczników końca, itd. Uporządkowaną na wzór XMLa wersją HTMLa jest XHTML.

19
Zgodnie z prezentowanymi celami utworzenia XML, powstał standard sieci WWW, którego aplikacje są obecnie jedną z najbardziej rozwijających się dziedzin praktycznego zastosowania informatyki w składowaniu i wymianie danych. XML włączono do kanonu uniwersalnych technologii: TCP/IP – uniwersalna sieć; HTML – uniwersalna prezentacja danych; XML – uniwersalne składowanie danych; Java – uniwersalny kod. Do najbardziej istotnych potomków XMLa, należy zaliczyć: XSL, MathML, SVG, XQuery, XPath, SMIL, XHTML, SOAP, .....

20
Plan wykładu: Wprowadzenie – XML a bazy danych; Cele XML; Podstawowe definicje i pojęcia; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

21
Podstawą wszelkich definicji jest rekomendacja XML 1
Podstawą wszelkich definicji jest rekomendacja XML 1.0 opracowana przez W3C ( DOKUMENT XML – Obiekt danych jest dokumentem XML wtedy, jeśli jest dobrze sformułowany („well-formed”), zgodnie z wymaganiami rekomendacji. DOKUMENT XML posiada strukturę fizyczną i logiczną. Fizycznie dokument XML składa się z encji, logicznie z deklaracji, elementów, komentarzy, instrukcji przetwarzania. Obiekt danych jest dobrze sformułowany (jest dokumentem XML) jeśli wszystkie jego encje zarówno bezpośrednio dane jak i te, do których odnosi się przez referencje, spełniają wymagania specyfikacji, oraz obiekt ten posiada wymaganą strukturę logiczną.
, zgodnie z wymaganiami rekomendacji. DOKUMENT XML posiada strukturę fizyczną i logiczną. Fizycznie dokument XML składa się z encji, logicznie z deklaracji, elementów, komentarzy, instrukcji przetwarzania. Obiekt danych jest dobrze sformułowany (jest dokumentem XML) jeśli wszystkie jego encje zarówno bezpośrednio dane jak i te, do których odnosi się przez referencje, spełniają wymagania specyfikacji, oraz obiekt ten posiada wymaganą strukturę logiczną.")
22
document ::= prolog element Misc*
Struktura logiczna dokumentu XML zdefiniowana jest jako: document ::= prolog element Misc* Dokument XML składa się z trzech podstawowych jednostek: prologu – deklaracja dokumentu, określająca typ i wersję, elementu głównego (root)– który zawierać może kolejne elementy, oraz z zera lub więcej jednostek typu „Misc” definiowanych jako: Misc ::= Comment | PI | S gdzie: Comment – komentarz, PI – instrukcja przetwarzania, S – znaki puste (#x20 | #x9 | #xD | #xA) („white spaces”). Przykładowy prolog: <?xml version="1.0" ?>
– który zawierać może kolejne elementy, oraz z zera lub więcej jednostek typu „Misc definiowanych jako: Misc ::= Comment | PI | S. gdzie: Comment – komentarz, PI – instrukcja przetwarzania, S – znaki puste (#x20 | #x9 | #xD | #xA) („white spaces ). Przykładowy prolog: < xml version= 1.0 >")
23
Podstawowe znaki wykorzystywane w definicjach specyfikacji XML i jej pochodnych do określania krotności (następstwa) jednostek: ? jednostka występuje raz lub wcale, * jednostka występuje jedno lub wielokrotnie lub wcale + jednostka występuje co najmniej raz [wartość] jednostka występuje dokładnie raz, tak jak zapisano , lista jednostek – sekwencja rozdzielana znakiem „ ’ ” | zbiór jednostek do wyboru („lub”).
.")
24
Instrukcja przetwarzania (PI) – zanurzona w dokumencie XML instrukcja dla aplikacji przetwarzającej dokument. Przykładem instrukcji przetwarzania jest prolog. PI ::= '<?' PITarget (S (Char* - (Char* '?>' Char*)))? '?>' PITarget ::= Name - (('X' | 'x') ('M' | 'm') ('L' | 'l')) Char ::= #x9 | #xA | #xD | [#x20-#xD7FF] | [#xE000-#xFFFD] | [#x10000-#x10FFFF] czyli Unicode Name ::= (Letter | '_' | ':') (NameChar)* NameChar ::= Letter | Digit | '.' | '-' | '_' | ':' | CombiningChar | Extender gdzie: Letter, Digit, CombiningChar, Extender jak i BaseChar oraz Ideographic to znaki zdefiniowane w rekomendacji XML poprzez zestaw kodów Unicodu.
)) > PITarget ::= Name - (( X | x ) ( M | m ) ( L | l )) Char ::= #x9 | #xA | #xD | [#x20-#xD7FF] | [#xE000-#xFFFD] | [#x10000-#x10FFFF] czyli Unicode. Name ::= (Letter | _ | : ) (NameChar)* NameChar ::= Letter | Digit | . | - | _ | : | CombiningChar | Extender. gdzie: Letter, Digit, CombiningChar, Extender jak i BaseChar oraz Ideographic to znaki zdefiniowane w rekomendacji XML poprzez zestaw kodów Unicodu.")
25
Komentarz – opis treści dokumentu XML lub inne uwagi zanurzone w dokumencie
Comment ::= '<!--' ((Char - '-') | ('-' (Char - '-')))* '-->' Uwaga! Zgodnie z powyższym zakończenie komentarza ‘--->’ jest niedozwolone. Przykładowy prolog: <!--Zadania testowe z XML--> CDATA – „character data” – dane tekstowe, definiowane w dokumencie XML poza znacznikami. Nie posiadają zatem strukturalnej i uporządkowanej własności języka XML. CDSect ::= CDStart CData CDEnd CDStart ::= '<![CDATA[' CData ::= (Char* - (Char* ']]>' Char*)) CDEnd ::= ']]>'
 | ( - (Char - - )))* --> Uwaga! Zgodnie z powyższym zakończenie komentarza ‘--->’ jest niedozwolone. Przykładowy prolog: <!--Zadania testowe z XML--> CDATA – „character data – dane tekstowe, definiowane w dokumencie XML poza znacznikami. Nie posiadają zatem strukturalnej i uporządkowanej własności języka XML. CDSect ::= CDStart CData CDEnd. CDStart ::= <![CDATA[ CData ::= (Char* - (Char* ]]> Char*)) CDEnd ::= ]]>")
26
Procesor XML – program komputerowy realizujący odczyt i operacje na treści dokumentu XML. Wymagania dotyczące programu i rodzaj procesorów XML określa specyfikacja XML. DTD – Document Type Definition (definicja typu/schematu dokumentu) – zanurzona w dokumencie XML lub zapisana poza nim struktura dokumentu, a więc dozwolone elementy, ich nazwy, krotność i hierarchia jak również możliwe atrybuty wraz z ich nazwami, typem, krotnością i występowaniem. DTD nie jest dokumentem XML! DTD jest w pełni zdefiniowany w rekomendacji XML. Włączenie DTD w dokumencie XML odbywa się w deklaracji DOCTYPE: <!DOCTYPE tu występuje DTD lub referencja do zewn. DTD> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2//EN">
 – zanurzona w dokumencie XML lub zapisana poza nim struktura dokumentu, a więc dozwolone elementy, ich nazwy, krotność i hierarchia jak również możliwe atrybuty wraz z ich nazwami, typem, krotnością i występowaniem. DTD nie jest dokumentem XML! DTD jest w pełni zdefiniowany w rekomendacji XML. Włączenie DTD w dokumencie XML odbywa się w deklaracji DOCTYPE: <!DOCTYPE tu występuje DTD lub referencja do zewn. DTD> <!DOCTYPE HTML PUBLIC -//W3C//DTD HTML 3.2//EN >")
27
Encje („entities”) – zgodnie z budową fizyczną dokumentu XML są to jednostki przechowywania danych. Każda encja ma nazwę i wartość. Encje definiowane są jawnie w DTD. Encje mogą być wewnętrzne i zewnętrzne. Wewnętrzna encja ma treść taką jaka jest w niej bezpośrednio zapisana. Zewnętrzna encja odwołuje się do zewnętrznego zasobu. Przykłady: -wewnętrzna encja: <!ENTITY info ”To są slajdy do wykładu o XML."> -zewnętrzna encja: <!ENTITY plik2 SYSTEM ” W definicji encji zewnętrznych stosuje się dwa typy identyfikatorów: systemowy oraz publiczny. Systemowy występuje zawsze i określa adres URI zasobu. Jeśli tylko ten identyfikator jest używany występuje słowo kluczowe ‘SYSTEM’. Przykład tego typu encji pokazano wyżej.

28
Jeśli stosuje się identyfikator publiczny wówczas stosuje się słowo kluczowe PUBLIC, po czym występuje identyfikator publiczny (generowane jest URI główne) i systemowy (URI domyślne). Ogólna postać definicji encji ma więc postać: <!ENTITY nazwa PUBLIC "FPI" "URI"> FPI - Formal Public Identifier – posiada budowę zawierającą znak : „-” zasób niestandardowy; „+” zasób standardowy (DTD), nazwę grupy lub osoby odpowiedzialnej za zasób, tekst określający typ i wersję zasobu, dwa znaki określające język dokumentu, znaki separacji „//” rozdzielające powyższe pola. <!ENTITY plik3 PUBLIC ”-//Jack Stone//TEXT CV version 2.1//EN” ”
, nazwę grupy lub osoby odpowiedzialnej za zasób, tekst określający typ i wersję zasobu, dwa znaki określające język dokumentu, znaki separacji „// rozdzielające powyższe pola. <!ENTITY plik3 PUBLIC -//Jack Stone//TEXT CV version 2.1//EN >")
29
Encje mogą być oznaczone jako nie podlegające rozbiorowi, tzn
Encje mogą być oznaczone jako nie podlegające rozbiorowi, tzn. zawierają dane nie podlegające interpretacji przez procesor XML (np. plik binarny). Stosuje się wówczas słowo kluczowe „NDATA”. <!ENTITY logo SYSTEM " NDATA gif> Encje dzielą się ponadto na encje ogólne oraz encje parametryczne. Te ostatnie mogą być tylko definiowane w dokumencie DTD. Różnica polega również na samej budowie encji. Encja parametryczna zawiera dodatkowo przed nazwą znak „%”. <!ENTITY % plik2 SYSTEM ” Do encji odwoływać się można przez referencje: &nazwa_encji; dla encji ogólnej (konieczne znaki „&” i „;”), %nazwa_encji; -dla encji parametrycznej (konieczne znaki „%” i „;”). <!ENTITY (...) <!ENTITY jwr "Jacek Rumiński & ;">
. Stosuje się wówczas słowo kluczowe „NDATA . <!ENTITY logo SYSTEM NDATA gif> Encje dzielą się ponadto na encje ogólne oraz encje parametryczne. Te ostatnie mogą być tylko definiowane w dokumencie DTD. Różnica polega również na samej budowie encji. Encja parametryczna zawiera dodatkowo przed nazwą znak „% . <!ENTITY % plik2 SYSTEM > Do encji odwoływać się można przez referencje: &nazwa_encji; - dla encji ogólnej (konieczne znaki „& i „; ), %nazwa_encji; -dla encji parametrycznej (konieczne znaki „% i „; ). <!ENTITY (...) <!ENTITY jwr Jacek Rumiński & ; >")
30
Wartość encji może przyjmować tylko określone znaki Unicodu, zgodnie z zakresem podanym na końcu rekomendacji. Zatem jawne wpisanie polskich znaków w danym edytorze, może spowodować, iż zapamiętywany jest kod znaku zgodnie ze stroną kodową edytora, a nie wymaganego Unicodu. Wówczas przy interpretacji znaku przez przeglądarkę wystąpi błąd. Z tych względów znacznie pewniej jest stosowanie w definicji wartości encji, referencji do znaków polskich, zamiast samych znaków. Przykładowo: Zamiast: <!ENTITY jwr "Jacek Rumiński & ;"> Lepiej: <!ENTITY jwr "Jacek Rumiński & ;"> gdzie: ń to referencja (&...;) do znaku (#) w kodzie szesnastkowym (x) o wartości 144.
 do znaku (#) w kodzie szesnastkowym (x) o wartości 144.")
31
Kody heksadecymalne polskich liter (Unicode)
")
32
Zgodnie z rekomendacją istnieją również predefiniowane encje:
Znak „ < ”: <!ENTITY lt "<"> Znak „ > ”: <!ENTITY gt ">"> Znak „ & ”: <!ENTITY amp "&"> Znak „ ’ ”: <!ENTITY apos "'"> Znak „ ” ”: <!ENTITY quot """> Przestrzenie nazw (namespaces) – zbiory nazw definiujące słownik możliwych znaczników, definicja: xmlns:<prefix>='<identyfikator przestrzeni nazw>' <prefix>, znacznik poprzedzający, określający zakres możliwych nazw zgodnie z wybranym przez „identyfikator przestrzeni nazw” słownikiem.
 – zbiory nazw definiujące słownik możliwych znaczników, definicja: xmlns:<prefix>= <identyfikator przestrzeni nazw> <prefix>, znacznik poprzedzający, określający zakres możliwych nazw zgodnie z wybranym przez „identyfikator przestrzeni nazw słownikiem.")
33
Przestrzenie nazw definiuje się dla elementu lub atrybutu.
Przykładowo: Dla elementu: <salon xmlns:s=" <s:model> C5 </s:model> </salon> Przestrzenią nazw dla elementu <model> jest „ Dla atrybutu: <samochod s:VIN=” ”> C5 </samochod> Przestrzenią nazw dla atrybutu „VIN” jest „

34
Prefix/Aplikacja Przestrzeń nazw XHTML http://www.w3.org/1999/xhtml
Przykładowe, standardowe przestrzenie nazw: Prefix/Aplikacja Przestrzeń nazw XHTML MathML SVG HTML XSL

35
Przegląd rekomendacji XML – demonstracja.
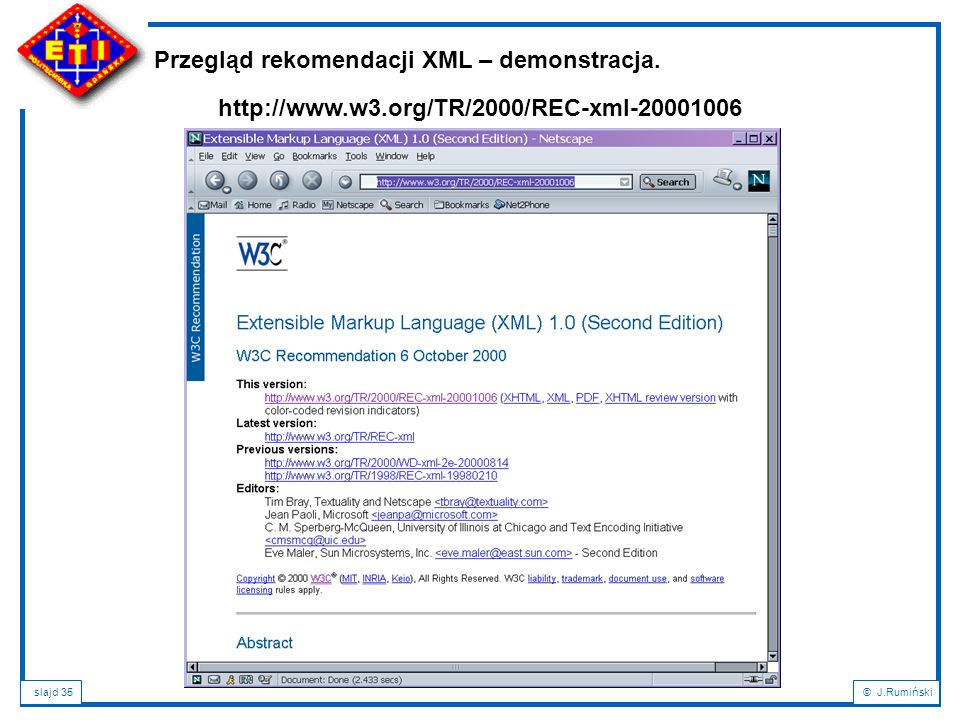
36
Plan wykładu: Wprowadzenie – XML a bazy danych; Cele XML; Podstawowe definicje i pojęcia; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

37
Dokument XML – ponownie.
opcjonalnie obowiązkowo typ wersja strona kodowa rozłączność prolog

38
Dokument XML – ponownie.
opcjonalnie obowiązkowo prolog Definicja typu dokumentu poprzez identyfikator systemowy, będący referencją do pliku „salon.dtd”. Definicja ta jest wymagana, ze względu na określenie w pierwszej instrukcji przetwarzania, iż bieżący plik XML nie jest rozłączny (samodzielny-> standalone=”no”).
.")
39
Dokument XML – ponownie.
opcjonalnie obowiązkowo „root” dokumentu Definicja głównego elementu dokumentu XML. Element posiada atrybut o nazwie „wlasciciel” i wartości stanowiącej referencje do encji o nazwie „kontakt”.

40
Dokument XML – ponownie.
opcjonalnie obowiązkowo komentarz Definicja subelementu o nazwie „samochod”. Element posiada 2 atrybuty („VIN” i „nrsilnika”) oraz cztery subelementy („marka”, „model”, „kolor”, „silnik”). Wartość elementu jest typu zbioru znaków, więc łatwo pomylić się wprowadzając tekst („;”).
 oraz cztery subelementy („marka , „model , „kolor , „silnik ). Wartość elementu jest typu zbioru znaków, więc łatwo pomylić się wprowadzając tekst („; ).")
41
Dokument XML – ponownie. Prezentacja w przeglądarce MS IE.

42
Plan wykładu: Wprowadzenie – XML a bazy danych; Podstawowe definicje i pojęcia; Cele XML; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

43
Porządek struktury dokumentu XML związany jest bezpośrednio z jego automatyczną interpretacją. Interpretację tę wspomagać ma opracowany przez konsorcjum W3C model DOM (Document Object Model), stanowiący interfejs API dla potrzeb tworzenia aplikacji będących procesorami XML. DOM bazuje na konstrukcji drzewa elementów, stąd główny element dokumentu nazywany jest <root> (korzeń). Z korzenia dokumentu wyprowadzone są poszczególne gałęzie i węzły, wyznaczające strukturę hierarchii elementów. W tworzeniu modelu obowiązuje zatem zasada „od ogółu do szczegółu”. DOM implementowany jest na poziomie języków programowania najczęściej Java i C++.
. Z korzenia dokumentu wyprowadzone są poszczególne gałęzie i węzły, wyznaczające strukturę hierarchii elementów. W tworzeniu modelu obowiązuje zatem zasada „od ogółu do szczegółu . DOM implementowany jest na poziomie języków programowania najczęściej Java i C++.")
44
Reprezentacja dokumentu według DOM
DOM – Document Object Model - przykład <TABLE> <TBODY> <TR> <TD>ShadyGrove</TD> <TD>Aeolian</TD> </TR> <TD>Over the River, Charlie</TD> <TD>Dorian</TD> </TBODY> </TABLE> Reprezentacja dokumentu według DOM Fragment dokument HTML

45
Automatyczna analiza dokumentu XML wykorzystuje rozbiór składniowy (parsing). Programy dokonujące takiego rozbioru (parsers) implementują określony model reprezentacji i interpretacji dokumentu XML. Jednym z dwóch głównych metod rozbioru jest budowanie pełnego drzewa dokumentu XML zgodnie ze specyfikacją DOM. Program implementujący DOM zawiera definicję metod zadeklarowanych w abstrakcyjnym modelu. Implementacja ta uwzględnia konkretny język programowania. Przykładowo dla bardzo często wykorzystywanego w pracy z XML języka Java, zestaw klas i metod modelu DOM przedstawia kolejny slajd. Do najbardziej znanych implementacji modelu DOM (parserów) można zaliczyć: Xerces (Apache), XML4J (IBM), JAXP (Sun), XP (James Clark).
 można zaliczyć: Xerces (Apache), XML4J (IBM), JAXP (Sun), XP (James Clark).")
46
Węzeł drzewa – zasadniczy
element danych Reprezentacja atrybutu Komentarz Wartość tekstowa elementu lub atrybutu Reprezentacja całego dokumentu XML Reprezentacja elementu

47
Rozbiór dokumentu XML zgodnie z modelem DOM realizowany jest poprzez kolejne wyszukiwanie węzłów w drzewie. Standardowo pierwszym krokiem jest wczytanie dokumentu i stworzenie jego reprezentacji w pamięci. Etap ten nie jest standaryzowany przez W3C, niemniej wielu dostawców oprogramowania stosuje proste wywołanie: DOMParser.getDocument(). Pobrany dokument znajduje się w pamięci! Jest to ważne z punktu widzenia ograniczeń w przetwarzaniu dokumentu. Wydobywanie informacji z drzewa odbywa się dalej zgodnie ze standardowymi (DOM) metodami parsera, np.: Document.getDocumentElement(); Element.getAttributte(); Node.getFirstChild(); itd.
. Pobrany dokument znajduje się w pamięci! Jest to ważne z punktu widzenia ograniczeń w przetwarzaniu dokumentu. Wydobywanie informacji z drzewa odbywa się dalej zgodnie ze standardowymi (DOM) metodami parsera, np.: Document.getDocumentElement(); Element.getAttributte(); Node.getFirstChild(); itd.")
48
Innym modelem rozbioru składniowego dokument XML jest model SAX (Simple API for XML parsing). SAX jest modelem wypracowanym przez użytkowników XML niezależnie od standardu DOM. Głównym założeniem modelu jest szybki dostęp do wybranych węzłów dokumentu XML bez konieczności składowania całego drzewa. SAX wychodzi z założenia, iż analizując dokument XML natrafiamy na różne encje. Encje te wywołują zdarzenia, których kategorie zależą od znalezionych encji. Jeżeli znajdujemy element, to generowane jest zdarzenie typu <jest element>, jeśli znak pusty to generowane jest zdarzenie <znak pusty>, itd. Obsługiwanie zdarzeń i pobieranie danych jakie niosą prowadzi do uzyskania danych dokumentu XML. Zestaw klas i interfejsów modelu SAX w wersji 2.0, zgodnie ze składnią języka Java, prezentuje kolejny slajd.

49
Główny zestaw metod obsługujących zdarzenia wywoływane w procesie analizy treści dokumentu XML.

51
Przykładowy proces analizy dokumentu XML według modelu SAX
startDocument

52
startElement (nazwa=„salon”, brak atrybutów)
Przykładowy proces analizy dokumentu XML według modelu SAX startElement (nazwa=„salon”, brak atrybutów)
")
53
Przykładowy proces analizy dokumentu XML według modelu SAX
ignorableWhitespace ignorableWhitespace

54
startElement (nazwa=„samochod” Atrybuty(„VIN”, „nrsilnika”)
Przykładowy proces analizy dokumentu XML według modelu SAX startElement (nazwa=„samochod” Atrybuty(„VIN”, „nrsilnika”)
")
55
Przykładowy proces analizy dokumentu XML według modelu SAX
ignorableWhitespace ignorableWhitespace

56
startElement (nazwa=„marka”, brak atrybutów)
Przykładowy proces analizy dokumentu XML według modelu SAX startElement (nazwa=„marka”, brak atrybutów)
")
57
Przykładowy proces analizy dokumentu XML według modelu SAX
characters

58
endElement (nazwa=„marka”)
Przykładowy proces analizy dokumentu XML według modelu SAX endElement (nazwa=„marka”) itd.
 itd.")
59
Uwaga praktyczna: Szybkość operacji rozbioru składniowego dokumentu XML, bez względu na model, zależy od jego zawartości. Zatem im mniej znaków pustych w dokumencie (spacji, CR, LF, itd.) tym lepiej.
 tym lepiej.")
60
Plan wykładu: Wprowadzenie – XML a bazy danych; Podstawowe definicje i pojęcia; Cele XML; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

61
Czy poddany przetwarzaniu dokument XML jest poprawny.
Programy dokonujące rozbioru składniowego dokumentów XML mogą być wzbogacane o możliwość weryfikacji: Czy poddany przetwarzaniu obiekt danych jest dokumentem XML, czyli czy jest dobrze-sformułowany? Czy poddany przetwarzaniu dokument XML jest poprawny. Dla przypomnienia, zgodnie z przedstawioną już specyfikacją XML, obiekt danych jest dobrze-sformułowany jeśli uwzględnia wszystkie wymagania jawnie zapisane w rekomendacji. Jawny zapis wymagań przedstawiony jest jako ścisła definicja budowy logicznej dokumentu, oraz zbioru wymagań szczegółowych poprzedzonych wyróżnikiem: „Well-formedness constraint: „ Przykładowo: Well-formedness constraint: Element Type Match The Name in an element's end-tag must match the element type in the start-tag. {Nazwa (zgodna z typem Name) znacznika końca elementu musi być identyczna jak nazwa znacznika początku tego samego elementu.}
 znacznika końca elementu musi być identyczna jak nazwa znacznika początku tego samego elementu.}")
62
„Validity constraint:”
Poprawność dokumentu XML (validity) określana jest na podstawie definicji typu dokumentu (DOCTYPE), najczęściej realizowanego poprzez DTD lub XML Schema. Podobnie jak w badaniu czy obiekt danych jest dobrze sformułowany, tak i w przypadku sprawdzania poprawności dokumentu XML konieczne jest spełnienie wymagań podanych w specyfikacji XML. Jawny zapis wymagań w rekomendacji poprzedzony jest wyróżnikiem: „Validity constraint:” Przykładowo: Validity constraint: Root Element Type The Name in the document type declaration must match the element type of the root element. {Nazwa (zgodna z typem Name) występująca w deklaracji typu dokumentu musi być identyczna jak nazwa głównego elementu (korzenia).}
 określana jest na podstawie definicji typu dokumentu (DOCTYPE), najczęściej realizowanego poprzez DTD lub XML Schema. Podobnie jak w badaniu czy obiekt danych jest dobrze sformułowany, tak i w przypadku sprawdzania poprawności dokumentu XML konieczne jest spełnienie wymagań podanych w specyfikacji XML. Jawny zapis wymagań w rekomendacji poprzedzony jest wyróżnikiem: „Validity constraint: Przykładowo: Validity constraint: Root Element Type. The Name in the document type declaration must match the element type of the root element. {Nazwa (zgodna z typem Name) występująca w deklaracji typu dokumentu musi być identyczna jak nazwa głównego elementu (korzenia).}")
63
Sprawdzanie poprawności wymaga definicji schematu dokumentu zawierającego definicje wszystkich możliwych do stosowania encji w tworzonym dokumencie. Sprawdzanie poprawności jest opcjonalne, tzn. obiekt danych nie musi być poprawny aby być dokumentem XML. Znakomita większość oprogramowania dostępnego na rynku, dostarcza mechanizmy umożliwiające weryfikację czy dany obiekt jest dobrze sformułowany. Tylko niektóre z nich umożliwiają dodatkowo sprawdzenie poprawności dokumentu. Rozpatrzmy kilka przykładów zastosowania programu badającego formułę i poprawność obiektów danych. Przeprowadzone analizy wykonano z zastosowaniem darmowego programu „xmlvalid” firmy ElCel („
.")
64
dla obiektu danych salon
dla obiektu danych salon.xml (wcześniejsze przykłady), nie zawierającego definicji typu dokumentu, sprawdzenie czy jest on dobrze sformułowany przebiega następująco: Polecenie: xmlvalid –v salon.xml Wynik: salon.xml is well-formed Zatem badany obiekt jest dokumentem XML. Wprowadzając sztucznie błąd, np. zmieniając nazwę znacznika początku elementu względem nazwy znacznika końca, wynik testu jest następujący: Wynik:salon.xml [58:9] : Fatal error: end tag '</silnik>' does not match start tag. Expected '</ilnik>' Pojawia się błąd krytyczny (podanie miejsca w kodzie źródłowym oraz informacji o rodzaju błędu). Zatem badany obiekt nie jest dokumentem XML!
, nie zawierającego definicji typu dokumentu, sprawdzenie czy jest on dobrze sformułowany przebiega następująco: Polecenie: xmlvalid –v salon.xml. Wynik: salon.xml is well-formed. Zatem badany obiekt jest dokumentem XML. Wprowadzając sztucznie błąd, np. zmieniając nazwę znacznika początku elementu względem nazwy znacznika końca, wynik testu jest następujący: Wynik:salon.xml [58:9] : Fatal error: end tag </silnik> does not match start tag. Expected </ilnik> Pojawia się błąd krytyczny (podanie miejsca w kodzie źródłowym oraz informacji o rodzaju błędu). Zatem badany obiekt nie jest dokumentem XML!")
65
2. dla dokumentu salon.xml (wcześniejsze przykłady), zawierającego definicję typu dokumentu, sprawdzanie czy jest on poprawny przebiega następująco: Polecenie: xmlvalid salon.xml Wynik: salon.xml is valid Zatem badany dokument XML jest poprawny. Wprowadzając sztucznie błąd jak poprzednio wynik testu jest następujący: Wynik: salon.xml [56:20] : Error: element content invalid. Element 'ilnik' is not expected here, expecting 'silnik' salon.xml [58:9] : Fatal error: end tag '</silnik>' does not match start tag. Expected '</ilnik>' Pojawia się błąd i błąd krytyczny (podanie miejsca w kodzie źródłowym oraz informacji o rodzaju błędu). Zatem badany obiekt nie jest poprawny i nie jest dokumentem XML!
. Zatem badany obiekt nie jest poprawny i nie jest dokumentem XML!")
66
Plan wykładu: Wprowadzenie – XML a bazy danych; Podstawowe definicje i pojęcia; Cele XML; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

67
Definicja typu dokumentu określa schemat możliwych dokumentów XML tworzonych zgodnie z danym typem. W schemacie definiowane są: znaczniki (elementy), jakie mogą być wykorzystane w dokumencie; atrybuty dla określonych elementów; wybór (lub definicja) typów danych dla powyższych encji, encje. Najbardziej popularne (rekomendacje W3C) metody definicji schematu dokumentu XML to: DTD (Document Type Definition); XML Schema. DTD jest definiowany bezpośrednio w rekomendacji XML. Schemat XML Schema, jako późniejszy, definiowany jest w oddzielnej specyfikacji: (struktura) (typy danych)
, jakie mogą być wykorzystane w dokumencie; atrybuty dla określonych elementów; wybór (lub definicja) typów danych dla powyższych encji, encje. Najbardziej popularne (rekomendacje W3C) metody definicji schematu dokumentu XML to: DTD (Document Type Definition); XML Schema. DTD jest definiowany bezpośrednio w rekomendacji XML. Schemat XML Schema, jako późniejszy, definiowany jest w oddzielnej specyfikacji: (struktura) (typy danych)")
68
DTD Obsługa schematu dokumentu XML zawiera zawsze dwa zasadnicze elementy: Definicję schematu Wywołanie schematu. W przypadku wykorzystania DTD definicja schematu może być: częścią składową dokumentu XML (wówczas atrybut standalone=„yes”), rozdzielnym dokumentem (wówczas atrybut standalone=„no”). Zanim rozpatrzymy reguły definicji DTD rozpatrzmy sposób jego powiązania z dokumentem XML. {dokument samodzielny} - <!DOCTYPE salon[ tu definicja DTD ]>, {dokument złożony} - <!DOCTYPE salon SYSTEM "salon.dtd">,czyli stosuje się identyfikator systemowy (ew. publiczny).
, rozdzielnym dokumentem (wówczas atrybut standalone=„no ). Zanim rozpatrzymy reguły definicji DTD rozpatrzmy sposób jego powiązania z dokumentem XML. {dokument samodzielny} - <!DOCTYPE salon[ tu definicja DTD ]>, {dokument złożony} - <!DOCTYPE salon SYSTEM salon.dtd >,czyli stosuje się identyfikator systemowy (ew. publiczny).")
69
DTD Definicja DTD zawiera listę typów encji możliwych do wykorzystania w tworzonym dokumencie – instancji DTD. ELEMENT – deklaracja typu: elementdecl ::= '<!ELEMENT' S Name S contentspec S? '>' contentspec ::= 'EMPTY' | 'ANY' | Mixed | children children ::= (choice | seq) ('?' | '*' | '+')? cp ::= (Name | choice | seq) ('?' | '*' | '+')? choice ::= '(' S? cp ( S? '|' S? cp )+ S? ')' seq ::= '(' S? cp ( S? ',' S? cp )* S? ')' Mixed ::= '(' S? '#PCDATA' (S? '|' S? Name)* S? ')*' | '(' S? '#PCDATA' S? ')' Przykłady: <!ELEMENT salon (samochod)+> <!ELEMENT samochod (marka, model, kolor, silnik)> <!ELEMENT marka (#PCDATA)>
 ( | * | + ) cp ::= (Name | choice | seq) ( | * | + ) choice ::= ( S cp ( S | S cp )+ S ) seq ::= ( S cp ( S , S cp )* S ) Mixed ::= ( S #PCDATA (S | S Name)* S )* | ( S #PCDATA S ) Przykłady: <!ELEMENT salon (samochod)+> <!ELEMENT samochod (marka, model, kolor, silnik)> <!ELEMENT marka (#PCDATA)>")
70
DTD Warto szczególnie zwrócić uwagę na jednostkę „Mixed”. Jej wykorzystanie umożliwia bowiem stworzenie treści elementu jako przeplatanego tekstu z subelementami. W DTD można określić wymagania co do typu tych elementów, lecz nie można zdefiniować kolejności ich występowania czy ich liczby w dokumencie XML. Jednostka „Mixed” umożliwia w zastosowaniach XML stworzenie wersji obiektu danych XML nazywanego jako „ukierunkowany na dokument” („Document oriented”). Druga postać obiektów danych XML, nazywanych jako „ukierunkowane na dane” („Data oriented”), nie zawiera przeplatania tekstu z subelementami.
. Druga postać obiektów danych XML, nazywanych jako „ukierunkowane na dane („Data oriented ), nie zawiera przeplatania tekstu z subelementami.")
71
DTD 2. ATTLIST – deklaracja listy atrybutów elementu
AttlistDecl ::= '<!ATTLIST' S Name AttDef* S? '>' AttDef ::= S Name S AttType S DefaultDecl AttType ::= StringType | TokenizedType | EnumeratedType StringType ::= 'CDATA' TokenizedType ::= 'ID' | 'IDREF' | 'IDREFS' | 'ENTITY' | 'ENTITIES' | 'NMTOKEN' | 'NMTOKENS' EnumeratedType ::= NotationType | Enumeration NotationType ::= 'NOTATION' S '(' S? Name (S? '|' S? Name)* S? ')' Enumeration ::= '(' S? Nmtoken (S? '|' S? Nmtoken)* S? ')' DefaultDecl ::= '#REQUIRED' | '#IMPLIED' | (('#FIXED' S)? AttValue) #REQUIRED – atrybut zawsze musi wystąpić, #IMPLIED – atrybut nie ma wartości domyślnej, #FIXED – atrybut ma podaną wartość stałą
* S ) Enumeration ::= ( S Nmtoken (S | S Nmtoken)* S ) DefaultDecl ::= #REQUIRED | #IMPLIED | (( #FIXED S) AttValue) #REQUIRED – atrybut zawsze musi wystąpić, #IMPLIED – atrybut nie ma wartości domyślnej, #FIXED – atrybut ma podaną wartość stałą.")
72
DTD Przykłady: <!ATTLIST salon wlasciciel CDATA #REQUIRED>
<!ATTLIST samochod VIN NMTOKEN #REQUIRED nrsilnika NMTOKEN #REQUIRED> <!ATTLIST silnik miara CDATA #REQUIRED>

73
DTD 3. ENTITY – deklaracje i definicje encji – zgodnie z opisem podanym na wcześniejszych slajdach. Przykłady: <!ENTITY wlasciciel "Jacek W. Rumiński"> <!ENTITY kontakt "&wlasciciel;

74
DTD – pełna definicja DTD (zgodna z poprzednim
DTD – pełna definicja DTD (zgodna z poprzednim przykładem dokumentu XML – „salon”) <!ENTITY wlasciciel "Jacek W. Rumiński"> <!ENTITY kontakt "&wlasciciel; <!ELEMENT salon (samochod)+> <!ELEMENT samochod (marka, model, kolor, silnik)> <!ELEMENT marka (#PCDATA)> <!ELEMENT model (#PCDATA)> <!ELEMENT kolor (#PCDATA)> <!ELEMENT silnik (#PCDATA)> <!ATTLIST salon wlasciciel CDATA #REQUIRED> <!ATTLIST samochod VIN NMTOKEN #REQUIRED nrsilnika NMTOKEN #REQUIRED> <!ATTLIST silnik miara CDATA #REQUIRED>
 <!ENTITY wlasciciel Jacek W. Rumiński > <!ENTITY kontakt &wlasciciel; > <!ELEMENT salon (samochod)+> <!ELEMENT samochod (marka, model, kolor, silnik)> <!ELEMENT marka (#PCDATA)> <!ELEMENT model (#PCDATA)> <!ELEMENT kolor (#PCDATA)> <!ELEMENT silnik (#PCDATA)> <!ATTLIST salon wlasciciel CDATA #REQUIRED> <!ATTLIST samochod VIN NMTOKEN #REQUIRED. nrsilnika NMTOKEN #REQUIRED> <!ATTLIST silnik miara CDATA #REQUIRED>")
75
Przykładowe wady DTD: ograniczone możliwości definicji struktury dokumentu (np. brak grupowania, referencji, opisów,itp.), brak typów danych innych niż tekstowy, brak możliwości definicji własnych typów danych, brak możliwości definicji kolejności i liczebności występowania elementów, niezgodność ze specyfikacją XML (efekt: specjalne programy rozbioru i syntezy dokumentu DTD). Eliminacja tych wad – XML Schema
. Eliminacja tych wad – XML Schema.")
76
XML Schema tworzony jest jako dokument XML zawierający główny element o nazwie <schema> zgodnie z wymaganą i definiowaną dla niego przestrzenią nazw: <xsd:schema xmlns:xsd=" Weryfikacja poprawności danego dokumentu XML względem schematu XML Schema wymaga wskazania pliku schematu. Realizowane to jest albo poprzez program dokonujący rozbioru (pliki jako parametry) albo poprzez jawne zapisanie w dokumencie XML referencji do schematu. Referencję zapisuje się z wykorzystaniem przestrzeni nazw: xmlns:xsi=" Przykładowo: <salon xmlns:xsi=" xsi:schemaLocation=" wlasciciel=”Jacek Ruminski” > <!-- etc. --> </salon>
 albo poprzez jawne zapisanie w dokumencie XML referencji do schematu. Referencję zapisuje się z wykorzystaniem przestrzeni nazw: xmlns:xsi= Przykładowo: <salon xmlns:xsi= xsi:schemaLocation= wlasciciel= Jacek Ruminski > <!-- etc. --> </salon>")
77
Definicja schematu dokumentu zgodna z XML Schema wymaga zbudowania dokumentu XML, zawierającego elementy zgodne z wymaganą przestrzenią nazw („xsd”). Każdy element umożliwia zdefiniowanie określonego aspektu schematu poprzez podanie wartości atrybutów tego elementu. Atrybuty są integralną częścią elementów przestrzeni XSD, zdefiniowanych w rekomendacji. Przykładowo definicja typu elementu projektowanego dokumentu XML wymaga określenia: <xsd:element name=”TU_NAZWA_PROJEKTOWANEGO_ELEMENTU” type=”TU_TYP_DANYCH_ZGODNIE_Z_XML_SCHEMA” ... „inne atrybuty> <...subelementy/> </xsd:element> np.: <xsd:element name=”samochod” type=„xsd:string”/> Definicja elementu o nawie „samochod” i typie danych jego treści jako łańcuch znaków. Element nie posiada żadnych atrybutów ani subelementów.

78
Element główny dokumentu XML (root) zawiera najczęściej subelementy
Element główny dokumentu XML (root) zawiera najczęściej subelementy. Zgodnie ze specyfikacją XML Schema, subelementy są częścią definicji typu elementu. Specyfikacja wyróżnia dwie klasy typów: simpleType oraz complexType. Typ simpleType jest zarezerwowany tylko do przechowywania wartości, bez określania subelementów czy atrybutów. Zatem jeśli dany element ma mieć subelementy to konieczne jest zapisanie ich w elemencie przestrzeni XSD o nazwie <xsd:complexType>. Przykładowo: <xsd:element name=”samochod” type=„xsd:string”> <xsd:complexType> <...> <xsd:element name=”marka” type=„xsd:string”/> <xsd:element name=”model” type=„xsd:string”/> </xsd:complexType> </xsd:element>
 zawiera najczęściej subelementy. Zgodnie ze specyfikacją XML Schema, subelementy są częścią definicji typu elementu. Specyfikacja wyróżnia dwie klasy typów: simpleType oraz complexType. Typ simpleType jest zarezerwowany tylko do przechowywania wartości, bez określania subelementów czy atrybutów. Zatem jeśli dany element ma mieć subelementy to konieczne jest zapisanie ich w elemencie przestrzeni XSD o nazwie <xsd:complexType>. Przykładowo: <xsd:element name= samochod type=„xsd:string > <xsd:complexType> <...> <xsd:element name= marka type=„xsd:string /> <xsd:element name= model type=„xsd:string /> </xsd:complexType> </xsd:element>")
79
Tworząc złożony typ danych dla elementu można określić warunki wykorzystania czy kolejności występowania subelementów. Do tych celów służą trzy podstawowe specyfikatory: <xsd:sequence> - subelementy zdefiniowane w tym elemencie muszą w instancji schematu (dokumencie XML) wystąpić w podanej kolejności; <xsd:all> - kolejność występowania subelementów w dokumencie XML jest dowolna; <xsd:choice>- element dokumentu XML zawierać może jeden ze zdefiniowanych subelementów lub jedną z grup subelementów. Przykład: <xsd:element name=”marka”> <xsd:complexType> <xsd:choice> <xsd:element name=”BMW” type=„xsd:string”/> <xsd:element name=”Mercedes” type=„xsd:string”/> </xsd:choice> </xsd:complexType> </xsd:element>
 wystąpić w podanej kolejności; <xsd:all> - kolejność występowania subelementów w dokumencie XML jest dowolna; <xsd:choice>- element dokumentu XML zawierać może jeden ze zdefiniowanych subelementów lub jedną z grup subelementów. Przykład: <xsd:element name= marka > <xsd:complexType> <xsd:choice> <xsd:element name= BMW type=„xsd:string /> <xsd:element name= Mercedes type=„xsd:string /> </xsd:choice> </xsd:complexType> </xsd:element>")
80
Deklaracje elementów i atrybutów można łączyć w grupy
Deklaracje elementów i atrybutów można łączyć w grupy. Elementy lub grupy należą do danej grupy, jeśli są subelementami elementu <xsd:group>, np.: <xsd:group name=”samochod”><xsd:sequence> <xsd:element name=”marka” type=„xsd:string”/> <xsd:element name=”model” type=„xsd:string”/> </xsd:sequence></xsd:group> Do deklaracji grupy, deklaracji elementu lub atrybutu można się odwołać poprzez użycie atrybutu „ref”, np.: <xsd:element name=”auto”><xsd:complexType> <xsd:group ref=”samochod”/> </xsd:complexType> </xsd:element> Za pomocą atrybutów ”minOccurs” oraz ”maxOccurs” elementu <xsd:element> można ponadto określić dopuszczalną powtarzalność deklarowanego elementu.

81
Definiując złożony typ danych dla elementu docelowego można wykorzystać atrybut „mixed” elementu <xsd:complexType>, którego wartość ”true” oznacza, że tekst może przeplatać się z subelementami (Document-oriented). Podobnie jak w DTD również i w XML Schema nie ma możliwości określania lokalizacji treści elementu względem subelementów. Przykład: XML Schema: <xsd:element name=”student”><xsd:complexType mixed=”true”> <xsd:group ref=”samochod”/> </xsd:complexType> </xsd:element> Element dokumentu XML: <student> Franek ma <marka> Reanult</marka> <model>Clio</model>, którym jeździ codziennie nad morze</student>

82
Deklaracja atrybutu występuje zawsze na końcu deklaracji złożonego typu danych. Atrybut definiowany jest poprzez atrybuty elementu <xsd:attribute>, np.: <xsd:element name=”auto”><xsd:complexType> <xsd:group ref=”samochod”/> <xsd:attribute name=”VIN” type=”xsd:decimal”/> </xsd:complexType> </xsd:element> XML Schema umożliwia również deklaracje określające, które elementy muszą być unikalne. Do tych celów służą elementy <xsd:unique> lub <xsd:key>. Elementy te zawierają zgodnie ze specyfikacją XPath adres unikalnego elementu, np.: <xsd:key name=”peselKluczem” > <xsd:selector xpath=”student”/> <xsd:field xpath=”pesel”/> </xsd:key>

83
W XML Schema można definiować własne, proste typy danych
W XML Schema można definiować własne, proste typy danych. Służy do tego element <xsd:simpleType>. Nazwa nowego typu definiowana jest jako wartość atrybutu elementu simpleType. Typ bazowy oraz dziedzinę określa szereg subelementów zdefiniowanych w rekomendacji, np..: <xsd:simpleType name="wiek"> <xsd:restriction base="xsd:integer"> <xsd:minInclusive value="0"/> <xsd:maxInclusive value="130"/> </xsd:restriction> </xsd:simpleType> (typ o nazwie „wiek” możliwe wartości to liczby całkowite z zakresu ) <xsd:simpleType name="kod"> <xsd:restriction base="xsd:string"> <xsd:pattern value="\d{2}-[A-Z]{5}"/> </xsd:restriction> </xsd:simpleType> (typ o nazwie „kod” możliwe wartości muszą być zgodne z wzorcem w postaci wyrażenia regularnego: po dwóch cyfrach występuje myślnik oraz 5 wielkich liter z zakresu kodu ASCII.) W deklaracjach elementów, atrybutów i prostych typów danych stosowane są typy danych zdefiniowane w specyfikacji XML. Należą do nich (kolejny slajd):
 <xsd:simpleType name= kod > <xsd:restriction base= xsd:string > <xsd:pattern value= \d{2}-[A-Z]{5} /> </xsd:restriction> </xsd:simpleType> (typ o nazwie „kod możliwe wartości muszą być zgodne z wzorcem w postaci wyrażenia regularnego: po dwóch cyfrach występuje myślnik oraz 5 wielkich liter z zakresu kodu ASCII.) W deklaracjach elementów, atrybutów i prostych typów danych stosowane są typy danych zdefiniowane w specyfikacji XML. Należą do nich (kolejny slajd):")
84
(unconstrained)
")
85
Specyfikacja XML Schema podaje znacznie więcej możliwości kompozycji schematu dokumentu niż te podstawowe wymienione w tym dokumencie. Do ciekawszych zaliczyć jeszcze można następujące elementy: <xsd:union> - unia elementów lub grup; <xsd:annotation> - opis dokumentu, zawiera szereg subelementów, jest stosowany do dokumentacji schematu zamiast tradycyjnego komentarza XML; <xsd:include> - załączenie innego schematu.

86
Plan wykładu: Wprowadzenie – XML a bazy danych; Podstawowe definicje i pojęcia; Cele XML; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

87
Składowanie dokumentów XML jest najczęściej związane z rodzajem dokumentu, lub jego zaklasyfikowaniem do danego rodzaju. Zgodnie z tym co przedstawiono wcześniej dokumentu podzielono na: ukierunkowane na dane ukierunkowane na dokumenty. Pierwszy rodzaj dokumentu posiada wyraźny podział struktury, bez przeplatania treści elementu XML ze znacznikami. Umożliwia to na proste rozbicie struktury XML i jej odwzorowanie na znane modele danych jak np. hierarchiczny, relacyjny czy obiektowy. Systemy zarządzania bazami danych obsługujące tego rodzaju dokumenty nazywane są „XML enabled”. Czasami możliwe jest również zastosowanie warstwy pośredniczącej (middleware) odwzorowującej XML na model danych obsługiwany przez określony SZBD. Oprogramowanie warstwy pośredniej realizuje najczęściej odwzorowanie: XML->SQL.
 odwzorowującej XML na model danych obsługiwany przez określony SZBD. Oprogramowanie warstwy pośredniej realizuje najczęściej odwzorowanie: XML->SQL.")
88
W przypadku drugiego typu dokumentów („document-centric”) tworzone SZBD składają całe dokumenty. Stanowią zatem swoiste kolekcje dokumentów, stąd często słowo „kolekcja” jest zamienne w tym przypadku względem tabeli (relacji). Kolekcje dokumentów XML są zorganizowane w ramach tzw. „Native XML Database” (NXD). Bazy dokumentów XML są dedykowane tym właśnie dokumentom, a tworzone dla nich systemy zarządzania umożliwiają podstawowe operacje zapisywania, usuwania, aktualizacji czy wyszukiwania. Z tych względów tworzone są również propozycje norm (rekomendacji) jak np. XML:DB (
. Kolekcje dokumentów XML są zorganizowane w ramach tzw. „Native XML Database (NXD). Bazy dokumentów XML są dedykowane tym właśnie dokumentom, a tworzone dla nich systemy zarządzania umożliwiają podstawowe operacje zapisywania, usuwania, aktualizacji czy wyszukiwania. Z tych względów tworzone są również propozycje norm (rekomendacji) jak np. XML:DB (")
89
Data-centric Wymiana danych pomiędzy bazą danych a dokumentem XML wymaga odwzorowania schematu dokumentu (DTD, XML Schema) na schemat bazy danych. Odwzorowanie jest często realizowane za pomocą implementacji wyrażeń SQL, XQuery czy XPath. Jeżeli z jakiś przyczyn dana struktura dokumentu XML nie może być bezpośrednio odwzorowana na strukturę bazy danych stosuje się dodatkową transformację dokumentu XML do innej postaci (zastosowanie XSLT, o czym później). Odwzorowanie schematu dokumentu wykorzystuje zasadniczo tylko logiczną strukturę dokumentu, i co więcej, ogranicza się jedynie do najważniejszych jej części tj.: elementów i atrybutów. Odwzorowanie realizowane jest najczęściej do dwóch postaci: tablicowej, obiektowo-relacyjnej.
 na schemat bazy danych. Odwzorowanie jest często realizowane za pomocą implementacji wyrażeń SQL, XQuery czy XPath. Jeżeli z jakiś przyczyn dana struktura dokumentu XML nie może być bezpośrednio odwzorowana na strukturę bazy danych stosuje się dodatkową transformację dokumentu XML do innej postaci (zastosowanie XSLT, o czym później). Odwzorowanie schematu dokumentu wykorzystuje zasadniczo tylko logiczną strukturę dokumentu, i co więcej, ogranicza się jedynie do najważniejszych jej części tj.: elementów i atrybutów. Odwzorowanie realizowane jest najczęściej do dwóch postaci: tablicowej, obiektowo-relacyjnej.")
90
Data-centric Odwzorowanie tablicowe jest bardzo często realizowane przez warstwy pośrednie, a polega na utworzeniu lub odtworzeniu struktury drzewiastej dokumentu XML w formie uszczegółowiania elementów bazy danych: <bazadanych> <tabela> <wiersz> <kolumna1>...</kolumna1> <kolumna2>...</kolumna2> ... <kolumnaN>...</kolumnaN> </wiersz> </tabela> </bazadanych>

91
Data-centric Odwzorowanie obiektowo-relacyjne dokumentu XML polega na utworzeniu struktury klasy danego typu (np. bazując na „complex element type” dla XML Schema), a później odwzorowaniu go na model relacyjny (klasy na tabele; pola na kolumny, itd.). Należy podkreślić iż odwzorowanie obiektowo-relacyjne nie wykorzystuje modelu DOM danego dokumentu, który jest raczej właściwy dla organizacji logicznej dokumentu XML (relacja Element->Element zamiast Samochod->Kierowca), niż dla reprezentacji danych. Dokumenty typu „data-centric” są również przechowywane w bazach danych typu NXD. Jedną z przyczyn zastosowania tego rodzaju bazy dla dokumentów „data-centric” może być potrzeba szybkiego pobierania dokumentów XML z bazy. Ponieważ w NXD składowane są dokumenty, zatem nie ma potrzeby ich tworzenia w odpowiedzi na dane żądanie pobrania.
, a później odwzorowaniu go na model relacyjny (klasy na tabele; pola na kolumny, itd.). Należy podkreślić iż odwzorowanie obiektowo-relacyjne nie wykorzystuje modelu DOM danego dokumentu, który jest raczej właściwy dla organizacji logicznej dokumentu XML (relacja Element->Element zamiast Samochod->Kierowca), niż dla reprezentacji danych. Dokumenty typu „data-centric są również przechowywane w bazach danych typu NXD. Jedną z przyczyn zastosowania tego rodzaju bazy dla dokumentów „data-centric może być potrzeba szybkiego pobierania dokumentów XML z bazy. Ponieważ w NXD składowane są dokumenty, zatem nie ma potrzeby ich tworzenia w odpowiedzi na dane żądanie pobrania.")
92
Data-centric Oddzielnym zagadnieniem jest odwzorowanie typów danych. W XML zasadniczym typem danych jest tekst. Zatem konieczne jest przeprowadzenie konwersji typów uwzględniającej zarówno zakres jak i rodzaj danych. Ponadto należy pamiętać o stosowanych zestawach danych. XML bazuje zasadniczo na Unicodzie, z wyjątkiem wybranych znaków sterujących, które nie powinny być wykorzystane jako treść danych. Kolejnym problemem są dane binarne. Odniesienie do nich jest możliwe poprzez zastosowanie encji, nie podlegających rozbiorowi (interpretacji przez procesor XML). Ponieważ encja jest jednak elementem fizycznym a nie logicznym struktury XML zatem nie jest odwzorowywana. Inna możliwość to zakodowanie bajtów znakami (kodowanie Base64). Brak jest jednak standardowych notacji na oznaczenie, że dany element zawiera tego typu zakodowane dane, stąd jest to tylko i wyłącznie w opcji oprogramowania realizującego odwzorowanie.
. Ponieważ encja jest jednak elementem fizycznym a nie logicznym struktury XML zatem nie jest odwzorowywana. Inna możliwość to zakodowanie bajtów znakami (kodowanie Base64). Brak jest jednak standardowych notacji na oznaczenie, że dany element zawiera tego typu zakodowane dane, stąd jest to tylko i wyłącznie w opcji oprogramowania realizującego odwzorowanie.")
93
Document-centric Składowanie dokumentów XML może również być zrealizowane na wiele sposobów. Pierwsze możliwe rozwiązanie to zapis dokumentu XML w modelu hierarchicznym -> jako plik w systemie plików. Innym rozwiązaniem może być zastosowanie typów danych LOB (Large OBject, np.. CLOB -> Character Large OBject). Jeszcze innym rozwiązaniem jest składowanie dokumentu XML jako obiektu w obiektowej bazie danych. Składowanie dokumentów XML wymaga w tym wypadku spełnienia warunku identyczności dokumentu dostarczonego do archiwum z dokumentem pobieranym z archiwum (round-tripping). Jest to niezwykle ważna własność szczególnie dla procesu podpisywania dokumentów XML (XML Digital Signature Standard); gdzie każdy znak dokumentu musi wystąpić aby pozytywnie zweryfikować podpis. Składowanie dokumentów XML (tzn. w formie document-centric) realizowane jest w ramach technologii Native XML Databases.
. Jeszcze innym rozwiązaniem jest składowanie dokumentu XML jako obiektu w obiektowej bazie danych. Składowanie dokumentów XML wymaga w tym wypadku spełnienia warunku identyczności dokumentu dostarczonego do archiwum z dokumentem pobieranym z archiwum (round-tripping). Jest to niezwykle ważna własność szczególnie dla procesu podpisywania dokumentów XML (XML Digital Signature Standard); gdzie każdy znak dokumentu musi wystąpić aby pozytywnie zweryfikować podpis. Składowanie dokumentów XML (tzn. w formie document-centric) realizowane jest w ramach technologii Native XML Databases.")
94
Plan wykładu: Wprowadzenie – XML a bazy danych; Podstawowe definicje i pojęcia; Cele XML; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

95
Native XML Databases (NXD) określa ogólną klasę systemów zarządzania bazami danych tworzących kolekcje dokumentów XML w formie pełnej (tzn., wszystkie znaki dokumentu XML są składowane). Podsumowanie metod organizacji baz danych XML przedstawia poniższy diagram (na przykładzie Oracle XML DB).
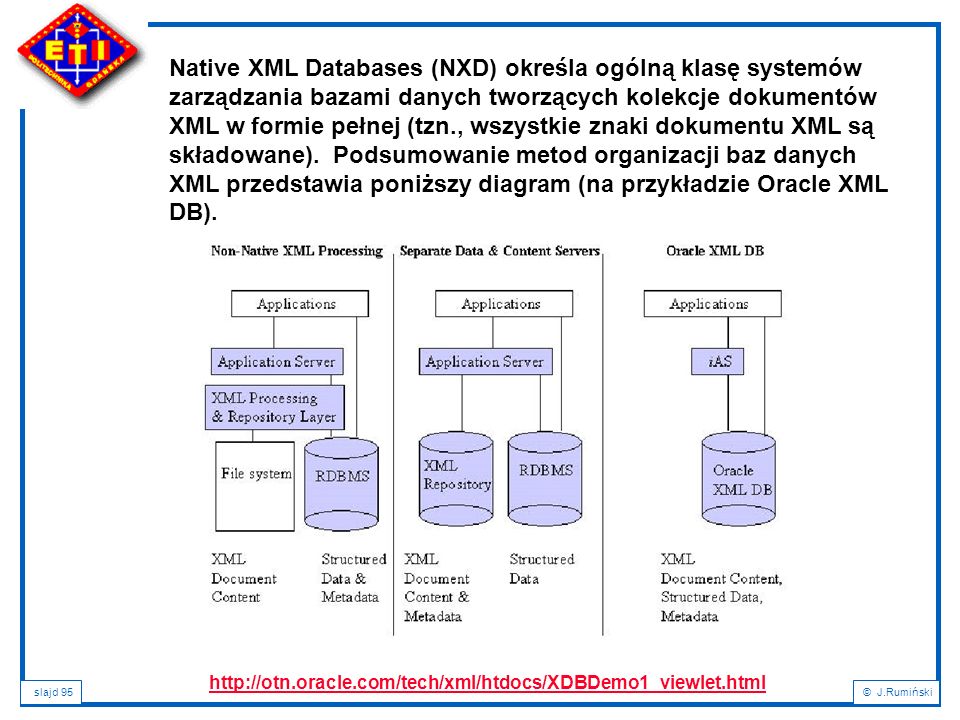
96
NXD umożliwiają składowanie zarówno elementów/atrybutów jak i komentarzy, encji nie podlegających rozbiorowi, itp. NXD obsługują dedykowane dla XML języki zapytań. Jest to istotna funkcja, gdyż trudno jest zdefiniować i wykonać w SQL lub OQL niektóre zapytania dotyczące składni dokumentu XML. Podjęto szereg prób definicji NXD; jedna z najbardziej popularnych została sformułowana przez XML:DB (na łamach listy dyskusyjnej): NXD: Definiuje logiczny model dokumentu XML – w odróżnieniu do danych dokumentu – oraz umożliwia składowanie i odzyskiwanie dokumentów zgodnie z tym modelem. Przykładowymi modelami są: XPath, DOM, SAX. Jednostką danych modelu jest dokument XML (w modelu relacyjnym krotka, w modelu obiektowym obiekt). Model nie określa fizycznej organizacji danych.
: NXD: Definiuje logiczny model dokumentu XML – w odróżnieniu do danych dokumentu – oraz umożliwia składowanie i odzyskiwanie dokumentów zgodnie z tym modelem. Przykładowymi modelami są: XPath, DOM, SAX. Jednostką danych modelu jest dokument XML (w modelu relacyjnym krotka, w modelu obiektowym obiekt). Model nie określa fizycznej organizacji danych.")
97
Cechy realizacji NXD: operują na pojęciu kolekcji (relacja w RDB) dokumentów XML (krotka w RDB); wykorzystują dedykowane języki zapytań, np.: XPath, XQL, Xquery; wykorzystują dedykowane metody aktualizacji danych, np.: XUpdate; dostarczają API dla rozwoju aplikacji; wspomagają indeksowanie dokumentów; normalizacja dokumentów realizowana jest na poziomie projektu schematu (możliwe są jednak elementy wielowartościowe); integralność referencyjna zapewnia istnienie poprawnych dokumentów XML wskazywanych przez XLink lub inne mechanizmy referencyjne. Popularną (poza komercyjnymi) wersją NXD jest Xindice (Apache, dawniej dbXML).
; integralność referencyjna zapewnia istnienie poprawnych dokumentów XML wskazywanych przez XLink lub inne mechanizmy referencyjne. Popularną (poza komercyjnymi) wersją NXD jest Xindice (Apache, dawniej dbXML).")
98
Plan wykładu: Wprowadzenie – XML a bazy danych; Podstawowe definicje i pojęcia; Cele XML; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

99
XPath – rekomendacja W3C pozwalająca na definiowanie referencji (adresu) do encji. Wykorzystywana jest często do formułowania treści wyszukiwanej w dokumencie XML. XPath jest bardzo często wykorzystywany przez XDB. W wersji XPath 2.0 wprowadzono wyrażenia regularne rozszerzające dodatkowo zakres możliwych do zdefiniowania wzorców. Zasadnicza składnia wyrażenia XPath opiera się o znaną ścieżkę dostępu w hierarchii systemu plików, np.: /sklep - oznacza główny element dokumentu (korzeń), /sklep/chleb - oznacza subelement „chleb” dokumentu, //napoj - oznacza wszystkie elementy „napoj” hierarchii, /sklep/* - oznacza wszystkie subelementy elementu „sklep”, /sklep/napoj[1] - oznacza pierwszego potomka subelementu „napoj”, /sklep/napoj[last()] – oznacza ostatniego (użycie funkcji) potomka subelementu „napoj”, - oznacza atrybuty „cola” wszystkich elementów „napoj”, - oznacza wszystkie elementy „napoj” bez atrybutow; – oznacza wszystkie elementy „napoj” o wartości atrybutu cola równej „pepsi”
, /sklep/chleb - oznacza subelement „chleb dokumentu, //napoj - oznacza wszystkie elementy „napoj hierarchii, /sklep/* - oznacza wszystkie subelementy elementu „sklep , /sklep/napoj[1] - oznacza pierwszego potomka subelementu „napoj , /sklep/napoj[last()] – oznacza ostatniego (użycie funkcji) potomka subelementu „napoj , - oznacza atrybuty „cola wszystkich elementów „napoj , - oznacza wszystkie elementy „napoj bez atrybutow; – oznacza wszystkie elementy „napoj o wartości atrybutu cola równej „pepsi")
100
//*[count(napoj)=2] – oznacza wszystkie elementy mające dwóch potomków „napoj”,
//*[contains(name(),‘n')] – oznacza wszystkie elementy zawierające w nazwie „n”, //napoj | //chleb - oznacza wszystkie elementy „napoj” i „chleb”, //napoj/parent::* - oznacza wszystkich rodziców elementu „napoj”, i wiele innych. Dla XPath zdefiniowano szereg funkcji oraz operatorów umożliwiających budowanie złożonych ścieżek dostępu. XPath 2.0 (draft) umożliwia również wykorzystanie wyrażeń regularnych, pętli, instrukcji warunkowych itp.
![//*[count(napoj)=2] – oznacza wszystkie elementy mające dwóch potomków „napoj ,](http://slideplayer.pl/slide/7286392/24/images/100/%2F%2F%2A%5Bcount%28napoj%29%3D2%5D+%E2%80%93+oznacza+wszystkie+elementy+maj%C4%85ce+dw%C3%B3ch+potomk%C3%B3w+%E2%80%9Enapoj+%2C.jpg "//*[contains(name(),‘n )] – oznacza wszystkie elementy zawierające w nazwie „n , //napoj | //chleb - oznacza wszystkie elementy „napoj i „chleb , //napoj/parent::* - oznacza wszystkich rodziców elementu „napoj , i wiele innych. Dla XPath zdefiniowano szereg funkcji oraz operatorów umożliwiających budowanie złożonych ścieżek dostępu. XPath 2.0 (draft) umożliwia również wykorzystanie wyrażeń regularnych, pętli, instrukcji warunkowych itp.")
101
XQuery – język zapytań da XML
Relacja pomiędzy XQuery a XPath 2.0: XQuery 1.0 (draft): „XQuery is derived from an XML query language called Quilt [Quilt], which in turn borrowed features from several other languages, including XPath 1.0 [XPath 1.0], XQL [XQL], XML-QL [XML-QL], SQL [SQL], and OQL [ODMG]. XQuery Version 1.0 is an extension of XPath Version 2.0. Any expression that is syntactically valid and executes successfully in both XPath 2.0 and XQuery 1.0 will return the same result in both languages.” Przykład: Generacja dokumentu HTML jako lista nagłówków zawierająca ceny napojów (elementy /sklep/napoj/cena): <html>{ let $sklep := document(„mojsklep.xml")/sklep for $t in $sklep/napoj return <h2>{$t/cena)</h2> }</html>
: „XQuery is derived from an XML query language called Quilt [Quilt], which in turn borrowed features from several other languages, including XPath 1.0 [XPath 1.0], XQL [XQL], XML-QL [XML-QL], SQL [SQL], and OQL [ODMG]. XQuery Version 1.0 is an extension of XPath Version 2.0. Any expression that is syntactically valid and executes successfully in both XPath 2.0 and XQuery 1.0 will return the same result in both languages. Przykład: Generacja dokumentu HTML jako lista nagłówków zawierająca ceny napojów (elementy /sklep/napoj/cena): <html>{ let $sklep := document(„mojsklep.xml )/sklep. for $t in $sklep/napoj. return <h2>{$t/cena)</h2> }</html>")
102
Przykładowa implementacja XQuery: http://xqueryservices
Przykładowa implementacja XQuery: - demonstracja przykładowych zapytań według: Inna: - możliwe do pobrania z tej strony API oraz prosta aplikacja umożliwiają testowanie własnych zapytań XQuery. Przykładowe podręczniki nauki XQuery opisane są na stronie W3C:

103
Przykład na podstawie: http://www.w3.org/TR/xmlquery-use-cases/

104
Plan wykładu: Wprowadzenie – XML a bazy danych; Podstawowe definicje i pojęcia; Cele XML; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

105
Jedną z najważniejszych cech technologii XML jest możliwość automatycznego przekształcania dokumentów XML. Przekształcenie to (transformacja) odbywa się poprzez zdefiniowany plik opisujący odwzorowanie źródło->cel. Plik taki tworzony jest zgodnie z rekomendacją XML oraz XSL (Extensible Stylesheet Language), i nosi nazwę arkusza stylów. XML Stylesheet wykorzystywane jest następnie (obok pliku źródłowego XML) do przekształcenia przez procesor XSLT (XSL Transform) do postaci końcowej. Postać końcowa oznaczać może inny plik XML, XHTML, PDF, itp. Transformacja plików XML na inną postać XML jest również czasem wykonywana przy składowaniu danych dokumentu XML w bazie danych. XSL jest zatem zarówno językiem transformacji dokumentów XML jak i słownikiem znaczników wykorzystywanych do formatowania składni dokumentu końcowego.

106
<?xml version='1.0' encoding='ISO-8859-2'?> ...
XSL ( musi być dokumentem XML, zawierającym oprócz prologu element arkusza stylów z definicją przestrzeni nazw „xsl”: <?xml version='1.0' encoding='ISO '?> <xsl:stylesheet version="1.0" xmlns:xsl=" ... </xsl:stylesheet> Arkusz zawierać może różne elementy definiowane w specyfikacji XSL, między innymi xsl:template (szablon), xsl:output (parametry formatu wyjścia), xsl:variable (definicja zmiennej), itd. Zasadniczym elementem, w obrębie którego definiuje się odwzorowanie jest szablon. Element xsl:template zawiera jako atrybut wyrażenie zgodne z XPath wskazujące adres elementu źródłowego, który jest odwzorowywany zgodnie z danym szablonem. <xsl:template match="szkoda"> </xsl:template>
, xsl:output (parametry formatu wyjścia), xsl:variable (definicja zmiennej), itd. Zasadniczym elementem, w obrębie którego definiuje się odwzorowanie jest szablon. Element xsl:template zawiera jako atrybut wyrażenie zgodne z XPath wskazujące adres elementu źródłowego, który jest odwzorowywany zgodnie z danym szablonem. <xsl:template match= szkoda > </xsl:template>")
107
W ciele tak zdefiniowanego elementu określa się reguły odwzorowania
W ciele tak zdefiniowanego elementu określa się reguły odwzorowania. W tym celu wprowadza się tekst wolny (tzn., taki, który nie jest interpretowany przez procesor XSLT lecz jest przepisywany), oraz elementy „xsl” służące do zdefiniowania dalszych reguł odwzorowania. Przykładowe elementy to: <xsl:apply-templates> - określa żądanie wstawienia wyniku przetwarzania węzłów potomnych lub węzłów określonych przez zgodny z XPath adres, podany jako wartość atrybutu „select”, np.: <xsl:apply-templates select="//rowid"/> <xsl:value-of> - określa żądanie wstawienia wartości elementu lub atrybutu według zgodnego z XPath adresu, podanego jako wartość atrybutu „select”, np.: <xsl:value-of select="opis"/> <xsl:element> oraz <xsl:attribute> - określają żądanie wstawienia do dokumentu końcowego elementów XML i ich atrybutów zgodnie z podanymi wartościami, np.:
, oraz elementy „xsl służące do zdefiniowania dalszych reguł odwzorowania. Przykładowe elementy to: <xsl:apply-templates> - określa żądanie wstawienia wyniku przetwarzania węzłów potomnych lub węzłów określonych przez zgodny z XPath adres, podany jako wartość atrybutu „select , np.: <xsl:apply-templates select= //rowid /> <xsl:value-of> - określa żądanie wstawienia wartości elementu lub atrybutu według zgodnego z XPath adresu, podanego jako wartość atrybutu „select , np.: <xsl:value-of select= opis /> <xsl:element> oraz <xsl:attribute> - określają żądanie wstawienia do dokumentu końcowego elementów XML i ich atrybutów zgodnie z podanymi wartościami, np.:")
108
<xsl:element name=”firma”>
<xsl:attribute name=”REGON”> </xsl:attribute> JTECH </xsl:element> Efekt: <firma REGON=” ”>JTECH</firma> <xsl:for-each> - określa realizowane w pętli żądanie wykonania danego odwzorowania dla elementów według zgodnego z XPath adresu, podanego jako wartość atrybutu „select”, np.: <xsl:for-each select=„samochod"> ... <xsl:for-each> <xsl:if> - określa żądanie wykonania odwzorowania jeśli spełniony jest warunek podany jako zgodny z XPath adres, stanowiący adres atrybutu „test”, np.:

109
<xsl:if test=”@REGON=‘000012345’ ”>
... </xsl:if> <xsl:choose>, <xsl:when>, <xsl:otherwise> - określa realizację w obrębie pętli danych instrukcji odwzorowania jeśli spełniony jest warunek podany jako wartość argumentu „test” elementu <xsl:when> lub innych instrukcji odwzorowania jeśli ten warunek nie jest spełniony (<xsl:otherwise>), np.: <xsl:for-each select=„samochod"> <xsl:choose> <xsl:when ”> </xsl:when> <xsl:otherwise> </xsl:otherwise> </xsl:choose> <xsl:for-each> i inne.
, np.: <xsl:for-each select=„samochod > <xsl:choose> <xsl:when > </xsl:when> <xsl:otherwise> </xsl:otherwise> </xsl:choose> <xsl:for-each> i inne.")
110
Przykładowy dokument XSL:
Na podstawie

111
Przykładowy dokument XSL:
Na podstawie

112
XSL i obiekty formatujące (FO)
Obiekty formatujące stanowią treść rozdziału 6 specyfikacji XSL 1.0. Obiekty te stanowią metodę odwzorowania z formatu składowania danych na format prezentacji danych. Specyfikacja określa zarówno składnię wykorzystania obiektów formatujących jak i ich pełny zestaw. Wykorzystywana przestrzeń nazw dla FO to: xmlns:fo=" Opis prezentacji zaczyna się od obiektu formatującego <fo:layout-master-set>, który zawiera jeden lub więcej elementów typu „page master” lub „page sequence master” określających układ dokumentu, np.: <fo:simple-page-master master-name="all" page-height="11.5in" page-width="8.5in" margin-top="1in" margin-bottom="1in" margin-left="0.75in" margin-right="0.75in"> <fo:region-body margin-top="1in" margin-bottom="0.75in"/> <fo:region-before extent="0.25in"/> <fo:region-after extent="0.5in"/> </fo:simple-page-master> Strony przygotowywanego dokumentu są grupowane w sekwencję stron.

113
Odwzorowywanie oraz wprowadzanie własnego tekstu odbywa się w obrębie elementu <fo:flow>. Wartość atrybutu tego elementu „flow-name” określa gdzie przetwarzane dane mają być zawarte. <fo:flow flow-name="xsl-region-body"> <xsl:apply-templates select="rowid"/> </fo:flow> Elementarne odwzorowanie definiowane jest w elemencie <fo:block> zdefiniowanym w elemencie <fo:flow> (najczęściej przez <xsl:apply-templates>). Element <fo:block> posiada wiele atrybutów umożliwiających zdefiniowanie parametrów prezentacji tekstu, np.: kolor czcionki, krój czcionki, rozmiar, itp. Przykładowe zastosowanie elementu: <fo:block color="blue">NAZWISKO:</fo:block>, <fo:block><xsl:value-of select="."/></fo:block> , <fo:block text-align="start" font-size="12pt" font-family="sans-serif"> ... </fo:block>
. Element <fo:block> posiada wiele atrybutów umożliwiających zdefiniowanie parametrów prezentacji tekstu, np.: kolor czcionki, krój czcionki, rozmiar, itp. Przykładowe zastosowanie elementu: <fo:block color= blue >NAZWISKO:</fo:block>, <fo:block><xsl:value-of select= . /></fo:block> , <fo:block text-align= start font-size= 12pt font-family= sans-serif > ... </fo:block>")
114
Przykład: <?xml version="1.0" encoding="ISO-8859-2"?>
<xsl:stylesheet xmlns:xsl=" xmlns:fo=" version="1.0"> <xsl:template match="ROWSET"> <fo:root xmlns:fo=" <fo:layout-master-set> <fo:simple-page-master master-name="all” page-height="11.5in" page-width="8.5in" margin-top="1in" margin-bottom="1in" margin-left="0.75in" margin-right="0.75in"> <fo:region-body margin-top="1in" margin-bottom="0.75in"/> <fo:region-before extent="0.25in"/> <fo:region-after extent="0.5in"/> </fo:simple-page-master> </fo:layout-master-set> <fo:page-sequence master-reference="all" format="i"> <fo:static-content flow-name="xsl-region-before"> <fo:block text-align="center" font-size="10pt" font-family="serif" line-height="1em + 2pt"> <fo:retrieve-marker retrieve-class-name="rowid” retrieve-boundary="page" retrieve-position="first-starting-within-page"/> FORMULARZ SZKODY - SLEEP SAFE INSURANCE <fo:retrieve-marker retrieve-class-name="rowid” retrieve-boundary="page„ retrieve-position="last-ending-within-page"/> </fo:block> </fo:static-content> <fo:static-content flow-name="xsl-region-after"> <fo:block text-align="center" font-size="10pt" font-family="serif" line-height="1em + 2pt">Strona (<fo:page-number/>) </fo:block></fo:static-content> <fo:flow flow-name="xsl-region-body"> <xsl:apply-templates select="rowid"/> </fo:flow></fo:page-sequence></fo:root></xsl:template>
 </fo:block></fo:static-content> <fo:flow flow-name= xsl-region-body > <xsl:apply-templates select= rowid /> </fo:flow></fo:page-sequence></fo:root></xsl:template>")
115
Przykład cd.: <xsl:template match="rowid">
<fo:block text-align="start" font-size="12pt" font-family="sans-serif"> <xsl:apply-templates select="nazwisko"/> <xsl:apply-templates select="imie"/> <xsl:apply-templates select="dimie"/> <xsl:apply-templates select="pesel"/> <fo:leader leader-alignment="reference-area" leader-pattern="dots” leader-length="5in"/> <fo:leader leader-alignment="reference-area" leader-pattern="dots" leader-length="5in"/> <xsl:apply-templates select="szkoda/adres"/> <xsl:apply-templates select="szkoda/opis"/> <xsl:apply-templates select="szkoda/czas"/> </fo:block> </xsl:template> <xsl:template match="nazwisko"> <fo:block color="blue">NAZWISKO:</fo:block> <fo:block start-indent="3em"><xsl:value-of select="."/></fo:block> <xsl:template match="imie"> <fo:block color="blue">IMIE:</fo:block>

116
Przykład cd.: <xsl:template match="dimie"> <fo:block color="blue">DRUGIE IMIE:</fo:block> <fo:block start-indent="3em"><xsl:value-of select="."/></fo:block> </xsl:template> <xsl:template match="pesel"> <fo:block color="blue">PESEL:</fo:block> <xsl:template match="szkoda/adres"> <fo:block color="red">MIEJSCE ZDARZENIA:</fo:block> <xsl:template match="szkoda/opis"> <fo:block color="red">OPIS ZDARZENIA:</fo:block> <xsl:template match="szkoda/czas"> <fo:block color="red">DATA I GODZINA ZDARZENIA:</fo:block> <fo:block start-indent="3em"> <xsl:value-of select="."/></fo:block> Bardzo dobry podręcznik dotyczący FO:

117
Plan wykładu: Wprowadzenie – XML a bazy danych; Podstawowe definicje i pojęcia; Cele XML; Charakterystyka dokumentu XML; Rozbiór składniowy dokumentu XML; Poprawność dokumentu XML; Metody definicji typów dokumentów: DTD, XML-Schema; Rodzaje dokumentów XML i formy ich składowania; NXD – Native XML Databases; Wyszukiwanie i przeszukiwanie dokumentów XML: XPath a XQuery; Przekształcanie dokumentów XML: XSL, XSLT, XPath, FO; Zastosowania XML

118
Zastosowania XML: Wiadomości elektroniczne, np. SOAP; Pliki konfiguracyjne; Interfejs (odwzorowywanie danych); Dokumentacja XML, różna forma (plik, baza danych) i różna treść (GML, MathML, HL7, inne); Opis treści danych multimedialnych - MPEG7; Inne. Dziękuję.
 i różna treść (GML, MathML, HL7, inne); Opis treści danych multimedialnych - MPEG7; Inne. Dziękuję.")
Podobne prezentacje


 Klasy i obiekty.>")












 miał miejsce.>")




