Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Wykład 12 Regresja liniowa
Materiały dotyczące regresji linowej zostały przygotowane w oparciu o materiały Profesora G. P. McCabe z kursu ,, Applied regression analysis’’ na Uniwersytecie Purdue. Kurs był przygotowany w oparciu o książkę: Kutner, Nachtsheim, Neter and Li, Applied Linear Statistical Models, (5th ed.)
")
2
Krzywa wieża w Pizie

3
Przykład (2) Zmienna zależna - nachylenie (Y)
Zmienna wyjaśniająca - czas (X) wykres dopasowanie prostej regresji przewidywanie przyszłości
 wykres. dopasowanie prostej regresji. przewidywanie przyszłości.")
4
SAS Data Step data a1; input year lean @@; cards;
; data a1p; set a1; if lean ne .;

5
SAS Proc Print proc print data=a1; run;

6
OBS YEAR LEAN

7
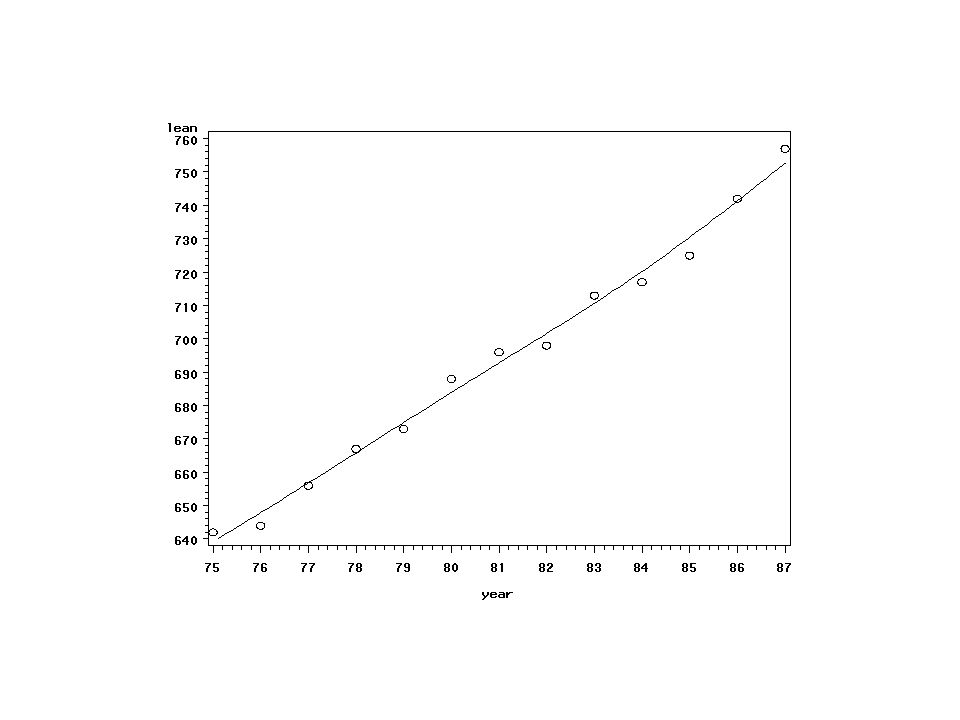
SAS Proc Gplot symbol1 v=circle i=sm70s;
proc gplot data=a1p; plot lean*year; run; symbol1 v=circle i=rl;

10
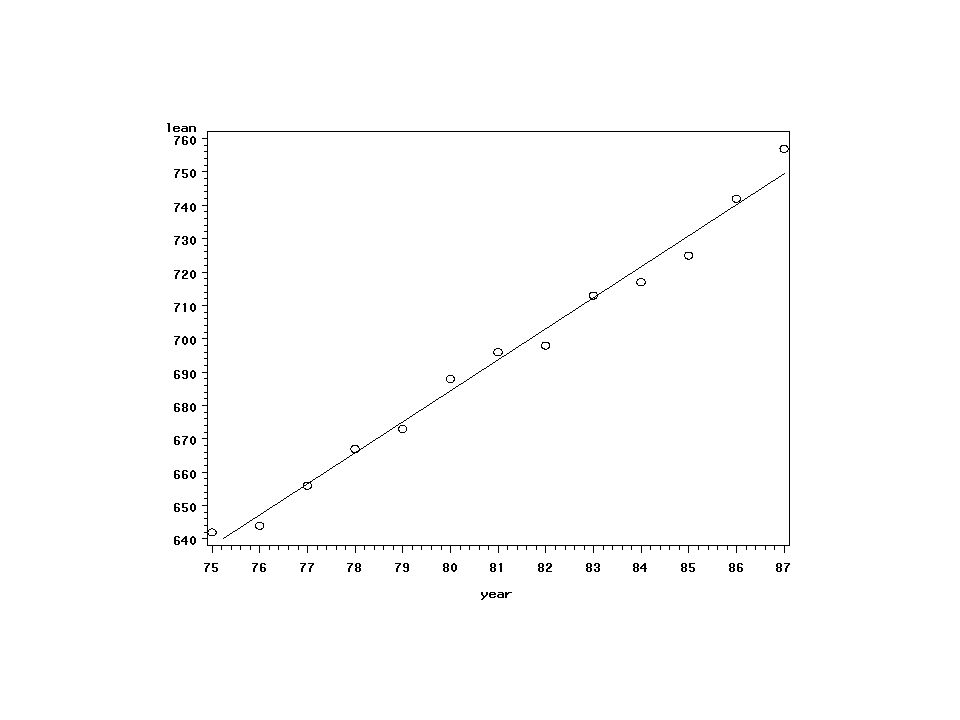
SAS Proc Reg proc reg data=a1; model lean=year/p r;
output out=a2 p=pred r=resid; id year;

11
Parameter Standard Variable DF Estimate Error INTERCEP YEAR T for H0: Parameter=0 Prob > |T|

12
Dep Var Predict Obs YEAR LEAN Value Residual
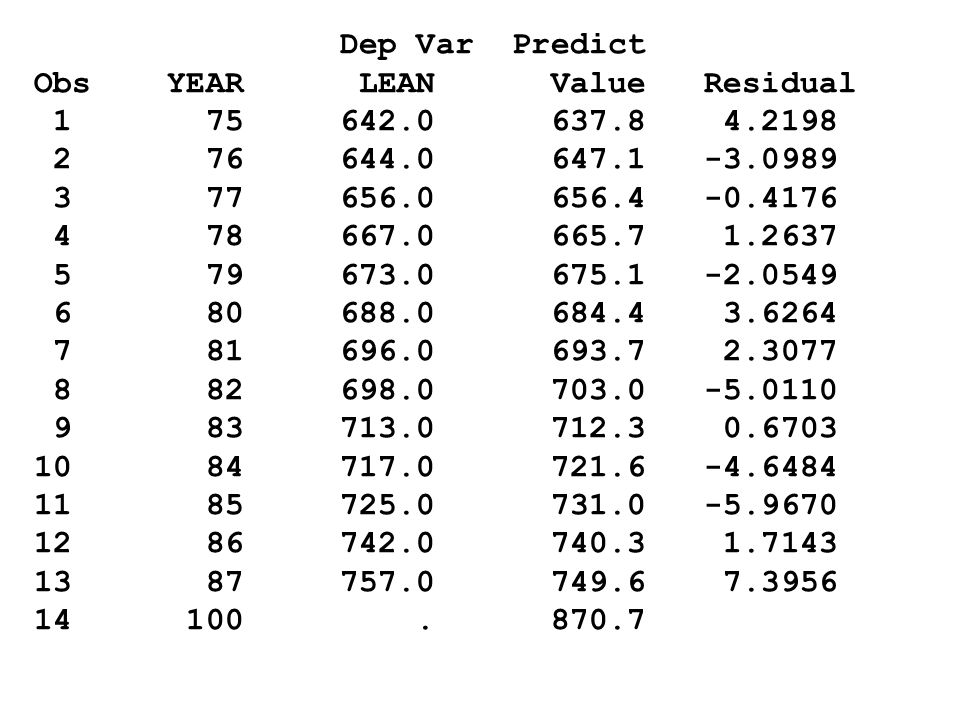
13
Struktura danych Yi zmienna odpowiedzi (zależna)
Xi zmienna wyjaśniająca dla przypadków i = 1 to n

14
Prosta regresja liniowa – model statystyczny
Yi = β0 + β1Xi + ξi Yi wartość zmiennej odpowiedzi dla itego osobnika Xi wartość zmiennej wyjaśniającej dla itego osobnika ξi zakłócenie losowe z rozkładu normalnego o średniej 0 i wariancji σ2

15
Parametry β0 – punkt przecięcia z osią Y β1 - nachylenie
σ2 - wariancja zakłócenia losowego

16
Własności modelu Yi = β0 + β1Xi + ξi E (Yi) = β0 + β1Xi
Var(Yi|Xi) = var(ξi) = σ2
 = var(ξi) = σ2.")
17
Dopasowane równanie regresji i reszty
Ŷi = b0 + b1Xi ei = Yi – Ŷi , reszta ei = Yi – (b0 + b1Xi)
")
18
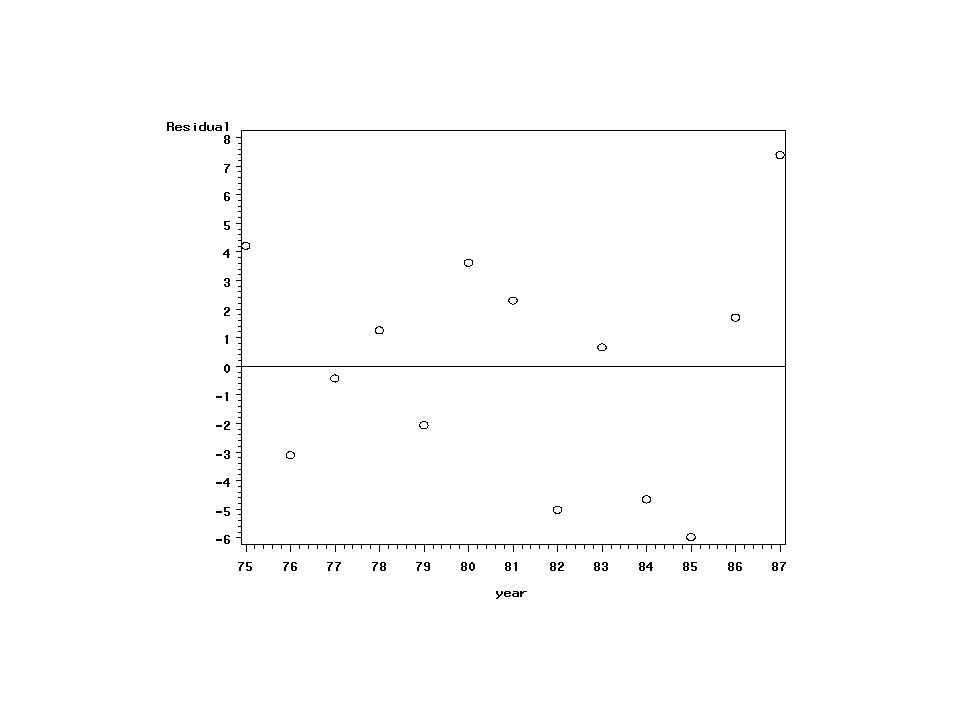
Wykres reszt proc gplot data=a2; plot resid*year; where lean ne .;
run;

20
Metoda najmniejszych kwadratów
Minimalizujemy Σ(Yi – (b0 + b1Xi) )2 =∑ei2 Liczymy pochodne względem b0 i b1 i przyrównujemy do zera
 )2 =∑ei2. Liczymy pochodne względem b0 i b1. i przyrównujemy do zera.")
21
Rozwiązanie Są to równocześnie estymatory największej wiarogodności

22
Metoda największej wiarogodności

23
Estymacja σ2

24
Parameter Standard Variable DF Estimate Error INTERCEP YEAR Sum of Mean Source DF Squares Square Model Error C Total Root MSE Dep Mean C.V

25
Teoria dotycząca estymacji β1
b1 ~ N(β1,σ2(b1)) gdzie σ2(b1)=σ2 /Σ(Xi – )2 t=(b1-β1)/s(b1) gdzie s2(b1)=s2 /Σ(Xi – )2 t ~ t(n-2)
) gdzie σ2(b1)=σ2 /Σ(Xi – )2. t=(b1-β1)/s(b1) gdzie s2(b1)=s2 /Σ(Xi – )2. t ~ t(n-2)")
26
Przedział ufności dla β1
b1 ± tcs(b1) gdzie tc = t(α/2,n-2), kwantyl rzędu (1-α/2) z rozkładu Studenta z n-2 stopniami swobody 1-α - poziom ufności
 gdzie tc = t(α/2,n-2), kwantyl rzędu. (1-α/2) z rozkładu Studenta z n-2 stopniami swobody. 1-α - poziom ufności.")
27
Test istotności dla β1 H0: β1 = 0, Ha: β1 0 t = (b1-0)/s(b1)
odrzucamy H0 gdy |t| tc, gdzie tc = t(α/2,n-2) P = Prob(|z| |t|), gdzie z~t(n-2)
 P = Prob(|z| |t|), gdzie z~t(n-2)")
28
Teoria estymacji β0 b0 ~ N(β0,σ2(b0)) gdzie σ2(b0)= t=(b0-β0)/s(b0)
w s( ), σ2 jest zastąpione przez s2 t ~ t(n-2)
, σ2 jest zastąpione przez s2. t ~ t(n-2)")
29
Przedział ufności dla β0
b0 ± tcs(b0) gdzie tc = t(α/2,n-2) 1-α - poziom ufności
 gdzie tc = t(α/2,n-2) 1-α - poziom ufności.")
30
Test istotności dla β0 H0: β0 = β00, Ha: β0 β00 t = (b0- β00)/s(b0)
odrzucamy H0 gdy |t| tc, gdzie tc= t(α/2,n-2) P = Prob(|z| |t|), gdzie z~t(n-2)
 P = Prob(|z| |t|), gdzie z~t(n-2)")
31
Uwagi (1) Normalność b0 and b1 wynika z faktu, że oba te estymatory można przedstawić w postaci liniowej kombinacji Yi, które są niezależnymi zmiennymi o rozkładzie normalnym.

32
Uwagi (2) Na mocy Centralnego Twierdzenia Granicznego, dla dostatecznie dużych rozmiarów prób, estymatory parametrów w regresji liniowej mają rozkład bliski normalnemu, nawet gdy rozkład ξi nie jest normalny. CTG zachodzi gdy wariancja błedu jest skończona. Można wtedy stosować opisane na poprzednich slajdach przedziały ufności i testy istotności.

33
Uwagi (3) Procedury testowania można zmodyfikować tak aby wykrywały alternatywy kierunkowe. Ponieważ σ2(b1)=σ2 /Σ(Xi – )2, błąd standardowy b1 można uczynić dowolnie małym zwiększając Σ(Xi – )2 .
=σ2 /Σ(Xi – )2, błąd standardowy b1 można uczynić dowolnie małym zwiększając. Σ(Xi – )2 .")
34
SAS Proc Reg proc reg data=a1; model lean=year/clb;

35
Parameter Standard Variable DF Estimate Error Intercept year t Value Pr > |t| 95% Confidence Limits <

36
Moc dla β1 (1) H0: β1 = 0, Ha: β1 0 t =b1/s(b1) tc = t(0.025,n-2)
dla α=.05 , odrzucamy H0 gdy |t| tc Potrzebujemy znaleźć P(|t| tc) dla dowolnej wartości β gdy β1 = 0, to ``moc’’ wynosi … ?
 dla dowolnej wartości β1 0. gdy β1 = 0, to ``moc’’ wynosi …")
37
Moc dla β1 (2) t~ t(n-2,δ) – niecentralny rozkład Studenta
δ= β1/ σ(b1) – parametr niecentralności Musimy założyć pewne wartości dla σ2(b1)=σ2 /Σ(Xi – )2 i n
 – parametr niecentralności. Musimy założyć pewne wartości dla. σ2(b1)=σ2 /Σ(Xi – )2 i n.")
38
Przykład obliczeń mocy β1
Załóżmy σ2=2500 , n=25 i Σ(Xi – )2 =19800 Tak więc mamy σ2(b1)=σ2 /Σ(Xi – )2=
2 = Tak więc mamy σ2(b1)=σ2 /Σ(Xi – )2=")
39
Przykładowe obliczenia mocy (2)
Rozważmy β1 = 1.5 Możemy teraz obliczyć δ= β1/ σ(b1) t~ t(n-2,δ), chcemy znaleźć P(|t| tc) Użyjemy funkcji SAS-a która oblicza dystrybuantę niecentralnego rozkładu Studenta.
 t~ t(n-2,δ), chcemy znaleźć P(|t| tc) Użyjemy funkcji SAS-a która oblicza dystrybuantę niecentralnego rozkładu Studenta.")
40
data a1; n=25; sig2=2500; ssx=19800; alpha=.05; sig2b1=sig2/ssx; df=n-2; beta1=1.5; delta=beta1/sqrt(sig2b1); tc=tinv(1-alpha/2,df); power=1-probt(tc,df,delta) +probt(-tc,df,delta); output; proc print data=a1; run;
; power=1-probt(tc,df,delta) +probt(-tc,df,delta); output; proc print data=a1; run;")
41
Obs n sig2 ssx alpha sig2b1 df beta1 delta tc power

42
data a2; n=25; sig2=2500; ssx=19800; alpha=.05; sig2b1=sig2/ssx; df=n-2; tc=tinv(1-alpha/2,df); do beta1=-2.0 to 2.0 by .05; delta=beta1/sqrt(sig2b1); power=1-probt(tc,df,delta) +probt(-tc,df,delta); output; end;
; power=1-probt(tc,df,delta) +probt(-tc,df,delta); output; end;")
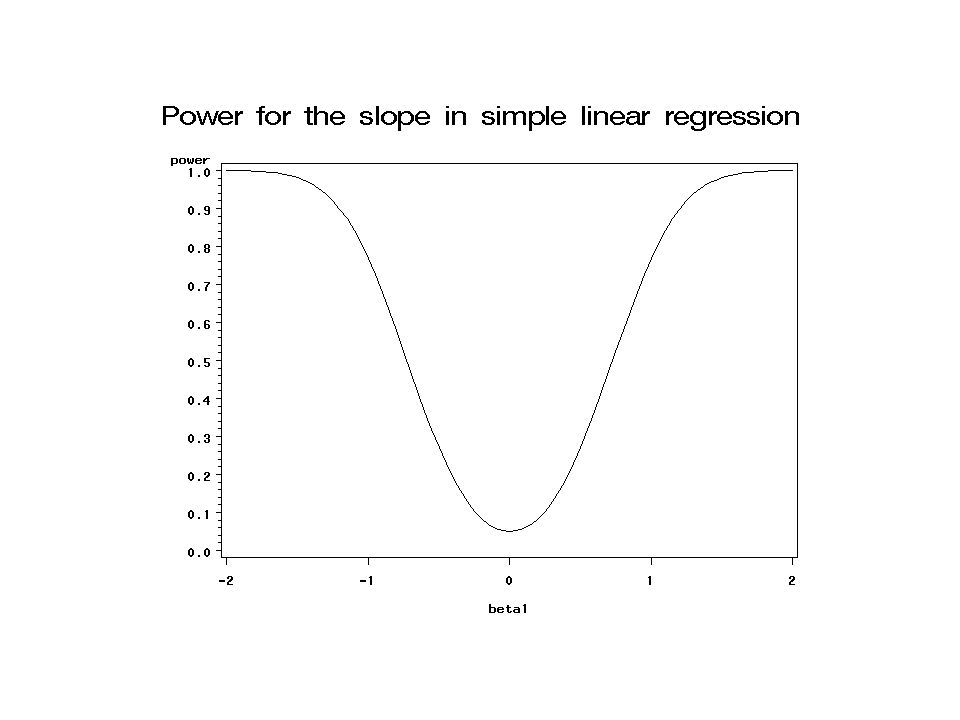
43
title1 'Power for the slope in
simple linear regression'; symbol1 v=none i=join; proc gplot data=a2; plot power*beta1; proc print data=a2; run;

Podobne prezentacje






>")




 zmiennej>")







