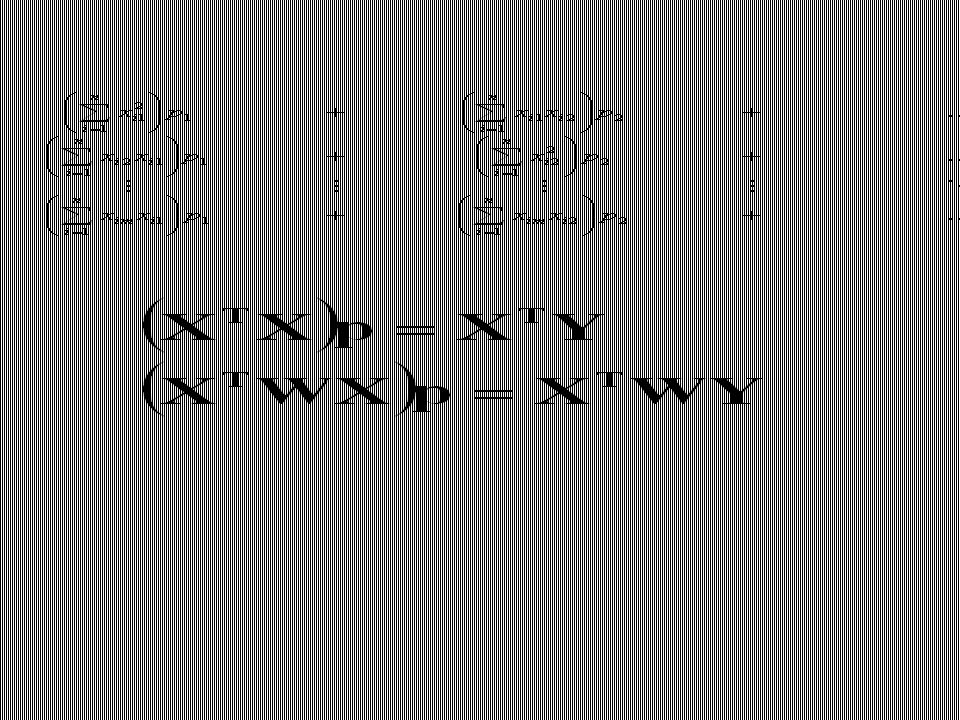Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Regresja liniowa Dany jest układ punktów
x x – zmienna objaśniająca (nie obarczona błędem) y – zmienna zależna (obarczona błędem) Naszym zadaniem jest poprowadzenie „najlepszej” prostej przez te punkty.
 y – zmienna zależna (obarczona błędem) Naszym zadaniem jest poprowadzenie „najlepszej prostej przez te punkty.")
2
Wyznaczanie optymalnych parametrów a i b

3
Bardziej ogólny przypadek dopasowywania równania prostej: regresja ważona

4
Ocena istotności równania regresji
Weryfikujemy następującą hipotezę zerową: H0 : a = wobec H1 : a ≠ 0 (jeżeli a = 0 “w granicach błędu” to nie można mówić o regresji) Przy prawdziwości H0 statystyka: ma rozkład t Studenta z liczbą stopni swobody równej n - 2.
 Przy prawdziwości H0 statystyka: ma rozkład t Studenta z liczbą stopni swobody równej n - 2.")
5
Z tablic rozkładu Studenta odczytujemy, dla wcześniej przyjętego poziomu istotności , wartość krytyczną tn-2,. Jeżeli obliczona wartość t znajduje w dwustronnym obszarze krytycznym (-, - tn-2,), (tn-2,, +), to H0 należy odrzucić na korzyść hipotezy H1
, (tn-2,, +), to H0 należy odrzucić na korzyść hipotezy H1.")
6
2. Zbadanie istotności różnicy pomiędzy różnicą wariancji odpowiadającą wprowadzeniu członu liniowego (ma ona 1 stopień swobody) a wariancją resztową z modelu liniowego (ma ona 2 stopnie swobody) przy pomocy testu F(1,n-2).
 a wariancją resztową z modelu liniowego (ma ona 2 stopnie swobody) przy pomocy testu F(1,n-2)..")
7
3. Można też przeprowadzić analizę współczynnika korelacji lub jego kwadratu (współczynnika determinacji).
..")
8
Trochę żonglerki sumami

9
W ten sposób mamy wzór na współczynnik korelacji przenaszalny na regresję wielokrotną a przy okazji potrafimy wyrazić F przez współczynnik korelacji Dla dociekliwych: udowodnić tożsamość

10
Linearyzacja Mamy dopasować funkcję nieliniową y=f(x,y;a.b)
Przekształcamy funkcję do takiej postaci aby uzyskać postać zlinearyzowaną y=ax+b Gdzie y jest nową zmienną zależną, x nową zmienną objaśniającą a a i b są nowymi parametrami, przy czym ogólnie x=x(x,y), y=y(x,y), a=a(a,b), b=b(a,b)
, y=y(x,y), a=a(a,b), b=b(a,b)")
11
Przykład problemu nieliniowego linearyzowalnego: kinetyka reakcji pierwszego rzędu

12
Jeżeli chcemy postępować poprawnie to należy wykonać regresję ważoną, wyliczając wagi poszczególnych przekształconych zmiennych objaśniających zgodnie z rachunkiem błędów. W poprzednim przykładzie

13
Inne przykłady linearyzacji:
Równanie Michalisa-Mentena Równanie Hilla

14
Obie zmienne są obarczone porównywalnym błędem
Sposób: regresja ortogonalna sy sx y x Poprawiona wartość wagi zależy od a, które jest parametrem regresji. Problem liniowy przekształca się w nieliniowy. Problem można obejść przeprowadzając najpierw “zwykłą” regresję i wyznaczyć przybliżone a, następnie wstawić a do wzoru na wagi i przeprowadzić regresję jeszcze raz.

15
Regresja uogólniona albo analiza konfluentna
(x,y) x y (x*,y*)
 x. y. (x*,y*)")
16
Przykład problemu nieliniowego nielinearyzowalngo: kinetyka reakcji pierwszego rzędu z produktem przejściowym

17
Parę słów o macierzach Macierz m´n: tablica m na n (m wierszy n kolumn) liczb (np. tabliczka mnożenia). Macierz kwadradowa: m=n Macierz symetryczna (zawsze kwadratowa): aij=aji Macierz transponowana AT: (AT)ij=aji Macierz nieosobliwa: macierz o niezerowym wyznaczniku. Macierz dodatnio określona: xTAx>0 dla każdego niezerowego wektora x. Norma euklidesowa macierzy: Norma spektralna macierzy Wskaźnik uwarunkowania macierzy
: aij=aji. Macierz transponowana AT: (AT)ij=aji. Macierz nieosobliwa: macierz o niezerowym wyznaczniku. Macierz dodatnio określona: xTAx>0 dla każdego niezerowego wektora x. Norma euklidesowa macierzy: Norma spektralna macierzy. Wskaźnik uwarunkowania macierzy.")
18
Regresja liniowa wielokrotna
Zmienne objaśniające x1,x2,…,xm nie muszą odpowiadać różnym wielkościom lecz mogą być funkcjami tej samej wielkości mierzonej (np. jej kolejnymi potęgami w przypadku dopasowywania wielomianów). Tak więc możemy tu mówić o ugólnym dopasowywaniu krzywych, które można przedstawić jako liniowe funkcje parametrów lub ich kombinacji.
. Tak więc możemy tu mówić o ugólnym dopasowywaniu krzywych, które można przedstawić jako liniowe funkcje parametrów lub ich kombinacji.")
19
Podobnie jak w przypadku “zwykłej” regresji minimalizujemy następujące sumy kwadratów odchyleń:
regresja nieważona regresja ważona

20
Przypadek szczególny: dopasowywanie wielomianu

22
Macierz wariancji-kowariancji parametrów:
Wariancja resztowa: Macierz wariancji-kowariancji parametrów: Regresja nieważona Regresja ważona Odchylenia standardowe poszczególnych parametrów: Regresja nieważona Regresja ważona

23
Macierz wariancji-kowariancji (dyspersji) parametrów
Macierz współczynników korelacji parametrów

24
Wyprowadzenie

25
Test F dla istotności efektu liniowego
Test F dla istotności włączenia nowych parmetrów m2>m1 F(m2,m1) porównujemy z wartością krytyczną Fa,m1-m2,n-m2 dla poziomu istotności a. F porównujemy z wartością krytyczną Fa,m-1,n-m Współczynnik determinacji i jego związek z F
 porównujemy z wartością krytyczną Fa,m1-m2,n-m2. dla poziomu istotności a. F porównujemy z wartością krytyczną Fa,m-1,n-m. Współczynnik determinacji i jego związek z F.")
26
Ocena istotności danego parametru
Weryfikujemy następującą hipotezę zerową: H0 : pi = wobec H1 : a ≠ 0 (jeżeli a = 0 “w granicach błędu” to nie można mówić o regresji) Przy prawdziwości H0 statystyka: ma rozkład t Studenta z liczbą stopni swobody równej n - m.
 Przy prawdziwości H0 statystyka: ma rozkład t Studenta z liczbą stopni swobody równej n - m.")
27
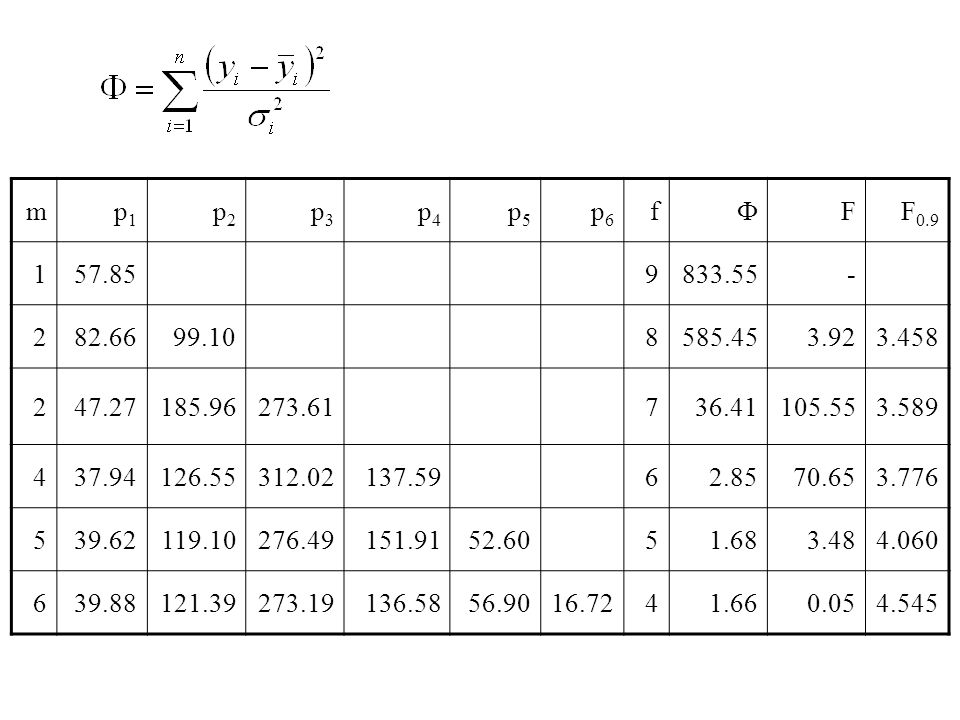
Przykład dopasowywania wielomianu: rozkład cosinusa kąta rozpraszania mezonów K z protonami (zakładamy że sj=sqrt(yj). j tj=cos(Qj) yj 1 -0.9 81 2 -0.7 50 3 -0.5 35 4 -0.3 27 5 -0.1 26 6 0.1 60 7 0.3 106 8 0.5 189 9 0.7 318 10 0.9 520
 yj")
28
m p1 p2 p3 p4 p5 p6 f F F0.9 1 57.85 9 833.55 - 2 82.66 99.10 8 585.45 3.92 3.458 47.27 185.96 273.61 7 36.41 105.55 3.589 4 37.94 126.55 312.02 137.59 6 2.85 70.65 3.776 5 39.62 119.10 276.49 151.91 52.60 1.68 3.48 4.060 39.88 121.39 273.19 136.58 56.90 16.72 1.66 0.05 4.545
29
Przykład zastosowania regresji wielokrotnej w analizie QSAR
(Leow et al., Bioorganic & Medicinal Chemistry Letters, 17(4), , 2007) IC50 – stężenie związku potrzebne do połówkowej inhibicji ludzkiej metylotransferazy izopropenylocysteinowej. pIC50=-log(IC50) PSA – powierzchnia grup polarnych [A2] PV – objętość grup polarnych [A3] PB1 – parametr steryczny podstawionej grupy fenylowej pPh2 – lipofilowość podstawionego pierścienia fenylowego
, , 2007) IC50 – stężenie związku potrzebne do połówkowej inhibicji ludzkiej metylotransferazy izopropenylocysteinowej. pIC50=-log(IC50) PSA – powierzchnia grup polarnych [A2] PV – objętość grup polarnych [A3] PB1 – parametr steryczny podstawionej grupy fenylowej. pPh2 – lipofilowość podstawionego pierścienia fenylowego.")
30
Metody rozwiązywania układów równań liniowych

31
Metody skończone: Metoda Gaussa Metoda Gaussa-Jordana Metody Choleskiego Metoda Householdera Metoda sprzężonych gradientów Metody iteracyjne dla dużych układów równań: Metoda Jacobiego Metoda Gaussa-Seidla

32
Metoda eliminacji Gaussa z wyborem elementu głównego w kolumnie
Układ równań sprowadzamy do postaci trójkątnej Układ z macierzą trójkątną można następnie łatwo rozwiązać zaczynając od obliczenia wartości xn z n-tego równania, następnie wstawić xn do równania n-1 i wyliczyć z niego xn-1, następnie wstawić xn oraz xn-1 do równania n-2 i wyliczyć xn-2 aż do dotarcia do równania pierwszego i wyznaczenia x1.

33
Wybieramy równanie i takie, że |ai1| jest największym elementem w pierwszej kolumnie po czym przestawiamy i-te równanie na początek i eliminujemy x1 z równań od 2 do n. Procedurę powtarzamy z macierzą A(1) o rozmiarach (n-1)x(n-1) i wektorem b(1) o rozmiarze n-1, eliminując z nich drugą zmienną i otrzymując macierz A(2) o rozmiarach (n-2)x(n-2) i wektor b(2) o rozmiarze n-2. W ten sam sposób postępujemy z kolejnymi macierzami A(2), A(3),..., A(n-1) oraz wektorami b(2), b(3),..., b(n-1).
 o rozmiarach (n-1)x(n-1) i wektorem b(1) o rozmiarze n-1, eliminując z nich drugą zmienną i otrzymując macierz A(2) o rozmiarach (n-2)x(n-2) i wektor b(2) o rozmiarze n-2. W ten sam sposób postępujemy z kolejnymi macierzami A(2), A(3),..., A(n-1) oraz wektorami b(2), b(3),..., b(n-1).")
34
Dla j-tego kroku Po zakończeniu operacji otrzymujemy układ równań z macierzą trójkątną p jest liczbą przestawień wierszy macierzy A podczas sprowadzania układu równań do postaci trójkątnej.

35
Z otrzymanego układu równań z macierzą trójkątną wyznaczamy po kolei xn, xn-1,..., x1.
Wysiłek obliczeniowy (liczba mnożeń i dzieleń) w metodzie eliminacji Gaussa: Faktoryzacja macierzy A: n(n2-1)/3 operacji Przekształcenie wektora b: n(n-1)/2 operacji Obliczenie x: n(n+1)/2 operacji. Razem: n3/3+n2-n/3≈n3/3 operacji. Kod źródłowy metody eliminacji Gaussa.
 w metodzie eliminacji Gaussa: Faktoryzacja macierzy A: n(n2-1)/3 operacji. Przekształcenie wektora b: n(n-1)/2 operacji. Obliczenie x: n(n+1)/2 operacji. Razem: n3/3+n2-n/3≈n3/3 operacji. Kod źródłowy metody eliminacji Gaussa.")
36
Metody typu Choleskiego dla macierzy symetrycznych silnie nieosobliwych
LT D L L klasyczna metoda Choleskiego tylko dla macierzy dodatnio określonych.

37
Postępowanie przy rozwiązywaniu układów równań metodą faktoryzacji Choleskiego.
Wyznaczenie faktorów L i D. Układ przyjmuje postać LDLTx=b 2. Obliczenie pomocniczego wektora w. w=L-1b przez rozwiązanie układu równań Lw=b. Ponieważ L jest macierzą trójkątną dolną układ ten rozwiązuje się wyliczając kolejno w1, w2,…, wn podobnie jak w koncowym etapie eliminacji Gaussa. 3. Obliczenie z=D-1w (D jest macierzą diagonalną więc po prostu dzielimy wi przez dii. Ten etap nie występuje w klasycznej metodzie Choleskiego. 4. Obliczenie x poprzez rozwiązanie układu równań z macierzą trójkątną górną LTx=z Ten etap jest identyczny z ostatnim etapem metody eliminacji Gaussa. Metoda wymaga ok. n3/6 operacji (2 razy mniej niż metoda eliminacji Gaussa). Uwaga: klasyczna metoda Choleskiego wymaga ponadto n pierwiastkowań.
. Uwaga: klasyczna metoda Choleskiego wymaga ponadto n pierwiastkowań.")
38
Klasyczna faktoryzacja Choleskiego (A=LLT)
")
39
Faktoryzacja “bezpierwiastkowa” kod źródłowy

Podobne prezentacje