Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Neuro-komputery Ryszard Tadeusiewicz

2
Współczesne komputery są coraz większe i coraz doskonalsze
Cyfronet AGH Superkomputer SGI 2800 „Grizzly”

3
Wciąż jednak nawet najdoskonalsze z posiadanych przez nas komputerów daleko ustępują niewielkiemu narządowi, który każdy posiada, a niektórzy nawet używają...

4
Nic dziwnego, że chcąc doskonalić systemy informatyczne zaczynamy obecnie coraz odważniej budować maszyny wzorowane na budowie i działaniu ludzkiego mózgu

5
Współcześnie budowane neurokomputery noszą zwykle nazwę Sieci Neuronowych i pod taką nazwą będą w tym referacie przedstawiane.

7
Sieci neuronowe są narzędziem którego zakres zastosowań stale się poszerza. Należą do tego zakresu między innymi takie zadania, jak: Tworzenie modeli złożonych systemów Automatyczne metody przetwarzania, analizy i klasyfikacji złożonych sygnałów Predykacja szeregów czasowych i liczne, liczne inne...

8
Modele statystyczne Systemy ekspertowe Metody dedukcyjne
Cechy charakterystyczne zadań, przy rozwiązywaniu których sieci neuronowe mają przewagę nad innymi technikami: Częściowy lub całkowity brak znajomości reguł Duża złożoność Modele statystyczne Systemy ekspertowe Metody dedukcyjne Częściowa znajomość reguł Mała i średnia złożoność Dokładne algorytmy Nieznajomość reguł rządzących problemem Sieci neuronowe Metody indukcyjne Pełna znajomość reguł Mała i średnia złożoność Stopień złożoności problemu

9
Zasadnicze zalety, warunkujące używanie sieci neuronowych są następujące:
Możliwość rozwiązywania problemów niezbyt dobrze sformułowanych formalnie Możliwość zastępowania procesu „ręcznego” tworzenia modelu procesem uczenia sieci Brak konieczności jawnego formułowania założeń dla modeli Możliwość pracy współbieżnej

10
Zalety te mogą być wykorzystane jedynie wtedy, gdy typ sieci zostanie właściwie dopasowany do charakteru rozwiązywanego zadania

11
Omówimy teraz elementy, determinujące różne dostępne typy sieci neuronowych

12
Sieci neuronowe są wzorowane na faktach, które udało się ustalić w trakcie wieloletnich badań ludzkiego mózgu

13
Nagrody Nobla związane z badaniami układu nerwowego, których wyniki wykorzystano w sieciach neuronowych: Pavlov I.P. - teoria odruchów warunkowych Golgi C., - badanie struktury układu nerwowego Ramón Y Cajal S. - odkrycie, że mózg składa się z sieci oddzielnych neuronów Krogh S.A. - opisanie funkcji regulacyjnych w organizmie 1932 – Sherrington Ch. S. - badania sterowania nerwowego pracy mięśni 1936 – Dale H., Hallett L.O. - odkrycie chemicznej transmisji impulsów nerwowych Erlanger J., Gasser H. S. - procesy w pojedynczym włóknie nerwowym Hess W.R. - odkrycie funkcji śródmózgowia Eccles J.C., Hodgkin A.L., Huxley A.F. - mechanizm elektrycznej aktywności neuronu 1969 – Granit R., Hartline H.K., Wald G. – fizjologia widzenia 1970 – Katz B., Von Euler U., Axelrod J. - transmisja informacji humoralnej w komórkach nerwowych 1974 – Claude A., De Duve Ch., Palade G. - badania strukturalnej i funkcjonalnej organizacji komórki. 1977 – Guillemin R., Schally A., Yalow R. - badania hormonów mózgu 1981 – Sperry R. - odkrycia dotyczące funkcjonalnej specjalizacji półkul móżdżku 1981 – Hubel D.H., Wiesel T. - odkrycie zasad przetwarzania informacji w systemie wzrokowym 1991 – Neher E., Sakmann B. - funkcje kanałów jonowych w komórkach nerwowych

14
Dzięki wieloletnim badaniom anatomia i fizjologia mózgu jest dzisiaj doskonale znana

15
Badania te na początku pozwoliły jedynie na ustalenie lokalizacji najbardziej podstawowych funkcji mózgu

16
Towarzyszyły temu mniej lub bardziej uzasadnione spekulacje na temat zadań, jakie pełnia poszczególne struktury mózgowe

17
Doskonalenie technik analizy działania mózgu pozwoliło na dokładniejsze określenie tego, w jaki sposób on działa

18
Dokładniejsze badania pozwoliły zidentyfikować i zlokalizować podstawowe funkcje mózgu

19
Zasadnicze funkcje mózgu bada się obecnie głównie przy użyciu techniki PET, która bez mała umożliwia „podglądanie myśli” podglądanie myśli Co ciekawe – technika ta pozwala wykryć i opisać nawet tak subtelne zmiany, jakie wywołuje w mózgu np. romantyczna miłość

20
Przy użyciu tej techniki można prześledzić nawet zakłopotanie, jakie sprawiają w trakcie percepcji tak zwane obrazy dwuznaczne

21
Przykład obrazu dwuznacznego, będącego źródłem konfuzji objawiającej się także w aktywności mózgu

22
Współczesne techniki analityczne pozwoliły sięgnąć nawet w najgłębsze zakamarki mózgu

23
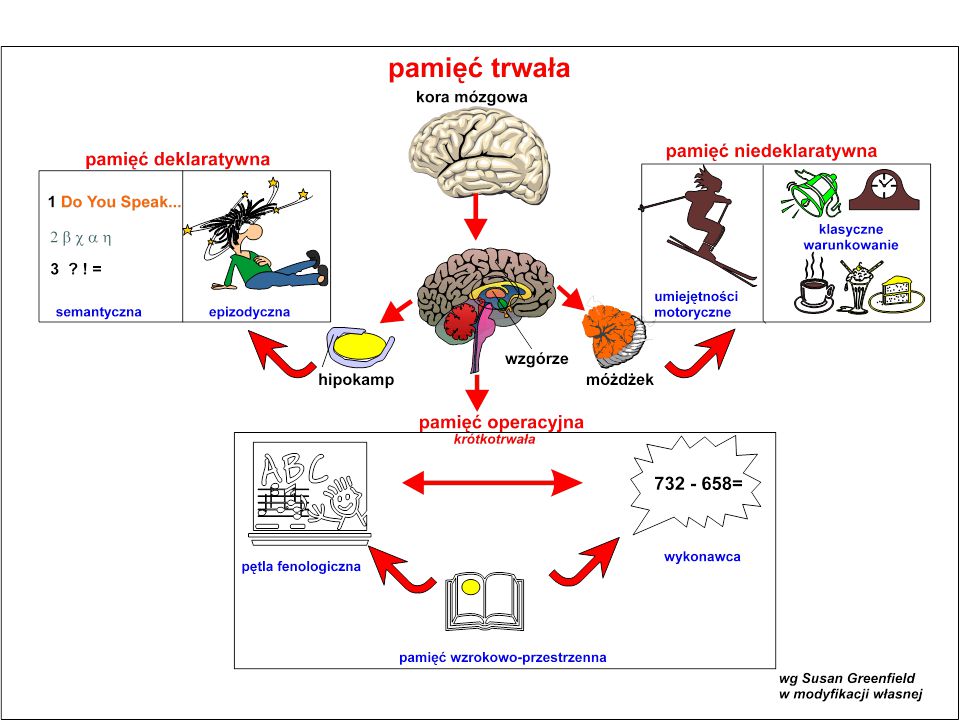
Wzajemne relacje pomiędzy różnymi systemami neurocybernetycznymi

24
Jak wynikało z poprzedniego slajdu istnieją różne techniczne realizacje sieci neuronowych, najczęściej jednak stosowana jest symulacja z wykorzystaniem typowych komputerów i specjalnego oprogramowania.

25
Przykład programu symulującego sieci neuronowe

26
Sztuczna sieć neuronowa, podobnie jak sieci rzeczywiste, zbudowana jest z neuronów

27
Komórka nerwowa ma wyraźnie zdefiniowany kierunek przepływu sygnałów, co pozwala wyróżnić jej wejścia (jest ich wiele) oraz wyjście.
 oraz wyjście.")
28
Elementy, z których buduje się neuronowy model

29
Budowa wiernego modelu nawet pojedynczego neuronu (komórki Purkinjego) jest bardzo kosztowna (de Schutter’05) Do zbudowania modelu użyto: 1600 kompartmentów 8021 modeli kanałów jonowych 10 typów różnych złożonych opisów matematycznych kanałów zależnych od napięcia 32000 równań różniczkowych! 19200 parametrów do oszacowania przy dostrajaniu modelu Opisu morfologii zrekonstruowanej za pomocą mikroskopu

30
Obrazy wyników symulacji komputerowej modelu komórki Purkinjego uzyskane w badaniach de Schuttera:
u góry aktywność elektryczna symulowanej komórki, u dołu zjawiska biochemiczne (przepływ jonów wapnia

31
Komórki nerwowe zwykle mają typowy rozgałęziony kształt, z dobrze wyróżnionym drzewkiem dendrytów i z aksonem dającym odgałęzienia do następnych neuronów

32
Najczęściej da się wtedy wyraźnie wyróżnić obszar wejściowych i wyjściowych połączeń komórki

33
Chociaż nie jest to wcale regułą

34
Innym razem liczne rozgałęzienia na aksonie zacierają różnicę między drzewem wejść, a gwiazdą wyjść

35
Zwykle jednak można wyraźnie wskazać skąd i dokąd przepływają sygnały

36
Zwykle na wejściu neuron zbiera informacje z raczej małego obszaru poprzedniej warstwy sieci, natomiast rozsyła swój sygnał do większej liczby neuronów kolejnej warstwy

37
Od reguły tej są jednak wyjątki

38
Niekiedy neurony są zaskakująco mało rozgałęzione

39
Innym razem rozgałęzień jest bardzo dużo

40
Czasem rozgałęzienia wyraźnie „szukają” swojego docelowego połączenia na wejściu...

41
... lub na wyjściu.

42
Czasem cała struktura komórki ma wyraźnie kierunkowy charakter

43
Bywają komórki o takiej budowie, że trudno orzec, gdzie jest ich wejście, a gdzie wyjście

44
Najciekawsze procesy toczą się na złączach pomiędzy neuronami

45
agregacja danych wejściowych obliczenie wartości funkcji aktywacji
Neuron - podstawowy element sieci w1 x1 Zadania ??? w2 y x2 Jak zróżnicować te sygnały? wn xn agregacja danych wejściowych obliczenie wartości funkcji aktywacji

46
Przy stosowaniu sieci neuronowych zasadnicze korzyści odnosi się z procesów uczenia zachodzących w obrębie tak zwanych synaps.

47
Pojęcie „wagi” synaptycznej jest w sztucznym neuronie bardzo uproszczone, podczas gdy w rzeczywistych komórkach odpowiada mu dosyć skomplikowana struktura anatomiczna i bardzo złożone procesy elektrochemiczne

48
Własności neuronu determinują: przyjęta agregacja danych wejściowych oraz założona funkcja wyjścia
neuron nieliniowy Agregacja liniowa neuron liniowy w1 x1 w2 y x2 y = s ... wn xn Agregacja radialna

49
W przypadku neuronu liniowego jego zachowanie daje się łatwo zinterpretować

50
W przypadku neuronu nieliniowego nie jest tak łatwo, ponieważ zagregowany (w taki lub inny sposób) sygnał wejściowy może być przetworzony przy użyciu funkcji nieliniowej o teoretycznie dowolnym kształcie.
 sygnał wejściowy może być przetworzony przy użyciu funkcji nieliniowej o teoretycznie dowolnym kształcie.")
51
Funkcje aktywacji neuronu może być dowolna, ale najczęściej stosowane są niżej podane kształty.

52
Nieliniowe funkcje aktywacji też bywają różne:

53
Dobierając współczynniki wagowe wejść neuronu można wpływać na kształt jego nieliniowej charakterystyki!

54
Taka forma funkcji aktywacji neuronu powoduje, że w przestrzeni sygnałów wejściowych zachowanie neuronu opisuje tak zwane „urwisko sigmoidalne”

55
Odmiennie działającym elementem używanym w niektórych typach jest tzw
Odmiennie działającym elementem używanym w niektórych typach jest tzw. neuron radialny (RBF) Agregacja sygnałów wejściowych w tym typie neuronu polega na obliczaniu odległości pomiędzy obecnym wektorem wejściowym X a ustalonym podczas uczenia centroidem pewnego podzbioru T Również nieliniowa funkcja przejścia w tych neuronach ma odmienną formę - „dzwonu” gaussoidy - czyli jest funkcją niemonotoniczną.
 Agregacja sygnałów wejściowych w tym typie neuronu polega na obliczaniu odległości pomiędzy obecnym wektorem wejściowym X a ustalonym podczas uczenia centroidem pewnego podzbioru T. Również nieliniowa funkcja przejścia w tych neuronach ma odmienną formę - „dzwonu gaussoidy - czyli jest funkcją niemonotoniczną.")
56
Sztuczny neuron jest więc w sumie dosyć prostą strukturą, dzięki czemu stosunkowo łatwo jest stworzyć sieć takich elementów

57
Przy budowie sztucznych sieci neuronowych najczęściej przyjmuje się, że ich budowa jest złożona z warstw, podobnie jak na przykład struktury neuronowe zlokalizowane w siatkówce oka

58
Trzeba jednak dodać, że sieci neuronowe w mózgu miewają też znacznie bardziej skomplikowaną strukturę

59
Przykład: schemat móżdżku

60
Zajmiemy się sieciami o niezbyt złożonej strukturze, bo ilość połączeń w dużej sieci neuronowej jest tak duża, że ich pełna prezentacja jest praktycznie nieczytelna

61
W dodatku duże sieci często mają strukturę trójwymiarową

62
Schemat sztucznej sieci neuronowej (uproszczonej)
Warstwa ukryta (jedna lub dwie) Warstwa wejściowa Warstwa wyjściowa Działanie sieci zależy od: przyjętego modelu neuronu, topologii (struktury) sieci, wartości parametrów neuronu, ustalanych w wyniku uczenia
 Warstwa wejściowa. Warstwa wyjściowa. Działanie sieci zależy od: przyjętego modelu neuronu, topologii (struktury) sieci, wartości parametrów neuronu, ustalanych w wyniku uczenia.")
63
Najbardziej typowa struktura: sieć MLP
Podstawowe właściwości: wiele wejść i wiele wyjść jedna (rzadziej dwie) warstwy ukryte nieliniowe charakterystyki neuronów ukrytych w formie sigmoid W warstwie wyjściowej neurony mogą być liniowe lub także mogą mieć charakterystyki sigmoidalne Uczenie najczęściej przeprowadzane metodą wstecznej propagacji błędów
 warstwy ukryte. nieliniowe charakterystyki neuronów ukrytych w formie sigmoid. W warstwie wyjściowej neurony mogą być liniowe lub także mogą mieć charakterystyki sigmoidalne. Uczenie najczęściej przeprowadzane metodą wstecznej propagacji błędów.")
64
A tak wygląda struktura innej praktycznie użytecznej sieci klasy GRNN
warstwa radialna każdy z neuronów reprezentuje skupienie występujące w danych warstwa wejściowa służy do wprowadzania danych do sieci warstwa regresyjna wyznacza elementy niezbędne do obliczenia wartości wyjściowej warstwa wyjściowa wyznacza odpowiedź sieci

65
Idea działania sieci realizujących regresję uogólnioną (GRNN -Generalized Regression Neural Network)
Wejściowe wektory uczące dzielone są na skupienia - w szczególnym przypadku każdy wektor tworzy oddzielne skupienie, Dla każdego skupienia znana jest wartość zmiennej objaśnianej, wartość zmiennej objaśnianej dla dowolnego wektora wejściowego szacowana jest jako średnia ważona z wartości tej zmiennej dla skupień - wagi uzależnione są od odległości od skupień.

66
Określenie wag neuronów radialnych metodą K-średnich
Elementy zbioru uczącego dzielone są na grupy elementów podobnych (metodą k-średnich). W charakterze wag stosowane są środki ciężkości każdej wyróżnionej grupy.
. W charakterze wag stosowane są środki ciężkości każdej wyróżnionej grupy.")
67
Możliwości zastosowań sieci: opis zależności regresyjnych
Y=NN(X1, X2, ..., XN) Y - zmienna ciągła Xi - zmienne ciągłe lub dyskretne powierzchnia, garaż, wiek, ogrzewanie, położenie, piętro, .... Cena rynkowa Przykład: Wycena mieszkań
 Y - zmienna ciągła. Xi - zmienne ciągłe lub dyskretne. powierzchnia, garaż, wiek, ogrzewanie, położenie, piętro, .... Cena rynkowa. Przykład: Wycena mieszkań.")
68
Przy modelowaniu dowolnego systemu za pomocą sieci używa się metodologii „czarnej skrzynki”

69
Działanie modelu regresyjnego wytworzonego za pomocą sieci

70
Możliwości zastosowań sieci: klasyfikacja wzorcowa
? Y=NN(X1, X2, ..., XN) Y - zmienna dyskretna Xi - zmienne ciągłe lub dyskretne ? dochody, zabezpieczenie, wiek, stan cywilny, oszczędności, zatrudnienie .... przyznać czy nie przyznać ? Przykład: Udzielanie kredytu
 Y - zmienna dyskretna. Xi - zmienne ciągłe lub dyskretne. dochody, zabezpieczenie, wiek, stan cywilny, oszczędności, zatrudnienie przyznać. czy. nie przyznać Przykład: Udzielanie kredytu.")
71
Przykład klasyfikacji binarnej

72
Istota procesu uczenia sieci przy klasyfikacji binarnej (dychotomii) polega na tym, żeby rozgraniczyć w przestrzeni sygnałów odpowiednie obszary
 polega na tym, żeby rozgraniczyć w przestrzeni sygnałów odpowiednie obszary")
73
Przykład klasyfikacji wieloklasowej

74
Możliwości zastosowań sieci: prognozowanie szeregów czasowych
Yt+1=NN(Yt, Yt-1,..., Yt-k, Xt, ..., Xt-1) $/Zł(t) $/Zł(t-1) DM/Zł(t) WIG(t) WIG(t-1) .... $/Zł (t+1) Przykład: Prognoza kursu waluty
 $/Zł(t) $/Zł(t-1) DM/Zł(t) WIG(t) WIG(t-1) .... $/Zł (t+1) Przykład: Prognoza kursu waluty.")
75
Przykładowa struktura sieci przewidującej przyszłe wartości wskaźnika WIG
Y(t) Y(t-1) Y(t-2) ... Y(t-k) Y(t+1)
 Y(t-1) Y(t-2) ... Y(t-k) Y(t+1)")
76
Możliwości zastosowań sieci: klasyfikacja bezwzorcowa
Badanie struktury zbioru obiektów Dane charakte- ryzujące obiekty (kraje Europy)
")
77
Wynik automatycznego grupowania danych
Struktura wzajemnego podobieństwa krajów Unii Europejskiej

78
Rozwiązywanie problemów przy pomocy sieci neuronowej
identyfikacja problemu; wybór typu sieci neuronowej (liniowa, MLP, RBF, PNN, GRNN, Kohonena); określenie struktury sieci (liczba warstw, liczba neuronów w warstwach); uczenie sieci (określenie wartości parametrów neuronów).
; określenie struktury sieci (liczba warstw, liczba neuronów w warstwach); uczenie sieci (określenie wartości parametrów neuronów).")
79
Uczenie sieci neuronowej
uczenie jest to w istocie iteracyjny proces estymacji optymalnych wartości parametrów sieci; początkowe wartości tych parametrów są zwykle wartościami losowymi; w trakcie uczenia sieci neuronowej prezentowane są przypadki uczące i w zależności od oceny reakcji sieci modyfikowane są jej parametry (najczęściej wagi synaptyczne).
. ")
81
Na procesy pamięciowe duży wpływ mają zapewne receptory NMDA, spotykane w strukturach hipokampa aktywowane przez kwas N-metylo-D-asparaginowy

82
Mechanizmy biochemiczne zaangażowane w proces zapamiętywania wiedzy są raczej skomplikowane

83
Dla uczenia sztucznych sieci neuronowych cała ta skomplikowana wiedza biochemiczna nie jest konieczna, bo praktyczne metody uczenia sieci oparte są na prostej intuicji: poszukiwania minimum funkcji błędu

84
Algorytm wstecznej propagacji błędów polega na szukaniu kierunku spadku E i na takim zmienianiu wartości wag w1, w2, żeby zmniejszać wartość funkcji błędu w kierunku jej najszybszego spadku E Kierunek najszybszego spadku błędu Odpowiadająca mu wartość błędu Przemieszczenie po powierzchni błędu Stary (gorszy) wektor wag Migracja w przestrzeni wag Nowy (lepszy) wektor wag
 wektor wag. Migracja w przestrzeni wag. Nowy (lepszy) wektor wag.")
85
Poszerzenie zakresu analizy pozwala wykryć, że znalezione ekstremum (tu: maksimum) ma charakter lokalny, a nie globalny
 ma charakter lokalny, a nie globalny")
86
Można przy tym rozważać otoczenia o różnym zasięgu.

87
W zależności od tego, jaki rozmiar otoczenia jeszcze nie wykazuje, że ekstremum nie jest globalne - możemy mówić o ekstremach różnych rzędów.

88
Uczenie z nauczycielem
Zbiór uczący: X1 X2 D x11 x12 d1 x21 x22 d2 xn1 xn2 dn Czy yi = di? Jeśli nie, to zmień wagi w taki sposób, aby te dwie wartości zbliżyły się do siebie. X1 Y X2 Epoka - Jednokrotna prezentacja wszystkich przypadków uczących Sposób zmiany wag neuronów w sieci w celu uzyskania dobrej zgodności rzeczywistych odpowiedzi neuronów z odpowiedziami wzorcowymi, podanymi w zbiorze uczącym, stanowi istotę wybranej metody uczenia.

89
Przykładowy zbiór uczący pozwalający rozwiązać problem regresyjny
zmienne objaśniające: cylindry, pojemność, moc, masa, przyspieszenie, rok, pochodzenie zmienna objaśniana:zużycie paliwa w l/100 km.

90
można to zrobić przetwarzając dane ze zbioru uczącego
Uczenie sieci polega na takim doborze jej parametrów, żeby zminimalizować błąd, jaki popełnia sieć; można to zrobić przetwarzając dane ze zbioru uczącego W zbiorze uczącym podane są poprawne wartości rozwiązań dla tych danych Sieć na tej podstawie oblicza i podaje swoje rozwiązanie (na ogół początkowo błędne) Na wejście sieci podawane są dane wskazane w zbiorze jako wejściowe Oto sieć neuronowa, którą trzeba uczyć
 Na wejście sieci podawane są dane wskazane w zbiorze jako wejściowe. Oto sieć neuronowa, którą trzeba uczyć.")
91
Uczenie sieci polega teraz na takim doborze jej parametrów, żeby zminimalizować błąd, jaki popełnia sieć przetwarzając dane ze zbioru uczącego Porównanie zawartej w danych wzorcowej odpowiedzi z wynikiem obliczonym przez sieć daje błąd Błąd Na podstawie błędu zmienia się wagi wszystkich neuronów w sieci, tak żeby malał Robi to algorytm uczenia

92
Kształtowanie się błędu sieci w trakcie uczenia
Zbiór uczący: Najczęściej stosowana formuła opisująca błąd popełniany przez sieć: X1 X2 D x11 x12 d1 x21 x22 d2 xn1 xn2 dn I rzeczywiście zwykle błąd maleje! Jeśli proces uczenia ma zakończyć się sukcesem, to błąd powinien maleć Potem wolniej Najpierw szybko X1 Y X2

93
W trakcie uczenia sieci błąd przez nią popełniany zmienia się w charakterystyczny i zwykle podobny sposób: szybko maleje na początku procesu i znacznie wolniej później. Dla tej samej sieci i dla tych samych danych uczących przebiegi procesu uczenia mogą się nieco różnić jeden od drugiego. Zależy to głównie od tego, jak wybrany został punkt startowy, to znaczy wartości wag na początku procesu uczenia.

94
Przeuczenie sieci czyli zanik zdolności do generalizacji
Zbiór uczący: Zdolność do aproksymacji: X1 X2 D x11 x12 d1 x21 x22 d2 xk1 xk2 dk X1 Y X2 Zdolność do generalizacji: Zbiór walidacyjny: X1 X2 D x(k+1)1 x(k+1)2 dk+1 xn1 xn2 dn Tutaj przerwać uczenie!
1 x(k+1)2 dk xn1 xn2 dn. Tutaj przerwać uczenie!")
95
Tu zaczyna się przeuczenie
Dzięki użyciu zbioru danych walidacyjnych można wykryć moment „przeuczenia” sieci. Tu zaczyna się przeuczenie 1 0.8 0.6 0.4 0.2 200 400 600 800 1000 Błąd dla zbioru uczącego Błąd dla zbioru walidacyjnego

96
Strukturę sieci trzeba tak dobrać, żeby otrzymać aproksymację danych uczących nie za bardzo skomplikowaną, ale i nie nazbyt uproszczoną

97
Działanie sieci posiadającej zdolność do aproksymacji i do generalizacji

98
Działanie (na tych samych danych) sieci nie posiadającej zdolności do generalizacji
 sieci nie posiadającej zdolności do generalizacji")
99
Efekty uczenia sieci - 1

100
Efekty uczenia sieci - 2

101
Efekty uczenia sieci - 3

102
Kwestia wyboru struktury modelu neuronowego
Nie istnieje ogólna recepta, każdy przypadek musi być rozważany indywidualnie!

103
Najbardziej istotny problem wiąże się z ustaleniem, ile elementów powinna mieć warstwa ukryta?
Mała może się okazać zbyt prymitywna, żeby sobie poradzić z trudnością rozwiązywanego zadania... ... duża z pewnością sprawi więcej kłopotów podczas uczenia

104
Przyjrzyjmy się, jak rozwiązują problem uczenia sieci o różnej architekturze
Wyobraźmy sobie przestrzeń percepcyjną pewnego zwierzaka. Postrzega on otoczenie za pomocą wzroku i słuchu, więc każde środowisko stanowi dla niego punkt na płaszczyźnie dźwięku i światła. Tu jest jasno i gwarno Dźwięk Tu jest głośno i ciemno (dyskoteka) A tu są dane dla konkretnego środowiska w którym umieszczamy naszego zwierzaka. Tu jest cicho i ciemno (sypialnia) Przedmiotem uczenia będzie to, w jakim środowisku zwierzak się dobrze czuje Tu jest cicho i jasno (plaża) Światło
 A tu są dane dla konkretnego środowiska w którym umieszczamy naszego zwierzaka. Tu jest cicho i ciemno (sypialnia) Przedmiotem uczenia będzie to, w jakim środowisku zwierzak się dobrze czuje. Tu jest cicho i jasno (plaża) Światło.")
105
„Samopoczucie” zwierzaka będzie sygnalizowane przez kolor odpowiednich punktów w przestrzeni sygnałów wejściowych Dźwięk Światło Tu zwierzak jest nieszczęśliwy Tu zwierzak jest zadowolony

106
Przykładowa mapa „samopoczucia” zwierzaka
Mapę taką będziemy dalej rysowali zwykle w postaci wygładzonej: Dźwięk Światło

107
Informację o tym, jak się powinien zachowywać, zwierzak dostawać będzie w postaci zbioru uczącego, składającego się z przypadkowo wylosowanych punktów („środowisk”) do których przypisane będą wymagane przez nauczyciela stany samopoczucia (sygnalizowane kolorem) Oto przykładowy zbiór uczący ... ...wygenerowany dla tej mapy

108
Zakładamy, że pomiędzy stanami:
pełnego szczęścia: i całkowitej depresji: Możliwe są jeszcze stany pośrednie, które będziemy oznaczać kolorami podobnymi, jak na mapach geograficznych pośrednie wysokości pomiędzy szczytami (entuzjazmu) a dnem (melancholii). Przykładowa mapa:
 a dnem (melancholii). Przykładowa mapa:")
109
Wyposażmy naszego zwierzaka w „mózg” w postaci bardzo prostej jednowarstwowej sieci neuronowej i spróbujmy przeprowadzić jego uczenie Zaczniemy od próby wyuczenia zwierzaka, żeby lubił gwarne śródmieście w samo południe: Zwierzak początkowo wcale nie ma na to ochoty, bo jego zachowanie wynikające z początkowych (przypadkowych!) wartości wag neuronów obrazuje mapa: Dźwięk Jasno i bardzo głośno! Jest to jak widać zwolennik dyskoteki i sypialni (?) Ale zwierzak nam się trafił ! Światło
 wartości wag neuronów obrazuje mapa: Dźwięk. Jasno i bardzo głośno! Jest to jak widać zwolennik dyskoteki i sypialni ( ) Ale zwierzak nam się trafił ! Światło.")
110
No to zaaplikujemy zwierzakowi uczenie
Wzorzec Stan Początek Dalszy etap początkowy uczenia uczenia Widać, że na początku ma „opory”, ale powoli zaczyna się uczyć...

111
Po kolejnych kilku epokach uczenia zwierzak już wie, o co chodzi:
Już się dostosował!

112
Poprzednie zadanie udało się rozwiązać, bo było bardzo proste, więc bardzo głupiutki zwierzak (sieć neuronowa bez warstw ukrytych) zdołał się go nauczyć. Zobaczmy jednak, jak ta sama sieć będzie się uczyć trudniejszego zadania.

113
Niech zadanie polega na stworzeniu preferencji dla „złotego środka”

114
Nasz zwierzak miota się i zmienia swoje upodobania, ale mimo dowolnie długiego uczenia nie zdoła wykryć, o co tym razem chodzi! Zauważmy: Ten „cyber-kretyn” nigdy się nie nauczy robić tego, czego się od niego wymaga, ale jego poglądy są zawsze bardzo kategoryczne (wszystko jest albo bardzo dobre, albo bardzo złe) – chociaż za każdym razem niestety błędne...
 – chociaż za każdym razem niestety błędne...")
115
Wyposażmy go więc w bardziej skomplikowany „mózg” zawierający pewną liczbę neuronów ukrytych.
Teraz proces uczenia przebiega zupełnie inaczej. Sieć startuje od stanu totalnego optymizmu (prawie wszystko się zwierzakowi podoba!).
.")
116
Wystarczy jednak kilka niepowodzeń w trakcie procesu uczenia, by zwierzak popadł w stan totalnego pesymizmu Dostał kilka razy karę od nauczyciela i się załamał!

117
Potem jednak proces uczenia przebiega coraz skuteczniej i kończy się całkowitym sukcesem

118
Ta sama sieć wystartowana powtórnie (z innymi początkowymi wartościami wag) także dochodzi do właściwego rozwiązania, chociaż inną drogą.
 także dochodzi do właściwego rozwiązania, chociaż inną drogą.")
119
Dzięki prostemu programowi symulacyjnemu można zebrać bardzo wiele podobnych historii uczenia.

120
Inny przykład Sieć z dwoma warstwami ukrytymi (powyżej) radzi sobie z problemem, który „przerasta” możliwości sieci z jedną warstwą ukrytą (na następnym slajdzie)
 radzi sobie z problemem, który „przerasta możliwości sieci z jedną warstwą ukrytą (na następnym slajdzie)")
121
Porażka sieci z jedną warstwą ukrytą

122
Oto jeszcze jedna przykładowa historia uczenia sieci o większej złożoności
Takie zabawy można kontynuować bez końca!

123
Całkiem poważnym problemem jest sposób reprezentacji danych w sieci neuronowej
Jeśli dane mają od początku charakter numeryczny to problemu nie ma – najwyżej trzeba je przeskalować. cel skalowania: dopasowanie zakresu wartości zmiennej do charakterystyki neuronu

124
Gorzej, jeśli dane mają charakter jakościowy
Gorzej, jeśli dane mają charakter jakościowy. Konieczne jest wtedy przekształcenie jeden-z-N Jeden-z-N – to sposób na przekształcenie wartości nominalnych do postaci numerycznej. Przykład: Pochodzenie ={Azja, Ameryka, Europa} Azja: {1, 0, 0} Ameryka: {0, 1, 0} Europa: {0, 0, 1} jedna zmienna – trzy neurony

125
Właściwej interpretacji wymagają też dane wyjściowe, otrzymywane z sieci jako rozwiązanie postawionego zadania Jeśli wymagane są wyniki numeryczne, to sprawa jest prosta, bo wystarczy je odczytać na wyjściach neuronów i tylko odpowiednio przeskalować. Trudności zaczynają się wtedy, gdy sieć pracuje jako klasyfikator, więc jej odpowiedzi trzeba interpretować jako decyzje.

126
Klasyfikacja wzorcowa
Celem klasyfikacji wzorcowej jest przypisanie badanych obiektów do jednej ze znanych klas. Zaklasyfikowanie obiektu dokonywane jest na podstawie wartości opisujących go zmiennych.

127
Klasyfikacja w przypadku dwóch klas
Warstwa wyjściowa - neuron z sigmoidalną funkcją aktywacji Reprezentacja klas: klasa 1 - wartość 1 klasa 2 - wartość 0 Wartość wyjściowa neuronu może być interpretowana jako prawdopodobieństwo przynależności do klasy 1

128
Klasyfikacja w przypadku większej liczby klas
Każdej klasie odpowiada jeden neuron w warstwie wyjściowej. Aby obiekt został zaliczony do i-tej klasy: wartość wyjściowa i-tego neuronu - wyższa od poziomu akceptacji, wartości wyjściowe pozostałych neuronów - niższe od poziomu odrzucenia. Interpretacja wartości wyjściowych jako prawdopodobieństw przynależności do klas - konieczne jest ich sumowanie do jedności - zapewnia to funkcja aktywacji SoftMax

129
Przykład klasyfikacji binarnej i wieloklasowej

130
Problem praktyczny: Czy wszystkie dostępne zmienne objaśniające należy wprowadzać na wejścia sieci?
Nie, w miarę możliwości należy ograniczać liczbę zmiennych wejściowych, Dlaczego? Bo stosując mniejszą liczbę zmiennych wejściowych uzyskujemy prostszą sieć, która: posiada mniejszą liczbę parametrów nastawianych podczas uczenia, a to powoduje łatwiejsze uczenie i daje lepsze zdolności do generalizacji, ma krótszy czas uczenia, gdyż mniej jest danych

131
Liniowa sieć neuronowa
Iteracyjne uczenie sieci liniowej nie jest konieczne, gdyż może być zastąpione procedurą pseudo-inwersji macierzy w11 x1 y1 = w11 x1 + w21 x wn1 xn ….. y1 w21 x2 wn1 yk = w1k x1 + w2k x wnk xn W zapisie macierzowym: Y = W X yk xn

132
Sieć liniowa jako najprostszy (ale użyteczny!) model regresyjny
Przesłanki przemawiające za stosowaniem liniowej sieci neuronowej: jest doskonałym narzędziem do opisu zależności liniowych, stanowi punkt odniesienia przy ocenie modeli nieliniowych, struktura i uczenie nie stwarza żadnych problemów.

133
Liniowa sieć neuronowa
P Y W W1 W2 Y X X P = W1 X Y = W2 P Y = W2 W1 X Y = W X ; W = W1 W2 Sieć liniowa z zasady nie posiada warstw ukrytych, bo nawet jeśli się je wprowadzi, to nie wzbogacą one zachowania sieci

134
Dlatego liniowa sieć neuronowa jest często przedstawiana w sposób przytoczony na tym obrazku

135
Perceptron wielowarstwowy
P = [W1 X] Y = [ W2 P ] Y = [ W2 [ W1 X ] ] P X W1 W2 Y W perceptronie na skutek istnienia nieliniowości w neuronach ukrytych nie jest możliwe „zwinięcie”jego wielowarstwowej struktury

136
Przykłady budowy modeli neuronowych z użyciem sieci typu perceptron
UWAGA! Zwykle rozwiązywane rzeczywiste problemy są znacznie bardziej złożone, głównie ze względu na konieczność uwzględniania wielu wejść i wyjść sieci!

137
Rzeczywiste dane, które muszą być aproksymowane z pomocą sieci są zwykle wielowymiarowe.

138
Sieć neuronowa może dać model lepszy niż metody statystyczne
Model statystyczny Sieć neuronowa

139
Niekorzystne jest zarówno użycie zbyt prostej, jak i zbyt skomplikowanej sieci
Sieć zbyt prosta (jeden neuron) Sieć zbyt skomplikowana
 Sieć zbyt skomplikowana.")
140
Mało skomplikowane sieci szybko się uczą i wykazują powtarzalne zachowanie, chociaż jest to często zachowanie błędne Wyniki kolejnych prób uczenia za małej sieci

141
Sieć neuronowa buduje model poprzez tworzenie w poszczególnych neuronach kombinacji liniowych ich sygnałów wejściowych oraz nakładanie na to nieliniowych funkcji aktywacji neuronów

142
Działanie sieci MLP o większej liczbie warstw oraz sieci RBF

143
Sieci o radialnych funkcjach bazowych(sieci RBF)
")
144
Sieci RBF - schemat neuronu radialnego

145
Zastosowanie RBF (zamiast MLP) spowoduje, że sieć neuronowa znajdzie aproksymację lepiej dopasowaną do lokalnych właściwości zbioru danych, ale gorzej ekstrapolującą. MLP RBF Funkcja bazowe Wynik dopasowania

146
Sieci RBF bywają nadmiernie wrażliwe na nawet nieliczne błędy w danych uczących

147
Przykład danych doświadczalnych (kółeczka) do aproksymacji z pomocą sieci neuronowej (linia kropkowana)
 do aproksymacji z pomocą sieci neuronowej (linia kropkowana)")
148
Kolejne eksperymenty uczenia tej samej sieci neuronowej na tych samych danych mogą dawać nieco różniące się wyniki.

149
Niekiedy sieć nadmiernie dopasowuje się do danych uczących (przeuczenie) i traci zdolność generalizacji
 i traci zdolność generalizacji")
150
W razie potrzeby służę konsultacją
O szczegółach techniki sieci neuronowych można się więcej nauczyć z mojej książki dostępnej bezpłatnie w Internecie : W razie potrzeby służę konsultacją

Podobne prezentacje