Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Analiza danych ankietowych
Dzięki uprzejmości dr inż. Agnieszki KUJAWIŃSKIEJ

2
Każdy proces badawczy składa się z etapów układających się w zamknięty cykl.
Analiza danych jest jednym z elementów tak pojętego cyklu badawczego. Miejsce analizy danych w procesie badawczym przedstawia rysunek obok

3
Zastosowanie metod statystycznych..
…wymaga odpowiedniego przygotowania danych surowych Dane surowe mogą mieć postać: wypełnionych kwestionariuszy, dzienników obserwacji, dzienników panelowych, zapisanych testów, lub zapisów z pomiaru… Dane należy skontrolować i odpowiednio zakodować

4
Kontrola danych i kodowanie danych to etapy poprzedzające analizę danych

5
Kontrola danych dotyczy przede wszystkim…
czytelności i dokładności. mimo bieżącej kontroli pomiaru zdarzają się pytania bez odpowiedzi niektóre pytania, a nawet całe strony, mogą być pominięte przez prowadzącego wywiad lub — w przypadku pomiarów ankietowych — przez respondenta niekiedy respondenci świadomie odmawiają odpowiedzi na niektóre pytania lub w ogóle nie poddają się pomiarowi zapisy na kartach kwestionariusza są czasami mało czytelne.

6
kilka powszechnie spotykanych błędów i braków:
1. Pomiary fikcyjne Są to oszustwa świadomie dokonane przez osoby prowadzące pomiar. Błędne dane Mimo że większość błędów jest niewidoczna, błędy dotyczące faktów można zwykle zidentyfikować. Poprawki można robić wówczas, gdy inne dane w kwestionariuszu są prawdziwe. 3. Sprzeczności i niezgodności Przykładem może być odpowiedź, z której wynika, że respondent nigdy nie słyszał o danym produkcie, podczas gdy w odpowiedzi na inne pytanie twierdzi, że używa tego produktu. O tym, która odpowiedź jest prawdziwa, można niekiedy wnioskować z innych odpowiedzi, ale wnioski te mogą być ryzykowne. 4. Odpowiedzi niekompletne lub niejednoznaczne Niektóre odpowiedzi są niekompletne, nieczytelne lub niejasne i wieloznaczne. Niekompletną odpowiedź można w przybliżeniu określić i uzupełnić. Natomiast odpowiedzi niejednoznaczne lub nieokreślone są trudne do interpretacji i ewentualnej poprawy.

7
Odpowiedzi nieadekwatne
Respondenci dają czasami odpowiedzi nie związane z tematem pytania. 6. Brak odpowiedzi na jedno lub kilka pytań albo brak zgody respondenta na przeprowadzenie pomiaru Tego typu błędy i braki zdarzają się najczęściej, zwłaszcza w pomiarach ankietowych.

8
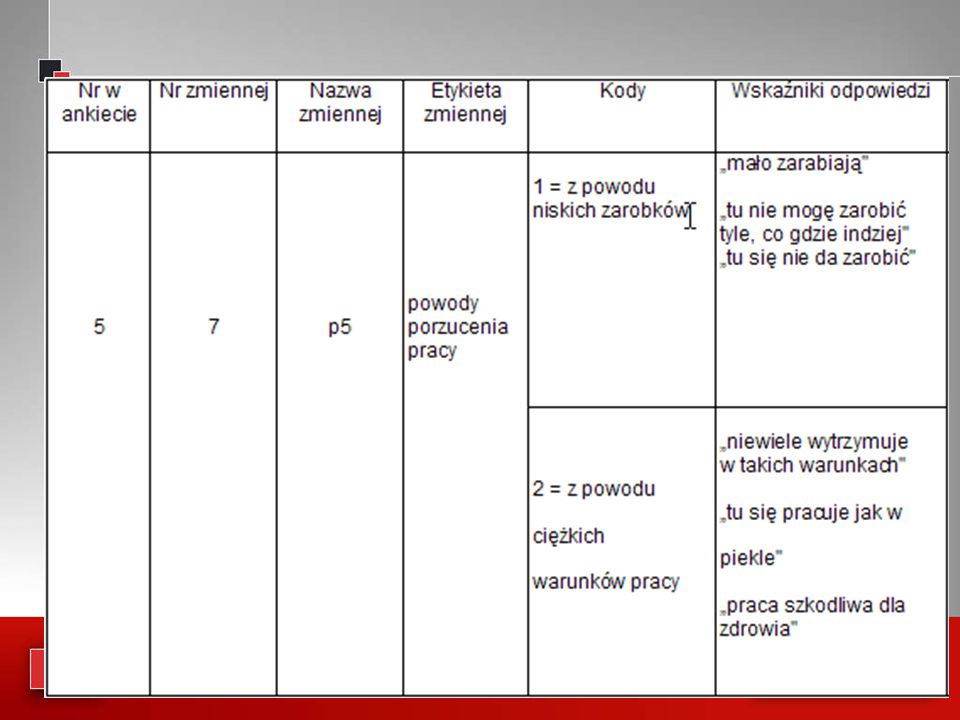
Kodowanie W czasach współczesnych kodowanie odpowiedzi w kwestionariuszach ma na celu przeniesienie danych z instrumentu pomiarowego (np. kwestionariusza ankiety) do pamięci komputera (arkusza kalkulacyjnego, bazy danych etc.). W tym kontekście kodowanie określić można jako przyporządkowanie symboli (liczb/kodów) danym zawartym w instrumentach pomiarowych
 do pamięci komputera (arkusza kalkulacyjnego, bazy danych etc.). W tym kontekście kodowanie określić można jako przyporządkowanie symboli (liczb/kodów) danym zawartym w instrumentach pomiarowych.")
9
Etapy kodowania: Instrukcja kodowania powinna zawierać

10
Sposób kodowania w istotnym stopniu zależy od rodzaju pytania i odpowiadających pytaniu odpowiedzi.
W naukach społecznych wyróżnić można przynajmniej kilka rodzajów pytań. Ich typologię zawiera poniższy rysunek: Pytania ankiety Otwarte: swoboda wyboru Zamknięte: Z góry przewidziano odpowiedzi Dychotomiczne Kafeteria zamknięta Dysjunktywna Koniunktywna Kafeteria półotwarta Pytania skale Metryczkowe: dane demograficzne i społeczne Filtrujące: eliminacja osób, których pytanie nie dotyczy

11
Pytania zamknięte – pytaniami samokodującymi
Kodowanie pytań zamkniętych polega na przeniesieniu odpowiadającego danej odpowiedzi kodu (liczby) do bazy danych. Przykładowo dla pytań zamkniętych z jedną opcją wyboru: Czy jest Pani zadowolona z dezodorantu Nivea?: Zdecydowanie tak 1 Raczej tak Raczej nie Zdecydowanie nie Jeszcze nie mam wyrobionej opinii 5
 do bazy danych. Przykładowo dla pytań zamkniętych z jedną opcją wyboru: Czy jest Pani zadowolona z dezodorantu Nivea : Zdecydowanie tak 1. Raczej tak 2. Raczej nie 3. Zdecydowanie nie 4. Jeszcze nie mam wyrobionej opinii 5.")
12
Więcej opcji do wyboru – Kodowanie geometryczne
Kod geometryczny to ciąg o wyrazie pierwszym równym 1 i o ilorazie równym 2. Są to następujące liczby (każda kolejna dwukrtonie większa od następnej): 1, 2, 4, 8, 16, 32, 64, …itd. Jakie papierosy kupował Pan w ostatnim miesiącu? Ares Caro Fajrant Jan III Sobieski Marlboro Prince inne…… 1 2 4 2 + 8 = 10 8 16 Jakakolwiek suma dowolnych liczb z takiego kodu daje niepowtarzalną kombinację 32 64
: 1, 2, 4, 8, 16, 32, 64, …itd. Jakie papierosy kupował Pan w ostatnim miesiącu Ares. Caro. Fajrant. Jan III Sobieski. Marlboro. Prince. inne…… = Jakakolwiek suma dowolnych liczb z takiego kodu daje niepowtarzalną kombinację")
13
Więcej opcji do wyboru – Kodowanie binarne
Kod geometryczny jest kłopotliwy, jeżeli jest dużo wariantów odpowiedzi Kodowanie binarne polega na wprowadzeniu do arkusza danych tylu zmiennych (kolumn), ile było wariantów odpowiedzi w danym pytaniu W kolumnach pojawiają się wówczas dwie wartości: 0 – nie zaznaczenie odpowiedzi 1 – wybranie odpowiedzi
, ile było wariantów odpowiedzi w danym pytaniu. W kolumnach pojawiają się wówczas dwie wartości: 0 – nie zaznaczenie odpowiedzi. 1 – wybranie odpowiedzi.")
14
Pytania otwarte W kodowaniu pytań tego typu badacz tworzy schemat kodowania nie przed podjęciem badań, lecz w ich trakcie, na podstawie reprezentatywnej próbki odpowiedzi na dane pytanie. Stąd, kodowanie tego rodzaju określić można jako indukcyjne. Tworzenie grup, kategorii i wskaźników kategorii

16
Po etapie kodowania Następuje etap przygotowania do analiz statystycznych poprzez przygotowanie tablic wynikowych: Jednodzielcze Dwudzielcze Wielodzielcze

17
tablice jednodzielcze
(służące do określenia prostych rozkładów częstotliwości występowania określonej [jednej] zmiennej), tablice dwudzielcze (ukazujące rozkłady dwóch zmiennych jednocześnie), tablice wielodzielcze (ukazujące rozkłady trzech [i więcej] zmiennych jednocześnie
, tablice dwudzielcze. (ukazujące rozkłady dwóch zmiennych jednocześnie), tablice wielodzielcze. (ukazujące rozkłady trzech [i więcej] zmiennych jednocześnie.")
18
Tablica jednodzielcza
Tablice jednodzielcze ukazują nam częstotliwości z jakimi wystąpiły zawarte w kafeterii (w przypadku pytań zamkniętych) lub pokategoryzowane w trakcie kodowania w przypadku pytań otwartych) odpowiedzi na odpowiednie pytania kwestionariusza Proszę powiedzieć, w jakim stopniu uważasz następujące sprawy za ważne w Twoim życiu: nauka Liczebność % bardzo ważne 223 44,2% raczej ważne 271 53,8% niezbyt ważne 6 1,2% w ogóle nieważne 2 0,4% trudno powiedzieć Ogółem 504 100,0%
 lub pokategoryzowane w trakcie kodowania w przypadku pytań otwartych) odpowiedzi na odpowiednie pytania kwestionariusza. Proszę powiedzieć, w jakim stopniu uważasz następujące sprawy za ważne w Twoim życiu: nauka. Liczebność. % bardzo ważne ,2% raczej ważne ,8% niezbyt ważne. 6. 1,2% w ogóle nieważne. 2. 0,4% trudno powiedzieć. Ogółem ,0%")
19
Tabele dwudzielcze Tabele dwudzielcze prezentują liczebności (lub procenty) osób poklasyfikowanych według dwóch zmiennych jednocześnie Płeć Wykształcenie Podstawowe Średnie Wyższe Razem Kobiety Mężczyźni mężczyźni z podstawowym wykształceniem kobiety z podstawowym wykształceniem mężczyźni ze średnim wykształceniem kobiety ze średnim wykształceniem mężczyźni z wyższym wykształceniem kobiety z wyższym wykształceniem

20
Procentowanie Płeć Wykształcenie Średnie Wyższe Razem Kobiety
Podstawowe Średnie Wyższe Razem Kobiety Mężczyźni 100 Płeć Wykształcenie Podstawowe Średnie Wyższe Razem Kobiety 100 Mężczyźni Płeć Wykształcenie Podstawowe Średnie Wyższe Razem Kobiety Mężczyźni 100

21
Generalnie stwierdzić możemy, że:
Jeżeli z dwóch zmiennych A i B jedna z nich jest zmienną niezależną w danym momencie analizy (jest przyczyną, jest zmienną wyjaśniającą, jest zmienną prognostyczną itp.), zaś druga jest zmienną zależną (skutkiem, zjawiskiem, wyjaśnianym, oczekiwanym efektem prognozy), to za podstawę do obliczeń procentowych (tj. za 100%) bierzemy liczebności podgrup poszczególnych wartości zmiennej niezależnej. Generalnie stwierdzić możemy, że: procentujemy zawsze w kierunku zmiennej niezależnej, procenty czytamy zaś (porównujemy) zawsze w kierunku zmiennej zależnej
, zaś druga jest zmienną zależną (skutkiem, zjawiskiem, wyjaśnianym, oczekiwanym efektem prognozy), to za podstawę do obliczeń procentowych (tj. za 100%) bierzemy liczebności podgrup poszczególnych wartości zmiennej niezależnej. Generalnie stwierdzić możemy, że: procentujemy zawsze w kierunku zmiennej niezależnej, procenty czytamy zaś (porównujemy) zawsze w kierunku zmiennej zależnej.")
22
Jeżeli interesuje nas wpływ płci (zmienna niezależna) na stosunek do wiary (zmienna zależna) to zawsze będziemy procentowali w kierunku płci, porównywali zaś będziemy w kierunku stosunku do wiary Przykład Kobiety częściej niż mężczyźni określały się jako osoby głęboko wierzące (13,1% w stosunku do 5,0%) oraz wierzące (73,0% do 66,9%). Związek z wiarą (głęboką wiarę oraz wiarę) zdecydowanie częściej deklarowały więc kobiety niż mężczyźni (odpowiednio: 86,6% do 71,9%). Mężczyźni z kolei częściej deklarowali swoje niezdecydowanie w prawach wiary (21,9% do 10,8%), obojętność w stosunku do wiary (3,1% do 0,9%) oraz brak wiary (odpowiednio: 3,1% do 1,7%). Sumując: kobiety generalnie deklarują wyższy poziom wiary niż mężczyźni.
 oraz wierzące (73,0% do 66,9%). Związek z wiarą (głęboką wiarę oraz wiarę) zdecydowanie częściej deklarowały więc kobiety niż mężczyźni (odpowiednio: 86,6% do 71,9%). Mężczyźni z kolei częściej deklarowali swoje niezdecydowanie w prawach wiary (21,9% do 10,8%), obojętność w stosunku do wiary (3,1% do 0,9%) oraz brak wiary (odpowiednio: 3,1% do 1,7%). Sumując: kobiety generalnie deklarują wyższy poziom wiary niż mężczyźni.")
23
Osoby starsze (tj. studiujące na roku czwartym) częściej niż młodsze (tj. studiujące na roku pierwszym) deklarują swoją wiarę (odpowiednio: 73,3% do 70,5%) oraz głęboką wiarę (14,8% do 7,8%). Wynika z tego, iż procent osób związanych z wiarą (wierzących lub głęboko wierzących) jest większy wśród starszych, mniejszy zaś wśród młodszych studentów (odpowiednio: 87,8% do 78,2%). Z kolei osoby studiujące na roku pierwszym częściej niż studiujące na roku czwartym określają się jako niezdecydowane, ale przywiązane do tradycji religijnej (stosunek 16,9% do 10,2%), niewierzące (3,2% do 0,5%) oraz obojętne w stosunku do wiary (1,6% do 1,5%). Na podstawie zaprezentowanych danych stwierdzić więc można, że wraz z przejściem od pierwszego do czwartego roku rośnie poziom deklarowanej wiary.
 jest większy wśród starszych, mniejszy zaś wśród młodszych studentów (odpowiednio: 87,8% do 78,2%). Z kolei osoby studiujące na roku pierwszym częściej niż studiujące na roku czwartym określają się jako niezdecydowane, ale przywiązane do tradycji religijnej (stosunek 16,9% do 10,2%), niewierzące (3,2% do 0,5%) oraz obojętne w stosunku do wiary (1,6% do 1,5%). Na podstawie zaprezentowanych danych stwierdzić więc można, że wraz z przejściem od pierwszego do czwartego roku rośnie poziom deklarowanej wiary.")
24
Przykładowo Wartości Lib. Kons. VAN Nie 137 102 Tak 27 33 24

25
299 Wartości Lib. Kons. Wiersz RAZEM VAN Nie 137 102 239 Tak 27 33 60
Zmienne niezależne Wartości Lib. Kons. Wiersz RAZEM VAN Nie 137 102 239 Tak 27 33 60 Kolumna 164 135 299 Zmienne zależne W tym przypadku przypuszczamy, że wartości społeczne mają wpływ na posiadanie określonego typu samochodu 25

26
Wartości Lib. Kons. Wiersz RAZEM VAN Nie 137 57,32% 102 42,68%
Obliczamy procenty w wierszach Wartości Lib. Kons. Wiersz RAZEM VAN Nie 137 57,32% 102 42,68% % Tak 27 33,33% 33 66,67% 60 100% Kolumna 164 135 299 (137/239)*100% 26
*100% 26.")
27
Wartości Lib. Kons. Wiersz RAZEM VAN Nie 137 83,54% 102 75,55% 239 Tak
Obliczamy procenty w kolumnach (137/164)*100% Wartości Lib. Kons. Wiersz RAZEM VAN Nie 137 83,54% 102 75,55% 239 Tak 27 16,46% 33 24,45% 60 Kolumna 164 100% 135 299 27
*100% Wartości. Lib. Kons. Wiersz. RAZEM. VAN. Nie ,54% ,55% 239. Tak ,46% ,45% 60. Kolumna %")
28
Wartości Lib. Kons. Wiersz RAZEM VAN Nie 137 45,82% 102 34,11% 239 Tak
Obliczamy procenty z całości (137/299)*100% Wartości Lib. Kons. Wiersz RAZEM VAN Nie 137 45,82% 102 34,11% 239 Tak 27 9,03% 33 11,04% 60 Kolumna 164 135 299 100% 28
*100% Wartości. Lib. Kons. Wiersz. RAZEM. VAN. Nie ,82% ,11% 239. Tak ,03% ,04% 60. Kolumna % 28.")
29
Czy zaobserwowane różnice są istotne statystycznie?
Przy prowadzeniu analizy danych za pomocą tabel kontyngencji mamy 2 problemy do rozpatrzenia: Czy zaobserwowane różnice są istotne statystycznie? Jaka jest siła związku pomiędzy zmiennymi? Czy relacje są pozorne czy rzeczywiste?

30
Problem 1: test c2 Wyznaczyć wartości oczekiwane Wyznaczyć różnicę pomiędzy tym co oczekiwane a tym co zaobserwowane Wniosek

31
c02=2,69 a=0,05 df=(w-1)(k-1)=1 ca2=3,84 (164*239)/299 Wartości Lib.
Kons. Wiersz RAZEM VAN Nie 137 131,09 102 107 239 Tak 27 32,90 33 27,09 60 Kolumna 164 135 299 c02=2,69 a=0,05 df=(w-1)(k-1)=1 ca2=3,84 Nie ma podstaw do odrzucenia H0. Brak jest związku miedzy wartościami a typem kupowanego auta
(k-1)=1. ca2=3,84. Nie ma podstaw do odrzucenia H0. Brak jest związku miedzy wartościami. a typem kupowanego auta.")
32
Zmiana poziomu istotności n. z 0,05 na 0,1
Sterowanie testem Zmiana poziomu istotności n. z 0,05 na 0,1 w przykładzie odrzucimy H0 Zmiana liczby stopni swobody, np. wzrost liczby kolumn lub wierszy)
")
33
Współczynnik kontyngencji C Pearsona:
Siła związku Współczynnik kontyngencji C Pearsona: Jeżeli C = 0 to brak zależności Górna granica zależy od liczby wierszy w tabeli i jest równa: W przykładzie C=0,099, co wskazuje na stosunkowo słaby związek pomiędzy zmiennymi

34
Współczynnik V Cramera
Niedogodność braku wartości maksymalnej dla współczynnika C Pearsona można pominąć stosując współczynnik V Cramera: gdzie k – mniejsza z liczb kolumn lub wierszy Współczynnik przyjmuje wartości z przedziału <0, 1>

35
Polecam: Analiza korespondencji Wieloraka analiza korespondencji
Analiza skupień

36
Dziękuję za uwagę

Podobne prezentacje
, gdzie X jest liczbą osób w rodzinie, a Y liczbą izb w mieszkaniu. Niech f.r.p. tej zmiennej.>")










>")
>")






