Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Internet jako źródło informacji
M. Kowalska

2
Treść zajęć Determinanty Internetu jako źródła informacji,
Modele wyszukiwania informacji, Narzędzia wyszukiwania w Sieci (ogólne i specjalistyczne), Analiza jakości informacji, Benchmarking jako analiza porównawcza (produkty, usługi), Monitoring mediów (zbiorowy, indywidualny). Warunki zaliczenia: wykonanie ćwiczeń w trakcie zajęć.
, Analiza jakości informacji, Benchmarking jako analiza porównawcza (produkty, usługi), Monitoring mediów (zbiorowy, indywidualny). Warunki zaliczenia: wykonanie ćwiczeń w trakcie zajęć.")
3
Jakim źródłem jest Internet?
Aspekty cywilizacyjno-informacyjne: nadmiar informacji, cisza informacyjna, pułapki Sieci (wojna edycyjna, cloaking, Google bomb, keywords stuffing), Specyfika danych w Sieci: dane rozproszone, jednostki informacyjne są obszerne, brak jednolitej struktury danych, wysoki procent danych jest ulotny, jakość danych, heterogeniczne dane, Kompetencje informacyjne użytkowników, Specyfika poszczególnych narzędzi (Web ), Umiejętność oceny jakości informacji.
, Specyfika danych w Sieci: dane rozproszone, jednostki informacyjne są obszerne, brak jednolitej struktury danych, wysoki procent danych jest ulotny, jakość danych, heterogeniczne dane, Kompetencje informacyjne użytkowników, Specyfika poszczególnych narzędzi (Web ), Umiejętność oceny jakości informacji.")
4
Wyszukiwanie, przeszukiwanie czy poszukiwanie w Sieci?

5
Wyszukiwanie, przeszukiwanie, poszukiwanie
Wyszukiwanie – czynności, metody, procedury prowadzące do uzyskania informacji z zapamiętanych danych, […] może być wykonywane w przetwarzaniu interaktywnym lub wsadowym (PN-ISO , s. 18), Przeszukiwanie – proces wyszukiwania realizowany przez system w wyniku działania użytkownika, obejmuje dopasowanie instrukcji wyszukiwawczej (zapytania) do charakterystyki dokumentu (formy i treści), Poszukiwanie – pogłębianie wiedzy poprzez odszukanie potrzebnej informacji w rozmaitych zbiorach informacji, realizowane przez użytkownika i rozpatrywane z jego punktu widzenia.
, Przeszukiwanie – proces wyszukiwania realizowany przez system w wyniku działania użytkownika, obejmuje dopasowanie instrukcji wyszukiwawczej (zapytania) do charakterystyki dokumentu (formy i treści), Poszukiwanie – pogłębianie wiedzy poprzez odszukanie potrzebnej informacji w rozmaitych zbiorach informacji, realizowane przez użytkownika i rozpatrywane z jego punktu widzenia.")
6
Modele poszukiwania informacji
Model Davida Ellisa: rozpoznanie potrzeby, definiowanie, wybór systemu, formułowanie zapytania, wysłanie zapytania, weryfikowanie rezultatów, wydobywanie informacji, rozważenie / zatrzymanie / powtórzenie wyszukiwania, Metoda kolejnych przybliżeń (iteracji): wielokrotne powtarzanie tego samego zapytania, z uwzględnieniem zmiennych wyników, Technika zbierania jagód Marcii Bates: zbieranie zbiorów informacji z których jedne prowadzą, czy też wywołują kolejne, inne zaś prowadzą do dokładniejszej eksploracji obiektów lub ich porzucenia, Zjawisko rosnącej perły: poszerzanie kręgu wyszukiwania informacji poprzez przechodzenie od informacji jednostkowej do jej zbiorów (np. rozpoczynanie od hasła przedmiotowego lub cytatu).
: wielokrotne powtarzanie tego samego zapytania, z uwzględnieniem zmiennych wyników, Technika zbierania jagód Marcii Bates: zbieranie zbiorów informacji z których jedne prowadzą, czy też wywołują kolejne, inne zaś prowadzą do dokładniejszej eksploracji obiektów lub ich porzucenia, Zjawisko rosnącej perły: poszerzanie kręgu wyszukiwania informacji poprzez przechodzenie od informacji jednostkowej do jej zbiorów (np. rozpoczynanie od hasła przedmiotowego lub cytatu).")
7
Metody poszukiwania informacji w Internecie
Oświecone zgadywanie – konstruowanie nazw stron/odnośników z wykorzystaniem szukanego słowa, Nawigowanie – znajdowanie drogi i podążanie nią w celu dotarcia do informacji, odbywające się w środowisku informacji i wiedzy, Przeglądanie – proces odbioru treści wyświetlanej na ekranie monitora w celu odnalezienia poszukiwanej informacji, zorientowania się w położeniu lub podjęcia decyzji o dalszym wyborze drogi postępowania, Formułowanie zapytań – wprowadzanie pytań do wyszukiwarki/baz danych w celu odnalezienia żądanej informacji.

8
Narzędzia wyszukiwania informacji w Internecie
Katalogi stron, Wyszukiwarki, Multiwyszukiwarki, Wortale, portale, Bazy danych, bibliografie i katalogi centralne, Katalogi specjalizowane - subject gateways i Ukrytego Internetu, Repozytoria i biblioteki cyfrowe, …

9
Katalogi stron drzewiasta struktura,
witryny przypisane są do poszczególnych kategorii, dzielą się na kategorie podrzędne, kategorie elementarne zawierają bezpośrednie odsyłacze do stron internetowych. Zalety: redagowane przez ludzi, stąd ich struktura jest bardziej zrozumiała, a odpowiedzi na zapytania bardziej relewantne. Wady: w niektórych przypadkach nie można polegać na wynikach redakcji, ponieważ strony są przydzielane do poszczególnych kategorii wg indywidualnych kryteriów oceniającego, przyrost stron sprawia, że struktura katalogów staje się coraz mniej przejrzysta, im większy jest katalog, tym mniej jest on aktualny. Zastosowanie: do zawężania wyszukiwania, do przeszukiwania interesującej użytkownika wybranej części Internetu (nie całości tylko kategorii), do przeszukiwania Ukrytego Internetu.
, do przeszukiwania Ukrytego Internetu.")
10
Katalogi stron

11
Wyszukiwarki narzędzia wyposażone w roboty do indeksowania stron,
działają w oparciu o słowa kluczowe lub katalog tematów. Wyszukiwarka poszukuje podane słowa, a następnie wyświetla rezultaty w postaci listy adresów internetowych, w których opisie wystąpił podany wyraz, zwykle odsyłacze wzbogacane są o streszczenia i inne informacje, jak język, kategoria, odsyłacze do dokumentów podobnych, listy słów kluczowych itp. Zalety: we wszystkich aspektach mają przewagę nad katalogami, rejestrują więcej linków, są szybsze od katalogów, oferują dodatkowe opcje wyszukiwania. Wady: jedyną przewagą katalogów nad wyszukiwarkami jest dostępność recenzji dokumentów i opisów przygotowanych ręką ludzką, ale i tu wyszukiwarki zaczynają konkurować, bo firmy utrzymujące katalogi nie są w stanie recenzować rosnącej liczby nowych dokumentów ani weryfikować istniejących linków.

12
Typy wyszukiwarek Wg zawartości treściowej:
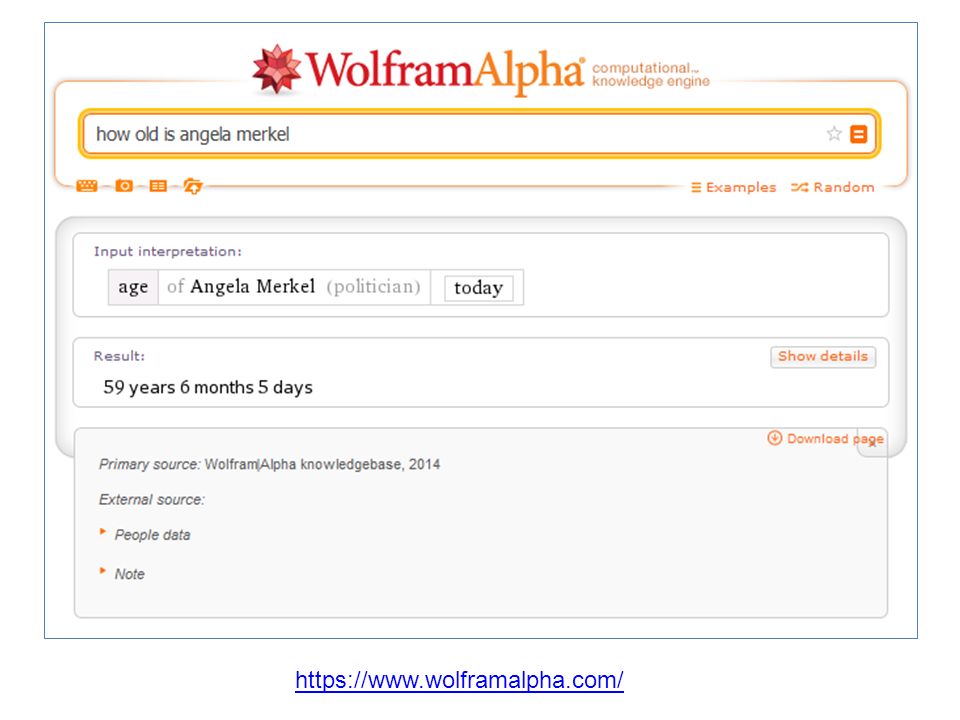
Ogólne, np. Google, Yahoo, Bing, Baidu, DuckDuck Go, P2P, np. Faroo, Yacy, Ludzi, np. InfoSpace, Wink, Comfibook, 1,2,3 people, Wiadomości, np. Daylife, Nexis, Trapit, Wg rodzajów/typów informacji: Blogów, np. Technorati, Regator, Bloglines, Map, np. OpenStreetMap, MapQuest, WikiMapia, Multimediów, np. Pixsta, Songza, Podscope, Pytań i odpowiedzi (automatycznych i generowanych przez ludzi), np. TrueKnowledge, BrainBoost, Answers.com, DeeperWeb, Wg modelu wyszukiwania: Semantyczne, np. Swoogle, Hakia, Yebol, Wykorzystujące serwisy prywatne użytkowników, np. DuckDuck Go, Open Source, np. Gigablast, Sciencenet, Sphinx, Społeczne, np. ChaCha Search, Wizualne, np. TinEye, Oolone,
, np. TrueKnowledge, BrainBoost, Answers.com, DeeperWeb, Wg modelu wyszukiwania: Semantyczne, np. Swoogle, Hakia, Yebol, Wykorzystujące serwisy prywatne użytkowników, np. DuckDuck Go, Open Source, np. Gigablast, Sciencenet, Sphinx, Społeczne, np. ChaCha Search, Wizualne, np. TinEye, Oolone,")
13
Formułowanie zapytań w wyszukiwarkach - rodzaje zapytań
Proste muzeum Złożone Muzeum Państwowe w Inowrocławiu Frazy „muzea polskie” Z operatorami Boole’a muzea NOT archiwa W języku naturalnym Jaki jest adres Muzeum Etnograficznego w Toruniu?

14
Wyszukiwanie w Google W przypadku grupy słów Google stosuje logikę boolowską (koniunkcja, negacja, sumowanie, itp). Domyślną regułą logiczną Google jest operacja AND. PRZYKŁAD: prawo uczeń student = wyszukane zostaną strony zawierające wszystkie wskazane słowa, lecz występujące niekoniecznie obok siebie i niekoniecznie w tej samej kolejności. Chcąc wyszukiwać wystąpienia dowolnego z podanych słów, konieczne jest zastosowanie operatora logicznego OR (dużymi literami!!!)) pomiędzy słowami: PRZYKŁAD: prawo OR uczeń OR student – wyświetlone zostaną strony zawierające słowo prawo lub uczeń lub student. Aby w wynikach wyszukiwania nastąpiło pogrupowanie podanych słów, konieczne jest umieszczenie niektórych słów w nawiasie: PRZYKŁAD: prawo (uczeń OR student) = odszukane zostaną strony odnoszące się do praw ucznia lub praw studenta. W przypadku, gdy chcemy wskazać element, który nie powinien wystąpić w wynikach wyszukiwania należy użyć znaku negacji – (minus bez spacji): PRZYKŁAD: prawo student –uczeń – wyszukiwarka zwróci strony poświęcone prawom studenta i wykluczy z wyszukiwania strony poświęcone prawom ucznia.
) pomiędzy słowami: PRZYKŁAD: prawo OR uczeń OR student – wyświetlone zostaną strony zawierające słowo prawo lub uczeń lub student. Aby w wynikach wyszukiwania nastąpiło pogrupowanie podanych słów, konieczne jest umieszczenie niektórych słów w nawiasie: PRZYKŁAD: prawo (uczeń OR student) = odszukane zostaną strony odnoszące się do praw ucznia lub praw studenta. W przypadku, gdy chcemy wskazać element, który nie powinien wystąpić w wynikach wyszukiwania należy użyć znaku negacji – (minus bez spacji): PRZYKŁAD: prawo student –uczeń – wyszukiwarka zwróci strony poświęcone prawom studenta i wykluczy z wyszukiwania strony poświęcone prawom ucznia.")
15
WIELKOŚĆ LITER: Google nie rozróżnia wielkości liter:
Przy wyszukiwaniu fraz, składających się z kilku słów, konieczne jest ujęcie ich w cudzysłów: PRZYKŁAD: "życie wsi" – zwróci adresy stron, na których – w dowolnym miejscu – podana fraza występuje przynajmniej raz, PRZYKŁAD: wpływ na "życie wsi" - zwróci adresy stron, na których przynajmniej raz występują słowa wpływ i na oraz co najmniej raz fraza ”życie wsi”, wszystkie podane wyrazy wystąpić mogą niekoniecznie w podanej kolejności. WIELKOŚĆ LITER: Google nie rozróżnia wielkości liter: identyczne traktowane będą frazy „LECH WAŁĘSA”, „lech wałęsa”, „LeCH WałęŚa”, czego efektem będą takie same wyniki wyszukiwania Google ma ograniczenie do 10 słów podanych jednocześnie w zapytaniu, obejmuje to również operatory logiczne. Jak to obejść? nie uwzględniać rodzajników ani łączników, np. the wall = wall, postawić na rzadkie lub specjalistyczne słowa, np. Pośród narodów - wyście nędzarzami!, Z dumą hidalgów nosicie łachmany, I odkrywacie światu swoje rany, Aby zarabiać na chleb krwią i łzami. (Asnyk) = * hidalgów * łachmany stosować znak zastępczy = patrz niżej Google nie obsługuje wykorzystywania znaków zastępczych w miejscu liter danego słowa (stemming), np. księga* = księgarstwo, księgarnia, księgarz. W zamian za to pozwala korzystać ze znaku zastępczego * (gwiazdki) umieszczanego w miejscu całego słowa, np. „trzy * myszy” = trzy zielone myszy, trzy ślepe myszy, trzy niesforne myszy, itd. Kiedy jest to przydatne? kiedy chcemy uniknąć ograniczenia do 10 słów w zapytaniu, np. A czymże jest prawdziwa męskość, jeśli nie wymieszanymi w odpowiednich proporcjach klasą i szaleństwem? (Sapkowski) = A czymże jest * kiedy mamy braki pamięci, np. w tekście piosenki Koniec nas już na horyzoncie ciemna [brak słowa] (chmura czy dziura???) (Cerekwicka) = Koniec nas już na horyzoncie ciemna *
 = * hidalgów * łachmany. stosować znak zastępczy = patrz niżej. Google nie obsługuje wykorzystywania znaków zastępczych w miejscu liter danego słowa (stemming), np. księga* = księgarstwo, księgarnia, księgarz. W zamian za to pozwala korzystać ze znaku zastępczego * (gwiazdki) umieszczanego w miejscu całego słowa, np. „trzy * myszy = trzy zielone myszy, trzy ślepe myszy, trzy niesforne myszy, itd. Kiedy jest to przydatne kiedy chcemy uniknąć ograniczenia do 10 słów w zapytaniu, np. A czymże jest prawdziwa męskość, jeśli nie wymieszanymi w odpowiednich proporcjach klasą i szaleństwem (Sapkowski) = A czymże jest * kiedy mamy braki pamięci, np. w tekście piosenki Koniec nas już na horyzoncie ciemna [brak słowa] (chmura czy dziura ) (Cerekwicka) = Koniec nas już na horyzoncie ciemna *")
16
Universal Search

17
Graf wiedzy

18
Składnia specjalna oprócz podstawowych operatorów AND i OR czy łańcuchów zapytań, wyszukiwarka Google oferuje rozbudowaną składnię specjalną, która rozszerza możliwości wyszukiwania, pozwala ona przeszukiwać określone elementy stron lub wyszukiwać szczególne rodzaje informacji, niektóre elementy można łączyć w celu uzyskania lepszego efektu, innych – nie. 1) intitle: ogranicza przeszukiwanie do tytułów stron, PRZYKŁAD: intitle:muzeum – zwraca strony zawierające w tytule strony słowo muzeum 2) inurl: ogranicza wyszukiwanie do adresów stron WWW, PRZYKŁAD: inurl:edu – zwraca strony, w których adresie wystąpi rozszerzenie edu
 intitle: ogranicza przeszukiwanie do tytułów stron, PRZYKŁAD: intitle:muzeum – zwraca strony zawierające w tytule strony słowo muzeum. 2) inurl: ogranicza wyszukiwanie do adresów stron WWW, PRZYKŁAD: inurl:edu – zwraca strony, w których adresie wystąpi rozszerzenie edu.")
19
Składnia specjalna cd. 3) intext: 4) inanchor: 5) site: 6) link:
powoduje przeszukiwanie wyłącznie treści stron, ignoruje hiperłącza, adresy stron i ich tytuły, PRZYKŁAD: intext:konserwacja – zwraca strony, w których treści wystąpi słowo konserwacja 4) inanchor: ogranicza wyszukiwanie do hiperłączy strony (podczas tworzenia hiperłaczy poza znacznikami html podawane są opisy, np. dla odsyłacza – podawany jest opis Wydawnictwo Helion), element inanchor: przeszukuje właśnie te opisy, PRZYKŁAD: inanchor:jacek – zwraca strony, które posiadają w swoich strukturach odsyłacze do stron zawierających w opisie słowo jacek (np. kurski, santorski, kuroń) 5) site: pozwala ograniczyć obszar wyszukiwania do dowolnej witryny lub domeny, PRZYKŁAD: rekrutacja site:umk.pl – zwraca strony podające zasady rekrutacji na UMK 6) link: zwraca listę stron, które zawierają odsyłacze do wskazanego adresu, PRZYKŁAD: link:tvn24.pl – zwraca strony, które zawierają łącza do serwisu TVN24.pl
 inanchor: ogranicza wyszukiwanie do hiperłączy strony (podczas tworzenia hiperłaczy poza znacznikami html podawane są opisy, np. dla odsyłacza – podawany jest opis Wydawnictwo Helion), element inanchor: przeszukuje właśnie te opisy, PRZYKŁAD: inanchor:jacek – zwraca strony, które posiadają w swoich strukturach odsyłacze do stron zawierających w opisie słowo jacek (np. kurski, santorski, kuroń) 5) site: pozwala ograniczyć obszar wyszukiwania do dowolnej witryny lub domeny, PRZYKŁAD: rekrutacja site:umk.pl – zwraca strony podające zasady rekrutacji na UMK. 6) link: zwraca listę stron, które zawierają odsyłacze do wskazanego adresu, PRZYKŁAD: link:tvn24.pl – zwraca strony, które zawierają łącza do serwisu TVN24.pl.")
20
Składnia specjalna cd. 7) filetype: 8) related: 9) info: 10) cache:
pozwala na wyszukiwanie różnych rodzajów plików, PRZYKŁAD: archiwa filetype:pdf – zwraca strony tematycznie dotyczące archiwów, zapisane w formacie pdf 8) related: wyszukuje strony podobne / pokrewne do wskazanej, PRZYKŁAD: related: – zwraca strony podobne do UMK, a więc szkół wyższych 9) info: pozwala wyświetlić hiperłącza do stron zawierających więcej informacji nt. wskazanej strony (poszukiwania obejmują hiperłacza, podstrony, strony zawierające wskazany adres), PRZYKŁAD: info: – wyświetlone zostaną odnośniki do stron zawierających kopię strony Wydawnictwa Helion, linki do tej strony i jej podstron oraz strony podobne 10) cache: odszukuje kopię strony zaindeksowaną przez Google, nawet jeśli oryginał strony nie jest już dostępny, PRZYKŁAD: cache: – zwraca archiwalną stronę wyszukiwarki Yahoo!
 related: wyszukuje strony podobne / pokrewne do wskazanej, PRZYKŁAD: related: – zwraca strony podobne do UMK, a więc szkół wyższych. 9) info: pozwala wyświetlić hiperłącza do stron zawierających więcej informacji nt. wskazanej strony (poszukiwania obejmują hiperłacza, podstrony, strony zawierające wskazany adres), PRZYKŁAD: info: – wyświetlone zostaną odnośniki do stron zawierających kopię strony Wydawnictwa Helion, linki do tej strony i jej podstron oraz strony podobne. 10) cache: odszukuje kopię strony zaindeksowaną przez Google, nawet jeśli oryginał strony nie jest już dostępny, PRZYKŁAD: cache: – zwraca archiwalną stronę wyszukiwarki Yahoo!")
21
Wyszukiwanie zaawansowane

22
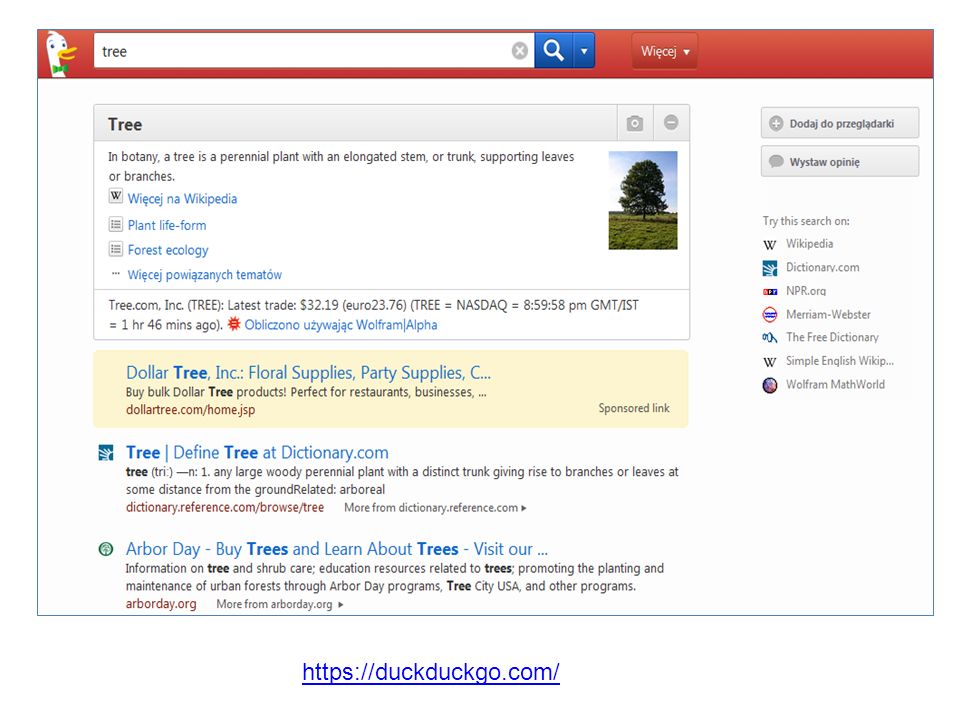
Wyszukiwarki

23
https://duckduckgo.com/
26
Wyszukiwarki zasobów naukowych

28
Multiwyszukiwarki narzędzia kierujące to samo zapytanie jednocześnie do kilku wyszukiwarek i łączące mniej lub bardziej jednorodne wyniki na jednej stronie, sam proces poszukiwania odbywa się po kolei, tzn. w określonym czasie multiwyszukiwarka łączy się i pobiera dane z każdej wyszukiwarki bądź katalogu. Uzyskane w ten sposób odnośniki są odpowiednio porządkowane i wyświetlane, czasem przy zachowaniu podziału na poszczególne wyszukiwarki. Rezultaty poszukiwań "spływają" na ekran bardzo szybko i nie trzeba czekać, aż załadują się wszystkie. Multiwyszukiwarki zapewniają najlepsze rezultaty w połączeniu z najwyższym komfortem użytkowania. Zalety: duża prędkość przy możliwości otrzymania bardziej reprezentatywnej listy wyników. Wady: można zadawać tylko proste pytania z uwagi na różnorodność dostępnych opcji w różnych wyszukiwarkach. Najpopularniejsze multiwyszukiwarki: Dogpile, Tinooo, Mamma, Search.com, Yippy, SurfWax, Excite, DeeperWeb, ZOO (dawny Metacrawler), clic2find, Polymeta.
, clic2find, Polymeta.")
32
Portale i wortale Portal to rodzaj serwisu informacyjnego, który zwykle zawiera skrót wiadomości dnia, pogodę, horoskopy, czasem darmowe konta pocztowe, fora dyskusyjne, chat rooms, a nawet darmowe publikowanie stron WWW. Zwykle istnieje też mały katalog popularnych tematów (muzyka, "gwiazdy", linki do oprogramowania). Np. Onet.pl, Interia.pl, Wirtualna Polska, Academicon. Wortal to portal wyspecjalizowany, publikujący informacje z jednej dziedziny, tematycznie do siebie zbliżone, np. dotyczące muzyki, filmu, programów komputerowych. Nazwa ma stanowić przeciwstawienie do zwykłego portalu, obejmującego szeroki zakres tematyczny (horyzontalnego), a przy okazji podkreślać wyższą jakość udostępnianych zasobów, jednak nie przyjęła się szeroko. Np. Salon książki muzealnej, Narodowy Instytut Muzealnictwa i Ochrony Zabytków, Wortal Rewitalizacja, Antyki.info – Wortal Antykwaryczny.
. Np. Onet.pl, Interia.pl, Wirtualna Polska, Academicon. Wortal to portal wyspecjalizowany, publikujący informacje z jednej dziedziny, tematycznie do siebie zbliżone, np. dotyczące muzyki, filmu, programów komputerowych. Nazwa ma stanowić przeciwstawienie do zwykłego portalu, obejmującego szeroki zakres tematyczny (horyzontalnego), a przy okazji podkreślać wyższą jakość udostępnianych zasobów, jednak nie przyjęła się szeroko. Np. Salon książki muzealnej, Narodowy Instytut Muzealnictwa i Ochrony Zabytków, Wortal Rewitalizacja, Antyki.info – Wortal Antykwaryczny.")
35
Subject gateways dziedzinowe przewodniki po wysokiej jakości zasobach internetowych (dokumentach, obiektach, witrynach, serwisach), przeznaczone głównie dla środowisk naukowych. selekcjonowane, oceniane, opisywane i katalogowane przez bibliotekarzy lub ekspertów z danej dziedziny, najczęściej ukierunkowane na dziedziny związane z obszarami zainteresowań akademickich, linki zgromadzone w tych serwisach dobiera się zgodnie z oficjalnie opublikowaną listą kryteriów oceny jakości, a następnie kataloguje się je i opisuje również według powszechnie stosowanych systemów klasyfikacyjnych, w porównaniu z ogólnymi i niekiedy przypadkowymi wykazami linków, subject gateways są bardziej pracochłonne, ale w rezultacie dają zbiór (bazę danych) o kontrolowanej jakości, który może być przeszukiwany według słów kluczowych i kategorii tematycznych, Przykłady: Infomine, ipl2, Intute, Complete Planet, Academic Info, Ekonomia online, Historicus, BazTol.
, przeznaczone głównie dla środowisk naukowych. selekcjonowane, oceniane, opisywane i katalogowane przez bibliotekarzy lub ekspertów z danej dziedziny, najczęściej ukierunkowane na dziedziny związane z obszarami zainteresowań akademickich, linki zgromadzone w tych serwisach dobiera się zgodnie z oficjalnie opublikowaną listą kryteriów oceny jakości, a następnie kataloguje się je i opisuje również według powszechnie stosowanych systemów klasyfikacyjnych, w porównaniu z ogólnymi i niekiedy przypadkowymi wykazami linków, subject gateways są bardziej pracochłonne, ale w rezultacie dają zbiór (bazę danych) o kontrolowanej jakości, który może być przeszukiwany według słów kluczowych i kategorii tematycznych, Przykłady: Infomine, ipl2, Intute, Complete Planet, Academic Info, Ekonomia online, Historicus, BazTol.")
39
Bibliograficzne bazy danych
Bibliografia polska BN SYMPOnet BazTech BazHum BazEkon Arianta Bazy w portalu Nauka Polska

40
Katalogi centralne WorldCat https://www.worldcat.org/
Nukat Karo

41
Dziedzinowe bazy danych
Nazwa bazy Zakres Dostęp Academic Search Complete Ogólnodziedzinowa Subskrypcja Arachne Archeologia, historia sztuki wolny Arts & Humanities Citation Index Sztuka, nauki humanistyczne Subskrypcja, Wirtualna Biblioteka Nauki Eric Edukacja, pedagogika, psychologia Wolny Elsevier zarządzanie m.in. wiedzą, zasobami ludzkimi, środowiskiem, informacją Wirtualna Biblioteka Nauki Mendeley Multidyscyplinarna NIMOZ Bazy muzeów, zabytków, strat wojennych, pracowni konserwatorskich Web of Science bazy bibliometryczno-abstraktowe na platformie ISI Web of Knowledge

42
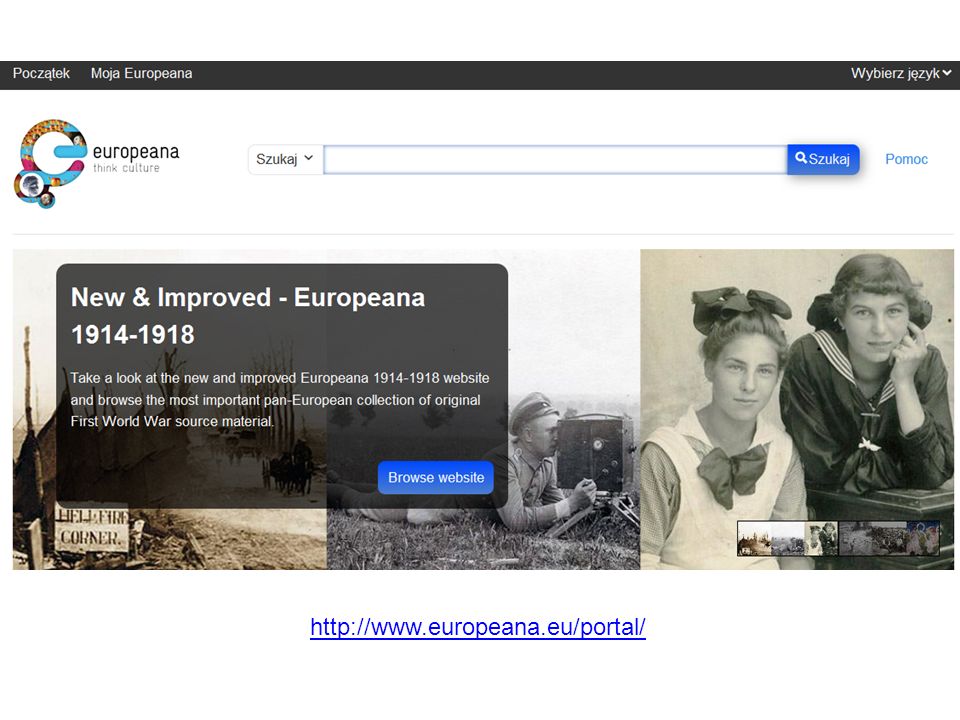
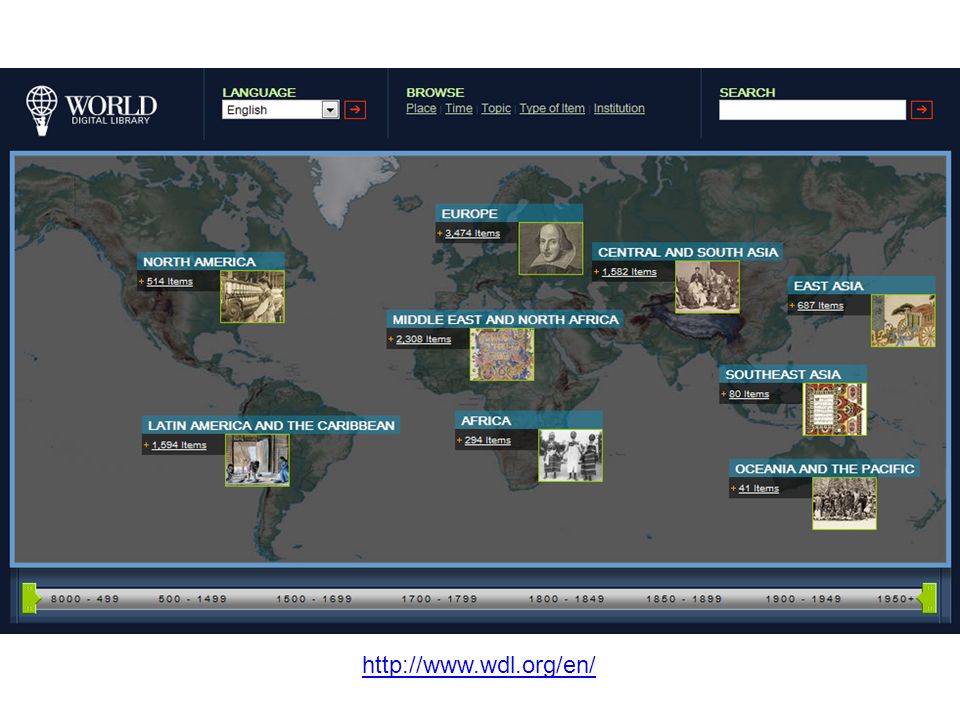
Biblioteki cyfrowe Polskie Biblioteki Cyfrowe (FBC), Europeana,
World Digital Library, American Memory Historical Collections, Digitale Sammlungen.

46
Repozytoria

48
Atrybuty jakości informacji

49
Zadanie

Podobne prezentacje