Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Wielowymiarowe metody analizy i wizualizacji danych

2
9 zmiennych – korelacje każdej z każdą

5
Współwystępowanie kategorii wykształcenia, miejsca zamieszkania i dochodu oraz miejsca zakupu ekożywności

6
Analiza skupień Analiza skupień jest techniką wielowymiarową pozwalającą wykrywać współzależności między obiektami. Związana jest ściśle z zagadnieniami klasyfikowania i porządkowania otaczającej nas rzeczywistości

7
Cele analizy skupień Eksploracja danych Kontrola danych Poszukiwanie obiektów nietypowych (odstających) Wykrycie wewnętrznej struktury obiektów Wykrywanie współzależności między zmiennymi Typologia Weryfikacja istniejącej typologii Propozycje klasyfikacji obiektów Redukcja danych Agregacja danych Wybór reprezentantów grup

8
Odwzorowanie obiektów w przestrzeni n - wymiarowej
Obiekt opisany za pomocą n zmiennych X1, X2,…Xn przedstawiamy jako punkt x=(x1,…,xn) w przestrzeni n-wymiarowej Celem podziału na grupy jest, aby obiekty podobne (reprezentowane przez punkty znajdujące się blisko siebie w przestrzeni) znalazły się w tej samej grupie, a obiekty niepodobne (reprezentowane przez punkty leżące w dużej odległości w przestrzeni) znalazły się w różnych grupach
 w przestrzeni n-wymiarowej. Celem podziału na grupy jest, aby obiekty podobne (reprezentowane przez punkty znajdujące się blisko siebie w przestrzeni) znalazły się w tej samej grupie, a obiekty niepodobne (reprezentowane przez punkty leżące w dużej odległości w przestrzeni) znalazły się w różnych grupach.")
9
Analiza skupień (przykład obiektów dających podzielić się na 5 grup)
")
10
Problemy do rozstrzygnięcia
Jak odwzorować obiekty w przestrzeni? Wybór zmiennych Normalizacja zmiennych Jak mierzyć odległości między obiektami? Jaką metodę grupowania zastosować?

11
Normalizacja Normalizacja ma na celu doprowadzenie obiektów lub zmiennych do porównywalnych wielkości. Problem ten dotyczy zmiennych mierzonych w różnych jednostkach (np. sztuki, czas, waluta). Przykład Rozważmy 3 obiekty i dwie zmienne: wiek osoby mierzony w latach i jej dochód mierzony w złotych lub tys. zł.
. Przykład. Rozważmy 3 obiekty i dwie zmienne: wiek osoby mierzony w latach i jej dochód mierzony w złotych lub tys. zł.")
12
Przekształcenia liniowe zmiennych - (standaryzacja)
, gdzie Współczynnik A nie wpływa na odległości między obiektami Współczynnik B pełni rolę czynnika skalującego. Szczególnie ważnym rodzajem przekształcenia jest standaryzacja

13
Metryka przestrzeni Odległość euklidesowa
Odległość Minkowskiego Jej szczególnymi przypadkami są: odległość miejska (p=1) odległość euklidesowa (p=2) odległość Czebyszewa (p= ) ponadto kwadrat odległości euklidesowej
 odległość euklidesowa (p=2) odległość Czebyszewa (p= ) ponadto kwadrat odległości euklidesowej.")
14
Optymalizacyjno-iteracyjne
Metody grupowania Hierarchiczne tworzą drzewa binarne Optymalizacyjno-iteracyjne poprawiają wstępny podział w kolejnych iteracjach Pozostałe np. tworzą skupienia nierozłączne, niezupełne, rozmyte

15
Metody hierarchiczne Metody najczęściej stosowane w praktyce. Uzyskana hierarchia (jedne skupienia zawierają się w innych) pozwala na uzyskanie pełnej informacji o strukturze skupień. Ograniczenie tych metod to wymagania pamięci, co powoduje, że w przypadku dużych zbiorów danych nie mogą być stosowane. Metody hierarchiczne dzielimy na metody aglomeracyjne i podziałowe. Punktem wyjścia w metodach aglomeracyjnych jest określenie odległości pomiędzy obiektami. metody aglomeracyjne C A S E Label Num I I metody podziałowe
 pozwala na uzyskanie pełnej informacji o strukturze skupień. Ograniczenie tych metod to wymagania pamięci, co powoduje, że w przypadku dużych zbiorów danych nie mogą być stosowane. Metody hierarchiczne dzielimy na metody aglomeracyjne i podziałowe. Punktem wyjścia w metodach aglomeracyjnych jest określenie odległości pomiędzy obiektami. metody aglomeracyjne. C A S E Label Num I I metody podziałowe.")
16
Metody aglomeracyjne Najbliższego sąsiedztwa Najdalszego sąsiedztwa Mediany Środka ciężkości Średniej odległości wewnątrz skupień Średniej odległości między skupieniami Minimalnej wariancji Warda

17
Porównanie sposobu wyznaczania odległości między skupieniami w wybranych metodach aglomeracyjnych
metoda najbliższego sąsiedztwa metoda najdalszego sąsiedztwa metoda mediany metoda środka ciężkości metoda średniej grupowej

18
metoda najbliższego sąsiedztwa metoda najdalszego sąsiedztwa
metoda mediany metoda średniej grupowej metoda środka ciężkości metoda Warda

19
Metody optymalizacyjno-iteracyjne (k-średnich)
Ustalamy liczbę grup (k) Wybieramy (w sposób losowy lub ustalony z góry) k punktów przestrzeni, stanowiących tzw. zalążki środków ciężkości skupień (cluster seeds) Każdy z obiektów (i=1,...,n) przydzielamy do grupy o najbliższym dla niego środku ciężkości Dla (j=1,...,k) obliczamy nowe środki ciężkości jako średnie arytmetyczne wszystkich obiektów należących do danej grupy Powtarzamy kroki 3 i 4 aż do chwili, gdy nie następują przesunięcia obiektów między grupami
 Wybieramy (w sposób losowy lub ustalony z góry) k punktów przestrzeni, stanowiących tzw. zalążki środków ciężkości skupień (cluster seeds) Każdy z obiektów (i=1,...,n) przydzielamy do grupy o najbliższym dla niego środku ciężkości. Dla (j=1,...,k) obliczamy nowe środki ciężkości jako średnie arytmetyczne wszystkich obiektów należących do danej grupy. Powtarzamy kroki 3 i 4 aż do chwili, gdy nie następują przesunięcia obiektów między grupami.")
20
Metody optymalizacyjno-iteracyjne (k-średnich)
Jednocześnie obliczana jest funkcja błędu podziału - ogólna suma kwadratów odległości wewnątrzgrupowych liczonych od środków ciężkości grup: tzn. gdzie d jest odległością euklidesową. W praktyce proces jest zbieżny po kilku lub kilkunastu iteracjach.

21
Ustalanie liczby skupień
Liczbę skupień wybiera się na podstawie przesłanek merytorycznych albo szacuje się je metodami hierarchicznymi. Można dokonać obliczeń dla wszystkich wartości k z ustalonego przedziału: Możliwe są różne podejścia: Arbitralny sposób np. przyjmuje się współrzędne pierwszych k obiektów (nie zawierające braków danych) jako zalążki środków ciężkości . Losowy wybór środków ciężkości, przy czym może to być losowy wybór k obiektów ze zbioru danych albo losowy wybór k punktów przestrzeni niekoniecznie pokrywających się z położeniem obiektów. Wykorzystanie algorytmu optymalizującego w pewien sposób położenie początkowych środków ciężkości np. przez uwzględnianie k obiektów leżących daleko względem siebie. Przyjęcie jako początkowych środków ciężkości uzyskanych na podstawie podziału otrzymanego inna metodą, głównie jedną z metod hierarchicznych.
 jako zalążki środków ciężkości . Losowy wybór środków ciężkości, przy czym może to być losowy wybór k obiektów ze zbioru danych albo losowy wybór k punktów przestrzeni niekoniecznie pokrywających się z położeniem obiektów. Wykorzystanie algorytmu optymalizującego w pewien sposób położenie początkowych środków ciężkości np. przez uwzględnianie k obiektów leżących daleko względem siebie. Przyjęcie jako początkowych środków ciężkości uzyskanych na podstawie podziału otrzymanego inna metodą, głównie jedną z metod hierarchicznych.")
22
SKUPIENIE (CLUSTER) – układ podobnych obiektów
SKUPIENIE (CLUSTER) – układ podobnych obiektów. Podobieństwo pary obiektów należących do danego skupienia jest większe niż podobieństwo obiektów należących do różnych grup. Skupienia są rozłączne – jeden obiekt należy tylko do jednej kategorii.
 – układ podobnych obiektów. Podobieństwo pary obiektów należących do danego skupienia jest większe niż podobieństwo obiektów należących do różnych grup. Skupienia są rozłączne – jeden obiekt należy tylko do jednej kategorii.")
23
Środek ciężkości– punkt, którego współrzędne równe są wartościom średnim zmiennych, ale tylko dla obiektów należących do tego skupienia.

24
Procedura aglomeracyjna
Macierz n obserwacji i p zmiennych jest znana. Konstruujemy macierz odległości: i,k=1,2,..,n dik – odległość między dwoma obiektami Szukamy pary obiektów najbardziej podobnych (o najmniejszej odległości). Łączymy je w pierwsze skupienie. Środek ciężkości tego skupienia wyznaczany jest jako średnia wartość każdej zmiennej dla tych dwóch obiektów.
. Łączymy je w pierwsze skupienie. Środek ciężkości tego skupienia wyznaczany jest jako średnia wartość każdej zmiennej dla tych dwóch obiektów.")
25
2. Wymiar macierzy D redukujemy o 1. I znowu liczymy odległości…
3. Krok 1 i 2 powtarzamy do momentu, aż wszystkie obiekty znajdą się w jednym skupieniu.

27
Przykład: 10 uniwersytetów, opisanych przez 3 zmienne: X1 – liczba studentów (2005) X2 – liczba studentów studiów doktoranckich (2005) X3 – liczba profesorów (2005)
")
28
Standaryzacja – ponieważ zmienne wyrażone są w różnych jednostkach

29
KROK 1. macierz odległości D
Najmniejszy dystans – dla obserwacji 5 i 8. To pierwsze skupienie. Powinien tu być wyznaczony środek ciężkości.

30
Dla każdej zmiennej należy obliczyć średnią z t wartości dla dwóch obserwacji – i to jest środek ciężkości tego nowopowstałego skupienia.

31
KROK 2. macierz odległości D z uwzględnieniem nowego skupienia

32
Teraz jest już 8 skupień. Łączymy dalej (kontynuujemy procedurę aglomeracyjną).
.")
33
Ostatni etap procedury aglomeracyjnej ukazuje obserwację 9 jako obserwację odstająca (brak przynależności do jakiegokolwiek skupienia), pozostałe obserwacje są w jednym skupieniu. Macierz odległości D: Ostatnia odległość to 4,151 –między obserwacjami 1-8 i 10 oraz 9. To już koniec procedury – nareszcie wszystkie obiekty są w jednym skupieniu. Ale czy o to nam chodziło?

34
Jak wybrać liczbę skupień?
Dendrogram – ilustruje łączenia obserwacji na poszczególnych poziomach (etapach) procedury aglomeracyjnej. ‘Ucinamy” ramiona w miejscu, gdzie zaczynają być dłuższe – oznacz to, ze nie ma wiązań i skupienia składają się z różniących się od siebie obserwacji. Ale to zawsze jest NASZA decyzja…
 procedury aglomeracyjnej. ‘Ucinamy ramiona w miejscu, gdzie zaczynają być dłuższe – oznacz to, ze nie ma wiązań i skupienia składają się z różniących się od siebie obserwacji. Ale to zawsze jest NASZA decyzja…")
35
Skupienie 1: obserwacje 2, 4, 3, 10, 1, 7
Skupienie 3: obserwacja 9 Podobne? Pod jakim względem? Porównajmy średnie (group mean –średnia dla grupy; grand mean – średnia dla całości Grupa 1 (Skupienie 1: obserwacje 2, 4, 3, 10, 1, 7) Nic ciekawego ;-)
 Nic ciekawego ;-)")
36
Najgorsza - średnia grupy dla każdej zmiennej o wiele niższa niż średnia dla całości zbioru
Najlepsza - średnia grupy dla każdej zmiennej o wiele wyższa niż średnia dla całości zbioru

37
X1 X2 X3

38
Metoda k-średnich Tworzymy k skupień. Ze wszystkich danych wybieramy k punktów (wybór dowolny). To są pierwsze środki ciężkości. Każdy punkt powinien być dołączony do jednego ze środków ciężkości (najbliższego). Po dołączeniu obserwacji, liczymy środki ciężkości. Krok 2 i 3 powtarzamy do momentu, aż obiekty przestana się ‘przemieszczać’ między skupieniami.
. Po dołączeniu obserwacji, liczymy środki ciężkości. Krok 2 i 3 powtarzamy do momentu, aż obiekty przestana się ‘przemieszczać’ między skupieniami.")
39
A oraz E są losowo wybrane jako centra skupień.
C ma bliżej do A niż do E, więc skupienie 2 zawiera A, B, C a skupienie 2 zawiera D oraz E (czerwone kropki oznaczają środki ciężkości skupień) . Teraz C ma bliżej środka ciężkości skupienia 2, będzie wiec przeniesione ze skupienia 1 do 2.
 . Teraz C ma bliżej środka ciężkości skupienia 2, będzie wiec przeniesione ze skupienia 1 do 2.")
40
Przykład: 10 uniwersytetów, opisanych przez 3 zmienne: X1 – liczba studentów (2005) X2 – liczba studentów studiów doktoranckich (2005) X3 – liczba profesorów (2005)
")
41
Decydujemy się na 3 skupienia
Decydujemy się na 3 skupienia. Ze względu na różne jednostki zmiennych, najpierw przeprowadzamy standaryzację. Pierwsze trzy obiekty to centra skupień.

42
Liczymy odległości obiektów od środka ciężkości
Liczymy odległości obiektów od środka ciężkości. Przyłączamy obiekty do najbliższego im skupienia.

43
Mamy takie skupienia:

44
Dla każdego skupienia policzono środek ciężkości, a następnie odległość obiektów od środka ciężkości:

45
Teraz jest inna konfiguracja obiektów:

46
I znowu – liczymy odległości obiektów od środka ciężkości.

47
Mamy następujące skupienia:

48
I znowu – liczymy odległości obiektów od środka ciężkości.

49
A teraz takie skupienia:

50
I znowu – liczymy odległości obiektów od środka ciężkości.
Te skupienia i poprzednie są takie same, konfiguracja obiektów już się więc nie zmieni. Nareszcie koniec

51
Mieliśmy 55 zmiennych!

53
Analiza czynnikowa zaletą jest możliwość odkrycia zmiennych bezpośrednio nieobserwowalnych, które wyjaśniają wzajemne powiązania między zmiennymi rzeczywistymi (obserwowalnymi). Identyfikacja ukrytych cech oznacza wyodrębnienie kryteriów segmentacji post hoc. może być użyta w celu konstrukcji map percepcji, ukazujących konfigurację badanych segmentów w przestrzeni wielowymiarowej.
. Identyfikacja ukrytych cech oznacza wyodrębnienie kryteriów segmentacji post hoc. może być użyta w celu konstrukcji map percepcji, ukazujących konfigurację badanych segmentów w przestrzeni wielowymiarowej.")
54
Do podstawowych celów analizy czynnikowej zalicza się:
W analizie czynnikowej przyjmuje się, że liczba obserwacji powinna co najmniej 5- krotnie przewyższać liczbę pierwotnych zmiennych. Do podstawowych celów analizy czynnikowej zalicza się: identyfikację ukrytych czynników wspólnych, redukcję wymiaru przestrzeni zmiennych, ortogonalizację przestrzeni, w której zlokalizowane są obiekty, identyfikację charakteru zmiennych, prezentację graficzną nowopowstałego układu.

55
Funkcje analizy czynnikowej
redundancyjna – zmniejszenie liczby zmiennych bez istotnej straty informacji, poznawcza – formułowanie hipotez dotyczących istnienia i natury prawidłowości kształtujących związki między zjawiskami, weryfikacyjna – sprawdzenie poprawności powyższych hipotez, deskryptywna – opis zjawisk zdefiniowanych przez wyodrębnione czynniki, delimitacyjna – porządkowanie i usytuowanie obiektów w przestrzeni czynników.

56
Kiedy stosować? Gdy większość zmiennych jest skorelowana w statystycznie istotny sposób. miara adekwatności próby - wskaźnik KMO (Kaisera-Meyera-Olkina); umożliwia określenie stopnia, w jakim zmienne są ze sobą powiązane: Przyjmuje wartości od 0 do 1. Wartość > 0,6 jest przesłanką do stosowania analizy czynnikowej.
; umożliwia określenie stopnia, w jakim zmienne są ze sobą powiązane: Przyjmuje wartości od 0 do 1. Wartość > 0,6 jest przesłanką do stosowania analizy czynnikowej.")
57
Kryteria wyboru liczby czynników
metoda wartości własnej większej od jedności (λ>1) – powinna być stosowana wówczas, jeżeli liczba zmiennych jest większa od 20, w przeciwnym razie istnieje ryzyko wyodrębnienia zbyt małej liczby czynników. Reguła wartości własnej większej od 1 wynika stąd, że każdy czynnik powinien wyjaśniać zmienność przynajmniej jednej zmiennej.
 – powinna być stosowana wówczas, jeżeli liczba zmiennych jest większa od 20, w przeciwnym razie istnieje ryzyko wyodrębnienia zbyt małej liczby czynników. Reguła wartości własnej większej od 1 wynika stąd, że każdy czynnik powinien wyjaśniać zmienność przynajmniej jednej zmiennej.")
58
Wartość własna 1 3,791 2 1,752 3 1,087 4 0,313 5 0,152 6 0,094

59
metoda odsetka wyjaśnionej wariancji; bierze się pod uwagę tylko te czynniki, które wyjaśniają łącznie 70, 80 lub 90% wariancji, a żaden następny nie tłumaczy więcej niż 5% wariancji. Udział wariancji wyjaśnianej przez kolejne czynniki (główne składowe) w całkowitej wariancji jest bowiem coraz mniejszy, przy czym największy jest udział wariancji pierwszej głównej składowej i to właśnie przez nią wyjaśniona jest największa część całkowitej zmienności.
 w całkowitej wariancji jest bowiem coraz mniejszy, przy czym największy jest udział wariancji pierwszej głównej składowej i to właśnie przez nią wyjaśniona jest największa część całkowitej zmienności..")
60
% wyjaśnionej wariancji
Wartość własna % wyjaśnionej wariancji 1 3,791 54,2 2 1,752 25,0 3 1,087 12,7 4 0,313 4,5 5 0,152 2,2 6 0,094 1,3 7 0,006 0,1

61
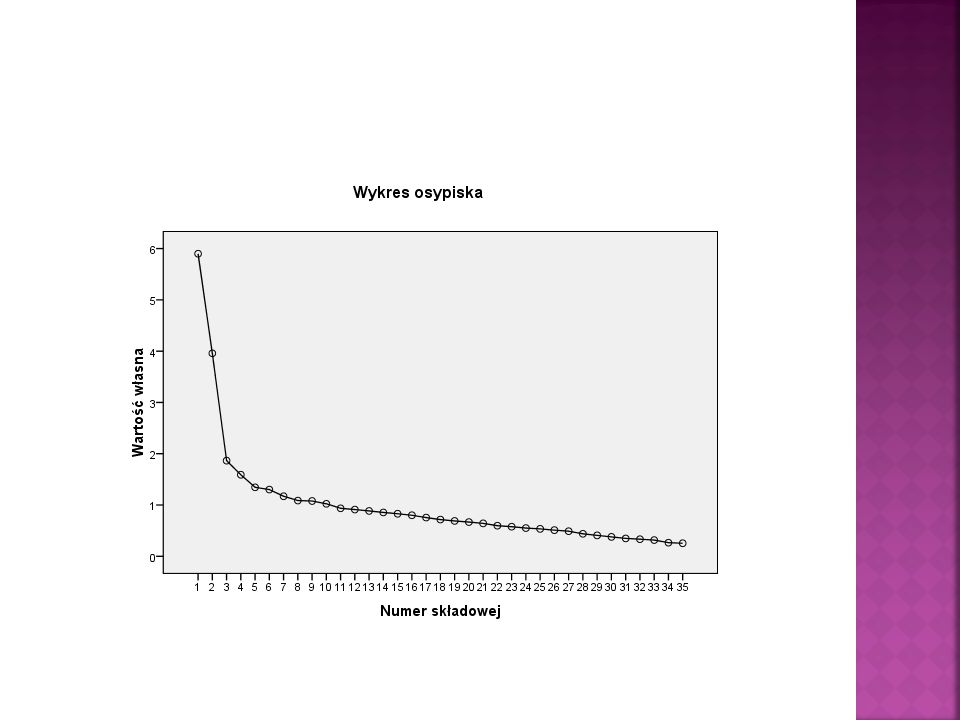
metoda testu osypiska (zaproponowanego przez Cattela); polega na sporządzeniu wykresu, w którym na osi odciętych zaznaczana jest liczba czynników, a na osi rzędnych – uzyskane wartości własne. Punkty załamania się krzywej wskazują na liczbę czynników.

63
Liczbę czynników określa się przed rotacją, zaś decyzje o liczbie czynników powinno się rozważyć w połączeniu z wiedzą merytoryczną o danym zagadnieniu, nie tylko na drodze mechanicznych wyborów. Miarą pomocną w rozwiązaniu tego zagadnienia są też wartości ładunków czynnikowych. Ładunki czynnikowe wyrażają stopień nasycenia zmiennej danym czynnikiem i stanowią - dla nieskorelowanych czynników - współczynniki korelacji pomiędzy zmienną pierwotną a poszczególnymi czynnikami. Im wyższa wartość ładunku czynnikowego, tym bardziej istotna jest ta zmienna dla danego czynnika. Wartości ładunków czynnikowych stanowią więc podstawę końcowej merytorycznej interpretacji wyników.

64
Rotacja varimax jest najczęściej stosowana
Rotacja varimax jest najczęściej stosowana. Upraszcza ona interpretację czynników poprzez minimalizację liczby zmiennych potrzebnych do wyjaśnienia danego czynnika. Rotacja quartimax upraszcza interpretację zmiennych poprzez minimalizację czynników potrzebnych do wyjaśnienia danej zmiennej.

65
Wyniki analizy Charakterystyka Główna składowa 1 2 3 4 Wart.ład.czyn.
Świeżość -0,062 0,903 0,168 0,076 Smak i zapach -0,837 0,031 -0,118 -0,282 Wygląd -0,187 -0,102 0,019 0,851 Wartość odżywcza 0,036 0,072 0,952 -0,097 Łatwość przygotowania -0,116 0,984 0,066 Cena -0,879 -0,069 -0,202 -0,179 Reklama 0,117 0,315 -0,363 0,796

66
Wyniki analizy – prezentacja graficzna

67
ANALIZA CONJOINT

68
Wybory Wybór partnera Wybór funduszu emerytalnego
Wybór samochodu, szkoły Wybór gazety, programu telewizyjnego, strony internetowej, stacji radiowej Wybór kawy, piwa, czekolady

69
Motywy Co skłania ludzi do podejmowania określonych decyzji?
Jak spośród różnorodnych przyczyn wyłowić te, które są istotne? W jaki sposób zdefiniować problem? Co tak naprawdę jest przedmiotem zainteresowania? W jaki sposób mierzyć? W jaki sposób przeformułować pytanie, by badanie dostarczyło przydatnych odpowiedzi? Jakie zastosować metody?

70
Pytania Można zapytać wprost:
Czym kieruje się Pan(i) podczas zakupu… Czy był(a)by Pan(i) skłonna zapłacić więcej za produkt, który byłby/miałby… Czy był(a)by Pan(i) skłonna kupić… Można zrobić ankiety, fokusy, wywiady indywidualne Można eksperymentować: W warunkach naturalnych, na swojej firmie W warunkach laboratoryjnych, na próbie respondentów Można przy tym… zwariować ;-)
 podczas zakupu… Czy był(a)by Pan(i) skłonna zapłacić więcej za produkt, który byłby/miałby… Czy był(a)by Pan(i) skłonna kupić… Można zrobić ankiety, fokusy, wywiady indywidualne. Można eksperymentować: W warunkach naturalnych, na swojej firmie. W warunkach laboratoryjnych, na próbie respondentów. Można przy tym… zwariować ;-)")
71
Skomplikowana rzeczywistość
Na decyzję konsumenta wpływa wiele zmiennych Nie zbadamy wszystkich (ani zmiennych, ani konsumentów) Nie ma metod idealnych
 Nie ma metod idealnych.")
72
Przykład problemu Czy konsumenci skłonni byliby zapłacić więcej za produkty wytworzone zgodnie z zasadami społecznej odpowiedzialności? Jakie znaczenie ma etykieta społecznej odpowiedzialności pośród innych cech produktu?

73
Fazy badania Definicje i zawężanie problemu:
Konsument => student WSIiZ, zazwyczaj znajomy(a) uczestnika projektu Produkt => kawa Czynniki wpływu => cechy produktu Społeczna odpowiedzialność => etykieta na opakowaniu, informująca o tym, że kawa została wyprodukowana bez szkody dla ludzi lub środowiska naturalnego
 uczestnika projektu. Produkt => kawa. Czynniki wpływu => cechy produktu. Społeczna odpowiedzialność => etykieta na opakowaniu, informująca o tym, że kawa została wyprodukowana bez szkody dla ludzi lub środowiska naturalnego.")
74
Ogólny plan badania DECYZJA KAWA CECHA1 CECHA2 CECHA3 CECHA4 CECHA5
Konsument podejmuje decyzję o wyborze produktu na podstawie jego cech.

75
Ogólny plan analizy PREFERENCJE ZMIENNE NIEZALEŻNE ZMIENNA ZALEŻNA
KAWA PREFERENCJE CECHA 1 CECHA 2 CECHA 3 CECHA 4 CECHA 5

76
Istota analizy conjoint
Masz duży problem? Rozbij go na mniejsze!

77
Istota analizy conjoint
Dekompozycja, czyli rozbicie całościowego wpływu wiązki zmiennych na indywidualny wpływ każdej z nich. Respondent zachowuje się pod wpływem zestawu zmiennych, postrzeganego całościowo – jak w warunkach naturalnych.

78
Jaka kawa? Jakie zmienne niezależne?
CENA 10 zł 20 zł WAGA 100 g 250 g KRAJ Indie Kolumbia RODZAJ rozpuszczalna mielona ETYKIETA społecznej odpowiedzialności społeczna wewnętrzna społeczna zewnętrzna ekologiczna etykieta neutralna Liczba wszystkich wariantów = 2 x 2 x 2 x 2 x 4 = 64

79
Jakie preferencje? Jaka zmienna zależna?
Sortowanie – od najbardziej do najmniej atrakcyjnej wersji produktu (od 1 do n, gdzie n jest liczbą wszystkich wariantów produktu) Przypisanie liczby punktów, wyrażającej atrakcyjność wariantu (np. z zakresu 1-100)
 Przypisanie liczby punktów, wyrażającej atrakcyjność wariantu (np. z zakresu 1-100)")
80
Idea Jak oszacować wpływ netto każdej zmiennej niezależnej,
skoro jedne zmienne bywają ilościowe, porządkowe i nominalne, a całkowita liczba wariantów nie powinna zadręczyć respondenta.

81
Plan ortogonalny Sposób wyboru możliwie małej liczby wariantów do badania, o ile zmienne niezależne wpływają naprawdę niezależnie.

82
Analiza danych Dysponując informacją o tym, jakie cechy posiadają badane warianty, oraz o tym, jak respondenci ocenili każdy z tych wariantów, możemy łatwo oszacować wpływ netto każdej cechy na ocenę danego wariantu, korzystając z metody CONJOINT.

83
2. Informacja o preferencjach respondentów.
Ogólny plan działania 1. Informacja o badanych wariantach, utworzonych w planie ortogonalnym. 2. Informacja o preferencjach respondentów. Kawa 1 1. Kawa 9 Kawa 2 2. Kawa 6 … … Kawa k k. Kawa 4

84
Wyniki Wpływ każdej ze zmiennych (= czynników) na preferencje badanych
KAWA CECHA1 10% wpływu CECHA2 35% wpływu CECHA3 10% wpływu CECHA4 15% wpływu CECHA5 30% wpływu

85
Wyniki Wpływ każdej wartości danej zmiennej (= każdego poziomu danego czynnika) na preferencje badanych KAWA Kolumbia KRAJ Indie mielona RODZAJ rozpuszczalna

86
Wyniki Obliczanie atrakcyjności (= użyteczności) każdego wariantu CENA WAGA KRAJ RODZAJ + + + + 10 zł 250 g Kolumbia mielona + = ekologiczna KAWA DOSKONAŁA

87
Ograniczenia, warunki Brak interakcji między zmiennymi niezależnymi
Brak założeń co do wielkości próby Zakładamy, że na decyzję respondenta wpływają wyłącznie cechy produktu

88
Możliwości Wyniki dla pojedynczego respondenta
Wyniki dla grup respondentów Miary dopasowania modelu do rzeczywistości Symulowanie preferencji wobec wariantów, które nie brały udziału w badaniu Szacowanie udziałów w rynku dla różnych wariantów produktu Segmentacja respondentów

89
Conjoint w trzech krokach
Wygenerować warianty według planu ortogonalnego. Zebrać dane i stworzyć bazę w odpowiednim formacie. Wykonać analizę.

90
Krok I – ORTHOPLAN Nr wariantu Cena Kraj Waga Rodzaj 1 20 zł Indie
mielona 2 10 zł 250 g rozpuszczalna … k Kolumbia

91
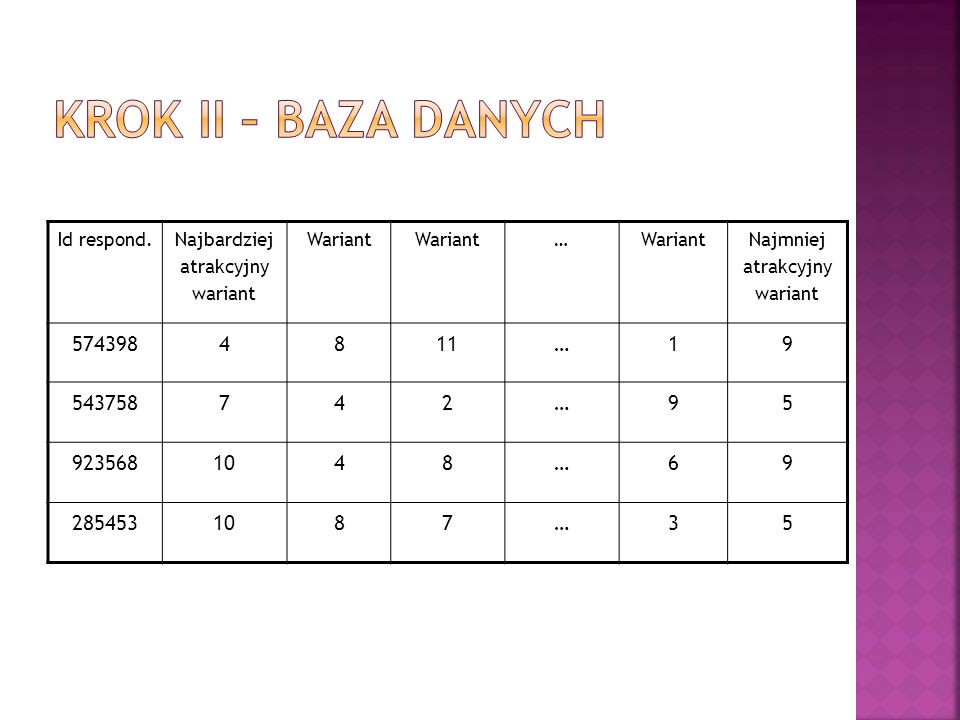
Krok II – baza danych Id respond. Najbardziej atrakcyjny wariant Wariant … Najmniej atrakcyjny wariant 574398 4 8 11 1 9 543758 7 2 5 923568 10 6 285453 3
92
Krok III – CONJOINT Określić parametry analizy Kliknąć
Poczekać na wyniki…

Podobne prezentacje

















 Średnia arytmetyczna (dla szeregu szczegółowego) Średnią arytmetyczną nazywamy sumę wartości zmiennej wszystkich jednostek.>")



