Pobierz prezentację
Pobieranie prezentacji. Proszę czekać

1
Bezpieczeństwo aplikacji Windows
Krzysztof Sumowski Piotr Warzocha Rafał Zarębski Toruń,

2
Plan prezentacji Część I Krzysztof Sumowski, Rafał Zarębski
Podstawowe zagadnienia Podstawowe błędy i sposoby ochrony Narzędzia testujące Część II Rafał Zarębski Bezpieczeństwo w WinApi - program Część III Piotr Warzocha Różne metody zabezpieczania programów Techniki kryptograficzne

3
CZĘŚĆ I

4
1. Podstawowe zagadnienia
Podstawowe pojęcia Znaczenie i rola bezpieczeństwa Dlaczego i jak powinniśmy się bronić? Oprogramowanie Open Source vs oprogramowanie komercyjne Konsekwencje błędów bezpieczeństwa w kodzie

5
Podstawowe pojęcia Bezpieczny program to taki, który zachowuje narzucone granice bezpieczeństwa podczas przetwarzania danych, dostarczonych ze źródła objętego innymi uprawnieniami niż sam program. Bezpieczeństwo to zdolność do sprawowania nadzoru nad wykorzystywaniem przez innych naszych zasobów komputerowych, czyli zdolność do powiedzenia ludziom nie (lub tak) i umiejętność wsparcia tego odpowiednim działaniem. Bezpieczne programowanie polega w takim samym stopniu na wiedzy o tym, czego nie robić, jak i na wiedzy o tym, co zrobić.
 i umiejętność wsparcia tego odpowiednim działaniem. Bezpieczne programowanie polega w takim samym stopniu na wiedzy o tym, czego nie robić, jak i na wiedzy o tym, co zrobić.")
6
Podstawowe pojęcia Poufność Dostępność
Integralność – informacja nie zmienia się bez naszej wiedzy Kontrola dostępu – możliwość kontrolowania dostępu poprzez identyfikacje i uwierzytelnienia Uwierzytelnianie – zapewnienie autentyczności informacji i osób Nienaruszalność - zapewnia integralność komunikacji Niezaprzeczalność – niemożność zaprzeczania faktowi wysyłania/odebrania informacji Dyspozycyjność – ograniczanie skutków ataków

7
Znaczenie i rola bezpieczeństwa
Ogromna rola w dzisiejszym zinformatyzowanym świecie Wiele czynności w naszym życiu uzależnionych od użycia komputera/Internetu. Sklepy internetowe, banki, dane poufne – konieczność obrony, zadbania o bezpieczeństwo. Wyróżniamy bezpieczeństwo na poziomie: funkcjonalnym - silna autentykacja i uwierzytelnienie do zasobów konfiguracji – odpowiednie opcje, wartości domyślne programu i ich interpretacja kodu – odporność kodu na specyficzne dane czy ataki złośliwych użytkowników

8
Znaczenie i rola bezpieczeństwa
Kod programu i dane znajdują się w tym samym obszarze w pamięci – udogodnienie dla programistów jak i złośliwych użytkowników. Najważniejsze z punktu widzenia bezpieczeństwa jest wejście programu (przetwarzanie danych wejściowych). Brak lub niewystarczająca walidacja danych wejściowych jest główną przyczyną problemów z bezpieczeństwem aplikacji.
. Brak lub niewystarczająca walidacja danych wejściowych jest główną przyczyną problemów z bezpieczeństwem aplikacji.")
9
Dlaczego i jak powinniśmy się bronić?
Złośliwi użytkownicy, atakujący: dla przyjemności dla zdobycia wiedzy, sprawdzenia się dla pieniędzy Mimo iż spora część napastników używa prostych narzędzi, przed którymi łatwo się obronić, nie powinniśmy bagatelizować zagrożenia ze strony najgroźniejszych z nich.

10
Dlaczego i jak powinniśmy się bronić?
Atak następuje, gdy zysk z niego jest większy bądź równy kosztom ataku. Powinniśmy dążyć do tego, aby koszt przeprowadzenia ataku stale wzrastał = przewyższał korzyści i zniechęcał atakującego. Nie istnieje całkowicie bezpieczny kod, możemy jedynie obniżać prawdopodobieństwo zajścia ataku.

11
Dlaczego i jak powinniśmy się bronić?
Fakt, iż nigdy nie zostaliśmy zaatakowani i nie przeczuwamy takiej sytuacji, nie powinien nas skłaniać do rezygnacji z dbałości o bezpieczeństwo naszych aplikacji. Nie ma narzędzia, które kompleksowo ochroni nas przed wszystkimi typami ataków. Defence in depth obrona na wielu warstwach (firewall, obrona samej aplikacji). Rewizja kodu naszego programu wtedy przynosi skutki, gdy jest dokonywana przez osoby, które go nie pisały (członek zespołu). Narzędzia administracyjne (np. użytkownika root) –nigdy nie powinny ufać danym, na które mogą mieć wpływ nieautoryzowani użytkownicy. Zawsze zakładamy możliwość podania złośliwych danych.
. Rewizja kodu naszego programu wtedy przynosi skutki, gdy jest dokonywana przez osoby, które go nie pisały (członek zespołu). Narzędzia administracyjne (np. użytkownika root) –nigdy nie powinny ufać danym, na które mogą mieć wpływ nieautoryzowani użytkownicy. Zawsze zakładamy możliwość podania złośliwych danych.")
12
Dlaczego i jak powinniśmy się bronić?
Projektowanie bezpiecznej aplikacji wymaga określenia wymagań bezpieczeństwa, stawianych projektowanej aplikacji. Jakie jest środowisko bezpieczeństwa pracy programu? Jakie są zagrożenia i na ile poważne? Komu nie można ufać? Jaka sieć/system operacyjny ? Jaka jest polityka bezpieczeństwa firmy/organizacji? Jakie dane będą chronione? Jakie wymagania bezpieczeństwa stawiane są programowi?

13
Oprogramowanie Open Source vs oprogramowanie komercyjne
Oprogramowanie, którego kod jest ogólnodostępny umożliwia lepsze jego uszczelnienie. Dostęp do kodu mają zarówno intruzi jak i potencjalne ofiary – każdy może zabezpieczyć się najlepiej jak potrafi. Oprogramowanie komercyjne – nie udostępnianie kodu/ nie informowanie o dziurach nie czyni go bezpieczniejszym. Stworzenie uaktualnienia nie jest takie łatwe. Fakt udostępnienia kodu źródłowego czyni oprogramowanie bezpieczniejszym.

14
Konsekwencje błędów bezpieczeństwa w kodzie
Niestabilne działanie systemu Zmiana uprawnień dostępu do plików Kradzież poufnych danych Straty finansowe, intelektualne, moralne Podmiana autorstwa Załamanie aplikacji/systemu Modyfikacja działania programu Przejęcie kontroli nad systemem operacyjnym Nieuprawnione użycie programu

15
Konsekwencje błędów bezpieczeństwa w kodzie
Rodzaje ataków robaki ataki Dos, DDos exploit backdoor

16
2. Podstawowe błędy i sposoby ochrony
Dlaczego powstają dziury w programach? Przepełnienie bufora. Błąd ciągów formatujących. Wycieki pamięci. Błędy dostępu do pliku. Podsumowanie.

17
Dlaczego powstają dziury w programach?
Brak odpowiedniej edukacji, mało dostępna literatura traktująca o pisaniu bezpiecznego kodu. Używanie prostych, ale niezabezpieczonych funkcji (np. języka C operujących na łańcuchach znaków). Programiści nie pamiętają, iż program pracuje w trybie „multiuser”, Programiści zamiast pisać od razu bezpieczny kod, piszą go byle jak, wmawiając sobie, że poprawią go później. Większość programistów nie potrafi myśleć jak intruz. Aktualizacja napisanego już kodu, pod kątem zwiększenia bezpieczeństwa jest trudna. Bezpieczne podejście wymaga większych nakładów czasowych, czyli większych nakładów finansowych.
. Programiści nie pamiętają, iż program pracuje w trybie „multiuser , Programiści zamiast pisać od razu bezpieczny kod, piszą go byle jak, wmawiając sobie, że poprawią go później. Większość programistów nie potrafi myśleć jak intruz. Aktualizacja napisanego już kodu, pod kątem zwiększenia bezpieczeństwa jest trudna. Bezpieczne podejście wymaga większych nakładów czasowych, czyli większych nakładów finansowych.")
18
Przepełnienie bufora Co to jest przepełnienie bufora?
Bufor to blok pamięci, zazwyczaj w formie tablicy. Jeśli przy zapisywaniu do bufora nie zostanie sprawdzony rozmiar tablicy, możliwe jest zapisanie danych poza zaalokowanym obszarem pamięci (buforem). Zdarzenie, w którym dane zapisywane są pod adresem wyższym niż zaalokowany bufor, nazywa się przepełnieniem bufora (buffer overflow). Generalnie chodzi o sytuację w której program otrzymuje dane z zewnątrz. Gdy zaalokowaliśmy bufor o stałej długości, nie sprawdzamy, czy dane przesyłane z zewnątrz nie zajmują więcej miejsca niż na nie przeznaczyliśmy.
. Zdarzenie, w którym dane zapisywane są pod adresem wyższym niż zaalokowany bufor, nazywa się przepełnieniem bufora (buffer overflow). Generalnie chodzi o sytuację w której program otrzymuje dane z. zewnątrz. Gdy zaalokowaliśmy bufor o stałej długości, nie sprawdzamy, czy dane przesyłane z zewnątrz nie zajmują więcej miejsca niż na nie przeznaczyliśmy.")
19
Przepełnienie bufora Przyczyny, umożliwiające włamanie się do programu: źle deklarowane wartości tablic, nieodpowiednio przekazywane parametry funkcji, nieprawidłowy znak, przepełnienie licznika, brak lub nieodpowiednia kontrola danych wejściowych. Szczególnie narażone programy napisane w C/C++ (które pozwalają na swobodę programiście)
")
20
Przepełnienie bufora Zagrożenia Załamanie aplikacji
Atak Dos na aplikację Wykonanie dowolnego kodu w systemie (z coraz większymi uprawnieniami uruchamianej aplikacji wiąże się większe zagrożenie) Przepełnienie stosu i sterty (trudniejsze do uzyskania i wykorzystania)
 Przepełnienie stosu i sterty (trudniejsze do uzyskania i wykorzystania)")
21
Przepełnienie bufora Budowa stosu w architekturze x86
Stos jest liniową strukturą danych, w której dane dokładane są na wierzch stosu i z wierzchołka stosu są pobierane (bufor typu LIFO, Last In, First Out; ostatni na wejściu, pierwszy na wyjściu). W architekturze x86 stos rośnie w dół, co oznacza, że nowsze dane są zapamiętywane pod adresami niższymi niż elementy wstawione na stos wcześniej.
. W architekturze x86 stos rośnie w dół, co oznacza, że nowsze dane są zapamiętywane pod adresami niższymi niż elementy wstawione na stos wcześniej.")
22
Przepełnienie bufora Każde wywołanie funkcji powoduje utworzenie nowej ramki stosu o następującej budowie (należy pamiętać, że lista uporządkowana jest w kolejności malejących adresów): parametry funkcji, adres powrotu funkcji, wskaźnik ramki, ramka procedur obsługi wyjątków, lokalnie zadeklarowane zmienne i bufory, rejestry zachowane przez funkcję wywołaną.
: parametry funkcji, adres powrotu funkcji, wskaźnik ramki, ramka procedur obsługi wyjątków, lokalnie zadeklarowane zmienne i bufory, rejestry zachowane przez funkcję wywołaną.")
23
Przepełnienie bufora Z budowy stosu widać, że przepełnienie bufora może nadpisać: inne zmienne zaalokowane przed buforem, ramkę obsługi wyjątków, wskaźnik ramki, adres powrotu oraz parametry funkcji. Aby przejąć kontrolę nad programem, wystarczy umieścić odpowiednią wartość w danych, które później zostaną załadowane do rejestru. Jedną z takich wartości jest adres powrotu funkcji. Typowe wykorzystanie przepełnienia bufora polega na nadpisaniu adresu powrotu funkcji i pozwoleniu instrukcjom powrotnym funkcji na załadowanie zmienionego adresu do rejestru.

24
Przepełnienie bufora

25
Przepełnienie bufora Osoby, które wykorzystują tego typu luki działają w taki sposób, że podstawiają własny adres powrotu, który jest podawany do programu. Możliwe jest to dzięki prostej funkcji łańcuchowej, kopiującej wartości w stosie z jednego adresu do drugiego. Nie ma w trakcie tego automatycznego sprawdzenia, czy pod adresem docelowym jest wystarczająca ilość miejsca.

26
Przepełnienie bufora

27
Przepełnienie bufora Przykłady. Stos wywołania funkcji FUN
#include<stdio.h> void FUN(int a, int b, int c){ char bufor[5]; char bufor2[10]; int *ret; ret = &a - 1; (*ret) += 10; } void main(){ int x; x = 0; FUN(1,2,3); x = 1; printf("%d\n",x);
{ char bufor[5]; char bufor2[10]; int *ret; ret = &a - 1; (*ret) += 10; } void main(){ int x; x = 0; FUN(1,2,3); x = 1; printf( %d\n ,x);")
28
Przepełnienie bufora Wykorzystanie Shellcodu
Shellcode oznacza prosty, niskopoziomowy program prezentowany najczęściej w postaci kodu maszynowego, odpowiedzialny za wywołanie powłoki systemowej. Często wykorzystywany w ostatniej fazie wykorzystywania wielu błędów zabezpieczeń przez exploity. Dostarczany jest on zwykle wraz z innymi danymi wejściowymi użytkownika. Na skutek wykorzystania luki w atakowanej aplikacji, procesor rozpoczyna wykonywanie shellcode, pozwalając na uzyskanie nieautoryzowanego dostępu do systemu komputerowego lub eskalację uprawnień.

29
Przepełnienie bufora Shellcode składa się z instrukcji asemblera zapisanych już w formie binarnej, w której wszystkie adresy muszą być zakodowane na stałe. Aby uniknąć bezwzględnych odwołań do pamięci generujących błąd naruszenia segmentacji programu. Większość adresów uzyskuje się ze stosu a skoki są wykonywane nie do konkretnego miejsca w pamięci tylko o konkretną ilość instrukcji procesora w przód, bądź w tył.

30
Przepełnienie bufora Zapobieganie przepełnieniom bufora
Aby zapobiegać przepełnieniom bufora, należy zwracać uwagę na funkcje, których używamy w naszych programach. Najczęstszą przyczyną problemów jest niewłaściwe stosowanie funkcji związanych z obsługą łańcuchów tekstowych. Dlatego też przyjrzymy się im bliżej, aby zobaczyć, jak można zabezpieczyć się przed niepożądanym działaniem.

31
Niebezpieczne konstrukcje języka C
Przepełnienie bufora Niebezpieczne konstrukcje języka C

32
Przepełnienie bufora Funkcja strcpy Wywołanie funkcji:
char *strcpy( char *strDestination, const char *strSource ); Istnieje bardzo wiele sytuacji, w której działanie funkcji zakończy się z błędem. Najpopularniejsze z nich to między innymi: gdy bufor źródłowy i docelowy są puste, jeżeli bufor źródłowy nie jest zakończony znakiem null i największy z problemów – gdy rozmiar ciągu źródłowego jest większy niż bufor docelowy.
; Istnieje bardzo wiele sytuacji, w której działanie funkcji zakończy się z błędem. Najpopularniejsze z nich to między innymi: gdy bufor źródłowy i docelowy są puste, jeżeli bufor źródłowy nie jest zakończony znakiem null i największy z problemów – gdy rozmiar ciągu źródłowego jest większy niż bufor docelowy.")
33
Przepełnienie bufora Funkcja strncpy Wywołanie funkcji:
char *strncpy( char *strDest, const char *strSource, size_t count ); Jest bezpieczniejsza niż strcpy, ale i tutaj nadal mogą pojawiać się problemy, szczególnie w przypadku przekazywania wartości null jako ciągu źródłowego lub docelowego. Dodatkowo problemem może być zła wartość licznika. Jedna z różnic pomiędzy tą funkcją a poprzednią to fakt, że jeśli bufor źródłowy nie jest zakończony null, to funkcja nie zakończy się z błędem.
; Jest bezpieczniejsza niż strcpy, ale i tutaj nadal mogą pojawiać się problemy, szczególnie w przypadku przekazywania wartości null jako ciągu źródłowego lub docelowego. Dodatkowo problemem może być zła wartość licznika. Jedna z różnic pomiędzy tą funkcją a poprzednią to fakt, że jeśli bufor źródłowy nie jest zakończony null, to funkcja nie zakończy się z błędem.")
34
Przepełnienie bufora Funkcja sprintf
Wywołanie funkcji: int snprintf( char *buffer, size _ t count, const char *format [, argument] ... ); Jest to jedna z bezpieczniejszych funkcji. Jedyna rzecz, na którą należy zwrócić uwagę to bufor docelowy jest zakończony znakiem null. Funkcja _snprintf int _snprintf( char *buffer, size _ t count, const char *format [, argument] ... ); Jest to jedna z bezpieczniejszych funkcji. Jedyna rzecz, na którą należy zwrócić uwagę, to sprawdzenie, czy bufor docelowy jest zakończony znakiem null.
; Jest to jedna z bezpieczniejszych funkcji. Jedyna rzecz, na którą należy zwrócić uwagę to bufor docelowy jest zakończony znakiem null. Funkcja _snprintf. int _snprintf( char *buffer, size _ t count, const char *format [, argument] ... ); Jest to jedna z bezpieczniejszych funkcji. Jedyna rzecz, na którą należy zwrócić uwagę, to sprawdzenie, czy bufor docelowy jest zakończony znakiem null.")
35
Przepełnienie bufora Address Space Layout Randomization (ASLR)
implementacja w Windows Vista I Windows 7 rozmieszczenie bibliotek i aplikacji pod losowymi adresami szansa na powodzenie ataku maleje 256 razy może powodować problemy kompatybilnościowe Stack Defender – IPS - uniemożliwia uruchomienie kodu napastnika z obszaru pamięci stosu Data Execution Prevention (DEP) - uniemożliwia wykonanie kodu pochodzącego z niewykonywalnego obszaru pamięci - ochrona programowa - można skonfigurować ją dla systemu lub dla aplikacji - ochrona sprzętowa - wymagane „rozumienie” technologii przez procesor
 - uniemożliwia wykonanie kodu pochodzącego z niewykonywalnego obszaru pamięci. - ochrona programowa - można skonfigurować ją dla systemu lub dla aplikacji. - ochrona sprzętowa - wymagane „rozumienie technologii przez procesor.")
36
Przepełnienie bufora Przepełnienie bufora to poważny problem. Każdy programista powinien mieć świadomość tego rodzaju zagrożenia. Zanim zacznie tworzyć kod, powinien wziąć pod uwagę podobne problemy i dużo wcześniej przemyśleć architekturę kodu. Z drugiej strony, programista powinien mieć pomoc ze strony narzędzi programistycznych – tak, aby to one mogły sprawdzić i rozwiązać takie problemy (przynajmniej częściowo). Po analizie tekstu możemy zadać następujące pytanie jak samemu wyrobić sobie nawyk nie popełniania takich błędów, jak przepełnienie bufora? O ile nigdy nie doświadczymy na własnej skórze problemu z włamaniem i nie stracimy przez to jakichś istotnych danych, to pewnie trudno nam będzie o tym pamiętać. A na poważnie – warto zrobić sobie listę wszystkich kroków, które musimy wykonać, i sprawdzić, czy wśród nich jest sprawdzenie możliwości wystąpienia przepełnienia bufora.
. Po analizie tekstu możemy zadać następujące pytanie jak samemu wyrobić sobie nawyk nie popełniania takich błędów, jak przepełnienie bufora O ile nigdy nie doświadczymy na własnej skórze problemu z włamaniem i nie stracimy przez to jakichś istotnych danych, to pewnie trudno nam będzie o tym pamiętać. A na poważnie – warto zrobić sobie listę wszystkich kroków, które musimy wykonać, i sprawdzić, czy wśród nich jest sprawdzenie możliwości wystąpienia przepełnienia bufora.")
37
Błąd ciągów formatujących
Format string attack - atak informatyczny, będący stosunkowo nową techniką wykorzystywania błędów programistycznych w aplikacjach. Błędnie napisana aplikacja może być przy wykorzystaniu tej techniki usunięta z listy procesów przez system operacyjny (tzw. crash) lub zmuszona do wykonania kodu dostarczonego przez napastnika.
 lub zmuszona do wykonania kodu dostarczonego przez napastnika.")
38
Błąd ciągów formatujących
Przez wiele lat niewłaściwe wykorzystanie funkcji operujących na ciągach formatujących było uważane za błąd, jednak nie brano uwagę, iż umożliwia on przejęcie kontroli nad aplikacją. W 2000 roku po raz pierwszy przedstawiono exploity wykorzystujące błędy tego typu w szeroko stosowanym serwerze usługi FTP. Kod źródłowy exploita pokazywał technikę umożliwiającą przejęcie kontroli nad aplikacją przy wykorzystaniu błędnego wywołania funkcji vsnprintf() wewnątrz własnej funkcji, odpowiedzialnej za formułowanie odpowiedzi (lreply()).
 wewnątrz własnej funkcji, odpowiedzialnej za formułowanie odpowiedzi (lreply()).")
39
Błąd ciągów formatujących
Atak wykorzystuje fakt, iż funkcje ze zmienną ilością argumentów takie jak printf() określają ilość tych argumentów na podstawie podanego ciągu znaków. Podczas jego interpretowania korzysta z dodatkowych parametrów podanych do funkcji, przedstawiając je w czytelnej dla człowieka formie. Podatność na atak ma miejsce gdy atakujący może dostarczyć do takiej funkcji ciąg formatujący. W ten sposób można zmienić zachowanie aplikacji, i przejąć nad nią kontrolę.
 określają ilość tych argumentów na podstawie podanego ciągu znaków. Podczas jego interpretowania korzysta z dodatkowych parametrów podanych do funkcji, przedstawiając je w czytelnej dla człowieka formie. Podatność na atak ma miejsce gdy atakujący może dostarczyć do takiej funkcji ciąg formatujący. W ten sposób można zmienić zachowanie aplikacji, i przejąć nad nią kontrolę.")
40
Błąd ciągów formatujących
Najprostszy przykład gdzie podanie ciągu formatującego jest możliwe: int funkcja (char *nazwa) { printf (nazwa); } W języku C jest dużo funkcji formatujących. Na kolejnym slajdzie wymieniono niektóre z podstawowych funkcji, na których bazowane są inne bardziej złożone, zaś niektóre z nich nie należą do standardu, lecz są ogólnodostępne.
 { printf (nazwa); } W języku C jest dużo funkcji formatujących. Na kolejnym slajdzie wymieniono niektóre z podstawowych funkcji, na których bazowane są inne bardziej złożone, zaś niektóre z nich nie należą do standardu, lecz są ogólnodostępne.")
41
Błąd ciągów formatujących
fprintf — drukuje do pliku printf — drukuje do strumienia standardowego wyjścia sprintf — drukuje do zmiennej typu string snprintf — drukuje do zmiennej typu string kontrolując długość vfprintf — drukuje do pliku ze struktury va_arg vprintf — drukuj from a va_arg structure vsprintf — drukuje do strumienia standardowego wyjścia ze struktury va_arg vsnprintf — drukuje do zmiennej typu string kontrolując długość ze struktury va_arg Pokrewne: setproctitle, syslog, inne err*, verr*, warn*, vwarn*

42
Błąd ciągów formatujących
Aby zrozumieć skąd bierze się podatność na ataki wymienionych funkcji trzeba zbadać jaki jest cel funkcji formatujących. Zastosowania: są używane do konwertowania prostych typów C do postaci ciągu znaków pozwalają określić format reprezentacji danych przetworzyć go (wyjście do stderr, stdout, syslog etc. )
")
43
Błąd ciągów formatujących
Jak działa funkcja formatująca? ciąg formatujący kontroluje zachowanie funkcji określa typ danych jakie mają być wydrukowane parametry są wepchnięte na stos zapisane albo przez wartość albo przez referencję Podstawowe parametry określające typ danych: %d – liczba całkowita %u – liczba całkowita bez znaku %x – liczba w systemie szesnastkowym %s – ciąg znaków %n – do argumentu zapisywana jest liczba dotychczas zapisanych znaków

44
Błąd ciągów formatujących
Przykład: printf ("liczba %d , liczba %d o adresie: %08x\n", a, b, &c); Z perspektywy prtintf stos wygląda następująco:
; Z perspektywy prtintf stos wygląda następująco:")
45
Błąd ciągów formatujących
Funkcja przetwarza ciąg formatujący po jednym znaku. Jeśli znak ten nie jest '%' zostaje przekopiowany do wyjścia w przeciwnym wypadku następny znak/znaki określa typ zmiennej.

46
Błąd ciągów formatujących
Zawieszenie programu Jest to najprostszy z ataków za pomocą ciągu formatującego. Bez problemu można wywołać błąd, próbując odczytać pamięć z niedozwolonego adresu. Dokonuje się tego za pomocą podania ciągu „%s%s%s%s%s%s%s”.

47
Błąd ciągów formatujących
Odczytanie danych ze stosu Podając ciąg taki jak np: „%08x %08x %8x” każemy funkcji printf odczytać ze stosu 3 argumenty i wyświetlić je jako ośmiocyfrowe liczby w systemie szesnastkowym. Zależnie od wielkości bufora przeznaczonego na ciąg formatujący i na wielkość bufora wyjściowego, można odtworzyć mniejsze lub większe obszary pamięci. Można w ten sposób dowiedzieć się więcej o działaniu programu, odczytać zmienne lokalne, znaleźć przedziały pamięci, które chce się zaatakować. Dodatkowo umieszczając ręcznie adres na stosie można odczytać pamięć pod tym adresem poleceniem %s.

48
Błąd ciągów formatujących
Pisanie do pamięci za pomocą %n Tak jak w przypadku czytania z dowolnego miejsca, tyle ze %n w tym wypadku wpisze liczbę całkowita do argumentu wskazywanego przez podstawiony adres. Używając tych metod można znaleźć i nadpisać kod powrotu funkcji tak aby wskazywał na spreparowany szkodliwy kod.

49
Błąd ciągów formatujących
Jak się bronić: Zamiast printf (string); pisać: printf („%s”,str); Ostrożność przy używaniu funkcji typu fprintf (STDOUT,strFormat,arg1,arg2,arg3); Testowanie kodu: Narzędzie RATS Dedykowane narzędzie pscan (Cygwin)
; pisać: printf („%s ,str); Ostrożność przy używaniu funkcji typu. fprintf (STDOUT,strFormat,arg1,arg2,arg3); Testowanie kodu: Narzędzie RATS. Dedykowane narzędzie pscan (Cygwin)")
50
Wycieki pamięci Zjawisko wycieku pamięci szczególnie znane jest osobom programującym w językach nie posiadających odśmiecania/śmieciarza (ang. Garbage Collector), takich jak C/C++. Na pozór, nazwa tego zjawiska niejako odnosi się do wadliwego działania pamięci, w rzeczywistości jednak winę ponosi niewłaściwie napisany kod. Aby zobrazować na czym polega cały problem, warto przeanalizować przykład z kolejnego slajdu.
, takich jak C/C++. Na pozór, nazwa tego zjawiska niejako odnosi się do wadliwego działania pamięci, w rzeczywistości jednak winę ponosi niewłaściwie napisany kod. Aby zobrazować na czym polega cały problem, warto przeanalizować przykład z kolejnego slajdu.")
51
Wycieki pamięci Przykład programu powodującego wyciek pamięci
#include <stdio.h> #include <stdlib.h> int main(void) { int **p; // Deklarujemy wskaźnik na wskaźnik na zmienną typu całkowitego do obszaru pamięci p = (int**) malloc ( sizeof(int*) ); // Rezerwujemy miejsce na 1 element typu wskaźnik na int pod tym wskaźnikiem *p = (int*) malloc ( sizeof(int) ); // Rezerwujemy miejsce na 1 element typu int pod wskaźnikiem na wskaźnik free(p); // Zwalniamy obszar pamięci, wskazywany przez wskaźnik p return 0; }
 { int **p; // Deklarujemy wskaźnik na wskaźnik na zmienną typu całkowitego do obszaru pamięci p = (int**) malloc ( sizeof(int*) ); // Rezerwujemy miejsce na 1 element typu wskaźnik na int pod tym wskaźnikiem *p = (int*) malloc ( sizeof(int) ); // Rezerwujemy miejsce na 1 element typu int pod wskaźnikiem na wskaźnik free(p); // Zwalniamy obszar pamięci, wskazywany przez wskaźnik p return 0; }")
52
Wycieki pamięci Na początku została zaalokowana pamięć pod wskaźnik p, a następnie pod wskaźnik na wskaźnik *p. Po czym, za pomocą funkcji free został zwolniony obszar pamięci wskazywany przez wskaźnik. Na pozór wszystko działa jak należy, a kompilacja nie wykazuje żadnych błędów. W rzeczywistości, każde wywołanie powyższego programu spowoduje wyciek 4 bajtów (bo tyle zazwyczaj wynosi rozmiar zmiennej typu int) pamięci. Nietrudno zauważyć dlaczego tak się dzieje. Wszystko spowodowane jest tym, że pamięć alokowana była dwa razy, a funkcja zwalniająca pamięć free została wywołana tylko raz.
 pamięci. Nietrudno zauważyć dlaczego tak się dzieje. Wszystko spowodowane jest tym, że pamięć alokowana była dwa razy, a funkcja zwalniająca pamięć free została wywołana tylko raz.")
53
Wycieki pamięci Ponieważ język C pozbawiony jest tzw. "odśmieciacza", dlatego każdemu wywołaniu jednej z funkcji alokujących pamięć, takich jak: malloc, calloc lub realloc, musi odpowiadać wywołanie funkcji free. Cały błąd w powyższym kodzie polega wiec na tym, że zwolniony został wskaźnik p, ale nie został zwolniony wskaźnik na ten wskaźnik. Problem jest o tyle skomplikowany, że po zwolnieniu wskaźnika p, nie mamy dostępu do wskaźnika *p, więc nie możemy zwolnić obszaru pamięci przezeń wskazywanego.

54
Wycieki pamięci Poniższy kod został pozbawiony tego błędu: Przykład programu potencjalnie pozbawionego wycieku pamięci #include <stdio.h> #include <stdlib.h> int main(void) { int **p; // deklarujemy wskaźnik na wskaźnik na zmienną typu całkowitego do obszaru pamięci p = (int**) malloc ( sizeof(int*) ); // rezerwujemy miejsce na 1 element typu wskaźnik na int pod tym wskaźnikiem *p = (int*) malloc ( sizeof(int) ); // rezerwujemy miejsce na 1 element typu int pod wskaźnikiem na wskaźnik free(*p); // zwalniamy obszar pamięci, wskazywany przez wskaźnik na wskaźnik p free(p); // zwalniamy obszar pamięci, wskazywany przez wskaźnik p return 0; }
 { int **p; // deklarujemy wskaźnik na wskaźnik na zmienną typu całkowitego do obszaru pamięci p = (int**) malloc ( sizeof(int*) ); // rezerwujemy miejsce na 1 element typu wskaźnik na int pod tym wskaźnikiem *p = (int*) malloc ( sizeof(int) ); // rezerwujemy miejsce na 1 element typu int pod wskaźnikiem na wskaźnik free(*p); // zwalniamy obszar pamięci, wskazywany przez wskaźnik na wskaźnik p free(p); // zwalniamy obszar pamięci, wskazywany przez wskaźnik p return 0; }")
55
Wycieki pamięci Warto zauważyć jedną z cech dynamicznej alokacji pamięci: Bardziej skomplikowane deklaracje, jak np. alokowanie pamięci pod wskaźnik na wskaźnik, albo pod wskaźnik na strukturę, w której znajdują się wskaźniki, zazwyczaj wiąże się ze zwalnianiem poszczególnych elementów w odwrotnej kolejności, niż zostały one zaalokowane. Trzeba zwrócić uwagę na to, jakim problemem może być wyciek pamięci w programie, który dłuższy czas działa w systemie, np. serwerze, czy demonie. W takim wypadku program zajmuje coraz większą ilość pamięci, której nie może wykorzystać, ani tym bardziej zwolnić. Sam wyciek może nie tylko prowadzić do spadku wydajności, a także, w skrajnym przypadku zawieszenia się programu, ale nawet do zablokowania całego systemu.

56
Wycieki pamięci Sam wyciek jest najczęściej wynikiem: zapominalstwa
wielu ścieżek powrotu z funkcji przypisania nowej wartości do wskaźnika przed wywołaniem free nie zwolnienia elementów struktury po zwolnieniu struktury nieświadomości, że funkcja wywoływana alokuje pamięć, którą funkcja wywołująca powinna zwolnić.

57
Wycieki pamięci Śledzenie wycieków pamięci
Jak już zostało wspomniane, mimo, że wycieki pamięci są efektem bardzo niepożądanym, tak naprawdę czasami całkiem nieświadomie możemy doprowadzić do tego, że nasza aplikacja będzie traciła pamięć przez nieudolną alokację i dealokację. Jednym ze sposobów jest staranne prześledzenie zmiennych związanych z alokacją pamięci, linia po linii, od narodzin do śmierci, jednak nie jest to ani łatwy, ani przyjemny sposób. Nie mniej jednak śledzenie wycieków może być względnie proste. Mowa tu głównie o aplikacjach śledzących wycieki pamięci, albo wykorzystaniu dyrektyw preprocesora.

58
Błędy dostępu do pliku Sytuacja, w której użytkownik chce otworzyć plik: - etap I: sprawdzanie dostępności pliku - etap II: otwarcie pliku - pomiędzy etapami procesor może zostać wywłaszczony do innego zadania, a napastnik może podmienić plik! Zagrożenia: - zwiększenie praw dostępu ( jeśli podatny program działa z podwyższonymi uprawnieniami)
")
59
Błędy dostępu do pliku Ochrona:
- większość języków udostępnia odpowiednie funkcje /*first dropping privileges…*/ FILE file = fopen(strFileName, „w+”); If (file) DoSomething ( file );
; If (file) DoSomething ( file );")
60
Podsumowanie Wskazówki podnoszące bezpieczeństwo:
Sprawdzanie wszystkich danych wejściowych. Unikanie możliwości przepełnienia bufora. Uruchamianie i późniejsze działanie z jak najmniejszymi przywilejami. Prostota projektu i implementacji. Domyślne opcje działania/instalacji ustawione na odmowę dostępu (ang. deny). Minimalizacja użycia dzielonych zasobów. Unikanie „wyścigów po zasoby” (ang. race conditions). Mechanizmy ochrony powinny być proste, jednolite i zaimplementowane w najniższych warstwach systemu.
. Minimalizacja użycia dzielonych zasobów. Unikanie „wyścigów po zasoby (ang. race conditions). Mechanizmy ochrony powinny być proste, jednolite i zaimplementowane w najniższych warstwach systemu.")
61
Podsumowanie Spójne stosowanie określonych konwencji programistycznych. Korzystanie tylko z bezpiecznych, zewnętrznych bibliotek. Walidacja parametrów przekazywanych do zewnętrznych programów. Sprawdzanie wyników wywołań funkcji systemowych. Pełne logowanie każdego zdarzenia, błędu, jednak z zachowaniem rozsądku, tak aby np. nie dostarczać atakującemu pełnego opisu wystąpienia błędu. Użytkownik ma wiedzieć co się stało, ale niekoniecznie dlaczego się coś stało. Nie upublicznianie funkcji ujawniających informacje testowe. Eliminowanie z kodu przestarzałych konstrukcji języka.

62
3. Narzędzia testujące Testowanie kodu źródłowego
Skanery kodu źródłowego Skanery kodu binarnego Opcje kompilatorów, biblioteki bezpieczeństwa Gotowe programy testujące

63
Testowanie kodu źródłowego
Wielostopniowy system dbania o jakość programów. Wykonywać testy dla jak największej liczby różnych przypadków. Dokumentowanie kodu. Wszystkie algorytmy w programie powinny zostać przetestowane przy użyciu najgorszego zestawu danych, czyli dla którego aplikacje wykonują się najdłużej.

64
Skanery kodu źródłowego
Zalety Duża szybkość działania Możliwość uruchamiania okresowego w celu wykrycia nowych błędów lub weryfikacji usunięcia poprzednio wykrytych podatności Istnieje szereg narzędzi dostępnych bez opłat, jak również możliwych do samodzielnego rozszerzania

65
Skanery kodu źródłowego
Wady Nie zawsze mamy dostęp do kodu źródłowego Wykrywają jedynie błędy najłatwiejsze do strukturalnego zdefiniowania Niektóre darmowe narzędzia działają nieoptymalnie, mają skomplikowany interfejs, niekompletną dokumentację false positives – wykrycie podatności tam, gdzie jej nie ma; false negatives – nie wykrycie podatności tam, gdzie jest.

66
Skanery kodu źródłowego
Analiza kodu C/C++ cppcheck RATS – Rough Auditing Tool for Security (działa także pod Windowsem) DevPartner for Visual C++ BoundsChecker Suite
 DevPartner for Visual C++ BoundsChecker Suite.")
67
Skanery kodu binarnego
Narzędzie o nazwie BFBTester służy do szybkiego testu programu binarnego. BFBTester potrafi przetestować program pod kątem długości argumentów dostarczonych jako parametry oraz sprawdzi odporność na przepełnienie zmiennych środowiskowych. Do jego możliwości można zaliczyć śledzenie wywołań funkcji systemowych, tworzących pliki tymczasowe oraz powiadamianie w przypadku, kiedy używane są niezabezpieczone funkcje. Oczywiście skaner ten nie wykrywa wszystkich błędów, ale może być użyteczny na samym początku, eliminując błędy, które w późniejszym czasie mogą okazać się katastrofalne w skutkach.

68
Opcje kompilatorów, biblioteki bezpieczeństwa
• Run-time Checks (RTC) – całkowite sprawdzenie sterty danymi niezerowymi, unikając założenia, że sterta jest zawsze pusta. Sprawdzane są granice wszystkich tablic, aby wyłapać nawet jeden bajt przepełniający bufor i znaleźć niezgodne wywołania. • PREfast – narzędzie dla programisty, które pomaga znaleźć błędy trudne do testowania i debugowania przez identyfikację założeń, które mogą być nieprawdziwe. PREfast znajduje się w Visual Studio 2005.
 – całkowite sprawdzenie sterty danymi niezerowymi, unikając założenia, że sterta jest zawsze pusta. Sprawdzane są granice wszystkich tablic, aby wyłapać nawet jeden bajt przepełniający bufor i znaleźć niezgodne wywołania. • PREfast – narzędzie dla programisty, które pomaga znaleźć błędy trudne do testowania i debugowania przez identyfikację założeń, które mogą być nieprawdziwe. PREfast znajduje się w Visual Studio")
69
Opcje kompilatorów, biblioteki bezpieczeństwa
• Source Code Annotation Language (SAL) – pozwala programiście na przypisanie wartości do bufora. Kiedy kod jest skompilowany, kompilator zna warunki, które pozwalają na określenie wartości oczekiwanych i aktualnych. Funkcjonalność pozwala programiście na odkrycie błędów, które mogą trudne do znalezienia ręcznie.
 – pozwala programiście na przypisanie wartości do bufora. Kiedy kod jest skompilowany, kompilator zna warunki, które pozwalają na określenie wartości oczekiwanych i aktualnych. Funkcjonalność pozwala programiście na odkrycie błędów, które mogą trudne do znalezienia ręcznie.")
70
Opcje kompilatorów, biblioteki bezpieczeństwa
• Application Verifier – to narzędzie pakietu Visual Studio, udostępniające funkcje instrumentacji obecne w systemie operacyjnym Windows. Instrumentacja ta pozwala w czasie działania aplikacji przeprowadzić jej weryfikację w wybranych obszarach, takich, jak przydział pamięci czy użycie sekcji krytycznych i uchwytów. Application Verifier wykrywa problemy czasu wykonywania w zakresie alokacji pamięci, wyjścia poza bloki na stercie, użycia pamięci po usunięciu, podwójnego usunięcia i zanieczyszczenia sterty. W zakresie wykorzystania sekcji krytycznych wykrywa działania, które mogą prowadzić do blokowania lub wycieku zasobów. Jeśli chodzi o użycie uchwytów, wykrywa próby powtórnego użycia uchwytów, które już nie są poprawne.

71
Opcje kompilatorów, biblioteki bezpieczeństwa
Przełącznik kompilatora Visual Studio /GS. Przełącznik /GS wstawia pomiędzy bufor a adres powrotu znacznik. Jeśli przepełnienie bufora nadpisze adres powrotu, to nadpisze także znacznik wstawiony pomiędzy adres a bufor. Nowa budowa ramki stosu jest następująca: • parametry funkcji, • adres powrotu funkcji, • wskaźnik ramki, znacznik, ramka procedur obsługi wyjątków, • lokalnie zadeklarowane zmienne i bufory, • rejestry zachowane przez funkcję wywołaną.

72
Opcje kompilatorów, biblioteki bezpieczeństwa
Przełącznik /GS Gdy testy bezpieczeństwa są włączone, sposób wykonania funkcji ulega zmianie. Instrukcje, które mają być wykonane zaraz po wywołaniu funkcji, znajdują się w początku funkcji. Jeżeli występuje niezgodność, aplikacja domyślnie kończy swoje wykonywanie po poinformowaniu użytkownika

73
Opcje kompilatorów, biblioteki bezpieczeństwa
Wady /GS - chroni tylko przed przepełnieniami stosu - wymaga włączonej optymalizacji - nie działa dla funkcji - z buforami o wielkości 1-4 bajty - o zmiennej liście argumentów - z wstawkami w asemblerze -kompilator może błędnie zadecydować, że funkcja nie wymaga ochrony

74
Gotowe programy testujące
BinScope Binary Analyzer. Analizuje ono aplikacje aby sprawdzić, czy ich autorzy przestrzegali zasad pisania bezpiecznego kodu. Obejmuje to np. sprawdzenie czy nie była użyta stara wersja kompilatora oraz czy kod był kompilowany z opcją /GS, która pozwala zmniejszyć ryzyko podatności na przepełnienie bufora. Co ciekawe Microsoft wprowadził w BinScope zabezpieczenie przed używaniem go do szukania dziur w programach innych autorów.

75
CZĘŚĆ II

76
4. Bezpieczeństwo w WinApi
Podstawowe pojęcia Struktura SECURITY_ATTRIBUTES Secuirty Descriptor Opis ACE Nadanie praw nowemu obiektowi Pobranie praw obiektu

77
Podstawowe pojęcia Logując się do Windowsa, otrzymujemy od systemu access token – klucz (żeton) umożliwiający dostęp do odpowiednich obiektów (do wszystkich ma dostęp tylko administrator). Access token – identyfikuje użytkownika w systemie (login i grupa, do której należy) i określa jego prawa oraz uprzywilejowania (privileges).
 umożliwiający dostęp do odpowiednich obiektów (do wszystkich ma dostęp tylko administrator). Access token – identyfikuje użytkownika w systemie (login i grupa, do której należy) i określa jego prawa oraz uprzywilejowania (privileges).")
78
Podstawowe pojęcia Obiektem systemu Windows nazywamy: Pliki Katalogi
Klucze rejestracyjne Procesy Wątki Muteksy, Semafory Potoki nazywane, nienazwane

79
Podstawowe pojęcia Security Descriptor
Używany, aby zabezpieczyć obiekt, dodawany przy każdej funkcji Create dowolnego obiektu Windows (użycie wartości NULL – dodanie domyślnego deskryptora bezpieczeństwa). Security Descriptor zawiera: Identyfikator właściciela deskryptora Identyfikator głównej grupy deskryptora SACL – systemowa lista kontroli dostępu DACL – zdyskretyzowana lista kontroli dostępu
. Security Descriptor zawiera: Identyfikator właściciela deskryptora. Identyfikator głównej grupy deskryptora. SACL – systemowa lista kontroli dostępu. DACL – zdyskretyzowana lista kontroli dostępu.")
80
Podstawowe pojęcia Czym jest ACL (access control list)?
ACL jest listą elementów ACE. ACE (access control entries) – wskazuje na użytkownika bądź grupę, którego/której mają tyczyć się uprawnienia (allow/deny). DACL – zawiera ACL z określeniem konkretnych praw dla każdego ACE. SACL – zwiera ACL z określeniem, do którego ACE będzie się odnosił audyt i w jakim celu.
 – wskazuje na użytkownika bądź grupę, którego/której mają tyczyć się uprawnienia (allow/deny). DACL – zawiera ACL z określeniem konkretnych praw dla każdego ACE. SACL – zwiera ACL z określeniem, do którego ACE będzie się odnosił audyt i w jakim celu.")
81
Struktura SECURITY_ATTRIBUTES
Struktura ta zawiera deskryptor bezpieczeństwa i informacje o jego dziedziczeniu oraz rozmiar struktury. typedef struct _SECURITY_ATTRIBUTES { DWORD nLength; LPVOID lpSecurityDescriptor; BOOL bInheritHandle; } SECURITY_ATTRIBUTES;

82
Security Descriptor typedef PVOID PSECURITY_DESCRIPTOR; InitializeSecurityDescriptor(&sd,SECURITY_DESCRIPTOR_REVISION); Inicjalizacja deskryptora bezpieczeństwa określonego przez sd.

83
Security Descriptor Ustawienie właściciela i grupy Deskryptora Bezpieczeństwa BOOL SetSecurityDescriptorOwner( PSECURITY_DESCRIPTOR pSecurityDescriptor, // address of security descriptor PSID pOwner, // address of SID for owner BOOL bOwnerDefaulted // flag for default ); BOOL SetSecurityDescriptorGroup( PSID pGroup, // address of SID for group BOOL bGroupDefaulted // flag for default
; BOOL SetSecurityDescriptorGroup( PSID pGroup, // address of SID for group. BOOL bGroupDefaulted // flag for default.")
84
Security Descriptor Ustawienie DACL w Deskryptorze Bezpieczeństwa (skojarzenie z isteniejącym ACL). BOOL SetSecurityDescriptorDacl( PSECURITY_DESCRIPTOR pSecurityDescriptor, // address of security descriptor BOOL bDaclPresent, // flag for presence of discretionary ACL PACL pDacl, // address of discretionary ACL BOOL bDaclDefaulted // flag for default discretionary ACL );
;")
85
Opis ACE Każde ACE zawiera:
SID – security identifier – wartość w rejestrze jednoznacznie określająca użytkownika bądź grupę 32 bitową maskę praw Nagłówek ACE – access denied / access allow

86
Opis ACE Maska praw Prawa dla plików w Windows
Uprawnienia do plików i katalogów

89
Opis ACE Funkcja odwrotna - LookupAccountSid
Skojarzenie SID (security identifier) z podaną nazwą użytkownika. Funkcja odwrotna - LookupAccountSid BOOL LookupAccountName( LPCTSTR lpSystemName, // address of string for system name LPCTSTR lpAccountName, // address of string for account name PSID Sid, // address of security identifier LPDWORD cbSid, // address of size of security identifier LPTSTR ReferencedDomainName, // address of string for referenced domain LPDWORD cbReferencedDomainName, // address of size of domain string PSID_NAME_USE peUse // address of SID-type indicator );
 z podaną nazwą użytkownika. Funkcja odwrotna - LookupAccountSid. BOOL LookupAccountName( LPCTSTR lpSystemName, // address of string for system name. LPCTSTR lpAccountName, // address of string for account name. PSID Sid, // address of security identifier. LPDWORD cbSid, // address of size of security identifier. LPTSTR ReferencedDomainName, // address of string for referenced domain. LPDWORD cbReferencedDomainName, // address of size of domain string. PSID_NAME_USE peUse // address of SID-type indicator. );")
90
Opis ACE Inicjalizacja ACL BOOL InitializeAcl(
PACL pAcl, // address of access-control list DWORD nAclLength, // size of access-control list DWORD dwAclRevision // revision level of access-control list );
;")
91
Opis ACE Dodanie i odebranie praw
BOOL AddAccessAllowedAce( PACL pAcl, // pointer to access-control list DWORD dwAceRevision, // ACL revision level DWORD AccessMask, // access mask PSID pSid // pointer to security identifier ); Definicja AddAccessDeniedAce identyczna
; Definicja AddAccessDeniedAce identyczna.")
92
Nadanie praw nowemu obiektowi
Inicjalizacja Deskryptora Bezpieczeństwa Inicjalizacja ACL Ustawienie praw dla konkretnych użytkowników AddAccessAllowedAce / AddAccessDeniedAce dla konkretnego Sid. (skojarzenie Sid z nazwą użytkownika LookupAccountName). Ustawienie właściciela i grupy Deskryptora Bezpieczeństwa Dodanie DACL do Deskryptora Bezpieczeństwa
. Ustawienie właściciela i grupy Deskryptora Bezpieczeństwa. Dodanie DACL do Deskryptora Bezpieczeństwa.")
93
Nadanie praw nowemu obiektowi
6. Określenie wszystkich elementów struktury SECURITY_ATTRIBUTES sa.nLength= sizeof(SECURITY_ATTRIBUTES); sa.bInheritHandle = FALSE; sa.lpSecurityDescriptor = &sd; 7. Dodanie struktury SECURITY_ATTRIBUTES do nowotworzonego obiektu (funkcja CreateSth)
; sa.bInheritHandle = FALSE; sa.lpSecurityDescriptor = &sd; 7. Dodanie struktury SECURITY_ATTRIBUTES do nowotworzonego obiektu (funkcja CreateSth)")
94
Pobranie praw obiektu Pobranie deskryptora bezpieczeństwa obiektu:
GetFileSecurity, GetKernelObjectSecurity. Pobranie właściciela i grupy Deskryptora Bezpieczeństwa: GetSecurityDescriptorOwner, GetSecurityDescriptorGroup Pobranie DACL Deskryptora Bezpieczeństwa: GetSecurityDescriptorDacl

95
Pobranie praw obiektu Pobranie informacji o ACL:
BOOL GetAclInformation( PACL pAcl, // pointer to access-control list LPVOID pAclInformation, // pointer to ACL information DWORD nAclInformationLength, // size of ACL information ACL_INFORMATION_CLASS dwAclInformationClass // class of requested information ); Struktura ACL_SIZE_INFORMATION typedef struct _ACL_SIZE_INFORMATION { DWORD AceCount; //number of ACEs DWORD AclBytesInUse; //number of bytes in used DWORD AclBytesFree; //number unused bytes } ACL_SIZE_INFORMATION;
; Struktura ACL_SIZE_INFORMATION. typedef struct _ACL_SIZE_INFORMATION { DWORD AceCount; //number of ACEs. DWORD AclBytesInUse; //number of bytes in used. DWORD AclBytesFree; //number unused bytes. } ACL_SIZE_INFORMATION;")
96
Pobranie praw obiektu Pobranie informacji o ACL:
BOOL GetAclInformation( PACL pAcl, // pointer to access-control list LPVOID pAclInformation, // pointer to ACL information DWORD nAclInformationLength, // size of ACL information ACL_INFORMATION_CLASS dwAclInformationClass // class of requested information ); Struktura ACL_SIZE_INFORMATION typedef struct _ACL_SIZE_INFORMATION { DWORD AceCount; //number of ACEs DWORD AclBytesInUse; //number of bytes in used DWORD AclBytesFree; //number unused bytes } ACL_SIZE_INFORMATION;
; Struktura ACL_SIZE_INFORMATION. typedef struct _ACL_SIZE_INFORMATION { DWORD AceCount; //number of ACEs. DWORD AclBytesInUse; //number of bytes in used. DWORD AclBytesFree; //number unused bytes. } ACL_SIZE_INFORMATION;")
97
Prezentacja programu

98
CZĘŚĆ III

99
5. Różne metody zabezpieczania programów
Prezentacja wybranych programów Proste metody zabezpieczania programów Kompresowanie plików wykonywalnych Zabezpieczenia przed debugerami Algorytmy wyznaczające sygnatury danych Problem generatorów liczb pseudolosowych Końcowe wskazówki

100
Prezentacja wybranych programów
Edycja plików binarnych Hex Workshop (shareware) – dodatkowo wyznaczanie sumy kontrolnej plików, porównywanie plików. Dla Linuksa – kHexEdit. Free Hex Editor Neo - darmowy
 – dodatkowo wyznaczanie sumy kontrolnej plików, porównywanie plików. Dla Linuksa – kHexEdit. Free Hex Editor Neo - darmowy.")
101
Prezentacja wybranych programów
Edycja zasobów (kursory, ikony, bitmapy, menu, okna dialogowe itp) plików wykonywalnych Resource Hacker –obsługuje typy: exe, dll, ocx, cpl, scr Darmowy ResEdit - darmowy ExeScope – shareware, wyświetla z jakich funkcji API korzysta program PE Resource Explorer – shareware
 plików wykonywalnych. Resource Hacker –obsługuje typy: exe, dll, ocx, cpl, scr. Darmowy. ResEdit - darmowy. ExeScope – shareware, wyświetla z jakich funkcji API korzysta program. PE Resource Explorer – shareware.")
102
Prezentacja wybranych programów
Debugery Olly Debug SoftICE – nie rozwijany – wiele programów zabezpieczonych przed tym debugerem Visual Studio Debugery umożliwiają zastawianie pułapek w zadanych miejscach kodu, przeglądanie stosu wywołań, niektóre pozwalają na modyfikację kodu, który ma zostać wykonany. Często wykorzystywane przez włamywaczy.

103
Proste metody zabezpieczania programów
Zabezpieczanie przed modyfikacjami pliku binarnego: sprawdzanie rozmiaru pliku (zabezpieczenie przed nieuprawnioną modyfikacją) sprawdzenie daty i czasu modyfikacji Metody nie zapewniają dostatecznej ochrony, mało skuteczne, łatwo zedytować plik binarny, aby jego wielkość pozostała taka sama; podmienianie starej daty modyfikacji.
 sprawdzenie daty i czasu modyfikacji. Metody nie zapewniają dostatecznej ochrony, mało skuteczne, łatwo zedytować plik binarny, aby jego wielkość pozostała taka sama; podmienianie starej daty modyfikacji.")
104
Proste metody zabezpieczania programów
Zastosowanie numeru seryjnego (zabezpieczenie przed nieuprawnionym kopiowaniem). Powinien być unikatowy pomiędzy wszystkimi egzemplarzami oprogramowania. Powinien być wygenerowany przez generator liczb pseudolosowych o takim algorytmie, aby kolejne numery miały jak najmniejszy związek ze sobą, najlepiej żaden. Powinien zawierać numer kontrolny (czy został wygenerowany przez właściwy algorytm) Powinien być jak najdłuższy, aby trudniej go było złamać, a jednocześnie powinien być jak najkrótszy, aby zmniejszyć uciążliwość wprowadzania go przez użytkownika.
. Powinien być unikatowy pomiędzy wszystkimi egzemplarzami oprogramowania. Powinien być wygenerowany przez generator liczb pseudolosowych o takim algorytmie, aby kolejne numery miały jak najmniejszy związek ze sobą, najlepiej żaden. Powinien zawierać numer kontrolny (czy został wygenerowany przez właściwy algorytm) Powinien być jak najdłuższy, aby trudniej go było złamać, a jednocześnie powinien być jak najkrótszy, aby zmniejszyć uciążliwość wprowadzania go przez użytkownika.")
105
Proste metody zabezpieczania programów
Prezentacja programu. Wykorzystanie debugera OllyDbg i edytora plików binarnych Hex Workshop

106
Proste metody zabezpieczania programów
Wnioski: Łamanie kodu polegającego na wplecionym gdzieś jednostkowym teście jest proste. Wielkość programu nie ma znaczenia, kraker uderza w krytyczne punkty aplikacji. Procedury weryfikacyjne powinny udostępniać jak najmniej punktów zaczepienia dla krakera (nie dawać wskazówek lecz zaskakiwać). Wymagana większa ilość procedur weryfikacji – w różnych losowych miejscach, użycie różnych algorytmów generacji wzorca.
. Wymagana większa ilość procedur weryfikacji – w różnych losowych miejscach, użycie różnych algorytmów generacji wzorca.")
107
Proste metody zabezpieczania programów
Idea kluczy rejestracyjnych przypisanych do użytkownika. Stworzenie klucza seryjnego przy użyciu informacji ze środowiska pracy, w którym uruchamiany jest program. Informacje te mogą tworzyć klucz odblokowujący program. Uniemożliwia to przekazywanie kluczy innym użytkownikom, umieszczania w Internecie, stworzenia keygena, pozostaje ryzyko złamania procedury weryfikującej. Wady – użytkownik zmienia konfigurację środowiska pracy – niezbędne ponowne wygenerowanie klucza.

108
Proste metody zabezpieczania programów
Techniki: Odczyt fragmentu pamięci BIOS. Odczyt numeru seryjnego dysku twardego Odczyt numeru MAC Stworzenie kilku alternatywnych kluczy (będą działać, jeśli co najwyżej jeden podzespół zostanie zmieniony – wymiana całego zestawu wymusi generowanie nowego klucza).
.")
109
Proste metody zabezpieczania programów
Gotowe systemy zabezpieczania aplikacji przed nieuprawnionym użyciem: SecuROM, StarForce - ochrona przed kopiowaniem programów Themida – utrudnia debugowanie, zrzuty aplikacji z pamięci, szyfrowanie fragmentów kodu. ASProtect Wszystkie te rozwiązania są drogie, konieczność częstych aktualizacji, gdyż każda nowa wersja jest/zostanie złamana przez krakerów (prędzej czy później). Rozwiązania dobre dla firm.
. Rozwiązania dobre dla firm.")
110
Kompresowanie plików wykonywalnych
Kompresja plików wykonywalnych pozwala na zmniejszenie ich rozmiaru, utrudnia debugowanie i modyfikacje programu, uniemożliwia edycję zasobów i plików binarnych. Kompresor zmniejsza rozmiar kodu binarnego i dołącza procedurę dekompresującą, która rozpakowuje kod do pamięci.

111
Kompresowanie plików wykonywalnych
Programy kompresujące: UPX – freeware, opcja dekompresowania. Program dostępny na wielu platformach. W Windowsie rozpakowuje skompresowany plik bezpośrednio do pamięci i w pamięci uruchamia plik. AsPack –shareware, istnieją programy, które dekompresują pliki wykonywalne spakowane AsPackiem, jak np. Adpackdie. AsPack kompresuje także pliki dll. PkLite – shareware, dokładny raport kompresji. Pe-Pack – kompresuje i dekompresuje AsProtect – shareware – kompresuje pliki wykonywalne, chroni zasoby programu, ochrona przed debugerami, weryfikacja sum kontrolnych (dobre algorytmy), stworzenie wersji trial.
, stworzenie wersji trial.")
112
Kompresowanie plików wykonywalnych
Wady: Praktycznie dla każdego programu kompresującego istnieje program dekompresujący. Niektóre z nich same posiadają taką opcję (UPX, Pe-Pack). Za pomocą edytorów plików binarnych możemy odczytać w nagłówkach takich plików nazwę programów kompresujących. Istnieją narzędzia, które sprawdzają jakimi programami został skompresowany dany plik binarny.
. Za pomocą edytorów plików binarnych możemy odczytać w nagłówkach takich plików nazwę programów kompresujących. Istnieją narzędzia, które sprawdzają jakimi programami został skompresowany dany plik binarny.")
113
Kompresowanie plików wykonywalnych
Jeśli skompresowany program jest całkowicie rozpakowany w trakcie działania, to wystarczy użyć programu ProcDump, aby otrzymać rozpakowaną wersję. Memory dump – zrzut programu z pamięci. Zatrzymanie działania programu przez debuger po deszyfracji lub dekompresji w celu zapisu wypakowanego kodu do pamięci operacyjnej.

114
Zabezpieczenia przed debugerami
Wykrywanie aktywnych debugerów czy programów zrzucających fragment pamięci typu ProcDump jest wyjątkowo trudną czynnością. Istnieje wiele wyrafinowanych sztuczek, które wykrywają tylko określone programy lub nawet tylko konkretne wersje. Dodatkowym utrudnieniem jest fakt, iż debugery są stale udoskonalane – rozszerzenia zabezpieczające przed wykryciem debugerów. Procedury kontrolujące działanie takich programów – zadanie dla zaawansowanych. Płatne środki ochrony przed debugerami: Themida, AsProtect.

115
Zabezpieczenia przed debugerami
Wykrywanie Debugera VS if(IsDebuggerPresent()) //dzialanie Debuger SoftIce nie jest już rozwijany – opracowano różne testy (wstawki w asemblerze) wykrywające jego działanie. Test sprawdzający, czy uruchomiony został program SoftICE poprzez wykrywanie sterownika debugera systemowego: mov ah, 43h int 68h cmp eax, 0F386h jz mamy_debuger
) //dzialanie. Debuger SoftIce nie jest już rozwijany – opracowano różne testy (wstawki w asemblerze) wykrywające jego działanie. Test sprawdzający, czy uruchomiony został program SoftICE poprzez wykrywanie sterownika debugera systemowego: mov ah, 43h. int 68h. cmp eax, 0F386h. jz mamy_debuger.")
116
Zabezpieczenia przed debugerami
Utrudnienie debugowania – wstawki niskopoziomowe. Makra preprocesora w C/C++. Makra zaciemniające kod programu, opłacalne szczególnie, gdy użyte w krytycznych fragmentach programu. Utrudnienie pracy krakera, śledzenie programu w debugerze. Wstawki wydłużają kod i nieznacznie spowalniają jego wykonanie.

117
Zabezpieczenia przed debugerami
Przykład jmp_buf env; #define AD(kod, numer) if (setjmp(env) == 0) \ { \ goto skok_ad_##numer; \ } \ else \ kod; \ goto koniec_ad_##numer; \ skok_ad_##numer: \ longjmp(env,1); \ koniec_ad_##numer: \ ;
 if (setjmp(env) == 0) \ { \ goto skok_ad_##numer; \ } \ else \ kod; \ goto koniec_ad_##numer; \ skok_ad_##numer: \ longjmp(env,1); \ koniec_ad_##numer: \ ;")
118
Zabezpieczenia przed debugerami
Makro wstawia kod: if(setjmp(env)==0) { goto_skok_ad_1; } else //wlasciwy kod goto koniec_ad_1; skok_ad_1: longjmp(env,1); koniec_ad_1; Aby wstawka była skuteczna, powinna zostać użyta wiele razy w kodzie.
==0) { goto_skok_ad_1; } else. //wlasciwy kod. goto koniec_ad_1; skok_ad_1: longjmp(env,1); koniec_ad_1; Aby wstawka była skuteczna, powinna zostać użyta wiele razy w kodzie.")
119
Zabezpieczenia przed debugerami
Fragment programu: while(warunek) { for (i=1;i<tysiac;i++) cos tam; miliard innych rzeczy } Po zaciemnieniu: AD( ,1) AD( miliard innych rzeczy, 2); },0)
 { for (i=1;i<tysiac;i++) cos tam; miliard innych rzeczy. } Po zaciemnieniu: AD( ,1) AD( miliard innych rzeczy, 2); },0)")
120
Zabezpieczenia przed debugerami
Innym sposobem ochrony przed debugerami jest kontrola czasu wykonania procedury. Może być stosowana tylko w najbardziej krytycznych fragmentach kodu, ponieważ jej użycie może spowolnić działanie programu. Zapamiętujemy czas systemowy i co kilkanaście linii kodu porównujemy ją z bieżącym stanem zegara systemowego. Jeśli ich wykonanie trwało za długo, daje nam to sygnał, iż możemy mieć styczność z debugerem.

121
Zabezpieczenia przed debugerami
Przykład: #include <time.h> int main() { time_t sekundy, biezacy; sekundy = time (NULL); //WAZNY KOD biezacy = time(NULL); if(biezacy -1 > sekundy) printf(“Mamy debugger\n”); exit(1); } return 0;
 { time_t sekundy, biezacy; sekundy = time (NULL); //WAZNY KOD. biezacy = time(NULL); if(biezacy -1 > sekundy) printf( Mamy debugger\n ); exit(1); } return 0;")
122
Algorytmy wyznaczające sygnatury danych
Funkcja mieszająca (ang hash function) – dla pewnej danej wejściowej tworzy znacznie krótszą od niej informację, stanowiącą tzw. sygnaturę danej wejściowej (skrót danych). Jej głównym zastosowaniem jest możliwość sprawdzenia integralności danych – tego, czy dane nie zostały zmodyfikowane po wyznaczeniu skrótu, przy zachowaniu jednocześnie niewielkich rozmiarów skrótu.
 – dla pewnej danej wejściowej tworzy znacznie krótszą od niej informację, stanowiącą tzw. sygnaturę danej wejściowej (skrót danych). Jej głównym zastosowaniem jest możliwość sprawdzenia integralności danych – tego, czy dane nie zostały zmodyfikowane po wyznaczeniu skrótu, przy zachowaniu jednocześnie niewielkich rozmiarów skrótu.")
123
Algorytmy wyznaczające sygnatury danych
Cechy idealnej sygnatury: Brak możliwości wygenerowania dwóch różnych wiadomości o tym samym skrócie. Zmiana nawet jednego bitu wiadomości powinna modyfikować średnio połowę bitów skrótu – dzięki temu z charakteru zmiany skrótu nie powinno dać się odczytać charakteru zmiany treści wiadomości i vice versa. Brak możliwości odtworzenia wiadomości wyłącznie na podstawie skrótu.

124
Algorytmy wyznaczające sygnatury danych
Kod CRC – cykliczny kod nadmiarowy – suma kontrolna danych. CRC jest dość łatwe do sfałszowania. Ze względu na szybkość i prostotę wyznaczania oraz niewielki narzut do długości danych jest on powszechnie stosowany wszędzie tam, gdzie trzeba wykryć przypadkowe błędy, na przykład powstałe w wyniku transmisji radiowej lub stratnej kompresji. Nie powinien być stosowany jako metoda zabezpieczenia danych przed złośliwą modyfikacją. Kod CRC wyznacza się poprzez binarne dzielenie z resztą ciągu danych z pewnym dzielnikiem zwanym generatorem lub wielomianem CRC. Zazwyczaj są to wielomiany o długości 17 lub 33 bitów dające kod bitowy.

125
Algorytmy wyznaczające sygnatury danych
MD5 to jeden z najpopularniejszych algorytmów do wyznaczania sygnatury wiadomości. Przez wiele lat uznawany za całkowicie bezpieczny. W 2004 roku znaleziono słabość algorytmu pozwalającą na wyznaczenie wiadomości różnej od zadanej, która ma taki sam skrót jak ona. Obecnie nie stosuje się tej funkcji do zabezpieczania najbardziej wrażliwych z punktu widzenia bezpieczeństwa danych – wciąż jednak może ona być używana do wielu zastosowań - podpisywanie plików pobieranych z Internetu bądź w celu kontroli integralności kodu programu.

126
Algorytmy wyznaczające sygnatury danych
SHA-1 opublikowany w 1993 roku, w 2004 opublikowano jego wady, przez wiele lat uznawany za bezpieczniejszy od MD5. Podpisywanie wiadomości o szczególnym znaczeniu – zaleca się stosowanie SHA-2.

127
Problem generatorów liczb pseudolosowych
Generatory liczb pseudolosowych – zastosowanie w grach komputerowych, w kryptografii (tworzenie trudnych do przewidzenia kluczy). Komputery nie potrafią tworzyć liczb prawdziwe losowych. Liczby pseudolosowe – zestawy liczb, które dają dość dobre przybliżenie prawdziwie losowego ciągu. Generator inicjowany jest pewną wstępną informacją zwaną ziarnem. Idealnie powinno ono pochodzić z losowego źródła. Każdorazowe rozpoczęcie generowania liczb pseudolosowych rozpoczyna się w innym miejscu ciągu. W praktyce dobry ziarnem jest często zmieniający się znacznik czasu, na przykład milisekundy.
. Komputery nie potrafią tworzyć liczb prawdziwe losowych. Liczby pseudolosowe – zestawy liczb, które dają dość dobre przybliżenie prawdziwie losowego ciągu. Generator inicjowany jest pewną wstępną informacją zwaną ziarnem. Idealnie powinno ono pochodzić z losowego źródła. Każdorazowe rozpoczęcie generowania liczb pseudolosowych rozpoczyna się w innym miejscu ciągu. W praktyce dobry ziarnem jest często zmieniający się znacznik czasu, na przykład milisekundy.")
128
Problem generatorów liczb pseudolosowych
Cechy liczb pochodzących z dobrego generatora: Kolejne wartości są zupełnie nieprzewidywalne dla człowieka. Nie można ustalić ziarna nawet na podstawie długiej obserwacji kolejnych wygenerowanych liczb. Znajomość wszystkich do tej pory wygenerowanych bitów nie pozwala na przewidzenie kolejnego.

129
Końcowe wskazówki Nie należy chwalić się wykryciem włamania, nie dawać wskazówek włamywaczowi, lecz po cichu zastosować odpowiednie procedury blokujące możliwość właściwego korzystania z programu. W okolicy testów bezpieczeństwa korzystać z jak najmniejszej liczby wywołań standardowych funkcji Windows API (okienka komunikatów, okna dialogowe).
.")
130
Końcowe wskazówki Lepiej użyć gotowego a nawet darmowego programu antydebugerowego niż pisać odpowiednie funkcje samodzielnie. Dodatkowa kompresja kodu - nawet jeśli krakerzy złamią to zabezpieczenie, nie przyjdzie im to zawsze ad hoc. Pisać skomplikowane, niebanalne i nieszablonowe wstawki antydebugerowe. Makra zaciemniające kod – nie są bariera nie do przejścia dla krakera, ale stanowić mogą duże utrudnienie i zaskoczenie.

131
Końcowe wskazówki Kreatywność, wyjście poza schematy. Cały czas zaskakiwać krakerów, a nie podążać za schematami, których oczekują włamywacze. Nie ma całkowicie bezpiecznych aplikacji, dlatego warto użyć wyobraźni, aby krakerzy musieli przez nas się nieźle napocić.

132
Końcowe wskazówki Sprawdzać zabezpieczenia jak najczęściej, aby maksymalnie utrudnić pracę krakerom – jak najwięcej miejsc, które musi zmodyfikować włamywacz. Unikać pojedynczych, choćby bardzo dobrze zabezpieczonych, punktów kontrolnych, co jest uciechą dla krakerów. Używać różnych algorytmów i różnych metod zabezpieczeń. Wklejając funkcję zabezpieczającą w wiele miejsc w kodzie, starać się, aby za każdym razem ją nieco modyfikować. Nie uruchamiać wszystkich zabezpieczeń w tym samym momencie. Używać zabezpieczeń, które nie uruchamiają się za każdym razem, ale np tylko co pewien okres lub przy użyciu rzadkiej funkcji programu.

133
Końcowe wskazówki Im mniej funkcji ma program, tym lepiej z punktu widzenia bezpieczeństwa. Jeśli jakaś funkcja nie jest koniecznie potrzebna - należy się jej pozbyć. Każda nadmiarowa linia kodu może być potencjalnym źródłem błędu bezpieczeństwa. Im kod będzie prostszy i łatwiejszy w zrozumieniu, tym mniejsza szansa, że będzie zawierał krytyczny błąd.

134
Końcowe wskazówki Większość ataków popełniana jest przez mało doświadczonych użytkowników korzystających z gotowych programów, znanych metod. Mówimy o nich script kiddies. Wszelakie zabezpieczenia, które wydają się nam być mało wartościowe i łatwe dla obejścia dla krakerów, mogą być dobry uzupełnieniem dla reszty zabezpieczeń i skuteczną ochroną przed script kiddies.

135
6. Techniki kryptograficzne
Podstawowe informacje Rys historyczny Symetryczne algorytmy szyfrowania Asymetryczne algorytmy szyfrowania Wykorzystanie kryptografii w zabezpieczaniu programów Końcowe wskazówki

136
Podstawowe informacje
Kodowanie polega na zamianie pewnej informacji na tajny ciąg wyłącznie za pomocą pewnego algorytmu. Wystarczy sama znajomość algorytmu, aby odtworzyć zakodowaną informację. Szyfrowanie – polega na ukryciu wiadomości za pomocą tajnego ciągu zwanego kluczem. Cechą dobrego algorytmu szyfrującego jest to, że ta sama wiadomość źródłowa zaszyfrowana tym samym algorytmem, ale przy użyciu dwóch różnych kluczy daje zupełnie inne ciągu wyjściowe.

137
Podstawowe informacje
Kryptografia – proces poufnej komunikacji z użyciem szyfrów. Kryptoanaliza – proces łamania (odszyfrowywania) zaszyfrowanych informacji.
 zaszyfrowanych informacji.")
138
Podstawowe informacje
System kryptograficzny można nazwać bezwarunkowo bezpiecznym, jeżeli jego złamanie nie jest możliwe nawet przy wykorzystaniu nieograniczonych zasobów obliczeniowych. Przeprowadzenie kryptoanalizy nie jest możliwe. Jeśli podczas ataku zostaną wykorzystane wszystkie możliwe klucze, nie będzie możliwe ustalenie, który klucz był właściwy.

139
Podstawowe informacje
System kryptograficzny jest uznawany za obliczeniowo bezpieczny, jeżeli najlepszy znany algorytm służący do jego złamania wymaga ogromnych zasobów obliczeniowych i czasu. Teoretycznie możliwe jest złamanie takiego szyfru, ale z praktycznego punktu widzenia nie ma to sensu, ponieważ wartość niezbędnych zasobów i czasu znaczeni przekracza maksymalną wartość chronionych danych.

140
Podstawowe informacje
Klucz jednorazowy – klucz o długości równej lub dłuższej od treści wiadomości. Wszystkie znaki takiego klucza są losowe i nie mają związku ze sobą. Zaraz po zaszyfrowaniu klucz powinien być niszczony, odbiorca, mający kopię klucza, po odczytaniu wiadomości, powinien zniszczyć klucz.

141
Podstawowe informacje
W praktyce używanie klucza jednorazowego bardzo trudne: Konieczność bezpiecznego przekazywania klucza i kolejnych, przy wysyłaniu nowych wiadomości. Kosztowne przesyłanie klucza- co najmniej tak długiego jak wiadomość. Problem generacji losowego klucza – napastnik może poznać i złamać algorytm generacji liczb pseudolosowych Bezpieczeństwo całej techniki szyfrowania jest zależna od dostarczenia klucza do nadawcy.

142
Rys historyczny Początkowo szyfry przestawieniowe (każda litera zamieniona miejscami z inną literą) i podstawieniowy (każda litera alfabetu podmieniana na inną odległą w alfabecie o pewną stałą liczbę pozycji – szyfr Cezara). Szyfry polialfabetyczne – różne szyfry użyte do różnych fragmentów wiadomości.
 i podstawieniowy (każda litera alfabetu podmieniana na inną odległą w alfabecie o pewną stałą liczbę pozycji – szyfr Cezara). Szyfry polialfabetyczne – różne szyfry użyte do różnych fragmentów wiadomości.")
143
Rys historyczny Zasada Kerckhoffsa
System szyfrujący jest bezpieczny tylko wtedy, gdy na jego bezpieczeństwo nie wpływa to, czy wróg zna go, czy nie. O sile systemu stanowi klucz.

144
Symetryczne algorytmy szyfrowania
Wykorzystanie takiego samego klucza do szyfrowania i deszyfrowania wiadomości. Oba procesy szybsze niż w szyfrowaniu asymetrycznym, problem stanowić może dystrybucja kluczy.

145
Symetryczne algorytmy szyfrowania
Szyfry blokowe działają na blokach o stałej wielkości, mających zwykle 64 lub 128 bitów. Jeżeli użyto identycznego klucza, ten sam fragment tekstu zawsze uzyska po zaszyfrowaniu taką samą postać. Przykłady: DES, AES. Szyfry strumieniowe generując strumień pseudolosowych bitów. Jest to strumień klucza, który jest wykorzystywany do operacji XOR na operacji jawnej. Ta technika dobrze sprawdza się przy szyfrowaniu ciągłych strumieni danych. Przykład: RC4.

146
Symetryczne algorytmy szyfrowania
DES – algorytm wynaleziony przez IBM. Oryginalny algorytm DES stosował tylko 56-bitowy klucz. Stworzono różne modyfikacje, np DESX – klucz o długości 184 bitów. DES był wielokrotnie łamany. Dla klucza o długości 56 bitów, wszystkie kombinacje można sprawdzić w ciągu kilku tygodni metodą pełnego przeglądu.

147
Symetryczne algorytmy szyfrowania
AES – odpowiedź na niewystarczające bezpieczeństwo algorytmu DES. Możliwe użycie kluczy o długościach 128, 192, 256 bitów. Nie jest pewne jakiej mocy obliczeniowej potrzeba, aby złamać najsilniejszą wersję algorytmu, dlatego też szyfrowanie tą metodą jest uznawane za bezpieczne.

148
Symetryczne algorytmy szyfrowania
RC4 – popularny, do niedawna uważany za bardzo silny, obecnie nie jest zalecany (w 2000 roku opracowano atak na ten algorytm). Wykorzystywany był w systemie szyfrowania WEP stosowanym do szyfrowania wiadomości w sieciach bezprzewodowych. Przydatny, gdy stanowi dodatkową ochronę danych czy kodu źródłowego. Jest relatywnie prosty. Do szyfrowania danych używane są dwa algorytmy: algorytm generowania kluczy wewnętrznych i generator liczb pseudolosowych. Oba algorytmy wykorzystują skrzynkę S o rozmiarach 8x8, która jest tablicą zawierającą 256 wartości od 0 do 255. W tabeli znajdują się wszystkie liczby od 0 do255 ale rozmieszczone w sposób losowy.
. Wykorzystywany był w systemie szyfrowania WEP stosowanym do szyfrowania wiadomości w sieciach bezprzewodowych. Przydatny, gdy stanowi dodatkową ochronę danych czy kodu źródłowego. Jest relatywnie prosty. Do szyfrowania danych używane są dwa algorytmy: algorytm generowania kluczy wewnętrznych i generator liczb pseudolosowych. Oba algorytmy wykorzystują skrzynkę S o rozmiarach 8x8, która jest tablicą zawierającą 256 wartości od 0 do 255. W tabeli znajdują się wszystkie liczby od 0 do255 ale rozmieszczone w sposób losowy.")
149
Symetryczne algorytmy szyfrowania
Algorytm RC4: Tablica skrzynki S zostaje zapełniona kolejnymi wartościami od 0 do 255. Kolejna 256 bajtowa tablica, oznaczana jako K, jest zapełniana wartościami ziarna (o maksymalnej długości 256 bitów). Mieszanie tablicy S: j=0; for i=0 to 255 { j = ( j + S[i] + K[i]) mod 256; zamiana S[i] i S[j]; } Po tej operacji wszystkie wartości w skrzynce S zostaną wymieszane zgodnie z wartością ziarna. Koniec algorytmu generowania kluczy wewnętrznych.
. Mieszanie tablicy S: j=0; for i=0 to 255. { j = ( j + S[i] + K[i]) mod 256; zamiana S[i] i S[j]; } Po tej operacji wszystkie wartości w skrzynce S zostaną wymieszane zgodnie z wartością ziarna. Koniec algorytmu generowania kluczy wewnętrznych.")
150
Symetryczne algorytmy szyfrowania
Kolejny krok: uzyskanie danych strumienia klucza za pomocą generatora liczb pseudolosowych. Dla każdego bajtu strumienia klucza wykonywany jest następujący pseudokod: i = ( i + 1 ) mod 256; j = ( j + S[i] ) mod 256; zamiana S[i] i S[j]; t = ( S[i] + S[j] ) mod 256; Przekazanie wartosci S[t]; Przekazana wartość S[t] sanowi pierwszy bajt strumienia klucza. Algorytm jest powtarzany dla kolejnych bajtów w strumieniu.
 mod 256; j = ( j + S[i] ) mod 256; zamiana S[i] i S[j]; t = ( S[i] + S[j] ) mod 256; Przekazanie wartosci S[t]; Przekazana wartość S[t] sanowi pierwszy bajt strumienia klucza. Algorytm jest powtarzany dla kolejnych bajtów w strumieniu.")
151
Asymetryczne algorytmy szyfrowania
Szyfry asymetryczne wykorzystują dwa klucze – klucz publiczny i klucz prywatny. Klucz publiczny jest dostępny dla wszystkich, należy natomiast zapewnić poufność klucza prywatnego. Każda wiadomość zaszyfrowana za pomocą klucza publicznego może zostać odszyfrowana tylko poprzez użycie klucza prywatnego. Rozwiązuje to problem dystrybucji kluczy. Wyznaczenie jednego z klucza na podstawie drugiego jest bardzo trudne i w praktyce niewykonalne.

152
Asymetryczne algorytmy szyfrowania
RSA – najpopularniejszy system używający szyfrowania asymetrycznego. Jego bezpieczeństwo opiera się na problemie faktoryzacji dużych liczb, która jest bardzo złożona obliczeniowo.

153
Asymetryczne algorytmy szyfrowania
Generacja klucza RSA: Losowanie dużych liczb pierwszych p i q oraz liczby e względnie pierwszej z φ(n), gdzie n=p*q, φ (p*q)=(p-1)*(q-1). φ – funkcja Eulera. Obliczenie d=e-1 mod φ(n) Kluczem publicznym jest para (e,n), kluczem prywatnym para (d,n). Liczby p i q powinny zostać zniszczone i nigdy nie powinny być podawane publicznie. Szyfrowanie wiadomości m polega na wykonaniu operacji: c=me mod n Deszyfrowanie polega na podniesieniu zaszyfrowanej wiadomości do potęgi d. Zgodnie z twiedzeniem Eulera : cd= med = m mod n
, gdzie n=p*q, φ (p*q)=(p-1)*(q-1). φ – funkcja Eulera. Obliczenie d=e-1 mod φ(n) Kluczem publicznym jest para (e,n), kluczem prywatnym para (d,n). Liczby p i q powinny zostać zniszczone i nigdy nie powinny być podawane publicznie. Szyfrowanie wiadomości m polega na wykonaniu operacji: c=me mod n. Deszyfrowanie polega na podniesieniu zaszyfrowanej wiadomości do potęgi d. Zgodnie z twiedzeniem Eulera : cd= med = m mod n.")
154
Asymetryczne algorytmy szyfrowania
Jeśli nie znamy d, to nie odtworzymy łatwo wiadomości. Nie znając sposobu faktoryzacji n na p i q, nie odtworzymy łatwo d na podstawie znanego e. Bezpieczeństwo metody RSA zależy od długości klucza. Najdłuższy klucz, jaki do tej pory udało się skutecznie złamać, to 600 bitów. Typowe klucze mają długość 1024 bitów, zalecane stosowanie kluczy o długości 2048 bitów.

155
Wykorzystanie kryptografii w zabezpieczaniu programów
Testowanie integralności danych programu Mamy pliki ‘ok.txt’ i ‘ok2.txt’, chcemy zweryfikować integralność pliku ‘ok.txt’. Wyznaczamy MD5 z zawartości pliku ‘ok.txt’. Szyfrujemy zawartość pliku ‘ok2.txt’, używając jako klucza wartości otrzymanej powyżej. (Metoda RC4). Dostarczamy plik ‘ok.txt’ w postaci normalnej i ‘ok2.txt’ w postaci zaszyfrowanej. W trakcie działania programu wyznaczmy MD5 z zawartości pliku ‘ok.txt’. Za pomocą powyższej wartości deszyfrujemy plik ‘ok2.txt’. Próbujemy użyć w programie pliku ‘ok2.txt’ jeśli plik został zmodyfikowany, nie uda nam się to.
. Dostarczamy plik ‘ok.txt’ w postaci normalnej i ‘ok2.txt’ w postaci zaszyfrowanej. W trakcie działania programu wyznaczmy MD5 z zawartości pliku ‘ok.txt’. Za pomocą powyższej wartości deszyfrujemy plik ‘ok2.txt’. Próbujemy użyć w programie pliku ‘ok2.txt’ jeśli plik został zmodyfikowany, nie uda nam się to.")
156
Wykorzystanie kryptografii w zabezpieczaniu programów
Weryfikacja pliku wykonywalnego Jeden program wylicza sumę kontrolną drugiego i wkleja w wyznaczone jego miejsce sumę kontrolną (sygnatura jest wyznaczana z pominięciem tego fragmentu). Jeśli sygnatura pliku wykonywalnego się zmieni, można to łatwo porównać z wklejonym wzorcem. Podczas używania tego zabezpieczenia nie możemy korzystać z programów kompresujących. Weryfikacja integralności pliku wykonywalnego powinna odbywać się jak najczęściej. Aby utrudnić ataki, gdyż włamywacz może wyznaczyć MD5 zmienionego pliku i wprowadzić go w odpowiednie miejsce, możemy wyznaczać skrót danych nie dla całego pliku, ale dla wybranych fragmentów (pierwsze 200 znaków, co 13 linia).
. Jeśli sygnatura pliku wykonywalnego się zmieni, można to łatwo porównać z wklejonym wzorcem. Podczas używania tego zabezpieczenia nie możemy korzystać z programów kompresujących. Weryfikacja integralności pliku wykonywalnego powinna odbywać się jak najczęściej. Aby utrudnić ataki, gdyż włamywacz może wyznaczyć MD5 zmienionego pliku i wprowadzić go w odpowiednie miejsce, możemy wyznaczać skrót danych nie dla całego pliku, ale dla wybranych fragmentów (pierwsze 200 znaków, co 13 linia).")
157
Wykorzystanie kryptografii w zabezpieczaniu programów
Zaciemnianie kodu – sprawienie, by stał się nieczytelny dla człowieka. Szyfrowanie fragmentów kodu i deszyfrowanie ich w trakcie działania programu – samo modyfikujący się program.

158
Wykorzystanie kryptografii w zabezpieczaniu programów
Klucz programowy – klucz zawierający fragmenty kodu programu. Bez jego dostępności program nie zadziała poprawnie. Im dłuższy klucz programowy – tym trudniejsze złamanie programu – staje się niemal zadaniem napisania kodu od nowa. Kod może zawierać niektóre fragmenty programu – określone funkcje, linie kodu.

159
Wykorzystanie kryptografii w zabezpieczaniu programów
Przykład. Mamy program A zabezpieczony kluczem programowym. Jego działanie polega na próbie wczytania klucza programowego i wprowadzenie otrzymanych bajtów w odpowiednie fragmenty pamięci. Do stworzenia klucza będzie potrzebny program B. Program A uruchomiony z parametrem będącym poprawnym hasłem, utworzy plik ‘klucz’, do którego zapisze aktualną postać fragmentu kodu. Plik zostanie użyty przez program B, który wyszukuje zawartość pliku ‘klucz’ w programie A i nadpisuje ją zerami. Program A uruchomiony z parametrem klucz odczytuje klucz programowy z pliku ‘klucz’ i odpowiednie fragmenty pamięci zostaną nadpisane danymi z klucza.

160
Wykorzystanie kryptografii w zabezpieczaniu programów
Deszyfrowanie fragmentów programu w trakcie jego działania – ochrona przed zrzutem zawartości pamięci (oczywiście nie jest 100% skuteczna – kraker nadal może robić zrzuty pamięci – nie wiadomo, czy w odpowiednim momencie). Procedury zabezpieczeń powinny wykonywać się w najróżniejszych miejscach programu i w różnych odstępach czasu. Każda procedura powinna być deszyfrowana innym kluczem.
. Procedury zabezpieczeń powinny wykonywać się w najróżniejszych miejscach programu i w różnych odstępach czasu. Każda procedura powinna być deszyfrowana innym kluczem.")
161
Wykorzystanie kryptografii w zabezpieczaniu programów
Przykład. Mamy program A. Program użyty z parametrem klucz produkuje plik ‘klucz’ z zawartością kodu programowego. Program B zabezpieczający program A, uruchamiany jako: B A klucz kod. Plik ‘klucz’ zostanie zniszczony, a program A zaszyfrowany podanym kodem. Użycie programu A z podanym jako parametrem kodem – odszyfrowanie.

162
Wykorzystanie kryptografii w zabezpieczaniu programów
CryptoAPI – interfejs programistyczny aplikacji, który umożliwia szyfrowanie, wyznaczanie sygnatur – zadania związane z kryptografią. Plik nagłówkowy Wincrypt.h

163
Wykorzystanie kryptografii w zabezpieczaniu programów
CSP - Cryptographic Service Provider Zawiera implementacje standardów i algorytmów kryptograficznych. W wariancie minimalnym, CSP składa się z biblioteki DLL (implementacje funkcji CryptoSPI) . CryptAcquireContext - Funkcja pozyskuje uchwyt do pojemnika klucza wewnątrz CSP. Uchwyt może być użyty do różnorakich funkcji dla wybranego CSP. CryptReleaseContext - Zwalnia uchwyt do CSP i pojemnika klucza.
 . CryptAcquireContext - Funkcja pozyskuje uchwyt do pojemnika klucza wewnątrz CSP. Uchwyt może być użyty do różnorakich funkcji dla wybranego CSP. CryptReleaseContext - Zwalnia uchwyt do CSP i pojemnika klucza.")
164
Wykorzystanie kryptografii w zabezpieczaniu programów
HCRYPTPROV Uchwyt do CSP (cryptographic service provider). typedef unsigned long HCRYPTPROV; HCRYPTHASH Uchwyt do obiektów hash typedef unsigned long HCRYPTHASH; Obiekt Hash - obiekt używany do haszowania (wyznaczania sygnatury) wiadomości. Jest tworzony poprzez CryptCreateHash. CryptGetHashParam - Funkcja odzyskuje dane, które operują na obiekcie hash oraz aktualną wartość sygnatury. CryptHashData Function - Dodaje dane do obiektu hash.
. typedef unsigned long HCRYPTPROV; HCRYPTHASH Uchwyt do obiektów hash. typedef unsigned long HCRYPTHASH; Obiekt Hash - obiekt używany do haszowania (wyznaczania sygnatury) wiadomości. Jest tworzony poprzez CryptCreateHash. CryptGetHashParam - Funkcja odzyskuje dane, które operują na obiekcie hash oraz aktualną wartość sygnatury. CryptHashData Function - Dodaje dane do obiektu hash.")
165
Końcowe wskazówki Klucze programowe
Jeśli klucz zawiera fragmenty kodu programu, to ciężko jest go złamać, bo bez klucza program po prostu nie zadziała. Różne fragmenty programu powinny otrzymywać różne klucze. Klucze szyfrujące fragment kodu Bez podania poprawnego klucza uruchomienie programu nie będzie możliwe. Każdy fragment programu powinien zawierać inny klucz. Deszyfracja powinna odbywać się w trakcie działania programu.

166
Końcowe wskazówki Wrażliwe dane zabezpieczać bardziej niż kod. Szyfrowanie ich, sprawdzanie, czy nikt ich nie uszkodził lub zmodyfikował bez pozwolenia.

167
Końcowe wskazówki Nigdy nie polegajmy na tym, że zaciemnianie sposobu działania programu bądź kodu spowoduje, że będzie on bezpieczniejszy, ale o ile to możliwe powinniśmy zakrywać przed niepowołanymi użytkownikami informacje, które ich nie dotyczą.

168
Łańcuch a sieć bezpieczeństwa
Łańcuch – kilka zabezpieczeń polega na sobie w taki sposób, że unieszkodliwienie dowolnego z nich powoduje, iż pozostałe nie działają. Sieć – wiele niezależnych zabezpieczeń, które mogą testować to samo lub nawet zabezpieczać siebie nawzajem. Jeśli włamywacz pokona jedno zabezpieczenie, jest szansa, że zostanie zatrzymany przez inne. Wspólne działanie zabezpieczeń. Niech zabezpieczenia nie polegają jedne na drugim, ale niech kontrolują się wzajemnie – aby system był bezpieczny, wystarczy aby jedno działało.

169
Źródła Hart Johnson M., Windows System Programming, Pearson Education, 2010. Brain Marshall, Reeves Ron, Win32 System Services, Prentice Hall, 2000. Erickson Jon, Hacking. Sztuka penetracji, Helion, Gliwice, 2004. Ross Jacek, Bezpieczne Programowanie. Aplikacje hakeroodporne, Helion, Gliwice, 2009. Centrum Innowacji Microsoft w Poznaniu MSDN Library – Security

170
Źródła Artykuły i prezentacje w Internecie:
Artykuły i prezentacje w Internecie:

171
Dziękujemy za uwagę

Podobne prezentacje
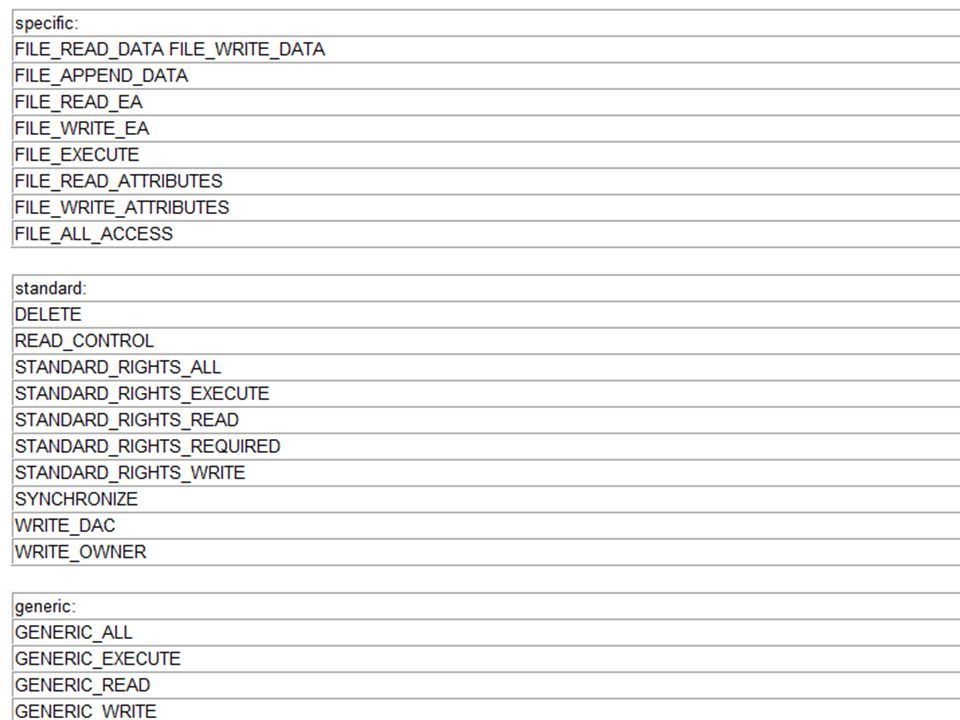

 Klasy i obiekty.>")










 PIOTR MAJCHER WYŻSZA SZKOŁA ZARZĄDZANIA I MARKETINGU W SOCHACZEWIE Zarządzanie.>")







